9장. 서브쿼리 활용하기
- 복잡한 데이터를 효과적으로 분석하려면 기존 쿼리의 실행 결과를 기반으로 다시 쿼리를 실행해야 하는 경우가 있습니다.
- 이 글에선 쿼리를 중첩해 작성하는 서브쿼리에 대해 알아보겠습니다.
📗 서브쿼리
📌 서브쿼리란?(Sub Query)
- 서브쿼리란 쿼리 안에 포함된 또 다른 쿼리를 말하는 것입니다.
- 안쪽 서브쿼리의 실행 결과를 받아 바깥쪽 메인쿼리가 실행됩니다.
- 다음 예제를 풀어보면서 서브쿼리에 대해 알아보겠습니다.
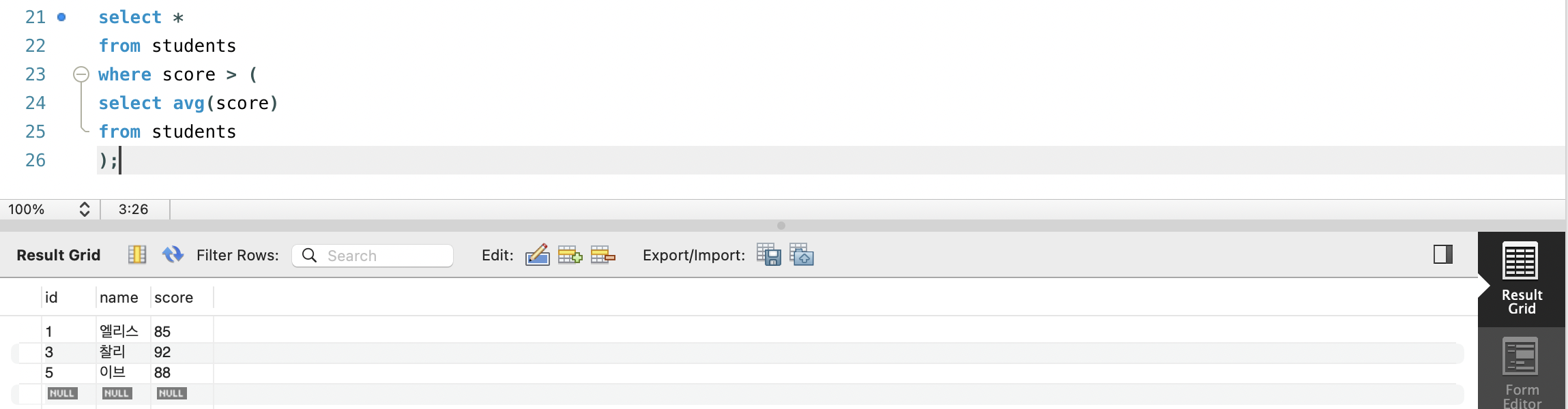
students 테이블에서 평균 점수보다 더 높은 점수를 받은 학생 찾기
- 이 문제에 대한 쿼리문을 작성하면 다음과 같습니다.
select *
from students
where score > (평균_점수);- 여기서 (평균_점수)가 학생들의 평균점수를 구하는 서브쿼리가 들어갈 공간입니다.
- 서브쿼리를 만드려면 괄호() 안에 새로운 쿼리문을 작성하면 됩니다.
📌 서브쿼리의 특징
- 서브쿼리는 다음 5가지의 특징이 있습니다.
1. 중첩구조다.
- 서브쿼리는 메인쿼리 내부에 중첩해 작성하는 용도의 쿼리입니다.
- 괄호()안에 서브쿼리를 작성해 메인쿼리의 일부로 사용합니다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE 칼럼명 연산자 (
서브쿼리
);2. 메인쿼리와는 독립적으로 실행된다.
- 서브쿼리는 메인쿼리와는 별개로 독립적으로 실행됩니다.
- 서브쿼리가 자체적으로 실행한 결과를 반환하면, 메인쿼리가 이를 받아 최종 실행합니다.
3. 다양한 위치에서 사용 가능하다.
- 서브쿼리는 WHERE절 뿐만 아니라 SQL의 여러 절에서 사용할 수 있습니다.
대표적인 서브쿼리 활용가능한 절
- SELECT
- FROM
- JOIN
- WHERE
- HAVING
4. 단일 값 또는 다중 값을 반환한다.
- 서브쿼리는 실행 결과를 단일 값 또는 다중 값으로 반환합니다.
- 이를 각각 단일 값 서브쿼리, 다중 값 서브쿼리라고 합니다.
단일 값 서브쿼리
- 서브쿼리를 실행하면 하나의 값을 반환함
- 단일값으로 반환된 결과는 메인쿼리에서 받아 비교 연산자와 함께 사용됨
다중 값 서브쿼리
- 서브쿼리를 실행하면 여러 개의 값을 반환
- 다중 값으로 반환된 결과는 메인쿼리에서 받아 IN, ANY, ALL, EXIST 연산자와 함께 사용됨
5. 조건 필터링 결과 또는 데이터 집계 결과를 반환한다.
- 서브쿼리는 메인쿼리에 특정 조건으로 필터링한 결과나 특정 연산에 따라 집계된 데이터를 제공합니다.
- 위에서 학생들 점수의 평균값을 집계함수로 반환한게 그 예시입니다.
- 따라서 좀 더 복잡하고 정교한 데이터 분석을 할 때 유용합니다.
📌 다양한 위치에서의 서브쿼리
- 8장에서 다뤘던 market 데이터베이스를 활용해 다양한 위치에서의 서브쿼리 사용법을 알아보겠습니다.
SELECT 절에서의 서브쿼리
- payment 테이블의 모든 결제 정보가 평균 결제 금액과 얼마나 차이나는지 알고 싶습니다. 어떻게 해야 할까요?
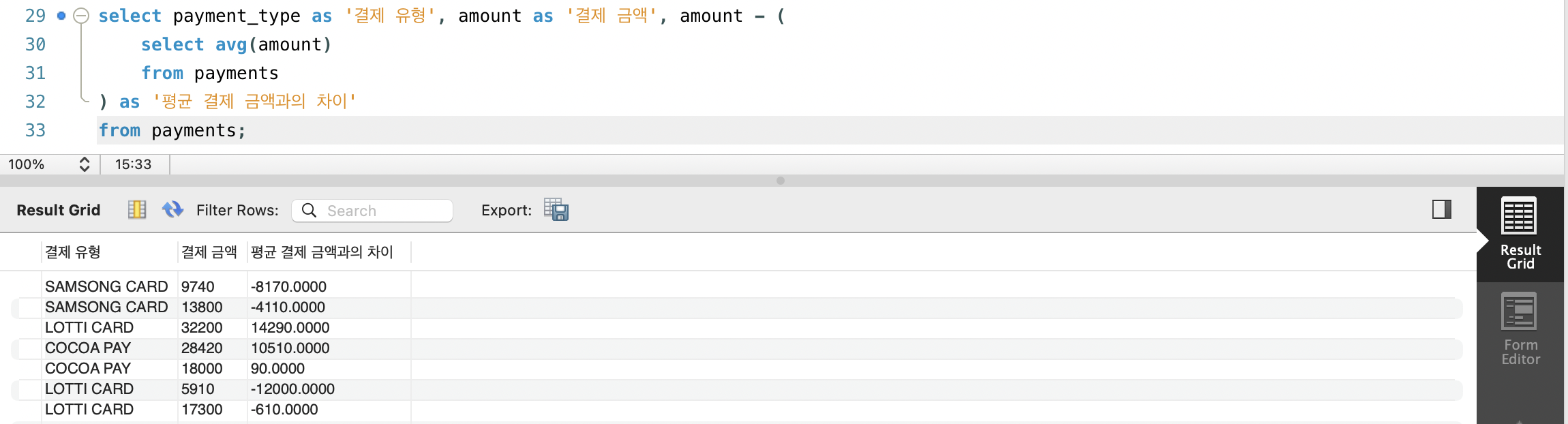
- 다음과 같이 SELECT절에서 새로 서브쿼리를 만들어 모든 amount의 평균값을 구하고 그 값을 유저들의 amount에 빼줘서 뷰를 만들수 있습니다.
FROM 절에서의 서브쿼리
- order_details 테이블에서 1회 주문 시 평균 상품 개수를 구하고 싶습니다.
- 단, 배송 완료된 상품 외에 장바구니에 담긴 상품도 주문 개수에 포함합니다.
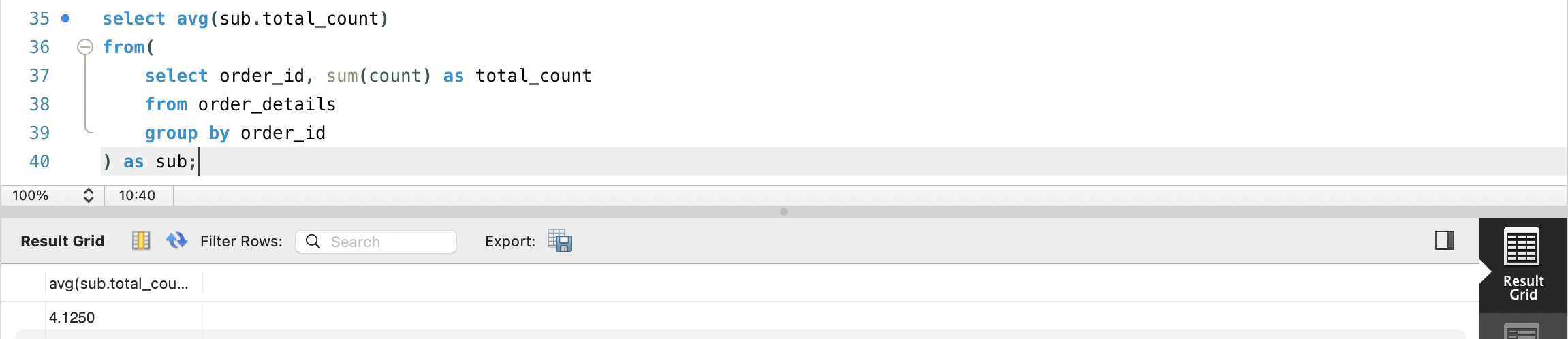
- 이 문제에선 order_details에 있는 주문내역들을 orders와 그룹화하여 orders의 맴버 수로 주문평균을 구해야 합니다.(order_details는 중복된 맴버의 주문까지 다 포함되어있어서 1인당 주문 평균을 구할 수 없음)
- FROM절에 orders 테이블과 그룹화한 테이블을 sub라는 별칭으로 지어주고, 메인 쿼리에서 sub에 모든 count의 합을 평균으로 구해서 뷰를 만들수 있습니다.
- SELECT 절에서의 서브쿼리는 단일 값을 반환해야 한다는 제한이 있지만, FROM절에서의 서브쿼리는 반환하는 행과 칼럼의 갯수가 제한이 없다는 특징이 있습니다.
- FROM 절에서의 서브쿼리는 반환값에 별칭을 지정해줘야 합니다.
JOIN 절에서의 서브쿼리
- products와 order_details 테이블을 조인해 상품별 주문 개수를 조회하려 합니다.
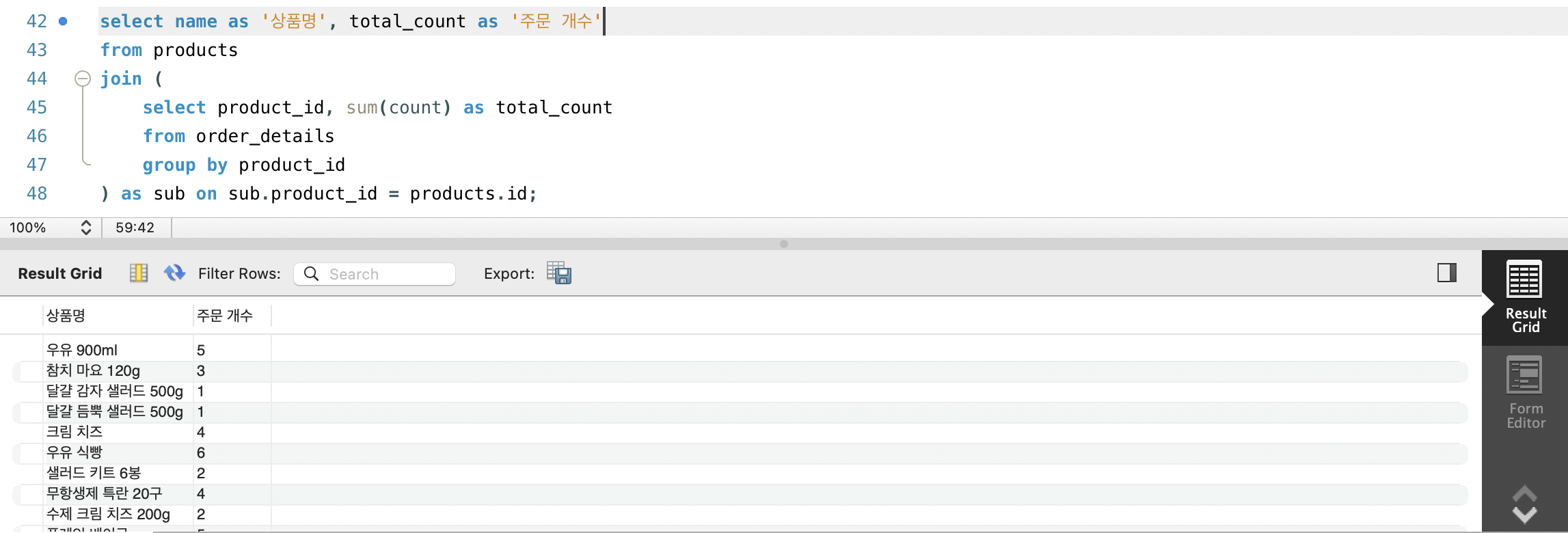
- JOIN 해야할 테이블에서 중복되는 product_id를 그룹화로 통일해줘서 테이블을 JOIN해주면 상품명이 겹치는일 없이 주문 개수를 구할 수 있습니다.
- JOIN 절에서의 서브쿼리는 FROM 절에서의 서브쿼리와 마찬가지로 반환해야 하는 행과 칼럼의 개수에 제한이 없습니다.
- JOIN에서의 서브쿼리는 FROM과 같이 별칭을 지정해줘야 합니다.
WHERE 절에서의 서브쿼리
- products 테이블에서 평균 가격보다 비싼 상품을 조회해봅시다.
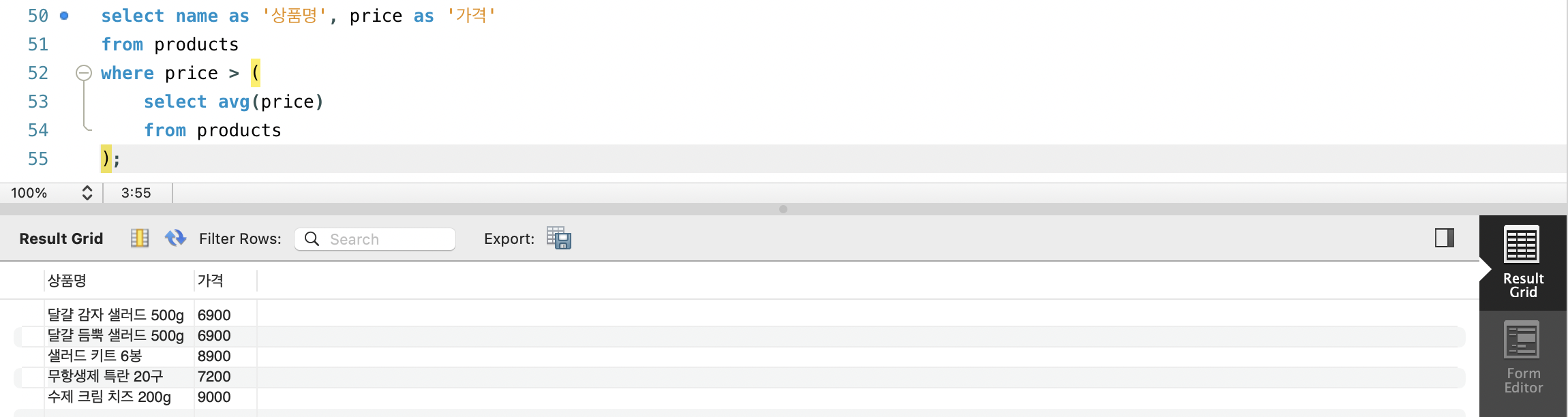
- 맨 처음에 해봤던 평균보다 높은 점수의 학생을 구하는 문제와 동일합니다.
- WHERE 절에서의 서브쿼리는 단일 값 또는 다중 행의 단일 칼럼을 반환합니다.
- 서브쿼리의 반환값이 단일 값일 경우 비교연산자를 통해 값을 비교할 수 있습니다.
- 만약 다중 행의 단일 칼럼이 반환값으로 오는 경우엔 IN, ANY, ALL, EXIST 연산자를 사용합니다.
HAVING 절에서의 서브쿼리
- products 테이블과 order_details 테이블을 조인해 크림 치즈보다 매출이 높은 상품을 조회해봅시다.
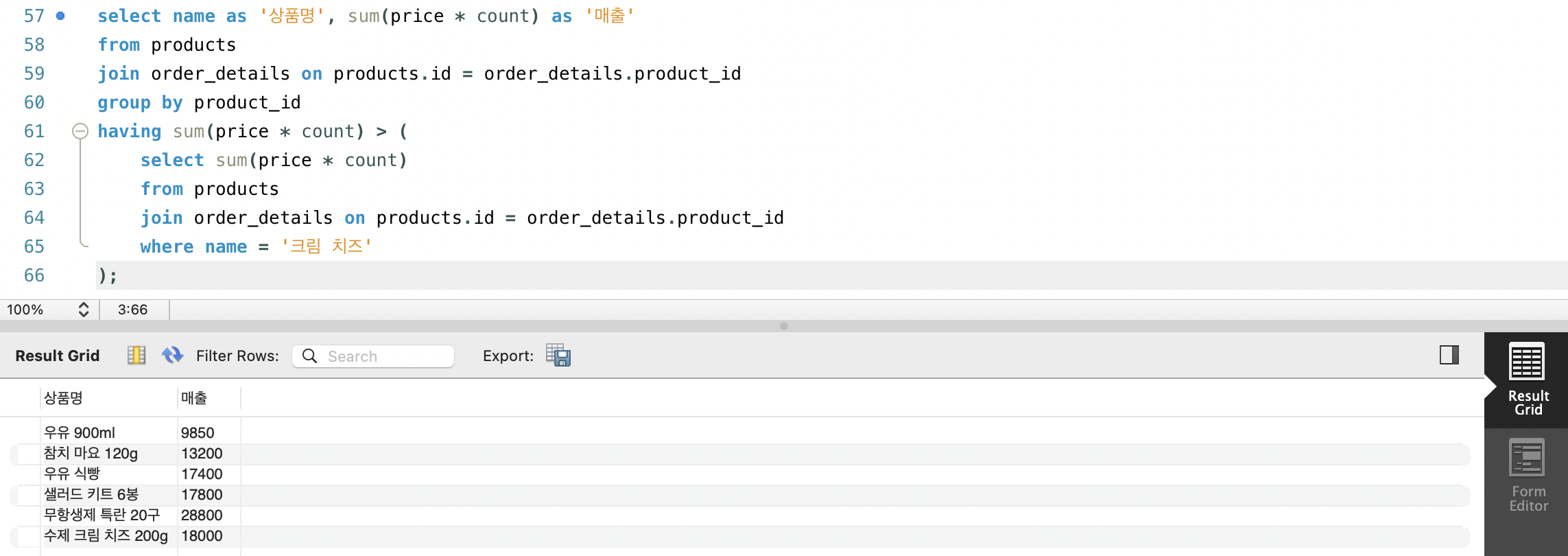
- products와 order_details를 서로 JOIN해 상품의 가격과 사용자가 주문한 갯수를 합칩니다.
- 사용자의 id로 그룹화 시켜 각 상품의 총 매출을 뽑으면 되는데, 크림 치즈보다 매출이 높아야 하니 having 조건절에서 다시 products와 order_details를 JOIN한 테이블을 만들어 거기서 크림 치즈의 총 매출만 서브쿼리로 구해서 튜플들의 총 매출과 비교해 뷰를 만들면 됩니다.
- HAVING 절에서의 서브쿼리는 그룹화 필터링을 수행하므로 WHERE 절의 서브쿼리와 같이 단일 값 또는 다중 행의 단일 칼럼을 반환할 수 있습니다.
📌 IN, ANY, ALL, EXISTS
- 이번엔 IN, ANY, ALL, EXISTS 연산자에 대해 알아보겠습니다.
IN 연산자
- IN 연산자는 지정된 집합에 포함되는 대상을 찾습니다.
- IN(값1, 값2)와 같은 형태로 쉼표(,)로 구분된 값 목록을 입력받거나 IN(서브쿼리) 형태로 다중 행의 단일 칼럼을 반환하는 서브쿼리를 입력받습니다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE 칼럼명 IN (쉼표로_구분된_값_목록);SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE 칼럼명 IN (다중_행의_단일_칼럼을_반환하는_서브쿼리);- products 테이블에서 name이 우유 식빵 또는 크림 치즈인 대상의 id를 조회해봅시다.
- 기존방식

- IN 연산자 사용

- 이번엔 우유식빵 또는 크림치즈를 포함하는 모든 주문의 상세 내역을 조회해봅시다.
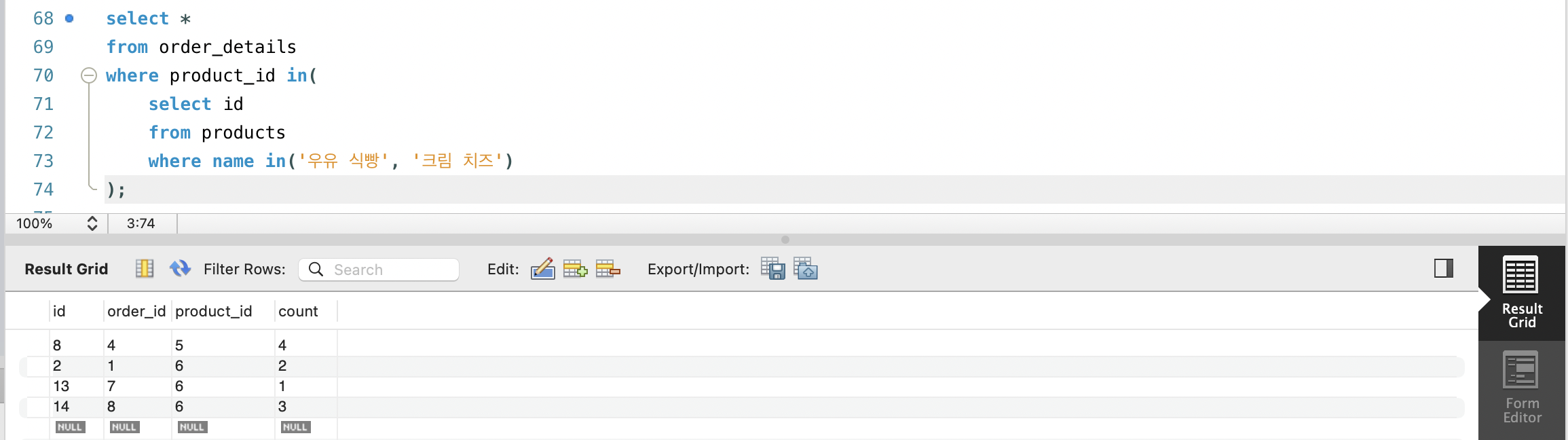
- where 절에 서브쿼리를 사용해 다중 행의 단일 칼럼을 뽑아내고(우유 식빵, 크림 치즈) IN연산자로 필터링하면 됩니다.
- 이번엔 우유 식빵과 크림 치즈를 주문하거나 장바구니에 담은 사용자의 id와 nickname을 찾아봅시다.
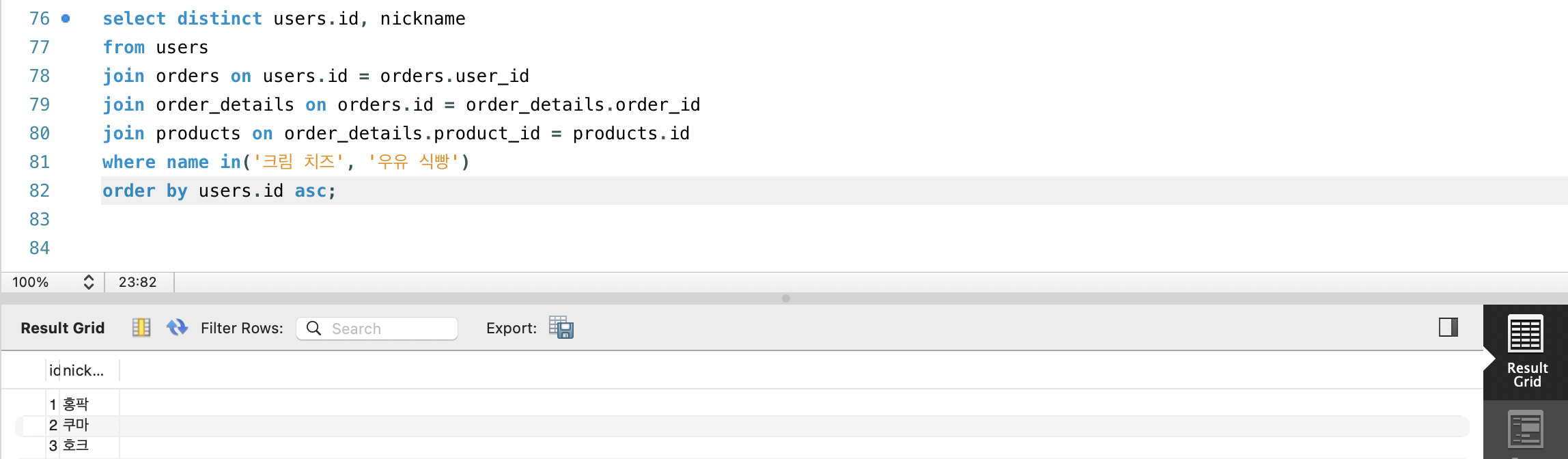
- id값인 users 테이블 부터 조건문에 사용할 상품명이 담긴 products 테이블 까지 전부 JOIN해서 IN연산자로 구해주면 됩니다.
ANY 연산자
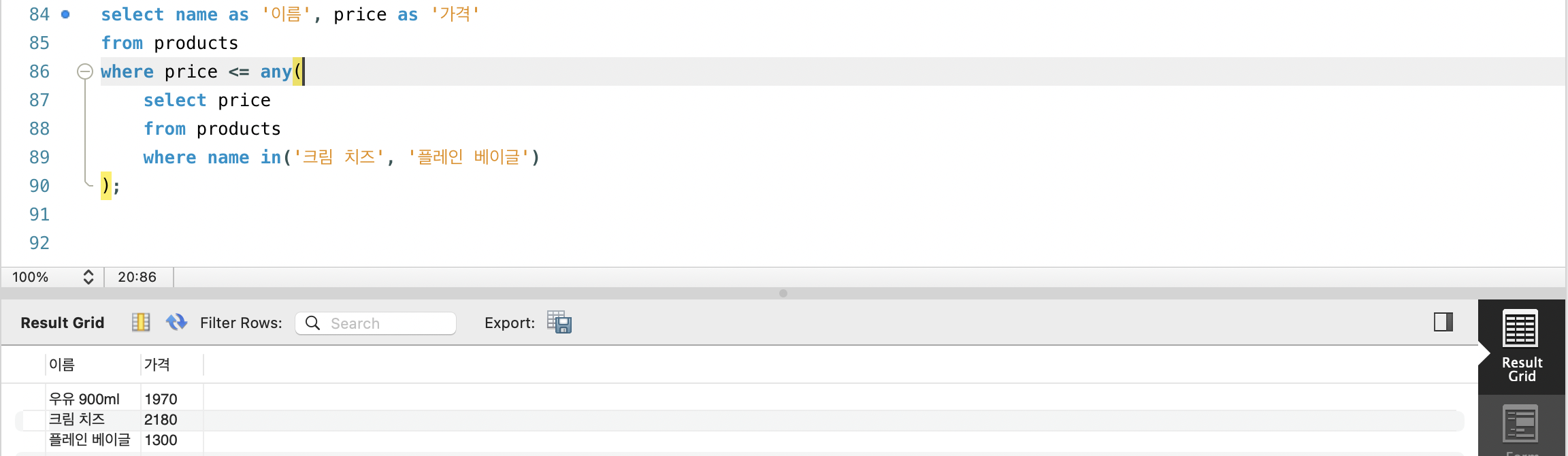
- ANY 연산자는 지정된 집합의 모든 요소와 비교 연산을 수행해 하나라도 만족하는 대상을 찾습니다.
- 다중 행의 단일 칼럼을 반환하는 서브쿼리를 입력으로 받습니다.
SELECT 칼럼명1, 칼럼명2, ..
FROM 테이블명
WHERE 칼럼명 비교_연산자 ANY(다중_행의_단일_칼럼을_반환하는_서브쿼리);- products 테이블에서 우유 식빵 또는 플레인 베이글과 비교해 이들보다 더 저렴한 상품이 있는지 찾아봅시다.
ALL 연산자
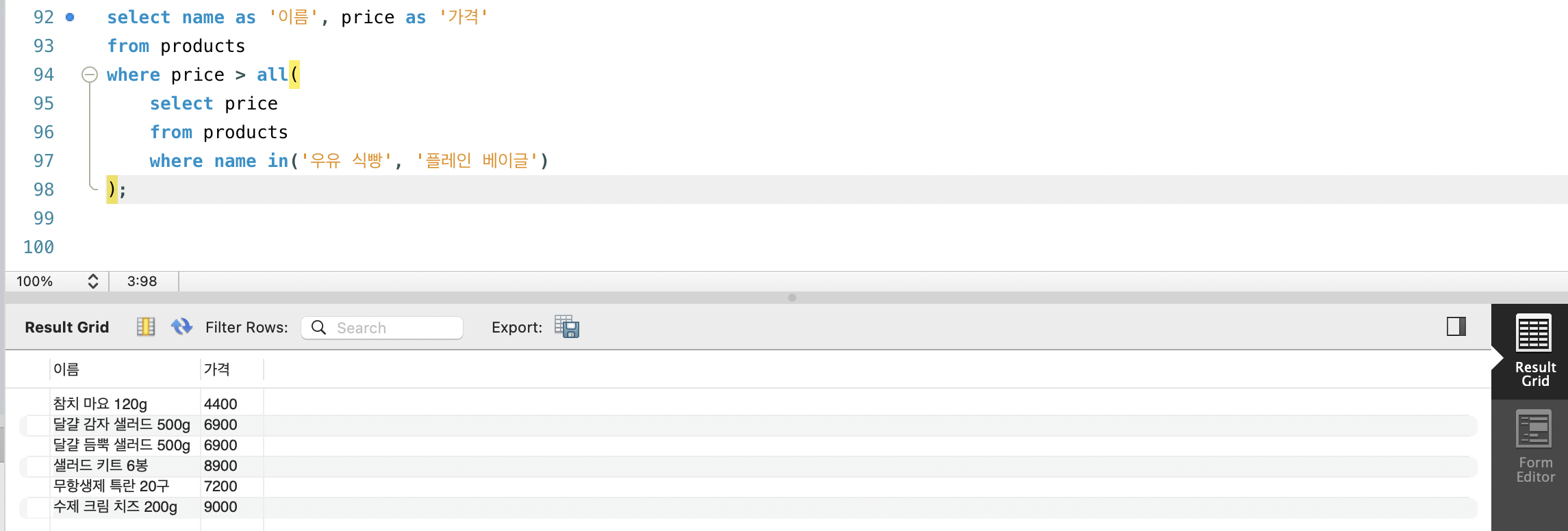
- ALL 연산자는 지정된 집합의 모든 요소와 비교 연산을 수행해 모두를 만족하는 대상을 찾습니다.
- ANY 연산자와 다르게 모든 요소가 비교 연산을 만족해야 한다는 특징이 있습니다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE 칼럼명 비교_연산자 ALL(다중_행의_단일_칼럼을_반환하는_서브쿼리);- products 테이블에서 우유 식빵과 플레인 베이글 보다 비싼 상품을 조회해 봅시다.
EXISTS 연산자
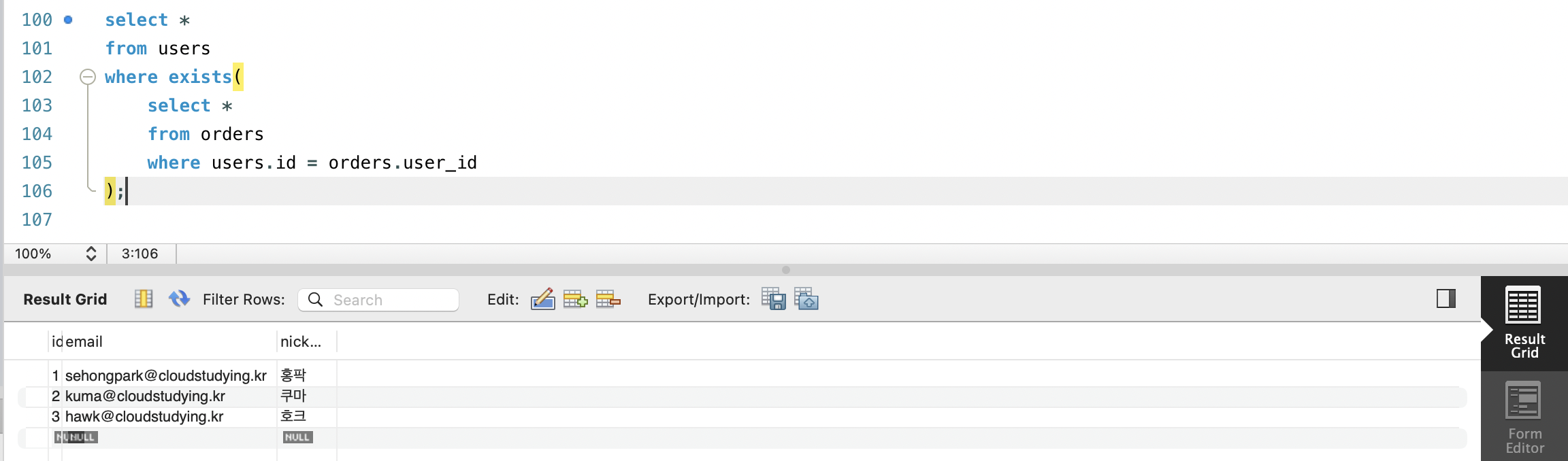
- EXISTS 연산자는 서브쿼리를 입력받아 서브쿼리가 하나 이상의 행을 반환하는 경우 TRUE, 그렇지 않으면 FALSE를 반환합니다.
- 이때 서브쿼리가 반환하는 행의 개수나 칼럼의 내용엔 제한이 없습니다.
- 단지 해당 서브쿼리에 반환값이 존재하는지, 존재하지 않는지를 판단하는 용도로 사용되는 연산자입니다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE EXISTS (서브쿼리);-
적어도 한번은 주문한적이 있는 사용자를 조회해봅시다.
-
참고로 EXISTS 연산자를 사용할때 서브쿼리의 반환값을 1 같은 작은 데이터로 하는게 권장됩니다.(위의 예시는 제가 깜빡하고 전체*를 넣은겁니다 😅)
-
EXISTS는 반환값에 행이 존재하는지만 판단하기 떄문에 이왕이면 메모리 사용량이 적은 데이터를 넣는게 성능면에서 권장됩니다.
-
여기서 특이한 점이 하나 있습니다.
-
현재 서브쿼리에서 메인쿼리의 users 테이블을 참조하고 있습니다.
-
이렇게 서브쿼리가 특정 값을 참조하는 쿼리를 상관쿼리라고 합니다.
📌 상관쿼리
- 상관쿼리는 메인쿼리의 각 행에 대해 반복 실행되는 서브쿼리를 일컫는 말입니다.
- 서브쿼리가 메인쿼리의 칼럼 값을 참조합니다.
- 상관쿼리는 상호 의존 관계를 가진 메인쿼리와 서브쿼리 간 특정 조건을 만족하는 튜플을 찾는 데 사용합니다.
- 상관 쿼리의 주요 특징은 다음과 같습니다.
1. 의존성
- 서브쿼리는 메인쿼리의 값을 참조해 데이터 필터링을 수행합니다.
2. 반복실행
- 서브쿼리는 메인쿼리의 각 행에 대해 반복적으로 실행됩니다.
3. 성능 저하
- 메인쿼리의 각 행마다 서브쿼리를 실행하므로 쿼리 전체위 성능이 저하될 수 있습니다. 데이터 양이 많은 경우 특히 그렇습니다.
📌 NOT EXISTS 연산자
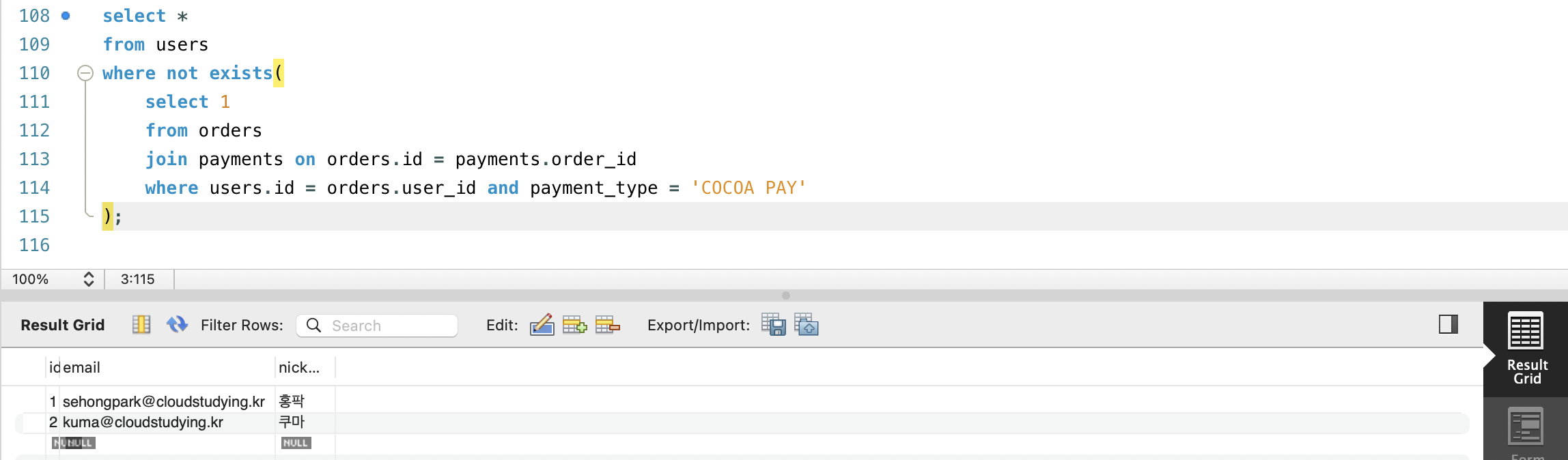
- NOT EXISTS 연산자는 EXISTS 연산자와 반대로 동작합니다.
- 입력받은 서브쿼리가 어떠한 결과도 반환하지 않을때 TRUE를, 하나 이상의 행을 반환하면 FALSE를 반환합니다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE NOT EXISTS (서브쿼리);- COCOA PAY로 결제하지 않은 사용자를 NOT EXISTS 연산자를 사용해 찾아봅시다.

frontend개발자가 되기 위해 노력합니다.