
1. 개요
현재 카카오 장르 키워드를 기준으로 모든 웹툰의 장르 키워드 삭제 및 변형을 성공했다.
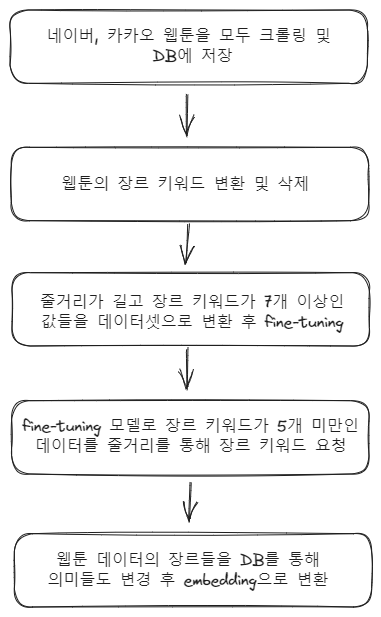
이번에는 웹툰의 장르를 분석해주는 모델을 미세조정을 통해 생성하는 것이 목표이다. 세세한 과정은 다음과 같다.
- 웹툰 데이터들 중 학습에 적합한 데이터들을 선별한 후 데이터셋으로 변환한다.
- 카테고리 별로 분류한 데이터 셋을 기존의 장르 키워드 뜻이 학습되어 있는 모델을 기반으로 학습시킨다.
2. 데이터 개수 확인
미세조정에 데이터의 질도 중요하지만 데이터의 양 또한 중요하다. 물론 3.5버전이 출시되기 전까지는 수백개의 데이터가 권장되었지만 지금은 수십개의 데이터만으로도 충분하다고 공식 사이트에서 밝히고 있다.
학습에 필요한 데이터의 최소 조건 다음과 같이 설정했다.
1. 줄거리가 300자 이상이다.
2. 장르 키워드가 7개 이상이다.
카테고리별로 학습을 순서대로 진행할 예정이기 때문에 제일 처음 학습하는 카테고리는 양이 많고 각 웹툰의 줄거리가 길고 장르 키워드도 많은 것이 적합하다. 모든 장르를 확인한 결과 "로판" 카테고리가 적합했다.
그리고 로판은 워낙 줄거리가 많고 장르 키워드도 많기 때문에 기준을 조금 더 올려서 장르 키워드는 9개 이상, 줄거리는 500자 이상으로 검색했다.
$ select COUNT(*) from Webtoon where category = "로판" and LENGTH(description) > 500 and genreCount > 9;위의 조건에 부합하는 로판 카테고리의 웹툰은 총 262개이다.
3. 데이터셋 변환
데이터 분류를 마쳤다면, 이제 미세조정에 필요한 형식대로 바꿔주어야 한다. 오픈AI에서 3.5버전 이상의 미세조정 데이터셋은 다음과 같은 형식을 강제하고 있다.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}- json 형태로 저장
// 웹툰 테이블의 제목, 줄거리, 장르를 미세조정 형식인 json 파일로 변환
async createWebtoonFineTuningPrompt(createFineTunePrompt: CreateFineTunePrompt): Promise<number> {
const webtoons = await this.getAllWebtoonForOption({ ...createFineTunePrompt });
let jsonData: any[] = [];
for (let webtoon of webtoons) {
const description = webtoon.description.replaceAll(/[\*\+#=\n]/g, "");
const systemMessage = `너는 웹툰의 제목과 카테고리, 줄거리를 읽고 장르의 뜻과 연관 지어서 분석 후 장르키워드를 알려주는 조수야`;
const userMessage = `제목: ${webtoon.title}\n\n카테고리: ${webtoon.category}\n\n줄거리: ${description}\n\n\n\n위 제목과 줄거리를 가진 웹툰의 장르 키워드를 알려줘`;
const assistMessage = genreToText(JSON.parse(webtoon.genres));
const messagesData: ChatCompletionMessageParam[] = [
{ role: "system", content: systemMessage },
{ role: "user", content: userMessage },
{ role: "assistant", content: assistMessage },
];
const messages = { messages: messagesData };
jsonData.push(messages);
}
const writePath = path.join(
OPENAI_JSON_FOLDER_PATH,
`webtoon_training_${createFineTunePrompt.category}.json`,
);
fs.writeFileSync(writePath, JSON.stringify(jsonData), { encoding: "utf-8" });
return webtoons.length;
}위의 코드는 DB의 Webtoon 테이블에서 category, genreCount 최소개수, description의 길이 등을 기준으로 웹툰리스트를 불러와서 json형식으로 파일을 저장해주는 함수이다.
또한, 미세조정의 질을 높이기 위해서 줄거리의 특수문자등을 일부 제거해주었다. 결과는 다음과 같다.
- jsonl 형태로 변환
transformToJsonl(filename: string): void {
const filePath = path.join(OPENAI_JSON_FOLDER_PATH, filename);
const writePath = path.join(OPENAI_JSONL_FOLDER_PATH, path.basename(filePath, ".json") + ".jsonl");
let jsonlData: string = "";
const arr: any[] = require(filePath);
arr.forEach((data) => {
jsonlData += JSON.stringify(data) + "\n";
});
fs.writeFileSync(
writePath,
jsonlData,
{ encoding: "utf-8" },
);
}위의 코드는 아까 저장된 json 파일을 미세조정에 필요한 jsonl 파일로 바꿔주는 함수이다. 결과는 다음과 같다.
4. 미세조정
이미 OpenaiModule에 기능은 구현이 되어 있기 떄문에 파일 업로드 및 미세조정을 시작한다.
- 파일 업로드
uploaded

processed
- 미세조정
start
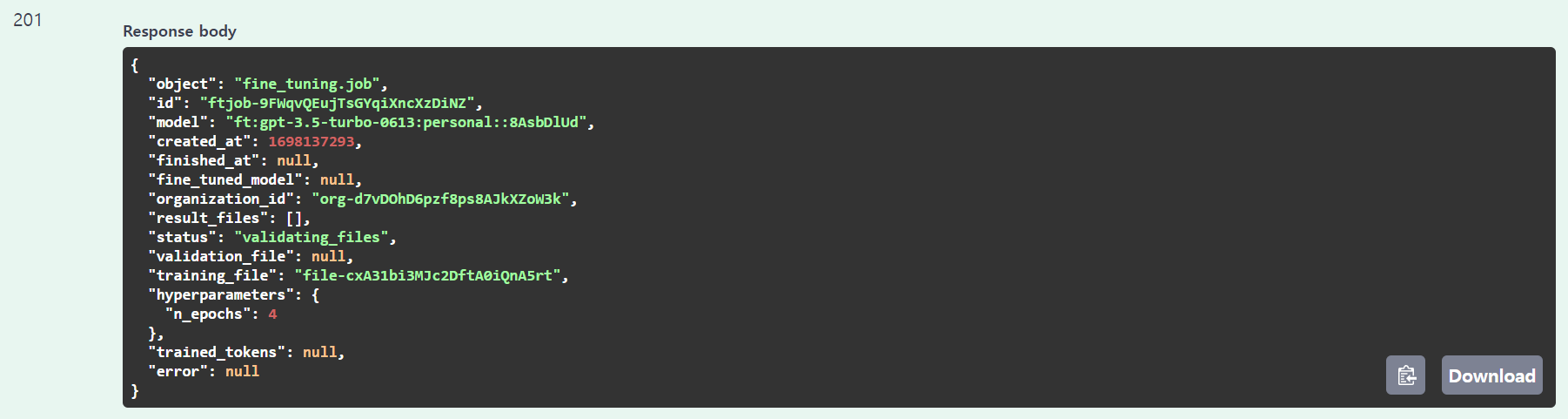
result
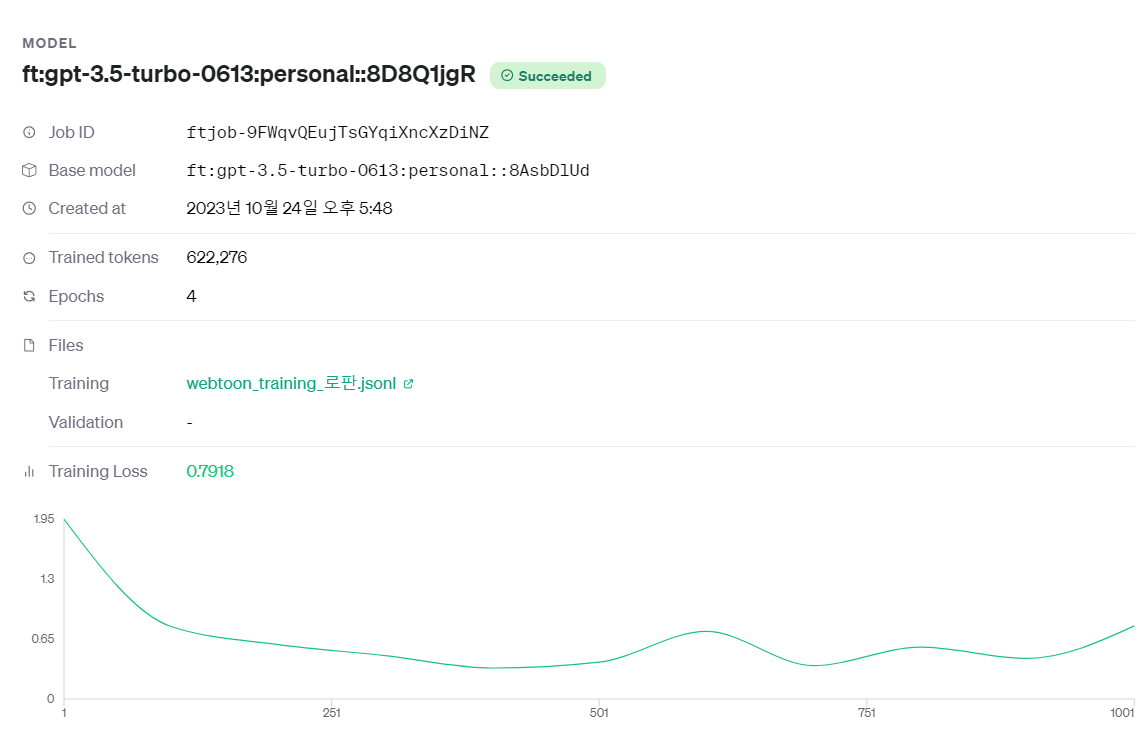
발전한점
- 데이터분류
리팩토링전에는 데이터를 학습시킬때 어떻게 하면 더 좋은 결과물이 나올지 어느 정도의 양을 학습시켜야 할지 무엇이든 생각하지 않고 바로 코드부터 작성했다.
물론 익숙치 않은 프레임워크에 익숙치 않은 api를 사용하다 보니 경험이 없어지만 현재는 오늘 목표의 시작부터 중간을 지나 끝까지 항상 어떤 데이터가 유리한지 어떻게 데이터를 분류하면 좋을지 생각을 하면서 코드를 작성한다.
- 재사용성
이 글에는 "로판" 카테고리만을 보여주고 있지만 실상은 모든 카테고리에 대해서 전부 데이터 학습과정을 거쳐야 하고, 결과가 좋지 않으면 재학습 또는 추가학습이 필요하다.
리팩토링 전에는 추가로 하나의 학습을 할려면 다시 그에 맞는 코드를 작성하고 또 추가해야 하는 기능이 있거나 하면 다시 새로 함수를 작성하는 등 무한으로 일이 생겼다..
하지만 리팩토링 후의 코드는 다른 카테고리를 학습하거나 추가학습, 재학습을 할경우 모든 것들이 추가로 개발 없이 구현되어 있는 기능에서 가능하다.
참고
