
주제: 영화 리뷰를 읽고, 감정 평가 예측
sentiment analysis는 머신러닝에서 까다로운 분야이다. 사람들이 감정을 표현한 글에서 sarcasm, ambiguity, play on words를 잘못 해석할 수 있기 때문이다.
목표:
part1. basic natural language processing
part2. deep learning for text understanding - word vectors
part3. deep learning for text understanding - more fun with word vectors
평가 기준: area under the ROC curve
part 1
what is NLP?
NLP(Natural Language Processing), 자연어 처리는 텍스트 문제에 대한 접근법이다.
이후 과제에서는 bag of words 모델을 사용해 리뷰를 보고 thumbs-up인지 thumbs-down인지 prediction 해 보았다.
- 데이터 불러오기
#import the pandas package, then use the "read_csv" function to read
# the labeled training data
import pandas as pd
train = pd.read_csv("labeledTrainData.tsv", header = 0, delimiter="\t", quoting=3)>>> train.shape
(25000,3)
>>> train.columns.values
array([id, sentiment, review], dtype = object)id, sentiment, review 세 칼럼으로 이루어진 25000개의 train 데이터를 불러왔다.
- 데이터 전처리
"!!!"이나 ":-(" 같이 sentiment를 담고 있는 문장부호가 있을 수 있지만, 이 과정에서는 모두 삭제하였다.
import re
#use regular expressions to do a find-and-replace
letters_only = re.sub("a-zA-Z]", example1.get_text())대문자를 모두 소문자로 바꾼 후 단어 단위로 끊어 tokenization 하였다.
lower_case = letters_only.lower() #convert to lower case
words = lower_case.split() #split into words"a", "and", "is", "the"와 같은 stop words(자주 나오는 의미 없는 단어들)를 words 에서 삭제하였다. stop words 리스트는 파이썬 NLTK에서 제공하고 있다.
import nltk
nltk.download() #download text data sets, including stop words
from nltk.corpus import stopwords #import the stop word list
#remove stop words from "words"
words = [w for w in words if not w in stopwords.words("english")]
print words(NLTK에서 porter stemming과 lemmatizing도 가능하지만 여기서는 생략하였다.)
- Creating Features from a Bag of Words(Using scikit-learn)
전처리한 데이터를 machine learning을 위한 numeric representation으로 바꾸어야 한다. 사용된 단어의 빈도를 feature vector로 사용했다. feature vector의 사이즈를 제한하기 위해, 가장 빈도가 높은 5000개의 단어를 사용했다.
print "Creating the bag of words ... \n"
from sklearn.feature_extraction.text import CountVectorizer
#initialize the "CountVectorizer" object, which is scikit-learn's
#bag of words tool.
vectorizer = CountVectorizer(analyzer = "word", tokenizer = None, preprocessor = None, stop_words = None, max_features = 5000)
#fit_transform() does two functions: First, it fits the model and learns the vocabulary
#second, it transforms our training data into feature vectors.
#The input to fit_transform should be a list of strings.
train_data_features = vectorizer.fit_transform(clean_train_reviews)
#convert the result to a numpy array
train_data_features = train_data_features.toarray()25000 x 5000 크기의 숫자로 이루어진 training data를 만들었다.
- Random Forest
Random Forest 알고리즘은 scikit-learn에 포함된 트리 기반 예측 알고리즘이다.
#use the random forest to make sentiment label predictions result = forest.predict(test_data_features)이때, 과적합을 피하기 위해 train_data_features가 아니라 test_data_features를 사용한다.
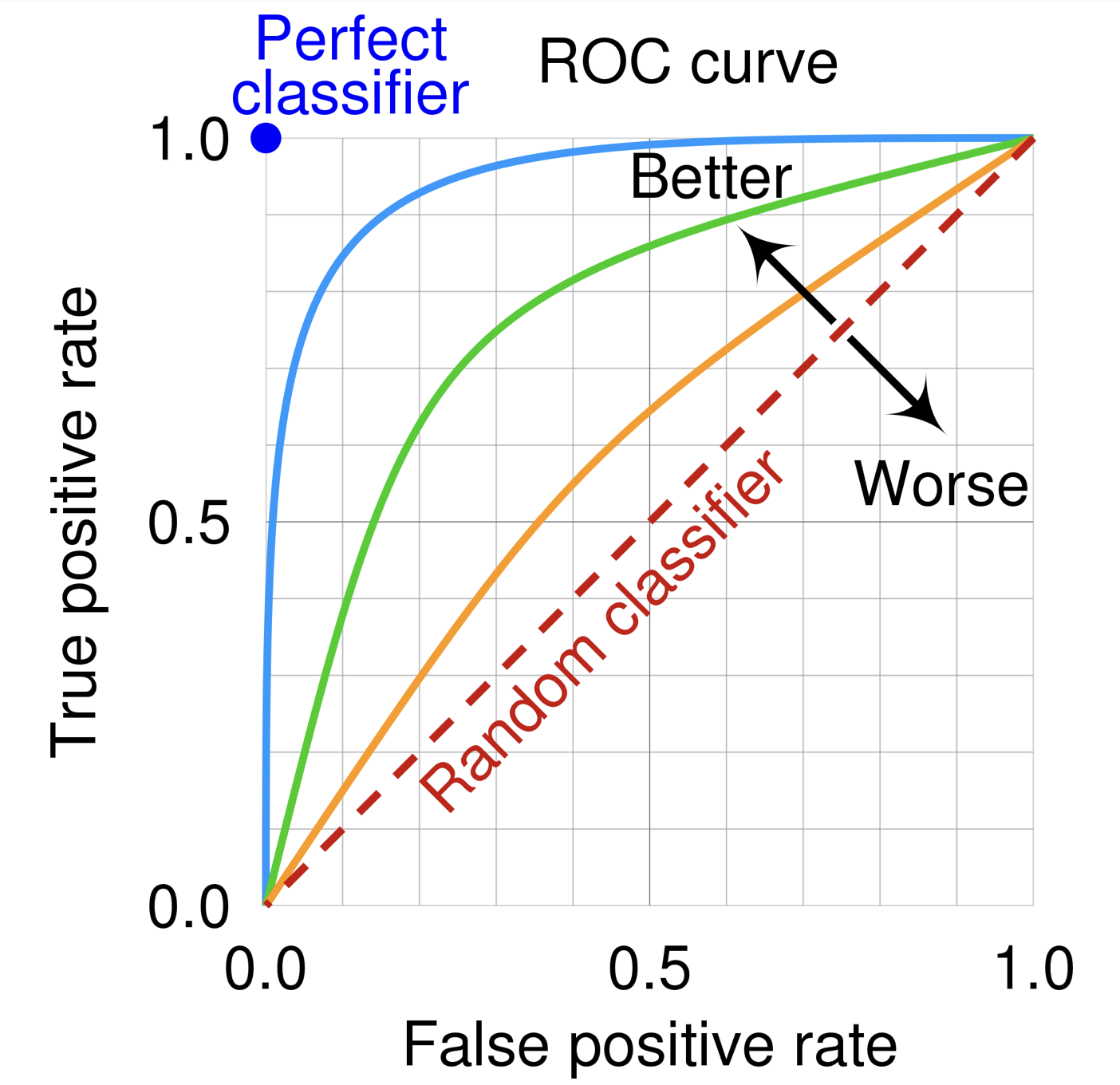
ROC curve
x축: 1- 특이도
y축: 민감도
특이도(specificity): 실제 음성 대 맞춘 음성의 비율 = TN/TN+FP
민감도(sensitivity): 실제 양성 대 맞춘 양성의 비율 = TP/TP+FN
*TN True Negative
FP False Positive
TP True Positive
FN False Negative
여러 감정 분류 모델 간의 성능을 비교:
각 모델의 곡선을 그려 비교하고, 곡선 아래 영역인 AUC(Area Under the Curve)를 계산하여 모델 간의 상대적 성능을 평가. AUC가 더 높은 모델이 더 나은 성능
참고 - https://www.kaggle.com/competitions/word2vec-nlp-tutorial
Use Google's Word2Vec for movie reviews
www.kaggle.com
