
ℹ️ <혼자 공부하는 머신러닝+딥러닝> 책을 읽고 정리한 내용입니다.
비지도 학습이란?
비지도 학습은 머신러닝의 한 종류로, 훈련 데이터에 타깃(정답)이 없는 것이 특징이다. 타깃이 없기 때문에 알고리즘은 외부의 도움 없이 스스로 데이터에서 유용한 패턴이나 구조를 학습해야 한다. 대표적인 비지도 학습 작업으로는 군집(clustering)과 차원 축소(dimensionality reduction) 등이 있다.
군집 알고리즘
군집은 비슷한 샘플끼리 그룹으로 모으는 작업으로, 대표적인 비지도 학습이다.
군집으로 모은 샘플 그룹을 '클러스터'라고 부른다.
예제: 사과, 파인애플, 바나나 군집으로 분류하기
사과, 파인애플, 바나나 그림이 각각 100개 들어있는 데이터가 있다. 출력해서 슬쩍 보면 아래와 같다.
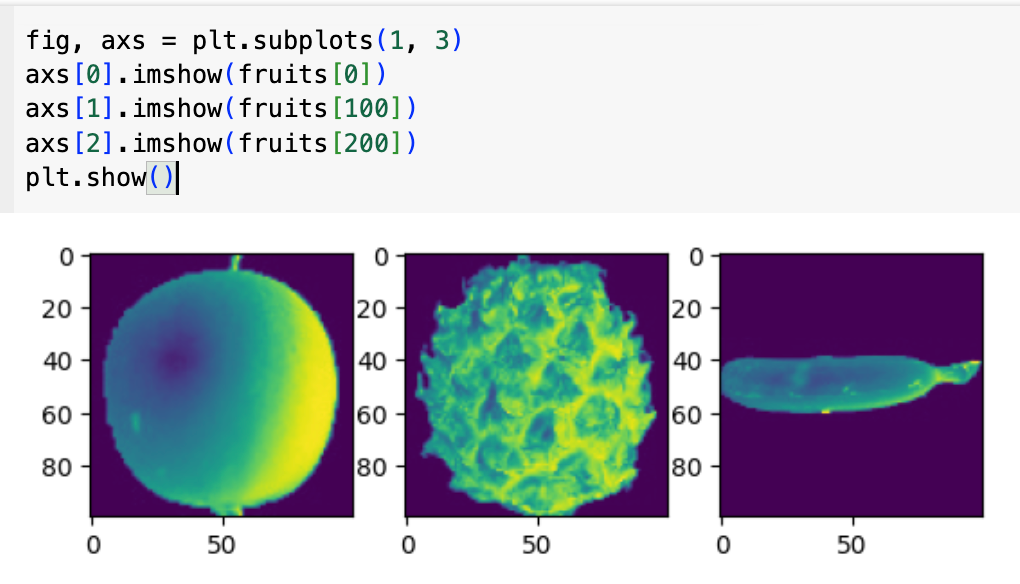
이미지들이 마치 엑스레이 사진처럼 배경은 검정색이고 피사체는 밝은 색으로 표현되어 있는데, 이는 의도적인 설계이다. 분석의 핵심은 피사체이므로, 관심 없는 배경은 0(검정색)으로, 중요한 피사체 부분은 255 이내의 양수 값(밝은색)으로 표현한다. 이렇게 하는 이유는 0이라는 값의 수학적 특성 때문이다. 알고리즘 계산 과정에서 배경 부분(0 값)은 어떤 연산을 해도 결과에 영향을 주지 않아 노이즈가 되지 않으며, 피사체 부분(양수 값)만이 의미 있는 정보로 활용될 수 있다.
무튼, 이제는 어떤 값을 기준으로 세 가지를 분류해볼지 생각해보자.
방법1: 픽셀 전체의 평균 (이미지의 전체적인 밝기)
먼저 각 이미지의 전체 픽셀 값들의 평균을 구해서 분류를 시도해보자.
이미지 하나를 100×100 = 10,000개의 작은 점(픽셀)로 이루어진 것으로 생각해보자. 각 점마다 0(검정)부터 255(흰색)까지의 밝기 값이 있다. 이 10,000개 값을 모두 더해서 10,000으로 나눈 것이 바로 "픽셀 전체의 평균"이다.
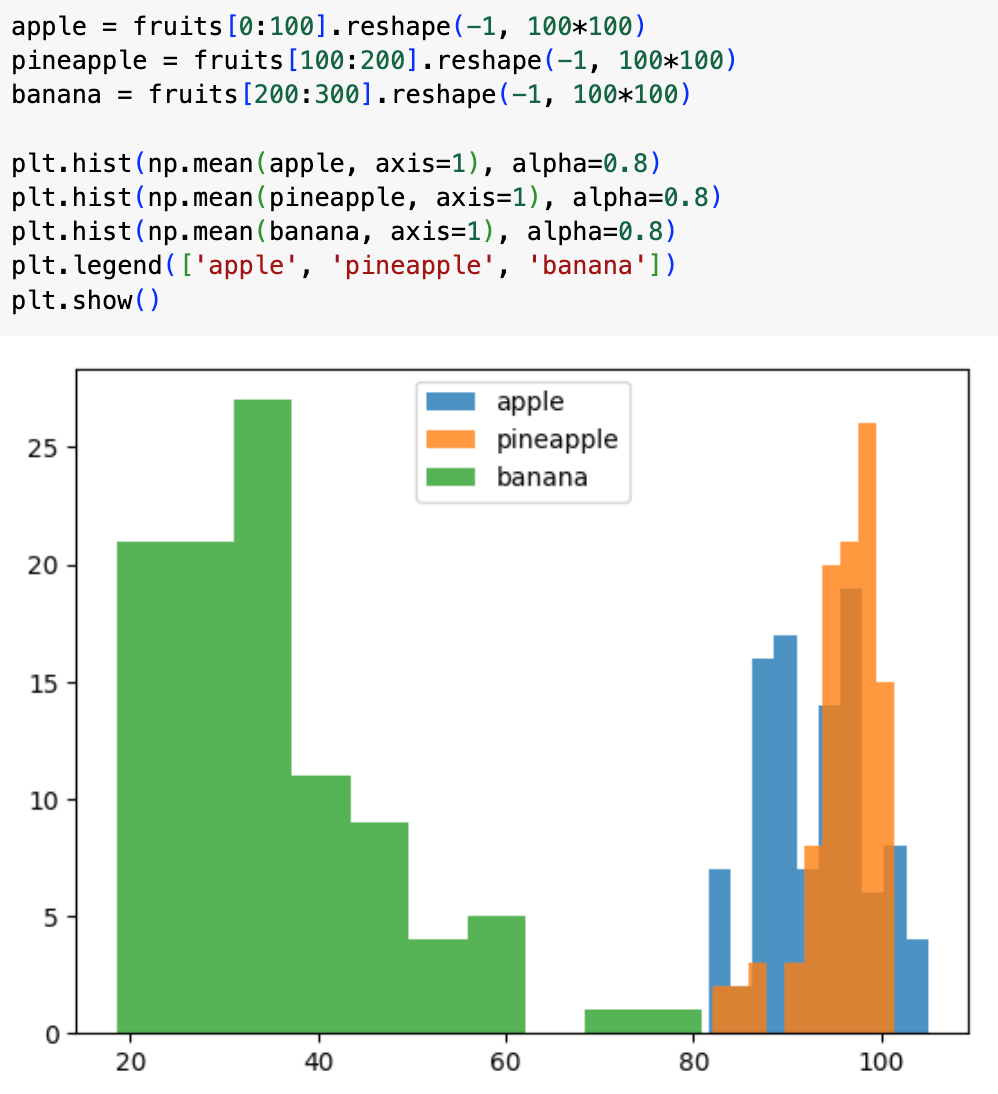
하지만 결과를 살펴보니 아쉽게도 파인애플과 바나나의 전체 밝기가 비슷해서 구분이 어렵다.
방법2: 각 픽셀의 평균 (위치별 특징)
이번엔 각 픽셀 위치별 평균을 구해보자. 구체적으로는 아래와 같이 진행된다.
- 사과 100장의 맨 왼쪽 위 모서리 픽셀 값들을 모두 더해서 100으로 나눔
- 사과 100장의 그 옆 픽셀 값들을 모두 더해서 100으로 나눔
- 이런 식으로 10,000개 위치 각각에 대해 평균을 구함
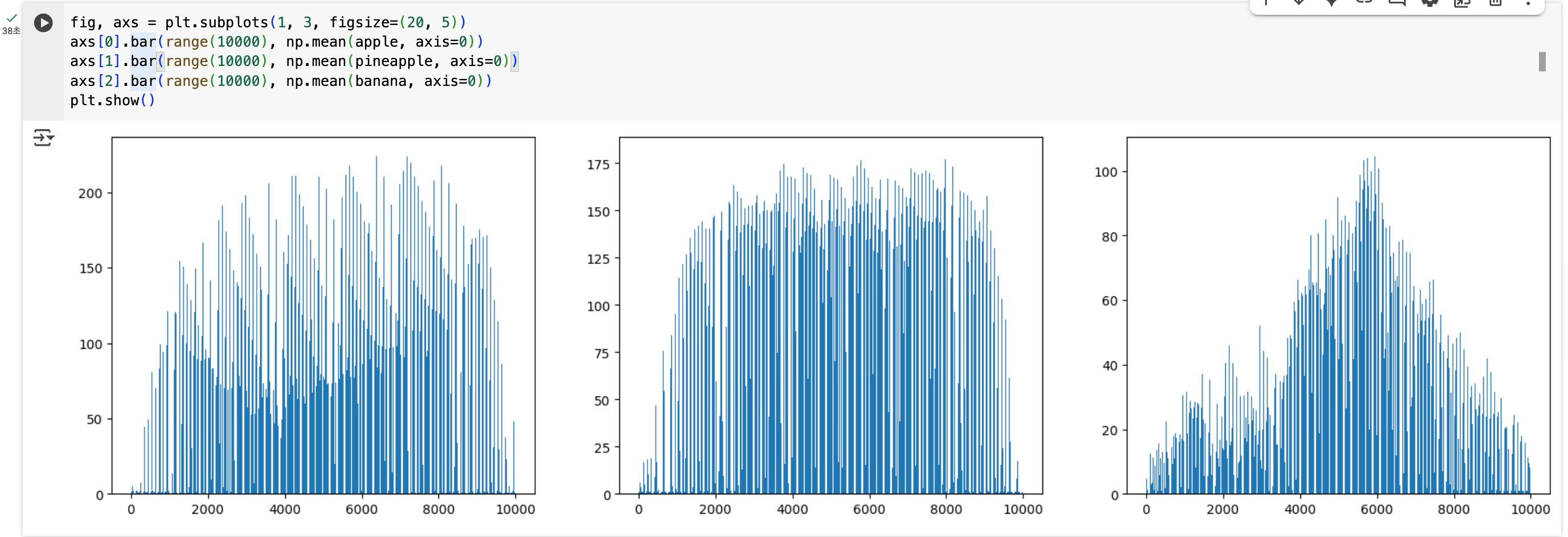
확실히 분포가 다른 것이 눈에 보인다. 이 방법이 앞선 방법보다 더 효과적인 이유는 위치 정보를 활용하기 때문이다. 단순히 사진의 전체적인 밝기를 아는 것보다는 "어느 위치에 밝은 부분이 있는가"가 과일을 구분하는 데 더 유용한 정보이다!
여기에 더해 각 픽셀의 평균값을 이용해 이미지를 그리면, 마치 여러 장을 겹쳐 놓고 투명하게 본 것 같은 "대표 이미지"가 만들어진다!
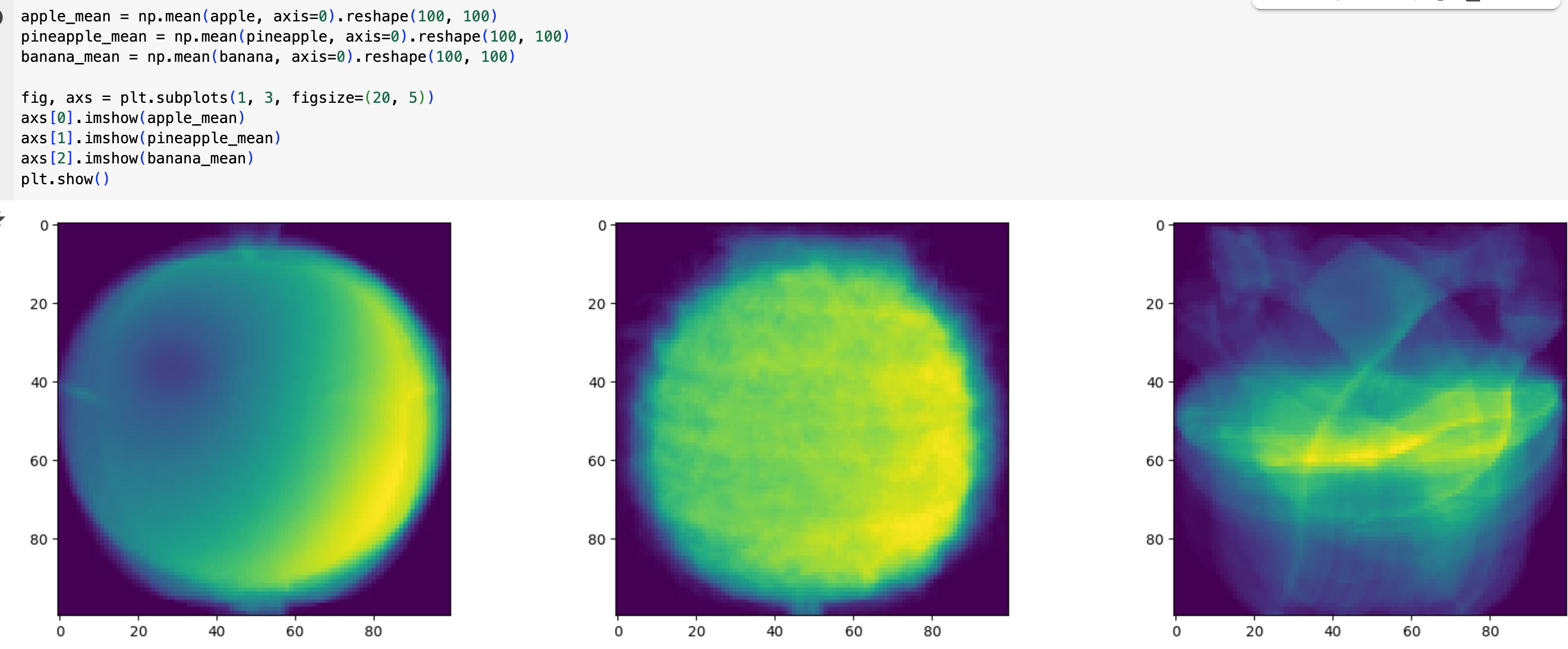
분류하기: 가장 비슷한 대표 이미지 찾기
이제 새로운 이미지가 들어오면, 세 개의 대표 이미지 중 어느 것과 가장 비슷한지 계산한다.
새 이미지와 사과 대표 이미지를 픽셀별로 비교해서 차이를 계산하여, 차이가 가장 작은 대표 이미지가 바로 그 이미지의 분류가 되도록 하는 것이다.
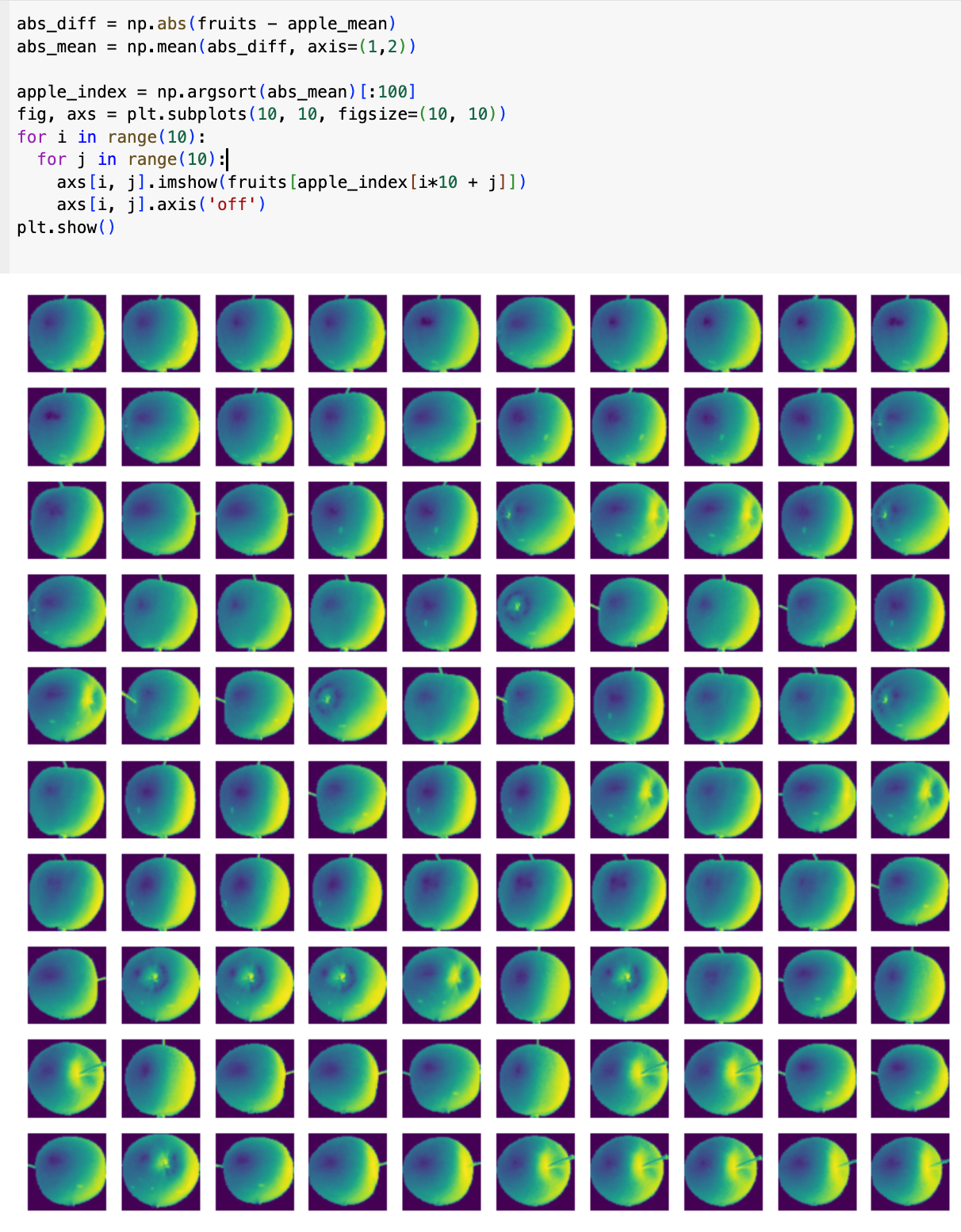
모아본 결과, 모두 다 사과로 잘 나오는 것을 확인할 수 있었다!
그럼 바나나는 어떨까?

바나나의 결과는 완벽하지 못했다. 맨 뒤 두 개는 사과이다.
파인애플 역시 완벽하지 않다. 중간에 사과 몇 개가 껴있다.

한계점
하지만 이 방식은 아쉬운 점이 있는데, 우리는 애초에 사과, 파인애플, 바나나가 있다는 걸 알고 있었다는 점이다. 즉 타깃값을 알고 있었기 때문에 사과, 파인애플, 바나나의 사진 평균값을 계산해서 가장 가까운 과일을 찾았다.
진짜 비지도 학습에서는
- 어떤 과일인지 미리 알 수 없음
- 몇 개의 그룹으로 나뉠지도 모름
- 컴퓨터가 스스로 패턴을 찾아서 비슷한 것끼리 묶어야 함
라는 특징이 있다.
K-평균 알고리즘
K-평균 알고리즘은 처음에는 랜덤하게 클러스터 중심을 선택한 뒤, 점차 가까운 샘플의 중심으로 이동하는, 비교적 간단한 알고리즘이다.
알고리즘 동작 과정 (구체적 이해)
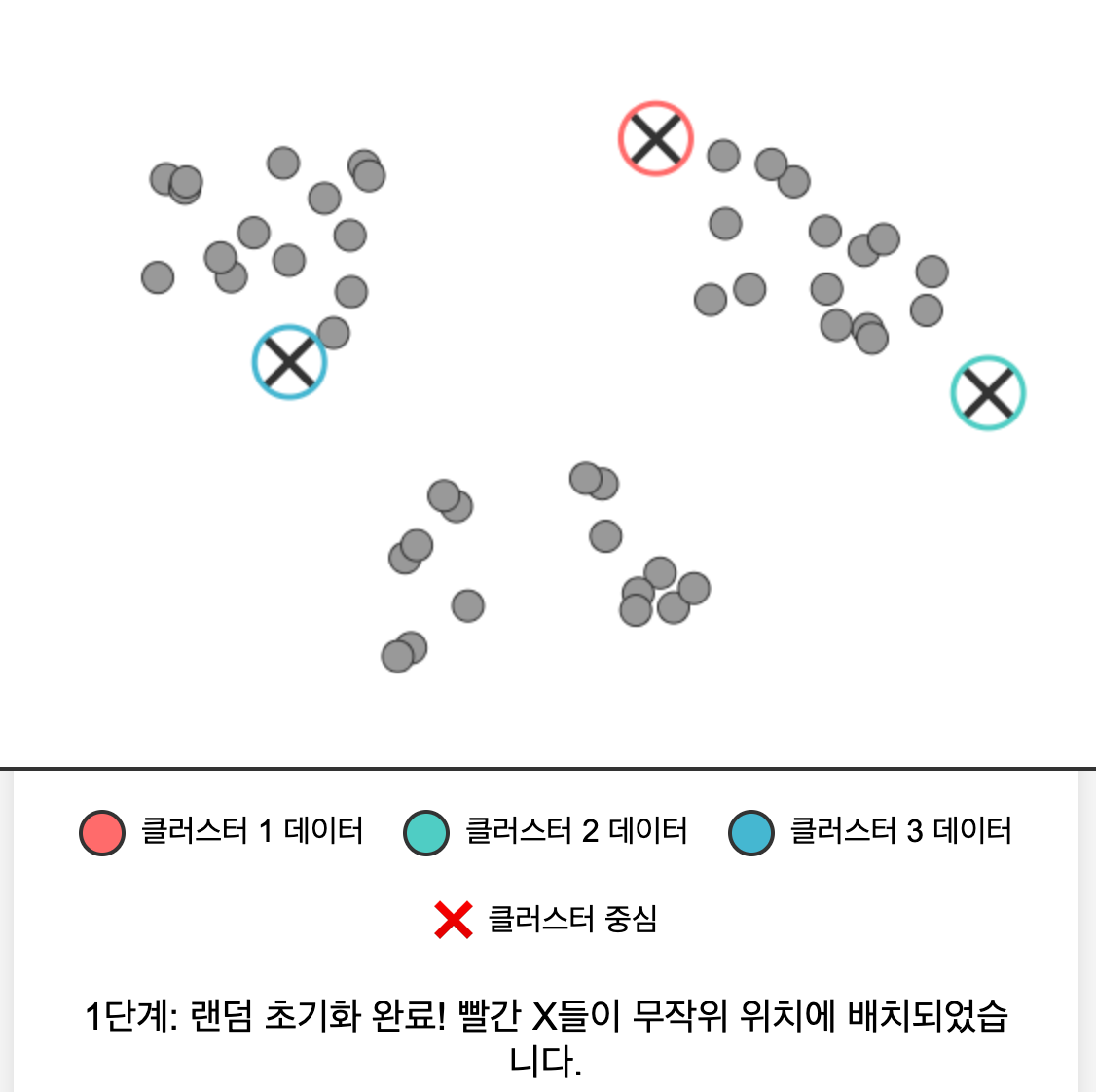
- 랜덤 초기화: K개의 클러스터 중심을 데이터 공간에 랜덤하게 배치한다.
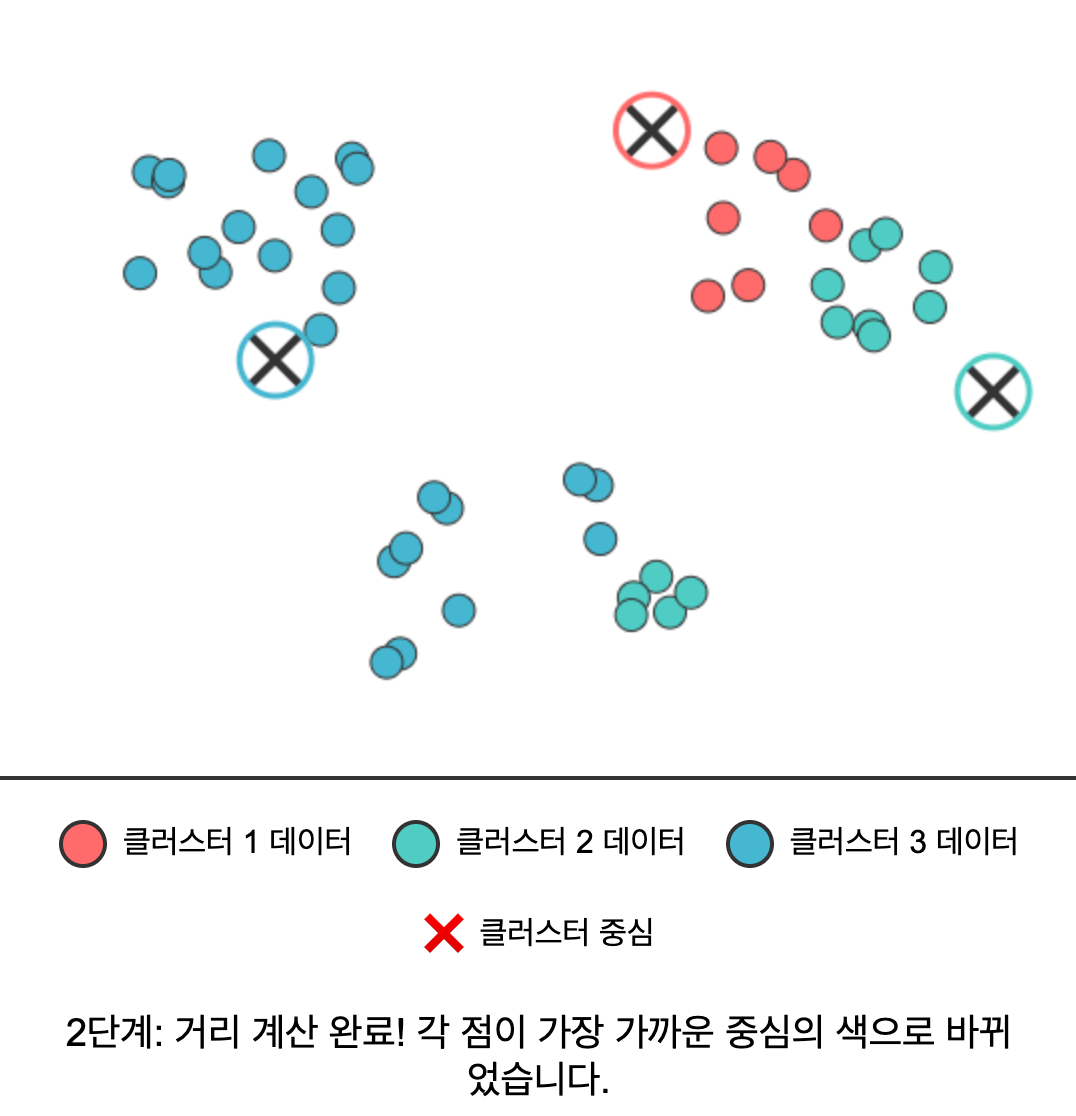
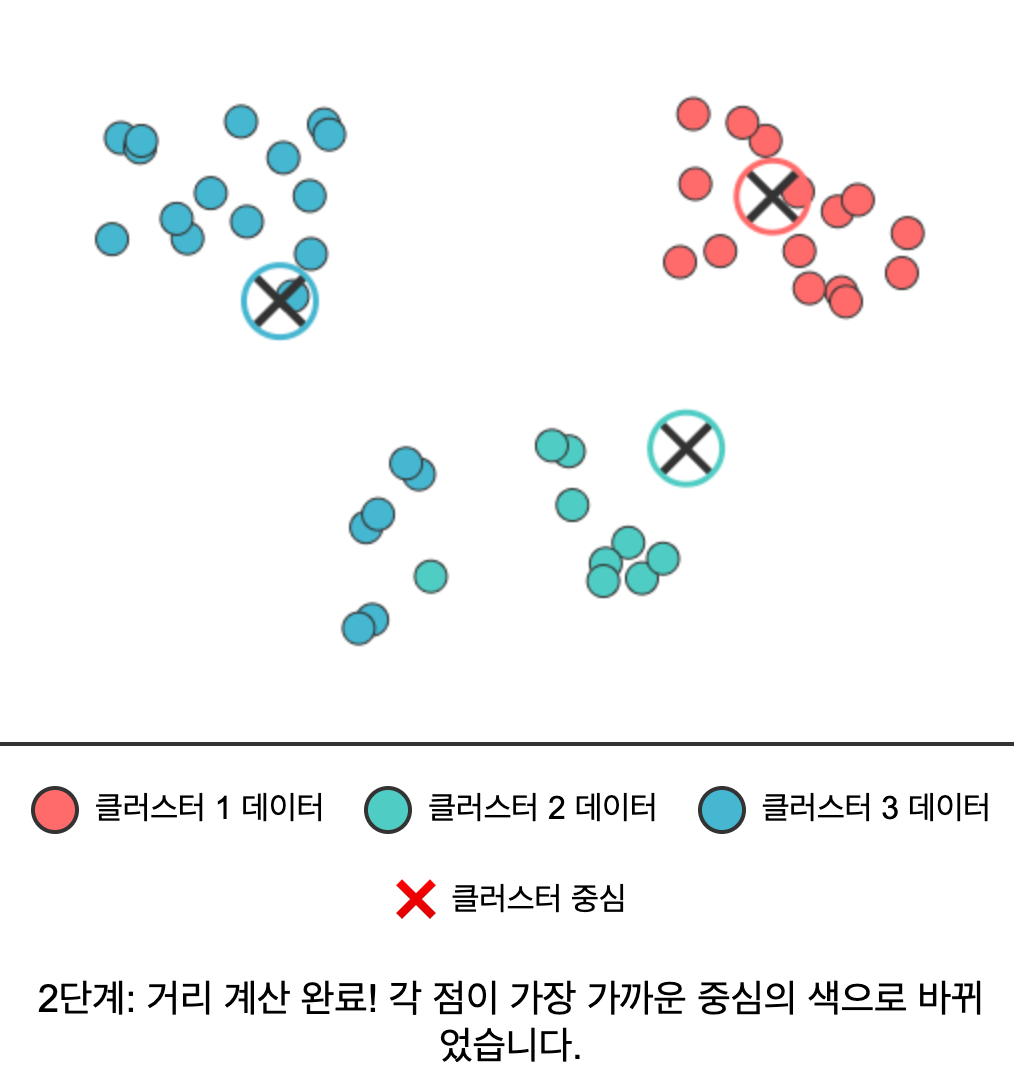
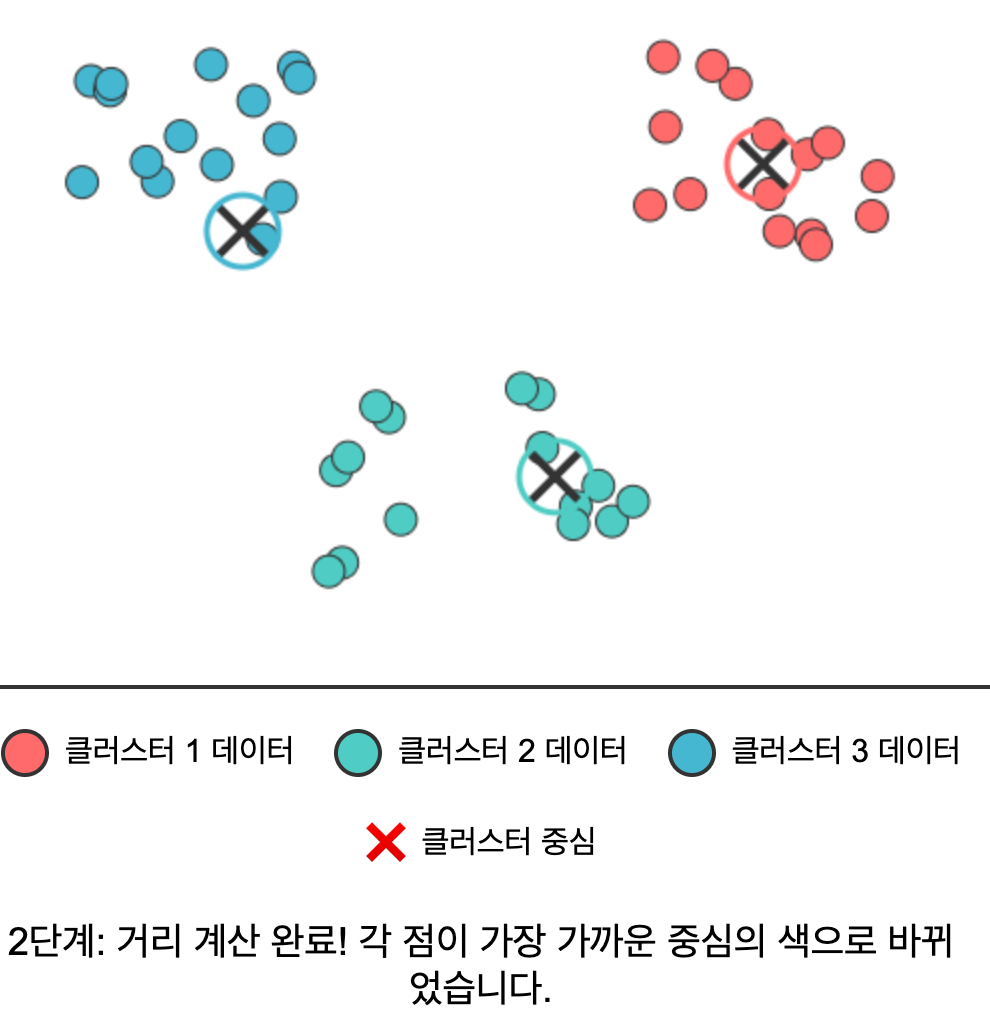
- 거리 계산 & 할당: 각 데이터 포인트를 가장 가까운 클러스터 중심에 할당한다.
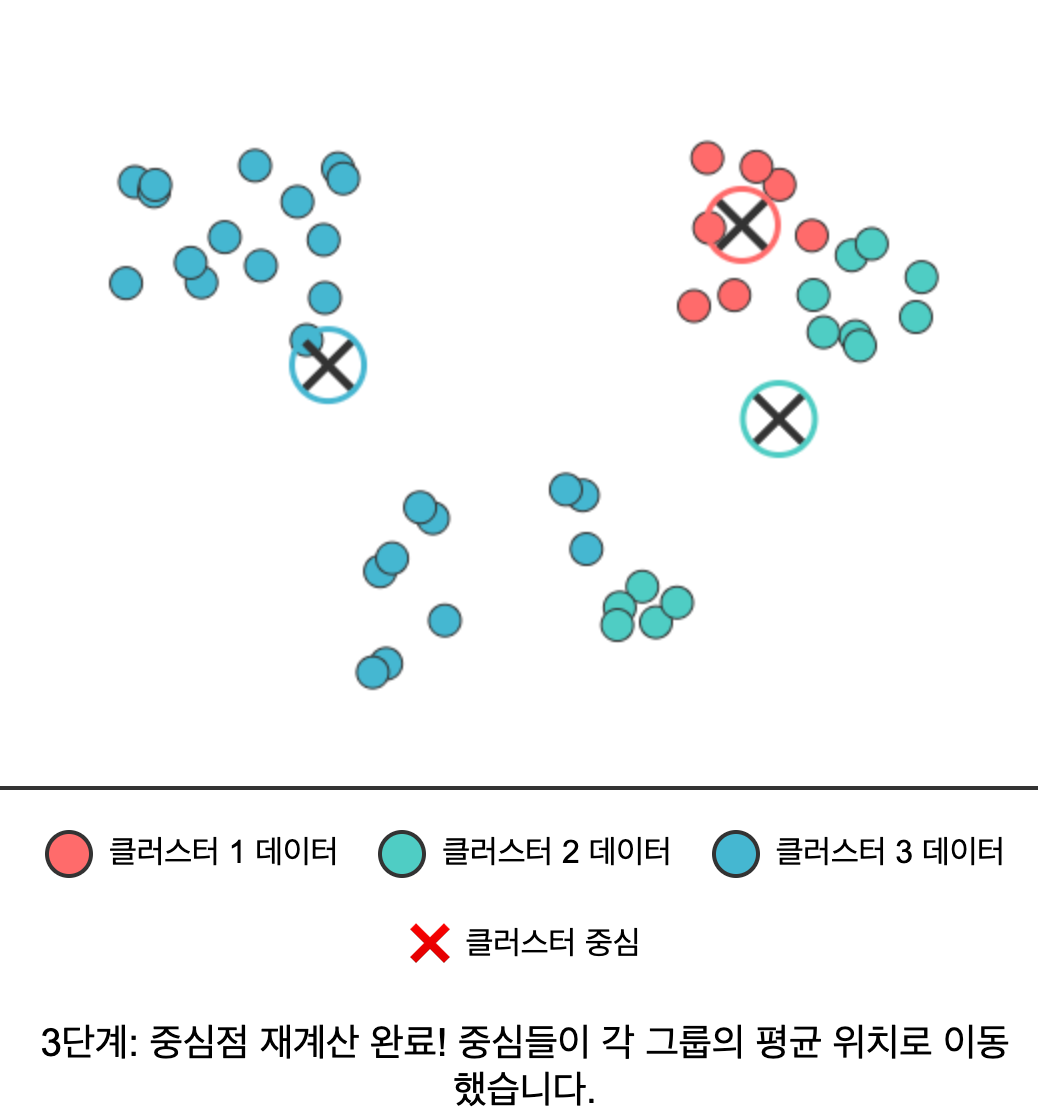
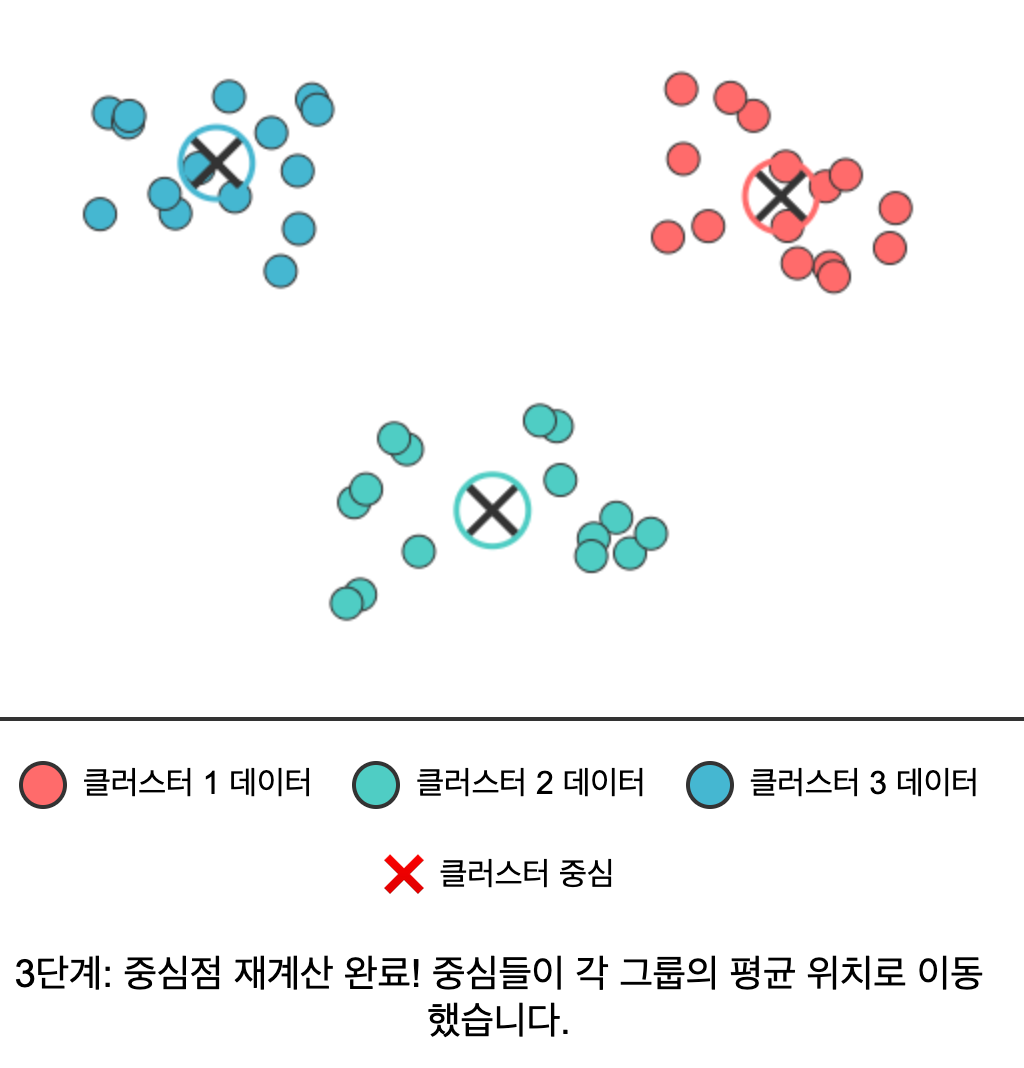
- 중심점 재계산: 각 클러스터에 속한 모든 데이터의 평균을 구해 새로운 중심점으로 설정한다.
- 반복: 중심점이 더 이상 변하지 않을 때까지 2-3단계를 반복한다.
구체적인 스탭을 예시로 들어보면 아래와 같다.
| 1 | 2 | 3 |
|---|---|---|
 |  |  |
| 4 | 5 | 6 |
|---|---|---|
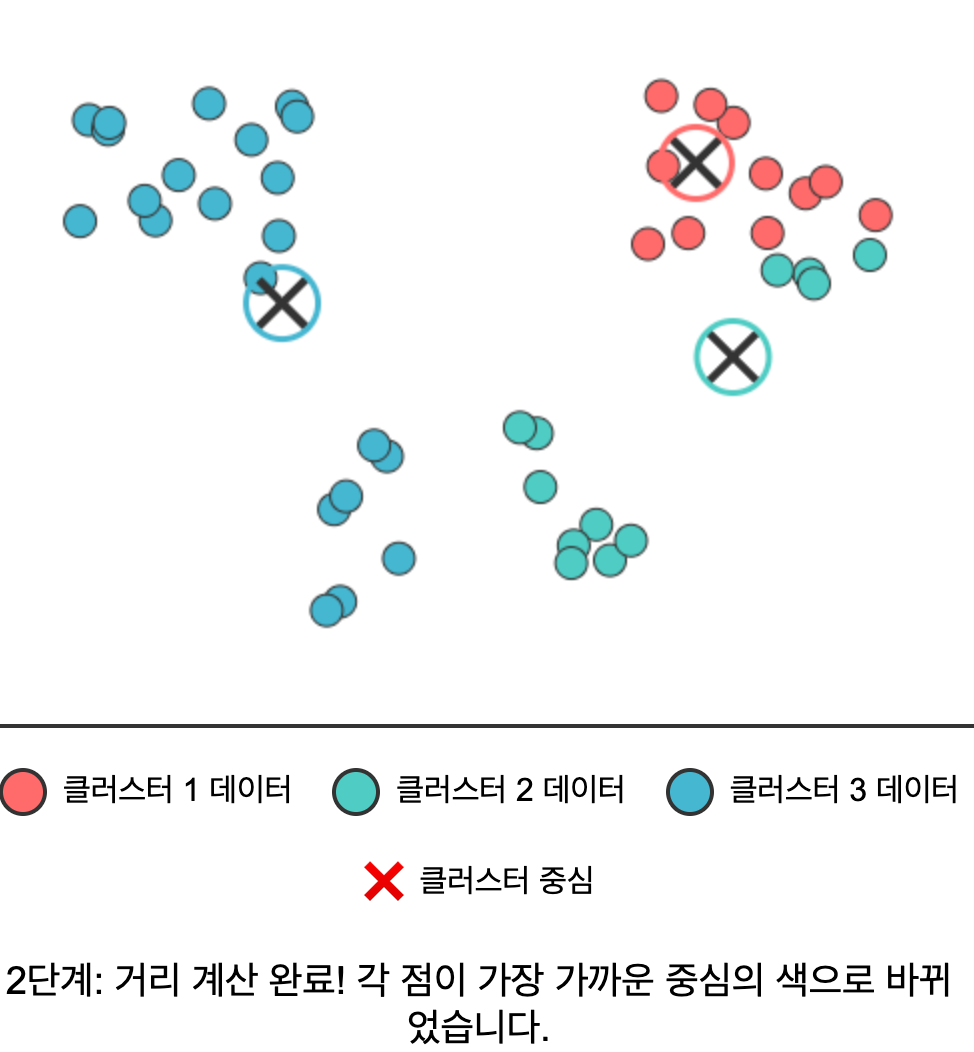 | 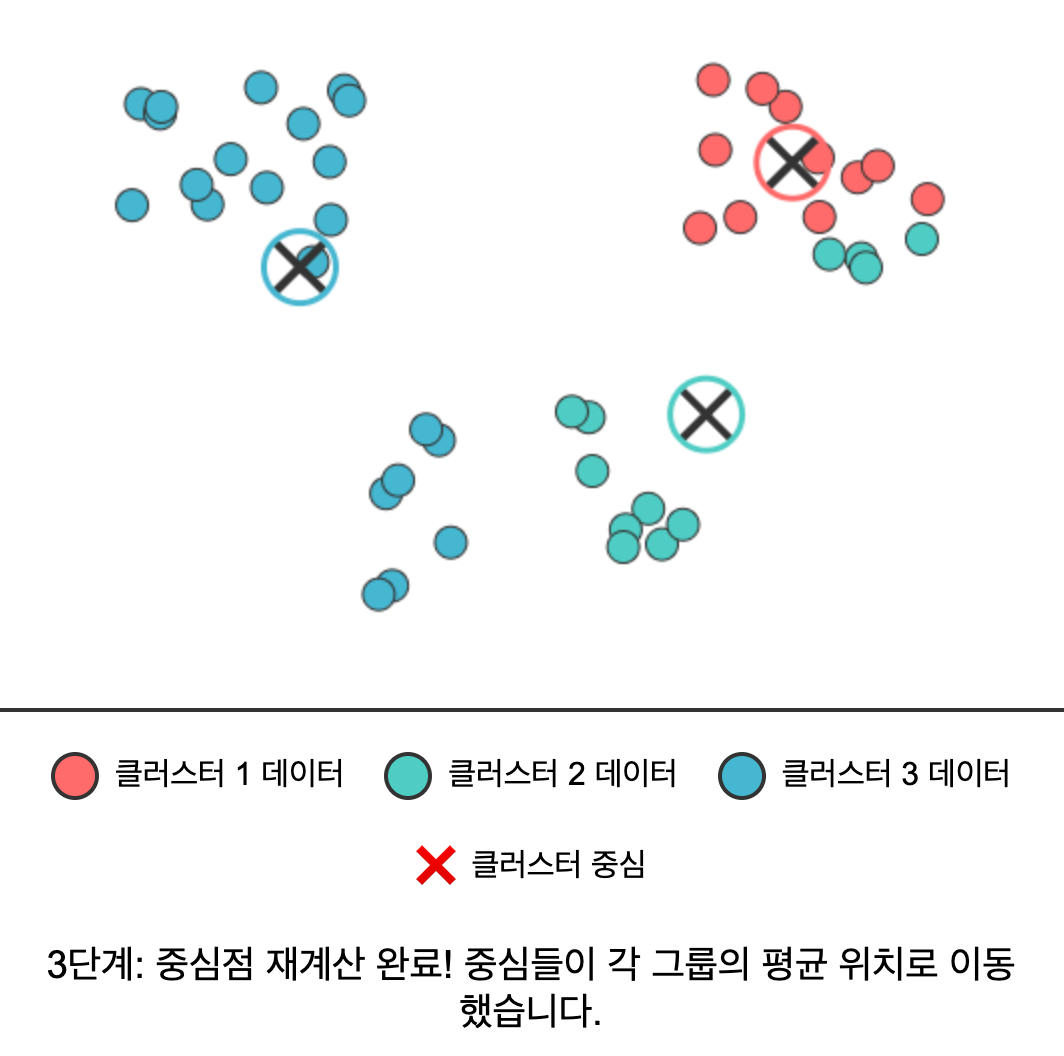 |  |
| 7 | 8 | 9 (완성) |
|---|---|---|
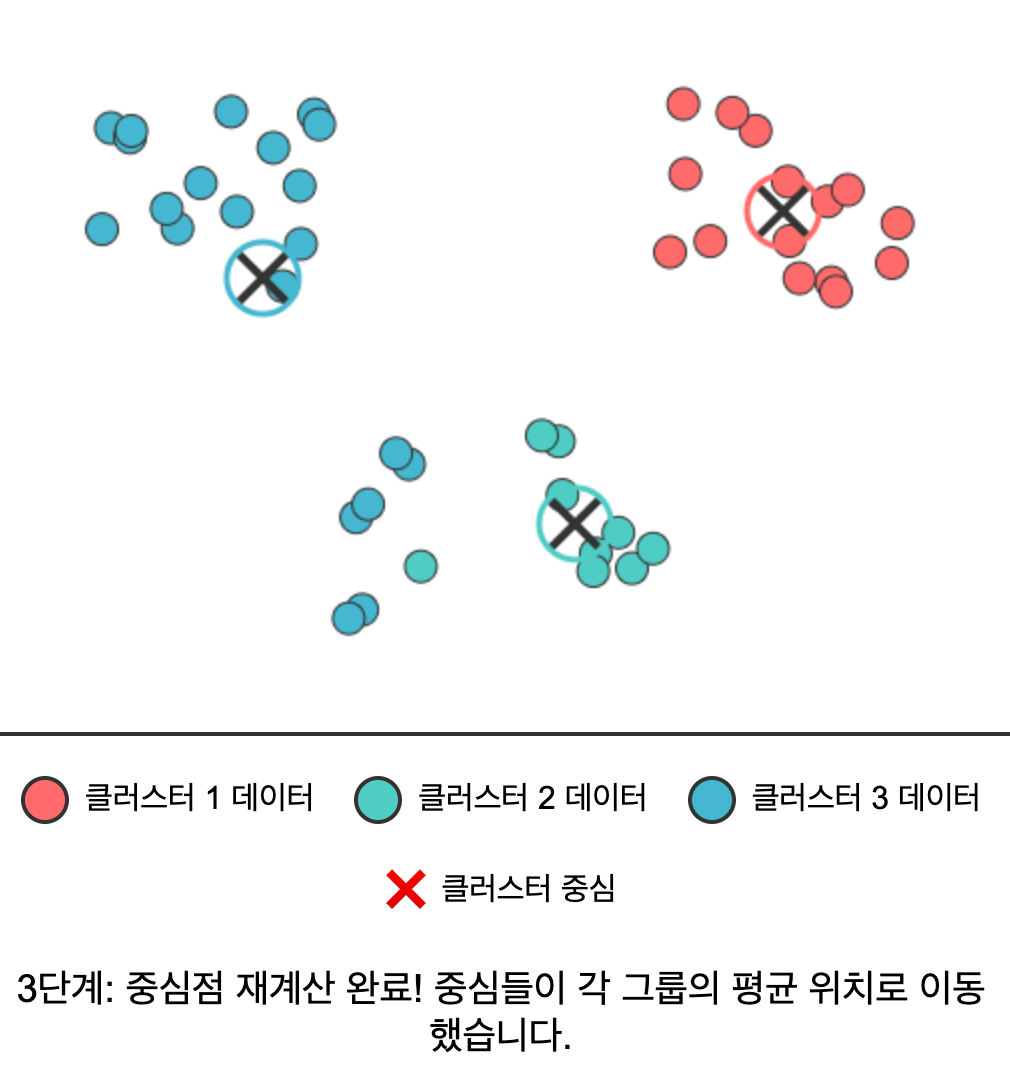 |  |  |
예제: 사과, 파인애플, 바나나 분류하기
스탭1: 일단 무작위로 클러스터 짓기
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100) # 100x100 이미지를 10,000차원 벡터로 변환
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42) # n_clusters=3: 우리가 알고 있는 과일 종류 수 (사과, 파인애플, 바나나)
km.fit(fruits_2d)sklearn의 KMeans를 사용해 손쉽게 구현해냈다. 얼마나 잘 분류되었을까? 아래와 같다.
| 파인애플 | 바나나 | 사과 |
|---|---|---|
 |  |  |
| 사과와 바나나가 몇 개 섞여 있음 | 올 바나나 👍 | 올 사과 👍 |
스탭2: 최적의 클러스터 개수는?
우리는 지금 바나나, 사과, 파인애플 이 세 가지가 있다는 걸 전제하고 클러스터 개수를 세 개로 두었다. 하지만 애초에 비지도 학습이라면 과일 종류가 몇 개인지도 알지 못한다. 이러한 경우 최적의 클러스터 개수는 몇 개로 선택할 수 있을까?
대표적인 방법으로 '엘보우'라는 방식이 있다. 엘보우 방법은 클러스터 개수를 늘려가면서 이너셔(클러스터의 중심과 샘플 사이 거리의 제곱 합)의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법이다.
클러스터 개수를 증가시키면서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 있는데, 이 지점부터는 클러스터 개수를 늘려도 클러스터에 잘 밀집되어 있는 정도가 크게 개선되지 않는다. 이 꺾이는 지점을 최적의 클러스터 개수로 보는 것이 바로 엘보우 방식이다. 이 지점이 마치 팔꿈치 모양이어서 엘보우 방법이라고 부른다.
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()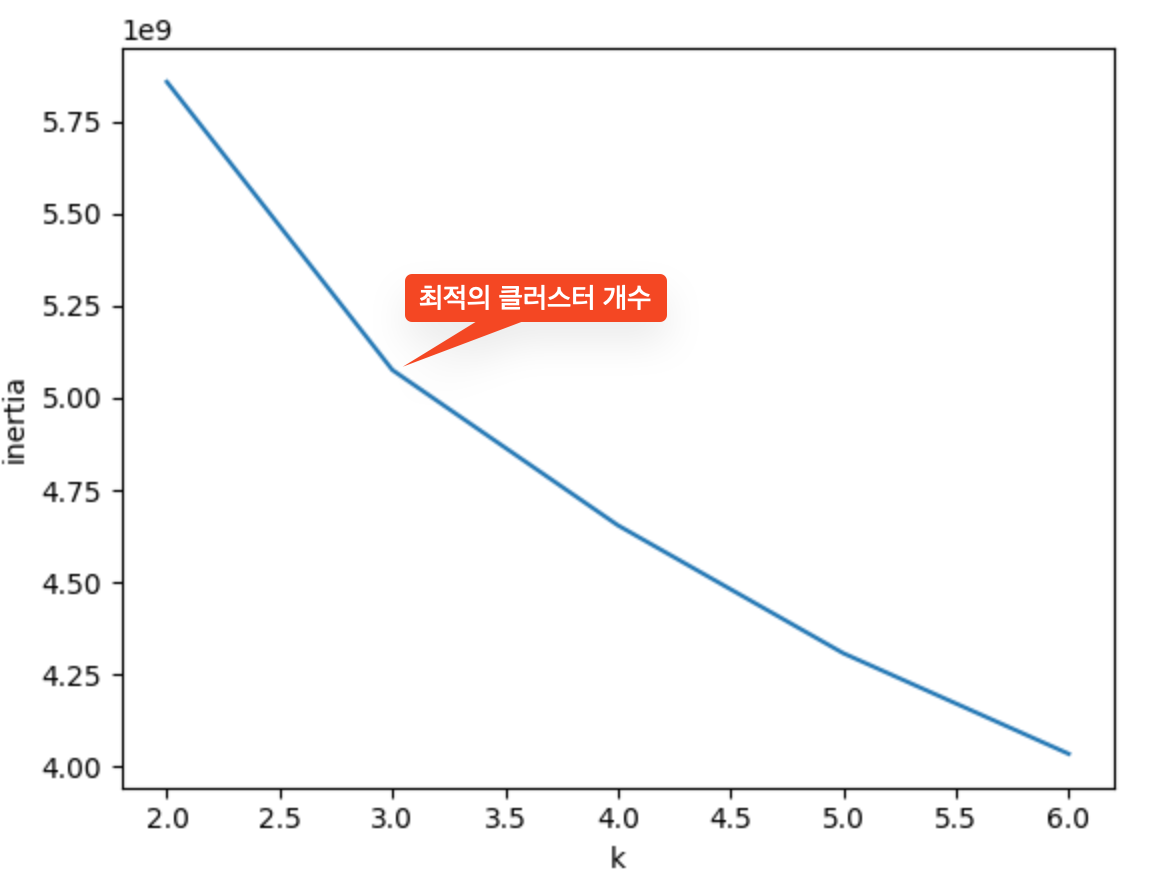
위 그래프에서 k=3 지점에서 기울기가 확연히 완만해지는 것을 볼 수 있다.
- k=2→3: 이너셔가 크게 감소 (의미있는 개선)
- k=3→4: 이너셔 감소폭이 줄어듦 (개선 효과 제한적)
따라서 k=3이 이 데이터에 대한 최적의 클러스터 개수로 판단된다.
