📌 지금까지 리뷰한 논문들은 classification 모델로 이미지의 클래스를 분류하는 작업을 했습니다. 이번에 공부할 논문은 이미지를 만들어내는 생성형 모델에 대해 공부해 보도록 하겠습니다.
💡Abstract
우리는 생성 모델을 추정하기 위한 새로운 프레임워크를 제안합니다. 이 프레임워크는 두 개의 모델을 동시에 학습시키는 방법입니다. 데이터 분포를 캡처하는 생성 모델 G와 샘플이 훈련 데이터에서 왔는지 G에서 생성되었는지의 확률을 추정하는 판별 모델 D입니다. G의 학습 목표는 D가 실수를 하도록 확률을 최대화하는 것입니다. 이 과정은 미니맥스 두 플레이어 게임에 해당하며, G가 훈련 데이터 분포를 회복하고 D가 모든 지점에서 0.5가 되는 고유한 해가 존재합니다. G와 D가 다층 퍼셉트론으로 정의되면, 전체 시스템은 역전파를 통해 학습할 수 있으며, 학습이나 샘플 생성 과정에서 마르코프 체인이나 근사 추론 네트워크가 필요하지 않습니다.
지금까지 배운 모델들은 하나의 모델이 정답 라벨을 맞추도록 학습해왔습니다. GANs에서는 두 개의 모델이 서로를 경쟁하며 맞추도록 학습을 합니다. 이 모델의 이름이 Adversarial, 즉 적대적 모델이라 명칭된 이유입니다.
두 개의 모델 G와 D가 있습니다.
G (generative) : 가짜 이미지를 만듭니다. D가 진짜와 가짜를 구분하지 못하도록 학습합니다.
D (discriminative) : 가짜 이미지인지, 진짜 이미지인지 맞추는 모델입니다. G가 만든 이미지와 실제 이미지가 무엇인지 잘 맞추도록 학습합니다.
위 두 모델이 서로 경쟁을 하며 학습을 하여 결국 진짜와 가짜를 구분하지 못하는 수준까지 가죠. 즉 모든 지점에서 확률이 0.5가 됩니다.
💡1. Introduction
딥러닝의 목표는 자연 이미지, 음성 파형, 자연어 기호 등 인공지능 응용 분야에서 사용되는 데이터의 확률 분포를 표현하는 풍부한 계층적 모델을 발견하는 것입니다. 현재까지 딥러닝의 가장 눈에 띄는 성공은 고차원 입력을 클래스 레이블로 매핑하는 판별 모델에 기반하고 있으며, 이는 주로 역전파(backpropagation)와 드롭아웃(dropout) 알고리즘을 활용한 것입니다. 이러한 성공은 주로 부분 선형 유닛(piecewise linear units)을 사용하여 잘 동작하는 경량화된 기울기를 활용한 결과입니다.
반면, 깊은 생성 모델은 최대 우도 추정(maximum likelihood estimation)과 관련된 많은 복잡한 확률적 계산을 근사하는 어려움과 생성 맥락에서 부분 선형 유닛의 장점을 활용하기 어려운 문제로 인해 영향을 덜 미쳤습니다. 우리는 이러한 어려움을 회피하는 새로운 생성 모델 추정 절차를 제안합니다.
제안하는 적대적 네트워크(adversarial nets) 프레임워크에서는 생성 모델이 판별 모델과 경쟁합니다. 판별 모델은 샘플이 모델 분포에서 왔는지 데이터 분포에서 왔는지를 판단하는 방법을 학습합니다. 이 과정을 통하여 생성 모델은 가짜 화폐를 만들고 탐지되지 않으려고 하고, 판별 모델은 가짜 화폐를 탐지하려고 합니다. 이 경쟁은 두 모델이 서로의 방법을 개선하도록 유도하여, 생성된 샘플이 진짜와 구별되지 않게 만듭니다.
이 프레임워크는 다양한 모델과 최적화 알고리즘에 대한 특정 학습 알고리즘을 제공할 수 있습니다. 본 논문에서는 생성 모델이 다층 퍼셉트론을 통해 랜덤 노이즈를 샘플로 변환하고, 판별 모델도 다층 퍼셉트론일 때의 특수한 경우를 탐구합니다. 이를 적대적 네트워크(adversarial nets)라고 부르며, 이 경우 두 모델은 역전파와 드롭아웃 알고리즘만으로 학습하고, 생성 모델로부터 샘플을 얻기 위해서는 전방향 전파(forward propagation)만을 사용합니다. 이 과정에서 근사 추론이나 마르코프 체인(Markov chains)은 필요하지 않습니다.
💡2. Realated work
최근 딥 생성 모델 연구는 확률 분포의 매개변수적 명세에 초점을 맞추어 왔습니다. 이러한 모델은 로그 우도를 최대화하여 학습되며, 딥 볼츠만 머신(Deep Boltzmann Machine)이 그 중 하나입니다. 하지만 복잡한 우도 함수로 인해 많은 근사가 필요하죠. 그래서 샘플을 생성할 수 있는 "생성 기계(generative machines)"가 등장했습니다. 생성 확률 네트워크(Generative Stochastic Networks)와 같은 모델은 정확한 역전파(backpropagation)로 학습할 수 있으며, 볼츠만 머신의 근사화가 필요 없습니다.
우리는 생성 과정을 통해 미분을 역전파하는 방법을 사용했습니다. 당시, Kingma와 Welling, Rezende 등이 Gaussian 분포의 미분 역전파 규칙을 개발했다는 것을 알지 못했으며, 이는 변분 오토인코더(Variational Autoencoders, VAEs)의 학습에 유용합니다. VAEs는 미분 가능한 생성 네트워크와 적분 네트워크를 사용하지만, GANs(Generative Adversarial Networks)는 가시 유닛을 통해 미분을 필요로 해서 이산 데이터를 모델링할 수 없습니다.
판별 기준을 사용한 생성 모델 학습 방법에는 노이즈-대조 추정(Noise-Contrastive Estimation, NCE)이 있습니다. NCE는 노이즈 분포와 모델 분포 간의 판별기를 학습하며, 이는 적대적 네트워크의 경쟁 메커니즘과 유사합니다. 그러나 NCE는 노이즈 분포와 모델 분포의 확률 밀도 비율이 필요합니다.
예측 가능성 최소화(Predictability Minimization)는 두 신경망이 경쟁하는 개념을 사용하여 은닉 유닛의 통계적 독립성을 장려합니다. 이는 GANs와는 다르게 네트워크 간의 경쟁이 유일한 훈련 기준이며, 목표 함수의 최소화 문제로 설명됩니다. GANs는 미니맥스 게임을 기반으로 하며, 하나의 네트워크가 최대화하고 다른 네트워크가 최소화하는 방식입니다.
💡3. Adversarial nets
적대적 모델링 프레임워크는 두 모델이 모두 다층 퍼셉트론일 때 가장 간단하게 적용할 수 있습니다. 데이터
x에 대한 생성기 분포 p𝑔를 학습하기 위해 입력 잡음 변수 p(z)에 대한 사전 분포를 정의한 후, 데이터 공간으로의 매핑을 G(z;θg)로 표현합니다. 여기서 G는 매개변수 θg를 가진 미분 가능한 다층 퍼셉트론 함수입니다. 또한, D(x;θd)라는 두 번째 다층 퍼셉트론을 정의하며, D(x)는 x가 데이터에서 온 것인지 생성기 pg에서 온 것인지를 나타내는 단일 스칼라 값을 출력합니다.
우리는 D를 훈련하여 학습 예제와 생성기 G의 샘플에 대해 올바른 레이블을 할당하는 확률을 최대화합니다. 동시에 G는 log(1−D(G(z)))를 최소화하도록 훈련됩니다. 즉, D와 G는 다음과 같은 두 플레이어 미니맥스 게임을 수행합니다.
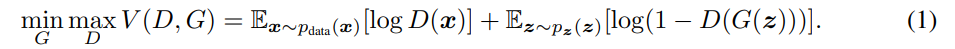
다음 섹션에서는 적대적 네트워크에 대한 이론적 분석을 제시하며, 학습 기준이 충분한 용량을 가진 G와 D를 통해 데이터 생성 분포를 복구할 수 있음을 보여줍니다. 즉, 비모수적 한계에서 가능하다는 것을 설명합니다. 더 직관적인 설명은 그림 1을 참고하십시오.
실제 구현에서는 반복적 수치적 접근이 필요합니다. D를 완전히 최적화하는 것은 계산적으로 비효율적이며, 유한 데이터셋에서는 과적합을 초래할 수 있습니다. 따라서 D를 k 단계 동안 최적화하고, 그 다음에 G를 한 단계 최적화하는 방식으로 교차 훈련합니다. 이로 인해 D는 최적 솔루션에 가까워지며, G가 충분히 천천히 변화하면 됩니다. 이 절차는 알고리즘 1에 공식적으로 제시되어 있습니다. 실제 문제에서는 식 1이 G의 학습에 충분한 기울기를 제공하지 않을 수 있습니다. 학습 초기에는 G가 부족할 때, D는 샘플을 높은 확신으로 거부할 수 있으며, 이로 인해 log(1−D(G(z)))가 포화될 수 있습니다. 따라서 G를 log(1−D(G(z)))를 최소화하는 대신 logD(G(z))를 최대화하도록 훈련할 수 있습니다. 이 목표 함수는 G와 D의 동적 고정점을 동일하게 하면서도 초기 학습 단계에서 훨씬 강력한 기울기를 제공합니다.
💡4. Theoretical Results
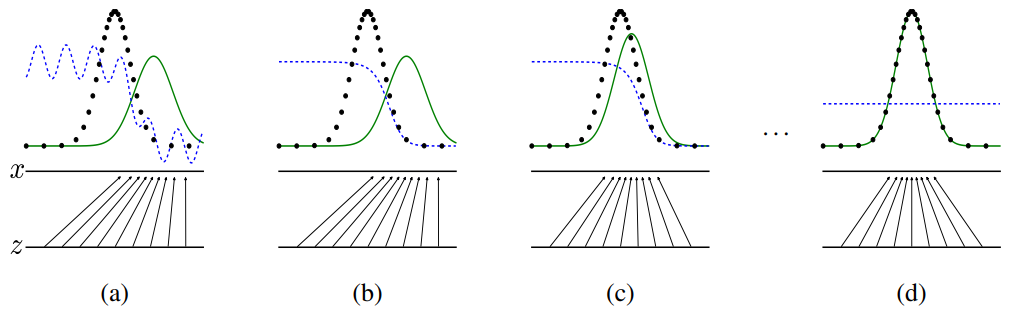
검은색 점선 : 실제 이미지
초록색 실선 : G 모델이 만들어낸 이미지
파란색 점선 : D 모델이 가짜와 진짜 이미지를 구분
(a)의 경우 실제 이미지(검은색 점선)와 가짜 이미지(초록색 실선)의 차이가 커서 D 모델이 가짜와 진짜를 잘 구분한다. 하지만 (d)로 갈 수록 초록색 실선과 검은색 점선이 겹쳐지며 거의 차이가 없다. 이 경우 파란색 실선이 중앙값, 즉 1/2 확률로 가짜와 진짜 이미지를 분류하는 최적의 상태이다.

논문에서는 k=1로 두어 D와 G가 번걸아가며 파라미터를 업데이트 한다고 합니다.
첫번째 수식을 먼저 살펴 봅시다.
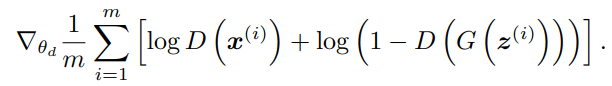
위 식은 D를 학습 시키기 위한 식입니다. D 모델은 이미지를 구분합니다. 진짜 이미지에 경우 1을, 가짜 이미지는 0이라는 값을 할당할 것 입니다. 진짜 이미지는 x, 가짜 이미지는 G모델이 만들었다하여 G(z)로 표현됩니다. 위 식에서 D(x)에는 1을, D(G(z))에는 0을 넣어 봅시다.
log(1)+log(1-1) = 0 으로 D 모델은 위 수식의 값이 0이 되도록 학습을 합니다.
두번째 수식을 살펴 봅시다.
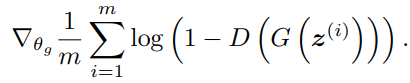
위 식은 G를 학습 시키기 위한 식입니다. G의 목적은 자신이 만들어낸 이미지를 D가 진짜라고 착각하여 1을 할당하도록 만드는 것입니다. 즉 D(G(z))값이 1이 되도록 말이죠. 위 식에 값을 넣으면 log(1-1) 은 마이너스 무한대로, G는 마이너스 무한대가 되도록 학습을 합니다.
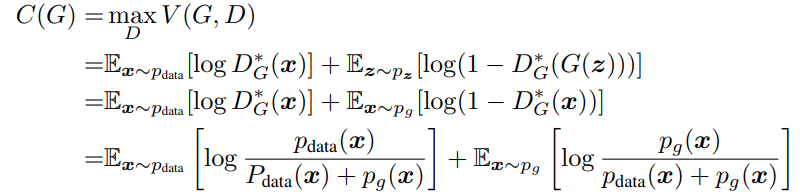
C(G)는 V(G, D)가 최대가 되도록 하는게 목표입니다.
이 경우 Pdata = Pg가 되어 log(1/2) + log(1/2)로 -log4 입니다.
💡 5. Experiments

우측열에 있는 이미지는 GANs이 만들어낸 가짜 이미지 입니다. 실제 샘플과 비교해도 손색이 없을 정도로 구분하기 어렵습니다.
학습시 D와 B를 잘 동기화 해야 합니다. G가 D를 업데이트 하지 않고 많이 훈련되면 "헬베티카 시나리오"가 발생할 수 있습니다. G가 너무 많은 z값을 동일한 x값으로 수렴시켜 데이터 분포를 모델링하는데 필요한 다양성이 부족해집니다.
