논문리뷰
1.[논문리뷰] AlexNet (ImageNet Classfication with Deep Convolutional Neural Networks)
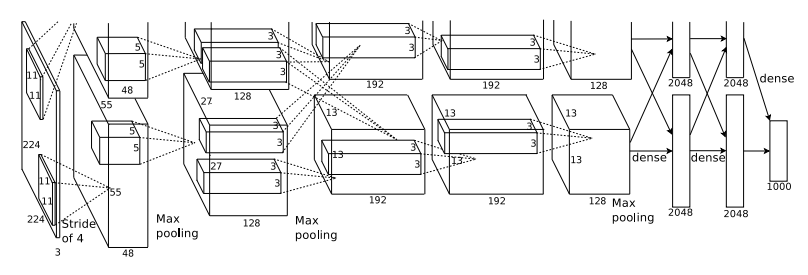
📌 컴퓨터 비전 분야의 시초라고 할 수 있는 AlexNet에 대해 리뷰해 보려고 합니다. 이 논문을 읽으시는 분들은 아마 딥러닝에 대해 논문을 읽는 첫 단계일 겁니다. 그렇기에 기본적인 용어에 대해서 자세히 설명하도록 노력해보겠습니다.
2.[논문리뷰] GoogLeNet (Going deeper with convolution)
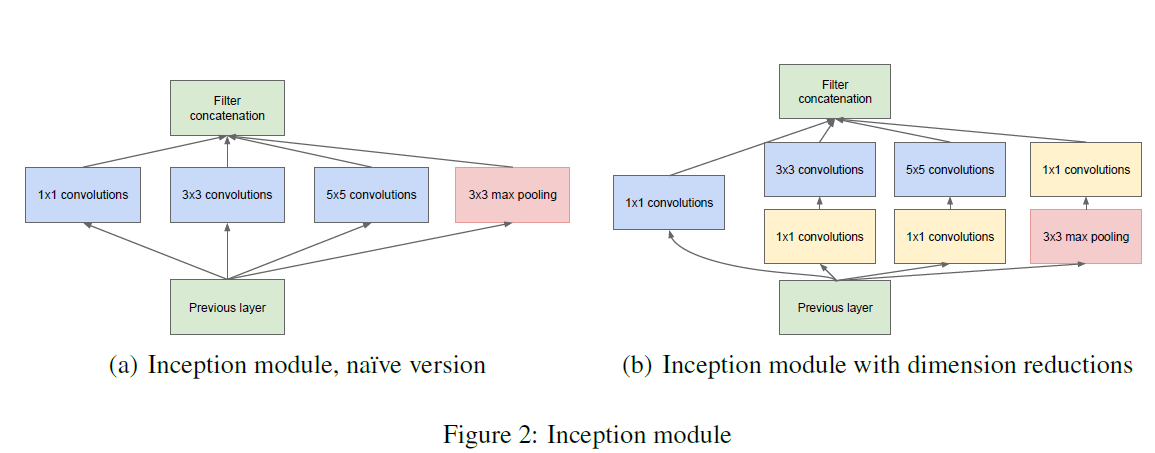
📌 두번째 논문 리뷰는 GoogLeNet입니다. 이름부터 구글이 참여했다는 걸 알 수 있죠? GoogLeNet은 이전 글에서 리뷰한 AlexNet 처럼 CNN을 이용합니다. 앞으로 나올 거의 모든 논문에서 CNN을 사용하죠. GoogLeNet의 특징이라고 하면 바로
3.[논문리뷰] VGGNet (Very Deep Convolutional Networks For Large-Scale Image Recongnition)

📌 앞서 살펴본 두 논문에서 성능을 향상시키기 위해 중요한 이론들이 사용되었지만, 현재는 더욱 발전된 모델들이 많이 개발되어 실제로 해당 모델들을 사용하는 경우는 드물어졌습니다. > 그러나 이번에 다룰 VGGNet은 단순히 이론적인 중요성뿐만 아니라 모델 자체의 실용성에서도 큰 가치를 지니고 있습니다. VGGNet은 유명한 Faster R-CNN이나 Y...
4.[논문리뷰] ResNet(Deep Residual Learning for Image Recognition)
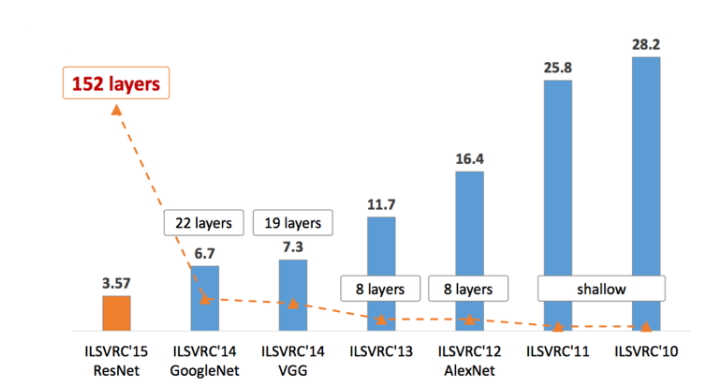
📌 저희가 앞서 배운 논문에서 AlexNet은 CNN의 효과를 증명했고, GoogLeNet은 다양한 크기 컨볼루션을 진행하며 1x1 컨볼루션으로 파라미터 수를 효과적으로 줄인 Inception 모듈을 사용했습니다. VGGNet은 3x3 컨볼루션이 5x5와 7x7컨볼루
5.[논문리뷰] GANs (Generative Adversarial Nets)
📌 지금까지 리뷰한 논문들은 classification 모델로 이미지의 클래스를 분류하는 작업을 했습니다. 이번에 공부할 논문은 이미지를 만들어내는 생성형 모델에 대해 공부해 보도록 하겠습니다. 💡Abstract 우리는 생성 모델을 추정하기 위한 새로운 프레임워크를 제안합니다. 이 프레임워크는 두 개의 모델을 동시에 학습시키는 방법입니다. 데이터 ...
6.[논문리뷰] Xception (Deep Learning with Depthwise Separable Convolutions)
📌 이번에 리뷰할 논문은 Xception으로, Inception 구조를 개선한 모델이라고 할 수 있습니다. > 특히 1x1 합성곱의 용도가 단순히 파라미터 수를 줄이는 데 그치지 않고, 새로운 해석을 제시하는 데 기여했다는 점에서 매우 인상적입니다. 💡Abstra
7.[논문리뷰] R-CNN (Rich fearture hierarchies for accurate object detection and semantic segmentation)
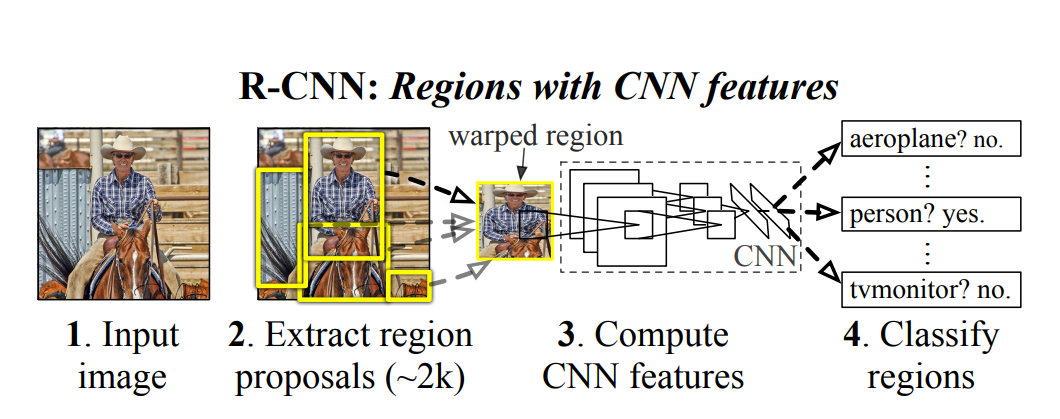
📌 드디어 classification이 아닌 object detection 논문을 읽어볼 차례입니다. classification의 경우 이미지당 하나의 클래스를 분류하는 문제였다면, object detection의 경우 이미지 한 장에서 여러개의 클래스를 찾아내고,
8.[논문리뷰] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
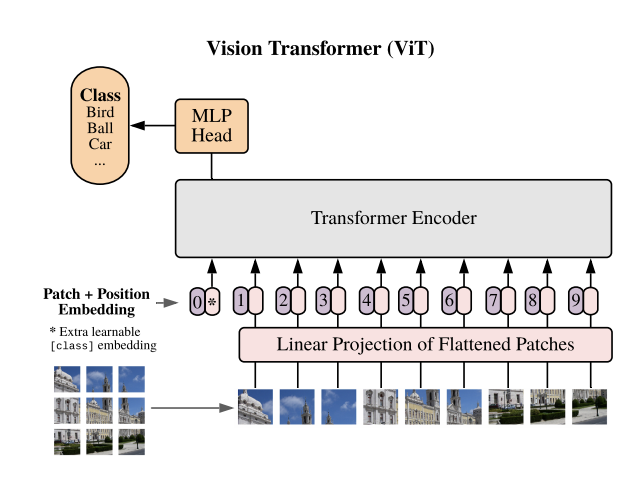
📌 VIT(Vision Transformer)라는 이름을 들어본 적이 있나요? 최근 인공지능 분야에서 주목받고 있는 이 기술은 이미지 처리에 새로운 패러다임을 제시하고 있습니다. 사실 VIT는 자연어 처리 분야에서 사용되는 구조입니다. 자연어 처리에서 성능이 좋았기
9.[논문리뷰] DINO : Emerging Properties in Self-Supervised Vision Transformer

📌 VIT의 경우 CNN의 성능을 뛰어넘기 위해서는 많은 데이터셋으로 학습을 시켜야 한다는 단점이 있습니다. 그렇다면 자가지도 학습을 VIT에 적용한다면, 이런 문제를 해결할 수 있지 않을까요?본 논문에서는 자기지도 학습(self-supervised learning)
10.[논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation
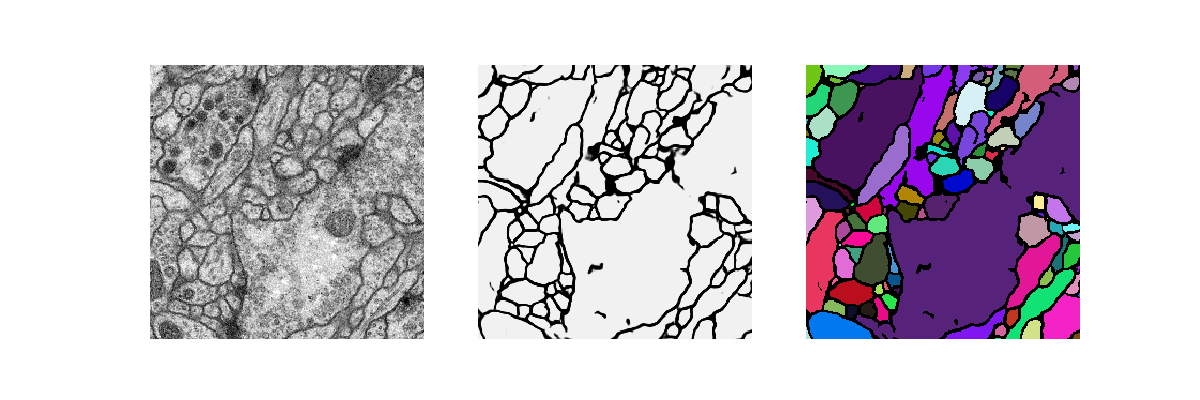
📌 Object detection을 공부하는 사람이라면 YOLO를 꼭 알아야 하듯, Segmentation 분야를 공부하는 사람이라면 UNet을 모를 수 없는 유명한 모델입니다.Classification : 이미지를 보고 해당 객체가 무엇인지를 구분하는 작업입니다.
11.[논문리뷰] Glass: A Unified Anomaly Synthesis Strategy with Gradient Ascent for Industrial Anomaly Detection and Localization

📌 이번엔 Anomaly Detection 분야에서 Mvtecdataset 기준 SOTA, 즉 정확도가 1위인 논문을 리뷰해보려고 합니다.논문을 읽어본 바, 지금까지 읽었던 논문 중에서 상당히 어려운 논문에 속합니다. 수식도 많고 다양한 아이디어가 적용되기 때문에 처
12.[논문리뷰] VAE: Auto-Encoding Variational Bayes
📌 최근 생성형 모델에서 주목받고 있는 diffusion 모델을 공부하기 전에 필수로 알아야할 VAE논문을 리뷰해보도록 하겠습니다.어떤 데이터(이미지)가 숨겨진 정보(잠재 변수)로부터 만들어졌다고 가정할 때, 이 숨겨진 정보가 정확히 어떤 값인지 알기 어렵고 이를 계