Cathe를 알아봤으니 다음은 어떤 정보가 필요한지 원티드에 검색을 해봤다. 🤔

Cathe를 이용한 DB , ORM 최적화.....? 🙄

그래서 오늘은 DB에 대해 알아봤다. 🐱💻
1. 데이터베이스란?
여러 자료 파일을 조직적으로 통합하여 자료 항목의 중복을 없애고 자료를 구조화하여 기억시켜 놓은 자료의 집합체
프로그래머가 필요에 의해 프로그램에 넣어놓은 데이터등 필연적으로 많은 데이터들이 생성되어지게 된다.
개인 컴퓨터를 사용해서 자료를 보관하면 데이터가 다 날라갈 때, 백업에 문제가 생깁니다. 따라서 안전하게 보관할 방법으로 DB가 탄생했습니다.
-
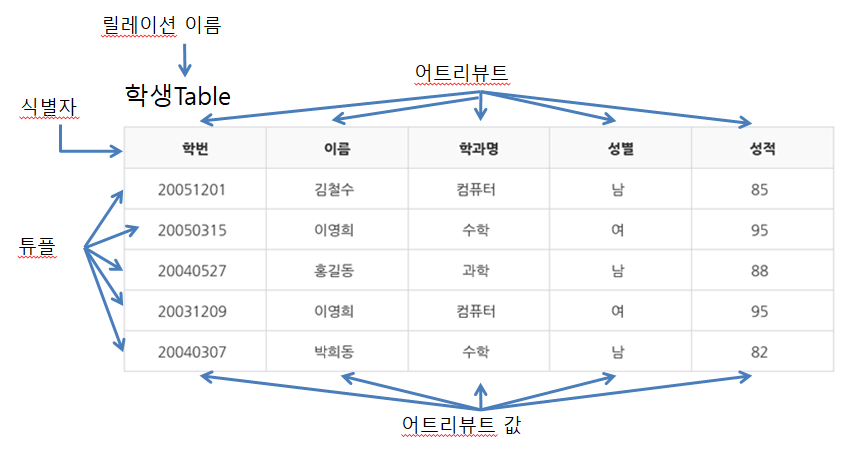
Relation(=Table) : 정보를 구분하여 저장하는 기본 단위이며 위와 같은 릴레이션 여러 개가 DB에 존재할 것입니다.
-
식별자(Identifier) : 집합체를 구분하는 논리적 개념입니다. 각 식별자는 서로 다른 키 값을 가집니다.
-
레코드(Tuple) : 테이블에서 행(row)를 의미하며 릴레이션에서 같은 값을 가질 수 없습니다. 튜플의 수는 Cardinality라고 합니다.
-
속성(Attribute) : 테이블에서 열(column)입니다. Attribute의 수는 Degree(차수)라고 합니다.
-
도메인(Domain) : 각 속성이 가질 수 있는 값의 집합
❓ 위 그림의 릴레이션, 식별자, 레코드, 속성은?
릴레이션 : 전체 표
식별자 : 학번, 이름, 학과명, 성별, 성적
튜플의 수 : 5
속성의 수 : 5
도메인 : 성별 -> 남 or 여, 성적 -> 0 ~ 100 같이 나타냄
2. DB Indexing이란?
✅ Index
.png)
데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조이다.
고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다.
때문에 테이블에 대한 검색 속도를 높여줄 수 있는 무언가가 필요했고 목차를 생성해서 검색 범위를 줄여 검색 속도를 높이기위해 Index를 사용합니다.
✅ Index 장점
index를 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있는데 이를 위해서는 쿼리 문법을 알고 있어야한다.
인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 각각 다음과 같은 연산을 추가적으로 해주어야 한다.
-
테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
-
전반적인 시스템의 부하를 줄일 수 있다.
✅ Index 단점
-
인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다고 한다.
-
인덱스를 관리하기 위해 추가 작업이 필요하다.
-
여러 쿼리 문법을 사용한 속성에 인덱스를 잘못 사용할 경우 인덱스의 크기가 커져서 탐색과정이 길어진다. 그럴경우 성능이 저하된다.
즉, INDEX는 규모가 크나 데이터 중복도가 낮으면서 쿼리 문법을 적게 쓴 컬럼에 사용하는 편이 좋다.
✅ 시간복잡도

-
O(1) – 상수 시간 : 입력값 n 이 주어졌을 때, 알고리즘이 문제를 해결하는데 오직 한 단계만 거칩니다.
-
O(log n) – 로그 시간 : 입력값 n 이 주어졌을 때, 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어듭니다.
-
O(n) – 직선적 시간 : 문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가집니다.
-
O(n^2) – 2차 시간 : 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱입니다.
-
O(C^n) – 지수 시간 : 문제를 해결하기 위한 단계의 수는 주어진 상수값 C 의 n 제곱입니다.
✅ Index의 종류
Binary Search Tree, B-Tree, Hash 등이 있는데 MySQL에서는 Balance-Tree(B-Tree)에서 확장된 개념은 B+Tree를 많이쓴다.
우선 B-Tree를 알아보자.
.png)
B-Tree는 데이터가 정렬되어 있는데, 각 데이터를 노드(Node)라고 하며 상단을 Root Node, 중간을 Branch Node, 하단을 Leaf Node라고 한다. 이 각 노드 간의 거리는 일정하기 때문에 균형트리라고 한다.
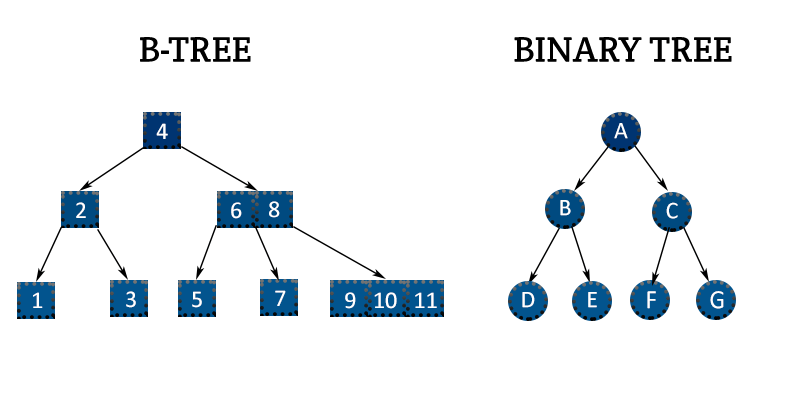
B-Tree는 Binary Tree에서 발전한 개념이라 비슷하지만, B-Tree는 한 노드당 자식 노드가 1개 이상이라는 점에 차이가 있다.
B-tree의 경우, internal 또는 branch 노드의 Key 와 Data를 담는다. 이를 이용해 데이터를 찾는 것이다.
따라서 브랜치 노드와 리프 노드에 메모리가 많아서 탐색하는데 B+Tree보다 느리다.
그럼 B+Tree는 무엇일까?
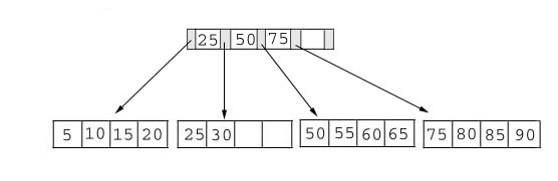
B+tree의 경우 브랜치 노드에 key만 담아두고, data는 담지 않는다. 오직 리프 노드에만 key와 data를 저장한다.
브랜치 노드에 data를 담아두지 않기 때문에 선형탐색으로 리프노드까지 한 번만 탐색하면 되서 빠르다.
3. DB 정규화란?
데이터를 모으는데, 데이터 특성의 범위, 단위 등 모두가 다를 것입니다. 따라서 데이터 특성의 단위를 무시해 값의 범위를 비슷하게 만드는 것을 Data Scaling이라고 합니다.
- Min-Max Normalization (최소-최대 정규화) : 이 작업을 정규화 작업이라고 합니다.
.png)
(측정값 - 최소값) / (최대값 - 최소값)
-
데이터를 특정 구간으로 바꾸는 척도법이다 (ex. 0~1 or 0~100)
-
데이터 군 내에서 특정 데이터가 가지는 위치를 볼 때 사용된다.
-
주가와 같은 주기를 띄는 데이터의 경우 과거에 비해서 현재 데이터의 위치가 어느정도 인지 파악하기에 좋아진다.
4. SQL Query 문법의 종류
DB에게 질의(Query)하기 위해 단어와 문법이 있을텐데 이것을 쿼리 질의, 쿼리문 이렇게 불린다.
쿼리 문법은 크게 DDL, DML, DCL로 나눠지며, 자세한 것은 이곳을 참고하자.
- 데이터 정의 언어 (DDL)
- 관계형 데이터베이스의 구조를 정의함
- 쌍, 속성, 관계 인덱스 파일 위치 등 데이터베이스 고유의 특성을 포함함
- 명령어 : CREATE, ALTER, DROP 등 - 데이터 조작 언어 (DML)
- 데이터베이스 검색, 등록, 삭제, 갱신을 하기 위해 사용하는 데이터베이스 언어
- 데이터베이스의 검색 및 업데이트 등 데이터 조작을 위해 사용
- 명령어 : SELECT, INSERT, UPDATE, DELETE 등
- 데이터 제어 언어 (DCL와 TCL 같이 기재함)
- 데이터베이스에서 데이터에 대한 엑세스를 제어하기 위한 데이터베이스 언어 또는 데이터베이스 언어 요소
- 박탈, 연결, 권한 부여, 질의, 자료 삽입, 갱신, 삭제 등
- 명령어 : GRANT, COMMIT, ROLLBACK 등

그래... 이제 DB가 뭔지 알 것 같다. 근데 당근마켓의 공고를 보니 뭔가 더 있었다..... 😵😫

이제는 RDBMS, NoSQL, Redis를 간략하게 알아보고자 한다... 😂😂😂
5. RDBMS와 NoSQL
DBMS는 DB를 관리하기 위한 소프트웨어를 말하는데,
RDBMS는 DBMS 중에서 관계형 데이터베이스 시스템말한다.
NoSQL은 관계형 데이터베이스 시스템이 아닌 것을 말한다.
그럼 RDBMS와 NoSQL 중에서 무엇을 사용해야할까?
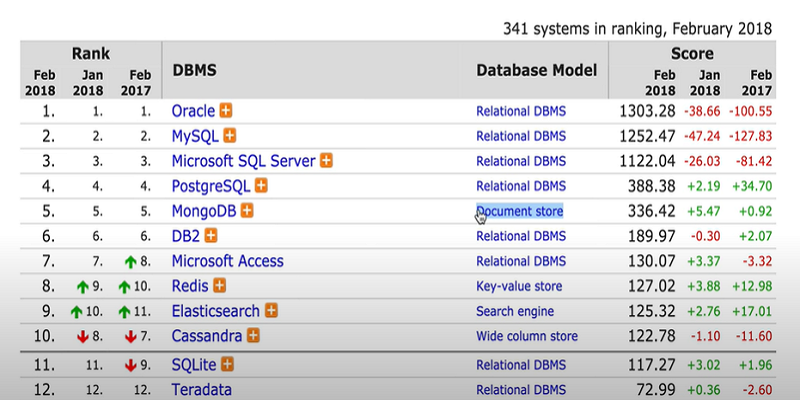
이것은 18년도의 DB Ranking이다.
관계형 데이터베이스 시스템이 1~4 등을 다 먹었다.
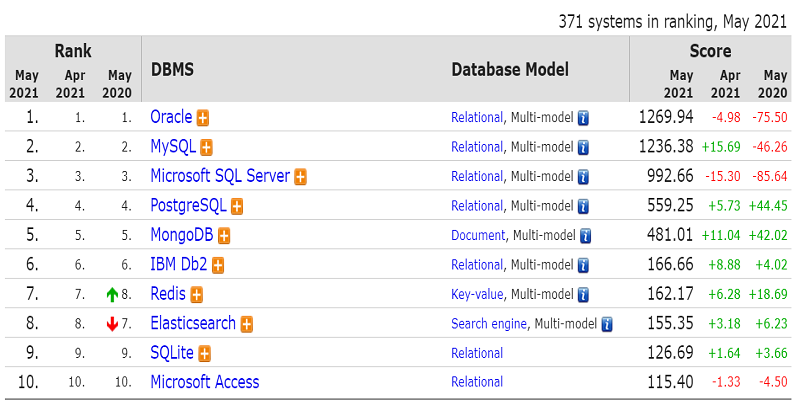
이제 21년도 DB Ranking을 보니 RDBMS의 Score는 계속 떨어지는 반면, Mongo DB, Redis의 Score는 증가하는 것을 볼 수 있다. 특히 Redis의 순위가 1계단 올랐다 🤔
Document store인 Mongo DB, Key-Value store인 Redis 등은 NoSQL이라고 한다.
우선은 RDBMS부터 알아보고 NoSQL을 알아보도록 하자.
RDBMS
RDBMS는 RDB를 관리하는 시스템이며 RDB는 관계형 데이터 모델을 기초로 두고 모든 데이터를 2차원 테이블 형태로 표현하는 데이터베이스입니다.
RDBMS는 여러 테이블을 외래키(Foreign Key)를 통해 Join을 합니다. 이렇게 Join을 해서 관계를 맺습니다.
장점
-
명확한 데이터 구조를 보장
-
데이터 무결성으로 인해 데이터 간에 중복이 없어 데이터 변경에 용이
단점
-
시스템이 커지면 커질수록 JOIN 문이 많아져 복잡해진다.
-
성능 향상을 위해서는 서버를 증강시켜야하는
Scale-up만을 지원합니다. 이로 인해 고성능 프로세스를 요구해 비용이 기하급수적으로 증가함. -
스키마로 인해 데이터가 유연하지 못함.
Not Only SQL(NoSQL)
RDBMS의 단점을 보면 기존 SQL 서버의 복잡성과 용량으로 인한 비용 증가로 유연하면서 데이터 용량이 더 큰 무언가가 필요해졌다. 그래서 데이터 일관성은 포기하되 비용을 고려하여 여러 대의 데이터에 분산하여 저장하는 Scale-Out을 목표로 NoSQL이 등장했습니다.
1. Key-Value Database
Key-Value Database는 데이터가 Key와 Value의 쌍으로 저장된다. Key는 Value에 접근하기 위한 용도로 사용되며, 값은 어떠한 형태의 데이터라도 담을 수 있다. 심지어는 이미지나 비디오도 가능하다. 또한 간단한 API를 제공하는 만큼 질의의 속도가 굉장히 빠른 편이다.
대표적인 NoSQL Key-Value Model로는 Redis, Riak, Amazon Dynamo DB 등이 있다.
2. Document Database
Documnet Database 데이터는 Key와 Document의 형태로 저장된다. Key-Value 모델과 다른 점이라면 Value가 계층적인 형태인 도큐먼트로 저장된다는 것이다. 객체지향에서의 객체와 유사하며, 이들은 하나의 단위로 취급되어 저장된다. 다시 말해 하나의 객체를 여러 개의 테이블에 나눠 저장할 필요가 없어진다는 뜻이다.
주요한 특징으로는 객체-관계 매핑이 필요하지 않다. 객체를 Document의 형태로 바로 저장 가능하기 때문이다. 또한 검색에 최적화되어 있는데, 이는 Ket-Value 모델의 특징과 동일하다. 단점이라면 사용이 번거롭고 쿼리가 SQL과는 다르다는 점이다. 도큐먼트 모델에서는 질의의 결과가 JSON이나 xml 형태로 출력되기 때문에 그 사용 방법이 RDBMS에서의 질의 결과를 사용하는 방법과 다르다.
대표적인 NoSQL Document Model로는 MongoDB, CouthDB 등이 있다.
장점
-
언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있다.
-
데이터 분산이 용이하며 성능 향상을 위한 Saclue-up 뿐만이 아닌 Scale-out 또한 가능
단점
-
데이터 중복이 발생할 수 있으며 중복된 데이터가 변경 될 경우 수정을 모든 컬렉션에서 수행을 해야 함
-
스키마가 존재하지 않아 명확한 데이터 구조를 알기 어려우며 로직을 수행하는데 적합한 데이터 구조 결정이 어렵다.
참고 자료
