[Korea University] Multivariate Data Analysis 1. introduction
Multivariate Data Analysis 1. introduction, Pilsung Kang 강의를 참고하였습니다.
https://www.youtube.com/watch?v=o9uEVxzFeR0&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2
1. Introduction to Data Science
아마존의 Anticipated Shipping는 특정 고객이 어떤 제품을 구매할 것인지를 예측을 하고, 예측된 상품들을 바로 가까운 지역 물류창고로 옮겨 놓는 것.
LANDING.AI회사는 어떠한 산업 공산품에 대해 이상치를 탐지하게 해준다.

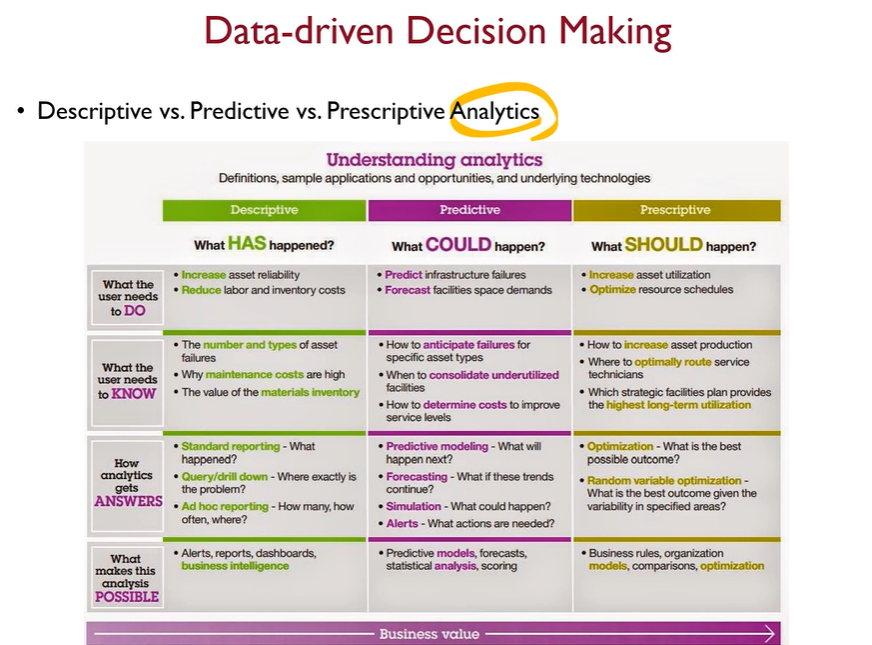
Data-driven Decision Making은 데이터를 기반으로 객관적인 수치를 통해 최적의 의사결정을 하자는 것. 의사결정의 반대는 경험기반 의사결정.
Data-driven Decision Making는 설명, 예측, 최적화 3단계로 나눌 수 있다.
설명단계는 과거에서 현재까지 무슨일이 일어난 것인가를 보는 것.
예측단계는 과거부터 현재까지 있었던 일을 바탕으로 미래에 일어날 일을 선제적으로 알아보자는 것. 이 단계에서는 무언가를 control하지 않는다. 지금 상황이 지속되면 어떤 일이 발생할지 알아보는 것.
최적화단계는 미래에 발생할 일을 바탕으로 현재 어떠한 일을 취해야 하는지 생각하는 것. 가장 유리한 상황을 만들기 위해서는 현재 어떻게 상황을 만들어야 하나?

이러한 Analytics의 가장 핵심적인 기술로, Machine Learning이 존재하는데, 그 정의는 다음과 같다.
어떠한 일을 해결하기 위하여 어떠한 경험 E로부터 학습하고, 그 일을 얼마나 잘 해결하는지 퍼포먼스를 측정하기 위한 P가 존재할 때, 일에 대한 퍼포먼스인 T와 그 측정단위 P가 E로부터 개선되는 컴퓨터 프로그램.
이러한 머신러닝에는 다음과 같은 두 가지 분야가 존재한다.
Supervised Learning
- 입력 원인 X와 예측하고자 하는 출력 Target Y가 존재
- 즉, y = f(x) 형태로 제공되어 관계식을 찾는 것이 목적
unsupervised Learning
- y값 없이 오직 x만을 가지고, 이를 통해 가질 수 있는 분포나 특징, 패턴들을 찾는 것이 목적
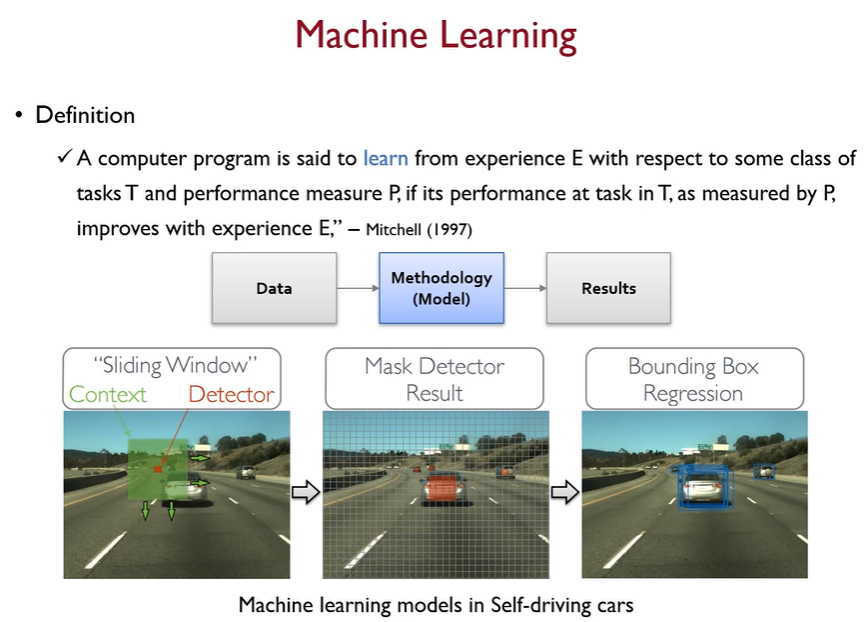
머신러닝은 다음과 같이 크게 3가지의 순서를 가진다. Data(경험) , Methodology(방법), Results(결과)
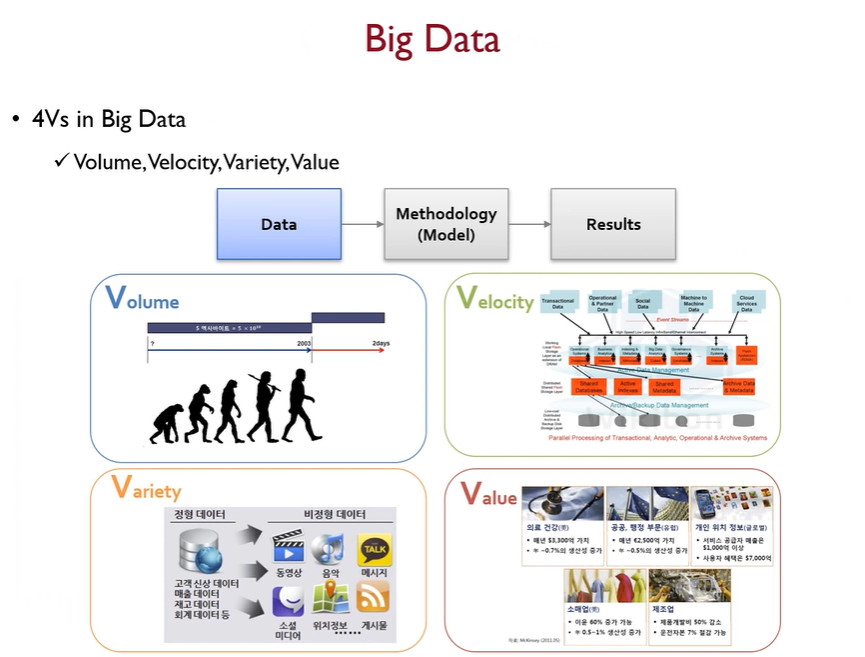
이러한 머신러닝이 잘 수행되기 위한 가장 첫번째 조건은 바로 Data이다. 그 중에서도 Big data는 현재 잘 사용되지는 않는데, 이는 이를 대체하거나 더 좋은 방법이 나타난 것이 아닌 이미 우리의 사회의 전반적인 부분에 모두 자리를 잡았기 때문이다.
머신러닝의 3가지 순서 중, Data(경험)에 관한 부분이 Big data가 되는 것.
Big data는 4V라는 4가지의 특징을 가지는데, 양 자체가 매우 방대하고(Volume) 데이터가 생성되는 속도도 그렇지만 처리되는 속도도 매우 빨라야하고(Velocity), 행은 관측치, 열은 변수들, element는 숫자인 정형데이터에서 비정형데이터로 넘어간 것처럼 데이터가 다양해졌으며(Variety), 데이터 분석을 통해서 매출이나 효율성 증가 등 객관적이고 정량적으로 효과를 낼 수 있어야 한다(Value).
Big data의 중요한 점 중 하나는 데이터의 존재 자체로써 복장한 분석 방법론이 없어도 문제가 해결될 수 있는 상황이 존재한다는 것. 네이게이션 등을 생각해보자.
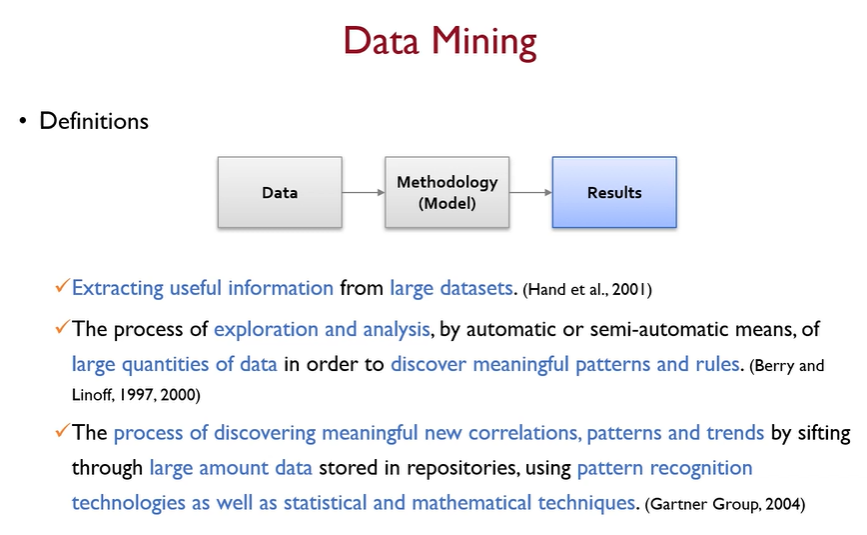
Data mining은 머신러닝의 3가지 요소 중 마지막에 해당하는 결과물을 어떻게 뽑아낼 것인가에 관한 것. 대량의 데이터셋으로부터 유용한 정보를 뽑아내고, 이를 탐색하고 분석하여 의미있는 패턴과 규칙을 찾아내고자 하는 것.

Artificial Intelligence는 사람처럼 지능화된 능력을 가지는 컴퓨터나 컴퓨터 소프트웨어
방법(Methodology)에 행위(Action)이 추가된 것. 이때, 창의성(Creativity)에 따라 약인공지능, 강인공지능으로 나뉘게 된다. 강인공지능은 마주하지 않은 상황에서도 좋은 성능을 발휘한다.
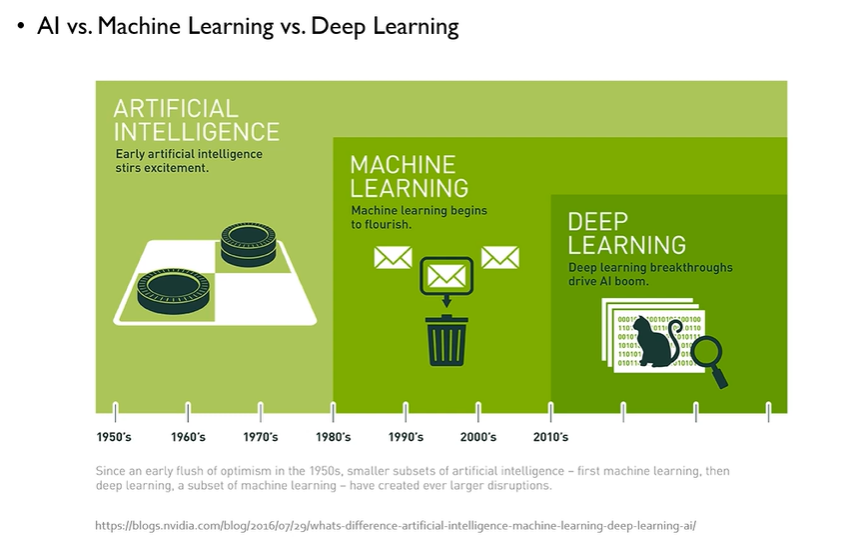
AI: 사람처럼 생각하는 기계를 만들자. 이때 인공지능을 만드는 지능 중에는 두 가지가 있다.
- 연역적 지능: A가 B이고 B가 C이면 A는 C이다. Symbolic 연산 가능해야 한다.
- 귀납적 지능: 경험을 통해서 배운다. 머신러닝에 해당
이때 머신러닝의 하위 개념인 Neural network를 special하게 컴퓨터가 모사하게 한 것이 Deep Neural network, 딥러닝에 해당한다.
2. Data Science Applications
2-1. Visualization for intuitive understanding

데이터를 가장 손쉽게 보기 위하여 시각화하고 요약하는 것. 다음과 같은 word cloud 등이 있다.
2-2. Predict, Diagnosis, Detection
날씨, 주가, 경제지표 등등을 예측 및 진단.
2-3. support decision making in every day life. (Recommendation system)
추천 시스템. 넷플릭스, 쇼핑사이트, 스포티파이 등에서 사용된다.
3. Multivariate Data Analysis in Data Science

다변량 데이터 분석은 다음과 같은 파트로 나눌 수 있다.
1. Data reduction/structural simplification: 데이터 축소, 단순화. 주어진 데이터들의 본질적인 특징을 최대한 보존하면서 훨씬 적은 차원의, 간단한 데이터셋으로 변환시키고자 하는 것. 해석이 쉬워진다. Variable reduction 방법, PCA 방법 등 존재한다.
- 국가 지표에 대한 핵심적인 Performance index 만들기
- 어떤 병에 대하여 중요한 역할을 하는 feature 만들기
2. Sorting and grouping: 유사한 것들끼리 그룹화. 비슷한 객체나 변수들을 묶어내는 것. 각각 다른 군집들은 어떠한 차이가 있는지 살펴본다. Hierarchical clustering, K-means clustering
- 보안 관점에서 컴퓨터를 사용하는 사용자들에게서 패턴을 찾아내 이 이외의 패턴을 보이는 사람 찾아내기
3. investigation of the dependence among variables: 변수끼리 dependence, correlation 확인. 각각의 변수들이 어떠한 관계를 가지는지 본질적인 특성을 파악하는 것. association rule mining, factor analysis.
4. prediction: 예측 모형. 가장 핵심이다. 어떠한 목적에 대해서 하나의 변수를 다른 변수들의 관측치로부터 예측하고자 하는 것. Classification, Regression 문제 둘다 있음.
5. hypothesis construction and testing: 가설 검정, 가설 생성, 가설 테스트. Inferences about a Mean Vector, Comparisons of several multivariate means
4. Data Science Procedure
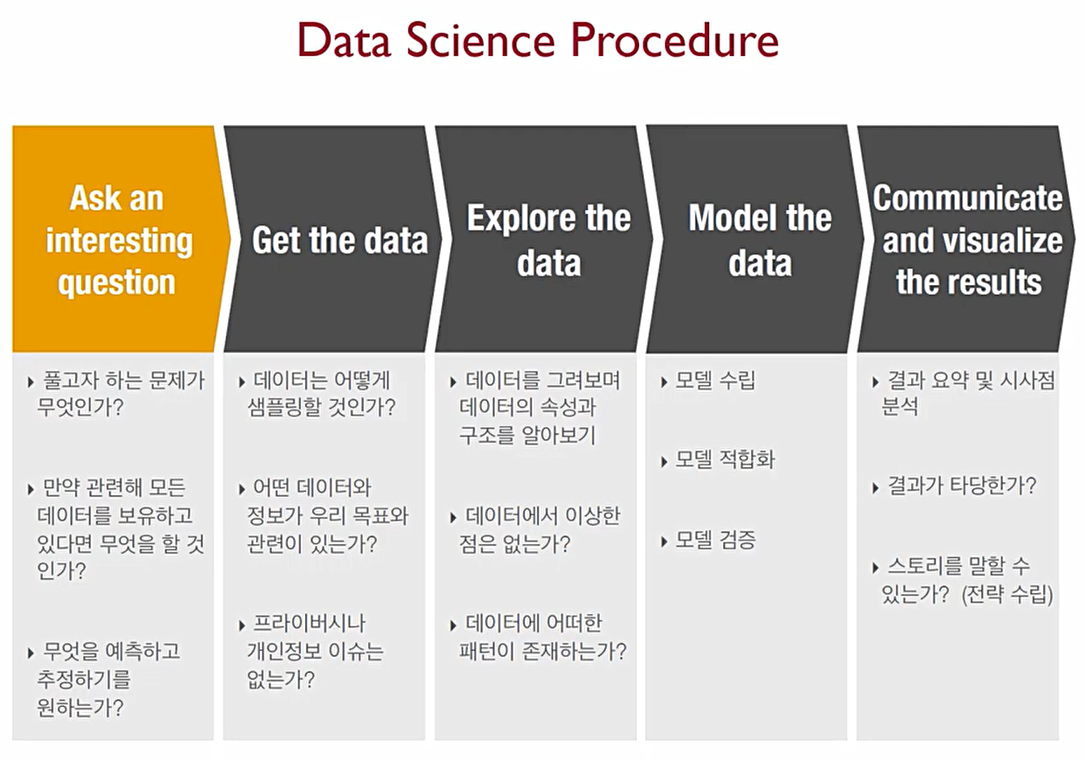
Data Science의 순서는 다음과 같다.
이때, interesting의 의미는 학술적인 의미, 비즈니스적인 의미가 모두 존재하는 것이므로 Task에 맞게 잘 생각해봐야 한다.
1. Ask an interesting question: 무언가 질문이 나왔을 때, 이것을 해결하면 시스템이나 조직 운영에 도움이 되는 것이어야 한다.
- 어떠한 문제를 풀어야 하는 것일까를 정의하는 것은 매우 중요하다.
2. Get the Data: 데이터를 확보하는 단계. 이때 가장 중요한 두 가지의 말이 있다.
- Garbage in, Garbate out
- The larger, the better
즉, 좋은 데이터를 가져오고 정제하여야 하고, 데이터는 크면 클수록 좋지만 현실적으로 내 능력(computing 능력 등 포함)안에서 허락 가능한 만큼만 가져와야 한다.
최근에는 인공지능 알고리즘을 학습시키기 위하여, Data annotation 자체를 비즈니스 모델로 세우는 경우가 있다. 이는 어떤 조직에서 문제를 풀기 위해 필요한 데이터에 Label(정답)이 달려있지 않는 경우, 해당 데이터의 label을 직접 작성해주는 것을 말한다. 이를 위해서는 전문가의 domain에 관한 지식이 매우 중요한데,
3. Explore the data before modeling: 모델링 전에 데이터를 충분히 이해하고 탐색하는 단계. 데이터와 친해지는 단계이다.
사람들이 가장 많이하는 실수는 해당 Raw 데이터를 무작정 모델에 집어 넣는 것이다. 단변량 데이터 분석이나, 통계량 분석 등의 전통적인 분석을 통하여 데이터의 특성을 숙지하여 적절한 알고리즘을 적용해야 한다.
spotfire, qlik, tableau 등 다양한 시각화 툴 이용해보자.
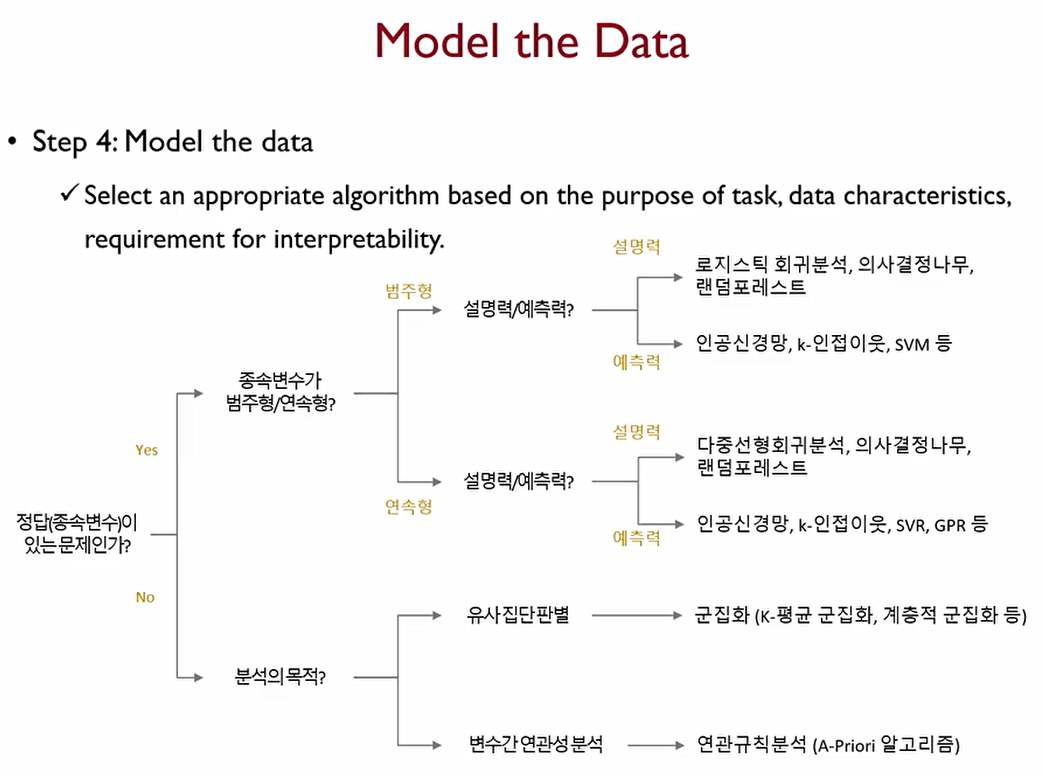
4. model the data: 상황에 따라 가장 적합한 알고리즘을 이용해야 하기에 다양한 모델을 알고 있어야 한다.
5. Communicate and visualize the results: 결과물을 보고 실제 활용이 되는 부분을 그 결과물을 운용할 사람들에게 communicate하고, 비전공자들에게 이를 설명하기 위해 visualize하는 단계이다.
또한 implementation을 통해 피드백을 받아 모델을 수정하고 업데이트 하여 좋은 모형을 만드는 단계.
