[Korea University] Multivariate Data Analysis 7-2. Ensemble Learning Bagging
Multivariate Data Analysis 7-2. Ensemble Learning Bagging, Pilsung Kang 강의를 참고하였습니다.
https://www.youtube.com/watch?v=giIaZDXu2No&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=24

실제 우리는 x와 y가 주어져 있는 데이터셋을 받을 수 있다. 이때 f(x) = y를 만족하는 모델을 만들 수 있고, 앙상블을 하기 위해서는 f1(x) = y, f2(x) = y, ..., fn(x) = y를 만족하는 모델들을 모두 만들 수 있어야 한다.
이때, 주어진 하나의 데이터셋을 가지고 어떻게 여러개처럼 보일 수 있을것인가가 목표?
그러나 사실 동일한 데이터 셋을 사용하는 것은 다양성 확보에 도움이 되지 않는다. 이에 하나의 데이터셋을 가지고 데이터 셋이 서로 다르면서, 이 데이터들로 구축한 모델들이 기본적인 성능을 구축하도록 데이터셋을 구축해야 한다.
1. K-fold data split
데이터를 비복원 추출을 하는 것. 전체 데이터 셋을 k개의 block으로 나눈 후, classifier model을 통하여 (k-1)개의 블록만을 가지고 훈련을 하는 것.
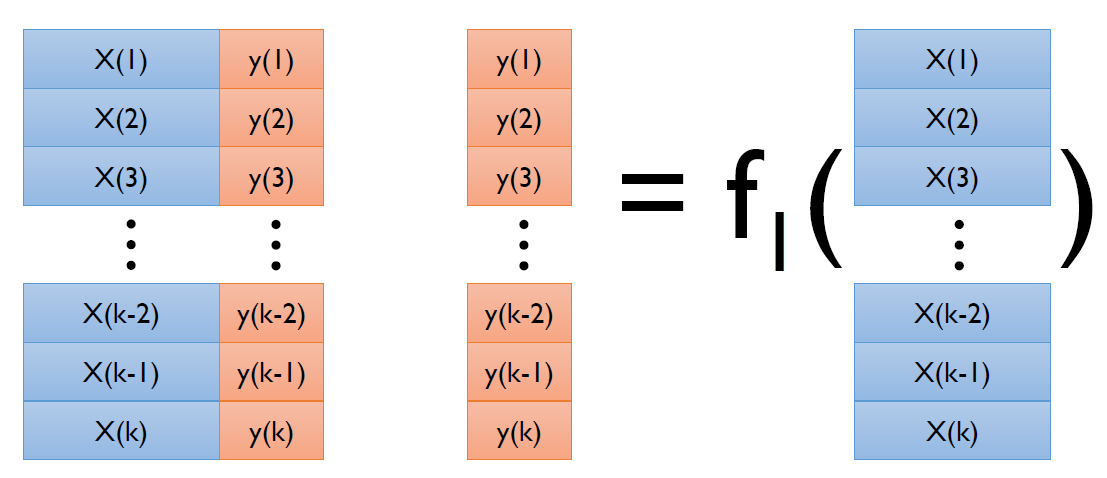
이때, f1(x) 모델에는 k번째 블록을 빼고 학습한다. 전체 데이터셋을 만들어서 모형을 만들면 똑같아지므로 약간 다르게 만들기 위하여 블록을 빼는 것.
이후 f2(x) 모델에는 k-1번째 블록을 빼고 학습하고, f3(x)에는 k-2번째 블록을 빼고 학습하고 이를 쭉 반복하여, fk-1번째 모델에는 2번째 블록을, fk번째 모델에는 1번째 블록을 빼고 학습.
이렇게 만들어진 모형들을 적절히 조합하여 Ensemble효과를 얻고자 하는 것.
(1)
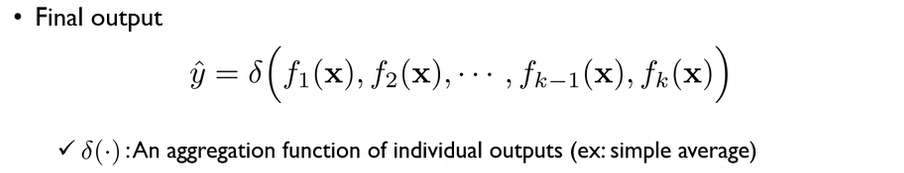
이렇게 만들어진 k개의 모델들을 서로다른 output들을 결합해주는 δ라는 Aggregation function 것을 취해준다. (그냥 평균 내는 등 다양한 방법 존재.)

사실, k-fold data split은 잘 사용하지 않는다. 그 이유는 원래 데이터셋보다 객체수가 적게 되고, 데이터 간의 중복이 많아져 다양성이 떨어지게 된다는 것. 이에 보통은 Boostrap Aggregating: Bagging을 사용한다.
2. Boostrap Aggregating:Bagging
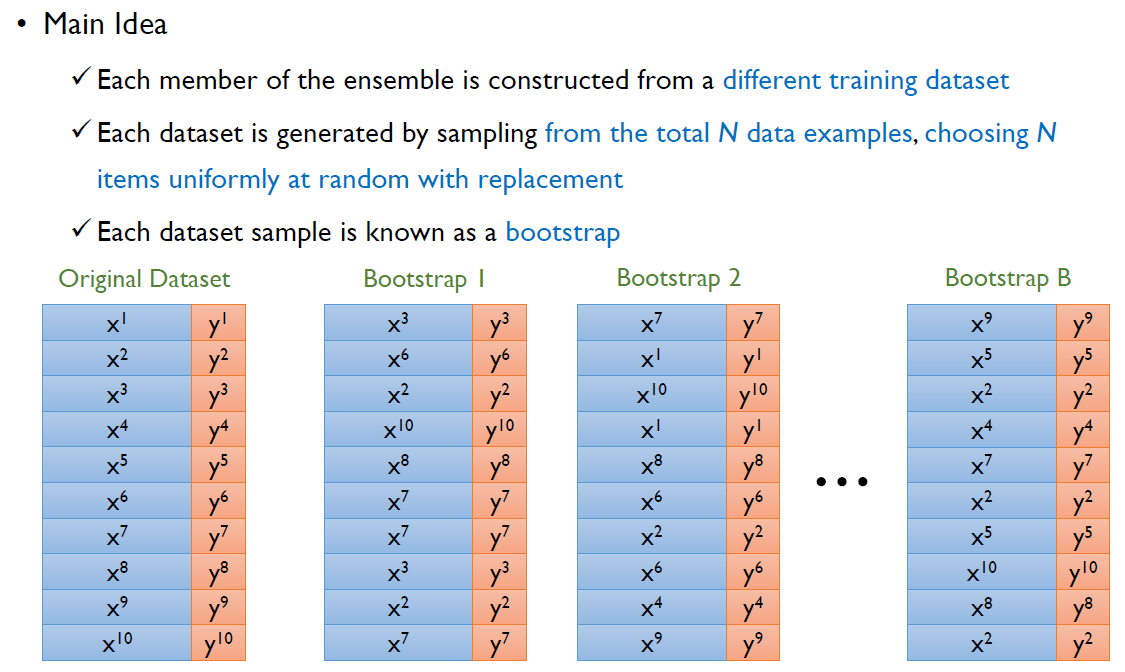
k-fold data split과 가장 큰 차이점은 바로 복원추출(with replacement)를 하는 것. 원래 데이터가 N개가 있다면 N개의 객체들을 복원추출 하겠다는 것. 이때, 각 데이터셋의 샘플들을 booststrap이라고 한다.
이때, booststrap을 하면서 Random하게 데이터들을 추출하게 된다. 이렇게 추출되는 데이터들은 중복될 수 있다.
이렇게 추출을 함으로써, k개의 블록으로 구분하는 것 보다는 original 데이터가 가지는 갯수도 보전할 수 있고 각각 booststrap 들에 약간 변형된 데이터를 전달할 수 있다. 이렇게 변형된 데이터를 Training subset이라고 한다.
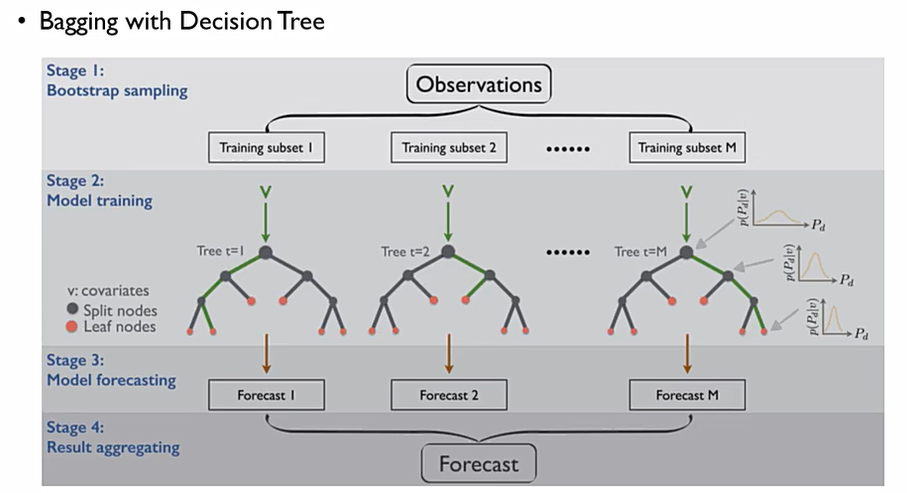
이후, 각 training subset으로 의사결정 나무를 만들면 나오는 의사결정 나무들은 모두 모양이 다르게 된다. 이후, test를 위하여 모든 test data들을 모든 의사결정 나무 모델에 동일하게 제공을 하면 각 나무마다 다른 예측값이 나오게 되는데, 이를 aggregating을 통해 하나의 예측값으로 만들게 되는 것이다.
이때, Bagging은 알고리즘 자체가 아니라 앙상블을 구성하기 위한 다양성을 확보하기 위해 데이터를 어떻게 구성할 것인가에 관한 테크닉. 이는 Bias는 작은데 Variance가 큰, 즉 모델의 complexity가 큰 알고리즘에 잘 맞는다. 이러한 배깅은 어떠한 supervised learning 알고리즘에 모두 사용 가능하다.
Bagging에 해당하는 부분은 Boostrap 데이터를 sampling하는 테크닉.

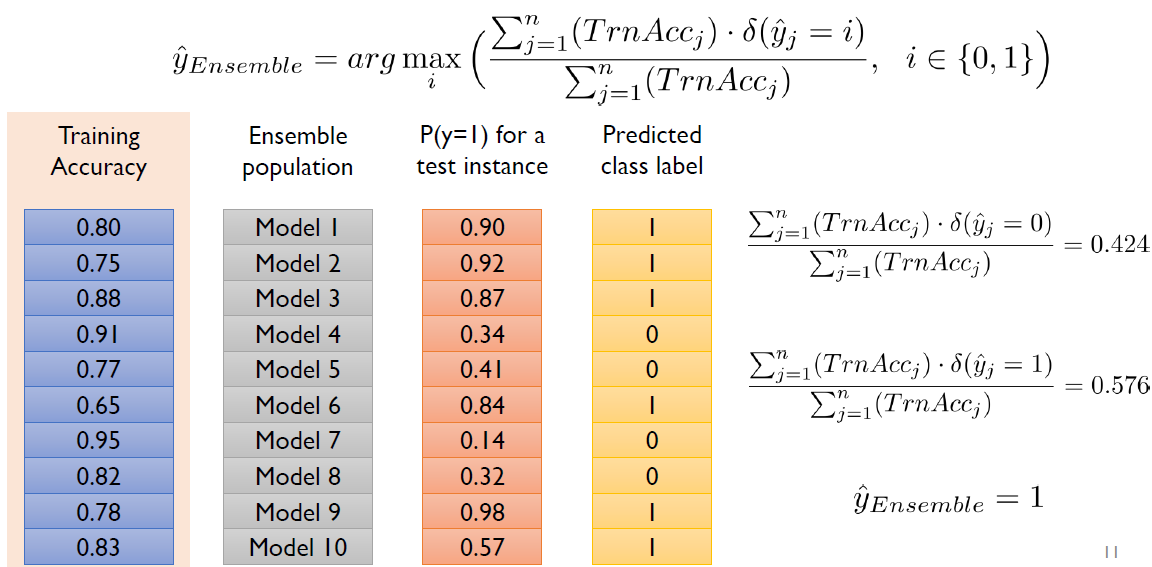
!! 위의 사진에서 Training Accuracy가 아닌 Validation Accuracy로 고쳐야 함 !!
앞서 나온 모든 결과들을 어떻게 Aggregation할 수 있을까?
predicted class label은 2범주 분류로 가정하여, P(y=1) for a test instance가 0.5(Cut off값)가 넘는다면 1로, 아니면 0으로 한다.
이때, 우리는 predicted class label로 Ensemble의 output은 무엇인가 예측을 하고 싶은 것이다. 이에는 다양한 방법론이 존재한다.
FOR CLASSIFICATION PROBLEM
- Majority voting: 다수결. 가장 많은 label이 나온 수를 앙상블로 Output으로 하는 것.
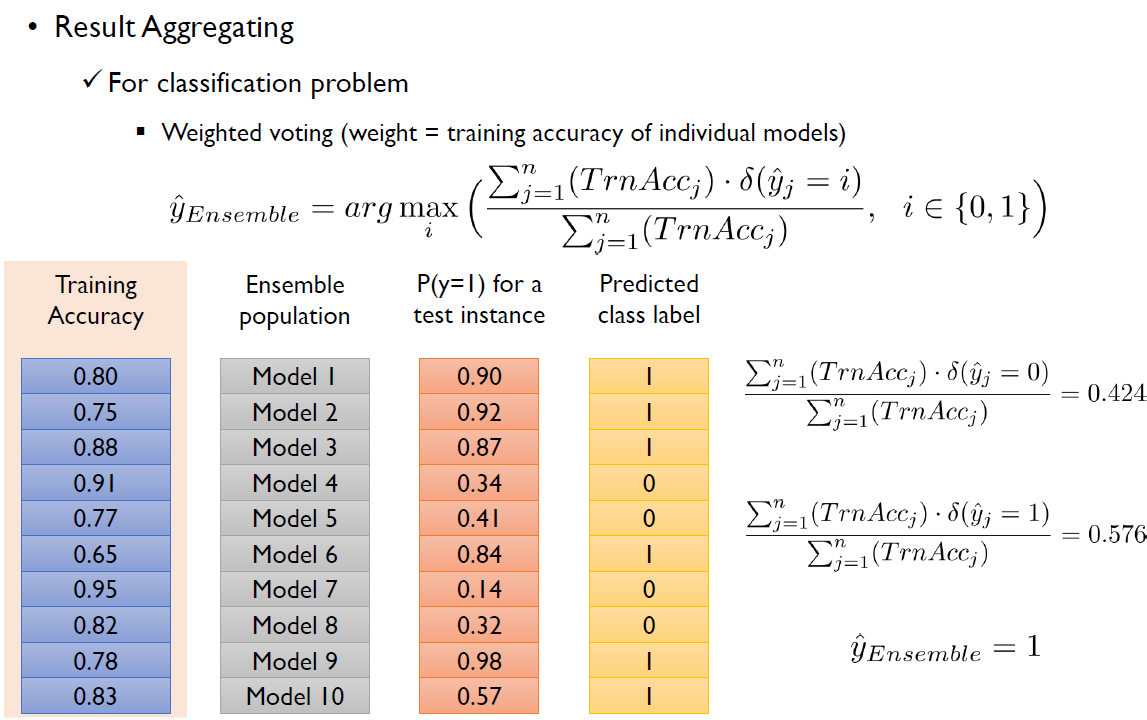
- Weighted voting: 가중합을 하자! 이때 가중치를 어떻게 쓸 것이냐에는 많은 방법이 있다.
1. Val accuracy 기준
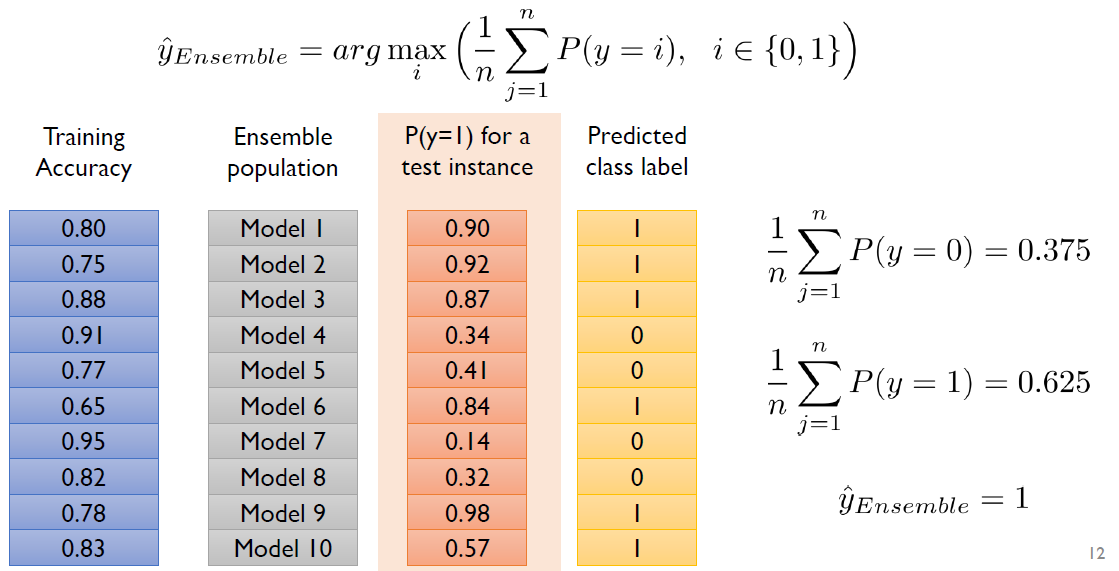
2. 해당 class에 속할 확률 기준
- Stacking: 다른 prediction model을 만든다.
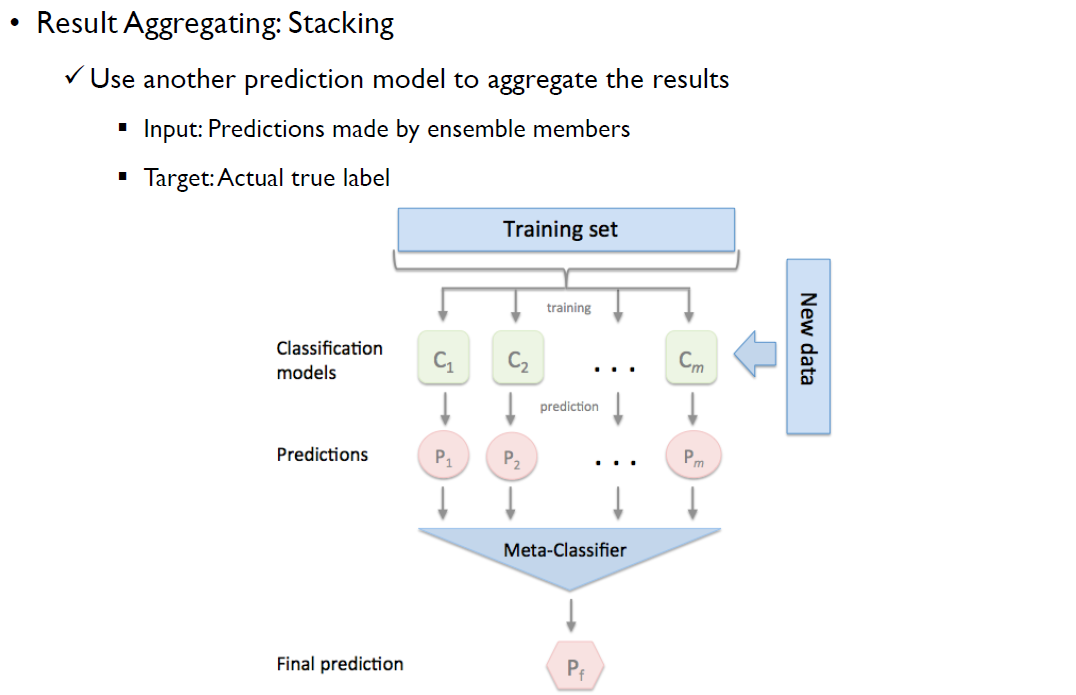
training data를 통해서 만들어진 final prediction Y가 존재할 때, preidctions가 X가 된다 이때, Y = f(X)를 만족하는 또다른 함수를 다시 만드는 것. 예측 결과를 통해서 정답을 추정하는 또 다른 하나의 모델을 만들어 Classification models 위에 새롭게 모델을 또 쌓는 것.
Out of bag error(OOB Error)
Bagging이 가지는 현실적인 특징 중 하나. Bagging은 Random sampling with replacement이Boostrap을 통해서 선택되지 않는 데이터들이 있을 수 있다. 이때, 이러한 out of bag data를 검증용 데이터로 사용하자는 것.
