- 자료출처 : PyTorch로 시작하는 딥 러닝 입문
- 컴퓨터는 숫자를 처리한다. 자연어 처리 역시 문자를 숫자로 바꿔야 한다.
1. 원-핫인코딩
- 문자를 숫자로 바꾸는 방법 중 하나, 단어를 표현하는 가장 기본적인 표현방법으로 머신러닝에서 반드시 배워야하는 표현 방법
# 코엔엘파이로 형태소 토큰화
from konlpy.tag import Okt
okt = Okt()
token = okt.morphs("나는 자연어 처리를 배운다")
print(token)['나', '는', '자연어', '처리', '를', '배운다']# 각 토큰에 인덱스 부여
word2index = {}
for voca in token:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
print(word2index)
{'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5} {'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5}
{'나': 0, '는': 1, '를': 4, '배운다': 5, '자연어': 2, '처리': 3}# 토큰을 입력하면 원핫 벡터로 만드는 함수 정의
def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index))
index = word2index[word]
one_hot_vector[index] = 1
return one_hot_vectorone_hot_encoding("자연어",word2index)[0, 0, 1, 0, 0, 0]2. 워드 임베딩
- 단어를 벡터로 표현하는 방법으로 희소표현, 밀집표현, 워드임베딩이 있다.
1) 희소표현
- 벡터 또는 행렬이 대부분 0으로 표현되는 방법이다.
- 원-핫 벡터처럼 단어의 인덱스만 1이고 나머지는 0으로 표현되는데, 이를 희소 벡터라 한다.
- 희소벡터의 문제는 단어의 개수가 늘어나면 벡터의 차원이 한없이 커지며 공간적 낭비를 불러일으킨다.
import torch# 원-핫 벡터 생성
dog = torch.FloatTensor([1, 0, 0, 0, 0])
cat = torch.FloatTensor([0, 1, 0, 0, 0])
computer = torch.FloatTensor([0, 0, 1, 0, 0])
netbook = torch.FloatTensor([0, 0, 0, 1, 0])
book = torch.FloatTensor([0, 0, 0, 0, 1])print(torch.cosine_similarity(dog, cat, dim=0))
print(torch.cosine_similarity(cat, computer, dim=0))
print(torch.cosine_similarity(computer, netbook, dim=0))
print(torch.cosine_similarity(netbook, book, dim=0))tensor(0.)
tensor(0.)
tensor(0.)
tensor(0.)2) 워드임베딩 (Word Emmbedding)
-
단어를 밀집 벡터(dense vector)의 형태로 표현한느 방법을 워드 임베딩이라고 한다.
-
밀집표현은 희소표현과 반대되는 표현으로 사용자가 설정한 값으로 벡터 차원을 맞춘다.
-
이 과정에서 0과 1뿐만이 아니라 실수값을 가지게 됩니다.
-
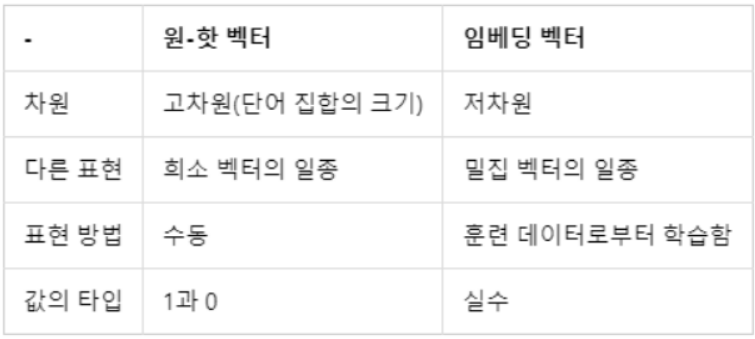
밀집 벡터는 워드 임베딩 과정에서 나온 결과로 임베딩 벡터라고도 한다.
-
희소벡터(원-핫 벡터)와 밀집벡터(임베딩 벡터)의 비교
Ex) 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0] # 이 때 1 뒤의 0의 수는 9995개. 차원은 10,000
Ex) 강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...] # 이 벡터의 차원은 128
3. 워드투벡터 (Word2Vec)
- 단어간 유사도를 반영하기 위해선 단어의 의미를 벡터화해야 한다.
- 이를 위한 대표적인 방법이 워드투벡터(Word2Vec)다.
- 벡터화 후 단어 의미를 연산할 수 있다. 아래는 한국어 단어 연산 사이트 모습이다.
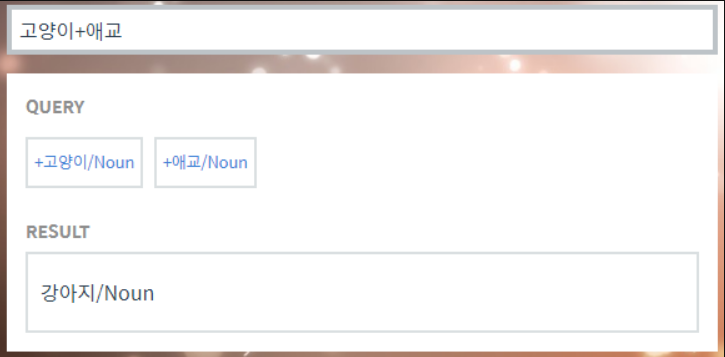
위 사이트에서 다른 한국어 벡터 연산도 수행해보자
- 바보 + 천재 = 엄친아
- 아이유 + 윤아 = 이효리
- 박찬호 - 야구 + 축구 = 호나우두
1) 분산표현
-
분산표현은 분포가설에 기반해 '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'고 가정한다.
-
강아지란 단어는 귀엽다, 예쁘다, 애교 등과 함께 등장하는데 이를 벡터화 한다면 저 단어들은 의미적으로 가까운 단어가 된다.
Ex) 강아지 = [0.2 0.3 0.5 0.7 0.2 ... 중략 ... 0.2]
-
고차원의 희소표현은 각 차원이 분리된 표현방법이라면, 분산표현은 저차원에 단어의 의미를 여러 차원에 분산하여 표현한다.
-
이를 통해 단어 간 유사도를 계산할 수 있다. 기존의 방법의 학습속도를 대폭 개선시킨 Word2Vec이 많이 쓰이고 있다.
2) CBOW (Continuous Bag of Words)
- Word2Vec에는 CBOW와 Skip-Gram 두 가지 방식이 있다.
- CBOW는 주변 단어를 통해 중간에 있는 단어를 예측하고, Skip-Gram은 반대로 중간 단어로 주변 단어를 예측한다.
- 매우 간소화 된 형태의 CBOW를 살펴보자.
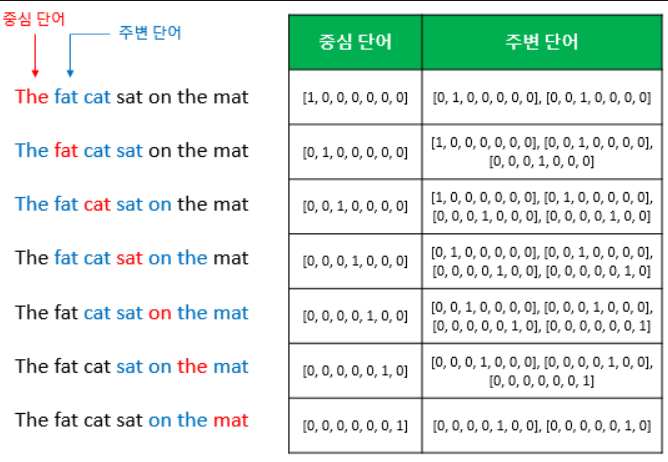
- 앞, 뒤로 몇개의 단어를 볼 지 범위 = 윈도우(Windows)
- 윈도우 크기에 따라 중심 단어를 바꿔가며 학습 데이터 셋을 만드는 방법 = 슬라이딩 윈도우
- 위 그림은 윈도우 크기를 2로 정했을 때, 슬라이딩 윈도우가 어떤 식으로 이루어지면서 데이터셋을 만드는지,
- Word2Vec에서 입력이 각각 어떤 원-핫 벡터가 되는지 보여준다.
3) CBOW 인공 신경망 도식화
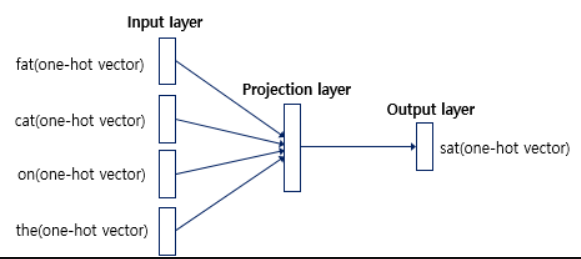
-
입력층에 사용자가 정한 윈도우 크기 범위 안에 있는 단어들의 원-핫 벡터가 들어가고,
-
출력층에 예측하고자 하는 중단 단어의 원-핫 벡터가 들어간다.
-
위 그림에서 보듯이 Word2Vec은 은닉층(투사층)이 1개만 존재하는 얕은 신경망 모델이다.
-
Vord2Vec의 은닉층은 다른 모델과 다르게 활성화 함수가 존재하지 않고 따로 연산담당 층이 있다.
(딥러닝 모델은 다수의 은닉층을 활용하는 심층신경망 모델을 말한다.)
-
이 연산담당층을 룩업 테이블이라는데, 다른 은닉층과 구분하기 위해 투사층이라고 부르기도 한다.
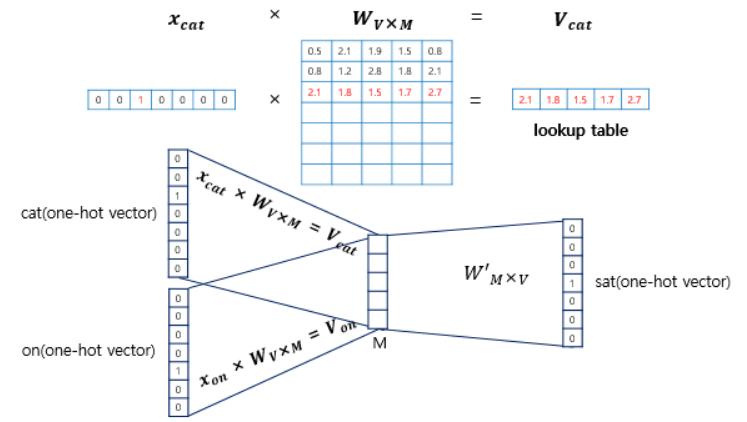
- 입력으로 들어오는 주변 단어의 원-핫 벡터는 X, 단어집합 V 이다.
- 0의 값을 가지는 입력 벡터와 가중치 W 행렬의 곱은 사실 W 행렬의 곱을 그대로 읽어오는 것(lookup)과 동일
- 투사층의 크기(M, 임베딩 벡터의 차원)은 5이며, 단어 집합의 크기는 원-핫 벡터의 차원으로 7이다.
- 입력층과 투사층 사이의 가중치 W1는 V x M 행렬(7x5)이고, 투사층과 출력층 사이의 가중치 W2는 M x V 행렬(5x7)
(주의할 점은 두 가중치 행렬은 동일한 행렬의 전치가 아니라, 서로 다른 행렬이라는 점이다.) - CBOW는 주변 단어를 중심으로 중심 단어를 더 정확히 맞추기 위해 계속 위 두 가중치를 학습하는 구조다.
