네이버 영화리뷰 데이터 학습
import pandas as pd
import matplotlib.pyplot as plt
import urllib.request
from gensim.models.word2vec import Word2Vec
from konlpy.tag import Okt
from tqdm import tqdm# 네이버 영화 리뷰 다운로드
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")('ratings.txt', <http.client.HTTPMessage at 0x7fd135a9cd10>)train_data = pd.read_table('ratings.txt')train_data[:5] # 상위 5개 출력| id | document | label | |
|---|---|---|---|
| 0 | 8112052 | 어릴때보고 지금다시봐도 재밌어요ㅋㅋ | 1 |
| 1 | 8132799 | 디자인을 배우는 학생으로, 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산... | 1 |
| 2 | 4655635 | 폴리스스토리 시리즈는 1부터 뉴까지 버릴께 하나도 없음.. 최고. | 1 |
| 3 | 9251303 | 와.. 연기가 진짜 개쩔구나.. 지루할거라고 생각했는데 몰입해서 봤다.. 그래 이런... | 1 |
| 4 | 10067386 | 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화. | 1 |
print(len(train_data)) # 리뷰 개수 출력200000# NULL 값 존재 유무
print(train_data.isnull().values.any())Truetrain_data = train_data.dropna(how = 'any') # Null 값이 존재하는 행 제거
print(train_data.isnull().values.any()) # Null 값이 존재하는지 확인Falseprint(len(train_data)) # 리뷰 개수 출력199992# 정규 표현식을 통한 한글 외 문자 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
train_data[:5] # 상위 5개 출력| id | document | label | |
|---|---|---|---|
| 0 | 8112052 | 어릴때보고 지금다시봐도 재밌어요ㅋㅋ | 1 |
| 1 | 8132799 | 디자인을 배우는 학생으로 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업... | 1 |
| 2 | 4655635 | 폴리스스토리 시리즈는 부터 뉴까지 버릴께 하나도 없음 최고 | 1 |
| 3 | 9251303 | 와 연기가 진짜 개쩔구나 지루할거라고 생각했는데 몰입해서 봤다 그래 이런게 진짜 영화지 | 1 |
| 4 | 10067386 | 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화 | 1 |
<svg xmlns="http://www.w3.org/2000/svg" height="24px"viewBox="0 0 24 24"
width="24px">
</button> <script>
const buttonEl =
document.querySelector('#df-77e70f87-2701-43b6-823a-e2d9f46cd1d4 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-77e70f87-2701-43b6-823a-e2d9f46cd1d4');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div># 불용어 정의
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# 형태소 분석기 OKT를 사용한 토큰화 작업 (다소 시간 소요)
okt = Okt()
tokenized_data = []
for sentence in tqdm(train_data['document']):
tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_sentence)100%|██████████| 199992/199992 [13:07<00:00, 254.04it/s]# 토큰화 된 상태에선 리뷰 길이 분포 확인 가능
print('리뷰의 최대 길이 :',max(len(review) for review in tokenized_data))
print('리뷰의 평균 길이 :',sum(map(len, tokenized_data))/len(tokenized_data))
plt.hist([len(review) for review in tokenized_data], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()리뷰의 최대 길이 : 72
리뷰의 평균 길이 : 10.716703668146726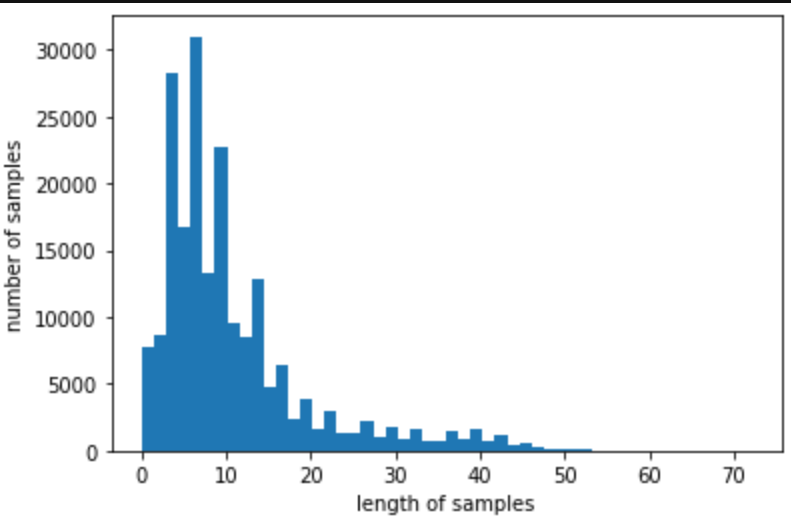
# Word2Vec으로 토큰화 된 네이버 영화리뷰 데이터 학습
from gensim.models import Word2Vec
model = Word2Vec(sentences = tokenized_data, size = 100, window = 5, min_count = 5, workers = 4, sg = 0)# 완성된 임베딩 매트릭스의 크기 확인
model.wv.vectors.shape(16477, 100)print(model.wv.most_similar("최민식")) # 최민식과 유사한 단어 출력[('안성기', 0.8868584632873535), ('한석규', 0.8745899200439453), ('설경구', 0.8583440780639648), ('김명민', 0.8510293960571289), ('오광록', 0.8441793918609619), ('최민수', 0.8384113311767578), ('최강희', 0.8371725082397461), ('황정민', 0.8300768733024597), ('주진모', 0.8284549713134766), ('송강호', 0.8275402784347534)]print(model.wv.most_similar("히어로"))[('슬래셔', 0.8747323751449585), ('무협', 0.8617346286773682), ('호러', 0.853229284286499), ('느와르', 0.8111505508422852), ('블록버스터', 0.8028939962387085), ('물', 0.8025708198547363), ('블랙', 0.7948458194732666), ('판타지', 0.7911989092826843), ('정통', 0.7907636165618896), ('멜로', 0.7863298654556274)]
나무를 심는 사람