이 글은 파이썬 머신러닝 완벽 가이드 책 내용을 기반으로 정리했습니다.
내용출처 : 파이썬 머신러닝 완벽가이드
- LightGBM은 XGBoost의 장점은 계승하고 단점은 보완하는 방슥으로 개발되어 학습시간은 짧고, 예측 성능엔 큰 차이가 없다.
- 하지만 적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉽다. LightGBM의 공식문서에선 10,000건 이하의 데이터세트라고 기술하고 있다.
import lightgbm; print(lightgbm.__version__)3.3.2LightGBM 적용 – 위스콘신 Breast Cancer Prediction
# LightGBM의 파이썬 패키지인 lightgbm에서 LGBMClassifier 임포트
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 워닝 무시
import warnings
warnings.filterwarnings('ignore')1. 데이터 로드 및 확인
dataset = load_breast_cancer()
ftr = dataset.data # fitrue
target = dataset.target
# feature, target data의 앞 3개만 확인
print(ftr.shape)
print(ftr[:3], '\n')
print(target[:3])(569, 30)
[[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-01
1.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+02
6.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+01
1.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-01
4.601e-01 1.189e-01]
[2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-02
7.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+01
5.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+01
2.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-01
2.750e-01 8.902e-02]
[1.969e+01 2.125e+01 1.300e+02 1.203e+03 1.096e-01 1.599e-01 1.974e-01
1.279e-01 2.069e-01 5.999e-02 7.456e-01 7.869e-01 4.585e+00 9.403e+01
6.150e-03 4.006e-02 3.832e-02 2.058e-02 2.250e-02 4.571e-03 2.357e+01
2.553e+01 1.525e+02 1.709e+03 1.444e-01 4.245e-01 4.504e-01 2.430e-01
3.613e-01 8.758e-02]]
[0 0 0]dataset.feature_namesarray(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')2. 학습
# train, test 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(ftr, target, test_size=0.2, random_state=156 )
# 앞서 XGBoost와 동일하게 n_estimators는 400 설정.
lgbm_wrapper = LGBMClassifier(n_estimators=400)
# LightGBM도 XGBoost와 동일하게 조기 중단 수행 가능.
evals = [(X_test, y_test)] # 원래 evals 데이터는 검증 데이터 셋을 별도로 둬야되는데 여기서는 테스트 데이터 사용
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)[1] valid_0's binary_logloss: 0.565079
[2] valid_0's binary_logloss: 0.507451
[3] valid_0's binary_logloss: 0.458489
[4] valid_0's binary_logloss: 0.417481
[5] valid_0's binary_logloss: 0.385507
[6] valid_0's binary_logloss: 0.355773
[7] valid_0's binary_logloss: 0.329587
[8] valid_0's binary_logloss: 0.308478
[9] valid_0's binary_logloss: 0.285395
[10] valid_0's binary_logloss: 0.267055
[11] valid_0's binary_logloss: 0.252013
[12] valid_0's binary_logloss: 0.237018
[13] valid_0's binary_logloss: 0.224756
[14] valid_0's binary_logloss: 0.213383
[15] valid_0's binary_logloss: 0.203058
[16] valid_0's binary_logloss: 0.194015
[17] valid_0's binary_logloss: 0.186412
[18] valid_0's binary_logloss: 0.179108
[19] valid_0's binary_logloss: 0.174004
[20] valid_0's binary_logloss: 0.167155
[21] valid_0's binary_logloss: 0.162494
[22] valid_0's binary_logloss: 0.156886
[23] valid_0's binary_logloss: 0.152855
[24] valid_0's binary_logloss: 0.151113
[25] valid_0's binary_logloss: 0.148395
[26] valid_0's binary_logloss: 0.145869
[27] valid_0's binary_logloss: 0.143036
[28] valid_0's binary_logloss: 0.14033
[29] valid_0's binary_logloss: 0.139609
[30] valid_0's binary_logloss: 0.136109
[31] valid_0's binary_logloss: 0.134867
[32] valid_0's binary_logloss: 0.134729
[33] valid_0's binary_logloss: 0.1311
[34] valid_0's binary_logloss: 0.131143
[35] valid_0's binary_logloss: 0.129435
[36] valid_0's binary_logloss: 0.128474
[37] valid_0's binary_logloss: 0.126683
[38] valid_0's binary_logloss: 0.126112
[39] valid_0's binary_logloss: 0.122831
[40] valid_0's binary_logloss: 0.123162
[41] valid_0's binary_logloss: 0.125592
[42] valid_0's binary_logloss: 0.128293
[43] valid_0's binary_logloss: 0.128123
[44] valid_0's binary_logloss: 0.12789
[45] valid_0's binary_logloss: 0.122818
[46] valid_0's binary_logloss: 0.12496
[47] valid_0's binary_logloss: 0.125578
[48] valid_0's binary_logloss: 0.127381
[49] valid_0's binary_logloss: 0.128349
[50] valid_0's binary_logloss: 0.127004
[51] valid_0's binary_logloss: 0.130288
[52] valid_0's binary_logloss: 0.131362
[53] valid_0's binary_logloss: 0.133363
[54] valid_0's binary_logloss: 0.1332
[55] valid_0's binary_logloss: 0.134543
[56] valid_0's binary_logloss: 0.130803
[57] valid_0's binary_logloss: 0.130306
[58] valid_0's binary_logloss: 0.132514
[59] valid_0's binary_logloss: 0.133278
[60] valid_0's binary_logloss: 0.134804
[61] valid_0's binary_logloss: 0.136888
[62] valid_0's binary_logloss: 0.138745
[63] valid_0's binary_logloss: 0.140497
[64] valid_0's binary_logloss: 0.141368
[65] valid_0's binary_logloss: 0.140764
[66] valid_0's binary_logloss: 0.14348
[67] valid_0's binary_logloss: 0.143418
[68] valid_0's binary_logloss: 0.143682
[69] valid_0's binary_logloss: 0.145076
[70] valid_0's binary_logloss: 0.14686
[71] valid_0's binary_logloss: 0.148051
[72] valid_0's binary_logloss: 0.147664
[73] valid_0's binary_logloss: 0.149478
[74] valid_0's binary_logloss: 0.14708
[75] valid_0's binary_logloss: 0.14545
[76] valid_0's binary_logloss: 0.148767
[77] valid_0's binary_logloss: 0.149959
[78] valid_0's binary_logloss: 0.146083
[79] valid_0's binary_logloss: 0.14638
[80] valid_0's binary_logloss: 0.148461
[81] valid_0's binary_logloss: 0.15091
[82] valid_0's binary_logloss: 0.153011
[83] valid_0's binary_logloss: 0.154807
[84] valid_0's binary_logloss: 0.156501
[85] valid_0's binary_logloss: 0.158586
[86] valid_0's binary_logloss: 0.159819
[87] valid_0's binary_logloss: 0.161745
[88] valid_0's binary_logloss: 0.162829
[89] valid_0's binary_logloss: 0.159142
[90] valid_0's binary_logloss: 0.156765
[91] valid_0's binary_logloss: 0.158625
[92] valid_0's binary_logloss: 0.156832
[93] valid_0's binary_logloss: 0.154616
[94] valid_0's binary_logloss: 0.154263
[95] valid_0's binary_logloss: 0.157156
[96] valid_0's binary_logloss: 0.158617
[97] valid_0's binary_logloss: 0.157495
[98] valid_0's binary_logloss: 0.159413
[99] valid_0's binary_logloss: 0.15847
[100] valid_0's binary_logloss: 0.160746
[101] valid_0's binary_logloss: 0.16217
[102] valid_0's binary_logloss: 0.165293
[103] valid_0's binary_logloss: 0.164749
[104] valid_0's binary_logloss: 0.167097
[105] valid_0's binary_logloss: 0.167697
[106] valid_0's binary_logloss: 0.169462
[107] valid_0's binary_logloss: 0.169947
[108] valid_0's binary_logloss: 0.171
[109] valid_0's binary_logloss: 0.16907
[110] valid_0's binary_logloss: 0.169521
[111] valid_0's binary_logloss: 0.167719
[112] valid_0's binary_logloss: 0.166648
[113] valid_0's binary_logloss: 0.169053
[114] valid_0's binary_logloss: 0.169613
[115] valid_0's binary_logloss: 0.170059
[116] valid_0's binary_logloss: 0.1723
[117] valid_0's binary_logloss: 0.174733
[118] valid_0's binary_logloss: 0.173526
[119] valid_0's binary_logloss: 0.1751
[120] valid_0's binary_logloss: 0.178254
[121] valid_0's binary_logloss: 0.182968
[122] valid_0's binary_logloss: 0.179017
[123] valid_0's binary_logloss: 0.178326
[124] valid_0's binary_logloss: 0.177149
[125] valid_0's binary_logloss: 0.179171
[126] valid_0's binary_logloss: 0.180948
[127] valid_0's binary_logloss: 0.183861
[128] valid_0's binary_logloss: 0.187579
[129] valid_0's binary_logloss: 0.188122
[130] valid_0's binary_logloss: 0.1857
[131] valid_0's binary_logloss: 0.187442
[132] valid_0's binary_logloss: 0.188578
[133] valid_0's binary_logloss: 0.189729
[134] valid_0's binary_logloss: 0.187313
[135] valid_0's binary_logloss: 0.189279
[136] valid_0's binary_logloss: 0.191068
[137] valid_0's binary_logloss: 0.192414
[138] valid_0's binary_logloss: 0.191255
[139] valid_0's binary_logloss: 0.193453
[140] valid_0's binary_logloss: 0.196969
[141] valid_0's binary_logloss: 0.196378
[142] valid_0's binary_logloss: 0.196367
[143] valid_0's binary_logloss: 0.19869
[144] valid_0's binary_logloss: 0.200352
[145] valid_0's binary_logloss: 0.19712
LGBMClassifier(n_estimators=400)3. 예측
preds = lgbm_wrapper.predict(X_test)
# 1 예측 확률값 3개만 확인
pred_proba = lgbm_wrapper.predict_proba(X_test)[:, 1]
pred_proba[:3]array([0.60514473, 0.00747978, 0.94351324])4. 평가
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
# 성능 평가 함수
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc), '\n')get_clf_eval(y_test, preds, pred_proba)오차 행렬
[[33 4]
[ 1 76]]
정확도: 0.9561, 정밀도: 0.9500, 재현율: 0.9870, F1: 0.9682, AUC:0.9905
-> 하이퍼 파라미터 튜닝이 안되어 있어서 XGBoost보다 성능은 다소 안좋게 나온 상태.
(4.6 XGBoost - 정확도: 0.9737, 정밀도: 0.9744, 재현율: 0.9870, F1: 0.9806, AUC:0.9951)
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
# 사이킷런 래퍼 클래스를 입력해도 무방.
plot_importance(lgbm_wrapper, ax=ax)<AxesSubplot:title={'center':'Feature importance'}, xlabel='Feature importance', ylabel='Features'>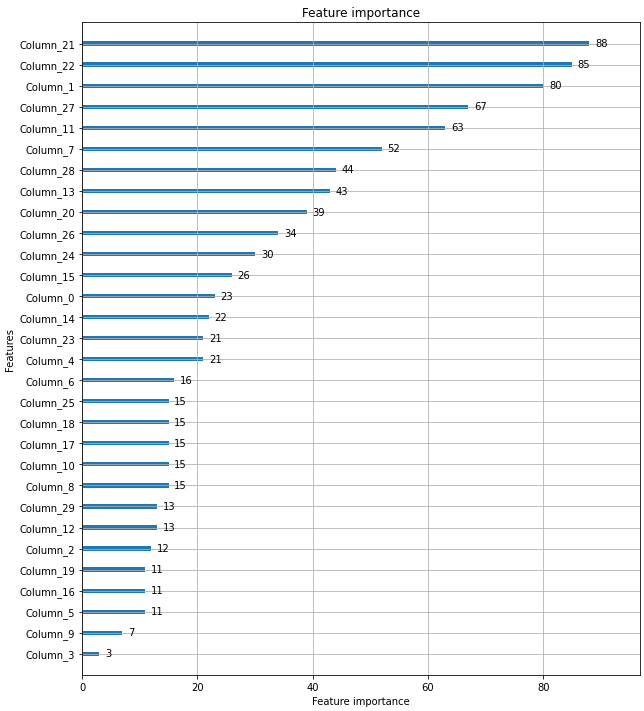
-> feature가 넘파이의 ndarray이므로, 이름이 feature 순서로 나옴
print(len(dataset.feature_names))
print(dataset.feature_names)30
['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness' 'mean compactness' 'mean concavity'
'mean concave points' 'mean symmetry' 'mean fractal dimension'
'radius error' 'texture error' 'perimeter error' 'area error'
'smoothness error' 'compactness error' 'concavity error'
'concave points error' 'symmetry error' 'fractal dimension error'
'worst radius' 'worst texture' 'worst perimeter' 'worst area'
'worst smoothness' 'worst compactness' 'worst concavity'
'worst concave points' 'worst symmetry' 'worst fractal dimension']
나무를 심는 사람