Amazon EC2(Elastic Compute Cloud)
: 아마존 웹 서비스(AWS)에서 제공하는 클라우드 컴퓨팅(가상 서버) 서비스
*클라우드 컴퓨팅: 인터넷(클라우드)를 통해 서버, 스토리지, 데이터베이스 등의 컴퓨터 서비스를 제공하는 서비스
- 필요에 따라 성능, 용량을 자유롭게 조절할 수 있고, 사용한 만큼만 비용을 지불한다.
EC2 사용 시 이점
- 구성하는 데 필요한 시간이 짧다.
만약 PC를 구매한다면 구매부터 받기까지 시간이 필요하지만, EC2 서비스는 몇 번의 클릭만으로 PC를 구성할 수 있다. - 필요한 용도에 따라 다양한 운영체제를 선택할 수 있다.
e.g. Windows, ubuntu, Linux, redhat, suse ... - CPU, RAM, 용량까지 원하는대로 구성할 수 있다.
인스턴스(Instance)
: AWS에서 빌리는 컴퓨터를 인스턴스(Instance)라고 한다.
- EC2는 컴퓨터를 한 대 빌리는 것이므로, 컴퓨터로 할 수 있는 모든 일을 할 수 있다.
- 빌린 컴퓨터는 아마존이 전 세계에 만들어놓은 데이터 센터(인프라)에 만들어져 있기 때문에, 컴퓨터를 조작하기 위해 네트워크(인터넷)을 사용한다는 차이점만 있을 뿐, 일반적인 컴퓨터와 다른 점이 없다.

AMI(Amazon Machine Image)
: 인스턴스를 생성하는 데 필요한 소프트웨어 구성(운영 체제, 애플리케이션 서버, 애플리케이션)이 기재된 템플릿
AWS에서 빌릴 PC는 사용 용도에 맞게 운영체제, 런타임 등이 구성된 Setting을 선택할 수 있다.
- 인스턴스는 선택한 AMI를 토대로 구성된다.
- AWS는 다양한 AMI 세팅이 준비되어 있으며, 이외에도 필요에 따라 직접 AMI를 구성할 수도 있다.
- 이미지 종류는 단순히 운영체제(Windows, ubuntu, Linux 등)만 깔려있는 템플릿을 선택할 수도 있고, 아예 특정 런타임이 설치되어 있는 템플릿(ubuntu + Node.js, Window + JVM 등)이 제공되기도 한다.
EC2 인스턴스 생성
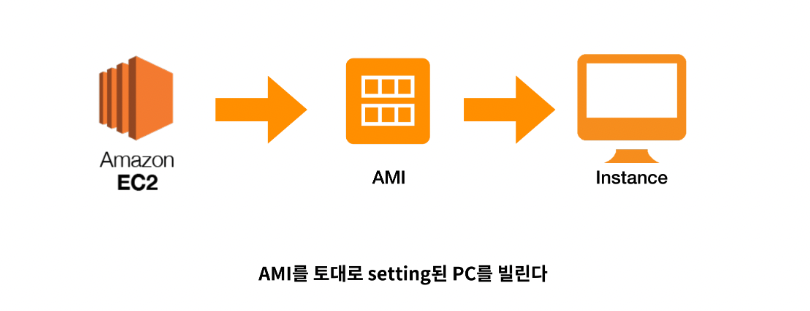
AWS EC2 인스턴스를 생성한다는 것은 AMI를 토대로 운영체제, CPU, RAM 혹은 런타임 등이 구성된 컴퓨터를 빌리는 것이다.
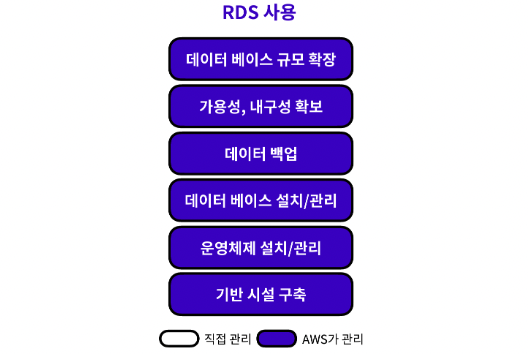
RDS(Relational Database Service)
: 클라우드에서 간편하게 데이터베이스를 설치, 운영 및 확장할 수 있는 AWS에서 제공하는 관계형 데이터베이스 서비스
왜 RDS를 사용해야 할까?
EC2 인스턴스에 MySQL과 같은 관계형 데이터베이스 엔진을 설치하면 굳이 RDS를 사용할 필요가 없지 않을까?
데이터 베이스만 따로 분리해서 서비스를 이용해야 할 이유가 있을까?
인스턴스에 데이터베이스를 설치하는 경우
- EC2 인스턴스에 데이터베이스를 설치하여 데이터를 관리하면, 사용자가 일일히 데이터베이스 엔진의 설치와 버전 관리, 데이터 백업 등을 해야 한다.
- 게다가, 가용성과 내구성이 확보되지 않기 때문에, 데이터베이스에 저장된 데이터가 유실될 수도 있고, 후에 필요에 따라 데이터베이스의 규모를 확장하는 것도 어렵다.
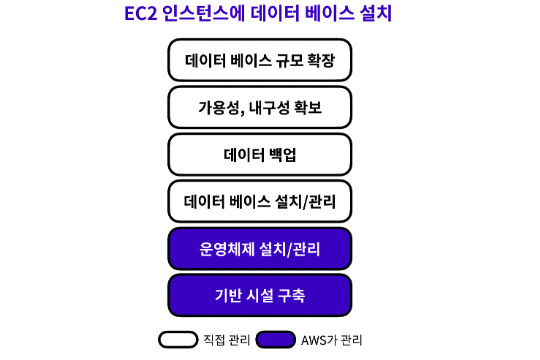
RDS를 사용하는 경우
- 하지만, RDS를 이용하면 데이터베이스 유지보수와 관련된 일들을 RDS에서 전적으로 자동 관리한다.
- 사용자가 해야할 일은 초기 설정을 제외하고 데이터베이스에 저장된 데이터를 관리하는 일 밖에 없다.
- 추가적으로, RDS를 이용하면 다양한 데이터베이스 엔진 선택지를 제공한다.
e.g. Oracle, MySQL, Amazon Aurora, MariaDB, SQL Server, PostgreSQL 등
S3(Simple Storage Service)
: AWS에서 제공하는 클라우드 스토리지 서비스
S3 사용의 이점
1. 높은 확장성
스토리지의 용량을 무한히 확장/축소할 수 있으며, 사용한 만큼만 비용을 지불하면 된다.
2. 강력한 내구성
저장된 파일을 유실할 가능성이 거의 없다.
3. 99.99%의 가용성 보장
가용성이 높다는 것은 스토리지에 저장된 파일을 정상적으로 사용할 수 있는 시간이 길다는 뜻이다.
지금까지 AWS의 EC2, RDS, S3에 대해서 알아보았는데, 해당 서비스들은 공통적으로 높은 가용성과 높은 내구성을 보장하고 있다.
AWS는 어떻게 이렇게 높은 가용성과 내구성을 보장할 수 있는걸까?
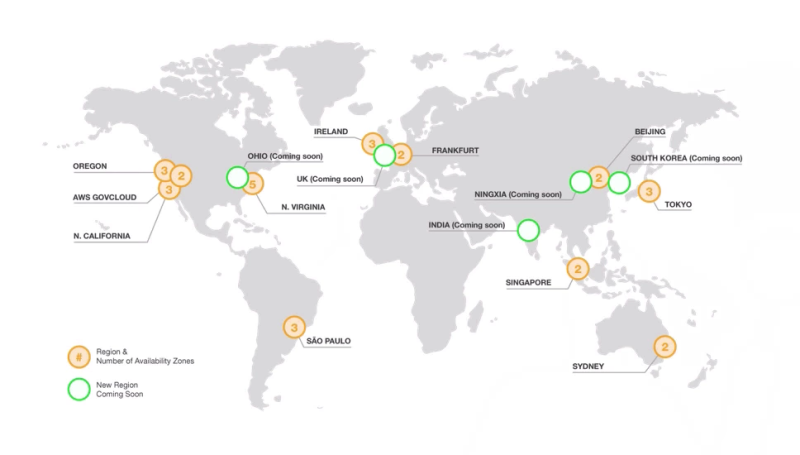
리전(Region)
: AWS에서 클라우드 서버를 제공하기 위해서 운영하는 물리적인 서버의 위치
가용 영역(Availability Zone)
: 각 리전 안에 존재하는 데이터 센터(IDC, Internet Data Center)
가용 영역은 각각 개별적인 위치에 떨어져서 존재하기 때문에, 한 곳이 재난이나 사고로 가동이 불가능해져도, 다른 가용 영역에 백업해놓은 데이터를 활용하여 문제없이 서버가 작동하게 할 수 있다.
4. 다양한 스토리지 클래스를 제공
저장소를 어떤 목적으로 활용할지에 따라 효율적으로 선택할 수 있는 스토리지 클래스가 달라진다.
Standard 클래스 : 데이터에 자주 액세스해야 할 경우 사용
- 데이터에 빠른 속도로 접근할 수 있고, 데이터 액세스 요청에 대한 처리 속도가 빠르다.
- 대신 보관 비용이 높기 때문에, 데이터를 오래 보관하는 목적으로는 좋지 않다.
Glacier 클래스 : 장기적인 보관 목적으로 사용할 경우 사용
- 저장된 데이터에 액세스하는 속도는 느리지만, 데이터를 보관하는 비용이 매우 저렴하다.
이외에도 Standard-IA, One Zone-IA, S3 Glacier Deep Archive 등 다양한 스토리지 클래스가 존재하며, 사용자의 목적에 따라 스토리지 클래스를 사용할 수 있다.
5. 정적 웹 사이트 호스팅 가능
- 정적 파일 : 서버의 개입 없이 클라이언트에게 제공될 수 있는 파일
↔ 동적 파일 : 클라이언트가 서버에게 요청을 보내면, 서버가 요청에 맞추어 그 자리에서 생성한 파일 - 웹 호스팅(Web Hosting) : 서버의 한 공간을 빌려주어 웹 사이트의 배포, 운영이 가능하게 만들어주는 서비스
- S3에서는 버킷을 통해 정적 웹 사이트 호스팅이 가능하다.
버킷(Bucket)
: 파일을 담는 바구니, 즉 파일을 저장하는 최상위 디렉토리
- 무한한 양의 파일을 저장할 수 있다.
- 버킷의 이름은 버킷이 속해있는 리전(Region)에서 유일해야 한다.
- 버킷의 정책을 생성하여 액세스 권한을 부여할 수 있다.
객체
: 버킷에 담기는 파일
S3에서 버킷에 담기는 파일을 왜 객체라고 부를까?
➡️ S3에서 저장소에 데이터를 저장할 때 키-값 페어 형식으로 데이터를 저장하기 때문이다.
- S3에 저장되는 객체는 파일과 메타데이터로 구성된다.
- 파일
: 파일은키-값페어 형식으로 데이터를 저장한다.- 파일의 키 : 각각의 객체를 고유하게 만들어주는 식별자 역할을 한다. 파일의 키를 이용해 원하는 객체를 검색할 수 있다.
- 파일의 값 : 실제 데이터를 저장한다.
- 메타데이터
: 객체를 설명하는 데이터
객체의 생성일, 크기, 유형과 같은 객체에 대한 정보가 담긴 데이터
- 모든 객체는 고유한 URL 주소를 가지고 있다.
URL 주소는http://[버킷의 이름].S3.amazonaws.com/[객체의 키]형태를 띄며, URL 주소를 통해서도 원하는 데이터에 접근할 수 있다.