
빅데이터를 다룰 때 필요한 hive는 Hadoop 을 통해 구동된다. 즉 어차피 둘 다 깔아야 하는데.. 문제는 Hadoop이 리눅스 환경에 맞춰져 있어서 Windows에 깔기 버겁다는 것.
우분투를 깔아 바보야
물론 언젠가는 리눅스 환경에서 하게 될 것이지만 당장의 귀차니즘을 해결하고자 구글링을 해본 결과 능력자 분들이 미리 빌드해놓은 파일이 돌아다니고 있었다.
이 포스트에서는 그러한 능력자 분들의 가이드라인을 따라가다가 막혔던 점들을 중점으로 소개하고자 한다.
1. Windows 10에 hadoop 2.6.0 설치
위 링크에 들어가면 빌드 된 hadoop 파일과 더불어 자세한 설치 방법을 설명하고 있다. 참고로 2.6.0을 다루는 이유는 당연히 기타 maven이니 뭐니 data 폴더를 만들라느니 다른 귀찮은 과정을 생략하기 위해서다.
하라는 데로 고대로~ 따라가면 되는데. 정말 불친절하시게도 이 포스트 뿐 아니라 어디에서도 namenode 포멧 과정을 아래 줄로만 딱 설명하고 지나친다.
hdfs namenode -format
조금만 머리를 굴려서 찾아보니 bin 폴더에 hdfs가 떡하니 있다. 그냥 cmd 킨 다음 cd C:\hadoop-2.6.0\bin 하고 위 명령어 입력하면 되는 것.
그냥 cmd 킨 다음 cd C:\hadoop-2.6.0\bin 하고 위 명령어 입력하면 되는 것.
이런 간단명료한 상황에서도 에러는 나타난다.
java.lang.ExceptionInInitializerError
라고 뜨길래 stackoverflow를 열심히 뒤졌더니 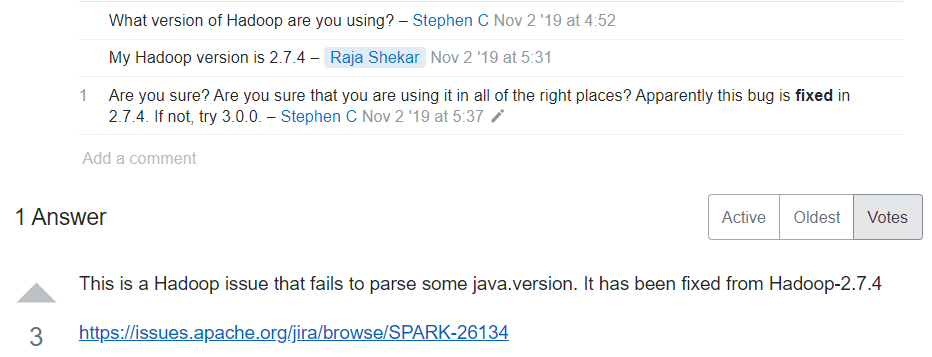
위와 같이 예전부터 있던 issue이므로 2.7.4 혹은 3버전 이상을 권장한다는 건방진 답변들 뿐이었다.
여러모로 귀찮은 버전을 다시 깔으라고? 그럴 순 없지
환경변수들을 다시 꼼꼼히 확인해보니 java --version으로 나타나는 현 자바 버전은 잘못 설정된 것이었다. java 16? 으로 돼있었는데 정작 path에서는 jdk 1.8.0을 가리키고 있더라...
그래서 hadoop-env.cmd 에 있는 JAVA_HOME과 환경 변수의 JAVA_HOME을 1.8.0으로 고쳤다.
자 이제 sbin에서 start-all.cmd 라는 커맨드를 실행시켜보자!
c:\Program file\은 실행할 수 없습니다.
파일 'hadoop'을 찾을 수 없습니다.
파일 'yarn'을 찾을 수 없습니다.
곱게 되겠지란 기대를 상큼하게 박살내주신다.
우선 첫 번째 문제는 간단하다.
set JAVA_HOME="C:\Program Files\Java\jdk1.8.0_221"
->
set JAVA_HOME=C:\Program" "Files\Java\jdk1.8.0_221
이렇게 수정하면 공백문자로 인한 오류가 사라진다.
문제는 두 번째인데... 이 역시도 환경 변수 문제였다. HADOOP_HOME 을 유저 환경변수와 시스템 환경 변수에 각각 bin 폴더를 가리키게끔 설정하면 해결된다!
자세한 것은 구글에 cannot find hadoop on windows로 검색해서 나온 답변들을 참고하자. (필자는 위 링크 방법으로 해결함)
2. Windows 10에 Hive 2.1.0 설치 & derby 설치
이 역시 유튜브에 어떤 천사분이 친히 다운로드 링크와 더불어 상세한 설치방식을 가르쳐주신다.
위에서 하둡을 제대로 깔았다면 여기서 하라는 것을 토시하나 틀리지 않고 진행하자.
.
.
.
.
그렇게 했는데? 이제 마지막 단계로 hive 딱! 입력하는 순간 오류가 난다.
Missing hadoop installation: hadoop home 위치~~
그러나 앞선 개고생으로 깨우침을 얻었던 나는 당황하지 않고 환경변수를 살펴보았다.
그리고 모두 문제가 없음을 알고 현타가 왔다.
"여기까지 했는데 막혀서 다시 리눅스 가상머신 깔고 새 인생 새 시작 해봐?"
라는 쓰디쓴 유혹이 시작되려던 찰나 hive를 실행시키는 본체 파일을 뜯어 hadoop home이 어떻게 언급되어있는지 살펴보았다.
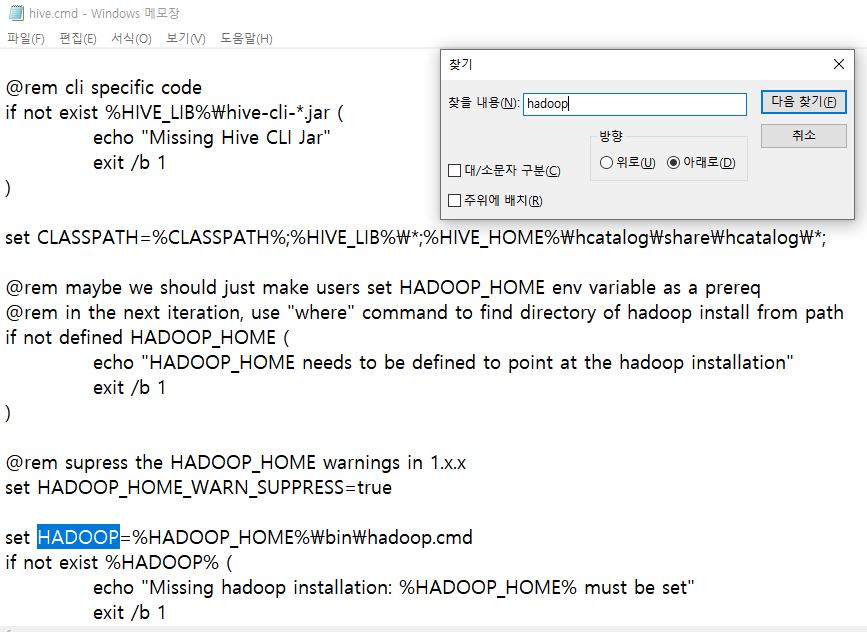
역시... %HADOOP_HOME%\bin\hadoop.cmd 라니 아까 HADOOP_HOME을 bin으로 설정하지 않았던가! (아닌가? 내가 실수한 거면 생쇼였던 것으로...)
나는 과감하게 \bin을 없애버렸다. 그렇지 않으면 bin\bin\이 될터이니.. hadoop.cmd를 못찾는게 당연했다.
- 주의 : 여기까지 따라왔는데 hive를 하고나서 java error가 뜬다면 기존의 JAVA_HOME과 지정된 jdk를 1.8.0으로 바꿔주자
(hadoop-env.cmd의 JAVA_HOME도 당연히 고쳐야 한다.)
고렇게 실행하면 hive가 잘 작동한다.
이제 시작이거늘... 벌써 하기 싫어진다.
시작이 반이라고 했다.
반정도 했으면 오늘은 이만 자자
ㅂㅂ
3. 실행 command
1. hadoop 실행
cd C:\hadoop-2.6.0\sbin
start-all.cmd
2. derby 실행
cd C:\derby\bin
startNetworkServer -h 0.0.0.0
3. hive 실행
cd C:\hive\bin
hive
