
오늘 수강한 강의 - EDA 서울시 CCTV 현황 데이터 분석 (01 ~ 11)
01 ~ 03 서울시 CCTV 현황 분석 데이터 읽기
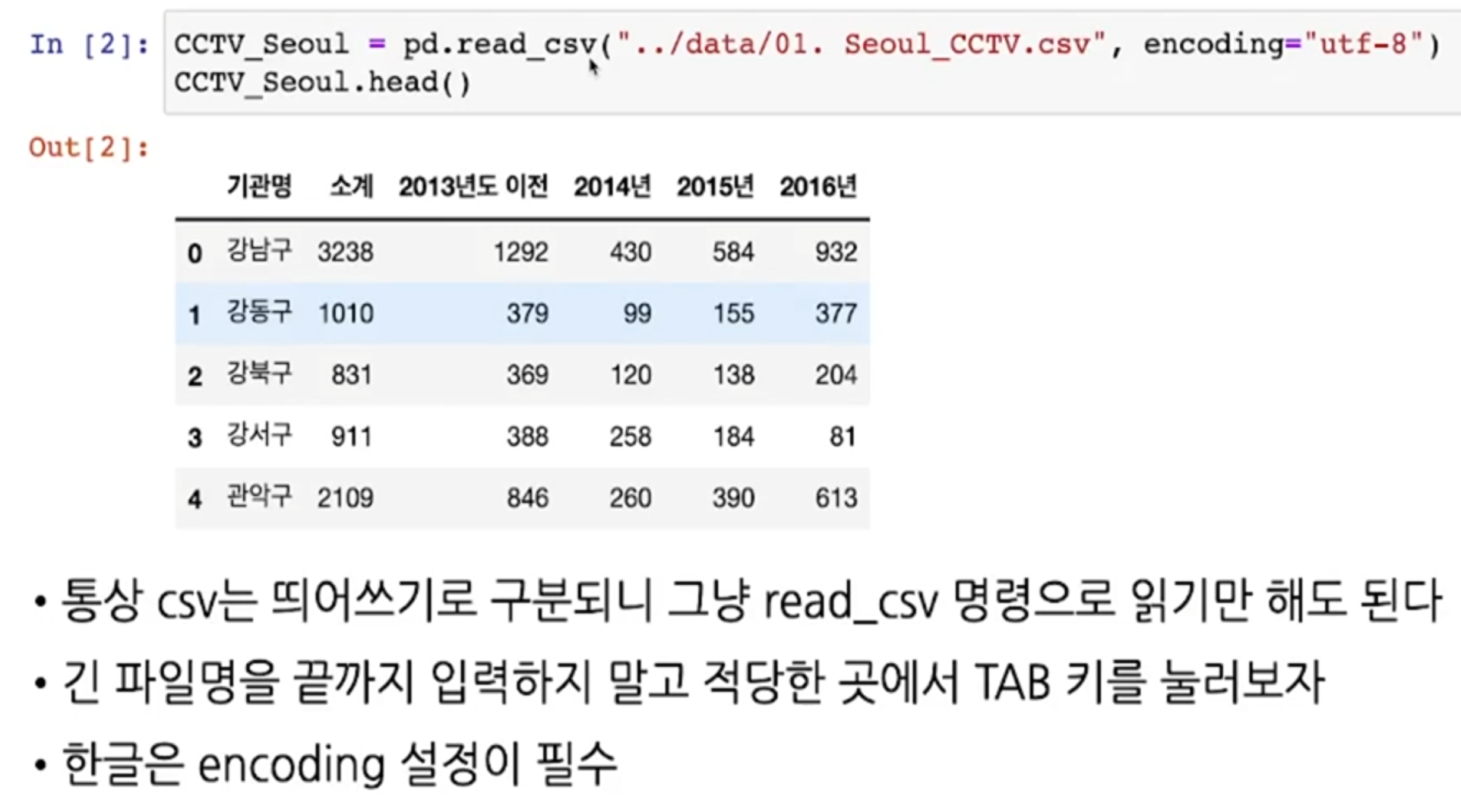
Pandas에서 csv 파일 읽기
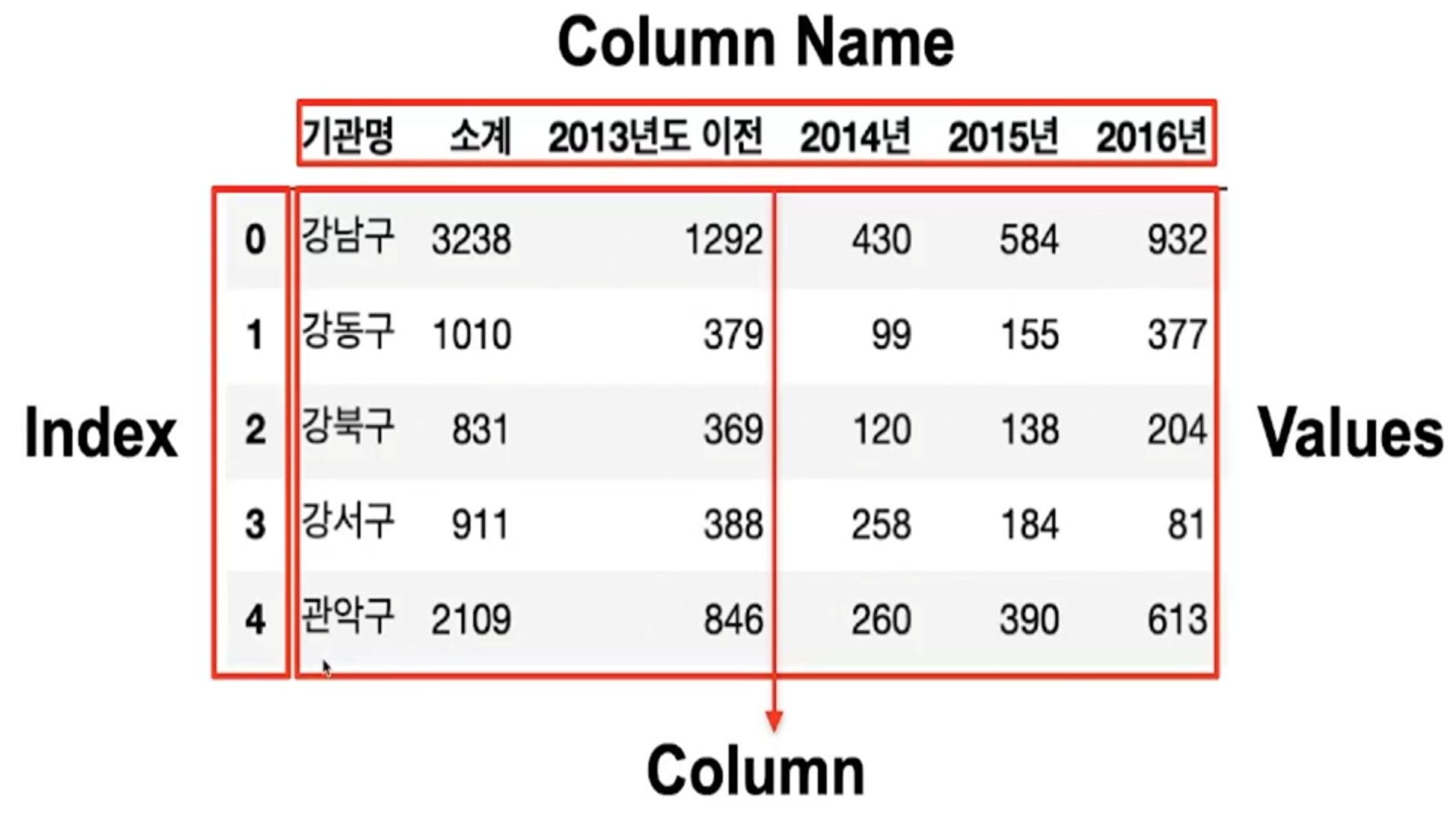
Pandas DataFrame의 구조
column 이름 조회

Pandas에서 엑셀 파일 읽기
- Pandas에서는 셀 병합이 이루어지지 않음
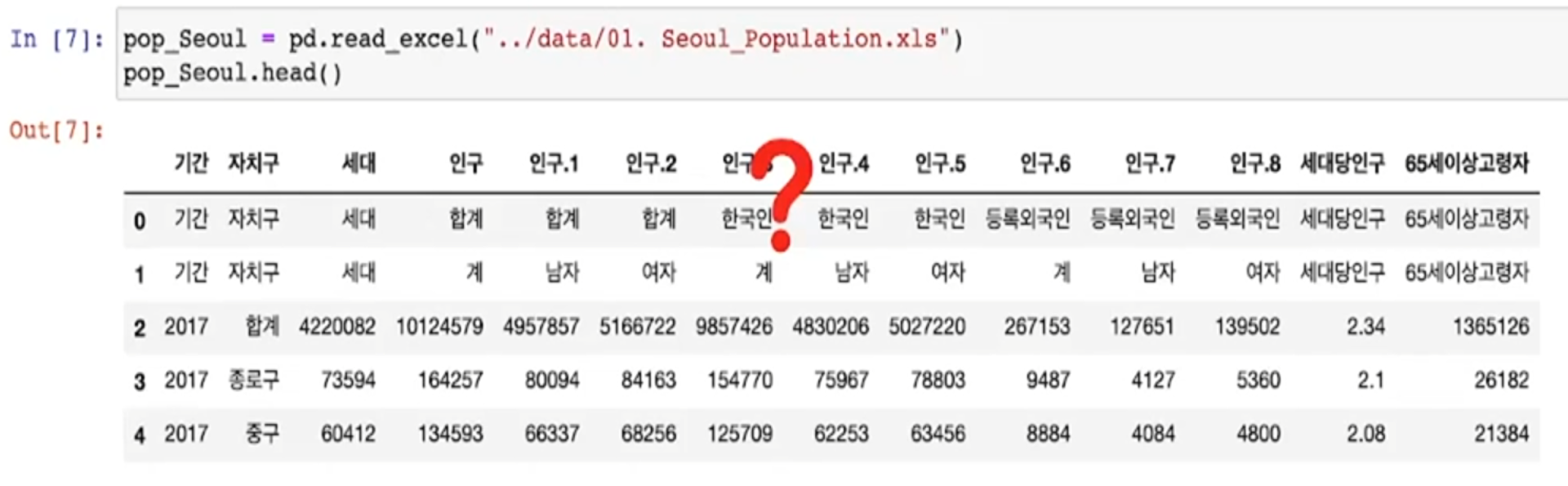
- 액셀 설정
- 자료를 읽기 시작할 행(header)을 지정
ex) header=2- 읽어올 엑셀의 컬럼을 지정(usecols)
ex) usecols="B, D, G, J, N"
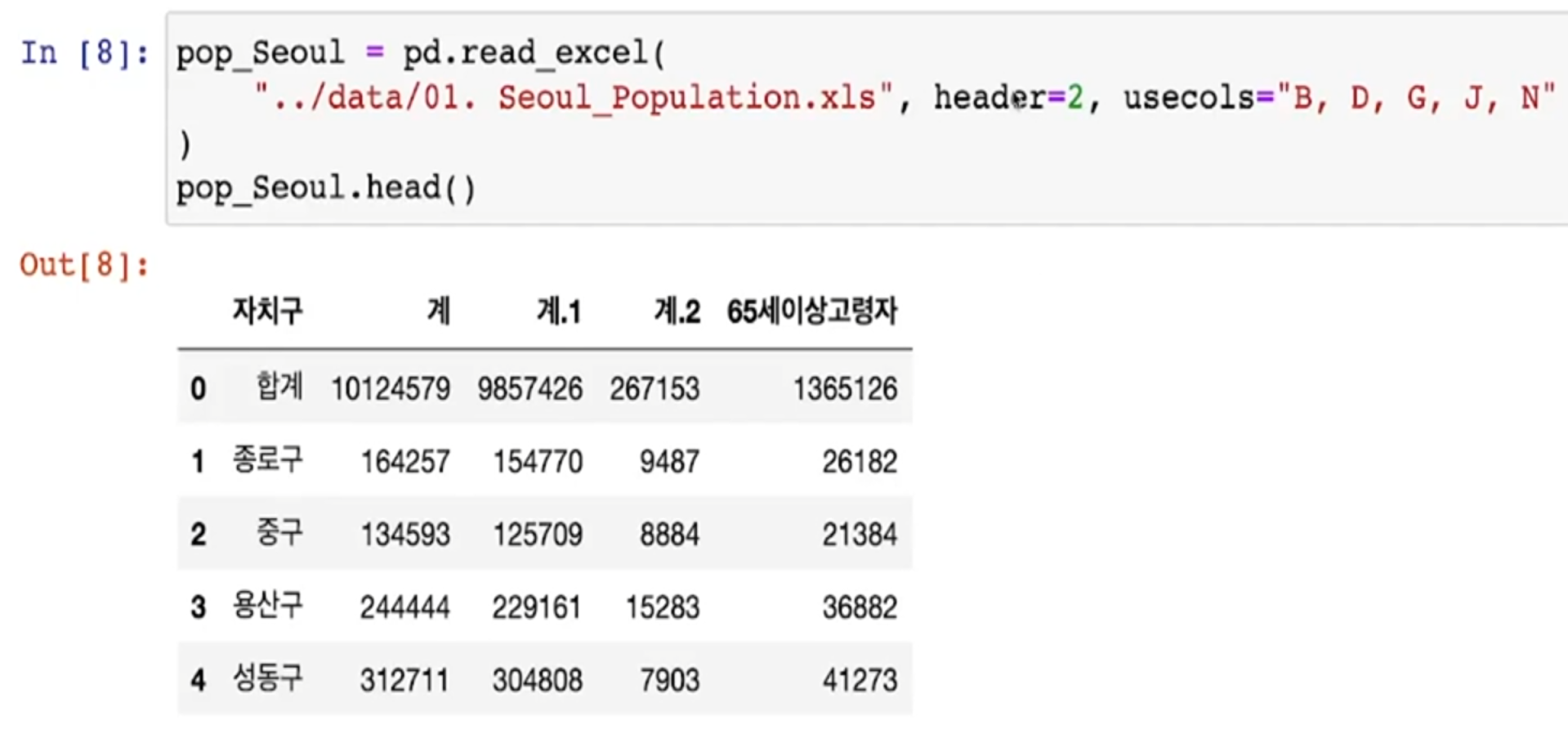
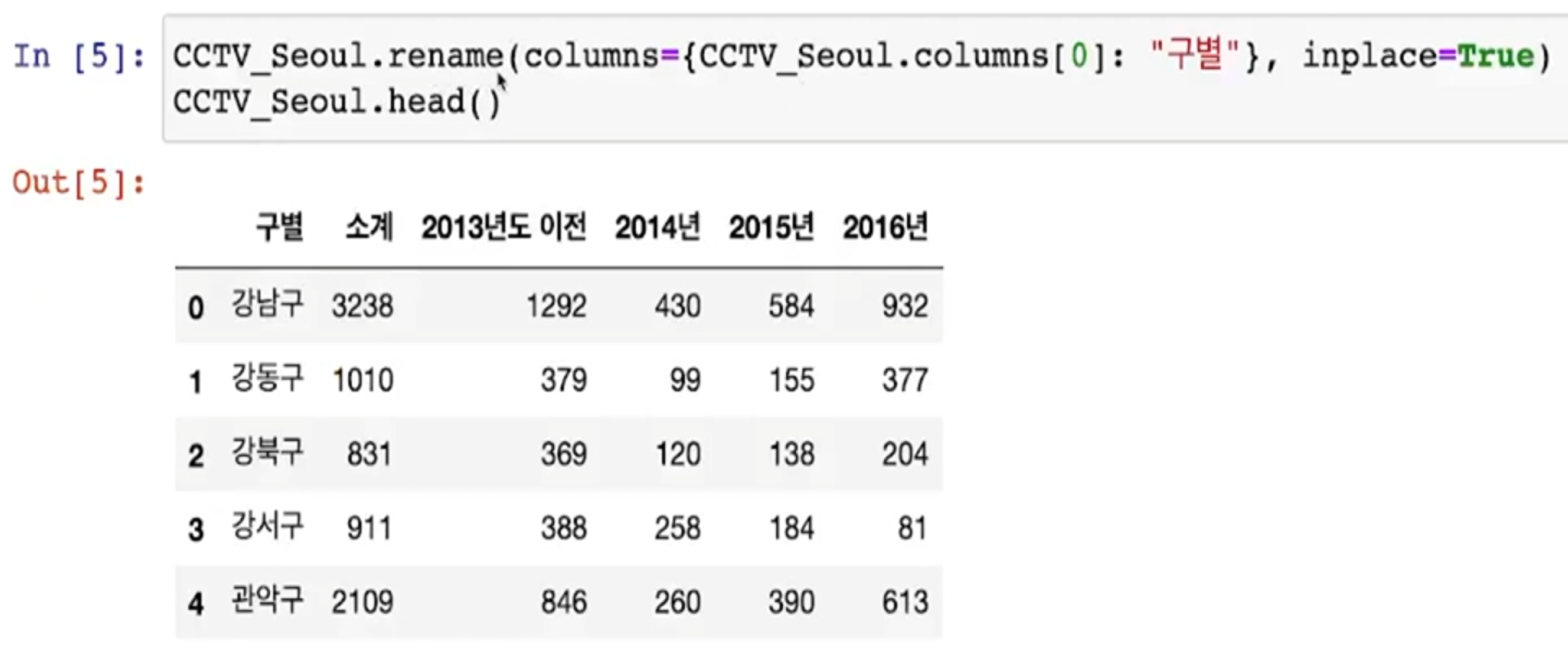
- 컬럼 이름을 바꾸기

04 ~ 06 서울시 CCTV 현황 분석 Pandas 기초
Pandas Basic
pd, np
- pandas는 통상 pd로 import한다
- 수치해석적 함수가 많은 numpy는 통상 np로 import 한다

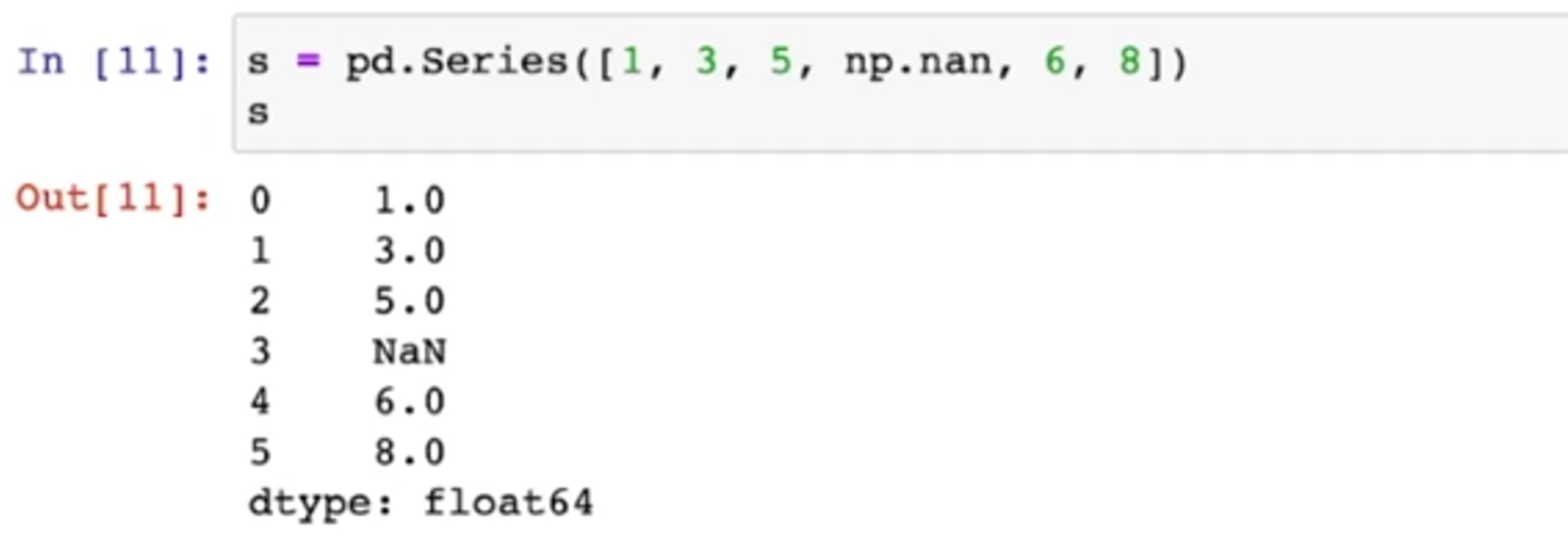
Series
- Pandas의 데이터형을 구성하는 기본은 Series이다
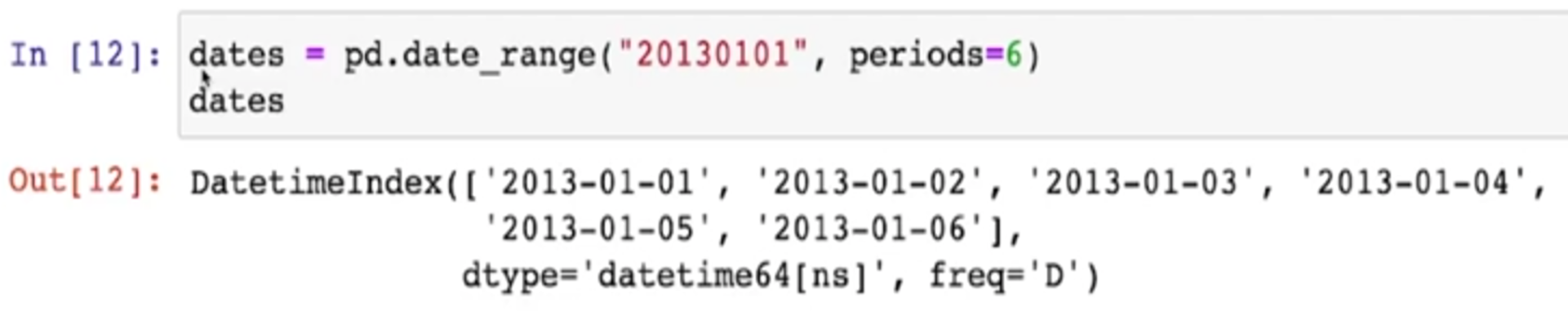
date_range
- 날짜(시간)를 이용할 수 있다
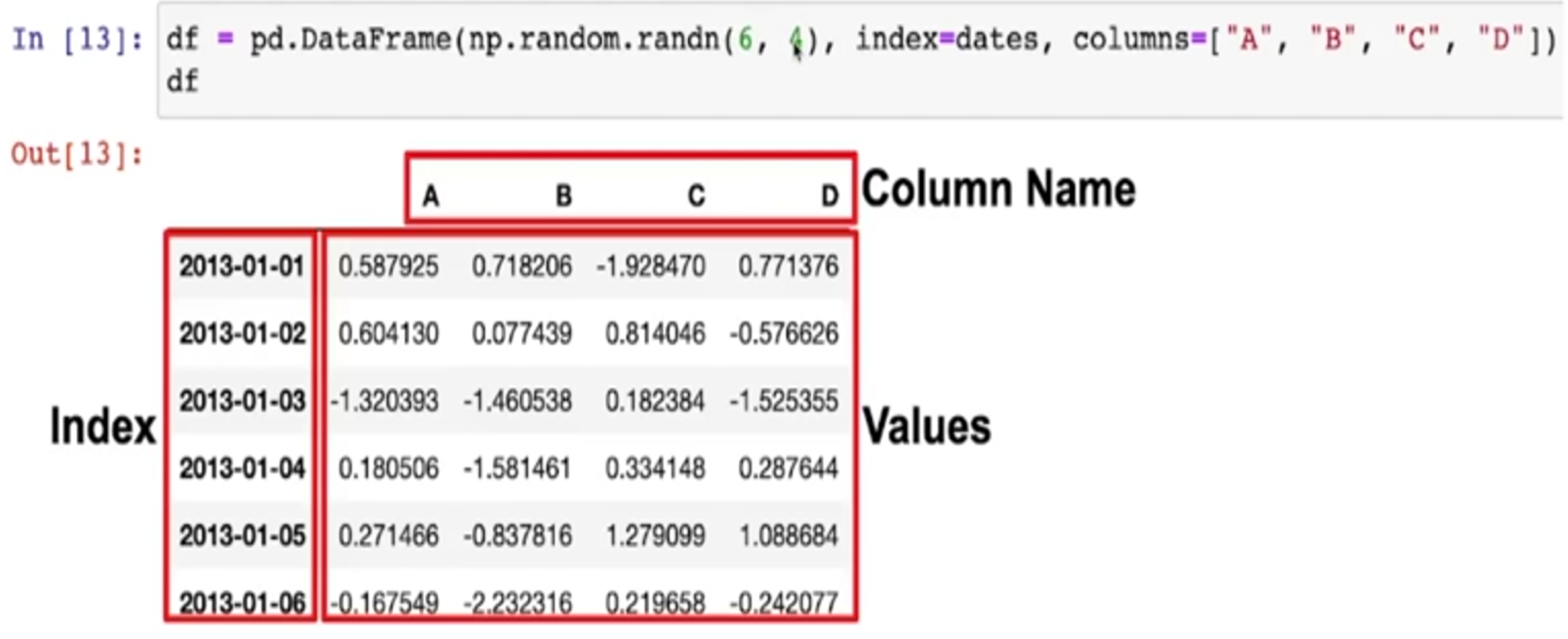
DataFrame(np.random.randn(6, 4), index=dates, columns=["A", "B", "C", "D"])
- Pandas에서 가장 많이 사용되는 데이터형은 DataFrame이다
- index와 columns를 지정하면 된다
values
- DataFrame의 index 조회
- DataFrame의 column 조회
- DataFrame의 value 조회
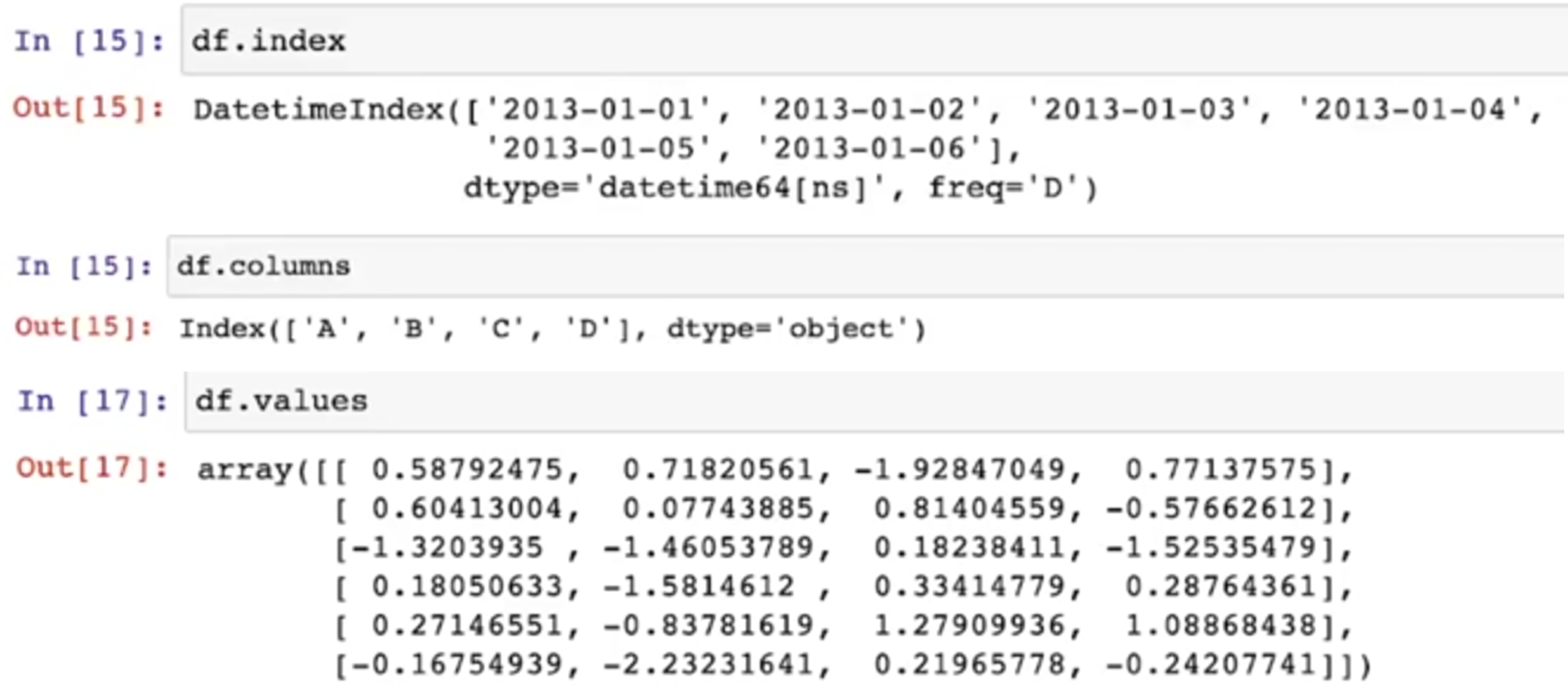
info()
- DataFrame의 기본 정보 확인
- 여기서는 각 컬럼의 크기와 데이터형태를 확인하는 경우가 많다
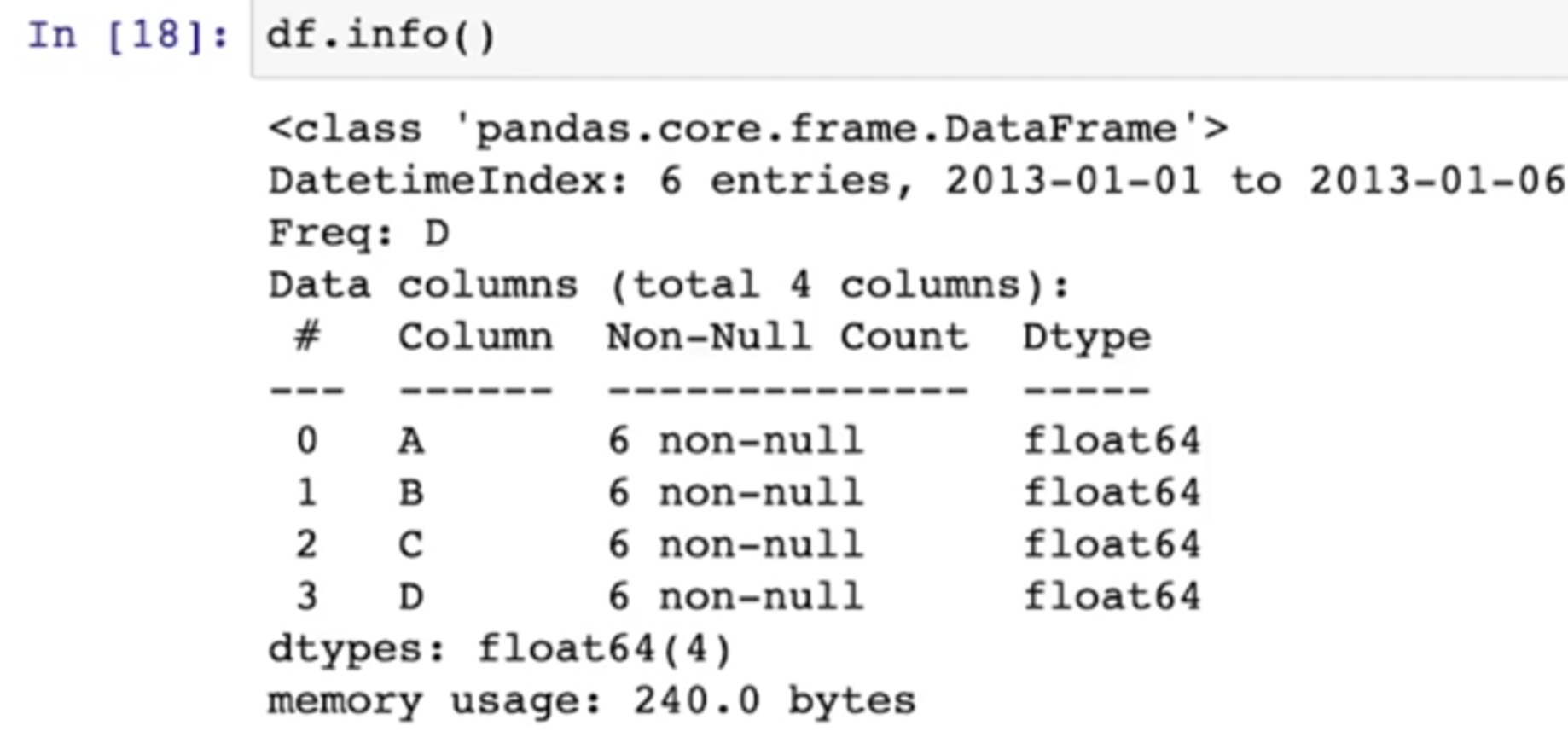
describe()
- DataFrame의 통계적 기본 정보를 확인
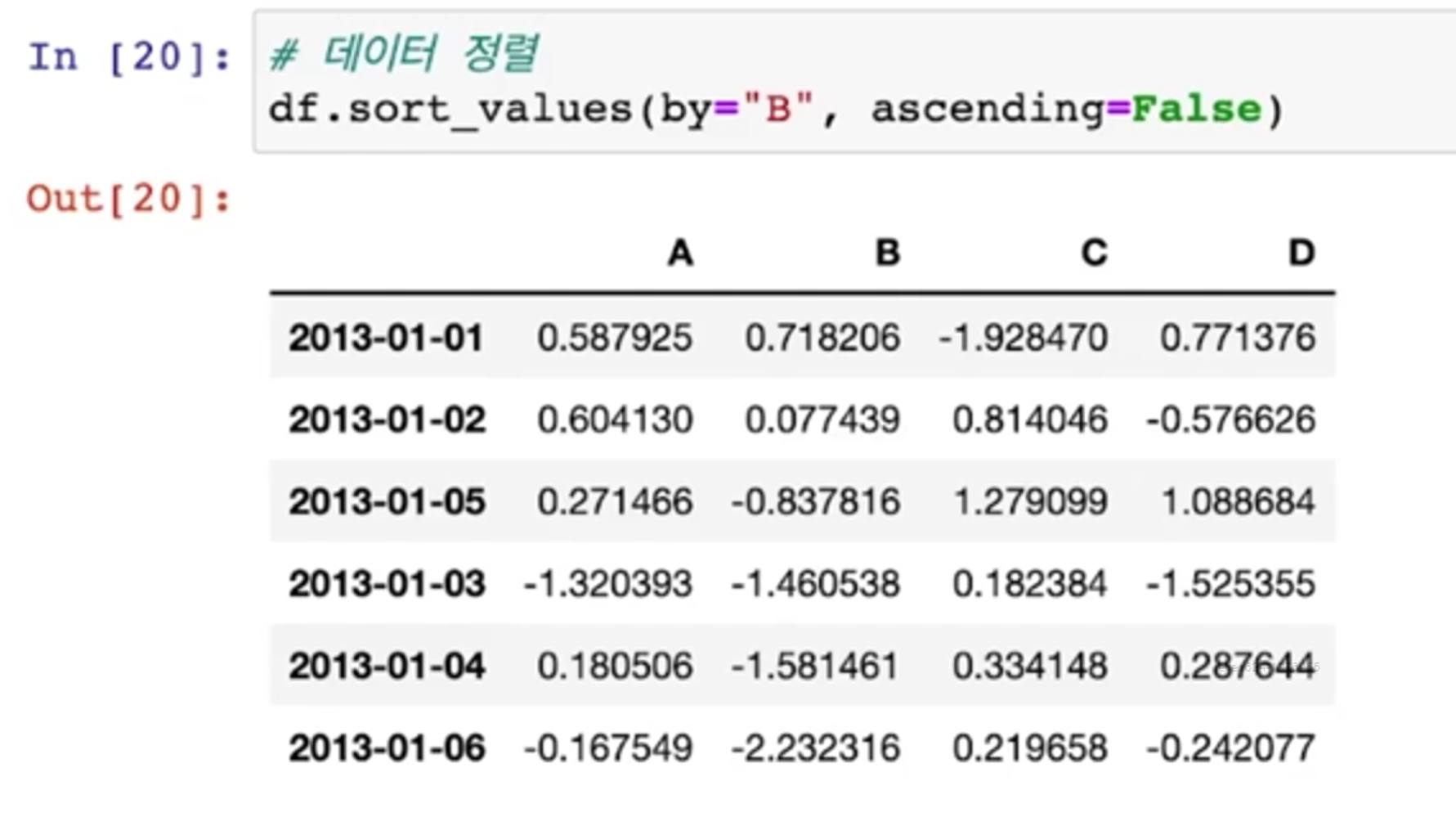
sort_values
- sort_values: 데이터를 정렬
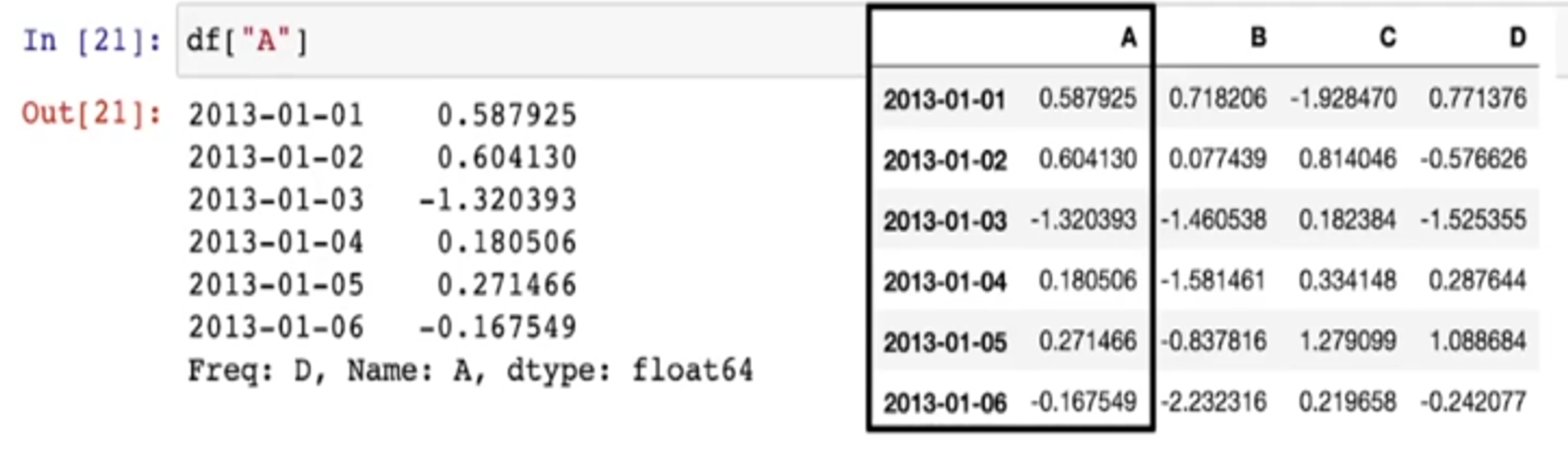
["A"]
- 특정 컬럼만 읽기
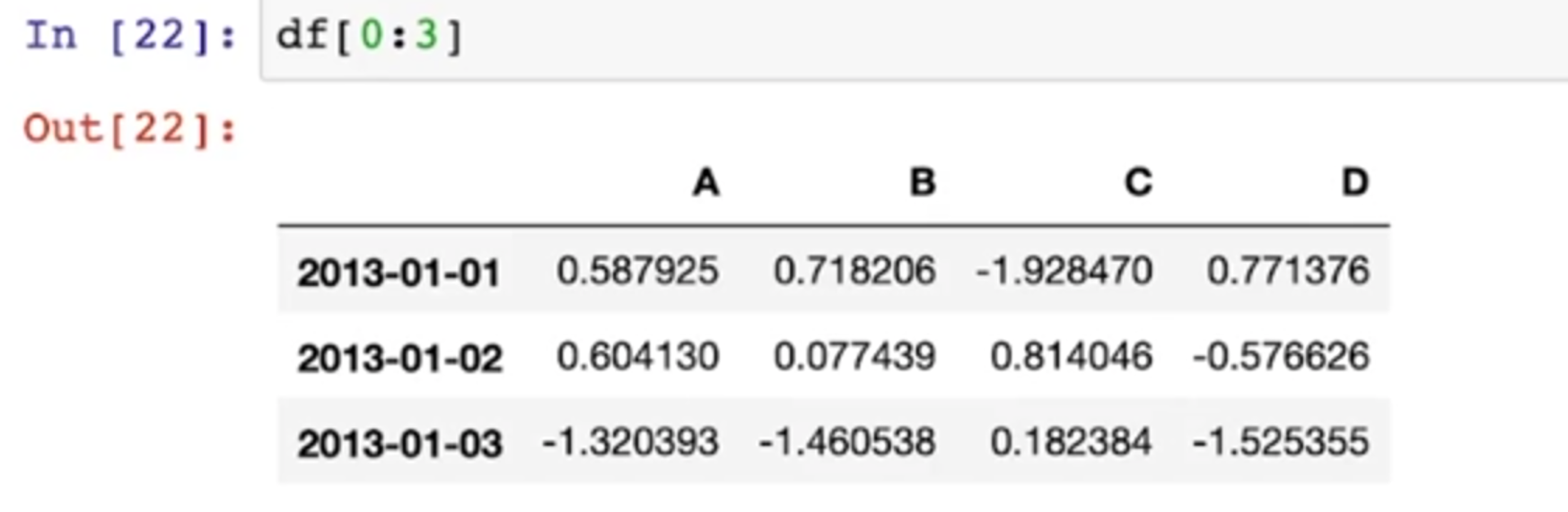
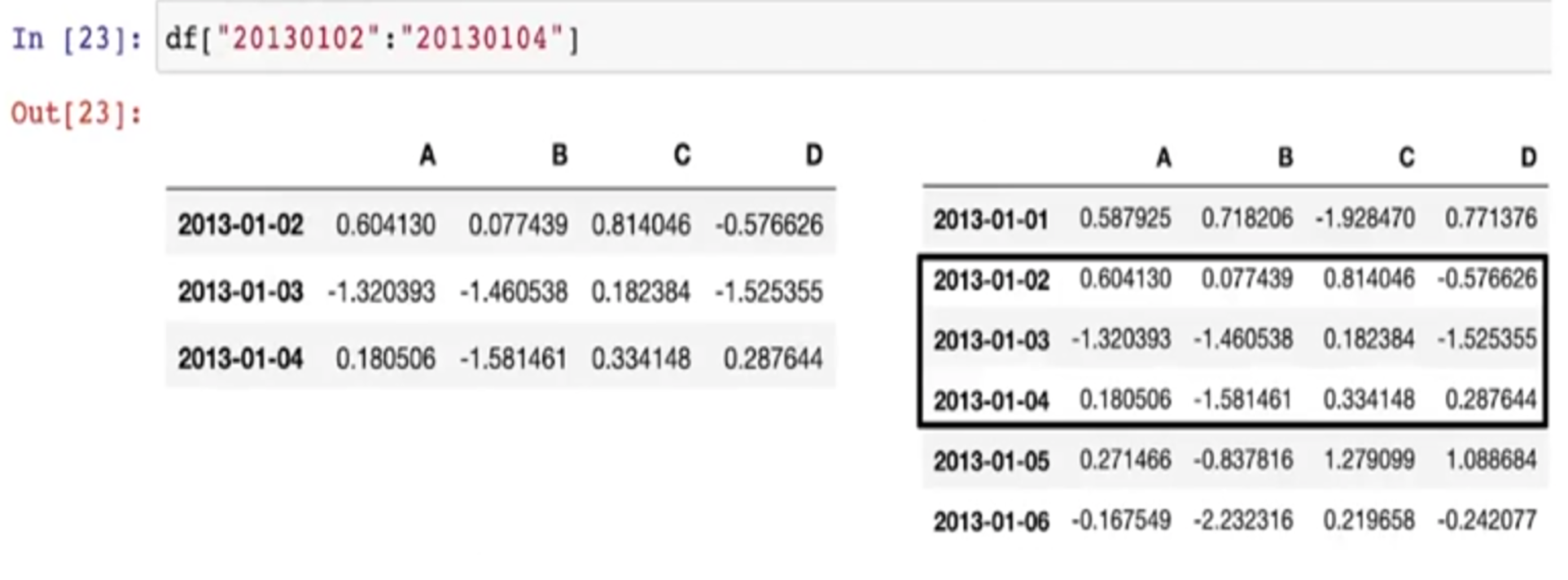
Pancas Slice
- [n:m] : n부터 m-1 까지
- 그러나 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함함
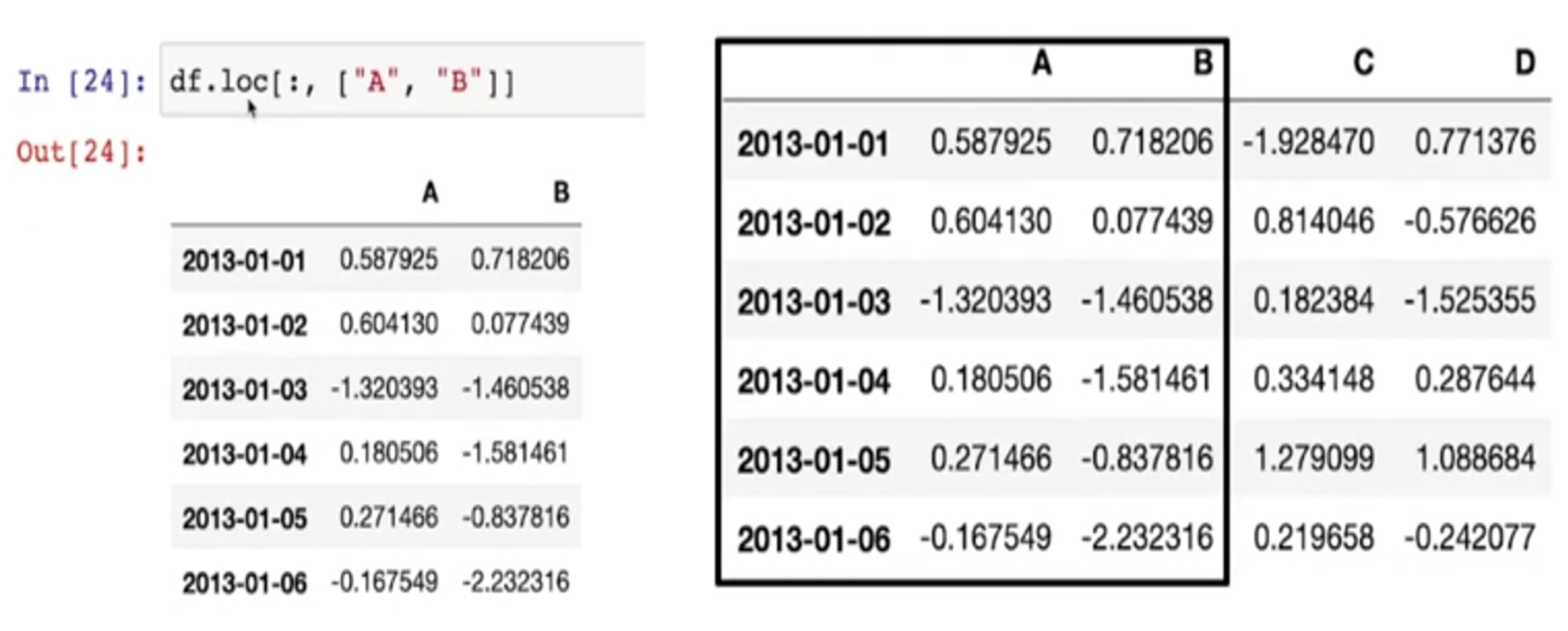
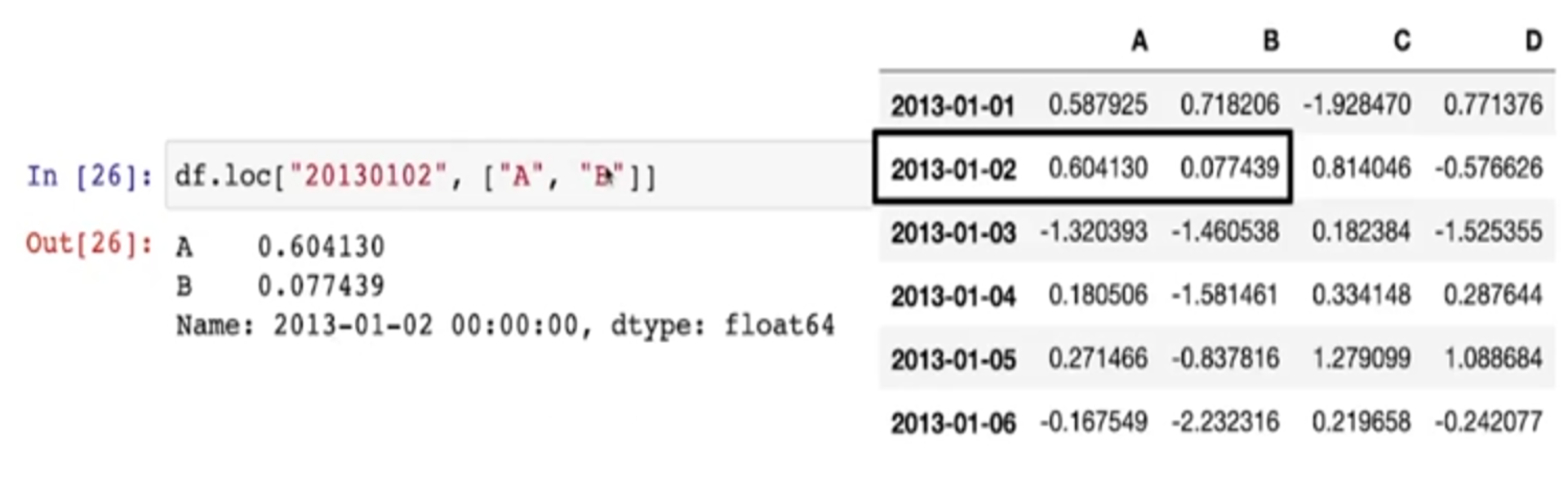
Pancas Slice - option LOC
- 이름으로도 사용 가능
- Pandas의 보편적인 slice 옵션

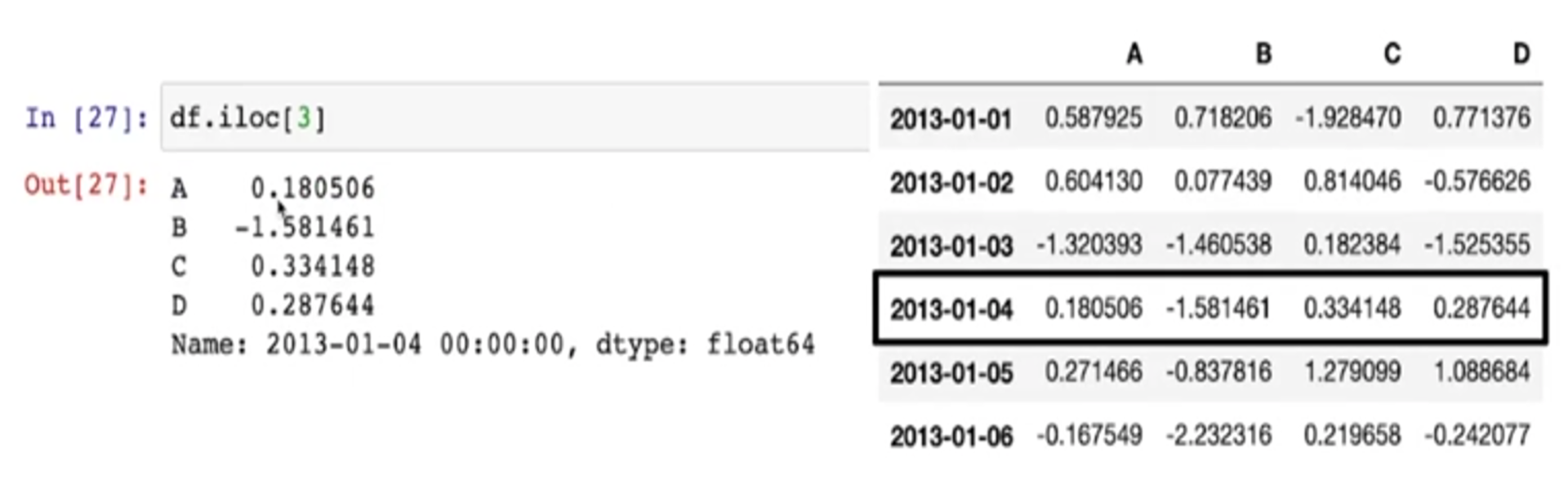
Pancas Slice - option iLOC
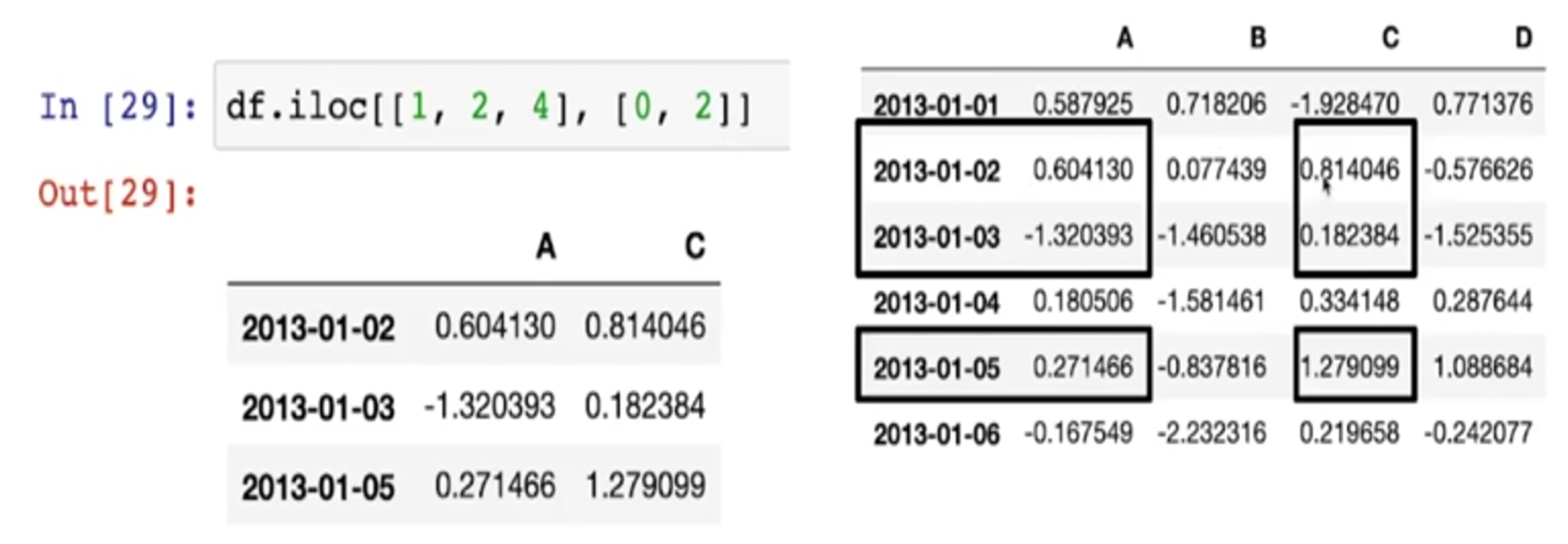
- iloc 옵션을 이용해서 번호로만 접근
- 1, 2, 4 번행 0, 2 컬럼 선택
Pancas Slice under condition
- df[condition]과 같이 사용하는 것이 일반적
- Pandas의 버전에 따라 조금씩 허용되는 문법이 다르다
- 인터넷에서 확보한 소스코드를 돌릴 때는 Pandas의 버전을 확인하는 것이 필요
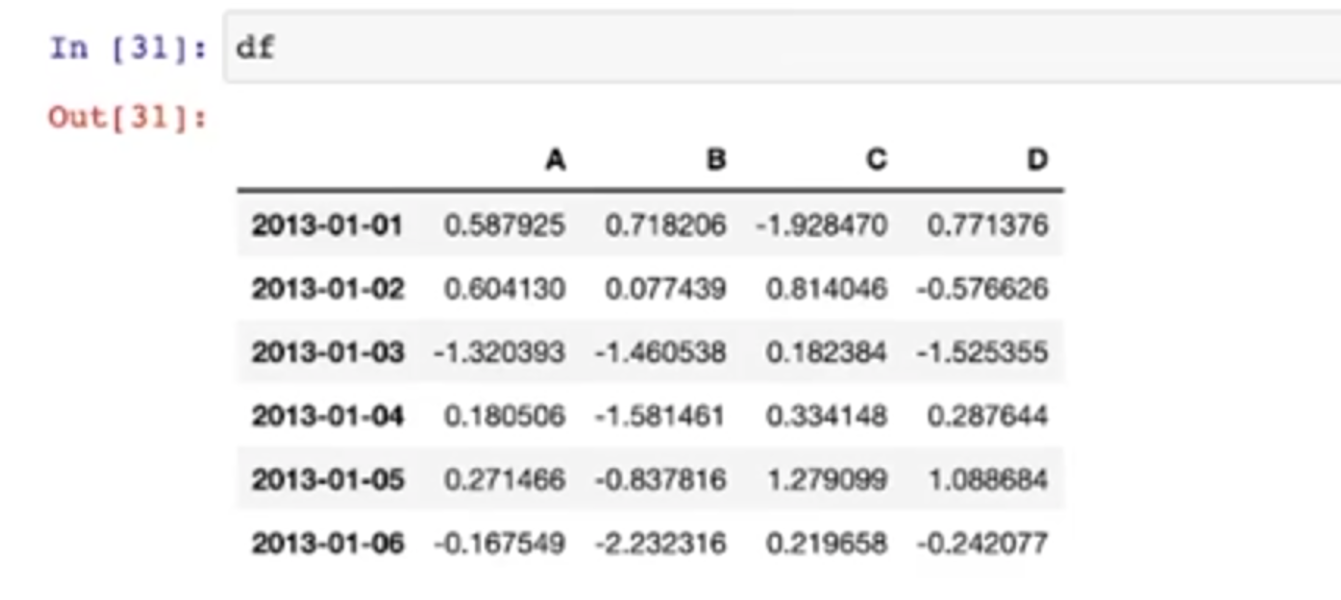
조건문
- A에서 0보다 큰 컬럼들
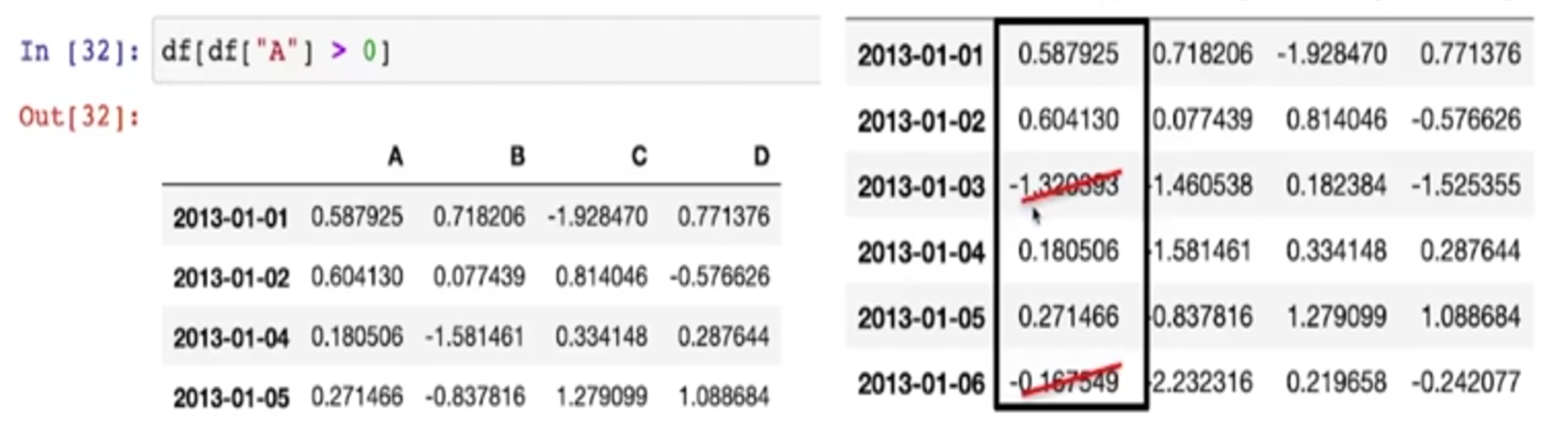
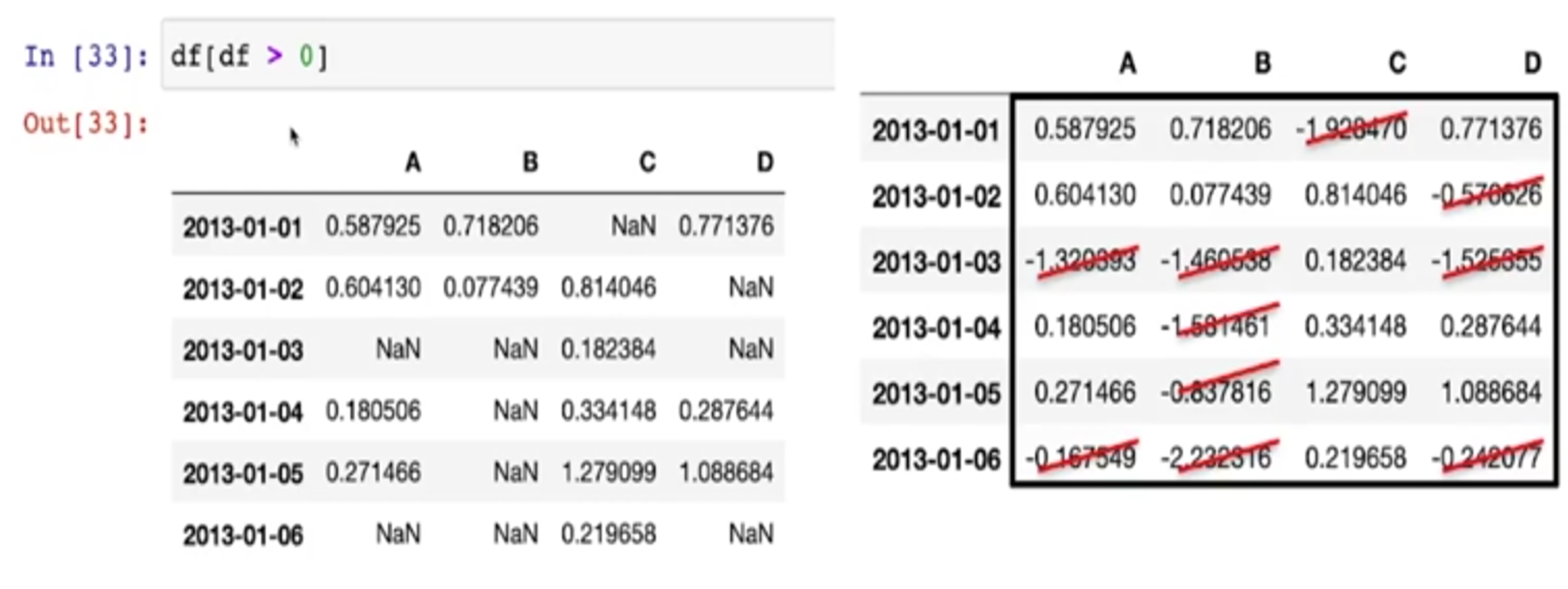
- 컬럼을 지정하지 않고 전체적으로 0보다 큰 것들만 출력해라
-> 0보다 작은 것들은 NaN이 됨
Pancas Slice under condition
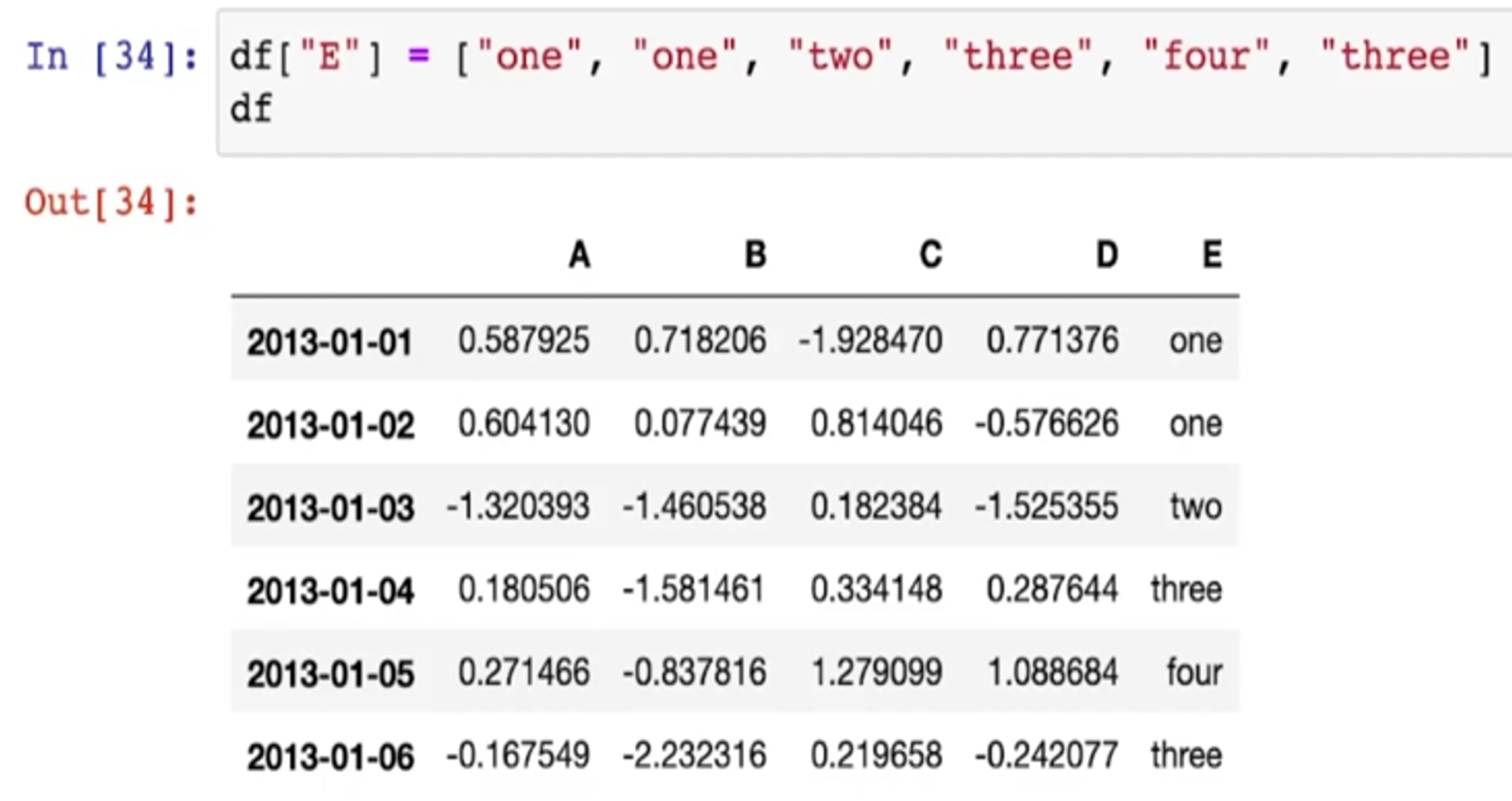
- E라는 컬럼을 만들어서 문자들을 집어넣음
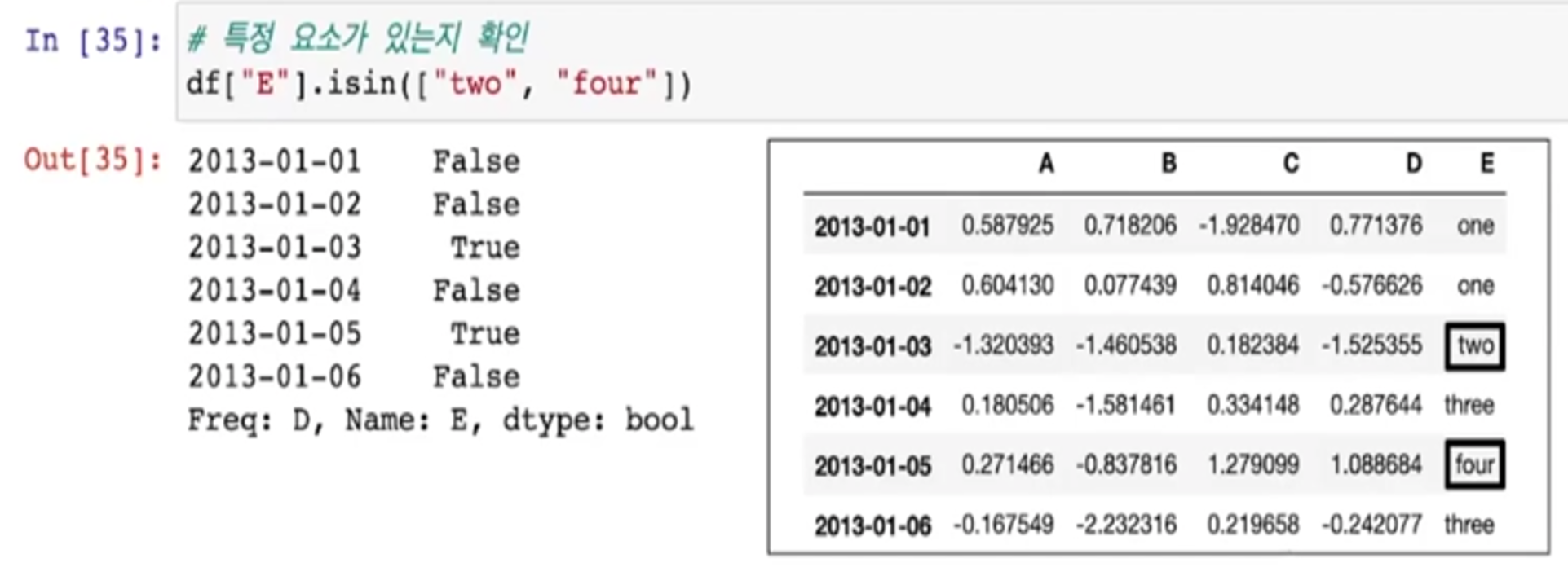
- E라는 컬럼에 two, four가 있는지 확인
-> 값은 True or False
- 대괄호로 묶어주면 two, four가 있는 행만 보여줌

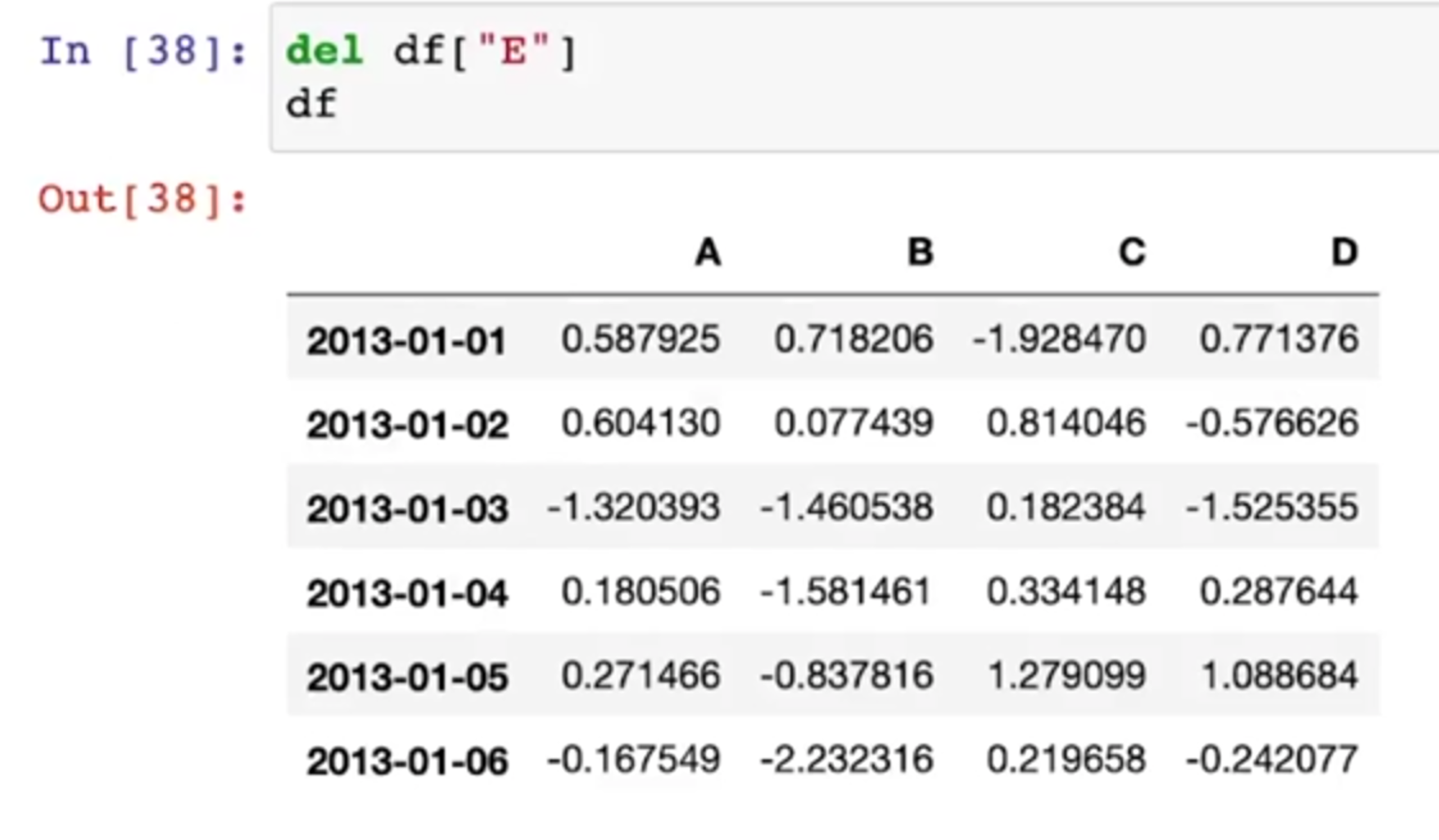
Pancas Column remove
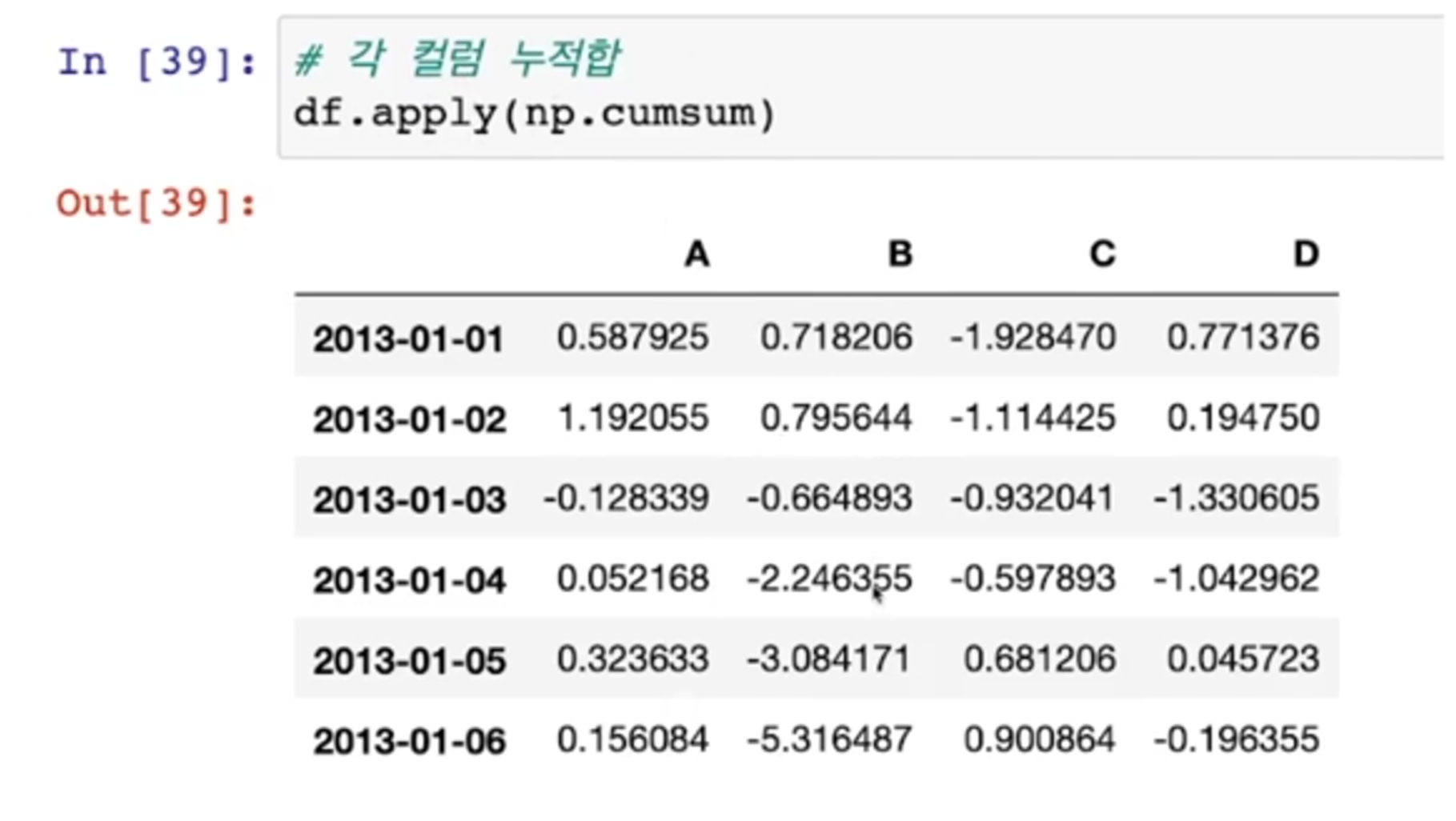
Pancas apply function
- cumsum은 누적합계함수
- apply()로 함수를 적용
07 ~ 08 CCTV 데이터와 인구형황 데이터 훑어보기
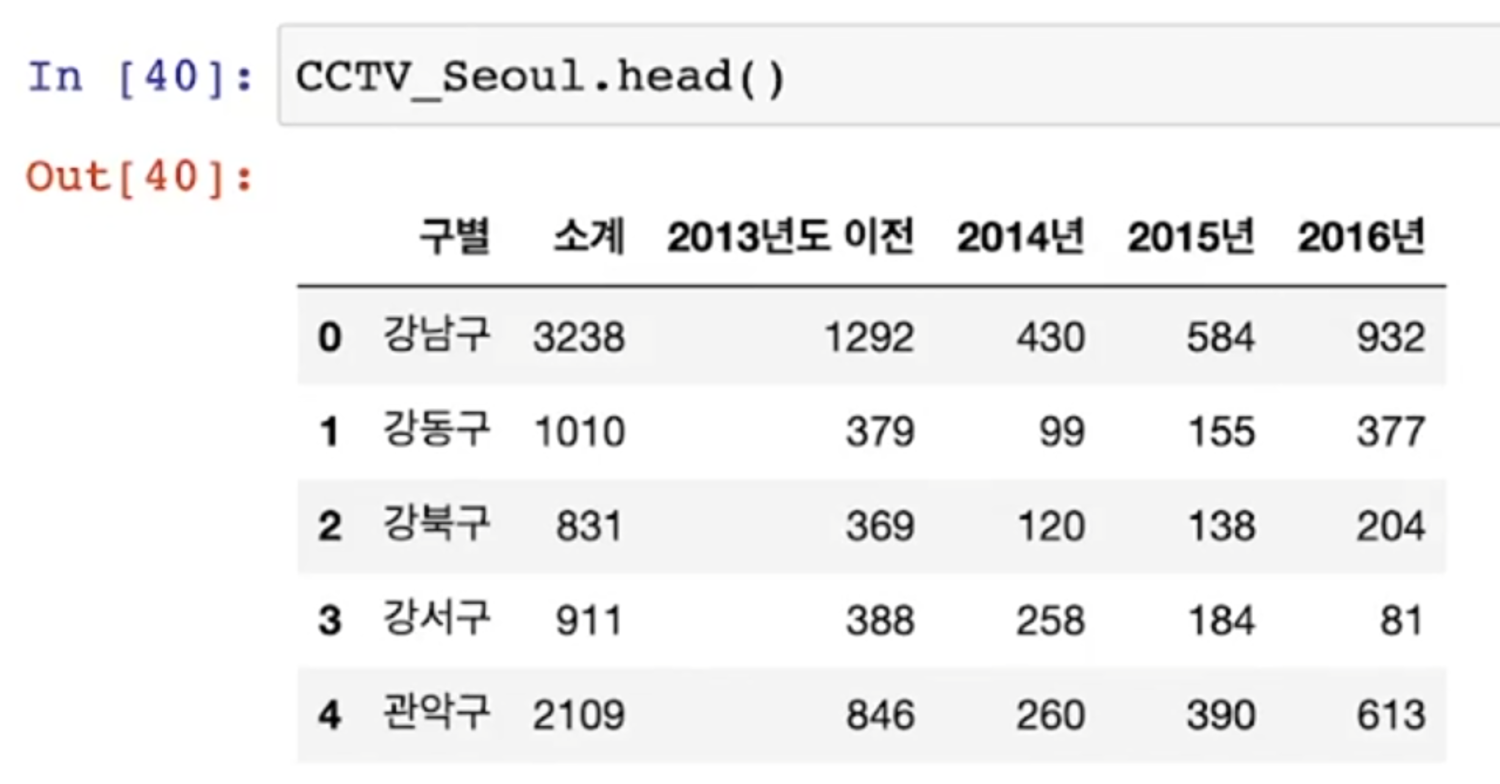
CCTV 데이터 단순히 확인해보기
head()
- CCTV 앞 부분 데이터 확인
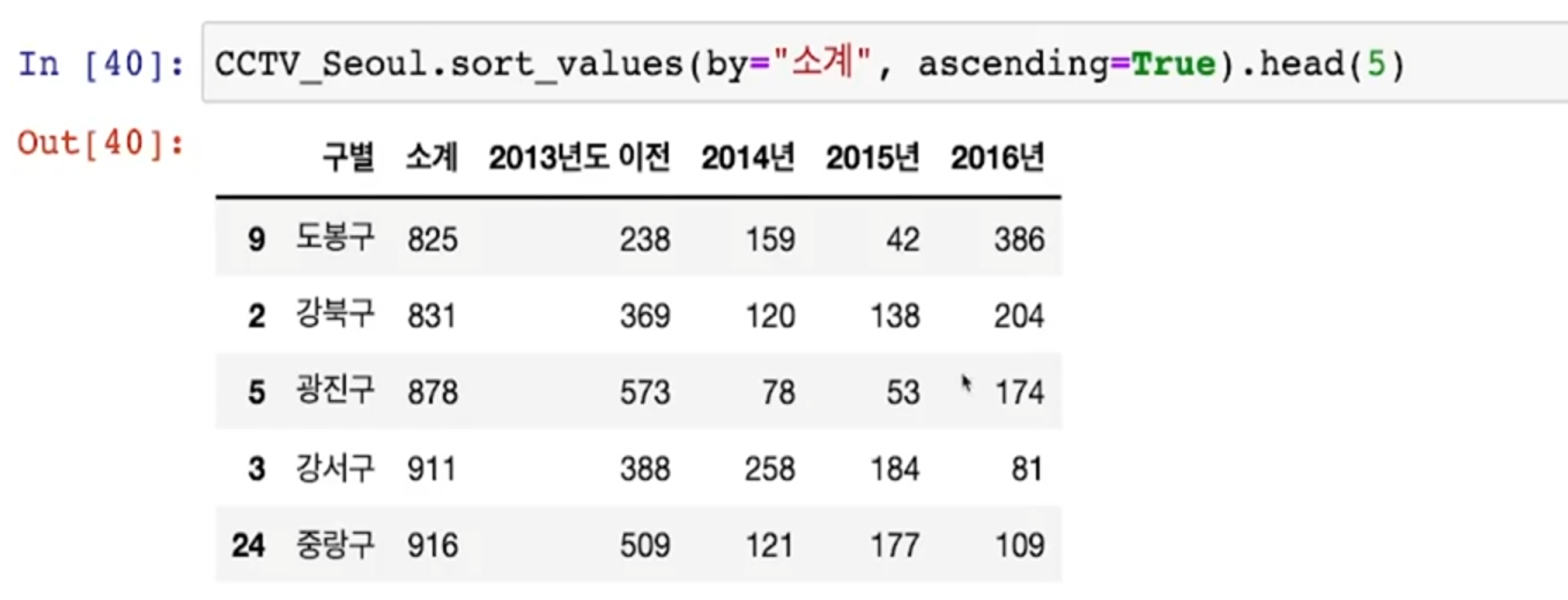
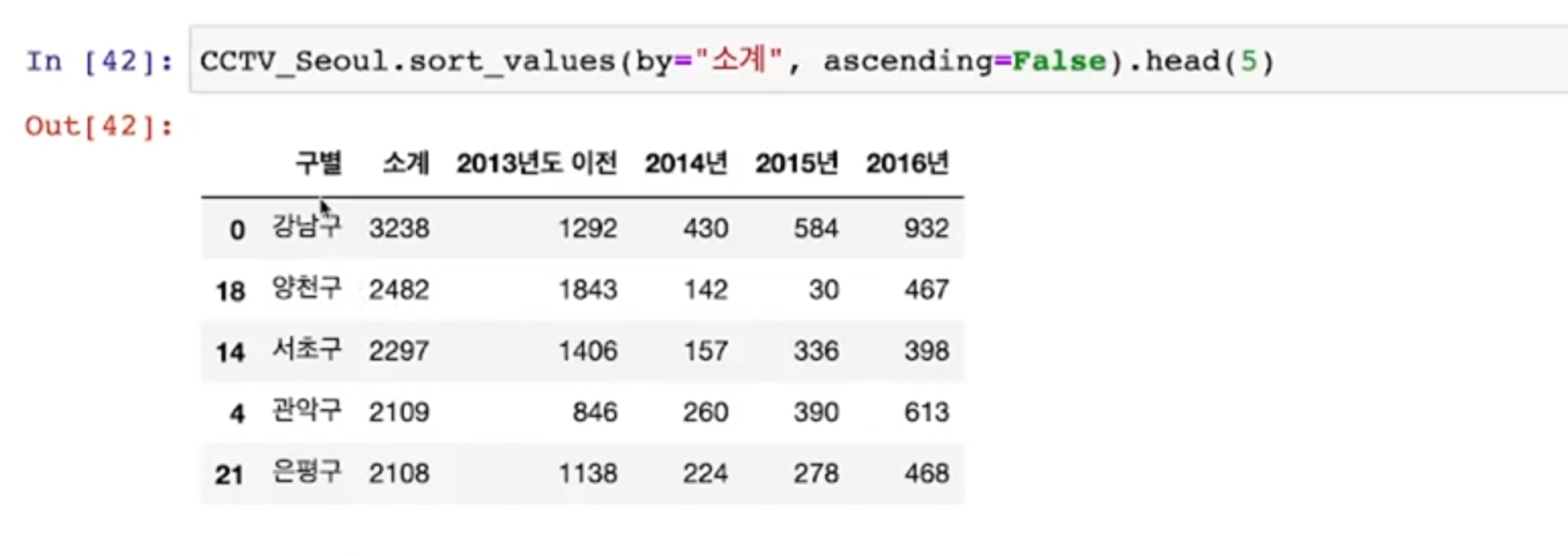
최소, 최대
- 가장 CCTV를 적게 보유한 구
- 가장 CCTV를 많이 보유한 구
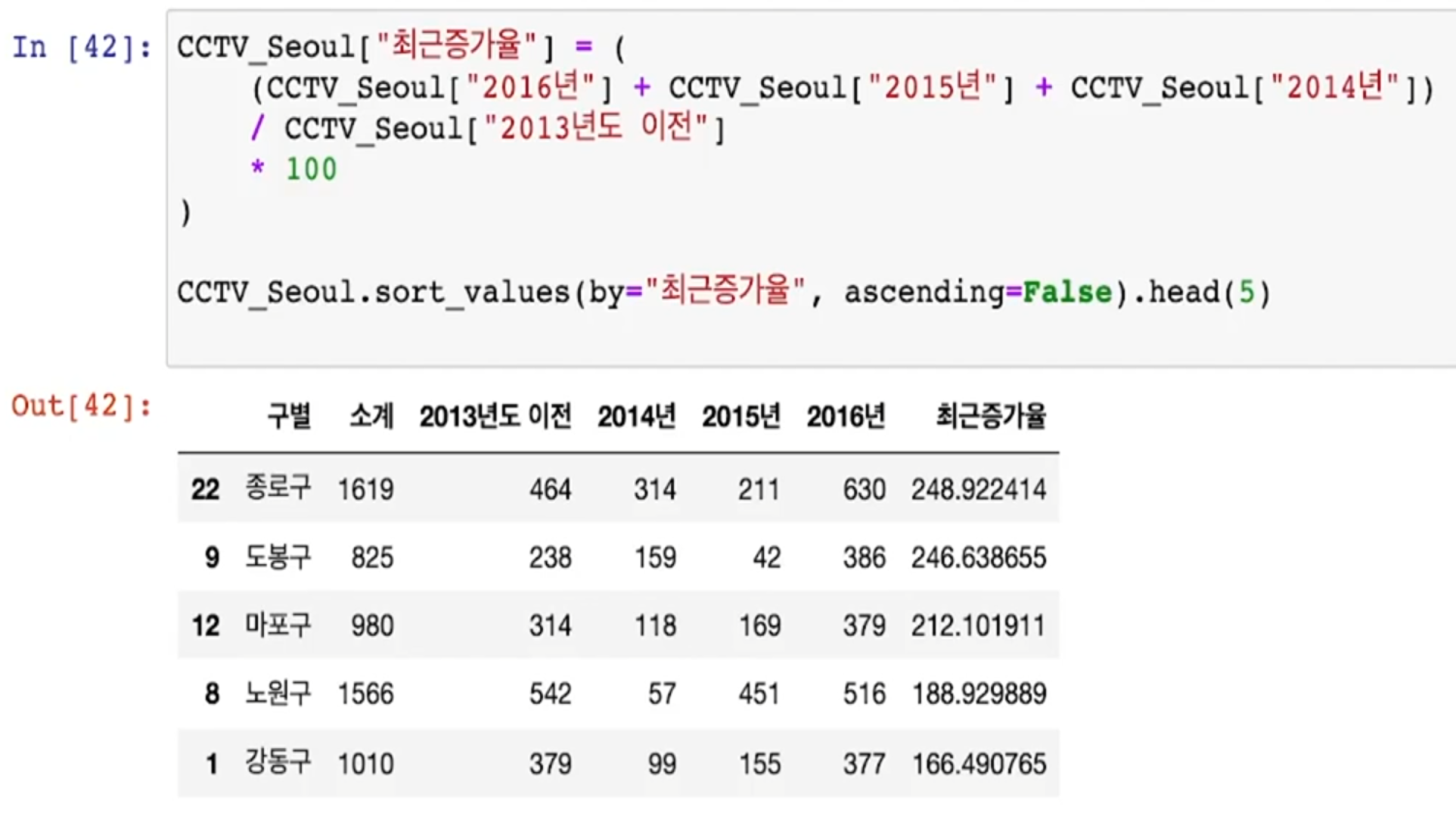
증가율
- 최근 3년간 그 전 보유한 갯수 대비 CCTV를 많이 설치한 구는 종로구
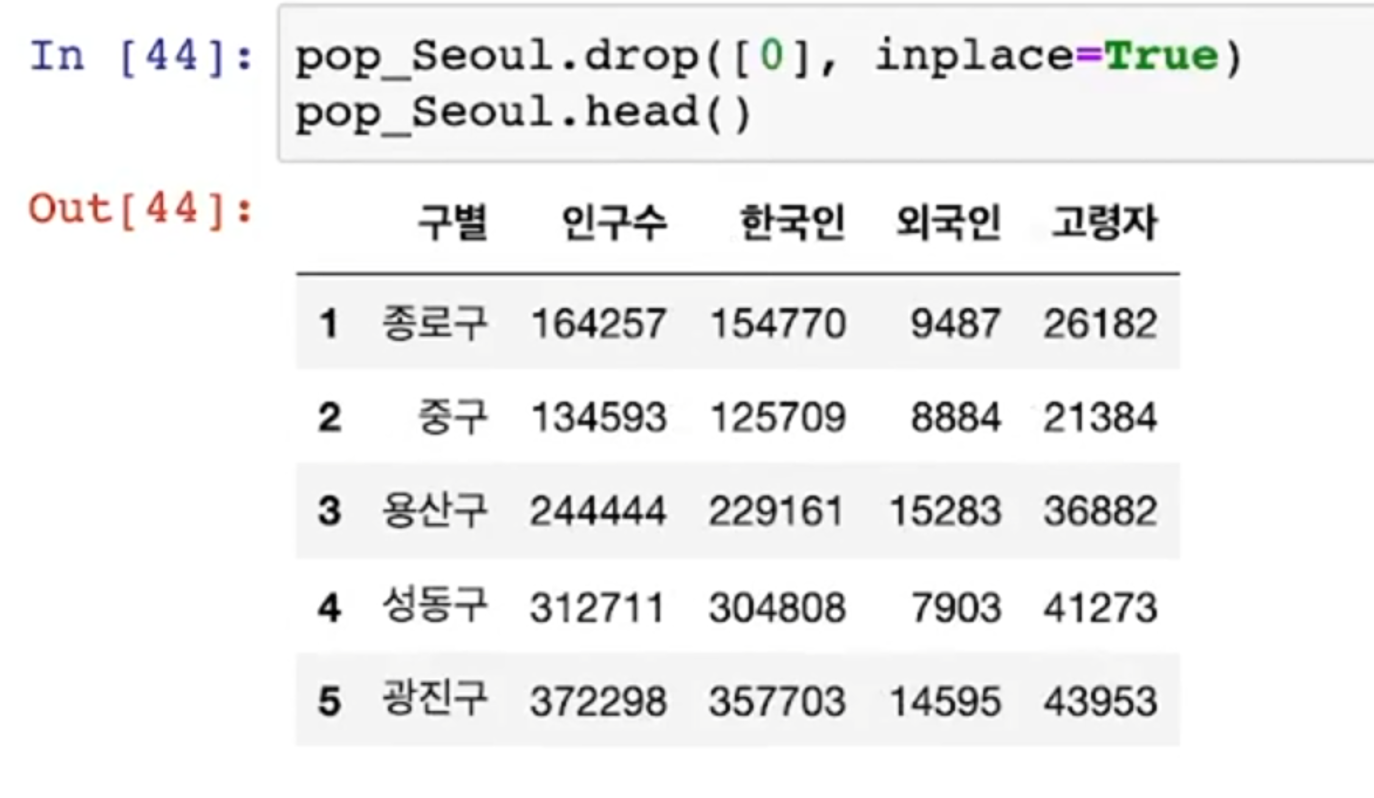
drop()
- 첫 행(0번)의 합계 데이터는 필요 없다
- 행을 지우는 명령 -> drop
unique()
- unique 조사
- 데이터가 많아지면 unique 조사를 통해 데이터를 초반 검증 한다

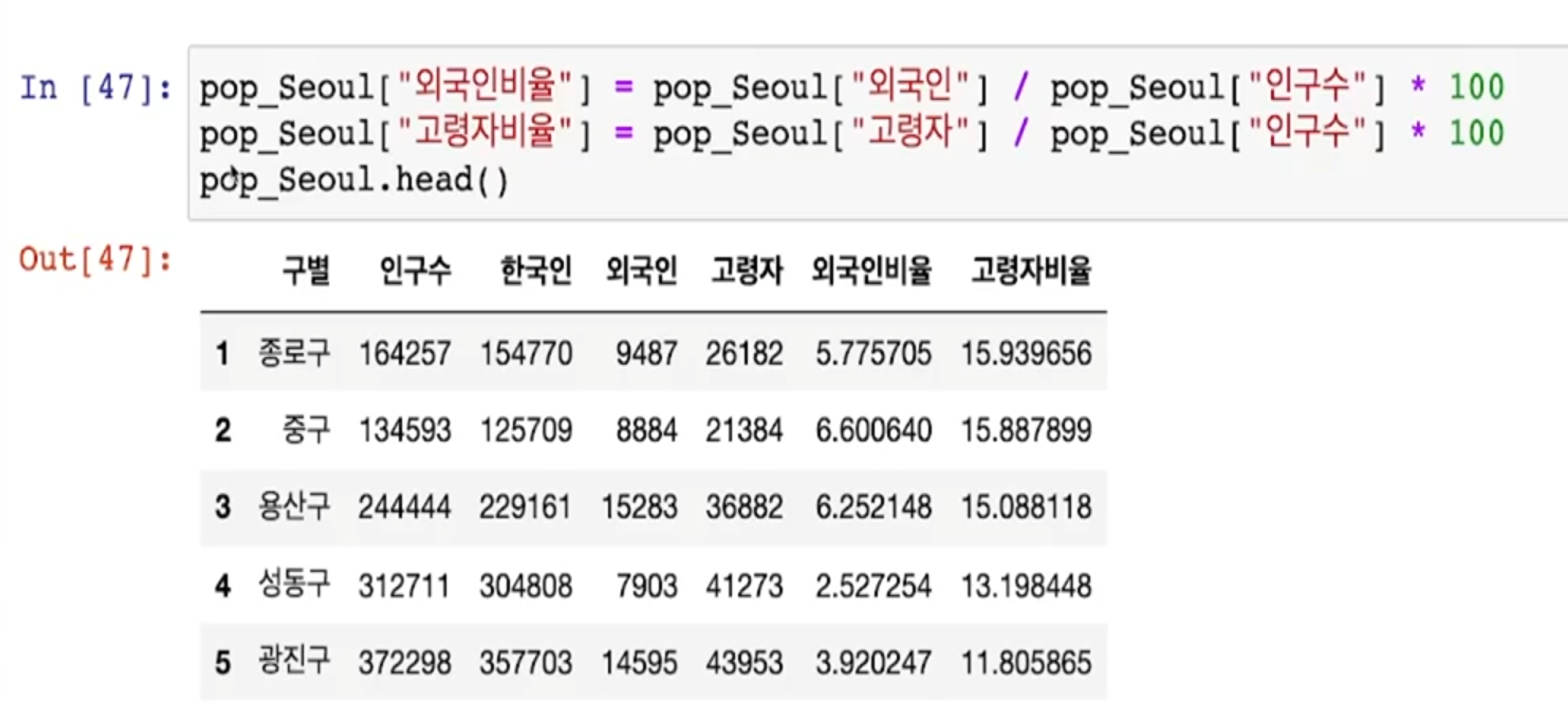
비율
- 외국과 고령자 비율을 만들어 둔다
- 컬럼 연산이 편하다는 것이 python의 장점
09 ~ 11 Pandas 데이터 merge 이용해서 병합하기
Pandas 데이터 병합하고 정리하기
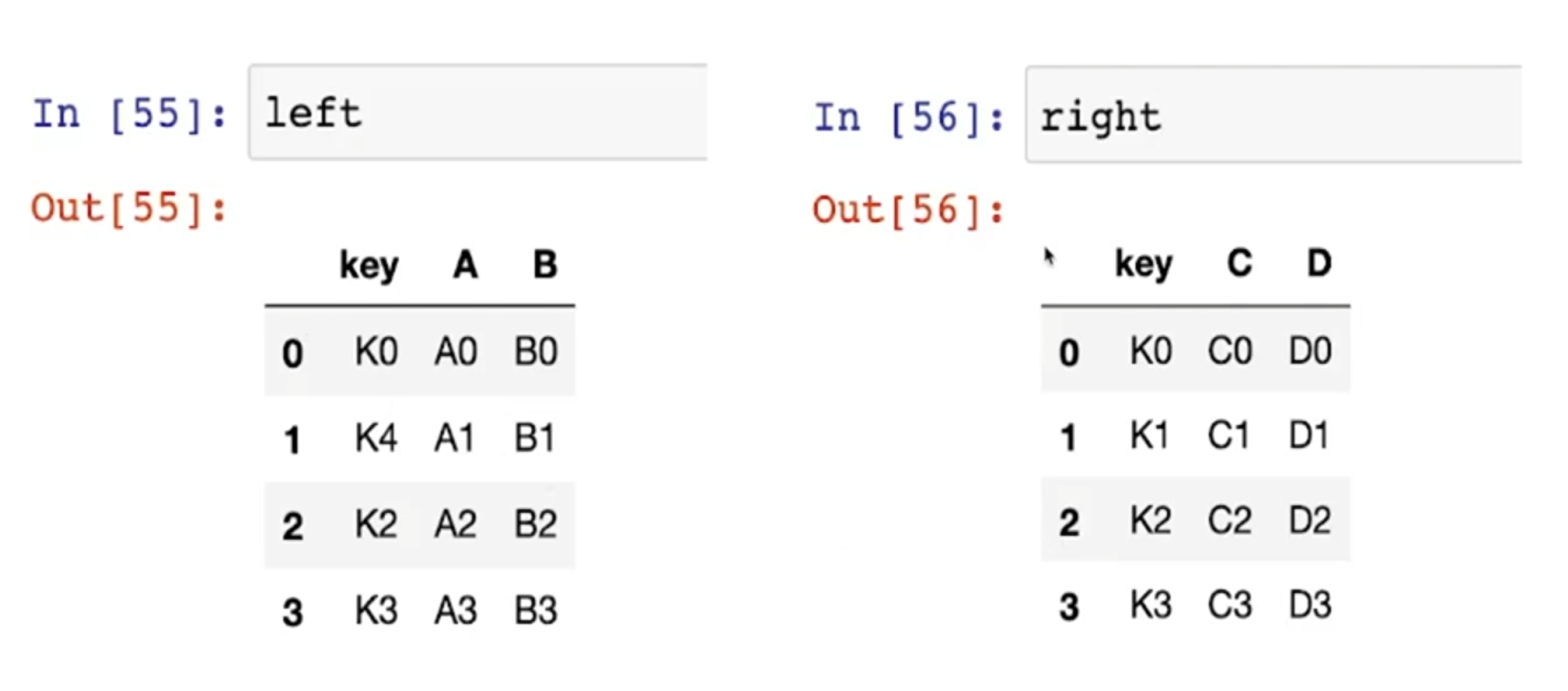
merge
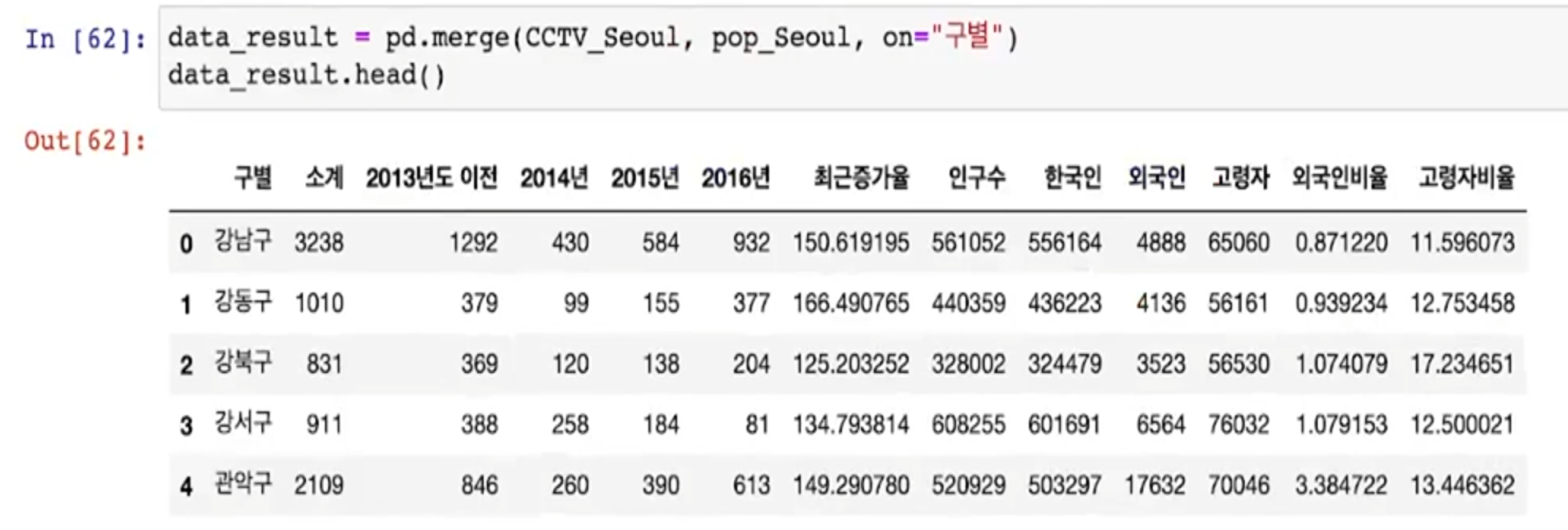
- merge를 이용한 데이터 병합
- Pandas DataFrame 데이터끼리의 병합은 빈번히 발생한다
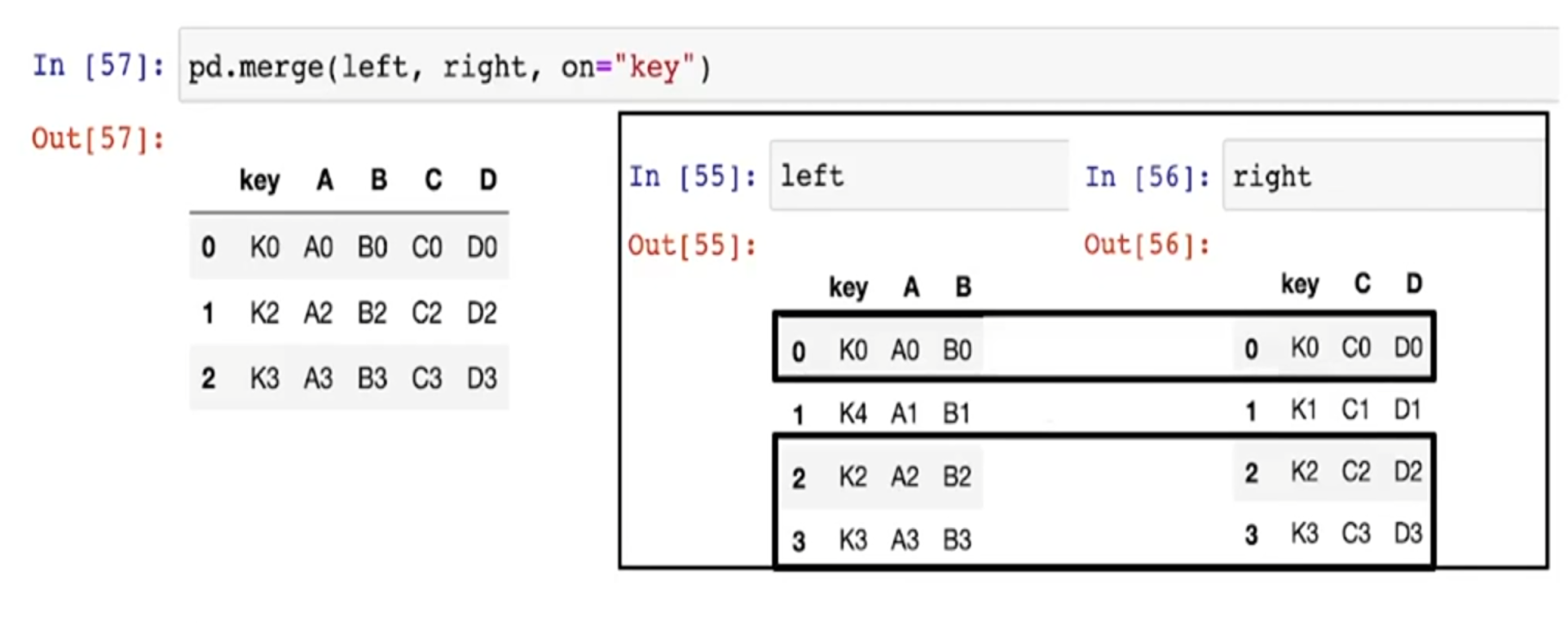
- key 컬럼을 기준으로 병합
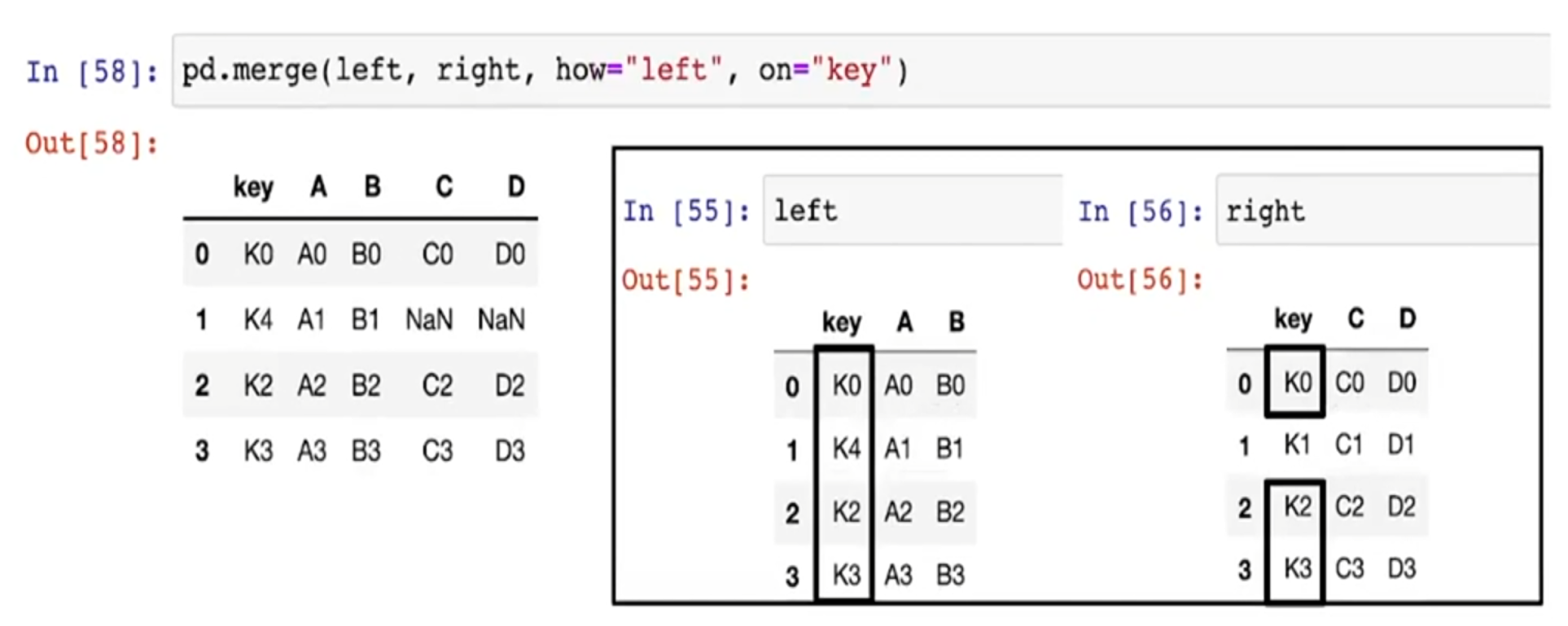
- left에 key를 기준으로 right 병합
- how="left" 를 하면 left의 key를 모두 보존 시킴
- right에는 k4가 없으므로 NaN이 출력됨
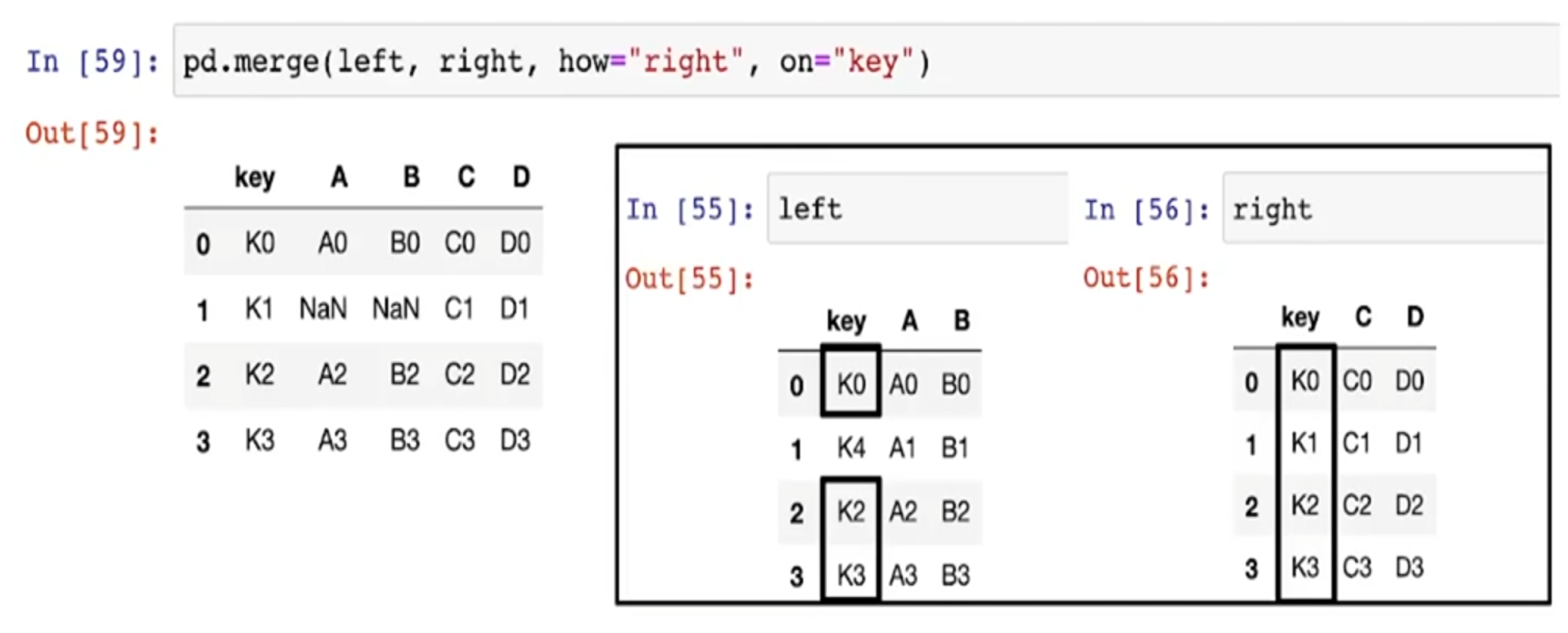
- right에 key를 기준으로 left 병합
- how="right" 를 하면 right의 key를 모두 보존 시킴
- left에는 k1이 없으므로 NaN이 출력됨
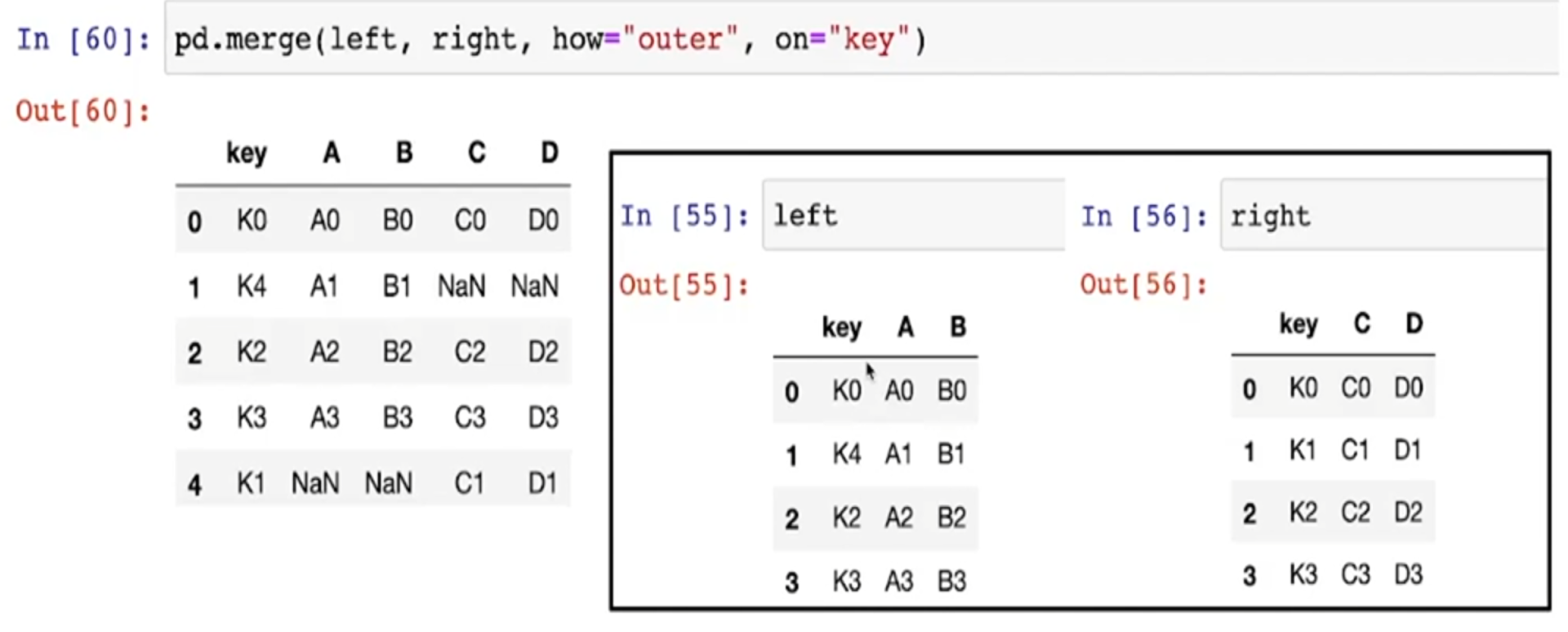
- 둘 다 손상되지 않도록 key를 기준으로 병합

CCTV 파일
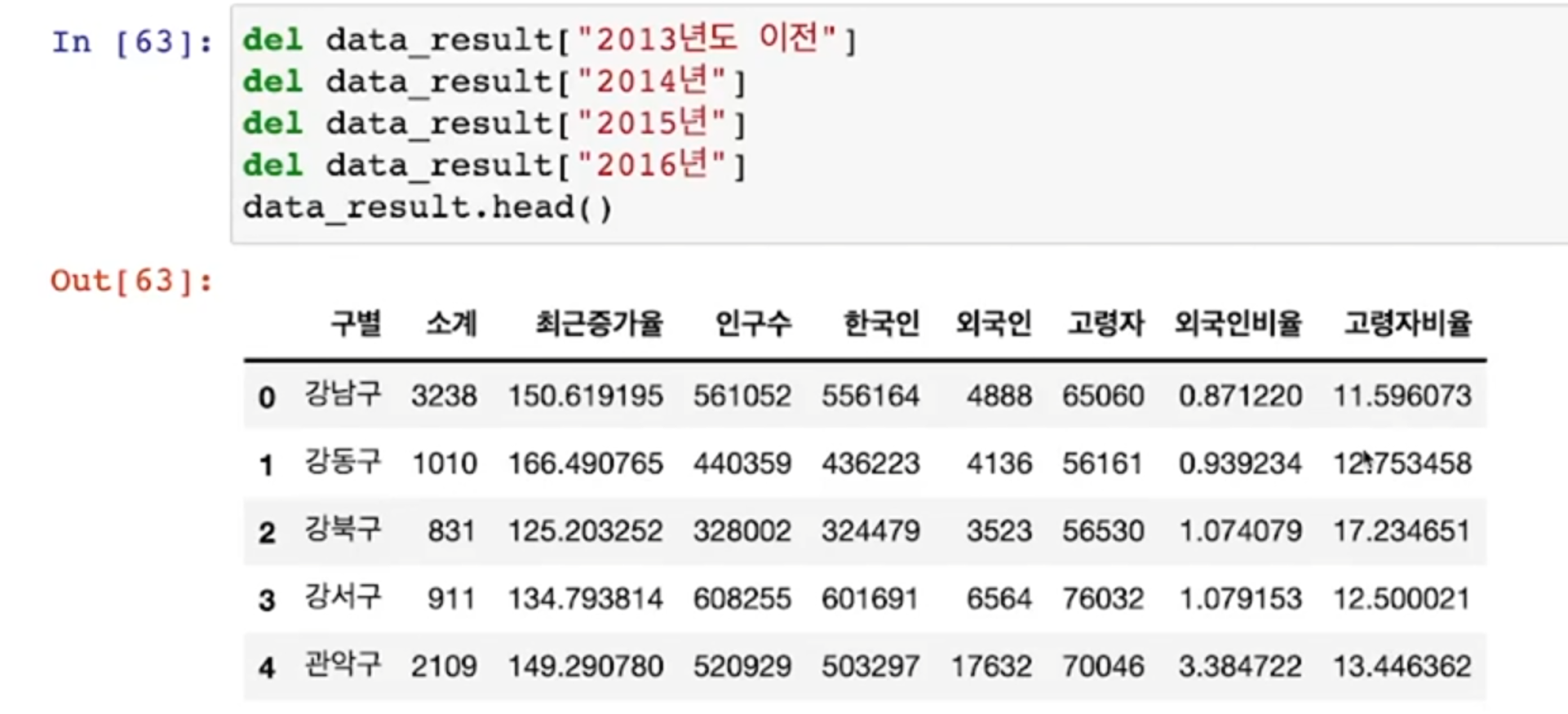
- 필요 없는 컬럼 제거
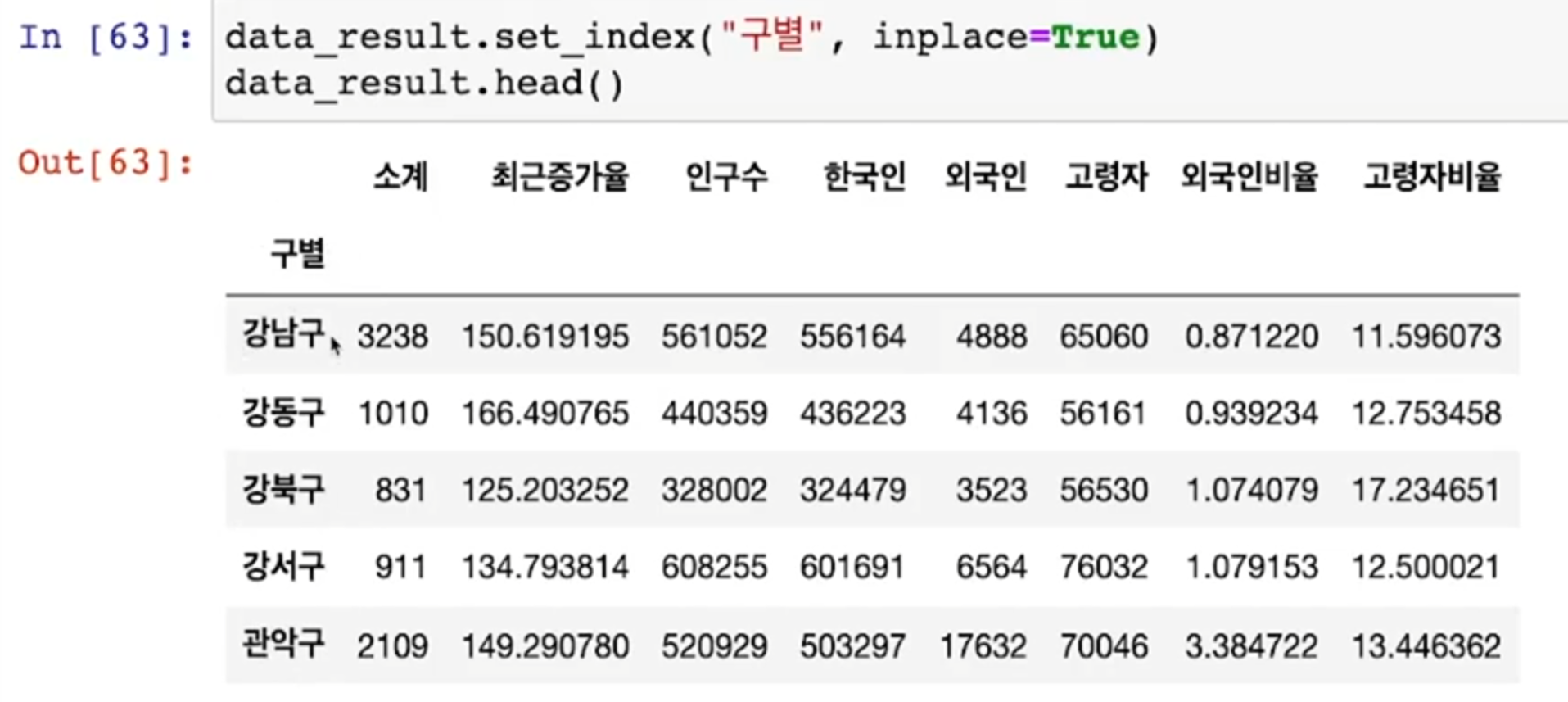
- Pandas index 지정
- 데이터를 정리하는 과정에서 index를 재지정할 때가 있다
- 여기서는 unique한 데이터인 구별로 index를 잡음
- index를 재지정하는 명령은 set_index 이다
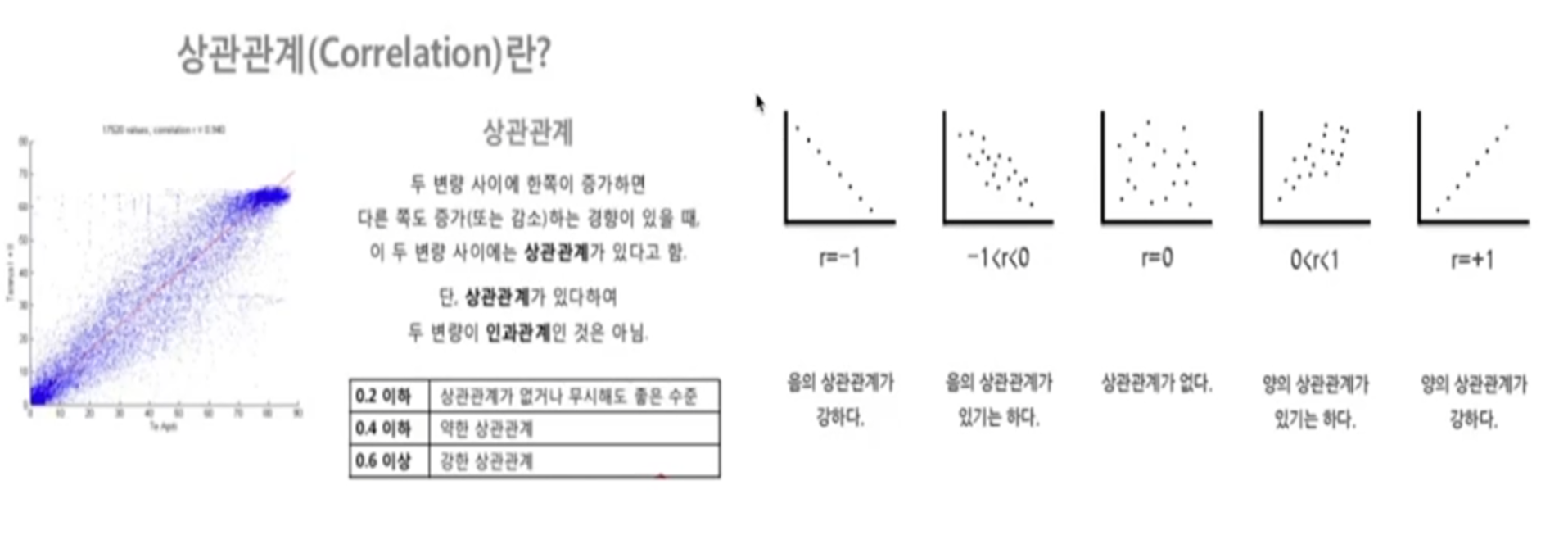
상관관계
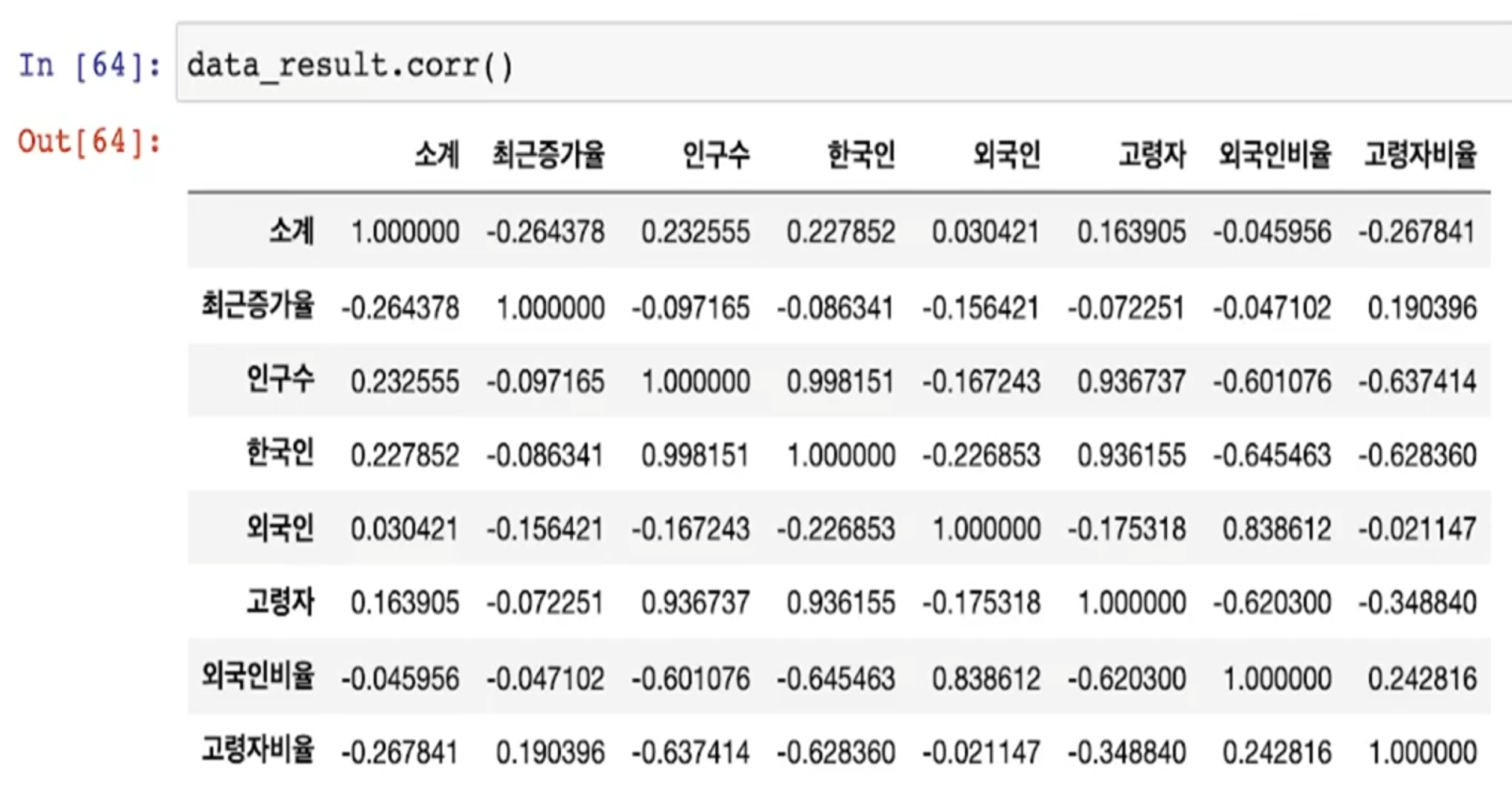
- corr() -> 상관관계
- 데이터의 관계를 찾을 때, 최소한의 근거가 있어야 해당 데이터를 비교하는 의미가 존재
- 상관계수를 조사해서 0.2 이상의 데이터를 비교하는 것은 의미가 있다
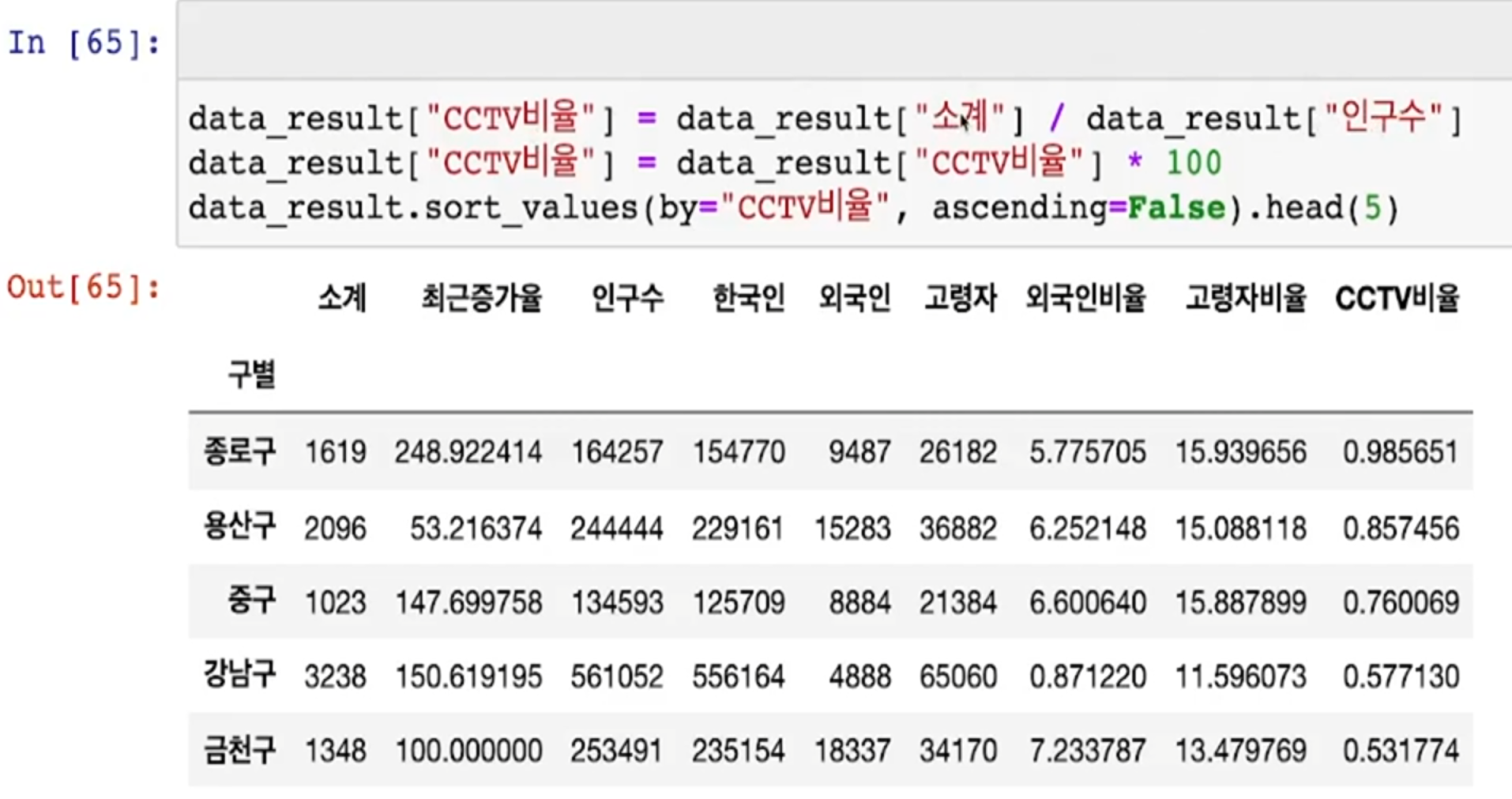
- CCTV 비율을 만들어 CCTV 비율이 높은 구를 보자
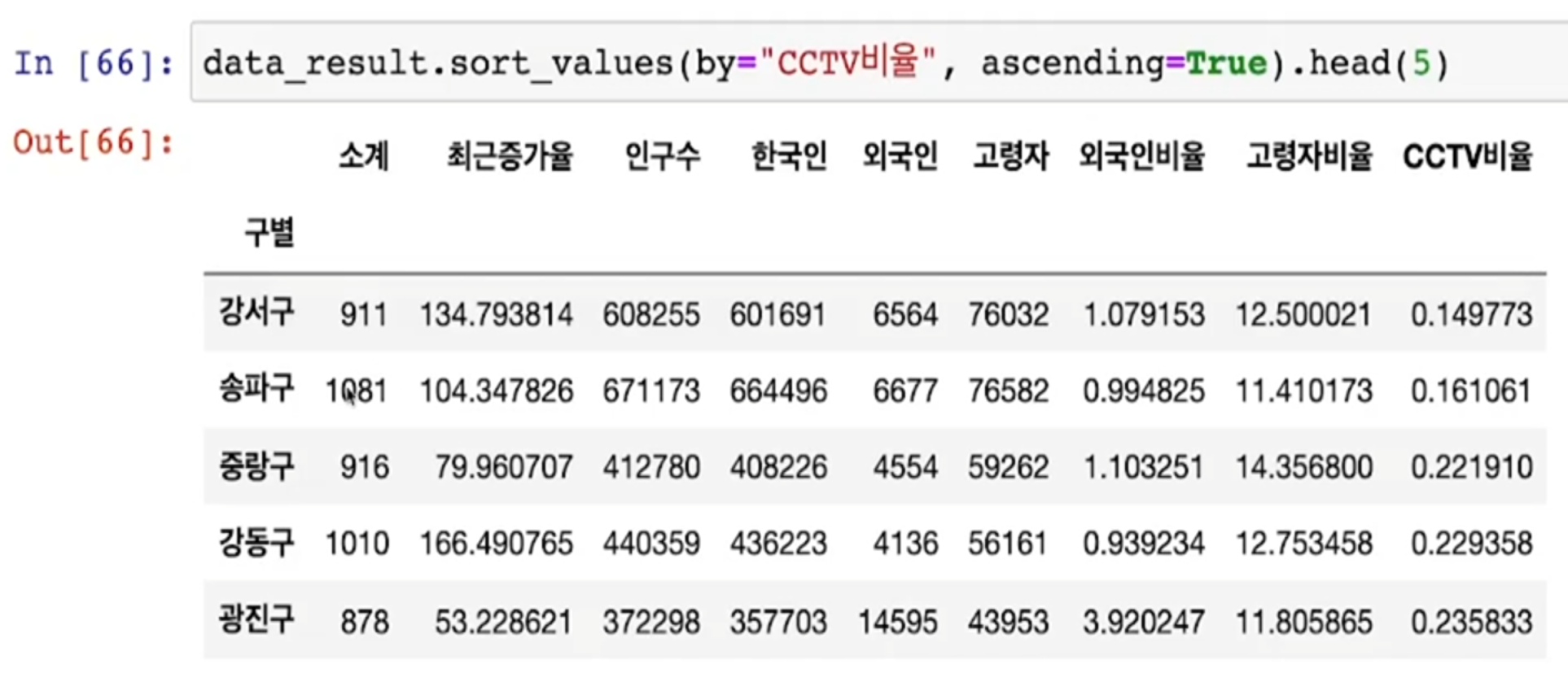
- CCTV 비율을 만들어 CCTV 비율이 낮은 구를 보자
재미있었던 부분
Pandas데이터를 merge를 이용해서 병합하고 병합한 데이터를 토대로 상관관계를 설명하는 부분이 가장 흥미롭고 재미있었다
어려웠던 부분
아직은 처음보는 함수가 많아서 기억하고 구조를 익히려면 좀 시간이 걸릴 것 같다
느낀점 및 내일 학습 계획
처음배우는 부분인 만큼 시간은 python에 비해서 훨씬 오래걸리는 것 같다
Jupyter notebook도 익숙하지 않아서 오류가 나면 뭐가 문제인지 찾는것도 일이다
내일도 이어서 CCTV나머지 부분을 공부할 예정이다

데이터 부트캠프 참여중