
오늘 수강한 강의 - EDA 서울시 CCTV 현황 데이터 분석 (12 ~ 20)
12 ~ 14 matplotlib 기초
- figure()로 열어서 show()로 닫는다
- figure()에는 그림에 대한 속성이 들어감

삼각함수 그리기
- np.arange(a, b, s): a부터 b까지의 s의 간격
ex) np.arange(0, 12, 0.01) -> 0부터 11까지 0.01의 간격으로- np.sin(value)
- 그래프를 그리는 코드를 def()로 작성한다
- 나중에 별도에 셀에서 그림만 나타낼 수 있기 때문
- grid() -> 그래프의 격자를 완성
- legend() -> 범례 표현
- xlabel() -> x축의 제목
- ylabel() -> y축의 제목
- title() -> 그래프의 제목 표현
- drawGraph() -> 함수가 실행됨


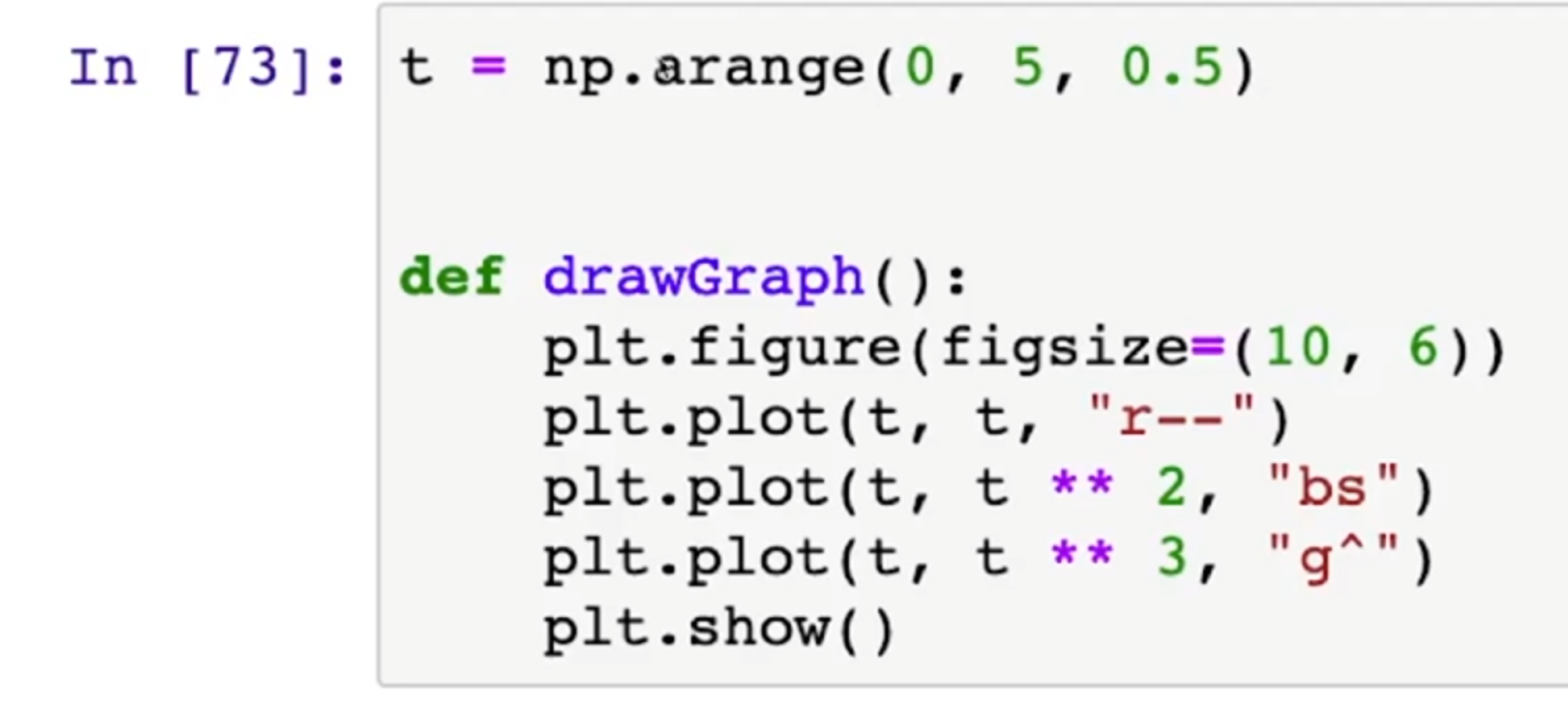
- r-- -> 빨간색 점선
- bs -> 파란 네모(bluesquared)
- g^ -> 초록색으로 위로 뾰족한 화살표 모양
- xlim -> x limit(범위 지정)
- ylim -> y limit(범위 지정)
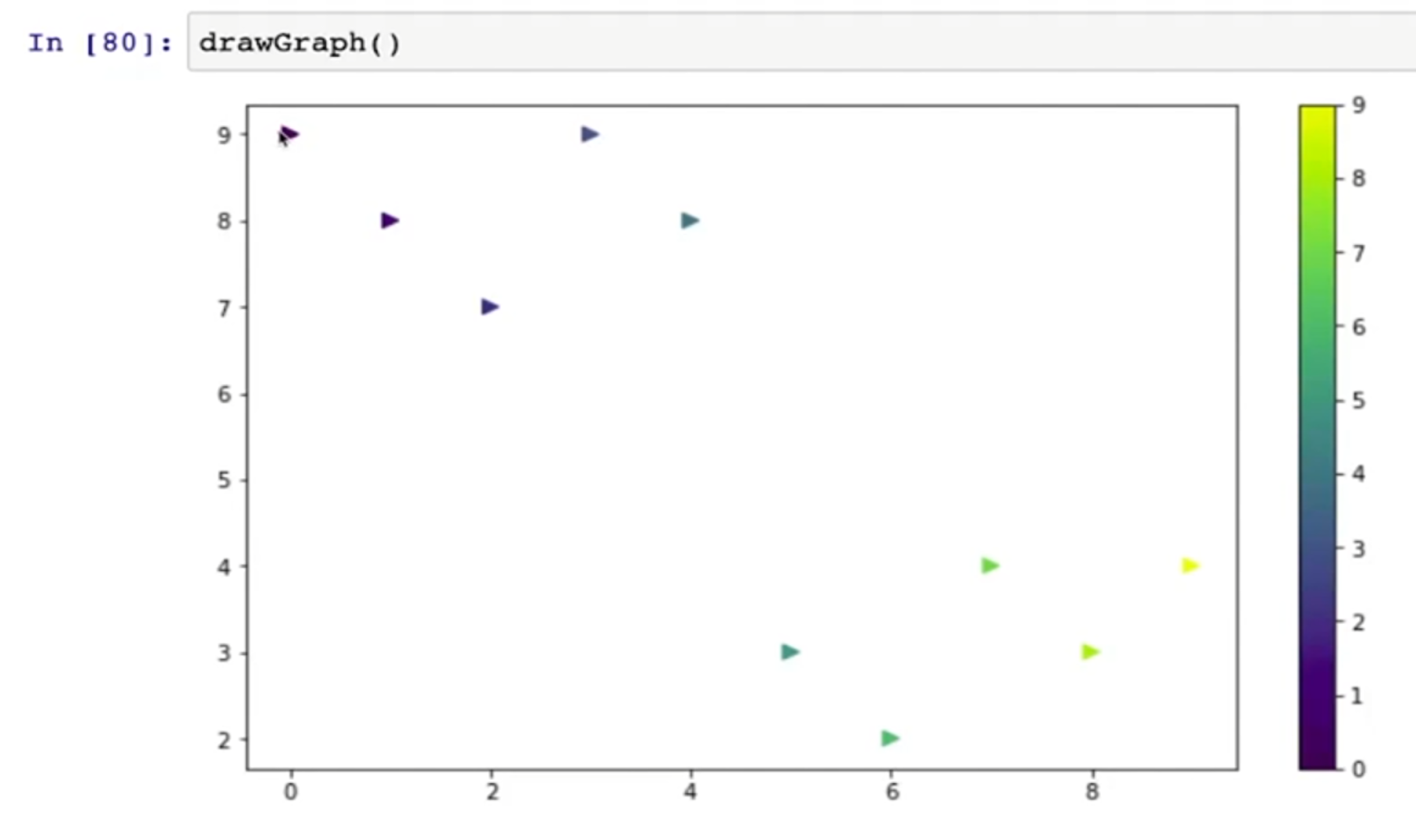
- scatter ->점을 뿌리듯이 그리는 그림
- colormap -> color 값 지정



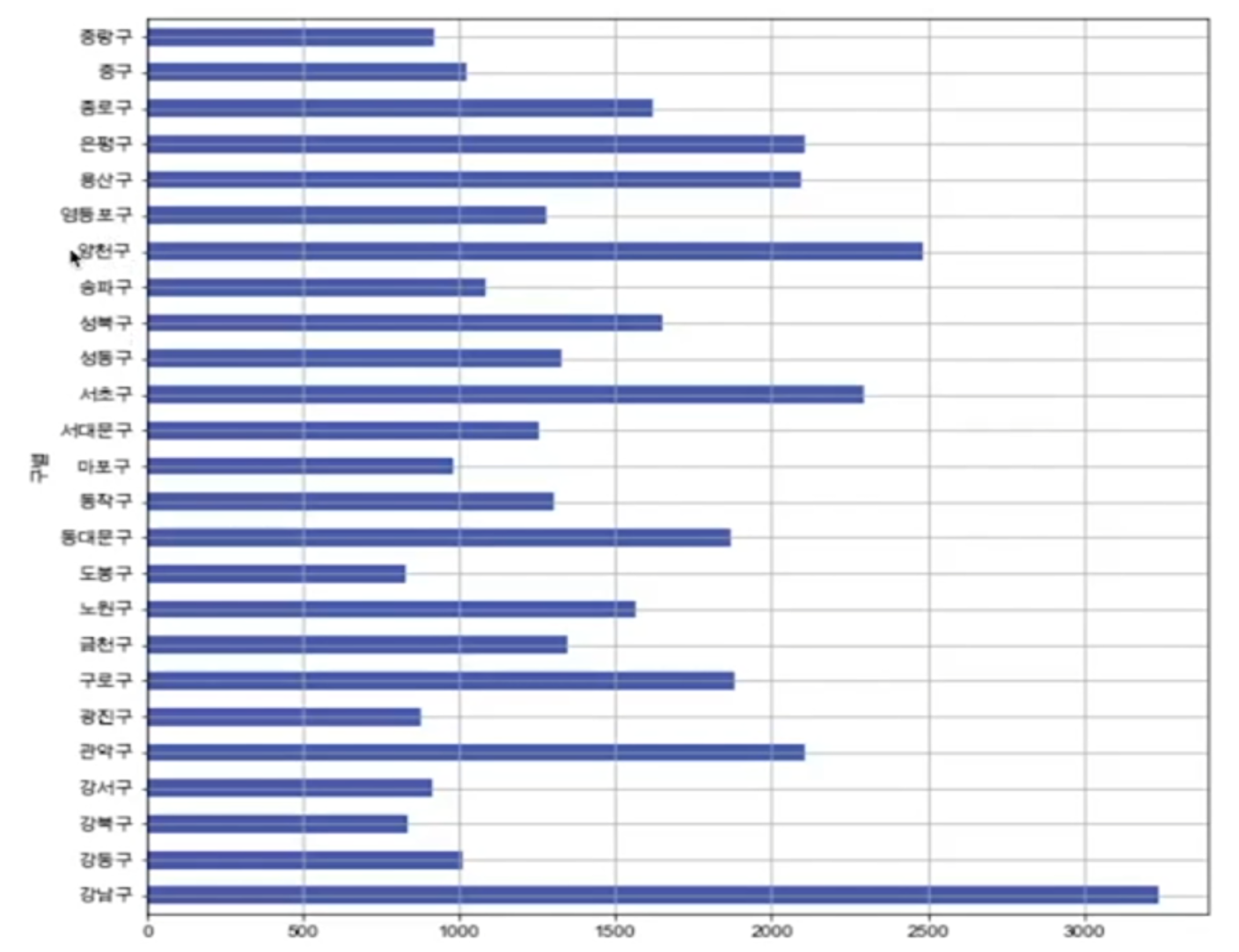
15 ~ 16 CCTV 데이터와 그래프로 표현하기
bar 그리기
- Pandas DataFrame은 데이터 변수에서 바로 plot() 명령을 사용할 수 있다
- 데이터(컬럼)가 많은 경우 정렬한 후 그리는 것이 효과적일 때가 많다
- sort_values() ->


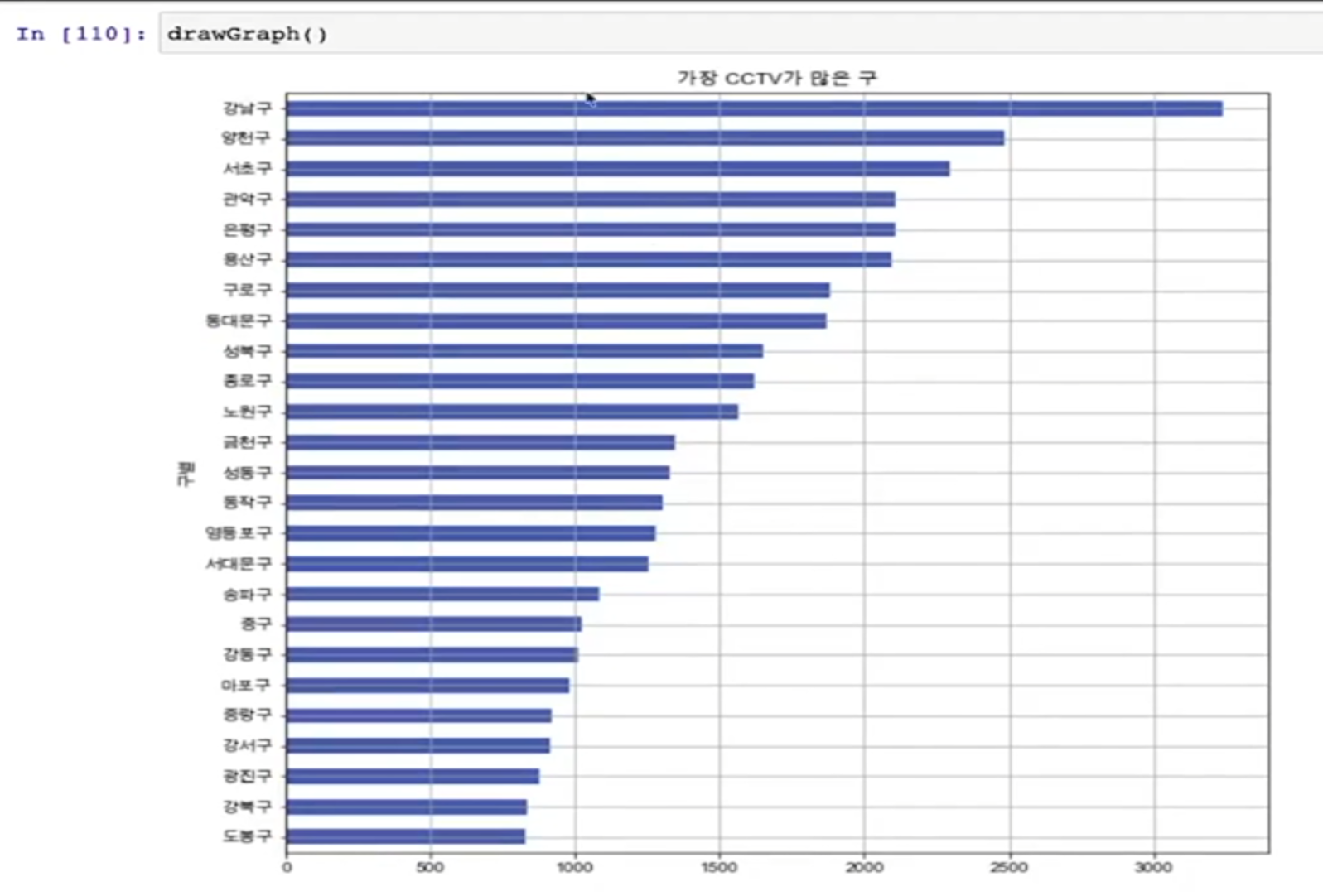

17 ~ 18 데이터 경향을 그려보자
선형회귀

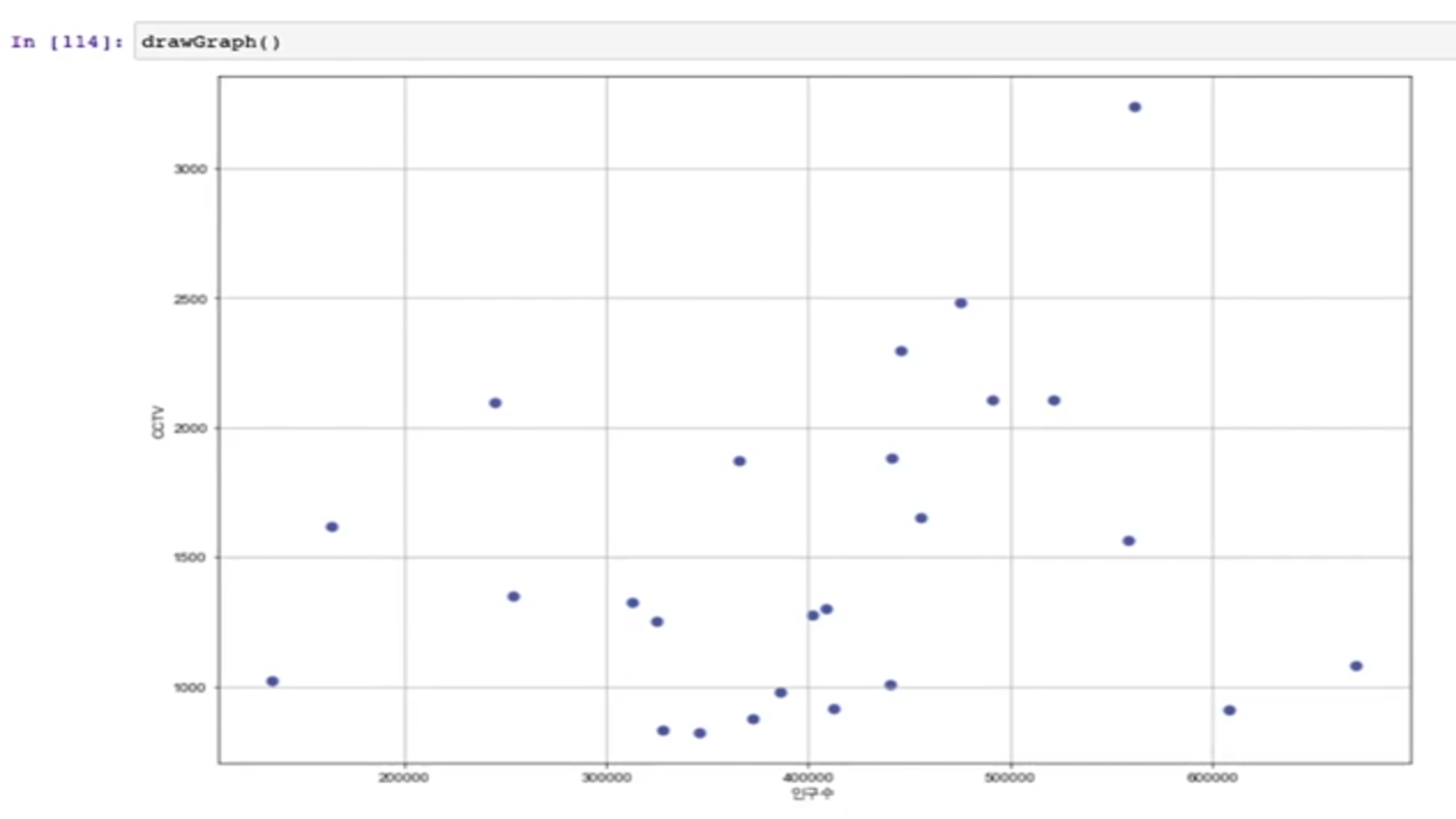
Numpy를 이용한 1차 직선 만들기
- numpy가 제공하는 간단한 함수를 이용해서 1차 직선을 만들어 그래프로 비교
- np polyfit -> 직선을 구성하기 위한 계수 계산
- np.poly1d -> polyfit으로 찾은 계수로 python에서 사용할 함수로 만들어 줌

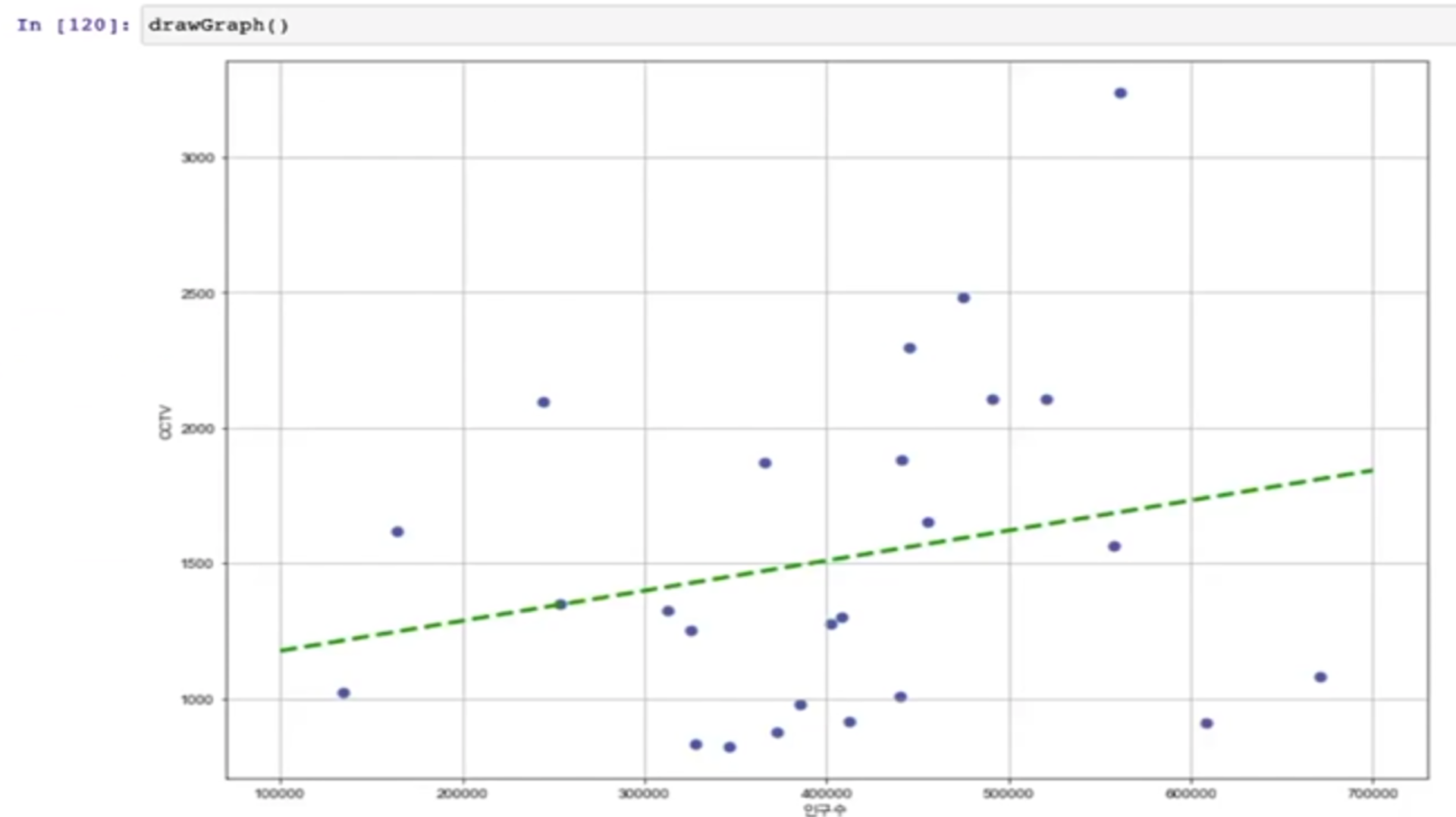
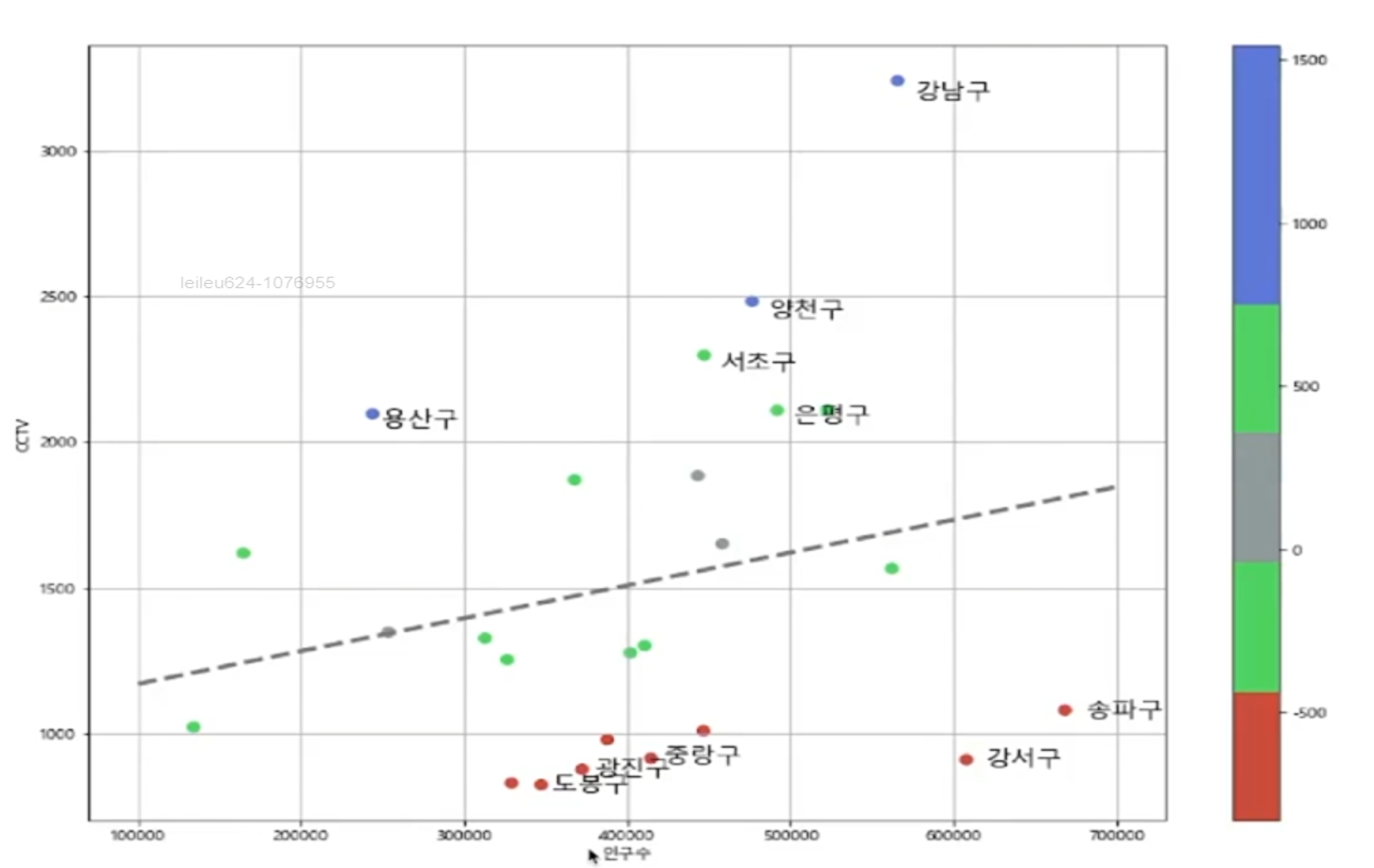
- 인구 40000인 구에서 서울시의 전체 경향에 맞는 적당한 CCTV 수를 알고 싶다면?
- 경향선을 그리기 위해 X데이터 생성
- np.linspace(a, b, n): a부터 b까지 n개의 등간격 데이터 생성




19 ~ 20 경향에서 벗어난 데이터 강조하기
그래프 다듬기
경향과의 오차를 만들자
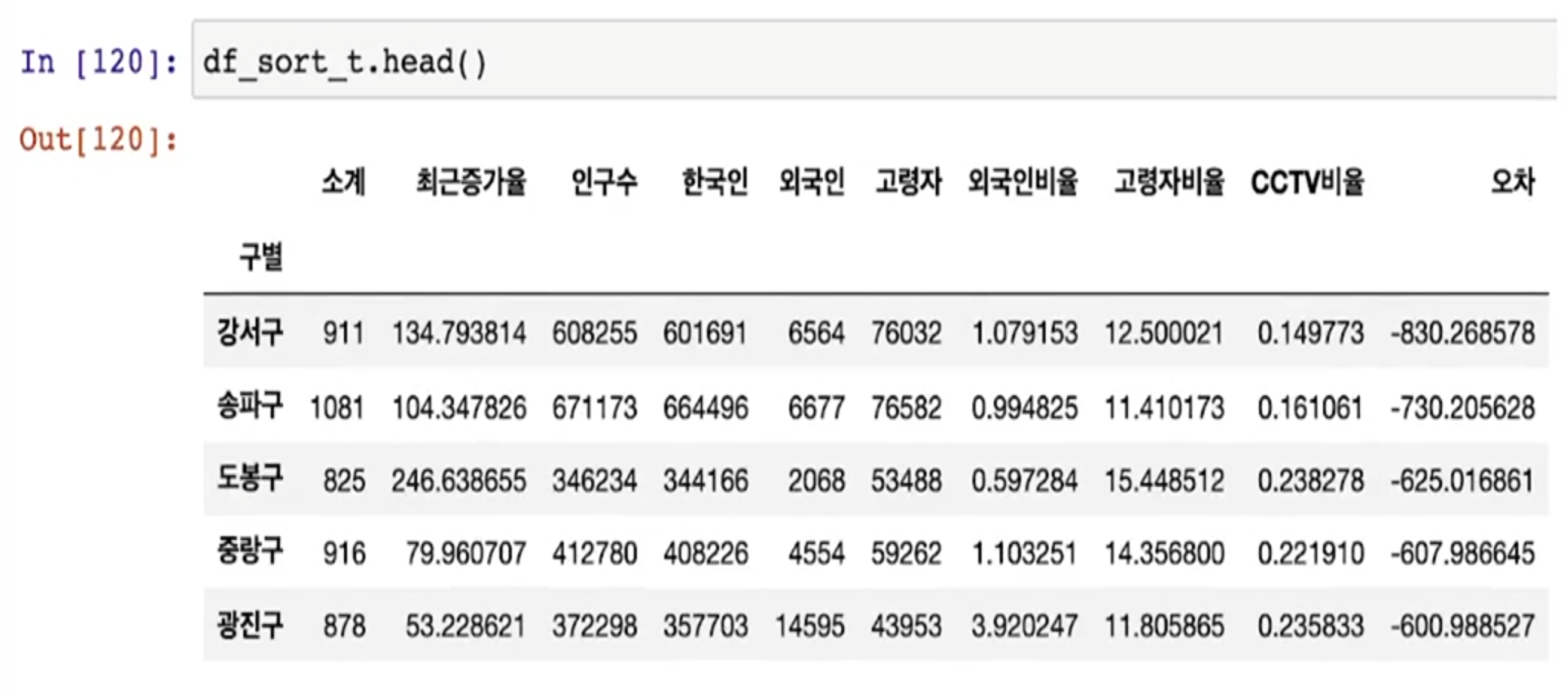
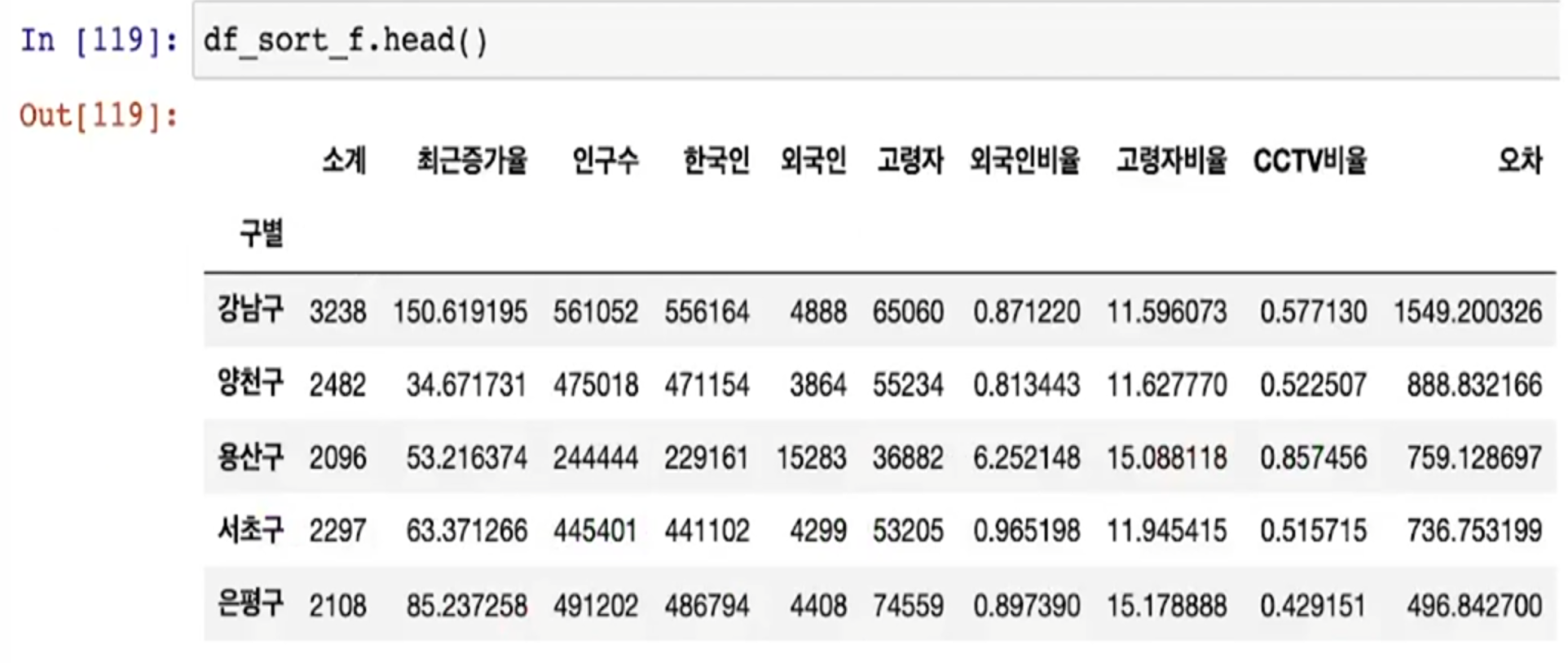
- data_result['오차'] = data_result['소계'] - f1(data_result['인구수'])
- 경향과의 오차를 만들자
- 경향은 f1 함수에 해당 인구를 입력: f1(data_result['인구수'])
- 현재값: data_result['소계']

경향 대비 CCTV를 적게 가진 구
경향 대비 CCTV를 많이 가진 구
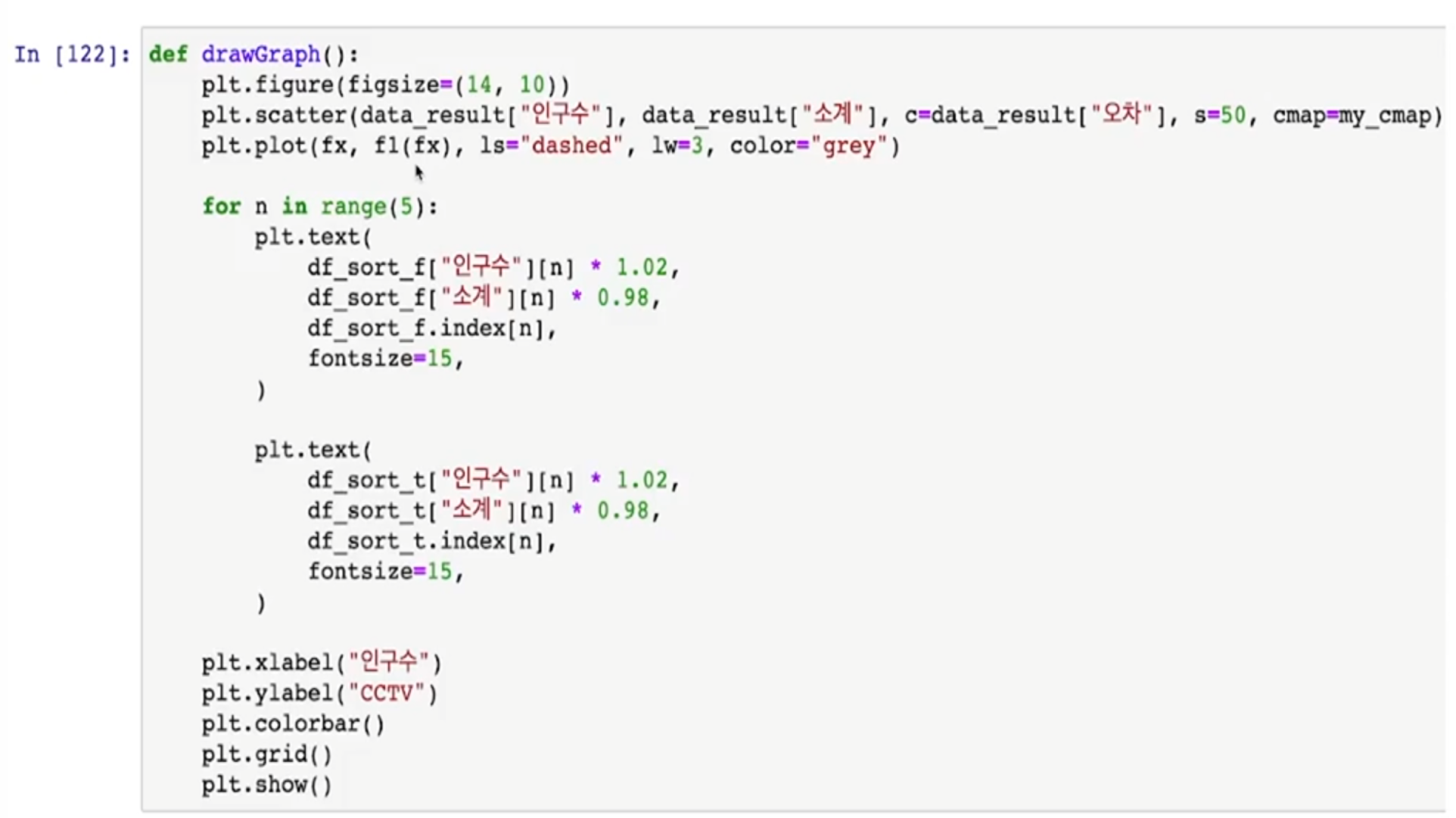
- plt.text() -> 정해진 좌표에 글짜를 찍는 함수
- s : 마커의 크기
- c : color 세팅에 방금 계산한 경향과의 오차를 적용
- cmap : 사용자 정의한 맵을 적용
- 오차가 큰 데이터 아래 위로 5개씩만 특별히 마커 앞에 구 이름을 명시



재미있었던 부분
저번에 이어서 오늘은 조금 더 구체적으로 데이터를 활용해서 그래프에 1차 함수를 추가하였다
경향과의 오차를 만들어 경향에서 벗어난 데이터를 강조하는 부분이 새롭고 재미있었다
어려웠던 부분
어려운 부분은 아니지만 새로운 코드를 활용하고 길어지는 코드에서 오류가 좀 났었다
느낀점 및 내일 학습 계획
trend 에서 벗어난 데이터를 찾고 강조시키는 것을 배웠는데 말로 들을떄보다 그래프로 만들고 나서 이해가 더 쉬운 부분도 있었다
내일은 다음 주제 서울시 범죄 현황 데이터 분석을 공부할 예정이다

데이터 부트캠프 참여중