
그래프 탐색이란?
어떤 한 그래프와 해당 그래프의 시작 정점이 주어졌을 때, 시작점에서 간선(Edge, E)을 타고 이동할 수 있는 정점(Vertex, V)들을 모두 찾아야 하는 문제
- 차례대로 모든 정점들을 한 번씩 방문한다.
- 대표적인 그래프 탐색 알고리즘에는 너비 우선 탐색(BFS)과 깊이 우선 탐색(DFS)이 있다.
- 너비 우선 탐색(BFS): 그래프의 시작점에서 가까운 점들부터 우선적으로 탐색하며 진행한다.
- 깊이 우선 탐색(DFS): 그래프의 시작점에서 다음 브랜치로 넘어가기 전에, 해당 브랜치를 모두 탐색한다.
ex) 특정 도시에서 다른 도시로 갈 수 있는지 없는지, 전자 회로에서 특정 단자와 단자가 서로 연결되어 있는지
BFS
시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점은 나중에 순회한다. 깊이 우선 탐색(DFS)보다 좀 더 복잡하다.
- 직관적이지 않다.
- 재귀적으로 동작하지 않는다.
- 어떤 노드를 방문했었는지 여부를 반드시 검사해야 한다.(visited)
- 무한루프 조심!
- FIFO 원칙으로 탐색한다. 자료구조로 큐(Queue)를 사용한다.
- 큐를 이용해 반복적 형태로 구현한다.
- 유사한 알고리즘: Prim, Dijkstra
BFS(너비 우선 탐색) 과정
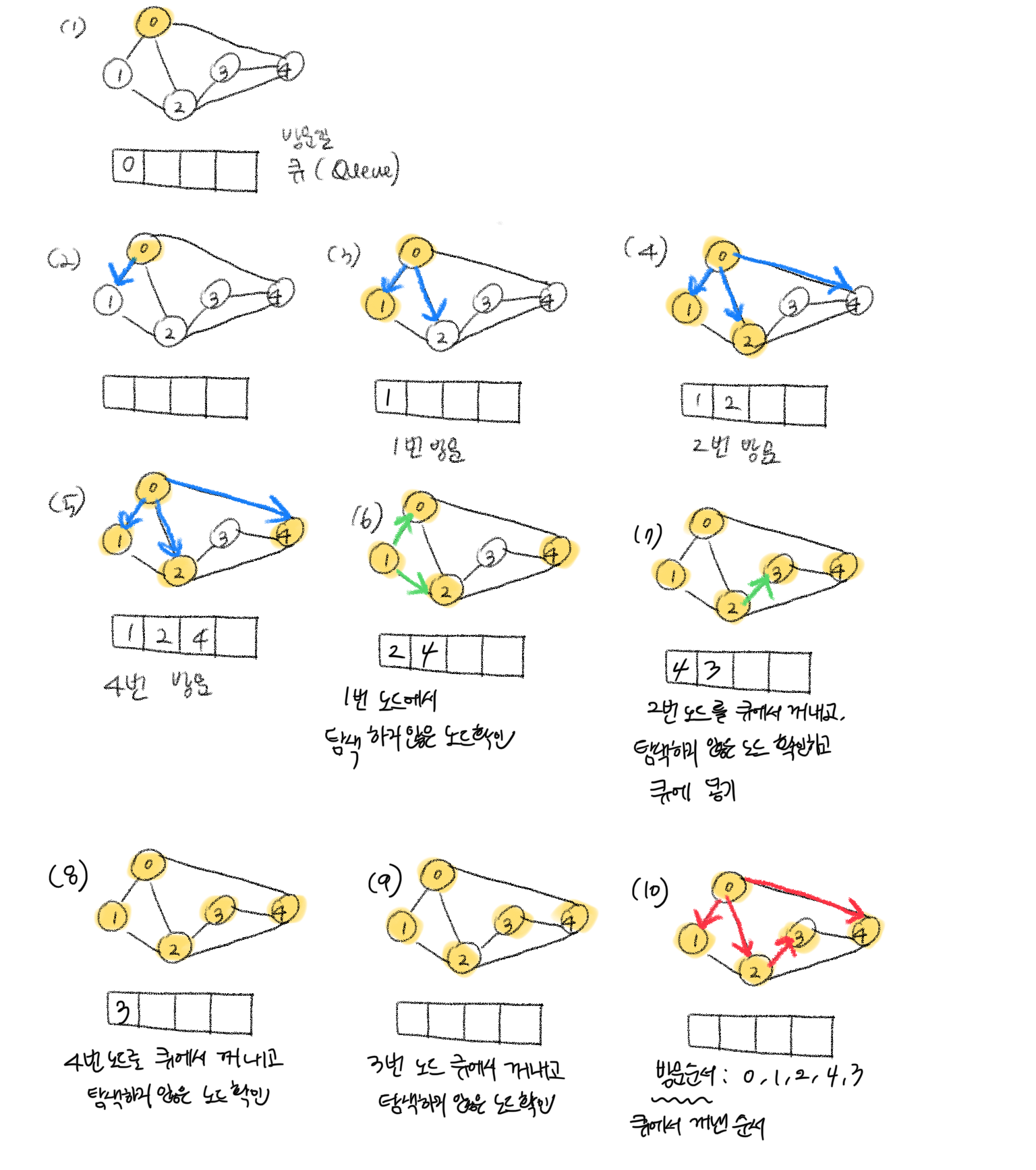
기억할 것
- 방문한 노드는 체크한다.
- 방문된 노드는 큐에 삽입한다.
- 시작 노드를 방문한다.
- 큐에 방문된 노드를 삽입한다. =>
enqueue - 초기 상태의 큐에는 시작 노드만 저장한다.
- 시작 노드의 이웃 노드를 모두 방문하고 이웃의 이웃들을 방문한다.
- 큐에 방문된 노드를 삽입한다. =>
- 큐에서 노드를 하나씩 꺼내면서 인접한 노드들을 모두 차례로 방문한다.
- 큐에서 꺼낸 노드를 방문한다.
- 큐에서 꺼낸 노드와 인접한 노드들을 모두 방문한다.
인접한 노드가 없거나, 이미 방문한 노드들만 있다면 노드를 꺼낸다. =>dequeue
- 큐에서 꺼낸 노드와 인접한 노드들을 모두 방문한다.
- 큐에 방문된 노드를 삽입한다. =>
enqueue
- 큐에서 꺼낸 노드를 방문한다.
- 큐가 소진될 때까지 계속한다.
BFS(너비 우선 탐색) 구현
큐(Queue)를 사용하여 구현한다.
pseudocode
search(Node root){
Queue queue = new Queue(); // 방문할 노드들을 저장하는 큐
root.marked = true; // 방문한 노드 체크
queue.enqueue(root); // 큐의 끝에 추가
// 큐가 다 없어질 때까지 계속한다.
while(!queue.isEmpty()){
Node r = queue.dequeue(); // 앞에 노드 추출
visit(r); // 추출한 노드 방문
// 큐에서 꺼낸 노드와 인접한 노드를 모두 차례로 방문
foreach(Node n in r.adjacent) {
// 인접한 노드가 방문되지 않은 상태라면
if(n.marked == false) {
n.marked = true; // 방문한 노드 체크
queue.enqueue(n); // 큐의 끝에 추가
}
}
}
}Java
다음은 인접 행렬을 이용해서 풀이한 코드이다.
void bfs(int start, int[][] graph, boolean[] visited){
// BFS에 사용할 큐를 생성한다.
Queue<Integer> q = new LinkedList<Integer>();
// 큐에 BFS를 시작할 노드 번호를 넣는다.
q.offer(start);
// 시작노드는 방문표시
visited[start] = true;
// 큐가 빌 때까지 반복한다.
while(!q.isEmpty()) {
int nodexIndex = q.poll();
for(int i =0; i < graph[nodeIndex].length; i++){
int temp = graph[nodeIndex][o];
// 방문하지 않았으면 방문처리 후 방문할 큐에 넣는다.
if(!visited[temp]){
visited[temp] = true;
q.offer(temp);
}
}
}
} 시간 복잡도
- 인접리스트: O(N+E)
- 인접 행렬: O(N^2)
DFS
노드에서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색한다.
- 미로에서 한 방향으로 계속 가다가 더 이상 갈 수 없게 되면 다시 가까운 곳으로 돌아와 다른 방향으로 탐색한다.
- 모든 노드를 방문하고자 하는 경우에 이 방법을 선택한다.
- 깊이 우선 탐색(DFS)이 너비 우선 탐색(BFS)보다 좀 더 간단하다.
- 단순 검색 속도 자체는 너비 우선 탐색(BFS)에 비해서 느리다.
DFS(깊이 우선 탐색) 과정
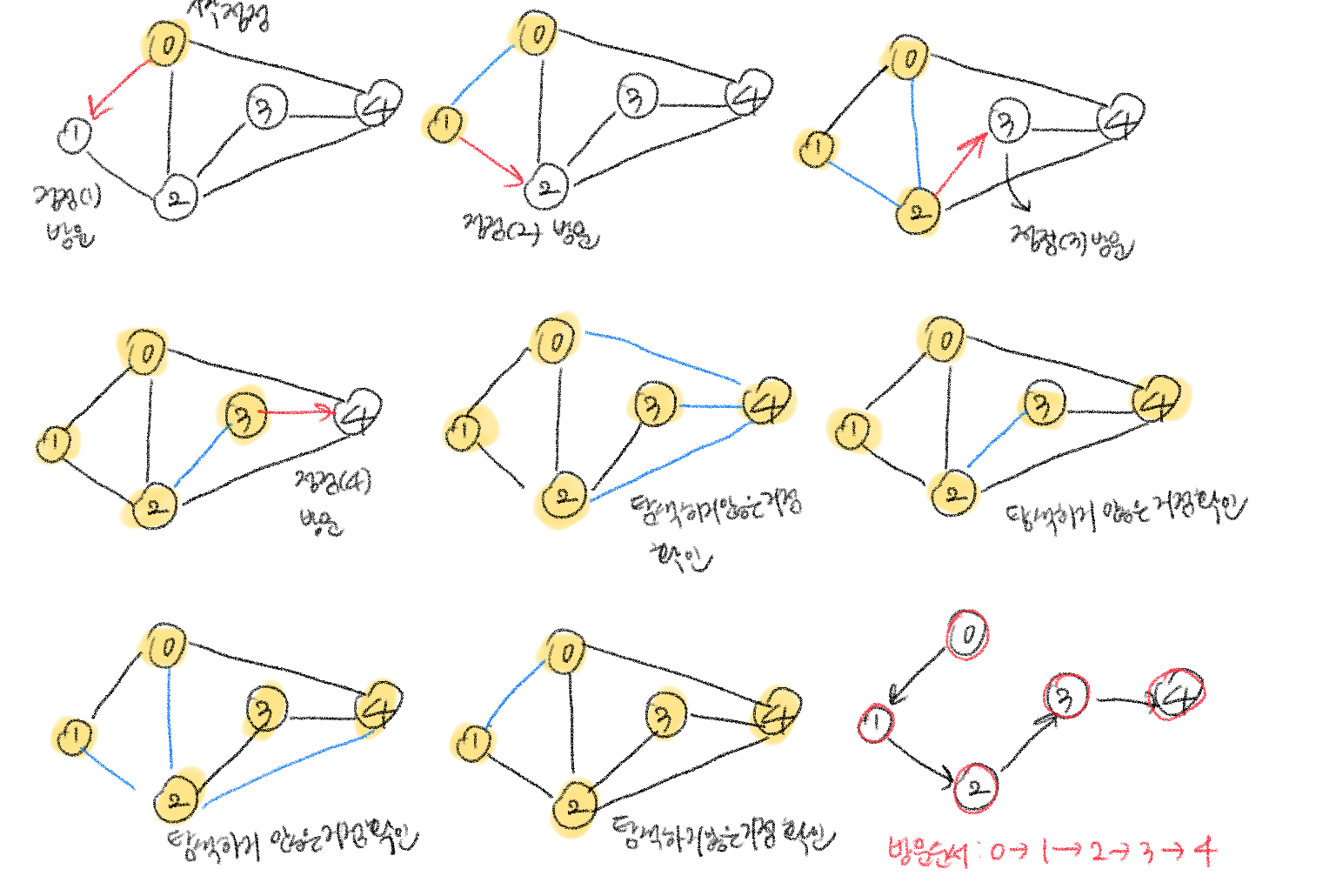
- 시작노드(a)를 방문한다.
- 방문한 노드는 방문 표시한다. (방문 여부를 검사하지 않으면, 무한루프에 빠질 수 있다.)
- 방문한 노드(a)와 인접한 노드(b)들을 차례로 순회한다.
- 인접한 노드가 없다면 종료한다.
- 인접한 노드(b)를 방문했다면, 해당 노드(b)에서 인접한 노드를 전부 방문한다.
- 해당노드를 시작 정점으로 다시 DFS 하여 b와 이웃한 노드들을 방문한다.
- 인접한 노드(b)를 전부 탐색했다면, 다시 시작노드(a)에서 방문하지 않은 노드를 찾는다.
DFS(깊이 우선 탐색) 구현
구현 방법
- 순환 호출을 이용한다.
- 명시적인 스택을 사용하여, 방문한 정점들을 스택에 저장했다 다시 꺼내어 사용한다.
의사코드
void search(Node root) {
if (root == null) return;
// 1. root 노드 방문
visit(root);
root.visited = true; // 1-1. 방문한 노드를 표시
// 2. root 노드와 인접한 정점을 모두 방문
for each(Node n in root.adjacent) {
if (n.visited == false) { // 4. 방문하지 않은 정점을 찾는다.
search(n); // 3. root 노드와 인접한 정점을 시작 정점으로 DFS를 시작한다.
}
}
} 시간 복잡도
- DFS는 그래프(정점의 수: N, 간선의 수: E)의 모든 간선을 조회한다.
- 인접 리스트로 표현된 그래프:
O(N+E) - 인접 행렬로 표현된 그래프:
O(N^2)
- 인접 리스트로 표현된 그래프:
Reference

https://mywnajsldkf.tistory.com -> 이사 중
감사합니다! 😌