
사용이유
MySQL에서는 PK로 대부분 AUTO_INCREMENT값이나 UUID값으로 설정을 하곤 한다.
개인적으로 PK를 AUTO_INCREMENT로 사용하는 이유는 사용하기 쉽고 알아보기도 쉬워서이다.
하지만 분산 환경에서의 고유성, 값 유추 불가등의 이유로 UUID를 PK로 많이 택하는 것 같다.
내가 개인적으로 하는 프로젝트 규모에서는 AUTO_INCREMENT로도 충분히 가능하며 메모리나 성능면에서 더 좋다는 것은 분명하다.
그래도 추후에 UUID를 제대로 사용하기 위해 이번에 사용해보면서 기본적으로 어떤 점을 고려해야하고 AUTO_INCREMENT에 비해 보완해야 할 점은 무엇이였는지를 정리해 보고자 한다.
그럼 시작!
1. UUID 단점이요?
UUID의 단점은 알아보기 힘들다는 점도 있지만 가장 큰 단점은 차지하는 크기과 Insert시 재정렬 과정에서의 성능 저하이다.
먼저 크기부터 살펴보자.
1) 저장 크기
MySQL은 UUID 생성시 내부적으로 버전1의 UUID를 생성하기 때문에 v1을 기반으로 한다.
UUID는 다음과 같이 32개의 16진수로 구성이 되며 5개의 그룹을 하이픈(-)으로 구분하여 표기한다.
ecb2e2ec-cfa2-11ed-b33a-9cb6d0ff1e62
각 그룹의 의미를 알아보면 다음과 같은데
- ecb2e2ec: TimeStamp의 low 32비트 (초)
- cfa2: TimeStamp의 middle 16비트 (분)
- 11ed: TimeStamp의 high 12비트와 최상위 비트(맨 왼쪽)은 UUID의 버전을 나타는데 여기선 버전 1임을 나타낸다.
- 4, 5번째 그룹: MAC주소와 같은 컴퓨터 장치에 대한 정보를 포함하고 있으며 단일 서버에서 생성되는 경우 거의 동일하다.
이 UUID 값을 저장하려면 하이픈(-)을 포함하여 36개의 문자가 필요하므로 레코드당 몇 바이트를 차지하는지 INT 타입과 비교해보도록 하자.
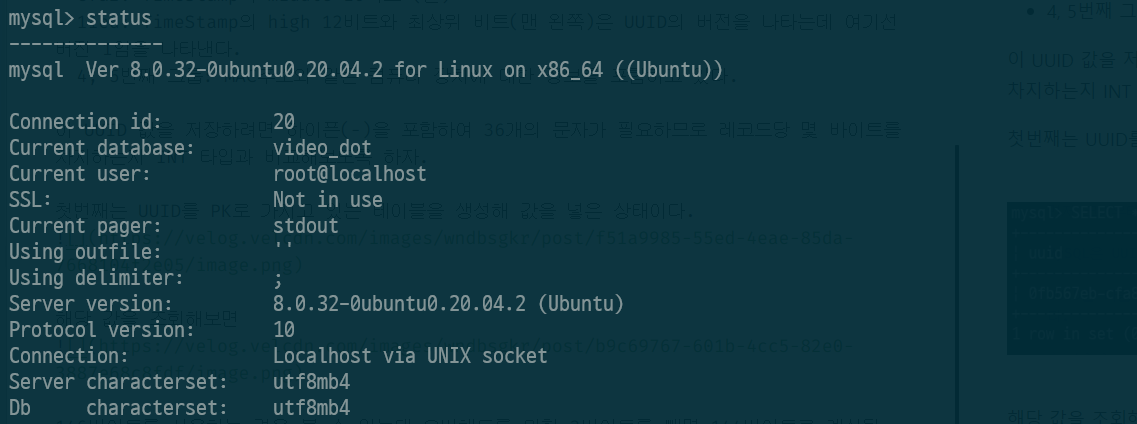
첫번째는 UUID를 PK로 가지고 있는 테이블을 생성해 값을 넣은 상태이다.

해당 값을 조회해보면

146바이트를 사용하는 것을 볼 수 있는데 오버헤드를 위한 2바이트를 빼면 144바이트로 계산된 것을 볼 수 있다.
이것은 내 DB의 CHARSET이 utf8mb4로 설정되어 있기 때문에 1문자당 4바이트로 게산된 결과이다.
만약 1문자당 3바이트로 계산이 되었다면 utf8로 설정되어 있을 것이다.
그럼 AUTO_INCREMENT로 설정하면 얼마나 차지할까?
동일하게 AUTO_INCREMENT를 PK로 가지고 있는 테이블을 생성해 값을 넣은 상태이다.

그럼 146바이트에 비해 적은 4바이트를 차지하는 것을 볼 수 있으며 이러한 차이 때문에 UUID를 사용할 계획이라면 VARCHAR 타입으로 생성한 UUID는 충분히 고려할 점이 된다.
2) Insert 성능
다음으로 알아볼 단점은 UUID의 삽입시 성능 문제이다.
이 문제를 이해하기 위해선 간단하게 MySQL의 PK가 Insert시 어떻게 동작하는지를 살펴볼 필요가 있다.
Clustered Index
기본적으로 Table을 생성할 때 Engine을 지정하지 않으면 InnoDB Engine으로 생성이 된다.
근데 InnoDB Table은 기본적으로 각 Table의 PK를 clustered index로 사용하는데 이 clustered index는 index가 하나 추가 될때(PK값이 하나씩 생성될때)마다 index를 재정렬 하고 이 순서대로 실제 테이블의 데이터를 배치한다.
어떻게 정렬하는데요?
InnoDB의 index는 B+tree라는 자료구조로 저장이 되는데 간단하게 알아보자.
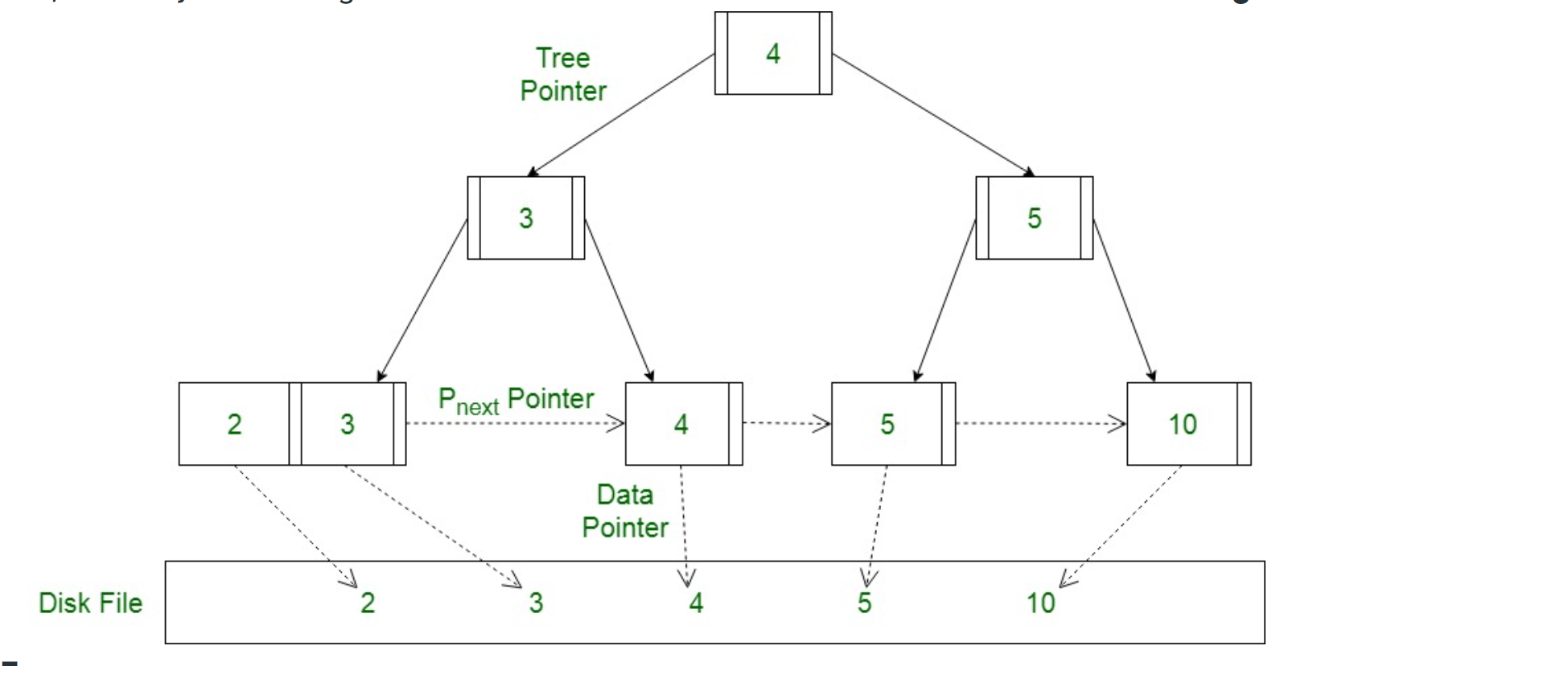
B+tree란 자식 노드를 최대 2개 이상 가질 수 있고 leaf 노드의 레벨이 전부 같은 자료구조이다.
B+tree는 leaf 노드가 아니면 자신의 Key와 자식 노드에 대한 포인터를 가지고 있고 각각의 leaf 노드는 Key와 data pointer를 가지고 있는 각각의 레코드가 정렬되어 있으며 같은 레벨에 있는 다음 leaf 노드로 가기 위한 포인터로 구성되어 있다.
그럼 순차적으로 증가하는 AUTO_INCREMENT의 경우 단순히 마지막 leaf 노드로 가서 값을 추가하면 되지만(재균형을 이루는 과정은 제외) 랜덤 값으로 생성되는 UUID의 경우 자신이 들어갈 알맞은 순서를 찾아야 하기 때문에 속도면에서 더 느리다.
그럼 어떻게 보완하나요?
1) 저장 크기
크기를 줄일 수 있는 방법은 16진수로 이루어진 UUID를 이진 문자열로 변환해주는 MySQL의 UNHEX() 함수와 UUID_TO_BIN() 함수를 통해 16바이트의 binary타입으로 변환해 저장하는 방법이다.
(1) UNHEX()
UNHEX()를 이용한 방법은 하이픈(-)으로 구분된 UUID를 16진수로만 구성하기 위해 하이픈을 제거해야 한다.

이렇게 146바이트를 차지했던 크기를 16바이트로 줄일 수 있었다.
하지만 우리가 읽을 수 없는 값들로 되어 있기 때문에 값으로 이용하기 위해선 다시 HEX() 함수를 통해 문자열로 되돌려야 한다.

(2) UUID_TO_BIN()
개인적으로 UNHEX()를 사용했었지만 앞으로는 크기와 속도 모두 해결해줄 수 있는 MySQL 내장함수를 사용하는게 맞는 것 같다.
일단 뒤에 flag는 제외하고 BIN_TO_UUID()의 결과를 보자


아까하고 결과값에 차이가 있는 이유는 UNHEX()함수는 16진수로 된 문자열을 변환해주기 때문에 하이픈을 제거하고 변환했었다.
그렇기 때문에 당연히 다시 되돌린 값도 하이픈을 제거한 값이 나올 것이다.
하지만 BIN_TO_UUID()함수는 하이픈을 포함해 UUID로 표기하는 문자열을 변환해주기 때문에 되돌리면 원래 UUID 표기법대로 되돌려준다.
2) Insert 성능
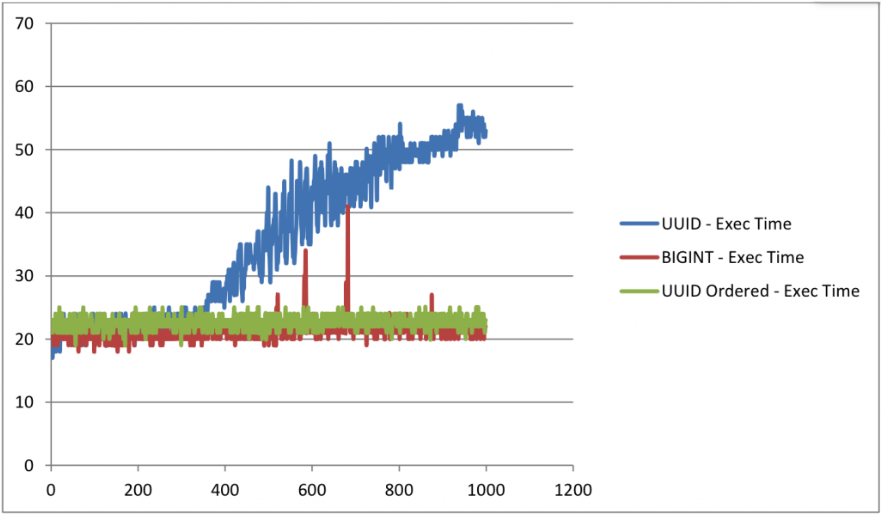
사실 BIN_TO_UUID()함수를 알았다면 간단히 이 함수를 썼겠지만 여기에서 TimeStamp를 기반으로 하는 UUID 버전 1의 구성 순서를 변경해 AUTO_INCREMENT와 비슷한 성능을 내는 글을 발견해 사용했었다.
구성 순서를 변경하면 일반 AUTO_INCREMENT와 윗 방식의 UUID 삽입 속도가 크게 차이나지 않는다는 것이다.
사실 아까 UUID_TO_BIN()함수의 flag를 나중에 설명한다고 했던 이유는 위에서 설명하는 변형된 UUID와 똑같은 구성을 flag값을 통해 생성할 수 있기 때문이다.
단지 둘의 차이는 하이픈이 있고 없고의 차이이다.
구성 순서를 어떻게 변경한다는 거에요?
아까 UUID의 구성 요소를 다시 보자.
ecb2e2ec-cfa2-11ed-b33a-9cb6d0ff1e62
이렇게 표기된 UUID의 1~3번째 그룹은 TimeStamp에서 생성되는 값들이라 했었다.
3번째 그룹이 time의 high라 했었고, 1번째 그룹이 time의 low라 했는데 비교적 빠르게 변하는 low부분을 나는 초로 생각했고, high부분을 시로 생각했다.
그럼 윗 글대로 1,3그룹을 바꾸면 시분초의 형태가 될 것이고 새로 생성할 때마다 초부터 늘어나는 순차적인 구조를 이뤄 인덱스 재정렬 시 효율적이라고 생각했기 떄문이다.
그럼 먼저 내가 프로젝트에 적용한 방법을 살펴보면
const uuid = uuidv1();
const orderedUuid = uuid.split('-');
return orderedUuid[2] + orderedUuid[1] +
orderedUuid[0] + orderedUuid[3] + orderedUuid[4];간단히 UUID 생성 라이브러리로 버전1을 생성하고 순서를 변경해서 return시켜 회원가입 시 해당 UUID로 PK를 설정하였다.
그리고 회원가입시 UNHEX()함수를 통해 binary로 변환하여 데이터베이스에 넣어 사용시에는 HEX()로 다시 복구해 사용했었다.
await this.dataSource.manager.query(
`INSERT INTO user(id, phone_number, nickname)
VALUES(UNHEX(?), ?, ?)`, [id, phoneNumber, nickName]
);마지막으로 flag를 통해 UUID의 구성을 변경하는 법에 대해서 알아보자.
UUID_TO_BIN()함수는 변환할 UUID말고도 flag값으로 0과 1을 넘겨줄 수 있다.
- 0: flag값을 넘겨주지 않았을 때와 똑같은 결과로 문자열을 그대로 변환한다.
- 1: 위의 글과 같이 첫번째 그룹과 세번째 그룹의 순서를 변경하여 저장한다.
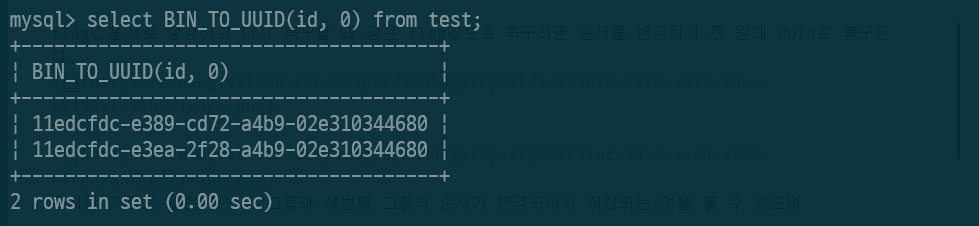
이 때 주의할 점은 다시 BIN_TO_UUID()함수로 되돌릴 때 같은 flag값을 동일하게 주지 않는다면 제대로 복구되지 않는다고 한다.
flag값을 1로 설정하고 다시 복구할 때 같은 flag값으로 복구하면 순서를 변경하기 전 원래 UUID로 복구된다.

하지만 저장된 값은 첫번째 그룹과 세번째 그룹의 순서가 변경되어서 저장되는 것을 볼 수 있으며

같은 flag값을 주지 않았을 때는 원래 값으로 복구되지 않는 것을 볼 수 있다.
이렇게 간단하게 UUID의 단점들을 보완해 사용할 수 있는 방법을 알아보았는데 이제는 내장 함수를 쓸 것 같다!
마치면서...
사실 MySQL 내장함수를 처음부터 알고 그것을 사용했다면 왜 UUID의 순서를 변경해야 하는지 순서를 변경한게 왜 index 정렬에 효과적인지등의 이유를 알 수 있었을까 하는 생각이 든다.
UUID를 사용하면서 가장 불편했던건 찍히는 로그를 보거나 Postman으로 테스트를 날려볼 때 복사를 해서 붙여넣어야 한다는 점...
참고
B+tree 이미지
Storing UUID Values in MySQL
B+Tree index structures in InnoDB
MySQL - UUID 활용 - PK 로 사용
wikipedia uuid
