0. 서론, 리팩토링
어제 그제 했던 작업들 중 풀리퀘 올렸을 때 리팩토링 리뷰가 들어온 게 있어서 몇 가지 수정을 하고, 이후에 추가적인 개선을 할 필요가 있는 부분을 정리해보려고 한다.
그리고 한 가지 중요한 부분은 내가 작업물이 겹쳐서 풀리퀘가 어마어마하게 길어진 사항이 있었는데, 그 원인을 찾았다.
다중 브랜치로 작업하는 것이 익숙하지 않아서 발생한 큰 실수인데 개발용인 dev 브랜치에서 새 브랜치를 checkout 해서 작업을 시작했어야 하는데 자꾸만 작업하던 것에서 다시 checkout 하는 바람에 풀리퀘가 너무 길어진 것이다.
<리팩토링 및 개선할 목록>
- 즐겨찾기 검색 페이징 된 거 다시 List로 변경
- 생각보다 완성 후 결과물이 짧아서 List로 변경할까 고민하던 차에 리뷰까지 동일 의견이 나와서 이 부분은 리팩토링 하기로 함
- 동시성 제어 개선을 위해 분산 락 적용 고려하기
- 스케줄러와 동시성 제어 때 분산서버로 2개가 돌아간다고 해서 그 부분을 생각해서 스케줄러 간격을 더 늘려야 될 거 같다.
- 분산 락에 대해 모르는 부분이 많아서 그 부분을 어떻게 걸어야 할지 문서화 및 공부하기
- 키워드 및 즐겨찾기 검색 속도 개선을 위한 부분 공부하기
1. 리팩토링
1. 즐겨찾기와 키워드 리팩토링
즐겨찾기에 리스트를 적용해주고 그 김에 주석을 차라라란 달아주었다.
이걸 보면 이제 QueryDSL을 몰라도 이해할지니..
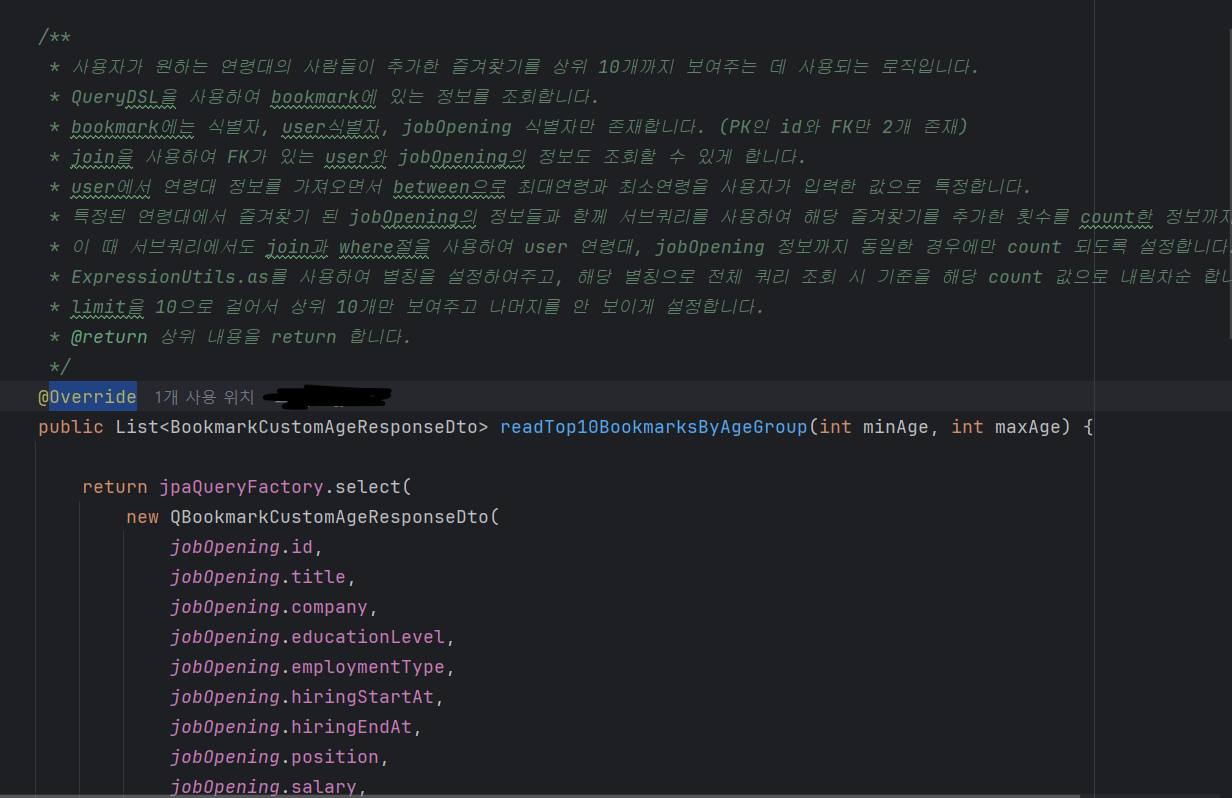
하나씩 뜯어서 보다보니 예외처리할 것도 더 발견했다.
어제는 minAge 와 maxAge에 각각 min이랑 max만 Vaild해주었느데 범위값이 이상하게 들어가도 되었던 문제가 있었다. 생각해보니 min값만 적용되면 최소나이는 int 최대치로 적을 수 있고, max만 적용한 최대나이도 마찬가지의 문제가 발생한다. 0 이하의 값도 받아지는 불상사가 일어나는 것이다.
그래서 dto 단에서 1차로 수습을 해 주었다.
@Min(value = 20, message = "최소 나이는 20세 이상이어야 합니다.")
@Max(value = 79, message = "최소 나이는 79세 이하여야 합니다.")
int minAge,
@Min(value = 20, message = "최대 나이는 20세 이상이어야 합니다.")
@Max(value = 79, message = "최대 나이는 79세 이하여야 합니다.")
int maxAge이러한 형태로 수습을 해주고, Service 단에서는 Controller 단에서 넘겨진 requestBody 값을 각각 최소, 최대 나이로 분리하는 작업만 했었는데 이 때 최소나이가 최대나이보다 적거나 같은 게 맞는지 검증하는 로직을 추가했다.
public List<BookmarkCustomAgeResponseDto> readTop10BookmarkByAgeGroup (
ReadBookmarkAgeRequestDto requestDto
) {
int minAge = requestDto.minAge();
int maxAge = requestDto.maxAge();
// 최소나이가 최대나이보다 클 때 예외처리하는 로직 추가
if (minAge > maxAge) {
throw new BadRequestException(ClientErrorCode.MIN_AGE_EXCEEDS_MAX_AGE);
}
return bookmarkRepository.readTop10BookmarksByAgeGroup(minAge, maxAge);
}이런 식으로 예외를 처리해주면 예외 숫자를 뭘 넣어도 예외 메시지가 제대로 나오게 된다. 뭔가 이상한 값 넣고 실험하면서 재밌었다. 그리고 BadRequestException(ClientErrorCode.MIN_AGE_EXCEEDS_MAX_AGE);이 부분은 내가 예외처리에 대한 리팩토링를 했을 때 만든 부분인데, Exception 클래스를 해당 상태에 대한 이름으로 바꾸고, ErrorCode Enum도 각각 인증 관련이면 auth, 클라이언트의 요청 관련이면 Client , 단순 데이터 처리 문제면 Data 등으로 바꾸어 주었다. 이로써 우리는 코드 한 줄을 보고 아, 이것은 잘못된 요청으로 인한 예외처리이며 클라이언트와 관련된 에러이구나 할 수 있는 것이다.
2. 컨플릭트!

으아아아아!!! dev랑 검색 관련 코드를 머지한 후에 어제 검색 다음으로 개선한 동시성 제어 부분에서 제대로 컨플릭트가 났다. GPT한테 물어보니 git에서는 대소문자 구분을 안해서 지금 대문자 패키지가 삭제되었는데 소문자가 삭제된 줄 알고 그 속에 있는 파일이 이상하게 꼬여버린 것 같다나...
아주그냥 극혐이다. 그래서 GPT에게 요청해서 콘솔 창에서 물리적으로 해당 파일을 삭제하고 깃허브에서 값을 복붙해 오는 걸로 해결했다. 그러나 이건 1차원적인 해결법이라서 다음에는 못 쓸 방법이다. 솔직히 이번에 컨틀릭트 난 코드는 레포지토리 하나라서 다행이지 만약에 impl 된 코드거나 Service 단이거나 그러면 정말 끔찍했을 것이다.
확실하게 이제는 dev에서 새 브랜치 파는 걸 기억할 수 있을 거 같다.
2. 테스트코드
1. 산넘어 산, 결합도가 너무 높아
테스트 코드를 한창 열심히 작성하는데, 아무리 해도 단위 테스트가 힘들다는 문제가 있었다. 비관적 락을 패키지 분리를 해서 집계 테이블만 비관적 락을 걸었으니 그 쪽만 동시성 테스트를 해야하고, 조회는 또 조회 따로 조회 테스트를 해야한다.
또한 스케줄러를 만들어서 동기화를 했기 때문에 동기화 작업의 테스트코드를 짜야했다. 그러나 나는 아무리 여러 번 시도해도 뭔가 하나의 기능만 테스트를 작성해도 다른 기능까지 딸려오는 문제가 있었다. 아무래도 이게 그거라고 생각했다. 결 합 도...
@Test
@DisplayName("비관적 락 적용 후 동시에 채용공고를 클릭했을 때")
void 비관적_락_여러_사용자가_동시에_채용공고_클릭() throws InterruptedException {
//given
JobOpening jobOpening = jobOpeningRepository.findAll().stream()
.findFirst()
.orElseThrow(() -> new RuntimeException("테스트를 위한 채용공고 데이터가 없습니다."));
long startTime = System.nanoTime();
AtomicInteger successCount = new AtomicInteger(0);
AtomicInteger failureCount = new AtomicInteger(0);
Long jobOpeningId = jobOpening.getId();
int totalRequests = 100;
int totalThreads = 10;
CountDownLatch latch = new CountDownLatch(totalRequests);
ExecutorService executorService = Executors.newFixedThreadPool(totalThreads);
//when
for(int i=0;i<totalRequests;i++) {
executorService.submit(() -> {
try {
jobOpeningService.getJobOpeningUrlAndIncreaseViewCount(jobOpeningId);
successCount.incrementAndGet();
} catch (Exception e) {
failureCount.incrementAndGet();
log.info("예외발생", e);
} finally {
latch.countDown();
}
});
}
latch.await();
executorService.shutdown();
//then
long duration = System.nanoTime() - startTime;
//then
log.info("총 소요시간: {}", duration / 1_000_000);
log.info("초기 요청 수: {}", totalRequests);
log.info("성공한 요청 수: {}", successCount);
log.info("실패한 요청 수: {}", failureCount);
assertThat(successCount.get() + failureCount.get()).isEqualTo(totalRequests);
}이런 형태로 테스트 코드를 작성했었는데 바로 여기서 문제를 깨달은 것이다. 고치려고 보니 셋 중 뭘 테스트 할 때도 getJobOpeningUrlAndIncreaseViewCount를 실행해줘야한다는 걸 깨달았기 때문이다. 그리고 이 코드가 책임분리가 안된 최악의 메서드라는 걸 깨달아버렸다.
/**
* ViewCount 정보를 관리하는 테이블과 채용공고가 올라오는 테이블에서 각각 id값(채용공고 id)으로 조회와 조회수 업데이트를 합니다.
* viewcount 테이블에서 비관 락이 작동하여 count 값의 정합성을 유지합니다.
* @param id 채용공고 사이트에 대한 식별 id
* @return 리다이렉트 된 페이지의 url
*/
@Transactional
public String getJobOpeningUrlAndIncreaseViewCount(Long id) {
JobOpening jobOpening = jobOpeningFindByService.findById(id);
JobOpeningViewCount jobOpeningViewCount = jobOpeningViewCountRepository.findByForUpdateViewCount(id)
.orElseGet(() -> {
JobOpeningViewCount newViewCount = JobOpeningViewCount.create(jobOpening); // 초기 조회수 0
return jobOpeningViewCountRepository.save(newViewCount);
});
String url = jobOpening.getJobOpeningUrl();
if (!url.startsWith("http")) {
url = "https://" + url;
}
jobOpeningViewCount.increaseViewCount();
return url;
}이 메서드인데 아주 그냥 다 짬뽕이 나 있었다.
jobOpening으로 조회를 하고, 그걸 이어서 viewCount레포지토리 단에서 카운트를 올려버렸다. ㅋㅋㅋㅋㅋ
거기로 안 끝나고 url도 조회해서 리다이렉트까지 했다. 총체적 난국이다. 그래서 나는 일단 다 뜯어고치기로 했다.
2. 처음부터 단일책임 원칙을 지키자
컨트롤러 단에서 애초부터 3개를 나누고, 각각 서비스 메서드로 호출하는 방식으로 고쳤고, 그걸 실행하는 것까지 했는데 문제는 해결하는 데에 급급해서 기록을 제대로 못 했다. 이 부분에 대해서는 나중에 테스트 코드를 짜면서 한 번 더 다뤄봐야 할 거 같다. 단일 책임 원칙을 처음부터 잘 생각하고 코드를 작성했다면 이런 문제가 없었을 거 같다는 생각이 들면서 아쉬웠다.
그리고 현재 테스트 코드 외의 분리된 메서드들은 모두 머지가 된 상태라서 테스트 코드는 잠시 내려두고 엘라스틱 서치 관련해서 모든 팀원이 같이 공부하고 적용하기로 했기 때문에 그 쪽을 할 예정이다.
