이제 검색 기능의 기본 뼈대는 만들어졌으니, 다시 비관적 락의 성능개선을 목표로 작업을 이어가보려한다.
1. 비관적 락을 빠르게 하는 법을 찾기
1. 내 머리로 생각해보기
일단 비관적 락을 빠르게 하려면 락이 걸리고 작업이 진행될 때까지 대기시간이 걸리기 때문이다. 비관적 락을 걸면서도 속도를 개선하려면 어떤 식으로 구현을 해야할까?
내 머리속에서 추측한 생각으로는 업데이트를 잠그는 방식이 아니고 일단 조회를 하고, 락을 나중에 거는 방식이다. 조회 -> 조회는 되면서 락은 딜레이 되는 것이다.
조회 수가 바로 반영되지 않는다는 단점이 있지만, 그래도 이런 방법이 있다면 좋지 않을까? 일단 비교분석을 위해 저번에는 안 했던 도구들을 찾아보기로 했다.
2. 도구를 찾아라 (도커 + 그라파나)
솔직히 도구들을 찾아봤을 때 이미지화 하는 도구가 뭔지 바로 찾긴 어려웠다. 다들 엘라스틱 서치 + 키바나 같은 건 쓰고 있지만 인텔리제이를 쓰는 윈도우 환경에서 간단하게 도구를 쓰려면 뭘 해야하는지 알려주는 글은 찾기 어려웠다.
그래서 GPT 선생님에게 도움을 구한 결과, 도커와 그라파나를 조합해서 써보라고 하더라. 이미 도커는 쓰게될 거 같아서 다운받아 놨고, 현재는 그라파나까지 실행 전 도커 쪽에 이미지로 다운받고 있다.
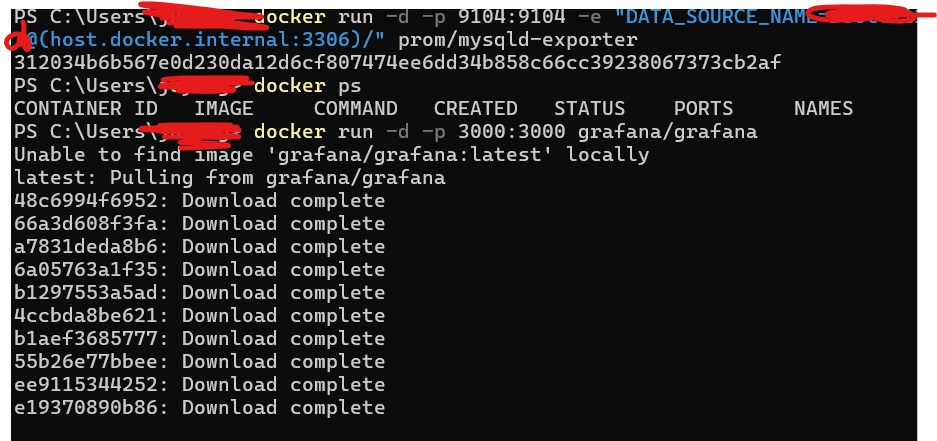
그리고 다 깔려서 로컬 환경에서 접속해보니 접속이 된다...
뭔가 별거 아닌데 기분 좋아졌다. 나 이런거 좋아하는 구나
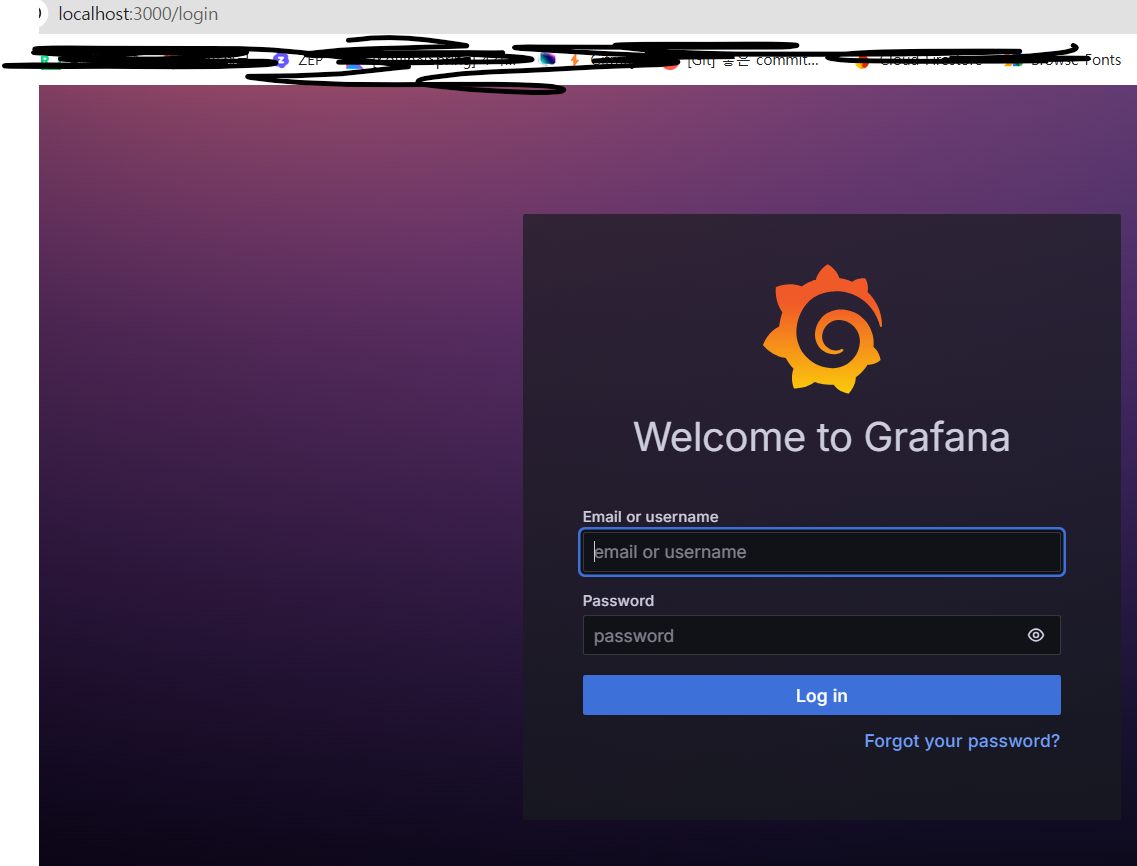
기본 로그인 아이디와 비밀번호는 둘 다 admin인데, 비번 바꾸라고 알림이 떠서 나는 혹시 몰라서 바꿔놨다. 무서운 거 싫으니까~
그리고 데이터는 랜덤 데이터로 계속 조회되길래 보니까 데이터 소스를 가져올 필요가 있다고 해서 그걸 가져오는 설정에 들어갔다.
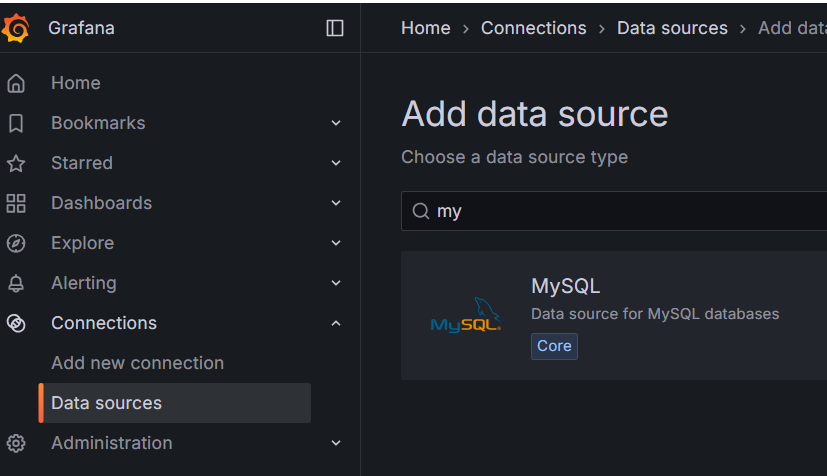
이렇게 들어가면 된다.
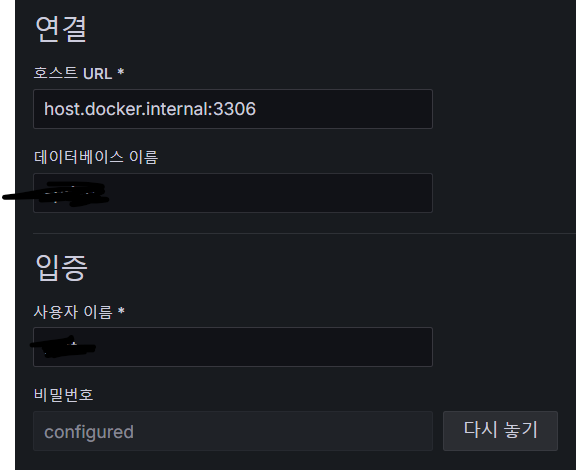
이런식으로 적어주고, 도커를 쓸 것이기 때문에 주소도 그냥 3306이면 안된다고 한다. 물론 도커 없이 그냥 쓸거면 3306이 맞을 거 같다.

연결완료 성공
연결 되고 나서 조회를 하려는데, 하다보니 뭔가 이상한 걸 깨달았다.
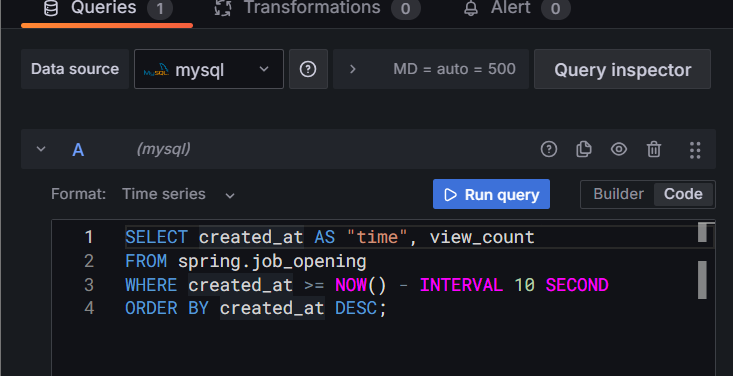
이런 식으로 하라는데.. created_at을 쓰는 게 맞나? 조회수 동시성 제어니까.. 별도에 update를 만들어서 타임스탬프를 찍어야 할 거 같은데...흠....
이 부분은 컬럼 자체를 추가해야 하는 문제이므로 팀원들 간의 상의가 필요해 보인다.
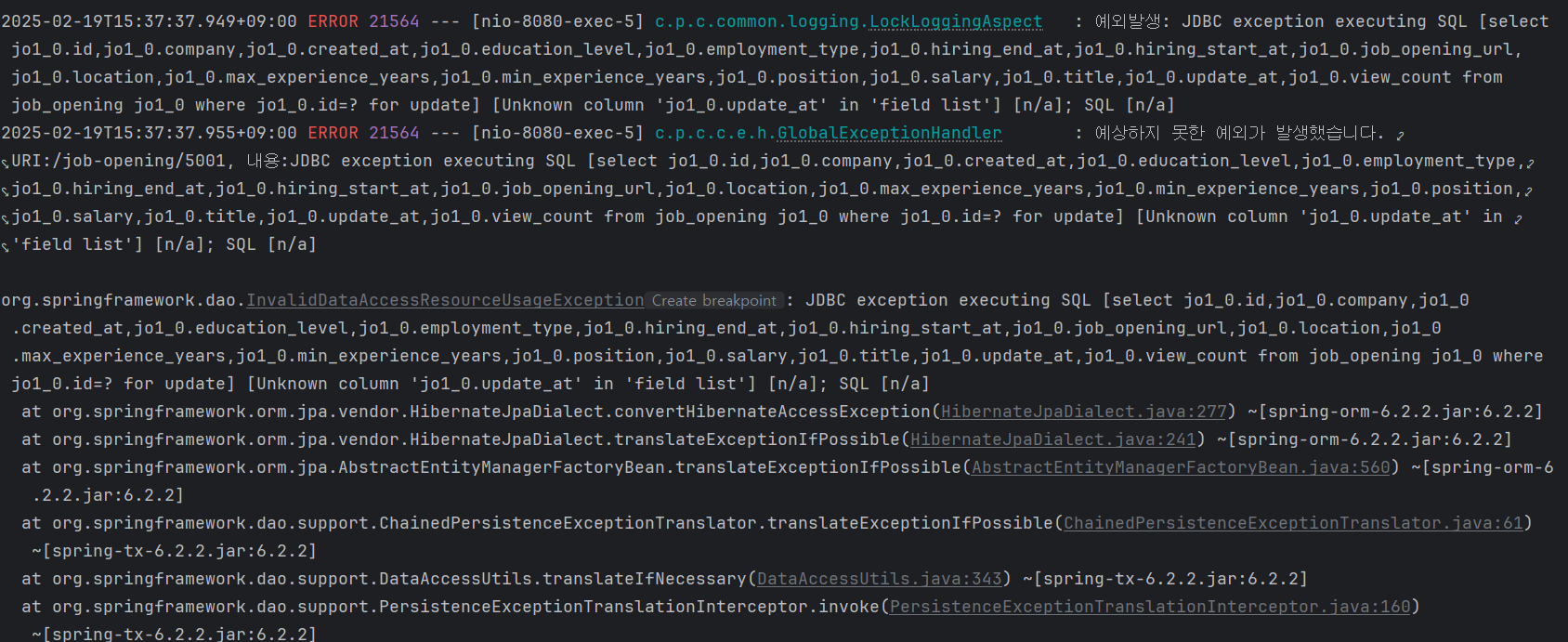
팀원들에게 공유하고 업데이트 컬럼 만들었는데 얘가 못 찾고 있다....
눈물이 나지만... 어쩔 수 없이 더미 테이블을 삭제하고 더미를 다시 넣는 불상사가 발생할 거 같다.. 기존 테이블에 컬럼이 왜 추가되지 않는거야...

아침에 dev랑 머지하고 push 날리느라 환경변수가 로컬환경에 맞게 update로 되어있지 않고 다르게 되어있다는 걸 이제 깨달아서 그 부분을 고치니 정상 추가되는 걸 확인 할 수 있었다. 근데 이러고 다시 그라피나 들어가보니 비밀번호 ...가 리셋되어 있었다.
쎄함을 감지
일단 저장이 안되는 아이라는 걸 깨닫고 나는 고이 이 두 분을 보내드리기로 했다. 솔직히 쓸만했다면 썼겠지만... 굳이? 라는 생각이 들 정도로 쓰기가 좀....애매....했다. 왜 자꾸 쿼리문을 못 읽어내는지 이해가 안되고... 제일 큰 문제는 구글링을 해도 답이 안 나오는 프로그램이라는 거였다.
3. 도구 없이 다시 찾아보기
구글링을 해도 해도, 도대체 다들 부트캠프만 다니는건지 velog, tistory 등... 일부 개시글이 다 뒤덮고 있고, 동시성 제어를 동작 하는 것 위주로 나와있지 비관적 락을 가지고 어떻게 성능을 개선해야 하는지 자세히 나온 글은 많이 못 본 것 같다.
결국 나는 스택오버플로우를 선택했다. 헬프미..!
스택오버플로우에 파파고까지 써가며 검색을 해도 참, 나오는 건 많지만 온통 영어라 눈물을 펑펑... 흘리며 영어공부하자 또 다시 다짐을 하게 되었다.
열심히 찾고, 드디어 조금 알 거 같아서 시작을 다시 해 보기로 했다.
2. 테이블을 분리하세요
먼저 ViewCount 컬럼을 그대로 둔 상태로 동일한 컬럼과 JobOpeninId를 가진 조회수 관련 테이블을 추가로 생성한 후에, 그 테이블 쪽에 비관적 락을 걸기로 했다.
근데 락 걸고 동기화까지 했는데 문제가 또 발생했다.
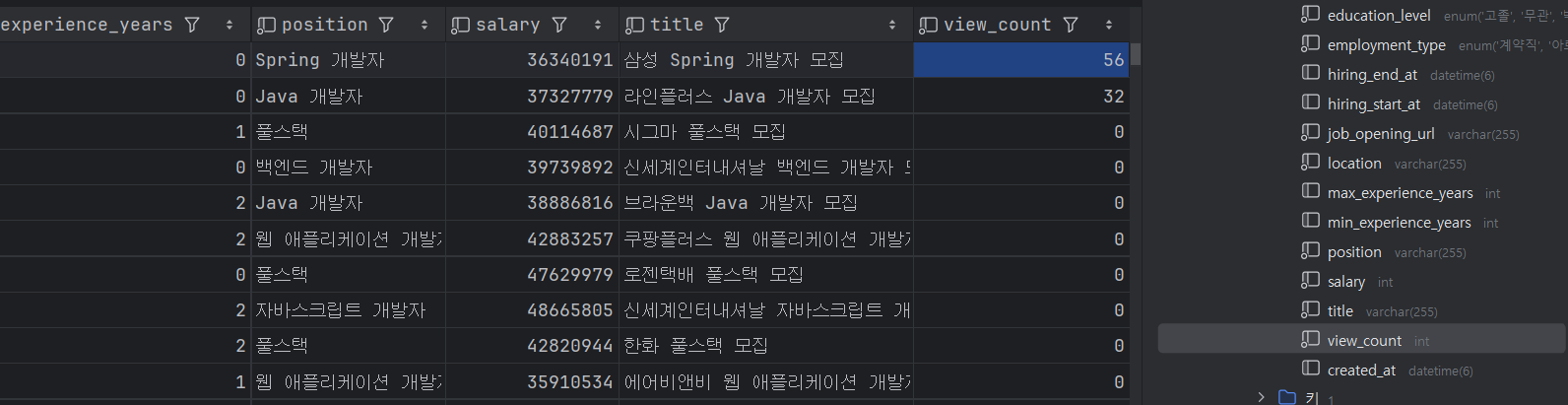
분명 난 맨 위에꺼 11번, 두번째 8번인가 그리 누른 거 같은데... 무한증식한다...
동기화가 잘못된 거 같다. (오열)
오늘도 자정인데... 쉽지 않다.
동기화를 하고 값을 초기화하는 로직을 추가했더니 좀 나아지는가 싶더니만...........
이제는 같은 행이 아닌 다른 행의 값에도 영향을 주고 있다. 끄어어ㅓ억ㄱ..ㄱ.
@Scheduled(fixedRate = 60000) // 1분마다 실행
@Transactional
public void syncViewCounts() {
// 1. jobOpeningViewCount 테이블에서 존재하는 jobOpening.id 목록 가져오기
List<Long> jobOpeningIds = jobOpeningViewsRepository.findAllJobOpeningId();
// 2. 각 jobOpening.id별로 viewCount 조회 및 업데이트
for (Long jobOpeningId : jobOpeningIds) {
Long viewCount = jobOpeningViewsRepository.findViewCountByJobOpeningId(jobOpeningId);
if (viewCount != null && viewCount > 0) {
jobOpeningRepository.updateViewCount(jobOpeningId, viewCount);
jobOpeningViewsRepository.resetViewCount(jobOpeningId);
}
}
log.info("조회수 동기화 완료");
}이러한 형태의 스케줄러인데 아무래도 List 형식으로 가져온 게 문제였던 걸까??
아니면 for문이 문제였던 걸까?? 뭔가 겹쳐서 값이 이중으로 들어가는 게 확실했다.
그래서 로그를 추가해봤는데, 로그 추가하니까 문제가 사라졌다. 아무래도 졸려서 내가 잘못 본 모양이다.
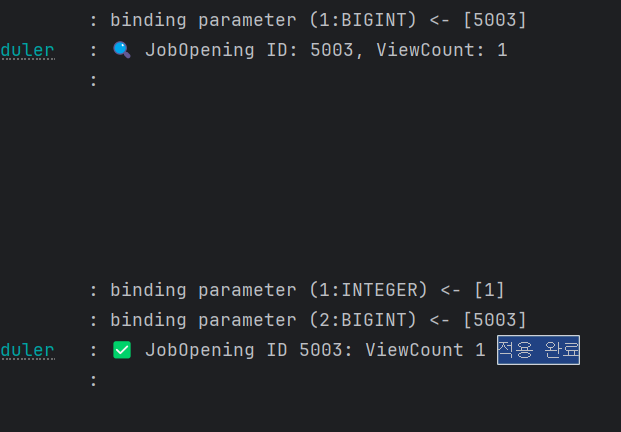
이런 느낌으로 적용에 성공했다. 후후...
<출처>
https://www.baeldung.com/jpa-pessimistic-locking
https://en.wikipedia.org/wiki/Multiversion_concurrency_control
https://ssuamje.tistory.com/89#2.4.%20%EA%B2%A9%EB%A6%AC%EC%88%98%EC%A4%80%20%EB%8D%94%20%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0
https://stackoverflow.com/questions/129329/optimistic-vs-pessimistic-locking
https://stackoverflow.com/questions/43932380/is-there-some-algorithm-for-r-w-lock-graphs/43934192#43934192
https://en.wikipedia.org/wiki/Concurrency_control
https://en.wikipedia.org/wiki/Database_transaction_schedule#Testing_conflict_serializability
https://dev.mysql.com/doc/refman/8.4/en/insert-on-duplicate.html
