[Database] RDBMS와 NoSQL의 차이점 알아보기 !
데이터베이스 관리 시스템으로 RDBMS(Relational DataBase Management System)이 널리 쓰이고 있지만,
대용량 데이터 저장, 비정형 데이터 저장, 빠른 응답시간 등의 새로운 요구사항에 기존 RDBMS만으론 대응하기 어려울 때가 있다.
그래서 RDBMS와 차별적인 데이터베이스 관리 툴인 NoSql이 등장했다.
이번 포스팅에서는 RDBMS와 NoSQL에 대해 알아볼 예정이다 !
그전에 아래는 DBMS와 SQL에 대한 간단한 설명이다.
- DBMS
- 데이터베이스 관리 시스템
- 사용자와 데이터 사이에서 사용자의 요청에 의해 데이터의 생성 조회 등 데이터베이스를 관리해주는 역할
- SQL
- 관계형 데이터베이스 관리 시스템(RDBMS)의 관리를 위해 제작된 언어
- 자료의 검색과 재조합, 스키마 생성과 수정과 같은 데이터베이스 객체 조정 관리를 위해 고안됨
✏️ RDBMS ( Relational DataBase Management System )
- 관계형 데이터베이스 관리 시스템
➜ 관계형 데이터 모델을 기초로 두고 모든 데이터를 2차원의 열과 행(테이블)의 형태로 표현
-
외래 키(foreign key)를 사용하여 테이블 간 Join이 가능
-
ACID(Atomicity, Consistency, Isolation, Durability) 원칙을 기본으로 구성
✔ 장점
-
정해진 스키마에 따라 데이터를 저장해야 해서 명확한 데이터 구조 보장
( 데이터 정합성 ) -
각 데이터를 중복 없이 한 번만 저장 가능
( 데이터 무결성 )- 데이터 정합성 ( Consistency )
➜ 어떤 데이터들이 값이 서로 일치하는 상태
- 데이터 무결성 ( Integrity )
➜ 데이터가 전송, 저장되고 처리되는 모든 과정에서 변경되거나 손상되지 않고 완전성, 정확성, 일관성을 유지함을 보장하는 특성
⠀
[DataBase] 무결성(Integrity)과 정합성(Consistency) 참고
- 데이터 정합성 ( Consistency )
✔ 단점
-
테이블 간 관계를 맺고 있어 시스템이 커질 경우 JOIN문이 많은 복잡한 쿼리 발생 가능
-
성능 향상을 위해 Scale-up만 지원
➜ Scale-out이 불가능하기 때문에 처리 비용이 기하급수적으로 커질 수 있음 -
스키마로 인해 데이터가 유연하지 못함
➜ 나중에 스키마가 변경될 경우 번거롭고 어려움✔️ Scale-up vs Scale-out
- Scale-up
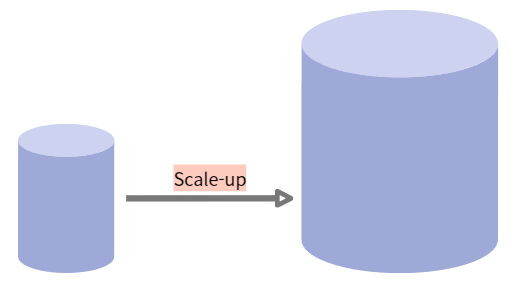
- 기존의 서버를 보다 높은 사양으로 업그레이드하는 것
- 하나의 서버의 능력을 증강하기 때문에 수직 스케일링(vertical scaling)이라고도 함
- Scale-out
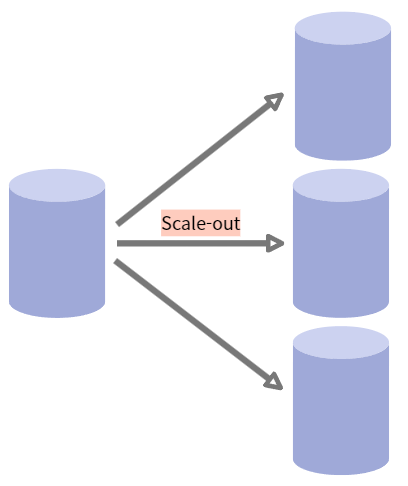
- 장비를 추가해 확장하는 방식
- 서버를 추가로 확장하기 때문에 수평 스케일링(horizontal scaling)이라고도 함
- 비슷한 사양의 서버를 추가로 연결해 처리할 수 있는 데이터의 용량 증가뿐만 아니라 기존 서버의 부하를 분담해 성능도 향상
⠀
[ Scale-up과 Scale-out에 대해 알아보자! 참고 ]
- Scale-up
▶ RDBMS를 사용하는 경우
1. 데이터 구조가 명확하며 데이터의 변경 가능성이 낮은 경우
2. 데이터 변경이 자주 이루어지는 시스템
( 중복된 데이터가 없어 변경이 용이하기 때문 )
✏️ NoSQL ( Not Only SQL )
💡 SQL을 사용하지 않는다는 의미에서 NoSQL이 아니라,
RDBMS가 갖고 있는 특성뿐만 아니라 다른 특성들도 부가적으로 지원한다는 의미
( SQL의 특성뿐만 아니라 다른 특성들도 있다 ~ )
-
RDBMS의 성능과 한계를 극복하기 위해 등장
-
ACID 특성을 제공하지 않지만 뛰어난 확장성이나 성능 등의 특성을 가짐
-
테이블 간 관계 정의 X
➜ 테이블 간 Join이 필요 X
✔️ NoSQL 모델 종류
⠀⠀
1. Key-Value DB
- Key-Value 방식으로 데이터를 저장
- Key값은 모든 데이터 타입을 수용할 수 있고, 중복되지 않는 유니크한 값
- 메모리 기반으로 빠르게 데이터를 읽어올 수 있음
Ex. Redis, AWS DynamoDB, Riak 등
- Document DB
- 비정형 대량 데이터를 저장하기 위한 방식
- Key-Value에서 확장된 방식으로, Key-Document 형태로 저장
- Document는 계층적인 데이터 타입(JSON, XML)으로 저장됨
- JSON 타입을 사용하므로 HTTP 기반의 웹서버의 경우 데이터를 편리하게 주고받을 수 있음
Ex. MongoDB, Couch DB 등
- Wide Column DB
- Row가 아닌 Column 위주로 데이터를 저장하는 방식
- Key, Value와 유사한 형태의 Column-family Model
- 데이터가 내부에서 Key를 기준으로 오름차순 저장됨
- 이전의 모델들이 key-value 값을 이용해 필드를 결정했다면, 이 모델은 키에서 필드를 결정
Ex. HBase, Hypertable
- Graph DB
- 객체와 관계를 그래프 형식의 데이터로 저장하기 위한 방식
- 데이터를 Node와 Edge, Property와 함께 그래프 구조를 사용하여 데이터를 저장
- SNS, Network Diagrams 등과 SNS에서 함께 아는 친구 찾기, 추천 등 연관된 데이터를 추천해주는 엔진이나 패턴 기능에 사용
Ex. Neo4j
✔ 장점
-
스키마가 없어 유연하고 자유로운 데이터 구조
➜ 언제든 저장된 데이터 조정과 새로운 필드 추가가 가능 -
성능 향상을 위해 Scale-up / Scale-out이 모두 가능
➜ 데이터 분산이 용이하고, RDBMS에 비해 대용량의 데이터 저장 가능
✔ 단점
-
스키마가 존재하지 않아 데이터의 일관성이 존재하지 않고
데이터 구조를 결정하기 어려울 수 있음 -
데이터의 중복 발생 가능
➜ 이 경우 데이터를 변경하려면 모든 컬렉션에서 update해야 함Ex. A, B 고객이 모두 C 상품을 주문을 한다고 할 때,
A, B 고객의 주문 정보에는 모두 C라는 상품 정보가 중복되어 들어가 있을 것이다.
⠀
RDBMS의 경우 C 상품 정보 테이블을 따로 빼서 관리하면 되는데,
NoSQL의 경우 이 값들이 중복되기 때문에 관리가 필요하다.
▶ NoSQL을 사용하는 경우
1. 정확한 데이터 구조를 알 수 없고 데이터가 변경/확장될 수 있는 경우
2. 데이터의 수정이 많이 이루어지는 시스템
3. 데이터베이스를 Scale-Out 하여 아주 많은 데이터를 저장해야 할 경우
[ 참고한 사이트 ]

양질의 포스팅 잘 읽었습니다, (graphDB 오타 있어요!)