📌 QueryDsl에 대한 자세한 개념들은 아래 포스팅을 참고해주세요.
<[Project] QueryDsl의 사용과 프로젝트에 적용하기 !>
✏️ N+1 문제란?
연관 관계에서 발생하는 이슈로,
일대다의 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 개수(n)만큼 연관 관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 되는 것
👉 즉, 1대 N(일대다)의 연관 관계를 가지고 있는 테이블이 있을 경우에,
1 쪽의 테이블을 조회하면 그에 연관관계를 가지고 있는 테이블들(N)이 함께 조회가 되어
1+N개의 쿼리가 발생하는 문제를 말합니다.
✔ N+1 문제의 원인
JPARepository에 정의한 인터페이스 메서드를 실행하면 JPA는 메서드 이름을 분석해서 JPQL을 생성하여 실행하게 됩니다.
JPQL은 SQL을 추상화한 객체지향 쿼리 언어로써
특정 SQL에 종속되지 않고 엔티티 객체와 필드 이름을 가지고 쿼리를 하기 때문에
findAll()이란 메서드를 수행하였을 경우,
해당 엔티티를 조회하는 select * from Yata 쿼리만 실행하게 됩니다.
JPQL은 기본적으로 글로벌 fetch 전략과 연관관계 데이터를 무시하고 해당 엔티티를 기준으로 JPQL만 가지고 SQL을 생성하기 때문에
연관 관계 데이터들이 필요할 때 따로 쿼리를 날려야 해서 N+1 문제가 발생하는 것입니다 !
✔️ fetchType
- Eager
➜ 즉시로딩 ( 연관된 엔티티 즉시 조회 )
⠀
Ex. A, B가 Eager(즉시로딩)로 연결되어 있을 경우,
A를 조회하면 B를 조회하는 쿼리까지 즉시 나감
⠀- Lazy
➜ 지연로딩 ( 연관된 엔티티를 프록시로 조회 )
➜ 프록시를 실제 사용할 때 초기화하면서 데이터베이스를 조회
⠀
Ex. A, B가 Lazy(지연로딩)로 연결되어 있을 경우,
A를 조회하면 A를 조회하는 쿼리만 나가고, B를 조회하는 쿼리는 생성되지 않음
실제로 B를 사용하는 시점에 B를 조회하는 쿼리가 나감
⠀
💡 fetch의 dafault 값 ➜@xxToOne에서는 EAGER /@xxToMany에서는 LAZY
💬 Q ) 위 예시에서 fetchType을 Lazy(지연로딩)로 사용하여 A를 조회할 경우,
A, B의 쿼리가 동시에 나오지 않는데 왜 N+1 문제가 발생한다고 할까?
⠀
👉 Answer )
A를 조회했을 경우에는 Lazy 타입을 사용하여 N+1 문제가 발생하지 않지만,
하위 엔티티인 B를 가지고 작업하게 될 경우 추가 조회가 발생하여 결국 N+1 문제가 발생하게 됩니다 !
⠀
연결된 Entity에 대해 프록시를 걸고, 사용할 때 결국 쿼리문을 발생시키기 때문에 프록시에 대한 쿼리가 발생하게 되는 것입니다.
🌼 프로젝트에서의 N+1 문제
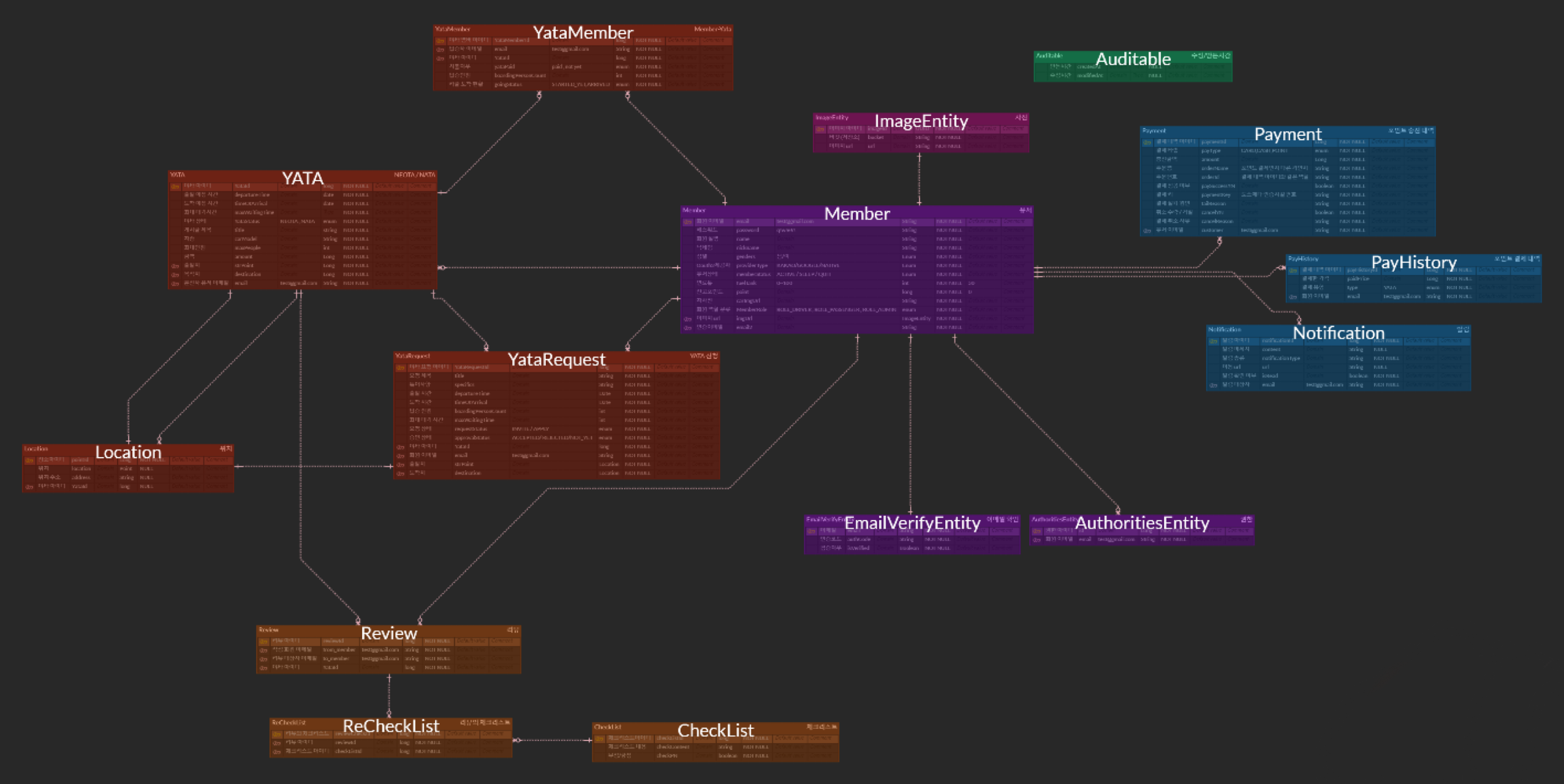
위 구조를 가진 프로젝트를 진행하면서 테이블 간 연관 관계를 많이 설정해야 했습니다.
그러다보니 1:N 관계가 맺어져 있는 테이블들을 전체 조회할 경우,
일대 다 관계로 매핑된 테이블의 조회 쿼리까지 함께 날아가는 N+1 문제가 발생하였습니다 !
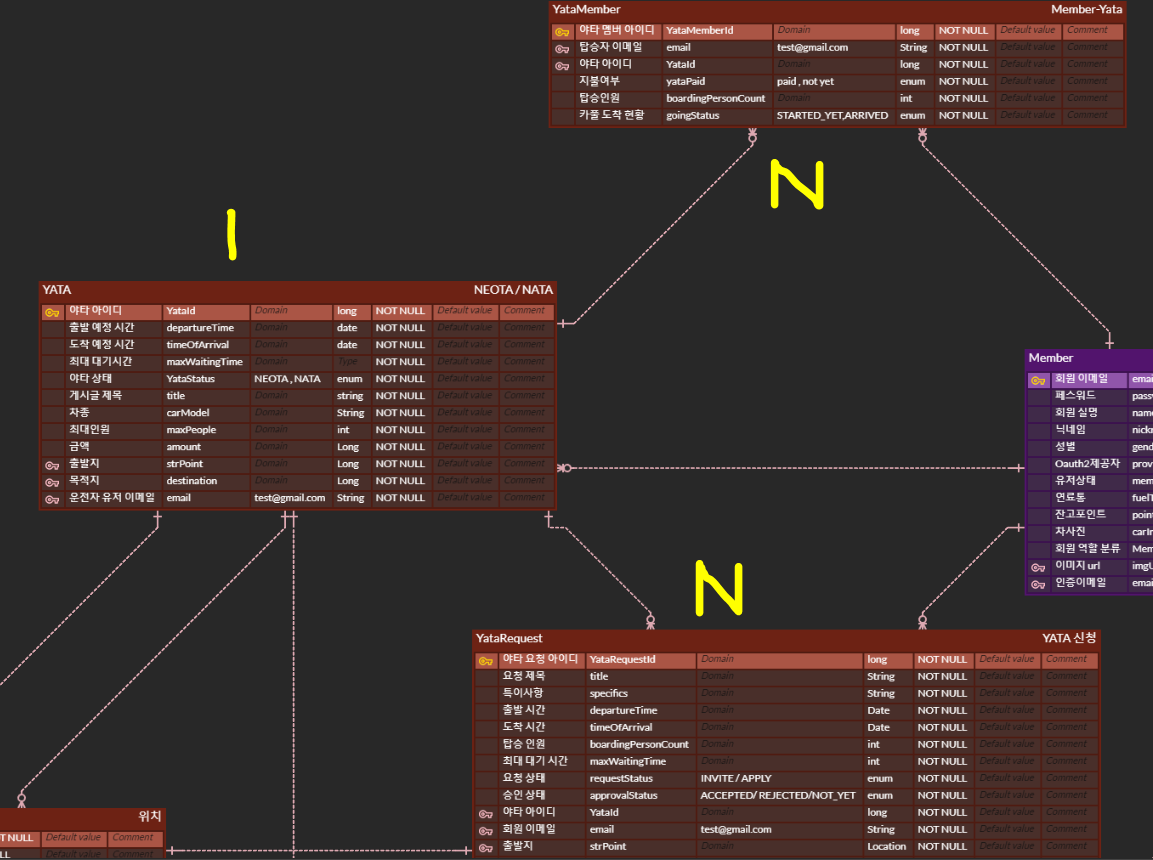

☘️ 해결 방법
미리 두 테이블을 JOIN하여 한번에 모든 데이터를 가져올 수 있다면 애초에 N+1 문제가 발생하지 않을 것입니다.
따라서 두 테이블을 JOIN하는 쿼리를 작성하기 위해
아래와 같이 1:N의 N 쪽에 fetchJoin을 걸어 해결해 주었습니다.
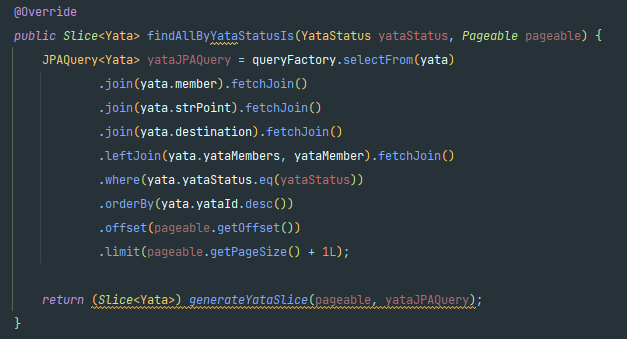
결과를 확인해보면 쿼리가 1번만 발생하고,
미리 yata와 yataMember 데이터를 조인(Inner Join)해서 가져오는 것을 볼 수 있습니다 !
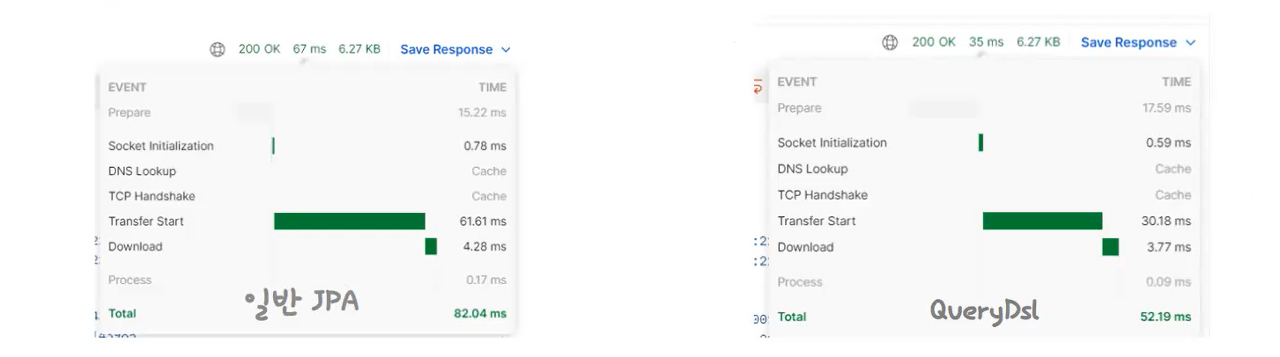
또한, postman으로 조회 시간을 확인해 보았을 때
67ms 에서 35ms로 반정도 줄어든 것으로 확인할 수 있습니다 !
✔️ FetchJoin의 단점
- 연관관계 설정을 해놓은 fetchType을 사용할 수 없음
➜ FetchJoin 사용 시, 데이터 호출 시점에 모든 연관관계의 데이터를 가져오기 때문에 FetchType을 Lazy로 해놓는 것은 무의미함
⠀- 쿼리 한 번에 모든 데이터를 가져오기 때문에 JPA가 제공하는 Pageable 사용이 불가능
⠀- 1:N 관계가 두 개 이상인 경우 사용 불가능
➜MultipleBagFetchException발생
⠀- 패치 조인 대상에게 별칭(as) 부여 불가능
⚠️ 주의점
카테시안 곱(Cartesian Product)이 발생하여 1의 수만큼 N의 중복 데이터가 존재할 수 있습니다.
따라서 중복된 데이터가 컬렉션에 존재하지 않도록 주의해야하며,
중복을 허용하지 않는 컬렉션 Set을 사용하거나
mapper 부분에 distinct()를 사용하여 중복을 제거해 줄 수 있습니다 !
( 해당 프로젝트의 경우 distinct()를 사용하였습니다. )
📌 카테시안 곱(Cartesian Product)에 대한 자세한 개념들은 아래 포스팅을 참고해주세요.
<[Project] QueryDsl의 사용과 프로젝트에 적용하기 !>
