📌 캐시에 대한 자세한 개념들은 아래 포스팅을 참고해주세요.
<[JPA] 캐싱(Caching)과 영속성(persistence)>
💬 2차 캐시 사용 이유
프로젝트의 테이블이 많아지고 연관관계가 많아지면서 데이터를 조회/검증 하는 데 많은 쿼리가 나가게 되었습니다.
또, 이러한 쿼리들이 많아지면서 데이터 베이스 서버의 네트워크 트래픽 증가의 문제가 있었습니다.
물론 Hibernate에서 기본적으로 제공하는 1차 캐시가 있지만,
이는 영속성 컨텍스트의 생명주기와 동일하여 트랜잭션이 종료되면 함께 종료됩니다.
따라서 이 1차 캐시는 캐싱 관점에서 테이터 베이스 접근 횟수를 줄이는 역할을 크게 하지는 않습니다.
이 Hibernate 2차 캐시는 애플리케이션 단위의 캐시이므로 애플리케이션이 종료되기 전 까지는 종료되지 않기 때문에
필요한 데이터를 매번 데이터 베이스에서 조회하지 않고, 애플리케이션 메모리에 캐시된 데이터를 복사해 가지고 옴으로써 데이터베이스의 접근 횟수를 줄여 결과적으로 애플리케이션의 성능을 개선할 수 있습니다.
💡 2차 캐시 설정
아래와 같이 application.yml 파일과 엔티티 클래스 레벨에 2차 캐시 설정을 해주었고
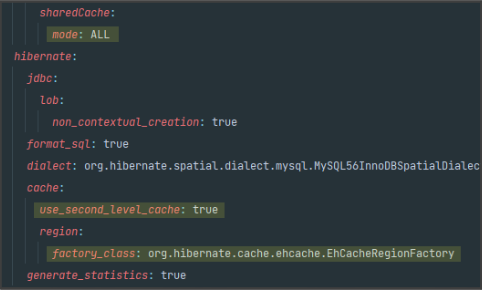
- hibernate.cache.use_second_level_cache
➜ 2차 캐시를 활성화
➜ 엔티티 캐시와 컬렉션 캐시를 사용 가능- hibernate.cache.use_query_cach
➜ 쿼리 캐시를 활성화- hibernate.cache.region.factory_class
➜ 2차 캐시를 처리할 클래스 지정- hibernate.generate_statistics
➜ 이 속성을 true로 설정하면 하이버네이트가 여러 통계정보를 출력해주는데 캐시 적용 여부 확인 가능
( 성능에 영향을 주므로 개발 황경에서만 적용해야 함 )
✔️ Hibernate가 지원하는 캐시
1. 엔티티 캐시
- 엔티티 단위로 캐시
- 식별자로 엔티티를 조회하거나 컬렉션이 아닌 연관된 엔티티를 로딩할 때 사용
⠀
- 컬렉션 캐시
- 엔티티와 연관된 컬렉션을 캐시
-- 컬렉션이 엔티티를 담고 있으면 식별자 값만 캐시 (하이버네이트 기능)
⠀
- 쿼리 캐시
- 쿼리와 파라미터 정보를 키로 사용해서 캐시
- 결과가 엔티티면 식별자 값만 캐시 (하이버네이트 기능)

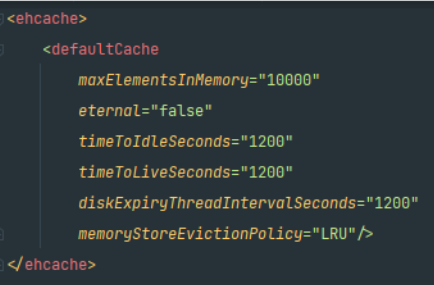
resources 부분에 아래와 같이 Hibernate에서 공식적으로 지원하는 ehcache.xml 파일을 추가하고,
1만개의 객체까지 20분동안 캐싱하는 설정을 해주었습니다.
🌼 2차 캐시 적용 전 / 후 비교
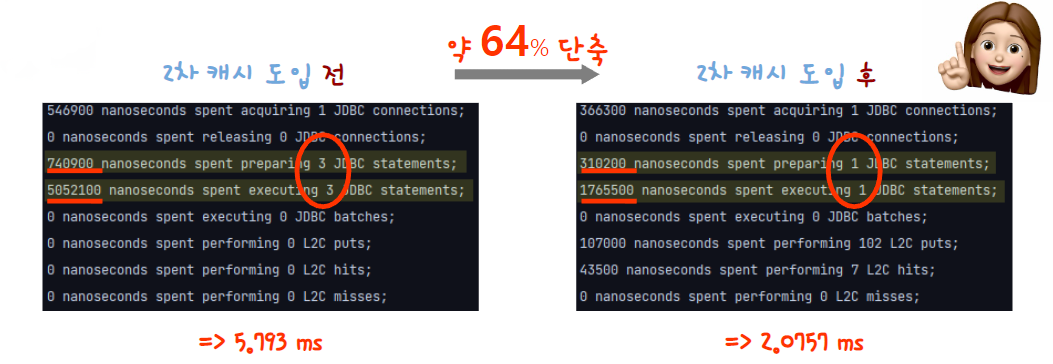
위 사진은 2차 캐시를 도입하기 전과 후의 100건 정도의 데이터 조회 속도와 쿼리문의 개수를 비교한 것입니다.
👉 속도는 약 64% 개선되었고, 실행되는 쿼리문은 3개에서 1개로 줄어든 것을 볼 수 있습니다.
( ❗ 위 사진에서 조회는 application.yml에 generate_statistics: true를 추가하여 콘솔 창에서 확인 가능 )
실무에서는 잘 사용하지 않는 2차 캐시
그런데 프로젝트가 끝나고 나서 알게되었는데, 실무에서는 2차 캐시를 잘 사용하지 않는다는 점이었다.
왜냐하면 2차 캐시는 설정도 복잡하고, 지원하는 캐시 라이브러리도 작다.
무엇보다 실무에서는 서비스 계층에서 복잡하게 외부 API도 호출하고, 여러 엔티티도 조회해서 그 결과로 DTO를 생성하는데,
스프링을 사용하면 이 DTO를 효과적으로 캐시할 수 있고, 지원하는 캐시 라이브러리도 풍부하다.
그런데 2차 캐시는 단순히 엔티티 조회(쿼리포함)와 관련된 부분만 캐시가 지원되기 때문에
하이버네이트 2차 캐시 보다는 스프링이 지원하는 캐시를 적극 사용하는 것이 낫다고 한다!!
