파일을 저장할 때 왜 UUID를 사용할까?
파일을 저장할 때는 왜 일반 ID가 아닌 UUID(Universally Unique Identifier)를 사용할까?
먼저 UUID에 대해 알아보자!
✏️ UUID (Universally Unique IDentifier)란?
-
네트워크 상에서 고유성이 보장되는 id를 만들기 위한 표준 규약
-
범용 고유 식별자라고 함
-
주로 분산 컴퓨팅 환경에서 사용되는 식별자
-
중앙관리시스템이 있는 환경이라면 각 세션에 일련번호를 부여해줌으로써 유일성을 보장할 수 있는데,
중앙에서 관리되지 않는 분산 환경이라면 개별 시스템이 id를 발급하더라도 유일성이 보장되어야 하기 때문에 이를 위해 탄생한 것이 UUID라고 한다.
✔ UUID 구조
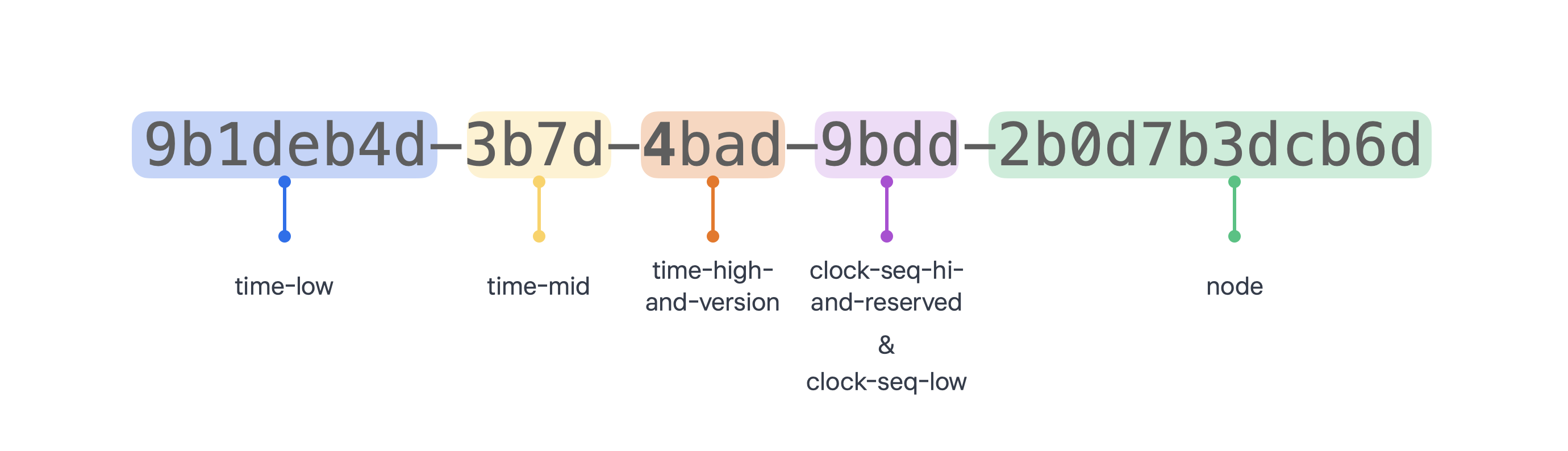
-
128-bit의 숫자 문자열
-
총 길이는 36자리
-
32개의 16진수 숫자가 4개의 하이픈으로 나누어진 8-4-4-4-12 형태
Ex. 9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6d와 같은 형태
하이픈 사이에 있는 16진수 숫자들은 하나의 필드이고,
각 필드는 정수로 취급되며 가장 중요한 숫자가 앞에 나온다.
ㅤ
Ex. 위 이미지에 볼드된 세 번째 필드의 첫 숫자는 4인데, 이는 UUID의 버전이다.
어떤 UUID를 봐도 세 번째 필드의 첫 번째 숫자는 버전 정보를 나타낸다!
✔ UUID 필드
1. time-low
- 타임스탬프의 low field
- 사이즈 : 4hexOctet / 32bit
2. time-mid
- 타임스탬프의 mid field
- 사이즈 : 2hexOctet / 16bit
3. time-high-and-version
- 타임스탬프의 high field & UUID 버전
- 사이즈 : 2hexOctet / 16bit
4. clock-seq-hi-and-reserved
- 클락 시퀀스의 high field & variant
- 사이즈 : hexOctet / 8bit
5. clock-seq-low
- 클락 시퀀스의 low field
- 사이즈 : hexOctet / 8bit
6. node
- node 식별자
- 사이즈 : 6hexOctet / 48bit
✔ UUID 버전
UUID는 총 5개의 버전이 존재한다.
각 특징을 알아보자면 아래와 같다!
✔️ Version 1,2
보통 타임스탬프(Timestamp) UUID로 부름
만들어진 시점과 기기 정보를 알 수 있음
✔️ Version 3,5
네임스페이스(Namespace) 기반으로 만드는 UUID
네임스페이스를 해싱 알고리즘으로 암호화해서 UUID를 생성함
다른 정보와 연결된 값을 만들고 싶을 때 사용하면 좋음
✔️ Version 4
가장 흔히 사용하는 UUID는 버전
다른 버전과 달리 외부 정보에 의존하지 않고 완전히 랜덤한 값으로 생성됨
시간, 기기 정보, 네임스페이스 등 정보가 없기 때문에 어디서 어떻게 생성됐는지 알 수 없음
보안 측면에서 뛰어나고 생성도 빠르기 때문에 대중적으로 사용되고 있음
여기서 중요한 점은 상황에 맞게 UUID 버전을 다르게 사용해야 한다는 점이다.
완전히 고유하고 랜덤한 값이 필요하다면 버전 4를 사용하고,
고유하면서 완전히 랜덤한 값보다는 특정 정보가 필요하면 다른 버전을 사용하자!
✔️ 사용시 장점
1. 고유성 보장
-
UUID는 서로 다른 것을 보장해주는 다양한 구성요소(타임스탬프, 무작위로 생성된 구성요소 등)를 조합하는 식으로 생성되어 유일한 값을 생성하는 데 사용됨
➜ 동일한 이름의 파일이 덮어쓰여지는 것 방지 가능
Ex. 사용자들이 동일한 파일 이름을 사용할 경우,
UUID를 통해 각 파일을 구분할 수 있어 데이터의 무결성을 유지할 수 있음!
RFC 4122 문서에 정의된 UUID 버전 4 표준 규약을 따르면, 1조 개의 UUID 중에 중복이 일어날 확률은 10억 분의 1이라고 한다!
2. 충돌 방지
-
UUID는 충돌 가능성이 극히 낮음
➜ 파일 시스템에서는 동일한 파일 이름이 존재할 경우에 마지막에 저장된 파일이 이전 파일을 덮어쓰게 되는데, UUID를 사용하면 파일 이름의 충돌을 사전에 방지 가능!
➜ ID 충돌로 인한 오류 방지 가능
Ex. 사용자가 "image.jpg"라는 파일을 여러 번 업로드하더라도, 각각의 파일은 고유한 UUID가 포함된 이름으로 저장되어 서로 다른 파일로 인식됨
3. 확장성
-
UUID는 128비트 숫자로, 이론적으로 340조 개의 UUID를 생성할 수 있음
➜ 이는 대규모 시스템에서 수많은 파일을 저장하고 관리하는 데 유리함
➜ 파일의 수가 증가하더라도 UUID를 사용하면 고유성을 유지할 수 있음
-
다른 고유 ID 생성 방법과 다르게 UUID는 중앙 시스템에 등록하고 발급하는 과정이 없어서 상대적으로 더 빠르고 간단하게 만들 수 있음
4. 보안성
-
UUID는 예측하기 어려운 문자열임
➜ 공격자가 데이터베이스의 레코드를 추측하기 어렵게 만듦
➜ 파일의 내용을 유추하기 어렵게 만듦
➜ 보안적인 측면에서 유리
5. 관리 용이성
-
파일 이름이나 경로에 UUID가 포함되어 있으면, 파일의 생성 시점이나 소유자를 쉽게 식별할 수 있음
➜ 일을 관리 및 추적이 더 용이해짐
6. 작은 크기
- 다른 고유 식별자에 비해 정렬, 차수, 해싱 등 다양한 알고리즘에 사용하기 쉽고 데이터베이스에 보관하기도 용이
✔️ 사용시 단점
1. WorkBench 사용시
MySQL을 사용하게되면 DB 테이블을 보기 위해 WorkBench을 사용하는데
여기서 UUID는 BLOB으로 깨져서 보인다 ㅠ
변환하면 볼 수는 있는데, 나는 굳이 변환까지 해서 보고싶진 않으니 패스하였다.
변환해보고 싶다면 아래 사이트를 참고하면 좋을 것 같다.
https://beautifulhill.tistory.com/6
2. 외부 서비스와 연동시
이건 UUID의 단점이라기보다는 서비스간 연동시에 단점이 될 수 있는데,
UUID를 이용하여 transaction key형식으로 다른 서비스와도 연동할때 고유값으로 사용하게되면 다른 서비스에서 해당 정보를 저장할때 테이블 크기가 넘치는 경우가 많이 있다고 한다.
그래서 다른 서비스에 table column 정보를 변경하기 위한 작업이 추가로 되어있어 다른 서비스와 연동할때 허용 가능한 key의 length를 확인해봐야 한다고 한다.
3. sorting 불가능
UUID는 랜덤으로 생성되다보니 순서에 대한 정렬을 할 수 없기 때문에
key로 사용될때 정렬에 대한 column이 하나 더 필요하다.
나의 경우에는 아래와 같이 fileOrder 컬럼을 추가하여 파일 업로드 순서를 보장하였다!

💡 참고 사이트
📌 파일 업로드 기능 구현 방법은 아래 포스팅을 참고해주세요.
