📌 선형회귀 (Linear Regression)
선형회귀는 머신러닝의 지도 학습 중 회귀에 해당한다.
선형회귀란, 데이터를 가장 잘 표현하는 최적의 선을 찾는 것을 말한다. 통계학에서는 좀 어려운 표현으로 이 선을 최적선, 영어로는 'Line of best fit' 이라고도 한다.
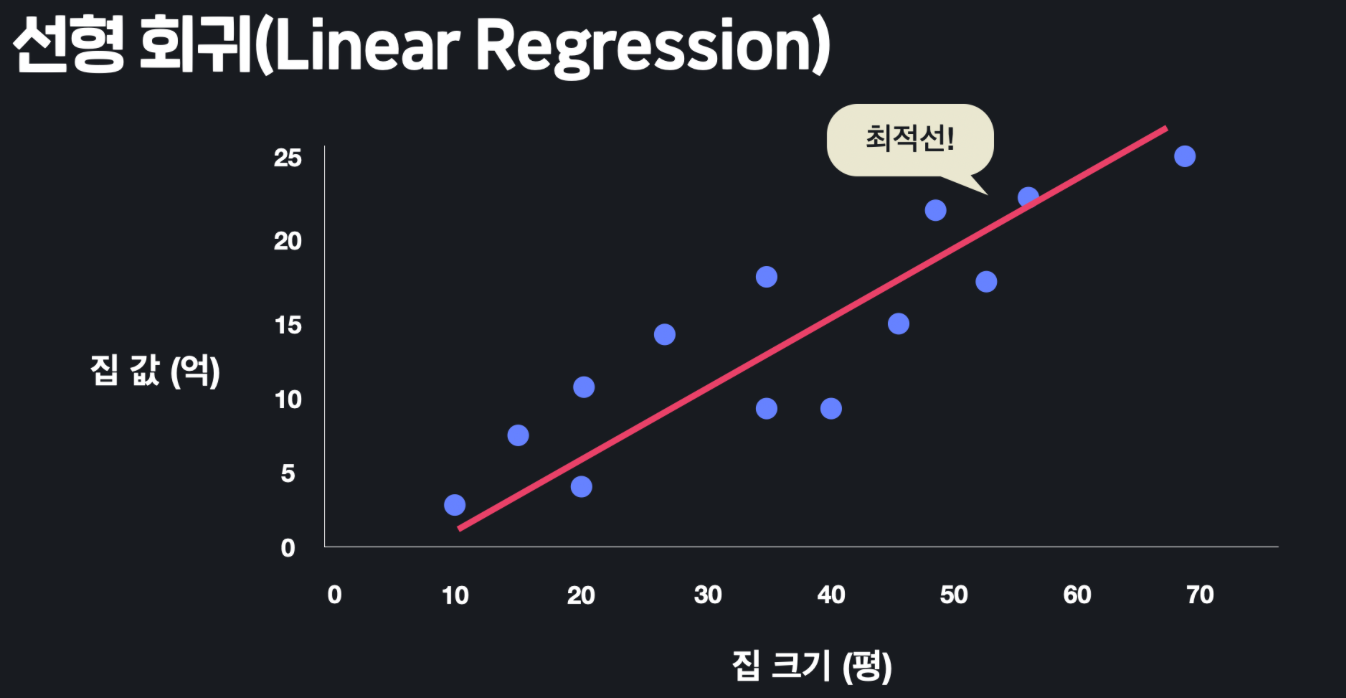
위의 사진에서처럼 집 크기에 따른 집 값을 예측한다고 하자. 우리가 맞추려고 하는 값, 즉 집 값은 '목표 변수', 영어로는 'target variable', 또는 'output variable'이라고도 한다. 편하게는 그냥 '아웃풋'이라고도 한다.
그리고 그 목표 변수를 맞추기 위해서 사용하는 값을 '입력 변수', 영어로는 'input variable'이라고 한다. 편하게는 그냥 '인풋'이라고 해도 되고, 좀 더 일반적으로는 'feature'라고도 한다.
📍 가설 함수
데이터를 가장 잘 표현하는 최적선을 찾아내기 위해 다양한 함수를 시도해 봐야 할 텐데, 시도하는 함수 하나하나를 '가설 함수', 영어로는 'hypothesis function'이라고 부른다. 따라서 학습이라는 것은, 여러 가설 함수들 중에서 가장 적절한 가설 함수를 찾는 것을 의미하게 된다.
현재 우리가 찾으려는 선은 일차식이기 때문에 가설 함수는 형태가 된다.
선형회귀의 임무는 이 가설 함수가 데이터를 가장 잘 표현하는 가설 함수가 되도록 하는 계수 , 를 찾는 것이다.
사실 가설 함수를 표현할 때는 피처의 개수가 많을 수 있음을 고려해서 다음과 같이 표현하는 것이 일반적이다.
통일성을 위해 을 이용하여 아래처럼 표현하기도 한다.
다시 말하자면 선형 회귀의 임무는 가장 적절한 이 세타 값들을 찾아내는 것이다.
📍 MSE (Mean Squared Error)
다시 위의 예시를 이용하면 입력 변수가 하나밖에 없기 때문에 가설 함수는 이 된다.
여러 에 대한 가설 함수들을 만들었을 때 가설 함수들의 좋고 나쁨을 어떻게 비교할까?
가설 함수가 얼마나 좋은지 평가하는 방법 중 대표적으로는 평균 제곱 오차(MSE)가 있다. 이 평균 제곱 오차라는 건, 이 데이터들(정답)과 가설 함수가 예측하는 값(예측값)이 평균적으로 얼마나 떨어져 있는지 나타내기 위한 하나의 방식이다.
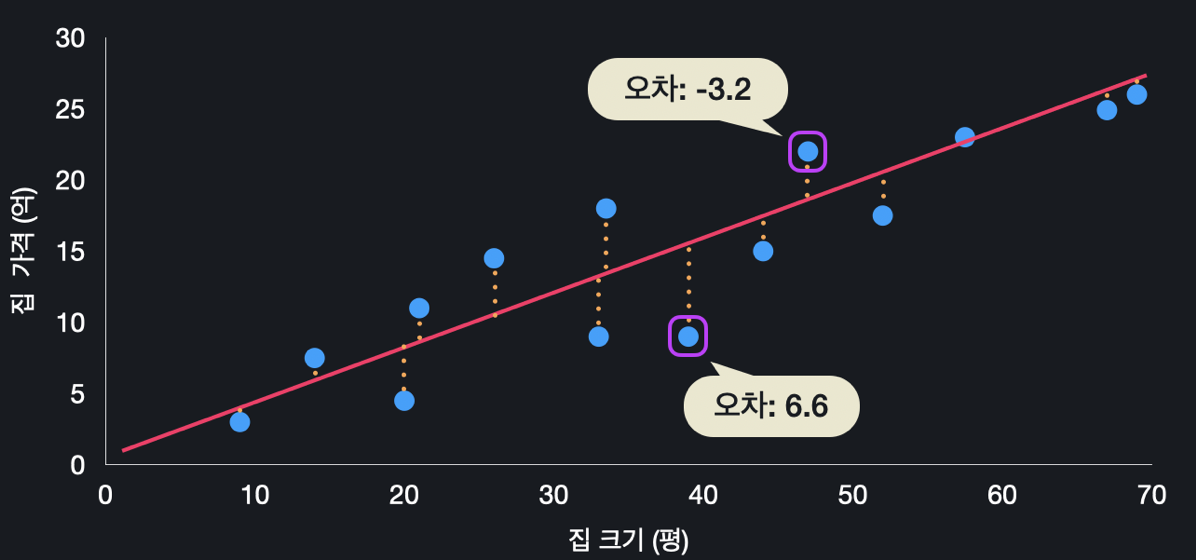
위와 같이 오차를 구해볼 수 있다.
오차를 구한 후에는 제곱을 하는데 제곱을 하는 이유는 다음과 같다.
- 양수로 통일시키기 위함
- 더 큰 오차에 대해서는 더 큰 페널티를 주기 위함
제곱한 값을 모두 더하고 데이터의 총 개수인 으로 나눠서 평균을 내면된다.
MSE를 일반화하면 아래와 같다.
📍 손실 함수 (Lost Function, Cost Function)
손실 함수는 어떤 가설 함수를 평가하기 위한 함수이다.
손실 함수의 아웃풋이 작을수록 가설 함수의 손실이 적기 때문에 더 좋은 가설 함수라고 할 수 있고, 반대로 손실 함수의 아웃풋이 클수록 가설 함수의 손실이 큰 거기 때문에 더 나쁜 가설 함수라고 할 수 있다.
선형 회귀의 경우에는 평균 제곱 오차가 손실 함수의 아웃풋이다. 따라서 손실 함수 는 다음과 같이 표현한다.
분모가 으로 된 것은 계산을 좀 더 수월하게 하기 위함이다. 또 주의해야 할 것은 손실 함수의 아웃풋은 값들을 어떻게 설정하느냐에 달려 있다. 따라서 는 에 대한 함수이다.
📍 경사 하강법 (Gradient Descent)
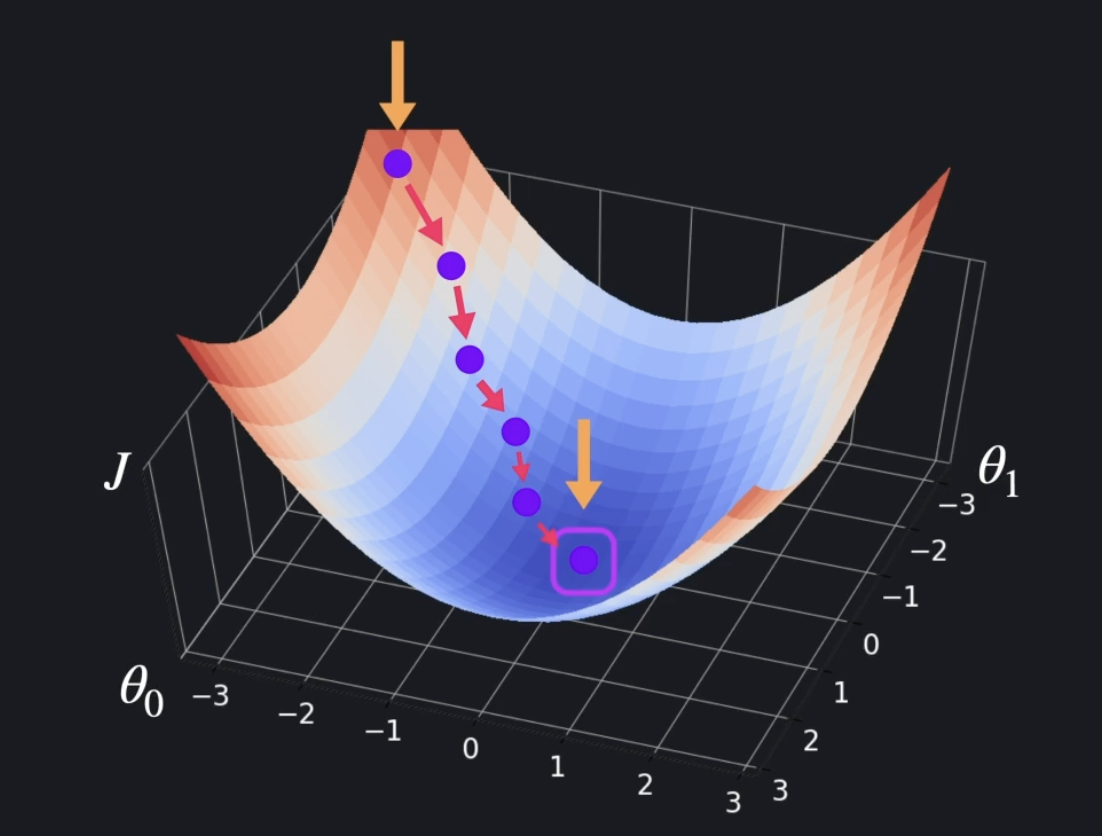
우리는 손실함수의 극소점을 향해 나아가야 한다. 손실함수의 기울기 벡터 는 가장 가파르게 올라가는 방향을 알려주니, 음수를 붙여 가장 가파르게 내려가는 방향 으로 가면 된다.
예를 들어 현재 지점이 이라 하자. 이라 한다면, 인 지점에서의 기울기 벡터는 이다.
극소점을 향해 가기 위해서는 가파르게 내려가야 하므로 음수를 붙인 이다. 이것에 학습률 를 붙여 기존 에 더해주면 된다.
이라 한다면, 업데이트 된 이 된다.
이로써 극소점을 향한 한 스텝이 이루어진 것이다.
이러한 경사 하강법 알고리즘을 일반화한 것은 아래와 같다.
즉,
-
기울기 벡터 값 (양수라면) :
의 값을 감소시켜야 값이 감소하고, -
기울기 벡터 값 (음수라면) :
의 값을 증가시켜야 값이 감소한다.
이런 과정을 반복하면서 기울기가 0에 가까워지도록 즉, 극소점에 가까워지도록 한다.
💡식 변형
업데이트 :
위에서 보았던 경사 하강법 수식에 손실함수를 대입하면 다음과 같다.
이 식에서 가설 함수 도 대입해주자.
이걸 에 대해서 편미분 해주면 다음과 같다.
부분은 가설 함수 와 동일하니까 원래대로 돌려놓자.
업데이트 :
도 일 때와 마찬가지로 식변형을 해주겠다.
이걸 에 대해서 편미분 해주면 다음과 같다.
부분은 가설 함수 와 동일하니까 원래대로 돌려놓자.
💡Vectorization
위에서 식변형을 통해 탄생한 공식으로 경사하강법을 Vectorization 해보자.
먼저 입력 변수 x를 벡터로 생각하면 다음과 같다.
목표 변수 y는 다음과 같다.
가설 함수는 다음과 같다.
오차 는 다음과 같다.
이 벡터 의 모든 원소의 평균은 라 표현할 수 있다.
또한 을 위해서 벡터 에 벡터 를 요소별 곱하기를 진행하면 다음과 같다.
위에서 식변형을 하여 탄생한 공식 2개는 아래와 같은데,
이 공식에 벡터로 표현된 변수들을 삽입시켜 식을 단순화 해보면 아래와 같다.
이런 식으로 단순화 작업을 하게 되면 코드로 구현했을 때 더 쉽게 구현할 수 있다는 장점이 있다.
📍 구현
import numpy as np
def prediction(theta_0, theta_1, x):
"""주어진 학습 데이터 벡터 x에 대해서 모든 예측 값을 벡터로 리턴하는 함수"""
return theta_0 + theta_1 * x
def prediction_difference(theta_0, theta_1, x, y):
"""모든 예측 값들과 목표 변수들의 오차를 벡터로 리턴해주는 함수"""
return prediction(theta_0, theta_1, x) - y
def gradient_descent(theta_0, theta_1, x, y, iterations, alpha):
"""주어진 theta_0, theta_1 변수들을 경사 하강를 하면서 업데이트 해주는 함수"""
for _ in range(iterations): # 정해진 번만큼 경사 하강을 한다
error = prediction_difference(theta_0, theta_1, x, y) # 예측값들과 입력 변수들의 오차를 계산
theta_0 = theta_0 - alpha * error.mean()
theta_1 = theta_1 - alpha * (error*x).mean()
return theta_0, theta_1# 입력 변수(집 크기) 초기화 (모든 집 평수 데이터를 1/10 크기로 줄임)
house_size = np.array([0.9, 1.4, 2, 2.1, 2.6, 3.3, 3.35, 3.9, 4.4, 4.7, 5.2, 5.75, 6.7, 6.9])
# 목표 변수(집 가격) 초기화 (모든 집 값 데이터를 1/10 크기로 줄임)
house_price = np.array([0.3, 0.75, 0.45, 1.1, 1.45, 0.9, 1.8, 0.9, 1.5, 2.2, 1.75, 2.3, 2.49, 2.6])
# theta 값들 초기화 (아무 값이나 시작함)
theta_0 = 2.5
theta_1 = 0
# 학습률 0.1로 200번 경사 하강
theta_0, theta_1 = gradient_descent(theta_0, theta_1, house_size, house_price, 200, 0.1)
theta_0, theta_1 # 최적의 세타값을 리턴최적의 세타0, 세타1의 값
(0.16821801417752186, 0.3438032402351199)경사 하강법의 시각화는 VSCODE를 참고해라.
📍 학습률
-
너무 큰 학습률
가 너무 크다면 의 값이 너무 크게 변하기 때문에 수렴을 하지 않고 발산을 할 수 있다. -
너무 작은 학습률
가 너무 작다면 이 정말 미미하게 변하기 때문에 수렴하기까지의 시간이 오래 걸리고, 연산의 수가 많아져 비효율적이다. -
적절한 학습률
따라서 는 1, 0.1, 0.01, 0.001 또는 0.5, 0.05, 0.005 이런 식으로 하나씩 실험을 해보면서 경사 하강을 제일 적게 하며 손실이 잘 줄어드는 학습률을 선택한다.
📍 RMSE
모델이 결과를 얼마나 정확히 예측하는지를 평가할 때 많이 쓰는 게 '평균 제곱근 오차', 영어로는 'root mean square error', 줄여서 'RMSE'라고 한다.
그냥 전에 배웠던 평균 제곱 오차에 루트를 하여 숫자를 정상화시켜주는 것이다.
📍 Training Set vs Test Set
학습시킨 훈련 데이터셋으로 RMSE를 평가하면 항상 좋게 나올 수밖에 없다. 따라서 애초에 데이터 셋을 훈련 데이터셋과 테스트 데이터셋으로 분리한 뒤에 진행을 한다.
예를 들어 전체 데이터셋에서 Training Set은 80%, Test Set은 20% 이런 식으로 분리하고 진행한 뒤에 학습된 모델을 평가할 때는 Test Set을 이용한다.
📍 scikit-learn 적용
💡데이터 셋 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=5)💡선형회귀 모델 사용
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
model = LinearRegression()
model.fit(x_train, y_train)
model.coef_ # 세타 1의 계수
model.intercept_ # 세타 0의 계수
y_test_prediction = model.predict(x_test)
mean_squared_error(y_test, y_test_prediction) ** 0.5 # RMSE 즉, MSE에 루트를 씌우기 위해 1/2 승을 해준다.출처: 코드잇
