📌 다중 선형 회귀
다중 선형회귀에서는 하나의 입력 변수가 아니라 여러 개의 입력 변수를 사용해서 목표 변수를 예측하는 알고리즘이다.
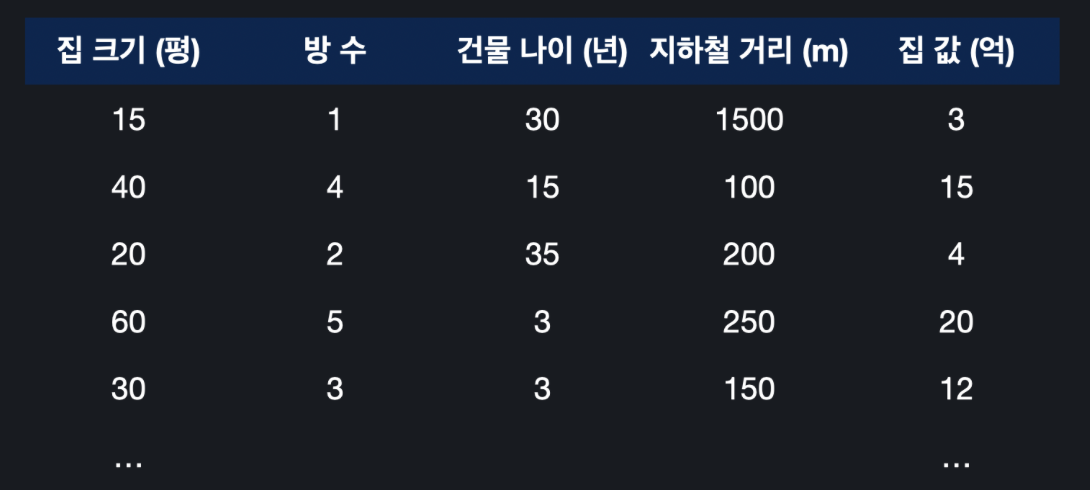
위 사진으로 데이터의 표현 방법을 알아보자. 피처의 개수는 n개, 학습 데이터의 개수는 m개이고, 목포 변수는 여전히 한 개이다.
집 크기, 방 수, 등등의 피처는 x1,x2,x3,...로 나타내고, 이를 가지는 입력 변수 하나는 x(i)라 표현한다. 일반화 해서 표현하자면 다음과 같다. x(i)=⎣⎢⎢⎢⎡x1x2x3x4⎦⎥⎥⎥⎤ 따라서 x(i)는 여러 개의 피처들을 담은 벡터이다.
i번째 데이터의 j번째 속성은 xj(i) 와 같이 나타낼 수 있다.
📍 가설 함수
다중 선형회귀의 가설 함수는 피처의 개수가 많아짐에 따라 가설 함수 또한 다음과 같이 나타낼 수 있다.
hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn
θ1 은 집 크기가 미치는 영향, θ2 은 방 수가 미치는 영향.. 등등이다.
💡 Vectorization
θ=⎣⎢⎢⎢⎢⎢⎢⎡θ0θ1θ2⋮θn⎦⎥⎥⎥⎥⎥⎥⎤,x=⎣⎢⎢⎢⎢⎢⎢⎡1x1x2⋮xn⎦⎥⎥⎥⎥⎥⎥⎤
θ 와 x 를 위와 같이 벡터화 한다면 다중 선형 회귀 가설 함수는 아래와 같이 정의할 수 있다.
hθ(x)=θTx
📍 다중 선형 회귀에서의 손실 함수와 경사 하강법
다중 선형회귀의 손실함수는 입력 변수가 하나일 때와 완전히 동일하다.
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
다중 선형회귀에서는 단순히 업데이트 해야할 θ 값들이 많아지는 것이다. 다중 선형회귀에서의 경사 하강법을 수식으로 나타내면 아래와 같다.
θj=θj−αm1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
j에 0부터 n까지 넣어가면서 θ0 ~ θn 까지 쭉 업데이트를 해야 경사 하강을 한 번 했다고 할 수 있다.
💡 Design Matrix
다중 선형회귀의 입력 변수를 행렬로 표현하면 다음과 같다.
X=⎣⎢⎢⎢⎢⎢⎡x0(1)x0(2)⋮x0(m)x1(1)x1(2)x1(m)⋯⋯⋯xn(1)xn(2)xn(m)⎦⎥⎥⎥⎥⎥⎤
행렬로 표현할 때 통일성을 위해서 가설함수 hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn 에 값이 1인 가상의 0번 속성 x0을 만들어준 것이다. 즉, hθ(x)=θ0x0+θ1x1+θ2x2+⋯+θnxn 처럼 표현할 수 있었고 위와 같은 행렬로 표현이 가능해졌다.
θ 또한 벡터로 표현하면 다음과 같다.
θ=⎣⎢⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎥⎤
그렇다면 예측 값은 행렬 X와 벡터 θ의 곱으로 나타낼 수 있다.
Xθ=⎣⎢⎢⎢⎢⎢⎡θ0x0(1)+θ1x1(1)+⋯θnxn(1)θ0x0(2)+θ1x1(2)+⋯+θnxn(2)⋮θ0x0(m)+θ1x1(m)+⋯+θnxn(m)⎦⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡hθ(x(1))hθ(x(2))⋮hθ(x(m))⎦⎥⎥⎥⎥⎤
예측 오차는 Xθ 에서 y 를 빼면 된다.
error=Xθ−y=⎣⎢⎢⎢⎢⎡hθ(x(1))−y(1)hθ(x(2))−y(2)⋮hθ(x(m))−y(m)⎦⎥⎥⎥⎥⎤
이로써 다중 선형회귀의 경사하강법은 다음과 같이 표현하는 것이 가능해진다.
⎣⎢⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎥⎤←⎣⎢⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎥⎤−αm1⎣⎢⎢⎢⎢⎢⎡∑i=1m(hθ(x(i))−y(i))⋅x0(i)∑i=1m(hθ(x(i))−y(i))⋅x1(i)⋮∑i=1m(hθ(x(i))−y(i))⋅xn(i)⎦⎥⎥⎥⎥⎥⎤
이를 정리하면 아래와 같다.
θ←θ−αm1(XT(Xθ−y))
이렇게 행렬을 사용하여 표현하게 되면 쉽게 구현을 할 수 있다는 장점이 있다. 구현해본 코드는 아래와 같다.
import numpy as np
def prediction(X, theta):
"""다중 선형 회귀 가정 함수. 모든 데이터에 대한 예측 값을 numpy 배열로 리턴한다"""
return X @ theta
def gradient_descent(X, theta, y, iterations, alpha):
"""다중 선형 회귀 경사 하강법을 구현한 함수"""
m = len(X)
for _ in range(iterations):
error = prediction(X, theta) - y
theta = theta - alpha / m * (X.T @ error)
return theta
house_size = np.array([1.0, 1.5, 1.8, 5, 2.0, 2.5, 3.0, 3.5, 4.0, 5.0, 6.0, 7.0, 8.0, 8.5, 9.0, 10.0])
distance_from_station = np.array([5, 4.6, 4.2, 3.9, 3.9, 3.6, 3.5, 3.4, 2.9, 2.8, 2.7, 2.3, 2.0, 1.8, 1.5, 1.0])
number_of_rooms = np.array([1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4])
house_price = np.array([3, 3.2, 3.6 , 8, 3.4, 4.5, 5, 5.8, 6, 6.5, 9, 9, 10, 12, 13, 15])
X = np.array([
np.ones(16),
house_size,
distance_from_station,
number_of_rooms
]).T
y = house_price
theta = np.array([0, 0, 0, 0])
theta = gradient_descent(X, theta, y, 100, 0.01)
print(theta)
최적의 세타값들:
array([ 0.11484521, 1.21120425, 0.18270523, 0.30060782])
📍 정규 방정식 (Normal Equation)
경사 하강법은 손실함수 J(θ) 의 극소점을 향해 θ를 조금씩 수정하는 것이라면, 정규 방정식은 J′(θ)=0 인 방정식을 풀어 손실함수의 기울기가 0이 되는 θ를 단번에 찾는 방법이다.
정규 방정식은 아래와 같다.
θ=(XTX)−1XTy
이 식이 도출되는 첫 단계는 먼저 손실함수를 행렬을 이용해서 표현해야 한다. 우리는 이전에 아래와 같은 손실함수를 보았다.
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
여기서 시그마로 구성된 식은 MSE 즉, 평균 제곱 오차의 합이다. 이것을 행렬 연산으로 다음과 같이 간단하게 표현할 수 있다.
J(θ)=2m1(Xθ−y)T(Xθ−y)
이제 ∇J(θ)=0 을 구하면 된다. 일단 미분을 할 것이니 앞의 상수 2m1은 무시하자. (Xθ−y)T(Xθ−y)을 전개하면 아래와 같다.
((Xθ)T−yT)(Xθ−y)
=((θTXT)−yT)(Xθ−y)
=θTXTXθ−θTXTy−yTXθ+yTy
=θTXTXθ−2θTXTy+yTy
이제 θ에 대해서 미분을 하자.
∂θ∂J(θ)=2XTXθ−2XTy
이제 미분한 식이 0이 되도록 하는 θ 를 찾아야 하므로 θ에 대해서 정리해주자.
2XTXθ−2XTy=0
XTXθ=XTy
θ=(XTX)−1XTy
이로써 증명이 끝났다.
📍 경사 하강법 vs 정규 방정식
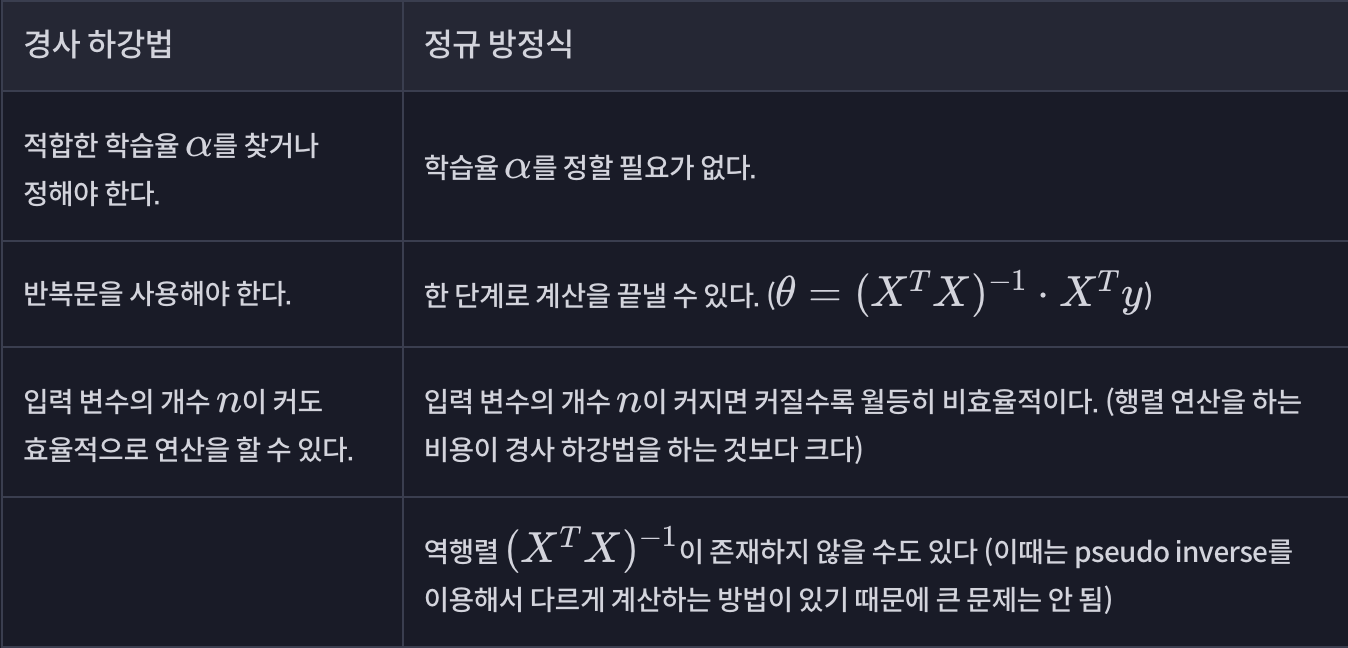
입력 변수가 1000개를 넘느냐를 기준으로 하는 게 일반적이다.
📍 Convex vs Non-Convex
손실함수 J(θ) 의 기울기를 구한 뒤에 이걸 이용해서 손실이 최소가 되게 하는 θ를 찾았었다.
근데 단순히 경사 하강법과 정규 방정식만 이용하면 항상 손실 함수의 최소 지점을 찾을 수 있을까?
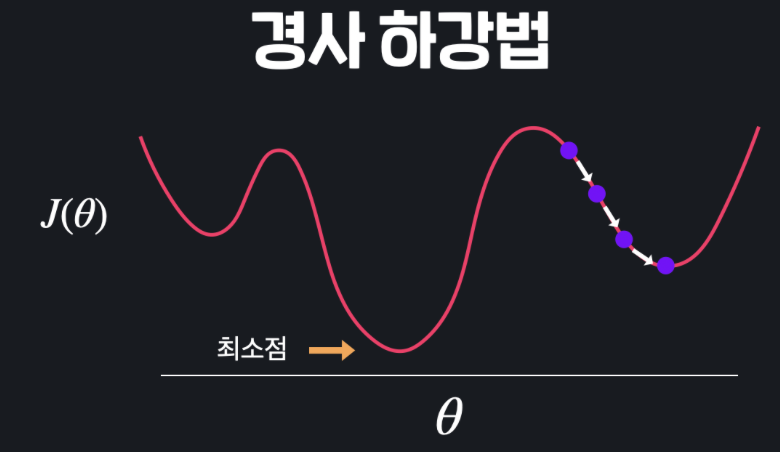
경사 하강법 같은 경우에는 임의의 지점에서 시작을 하고 경사 하강을 한 뒤 극소점에 도달해 경사 하강이 종료되었을 때, 그 지점이 전역 최솟값(Global minimum)을 가진다고 확신할 수 없다. 즉, 지역 최솟값(Local minimum)일 수도 있다는 것이다. 이러면 손실함수의 최저점을 찾아갈 수가 없다.
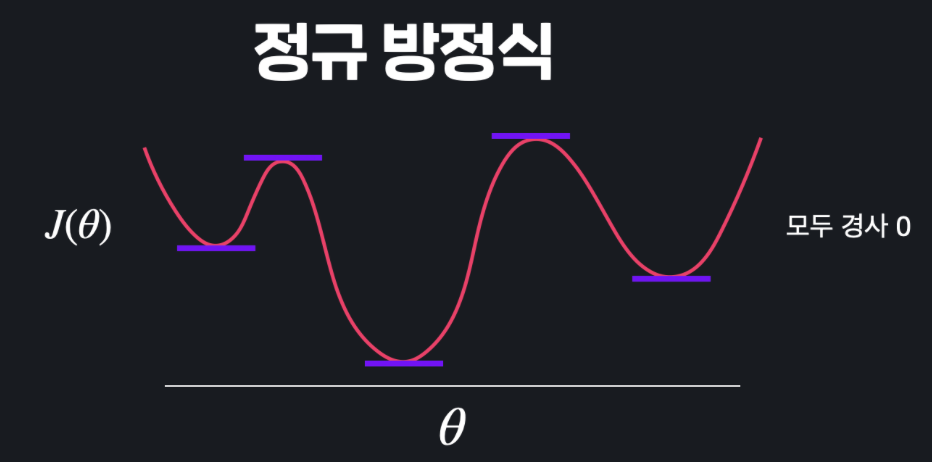
정규 방정식도 마찬가지이다. 미분값이 0이 되게 하는 θ 값을 구해도, 그 θ 에 대한 손실함수 값이 전역 최솟값인지는 모른다.
이렇게 함수가 Non-Convex한 경우에는 경사 하강법과 정규 방정식으로 값이 항상 전역 최솟값이라고 확신할 수는 없게 된다.
반대로 손실함수가 Convex하다면 즉, 아래로 볼록하다면 경사 하강법과 정규 방정식으로 값이 항상 전역 최솟값이라고 확신할 수 있다.
선형 회귀에서는 MSE를 손실 함수로 사용했는데, MSE는 오차의 '제곱'이니까 Convex 하게 된다. 따라서 선형 회귀를 할 때는 경사 하강법과 정규 방정식 모두 전역 최솟값을 보장한다.
출처: 코드잇
