📌행렬 인수분해
📍행렬 인수분해란?
인수분해란 자연수나 다항식을 여러 개의 인수의 곱으로 변형하는 수학 개념이다. 따라서 행렬 인수분해란 말 그대로 하나의 행렬을 두 개의 다른 행렬의 곱으로 변형하는 것을 의미한다.
일단 예시를 먼저 봐보자.
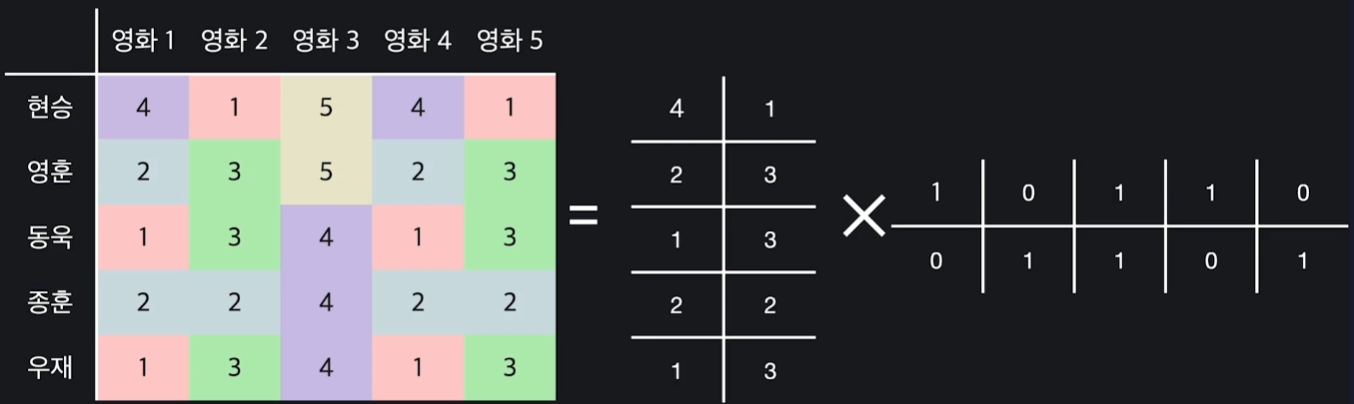
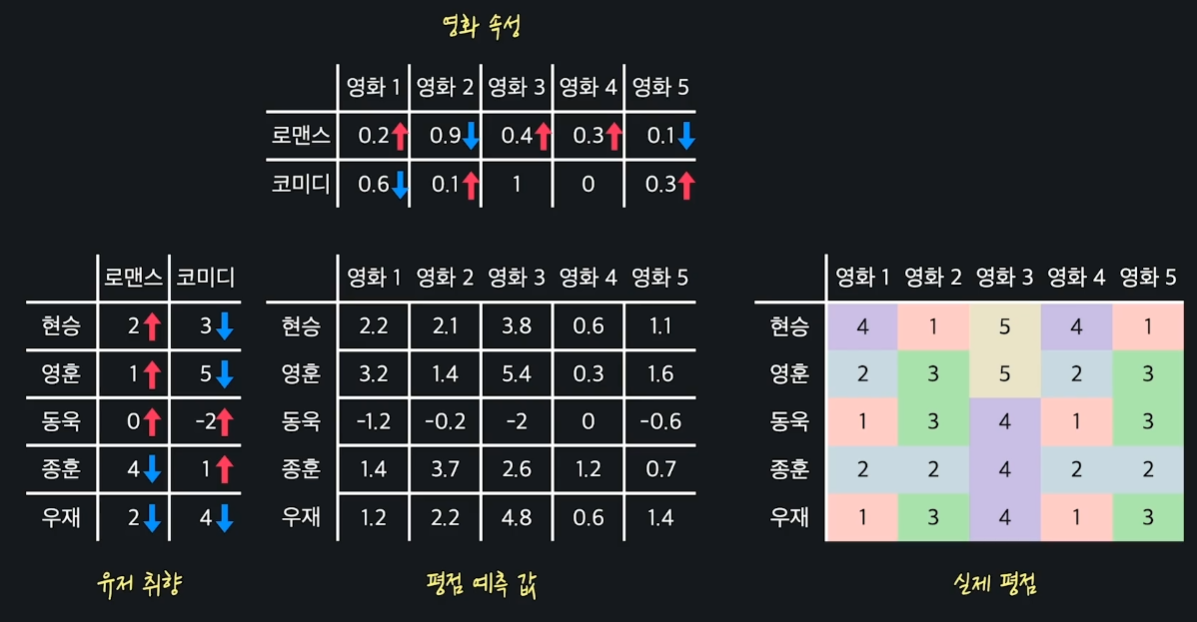
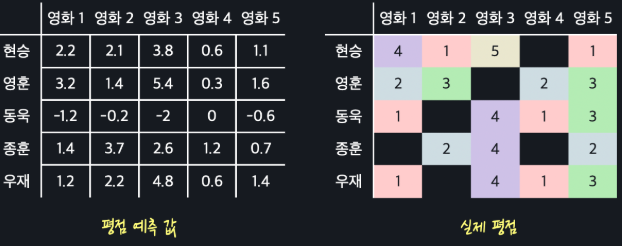
왼쪽의 평점 데이터 행렬을 오른쪽의 5X2 행렬과 2X5 행렬로 분해할 수 있다고 하자. 이를 보기 편하게 다시 나타내면 아래와 같다.
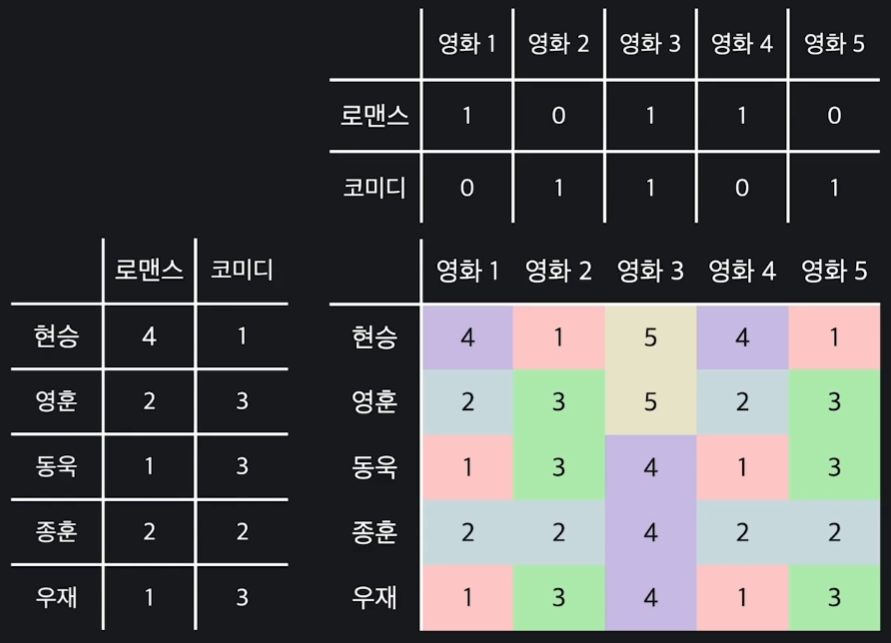
위 사진에서 평점 테이블 왼쪽에 있는 행렬(5X2)은 유저의 취향을 저장하고 있는 행렬이라 할 수 있다. 예를 들어 현승은 로맨스를 4만큼 좋아하고, 우재는 코미디를 3만큼 좋아한다고 할 수 있다.
위에 있는 행렬(2X5)은 영화의 속성을 저장하고 있는 행렬이다. 예를 들어 영화 1은 로맨스 속성을 1만큼 가지고 있으나, 코미디 속성은 가지고 있지 않으며, 영화 3은 로맨스와 코미디 속성을 둘 다 가지고 있다고 볼 수 있다.
이렇게 유저의 취향을 저장하고 있는 행렬을 , 영화의 속성을 저장하고 있는 행렬을 이라 한다면, 평점 테이블 행렬 은 다음과 같이 인수분해 될 수 있다.
이는 다시 말해, 유저의 영화에 대한 평점은 유저의 취향과 영화의 속성의 곱이라고 할 수 있다.
이런 평점 행렬을 인수분해 하는 방식을 사용하면 아래와 같이 비어있는 평점 부분을 예측할 수 있다.
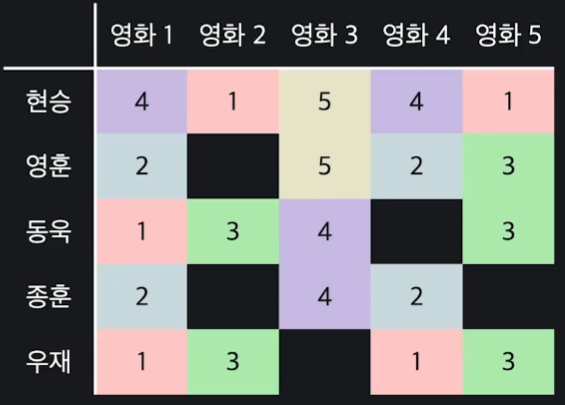
위의 평점 행렬에서 평점이 몇 개 비어있더라도 방금과 같이 이를 행렬 인수분해 하여 와 로 쪼갤 수 있다면, 이들의 곱으로 비어있는 평점을 역으로 예측할 수 있다.
실제로 이 방식을 사용하면, 성능이 굉장히 좋은 추천 시스템을 만들 수 있다.
하지만 평점 행렬이 완전할 경우 행렬 인수분해가 쉽지만, 위와 같이 평점이 비어있는 경우에는 완전한 행렬 인수분해가 쉽지 않다.
따라서 행렬 인수분해를 하더라도, 곱했을 때 최대한 평점 행렬과 비슷하게 나오는 두 행렬을 구할 것을 목표로 해야한다.
📍Feature Learning
행렬 인수분해는 와 모두 머신러닝으로 구한다는 것이 특징이다. 즉, 유저의 취향은 물론이고 영화의 속성마저 머신러닝 기법으로 구한다는 것이다. (따라서 원래 어떤 속성이 뽑히는지는 해석 불가능하지만, 편의상 로맨스와 코미디 속성이 뽑혔다고 가정한다.)
영화의 속성을 직접 정해서 나타내는 행렬은 얼마나 정확할까? 아무래도 주관적인 의견이 들어갔을 것이기에 정확도가 높다고 보긴 어렵다.
따라서 영화의 속성 또한 머신러닝 기법으로 구하자는 것이다.
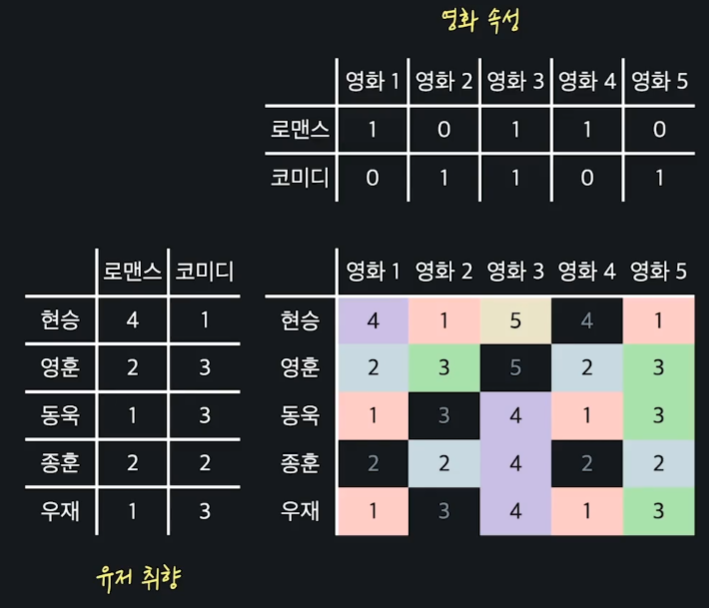
행렬 인수분해에서는 유저의 취향과 영화 속성을 둘 다 경사 하강법으로 학습을 하게 되는데, 아래 그림을 먼저 보자.
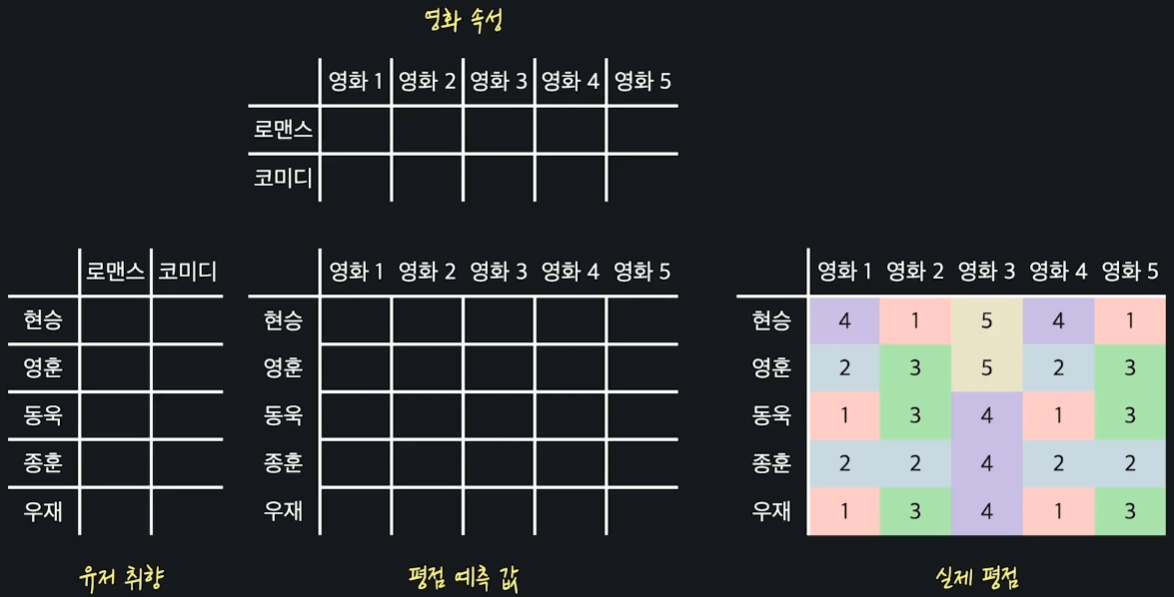
목표 변수인 실제 평점, 학습할 유저 취향과 영화 속성 행렬, 그리고 평점 예측 행렬이 있다.
일단 유저 취향 행렬과 영화 속성 행렬은 모두 학습을 통해서 구할 것이기 때문에 처음에는 임의의 값으로 초기화한다.
그리고 초기화 한 두 행렬을 곱해서 예측 값을 계산하고, 이 예측 값이 실제 값에 비해 얼마나 정확한지를 확인한다.
그런 다음엔 손실을 가장 빠르게 줄일 수 있는 방향으로 유저 취향과 영화 속성 행렬을 업데이트 해주면 된다. 이러한 과정을 다음 사진은 아래와 같다.
이게 지금 경사하강법을 한 번 해준 것인데, 이걸 필요한 만큼 충분히 반복해준다.
이 과정이 끝나면, 곱했을 때 실제 평점 행렬과 비슷하게 나오는 두 행렬을 구할 수 있게 된다. 즉, 행렬을 인수분해 했다고 할 수 있는 것이다.
이런 식으로 속성의 값도 머신러닝 기법으로 최적화 하는 방식을 속성 학습(Feature Learning)이라고 한다.
최적화한 영화 속성과 유저 취향 행렬을 구한 뒤에는 이제 이걸 사용하면 되는데, 아래와 같이 비어있는 평점이 있는 평점 행렬이 있다고 하자.
비어있는 평점은 유저 취향과 영화 속성 벡터를 내적곱을 해서 위와 같이 예측하면 된다.
여기서 예측 값이 높게 나오는 영화들을 각 유저에게 추천해주면 되는 것이다.
📍데이터 표현
이번엔 행렬 인수분해에서 사용할 수학적 표현들에 대해서 잠깐 짚고 넘어가보자.
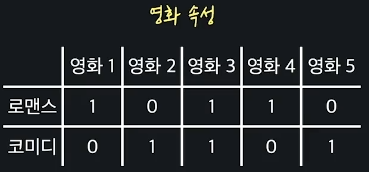
위와 같은 영화 속성 데이터에서는 변수 를 사용하여 다음과 같이 표현한다.
조금 더 일반화해서 자세히 표현하면 다음과 같다.
이는 번째 영화의 번째 속성을 나타낸다.
그리고 영화의 개수는 을 써서 나타내는데, movie의 앞글자를 따서 이라고 표현하겠다.
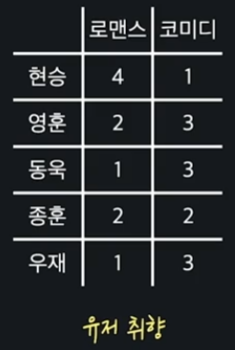
위와 같은 유저 취향 데이터에서는 를 써서 다음과 같이 표현한다.
조금 더 일반화해서 자세히 표현하면 다음과 같다.
이는 번째 유저의 번째 영화 속성에 대한 선호도를 나타낸다.
유저 데이터의 개수는 user의 앞글자를 따서 라고 표현하겠다.
그리고 방금 배웠던 데이터 표현법들을 가지고 유저 의 영화 에 대한 예측값은 다음과 같이 표현하여 계산할 수 있다.
즉, 유저 의 취향이 저장되어 있는 와 영화의 속성이 저장되어 있는 을 내적곱을 한다.
이는 유저가 로맨스를 얼마나 좋아하는지와 영화가 얼마나 로맨스인지를 곱하고, 유저가 얼마나 코미디를 좋아하는지와 영화가 얼마나 코미디인지를 곱해서 다 더하게 되는데, 이 값이 바로 유저 의 영화 에 대한 예측값이다.
실제 평점 데이터는 맞추려는 데이터니까 목표 데이터에 사용하는 변수 를 사용하자.
이는 번째 유저가, 번째 영화에 준 실제 평점을 나타낸다.
마지막으로 평점 데이터의 유무를 나타내는 데이터 표현법을 알아보자. 이는 을 사용해서 나타낸다.
예를 들어 평점을 줬으면 1, 안 줬으면 0으로 표시할 수 있다.
📍손실 함수
위와 같이 예측한 평점(왼쪽)이 있고, 실제 평점(오른쪽)이 있다. 경사 하강법을 써서 두 행렬이 평점을 더 잘 예측하게 만들어 가려면 손실 함수가 필요하다. 손실 함수는 아래와 같다.
먼저 손실 함수 는 모든 유저 데이터 와 영화 데이터 에 대한 함수라는 뜻이다. 다시 말해 손실 함수가 얼마나 크고 작은지는 유저 속성과 영화 속성이 어떤 값들을 갖는지에 따라서 결정된다는 의미이다.
그 다음은 시그마인데, 은 유저가 실제로 평점을 준 영화들에 대해서만 오차를 구한다는 의미이다. 실제 평점 데이터에서 평점이 비어있는 부분은 오차를 계산할 수 없으니 말이다.
마지막으로는 예측 평점 값 과 실제 평점 값인 을 뺀 다음, 제곱한다.
정리하자면 유저가 실제로 평점을 준 영화들에 대해서만 예측 평점 값과 실제 평점 값을 빼고 제곱한 다음, 이 값들을 모두 더한다는 것이다. 즉, 평점 데이터에 대한 제곱 오차 합을 계산해 주는 것이다.
📍경사 하강법
우리는 유저 취향 값들과 영화 속성 값들을 잘 선택해서 둘을 곱했을 때 평점 데이터에 엄청 가깝게 나오게 하는 것이 목표이다. 즉, 손실 함수의 아웃풋을 최대한 작게 만들어야 한다.
이 때 경사 하강법을 사용하여 손실을 가장 빠르게 줄이는 방향으로 , 값들을 바꿔주면 된다. 식은 아래와 같다.
업데이트해야 할 변수가 늘어났긴 했지만, 평소에 보던 경사 하강법 알고리즘과 유사하다. 한 번 경사 하강을 할 때마다, 취향 데이터와 속성 데이터를 둘 다 업데이트하는 방식이다.
위 두 식에서 를 업데이트하는 것만 순차적으로 봐보겠다.
이 때 과 를 안으로 넣어준다. (시그마는 덧셈을 하는 역할밖에 없기 때문에 편미분은 시그마 안으로 옮길 수 있다.)
합성함수 미분을 하면 아래와 같은 결과를 얻을 수 있다.
를 업데이트 할 때에도 똑같이 적용하여 아래와 같이 구할 수 있다.
📍행렬 인수분해 손실 함수 볼록도
행렬 인수분해의 손실 함수는 non-convex이다.
선형 회귀와는 달리 변수가 뿐만 아니라 도 있고, 이 둘이 곱해졌기 때문이다.
따라서 경사 하강법으로 찾은 값이 전역 최적해가 아니라 지역 최적해일 수도 있다.
손실 함수가 볼록하지 않다는 문제점을 극복하기 위해서는 임의로 초기화를 여러번해서 경사 하강법을 많이 해본 이후, 가장 성능이 좋게 나온 모델을 사용하는 방식을 사용할 수 있다.
📍행렬 인수분해 정규화
잠깐 복습하자면, 과적합은 머신 러닝 모델이 training 셋에 너무 딱 맞아서 test 셋에서는 성능이 안 좋게 나오는 경우를 의미한다.
그리고 이를 막기 위해 정규화라는 작업을 진행해줬다.
정규화는 손실 함수에 특정 항을 더해서 각 파라미터들의 크기가 너무 커지는 걸 방지하는 방법이다.
다항 회귀의 경우 손실 함수에 L1 또는 L2 정규화 항을 더해서 손실 함수를 최소화시켜줌과 동시에 과적합까지 막을 수 있는 세타 값들을 경사 하강법으로 찾았었다.
이를 통해 여러 데이터셋에서도 일관된 성능으로 일반화 성능을 높일 수 있었다.
행렬 인수분해를 할 때도 모델이 과적합이 되는 문제가 발생할 수 있는데, 전에 배웠던 거랑 똑같이 손실 함수에 정규화 항을 더해줌으로써 이 문제를 극복할 수 있다.
현재 변수가 와 로, 이 두 변수들이 커지는 걸 막아야 한다. 그러기 위해서는 다음과 같은 정규화 항들을 더해주면 된다.
그냥 그냥 모든 와 값들을 제곱해서 더해주는 항들이다. 이걸 손실 함수에 더해주면 아래와 같다.
이는 편미분을 통해 각 파라미터들을 다음과 같이 업데이트해 줄 수 있다.
이렇게 업데이트를 하면 모델이 데이터에 과적합되는 걸 방지하면서 학습을 할 수 있다.
📍결과 해석 및 마무리
행렬 인수분해를 통해 얻게 되는 유저의 취향과 속성 행렬을 이용하여 평점 행렬의 비어있는 부분을 예측할 수 있었다.
지금같은 경우는 보기 편하게 학습된 데이터에서 로맨스와 코미디라는 이름을 붙여주었는데 사실은 정말 로맨스인지, 코미디인지, 공포인지, 스릴러인지는 아무도 모른다.
경사하강법을 통해서 학습을 할 때, 아래 사진과 같이 프로그램은 각 속성들이 어떤 의미를 갖는지를 알지 못한다. 그냥 경사 하강법을 통해서 단순하게 좀 더 예측을 잘할 수 있는 아무 취향과 아무 속성 값들을 찾아낼 뿐이다.
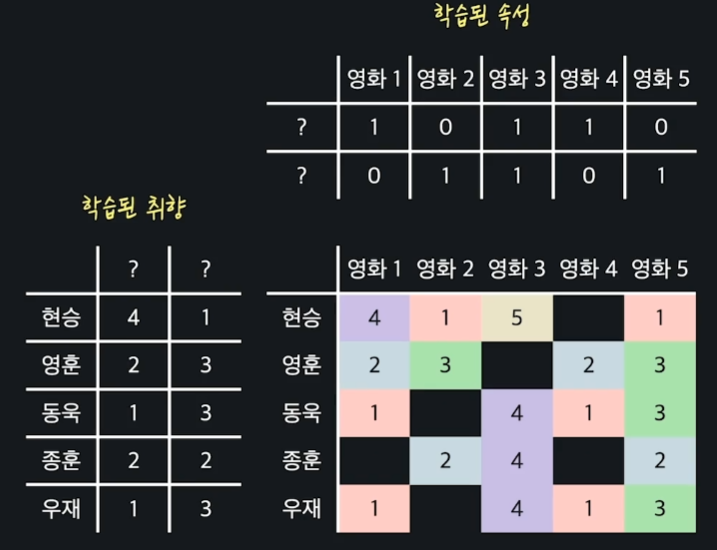
따라서 학습을 시작하기 전에, 각 데이터에 의미를 부여하지 않고 작은 임의의 값들로 초기화해준다.
또한, 어떤 속성을 쓸지는 정하지 않지만 몇 개의 속성을 뽑아서 쓸지는 정해야 하므로 이는 그리드 서치나 교차 검증 방식을 이용하여 최적의 속성 수를 알아내면 된다.
이렇게 임의의 작은 값들로 초기화 해주고 좋은 속성 값을 정해주면, 프로그램이 우리는 해석하기 어려운 좋은 속성들을 알아서 뽑아준다.
마지막으로 행렬 인수분해는 협업 필터링의 한 종류이다.
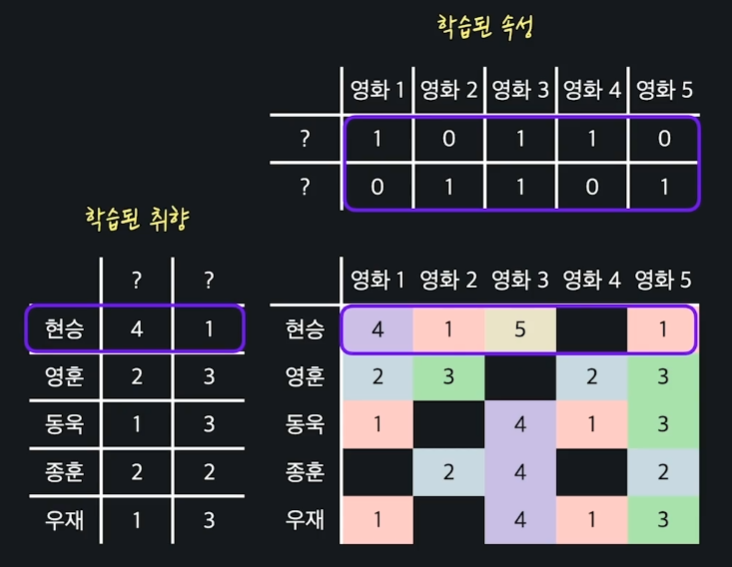
위의 사진과 같이 현승의 취향 값들은 영화 속성들과 곱했을 때, 실제 현승이 준 평점과 최대한 비슷하게 나오도록 학습이 됐었다. 이것만 보면 마치 현승의 취향이 학습될 때 다른 유저 취향을 고려하지 않은 것처럼 보인다.
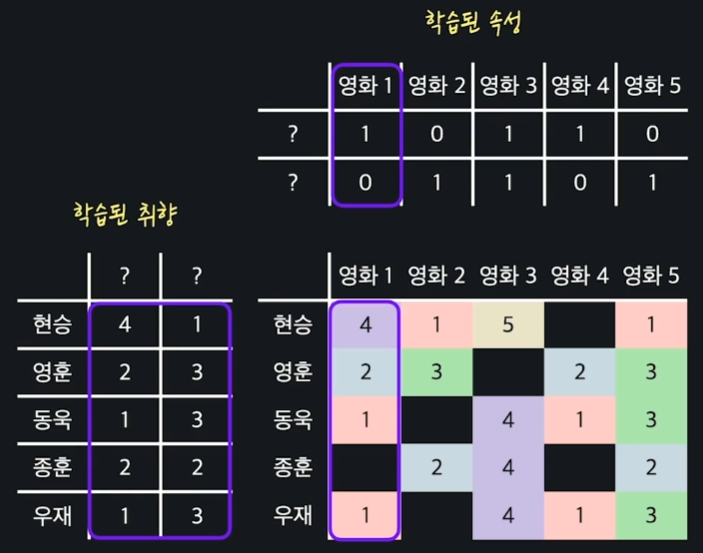
하지만 위와 같이 영화 속성 값들은 학습될 때 모든 유저 취향 값들과 곱해져서 학습이 된다. 그리고 이렇게 학습된 영화 속성은 다시 유저 취향을 학습할 때 사용이 된다.
이렇게 각 유저 취향과 영화 속성이 모든 유저 데이터를 사용해서 학습이 되기 때문에 행렬 인수분해는 협업 필터링이라고 볼 수 있는 것이다.
따라서 행렬 인수분해의 장단점은 협업 필터링의 장단점을 따라가게 된다.
내용 기반 추천, 유저 및 상품 기반 협업 필터링, 행렬 인수분해 모두 장단점이 있기 때문에 한 가지 모델만을 추구하는 것이 아니라 여러 모델을 종합적으로 사용하여 단점은 보완하고 장점은 살리는 방식을 추구해야 한다.
참고: 코드잇
