실험 기록의 중요성
대회가 시작하고 첫 주말이 왔다.
첫 2일 동안은 강의를 듣고, 수요일부터 본격적인 대회를 팀원들과 시작하였는데 회고글에서 말했다시피 baseline code를 분석하기에도 빡빡했고, 알고있던 이론을 코드로 구현하기에도 힘이 들었다. 그래도 뭐 꾸역꾸역 어떤 구조로 돌아가고, 내가 원하는 것을 하려면 코드의 어디를 고치면 되겠구나가 파악이 되어서 ResNet을 시작으로 모델을 학습시키기 시작했다.
하지만 가장 중요한 점을 빠트렸다는 것을 이제야 깨달았다....
바로 실험의 기록이다. 실험을 많이 하면 무슨 소용인가? 기록을 안해서 어떠한 하이퍼파라미터는 어느정도의 성능이 내었는지 모델 2~3개만 더 돌리다보면 까먹어버렸다....
그래서 기록을 하기 위한 TensorBoard를 하려고 했는데 이효석 캠퍼님께서 Wandb를 사용하는 것이 어떠냐고 제안하셨다. 그래서 모델을 돌려가며 Wandb가 무엇인지, 어떻게 구현을 하는지 공부를 했고, 실험삼아 모델을 몇번 돌리는 도중 이효석 캠퍼님께서 우리 팀의 Wandb project를 파주셨다. Wandb를 공부할때 참고한 사이트는 다음과 같다.
세상의 변화에 대해 관심이 많은 이들의 Tech Blog , 안경잡이개발자
느낀 점
기록은 못했지만, ResNet 모델을 돌려가며 깨달은 점은
-
Resize를 작게 하는 것보다 크게 하는 것이 성능이 잘 나온다는 점
-
epoch를 일단 많이 돌리고, early stopping을 하는 것이 편하다는 점
-
데이터 불균형으로 인해 일반화가 잘 안되고 오버피팅이 일어난다는 것.
-
평가를 F1_score로 하기 때문에, cross_entropy_loss 보다 f1_loss, focal_loss가 더 효과적이었다는 점.
-
lr_scheduler를 StepLR 보다 CosineAnnealingLR, ReduceLROnPlateau를 사용하는 것이 효과적이었다는 점.
기록을 잘 못해서 생각나는 점만 적었다..( 기록의 중요성을 세삼 느낀다...)
다음으로 Efficientnet을 모델로 사용하면서 Wandb에 기록한 내용들이다. (확실히 성능 비교도 편하고, 어떤 하이퍼파라미터들을 사용하였는지 비교하기도 좋다!!)
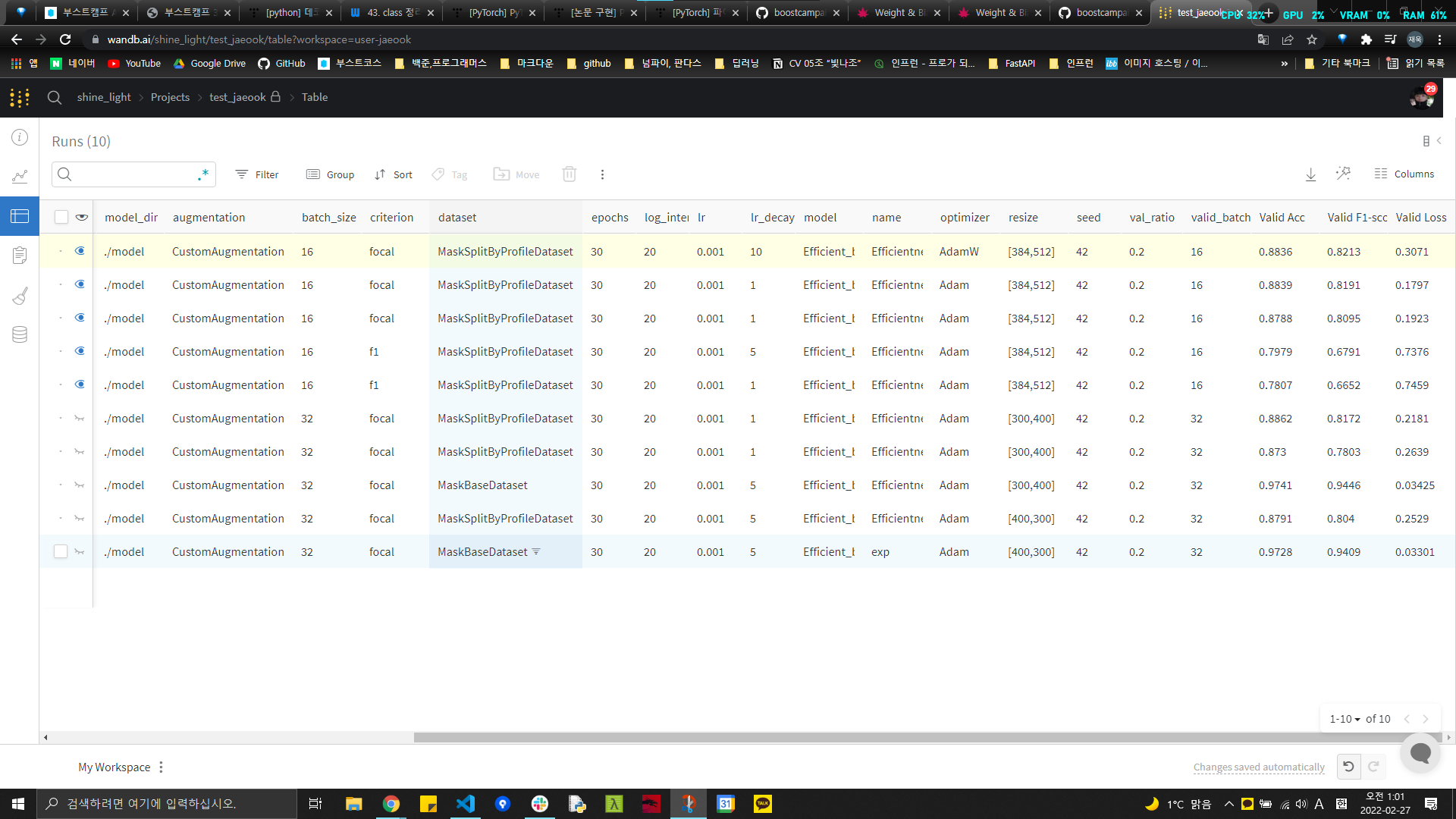
지금까지 실험을 해본것은 dataset, resize, criterion 이다.
-
dataset
-
dataset에는 마스크 착용 기준으로 train/val 을 나누는 함수와, 사람을 기준으로 train/val을 나누는 함수가 있다.
-
내가 한 실험 결과로 보자면 local에서는 마스크 착용 기준으로 나눈 dataset이 성능은 높게 나오지만 test에서는 성능이 많이 떨어졌다.
- 추측하건데 local에서는 val셋에 train셋에 있는 사람과 같은 사진이 들어갈 수도 있기 때문에 data leakage가 발생했기 때문이라 생각한다.
-
사람들 기준으로 train/val을 나누는 dataset은 local에서는 성능이 좀 떨어지지만, test에서의 성능과는 차이가 많이 안났다.
-
-
Resize
- 처음에는 (400,300) , (300,400) 으로 resize하여 학습을 시켰는데, 원본 사이즈인 (384,512)로 학습을 시키니 성능이 향상되었다.
- criterion
- 아직 비교중이지만 기존 loss인 cross_entropy_loss 보다는 f1_loss와 focal_loss의 성능이 더 높게 나왔다.
시도해볼것
-
AdamW 사용하기
-
Adam은 “optimizer는 묻지도 따지지도 말고 Adam을 사용해라” 라는 격언이 있을 정도로 만능 optimizer처럼 느껴진다. 하지만 만능인 것 치고는 일부 task, 특히 컴퓨터 비젼 task에서는 momentum을 포함한 SGD에 비해 일반화(generalization)가 많이 뒤쳐진다는 결과들이 있다했다.
(출처 : https://hiddenbeginner.github.io/ ) -
이를 해결한 AdamW를 사용해보기로 했다.
-
-
Data augmentation으로 data 불균형 맞추기.
