📌 우리 팀과 나의 학습목표
프로젝트 기간 동안 이번주 저희 팀의 학습목표는 점수와 순위에 집착하지 않고 이제 까지 배운 내용을 토대로 내실을 다질 수 있는 기회로 삼고, 앞으로 있을 스테이지를 진행하기 위한 기반(프로젝트, 코드)을 만들어 두는 것을 목표로 했습니다.
저의 개인적인 목표는 상위 순위권에 드는 것을 목표로 잡고 프로젝트를 시작했지만, 제가 생각했던 것 보다 EDA부터 시작해서 Dataset, Dataloader 등 모든 것이 어려웠습니다.
따라서 가장 먼저 baseline code를 분석하는 것을 목표로 삼고, 천천히 실험을 통해 어떤 구조로 학습이 이루어지는지 파악하는 것을 목표로 삼았습니다.
팀 학습
저희 팀은 가장 먼저 EDA를 통해 데이터의 불균형을 파악하고, 피어세션 시간에 이를 어떻게 해결하면 좋을지 간단히 의견을 나누었습니다. 그리고 각자 "아이디어 제시 및 어떤 테스트를 할 지"를 github issue 및 project에 올려서 서로 겹치지 않도록 저희만의 룰을 정했습니다. 물론 대부분의 팀원분들(저 포함)이 baseline code를 분석하고, AI에 관한 지식이 깊은 편이 아니라 진도가 많이 더뎠지만, 날이 지날수록 아이디어 제시 및 테스트 속도가 빨라졌습니다. 이를 토대로 하위권에 있던 저희 조의 순위가 중위권까지 올라갈 수 있었습니다.
개인 학습
저는 위에서 말했던 것 처럼 baseline code 분석을 제일 우선으로 삼고, 어느정도 구조를 파악하고 나서 가장 잘 알고 있는 모델인 VGG, ResNet으로 모델을 학습시켜 보았습니다.
또한, baseline code에 있는 여러 dataset, loss, resize 크기 등 여러 가지 조합의 수를 생각해서 모델을 반복적으로 돌려보며 어떤 조합이 가장 좋고, 우리 팀의 base조합으로 가져가면 될지 파악하고자 했습니다.
📌 나는 어떤 방식으로 모델을 개선했는가?
모델을 개선하기에 앞서 EDA를 하면서 느낀점은 주어진 데이터가 상당히 불균형하다는 것이었습니다. 모든 데이터셋은 아시아인 남녀로 구성되어 있고 나이는 20대부터 70대까지 다양하게 분포하고 있습니다. 간략한 통계는 다음과 같습니다.
- 사람 수 : 4,500
- 한 사람당 마스크 정상 착용 5장, 오착용 1장, 미착용 1장
- 이미지 크기 : (384, 512)
아래 사진과 같이 총 18개의 Class를 예측해야 합니다.

EDA를 수행한 결과 데이터의 불균형을 발견할 수 있었는데, 다음과 같습니다.
-
마스크 착용, 오착용, 미착용의 불균형 (5:1:1)
클래스별 불균형이 심해서 이를 해결할 방안이 필요
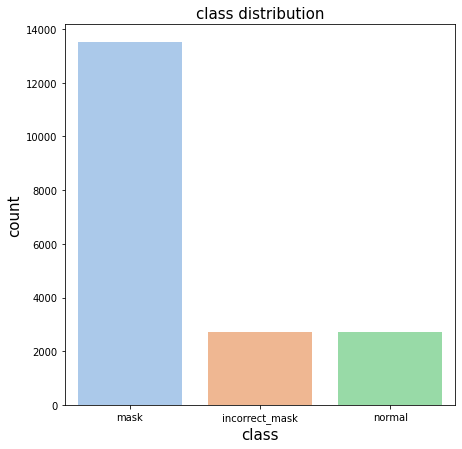
-
마스크 오착용의 기준이 되게 여러가지다.(턱스크, 눈?스크 등 제각각)
-
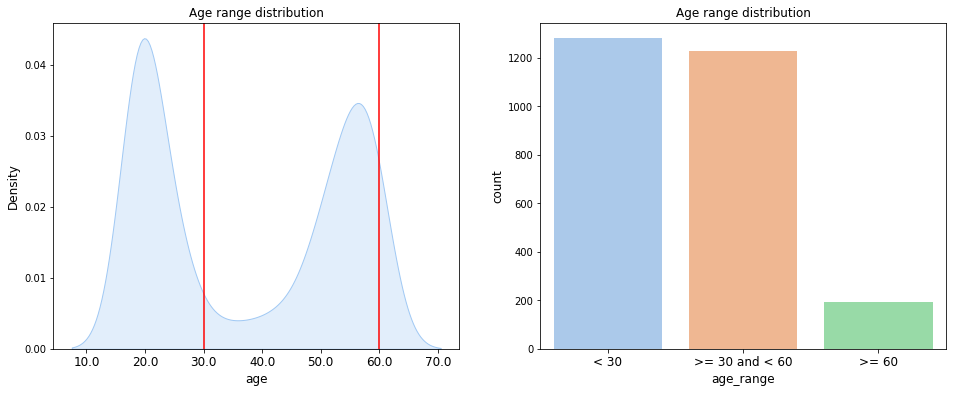
나이 그룹이 총 3개의 그룹(18~29, 30~59, 60~) 으로 나뉘는데, 60세 이상의 데이터는 전체 데이터의 약 8% 수준
사용한 지식과 기술
우선 저희 팀은 데이터 불균형을 해소하기 위해 다음과 같은 방법을 제시했습니다.
-
나이 그룹과 마스크 착용 데이터에 대해서 부족한 데이터를 직접 augmentation 하여 데이터 수를 늘리는 방법
-
Cutmix 방법
-
전체적으로 data augmentation 을 적용하여 data 증강.
-
성별, 마스크, 연령대 별로 학습을 시켜 앙상블 시키기.
-
평가 기준인 F1-score에 맞춰서 loss와 metric 변경하기.
Data에 대해서는 위와 같이 크게 5가지 방법을 제시하였습니다. 각 방법에 대해 github project로 역할이 겹치지 않게 수행해보도록 하였습니다.
다음으로 baseline code로 주어진 .py 파일들을 분석해가며 model과 loss, metric 등 여러 가지를 직접 수행하며 어떤 조합을 기본 base로 가져갈지 분석하기로 했습니다. 또한, 실험해봐야 할 조합이 많기 때문에 git issue 및 project를 이용해서 서로 실험이 중복되지 않게 하기로 그라운드룰을 정했습니다. 그리고 각자 생각난 아이디어는 저희가 정한 양식에 맞게 issue에 등록하기로 했습니다.
📌 마주한 한계는 무엇이며, 아쉬웠던 점은 무엇인가?
사전학습 되지 않은 ResNet부터 시작해서 여러가지 모델과 하이퍼파라미터의 조합을 실험해보고자 했으나, 이론을 Python IDLE 형식의 코드로 옮기는 실력에서 부족함을 많이 느꼈습니다...
그리고 마주한 문제점을 제대로 파악하지 못했습니다. Multi classification 관점에서 각각의 클래스는 상호 배타적(Mutually Exclusive), 독립적이라는 가정이 따르는데, 만약 이 정답 클래스 들이 서로 어떤 공통분모가 존재해서 의존성이 있는 경우라면 위와 같이 학습하는게 과연 옳은 것인가... 에 대한 마스터님의 조언을 잘 이해하지 못하였습니다.
또한 처음 하는 협업 및 대회이기 때문에, 초반에 팀원들과 협업을 하는데 다소 어리버리한 점이 아쉬웠습니다.
📌 한계/교훈을 바탕으로 스스로 새롭게 시도해볼 것
-
이론을 코드로 옮기는 실력을 기르기 위해 baseline code 와 special mission을 주말동안 수행하자.
-
무작정 모델을 돌리지 말고 왜 이러한 모델에서는 이러한 성과를 냈느지 한 번쯤 생각해보자
-
팀원들과 소통을 더욱 활발히 하자
📌 느낀 점 및 잘한 점
-
대회를 처음 접해서 많이 낯설었지만, 아주 좋은 경험이 될 것 같다
-
baseline code를 활용해 나만의 커스텀 모델 개발하는 방법을 배움. ----> 아직 부족하다.. 더 공부!!
-
github로 협업을 하는 방법을 터득!! --> 더 연습이 필요
-
Wandb를 적용한점!!! --> 너무 유용하다!!!
