📌 Model
PyTorch의 특징
-
Low-Level
-
PyTorch는 Low-level로 짜여져 있어서, 부분적으로 내용들을 이해하고 있으면 쉽게 Custom화 할 수 있다는 장점이 있다.
-
텐서플로우 같은 경우는 기능적인 부분만 익힌다면 쉽게 사용 가능하지만 내가 원하는 Tuning에는 한계가 있다. 반면 파이토치 같은 경우는 처음 보면 기능을 이해하는데 어려움이 있겠지만, 한번 이해하면 더 Flexible하게 사용할 수 있다.
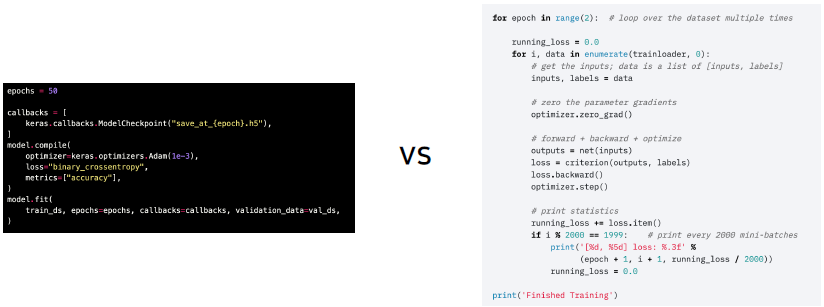
케라스는 사용하기에는 매우 간편하지만, 세세하게 뜯어 고치기에는 힘들다..
-
-
PyThonic
-
Flexibility
-
Dynamic Graph
nn.Moudule
Pytorch 모델의 모든 레이어는 nn.Module 클래스를 따른다.
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x)) -
__init__에서 레이어들을 정의. -
모델의 클래스를 선언하고
module()메소드를 통해 모듈이 어떻게 구성되어 있는지 확인할 수 있다.- 이때 모듈들은 파라미터를 가진 모듈을 의미한다.
forward
모델이 가지는 연결점들을 연결해 순서대로 진행되는 과정(순전파).
-
forward 함수도 nn.Module을 상속받으면 구현해주어야하는 함수이다.
-
모든 nn.Module은 child modules를 가질 수 있다.
-
모델을 정의하는 순간에, 그 모델에 연결된 모든 module을 확인할 수 있다.
-
forward함수를 한번만 실행한 것으로 그 모델의 forward에 정의된 모듈 각각의 forward()가 실행이 된다.
- 즉 쉽게 얘기하면, nn.Module 상속을 통해 만들어진 모델 클래스는 자잘자잘한 모듈들의 forward의 실행을 통해 합쳐진다고 이해하면 쉽다.
Parameters
모델에 정의되어 있는 modules가 가지고 있는 계산에 쓰일 Parameter
-
state_dict(): 파라미터들의 키 값과 tensor를 같이 출력 -
parameters(): 파라미터들의 tensor 값만을 출력 -
각 모델 파라미터들은 data, grad, requires_grad 변수 등등을 가지고 있다.
-
data : 파라미터의 값들
-
grad : 각각 파라미터가 어떤 Gradient를 가지고 있나.
-
requires_grad : 그레디언트를 계산할 대상인지 확인(boolean)
-
Pre-Trained Model
미리 학습된 좋은 성능이 검증되어 있는 모델을 사용하면 시간적으로 매우 효율적
torchvision.models 에서 다양한 Pre-Trained Model을 제공한다.
Transfer learning
학습된 weight를 가져와서 바로 사용하는 것이 아니라 '나의 task에 맞게 수정하고 변형'해줘야한다. 이처럼 이미지넷의 weight를 나의 task에 맞게 학습시키는 과정을 Transfer learning이라고 한다.
ResNet18의 일부를 보면 다음과 같다.
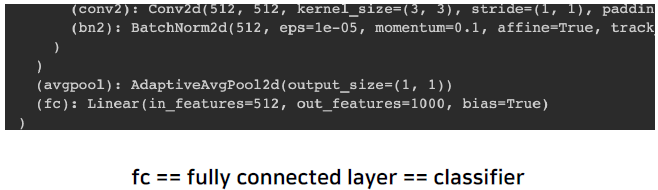
ResNet의 경우 마지막 out_features를 보면 1000개로 되어 있다. 이 Pre-Trained 된 모델은 실생활 존재하는 이미지를 1000개의 다른 Class로 구분하기 위한 모델이었기 때문이다.
Pre-Trained 모델을 학습할 때 사용한 데이터 및 Task와 '내 데이터 및 모델과의 유사성'을 따져가면서 적용해야한다.
Case by Case
Case 1. 문제를 해결하기 위한 학습 데이터가 충분할 때
.png)
위의 방식은 Feature Extraction, 아래 방식은 Fine Tuning이라고 한다.
Case 2. 학습 데이터가 충분하지 않은 경우
- High Similarity : CNN Backborn = Freeze, Classifier = Trainable
- Low Similarity : 추천하지 않음
📌 Training & Inference
학습 프로세스에 필요한 요소는 크게 Loss, Optimizer, Metric 으로 나눌 수 있다.
Loss
Backpropagation을 진행할 때, Output과 Target 값을 가지고 Loss 값을 구할 때 사용하는 함수이다.
.png)
-
Loss는 nn 패키지안에 멤버로 있다.
-
Loss 함수 또한 forward 함수를 가지고 있기 때문에, Model과 연결되어 학습이 진행된다.
-
loss.backward()-
backward()함수가 실행되면 모델의 파라미터의 grad 값이 업데이트 된다.
-
파라미터의 required_grad가 False가 되면 업데이트 해당 파라미터는 업데이트 되지 않는다.
-
forward 함수를 통해서 Model 부터 loss 과정 전체가 Chain 으로 연결
-
Optimizer
-
LR scheduler : 학습 시에 Learning rate를 동적으로 조절할 수 없을까?
- StepLR : 특정 step마다 LR 감소
.png)
- CosineAnnealingLR : Cosine 함수 형태처럼 LR을 급격히 변경
.png)
- ReduceLROnPlateau : 더 이상 성능향상이 없을 때 LR 감소
.png)
- StepLR : 특정 step마다 LR 감소
Metric
모델의 평가
-
Classification : Accuray, F1-score, precision, recall, ROC & AUC
-
Class별 밸런스가 적절히 분포 → Accurary
-
Class별 밸런스가 좋지 않아서 각 클래스 별로 성능을 잘 낼 수 있는지 확인 필요 → F1 score
-
-
Regression : MAE, MSE
-
Ranking : MRR, NDCG, MAP
-
학습된 모델을 객관적으로 평가할 수 있는 지표가 필요
✍ 데이터들의 Label 분포가 불균형, 너무 한 쪽으로 치우쳐져 있는 경우에 ACC 는 높은 것처럼 보이나 실제로는 정확도가 높지 않을 수 있다. 그래서 Balance 하게 데이터를 가꾸는 것도 성능에 중요한 요소이다.
Training Process
-
Training 프로세스 이해
-
model.train()- module을 training mode로 Setting 해준다. 이를 왜 해주냐면, training/evaluation 과정에서 Dropout이나 BatchNorm 과정이 다르게 영향을 줄 수 있기 때문
-
optimizer.zero_grad()-
매 Step 마다 이전 Step에 있는 Gradient가 남아 있기 때문에 초기화 해준다.
-
이전 단계의 gradient를 사용하지 않을 것이면 zero_grad()를 통해 grad 값을 초기화한다.
-
-
loss = criterion(outputs, labels)- optimizer의 step()함수가 input으로 받은 파라미터를 돌면서 업데이트된 grad값을 보고 파리미터를 업데이트
-
Gradient Accumulation
-
GPU 메모리 한계로 인해 미니배치의 분포를 가지고 학습을 하게 되는데 어떤 데이터는 전체 데이터의 분포를 따라야 하는 경우도 존재
-
Update하는 작용에서 Step을 건너 뛰어서 Gradient를 중첩시켜 놓고난 다음, Update를 진행
-
-
Inference Process
-
model.eval()-
evaluation mode로 세팅하는 함수
-
여러 이유 중 하나는 dropout 같은 기법들은 train 시에는 동작해야하지만, evaluate 할 때는 동작하면 안되기 때문.
-
-
with torch.no_grad()-
torch.no_grad()를 with statement에 포함시키게 되면 Pytorch는 autograd engine을 꺼버린다. -
즉, 더 이상 자동으로 gradient를 트래킹하지 않는다는 말이 된다.
-
📌 Ensemble
Ensemble
싱글 모델보다 더 나은 성능을 위해 서로 다른 여러 학습 모델을 사용하는 것
-
High Bias를 가진 경우 Boosting 을 사용
-
High Variance의 경우 Bagging을 사용(예를들어, 랜덤 포레스트)
-
Model Averaging (Voting)
-
Hard Voting : 다수결 방식, 다른 모델에서 소수의 의견이 무시될 수 있다는 단점이 존재.
-
Soft Voting : Hard Voting의 단점을 해결. 각 모델이 예상되는 확률들을 계산하고 모두 고려하는 방식.
-
- Cross Validation
- '훈련 셋과 검증 셋을 분리는 하외, 검증 셋을 학습에 활용할 수 없을 까?'--> Validation set을 적절히 섞어서 학습에 활용할 수 있다.
-
Stratified K-Fold Cross Validation
-
가능한 경우를 모두 고려 + split 시에 Class 분포까지 고려
-
적절한 Validation과 Train을 비율로 나누고, 그 Validation을 한 덩어리로 생각을 하고 모든 경우로 나눠서 처리하는 방법.
.png)
-
-
TTA(Test Time Augmentation)
-
Test 할때, Augmentation을 부여해서, 여러 상황에서 어떤 결과가 있는 지 확인해보는 방법
-
테스트 이미지를 Augmentation한 후, 출력된 여러가지 결과를 앙상블 한다.
-
Hyperparameter Optimization
Hyperparameter란?
-> 시스템의 매커니즘에 영향을 주는 주요한 파라미터 ex) Hidden Layer 개수, Learning rate, K-fold의 K, batch_size, ...
Optuna
-
Optimization을 하는 라이브러리
-
파라미터 범위를 주고 그 범위 안에서 trials만큼 시행
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
return (x -2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
study.best_params # {'x': 2.002108042}📕 피어세션
- github 룰 정리
- issue template
- project
- commit convention
