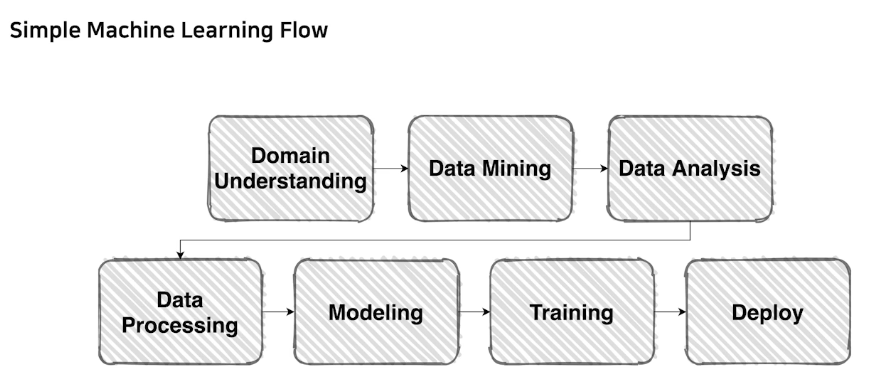
📌P-Stage
Level1 P-Stage는 카메라로 촬영한 사람 얼굴 이미지의 마스크 착용 여부를 판단하는 Task를 통해 프로젝트를 진행하게 됩니다. 이를 통해 실습 위주의 Practical Skill들을 학습하는 것이 목표이고, 머신러닝 파이프라인을 전체적으로 경험할 수 있습니다.
-
Competition을 통해 얻을 수 있는 것
-
내가 하고자 하는 것에 방향성을 부여한다.
-
문제가 있다면 문제를 정의할 수 있다.
-
정의된 문제로부터 데이터를 통해서 해결할 수 있는가를 고민한다.
-
데이터를 통해서 해결할 수 있다면, 이를 AI로 해결할 수 있는 것인지 고민을 한다.
-
AI로 해결할 수 있다면 어떤 모델로 어떤 파라미터로 접근하는 것이 적합한지 스스로 생각하고 판단한다.
-
2 Problem Definition(문제 정의)
-
내가 지금 풀어야 할 문제가 무엇인가?
-
이 문제의 Input과 Output이 무엇인가?
-
이 솔루션은 어디서 어떻게 사용되어지는가?
이런 접근으로 학습해야 다른 문제가 나오더라도 접근하는 접근법을 알 수 있게 될 것.
-
데이터 셋
제공되는 데이터셋은 남녀로 구성되어 있고, 연령은 20대 ~ 70대 입니다. 자세한 내용은 다음과 같습니다.
-
전체 사람 명 수 : 4,500
-
한 사람당 사진의 개수: 7 [마스크 착용 5장, 이상하게 착용(코스크, 턱스크) 1장, 미착용 1장]
-
이미지 크기: (384, 512)
이 데이터셋을 통해 마스크 착용여부, 성별, 나이를 기준으로 총 18개의 class를 예측해야 합니다.
평가 방법은 F1 Score를 통해 진행합니다.
-
프로젝트는 오는 수요일(23)부터 리더보드에 제출하여 평가를 받을 수 있고, 그 전까지 강의를 통해 프로젝트에 대한 기본적인 개념을 잡을 수 있을 것 같습니다.
📌Image Classification & EDA
✨ EDA(Exploratory Data Analysis)란?
탐색적 데이터 분석으로, 데이터를 이해하기 위한 노력이다.
-
EDA는 우리가 분석하고자 하는 대상에 대해 가지는 의문점을 분석하는 것!!
-
그러므로 EDA는 어떤 도구를 사용하여 분석하든지 상관없다.
✨ Image란?
시각적 인식을 표현한 인공물
-
이미지는 (width, height, channel)의 정보를 가지고 있으며, 채널은 (R, G, B)의 정보를 가지고 있다.
-
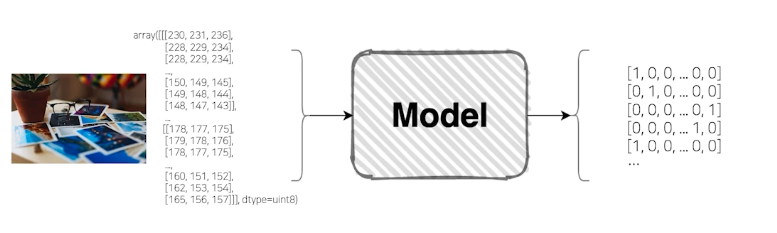
Input + Model = Output
.png)
- Input의 형태는 Image, Text, Sound, ... 등의 여러가지 형태를 가지고 있다.
- Output의 형태는 Categorical Class, Probability, Position, ... 등의 여러가지 형태를 가지고 있다.
- Input이 이미지이면? Image Classification Model
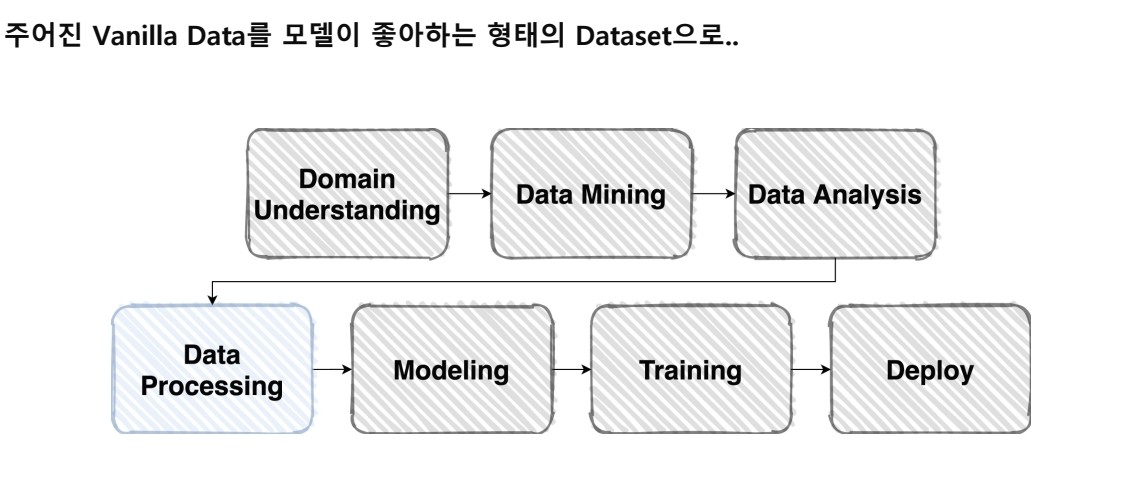
📌Dataset
✨ Vanilla 한 데이터를 원하는 모델에 맞게 일반화, 수정하는 작업을 통해 새 DataSet형태로 변환이 필요
-
Pre-processing
- 데이터 수집 후 결측치나 노이즈와 같이 쓸 수 없느 데이터가 존재 한다.
- 이를 해결하기 위해 전처리작업(Pre=processing)이 필요.
- 하지만 전처리작업이 꼭 성능 향상으로 귀결되는 것은 아니다. 전처리 방식이 당위성을 가지려면 많은 실험을 통해 입증해야 한다.
-
Resize
- 계산의 효율을 위해 적당한 크기로 사이즈 변경.
- 큰 사이즈의 이미지는 학습 하는데 시간이 굉장히 오래 걸리기 때문에 학습의 효율을 위해서 이미지를 적절하게 줄이는 방법.
.png)
-
Bounding box
- 바운딩 박스는 object를 crop하는 방법인데 직사각형 모양을 사용한다.
- 그러나 일반적인 물체는 사각형이 아닌 경우가 많기 때문에 물체를 제외한 나머지 부분은 사실상 노이즈라 할 수 있다.
- Train / Validation
- 모델 학습을 시킬 경우 항상 주의해야 할 점은 Underfitting 과 Overfitting.
.png)
- 위 그림을 보면 Underfitting은 bias가 높아 모델이 데이터를 잘 예측하지 못하고, Overfitting은 Variance가 높아 데이터는 잘 맞추지만 모델의 모양이 일관적이지 않다.
- 테스트 데이터로 평가를 하다 보면 테스트 데이터에만 최적의 성능을 발휘하는 편향된 모델을 유도하는 경향이 생길 수 있다. 이 경우 또 다른 새로운 테스트 데이터에 있어서 과도하게 성능이 낮아지는 문제가 발생할 수 있다.
- Train set중 일부를 분리하여 Validation set으로 Test 하
.png) 기 전에 제대로 학습되었는지 검증한다.
기 전에 제대로 학습되었는지 검증한다.
-
Data Augmentation
- 데이터의 수를 늘리는 방법은 오버피팅을 억제하는 방법 중 하나이다.
- Data Augmentation은 가지고 있는 데이터셋을 여러 가지 방법으로 augment하여 실질적인 학습 데이터셋의 규모를 키울 수 있는 방법이다.
- 하지만 아래와 같이 사진을 찍을때 거꾸로 뒤집은 경우 데이터로써 의미가 있을까?
.png)
📌Data Generation
-
Data Feeding
-
먹이를 준다 → 대상의 상태를 고려해서 적정한 양을 준다.
- 모델의 계산이 20 batch/s인데 Data Generator가 10 batch/s라면 성능은 10 batch/s이다.
- Data Generator가 30 batch/s인데 모델이 20 batch/s라면 성능은 20 batch/s이다.
- 즉, Model에 성능보다 Data Generator의 성능이 적다면 그만큼 효율이 낮을 것이고 반대로 Data Generator의 성능이 모델이 처리할 수 있는 양보다 높으면 Model의 최대 효율을 낼 수 있다.
.png)
-
-
Dataset 생성 능력 비교
transform1 = transforms.Compose([ transforms.ToTensor(), transforms.RandomRotation([-8,8]), transforms.Resize([1024,1024]) ]) transform2 = transforms.Compose([ transforms.ToTensor(), transforms.Resize([1024,1024]), transforms.RandomRotation([-8,8]) ])-
transformer1은 회전 후 크기 확대,transformer2는 크기 확대 후 회전 -
transformer2가 시간이 더 오래 걸린다.- 사진을 확대 하고 회전을 하려면 확대 한 만큼 연산량이 많아지기 때문.
-
-
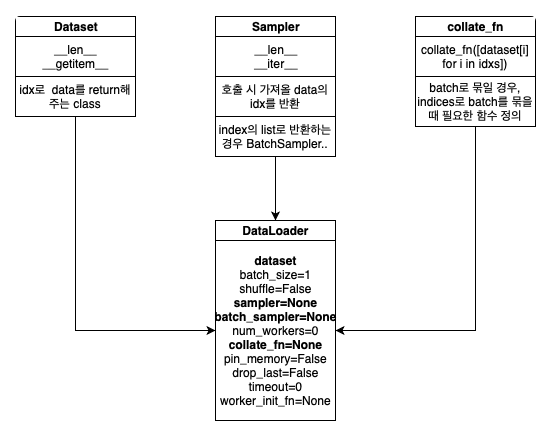
DataLoader
-
-
Dataset
- Data를 가지고있는 객체.
__len__,__getitem__을 구현해야 한다.- DataLoader를 통해 data를 받아올 수 있다.
-
DataLoader
- Dataset을 인자로 받아 data를 뽑아냄
-
Sampler
- data의 index를 반환
- Dataset을 인자로 받음
- shuffle을 하기 위해 씀
-
collate_fn
- batch sampler로 묶인 이후에는, collate_fn을 호출해 batch로 묶는다
-
📕 피어세션
- Special Mission 하기.
- 프로젝트 리더보드 열리기 전에 강의 다 듣기!!
- PyTorch Template
