Goals
Direction
프로젝트 기간 동안 저희 팀의 학습목표는 점수와 순위에 집착하지 않고 이제 까지 배운 내용을 토대로 내실을 다질 수 있는 기회로 삼고, 새로운 지식을 학습하는 것을 목표로 했습니다.
저의 개인적인 목표는 순위권에 드는 것을 목표로 프로젝트에 임하였지만, 제가 생각했던 것 보다 EDA부터 시작해서 Dataset, Dataloader 등 모든 것이 어려웠습니다.
따라서 천천히 실험을 통해 어떤 구조로 학습이 이루어지는지 파악하며, 여러가지 실험 툴을 사용하며 학습을 하는 것을 목표로 삼았습니다.
Team
저희 팀은 가장 먼저 EDA를 통해 데이터의 불균형을 파악하고, 피어세션 시간에 이를 어떻게 해결하면 좋을지 간단히 의견을 나누었습니다.
그리고 각자 "아이디어 제시 및 어떤 테스트를 할 지"를 github issue 및 project에 올려서 서로 겹치지 않도록 저희만의 룰을 정했습니다. 그리고 다른 협업 툴 로써 Slack과 Wandb를 사용하면서 협업툴을 경험해보고자 했습니다.
Personal
저는 baseline code 분석을 통해 어떤 구조로 파이프라인이 돌아가는지 파악하는 것을 제일 우선으로 삼고, 어느정도 구조를 파악하고 나서 성능이 좋은 모델인 ResNet, EfficientNet 으로 학습시켜 보았습니다.
또한, 여러 가지 조합의 수를 생각해서 모델을 튜닝하고 반복적으로 돌려보며 어떤 조합이 가장 성능이 좋고, 우리 팀의 base조합으로 가져가면 될지 파악하고자 했습니다.
What I did
모델을 개선하기에 앞서 EDA를 하면서 느낀점은 주어진 데이터가 상당히 불균형하다는 것이었습니다. 모든 데이터셋은 아시아인 남녀로 구성되어 있고 나이는 20대부터 70대까지 다양하게 분포하고 있습니다. 간략한 통계는 다음과 같습니다.
- 사람 수 : 4,500
- 한 사람당 마스크 정상 착용 5장, 오착용 1장, 미착용 1장
- 이미지 크기 : (384, 512)
아래 사진과 같이 총 18개의 Class를 예측해야 합니다.

EDA를 수행한 결과 데이터의 불균형을 발견할 수 있었는데, 다음과 같습니다.
-
마스크 착용, 오착용, 미착용의 불균형 (5:1:1)
클래스별 불균형이 심해서 이를 해결할 방안이 필요
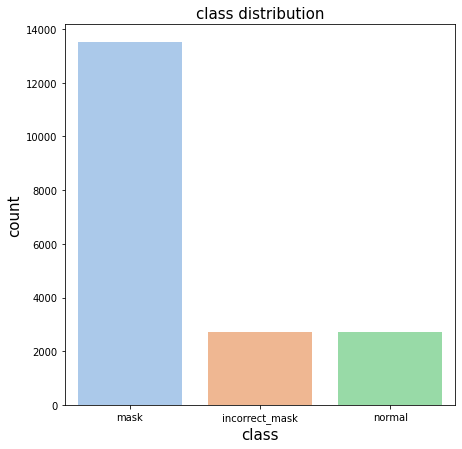
-
마스크 오착용의 기준이 되게 여러가지다.(턱스크, 눈?스크 등 제각각)
-
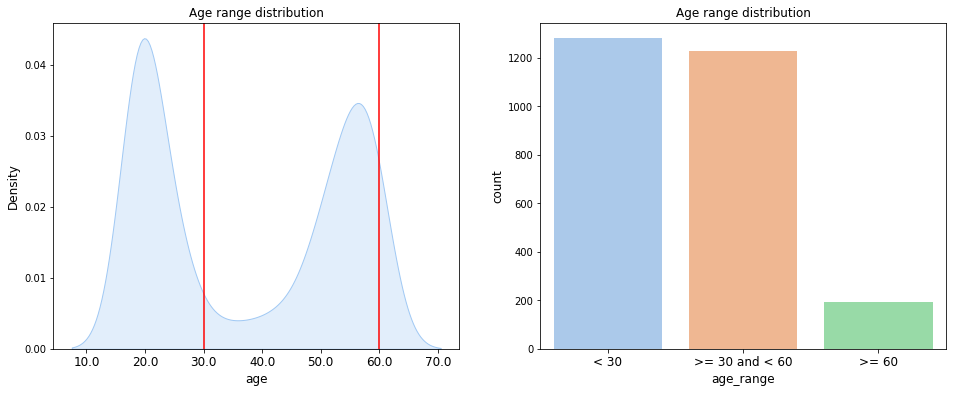
나이 그룹이 총 3개의 그룹(18~29, 30~59, 60~) 으로 나뉘는데, 60세 이상의 데이터는 전체 데이터의 약 8% 수준
사용한 지식과 기술
-
아키텍쳐 : efficientnet_b4
-
LB(F1_score) : 0.7311
-
dataset
- MaskSplitByProfileDataset
-
data augmentation
-
Train
- HorizontalFlip()
- ShiftScaleRotate()
- HueSaturationValue()
- RandomBrightnessContrast()
- GaussNoise()
- Normalize()
- ToTensorV2()
-
Valid
- Normalize()
- ToTensorV2()
-
-
img_size = 512 x 384
-
Loss : Focal loss
-
sampler : WeightedRandomSampler()
-
scheduler : CosineAnnealingWarmUpRestarts(T_0=10, T_mult=1, eta_max=3e-4, T_up=3, gamma=1)
-
optimizer : AdamP(lr=3e-5, weight_decay=1e-5, nesterov=True)
-
TTA(Test Time Augmentation)
-
StratifiedKFold : 5-fold
-
아키텍쳐는 ResNet을 사용하다가, ImageNet 대회에서 가벼운 모델로 최고 성능을 낸 EfficientNet을 사용했습니다.
dataset은 기존의 MaskBaseDataset(마스크 기준)에서 동일 인물의 사진이 학습셋과 검증셋에 섞여 들어가는 오버피팅이 발생하는 것을 방지하기 위해 MaskSplitByProfileDataset(Profile 기준)을 사용하여 같은 인물의 사진이 Train과 Valid에 섞여 들어가지 않도록 했고, 이는 generalization의 향상으로 이어졌습니다.
augmentation은 기존에 Train, Val셋에 동등하게 해줬던 baseline code를 customizing해서 Train/Val 각각 다르게 적용되도록 하였습니다.
또한 위에서 EDA 결과를 보면 알 수 있듯이, Class 불균형 해소를 위해 한 에폭에 Class가 균등하게 들어갈 수 있도록 Oversampling+Undersampling 기법인 Weighted Random Sampler를 적용해보았습니다. 이를 통해 0.6599 -> 0.6853로 성능이 향상되었습니다.
optimizer는 AdamP를 사용했습니다. 기존에 알고있던 Adam이 만능인 것 치고는 일부 task, 특히 컴퓨터 비젼 task에서는 momentum을 포함한 SGD에 비해 일반화(generalization)가 많이 뒤쳐진다는 결과들이 있었다고 합니다. AdamW를 소개한 논문 “Decoupled weight decay regularization”에서는 L2 regularization과 weight decay 관점에서 Adam이 SGD이 비해 generalization이 떨어지는 이유를 설명하고 있습니다. 또한 이렇게 optimizer에 대해 공부하던 중 ClovaAI에서 만든 AdamP를 알게되었고, 이를 사용하게 되었습니다.
loss는 기존의 cross_entropy를 사용하다가 평가지표가 f1이어서 f1_loss를 사용했습니다. 그리고 focal_loss와 f1_loss를 비교해 봤을 때, focal_loss의 LB점수가 더 높게 나와서 focal_loss를 사용했습니다.
Learning rate Scheduler는 Custom CosineAnnealingWarmRestarts, CosineAnnealingLR, ReduceLROnPlateau 이 세가지를 비교하며 실험하여 사용했습니다. 이 중 Custom CosineAnnealingWarmRestarts, ReduceLROnPlateau의 성능이 가장 좋았습니다.
마지막으로 StratifiedKFold를 적용(5-fold)하여 0.6925 -> 0.7311로 성능을 향상시켰습니다.
시도해봤으나 잘 되지 않았던 것들
-
저는 Data augmentation을 아주 많이 적용하고 모델을 학습시켰는데, 성능향상으로 이어지진 않았습니다. 이는 너무 많은 augmentation 때문에 오히려 성능을 감소시켰기 때문이라 생각합니다. 예를 들어 blur와 같은 augmentation은 age class를 분류하는데 중요한 '주름'과 같은 feature들을 없애서 성능이 떨어졌을 수도 있다 생각합니다.
-
마지막 날에 정확도를 높이기 위해 TTA(Test Time Augmentation)을 시도해 봤습니다. 2XTTA(원본, HorizontalFlip)을 시도했으며, 이는 horizontalflip은 사진의 좌우만 바꾸어 inference시에 mislabeling할 확률이 적다고 판단하였기 때문입니다. 처음엔 가중치를 각각 0.5씩 하여 TTA를 실행했지만, 성능은 오히려 떨어졌습니다. 그래서 가중치를 원본이미지에 더 많이 주어서 실험을 여러번 해봤지만, 여전히 성능향상으로 이어지진 않았습니다.
Review
마주한 한계
AI분야를 나름 많이 접해왔다 생각했지만, 막상 P-Stage를 시작하니 이제까지 자만심에 가득찼던 것을 깨달았습니다. EDA부터 시작해서 모델의 성능을 끌어올리는 것 까지 어느 것 하나 제가 스스로 해본 것이 이번이 처음이었고, 많이 낯설고 어려웠습니다. 데이터의 불균형 문제부터 시작해서, 모델을 설계하고, 오버피팅을 잡고, 노트북 형식이 아닌 Python Idle의 모듈 형식의 코드를 짜는 등 많은 어려움이 있었습니다.
하지만 주어진 baseline code와 팀원분들의 도움으로 이러한 어려움을 이겨낼 수 있었고, P-Stage를 시작하기 전의 나와 끝난 후의 나를 비교해보았을때 pytorch template을 기반으로 한 module형식의 코드를 짤 수 있는 능력을 얻음과 동시에 한층 성장했다는 것을 느낄 수 있었습니다.
아쉬웠던 점
여러 실험을 하면서 성능을 높이고 있는데 어느순간부터 f1_score가 더 이상 올라가지 않는 것을 보고 벽에 가로막힌 기분이 들어 의욕이 떨어진 적이 있습니다. 5~6일 정도 여러 튜닝을 하고, 여러 자료도 찾아가면서 실험을 해 보았지만 성능이 좋아지지 않아 포기하고 싶은 마음이 들어 하루정도는 쉰거 같습니다. 어떤 자료를 찾았을 때 "이것을 내가 풀고있는 문제에 적용할 수 있을까?"라는 생각이 들면 포기를 한 적도 많았습니다.
그런데 이제와서 생각해보면 "과연 내가 할 수있는 모든 시도들은 다 하고 포기를 한걸까?"라는 생각이 들었습니다. 제가 마주한 벽을 허물 수 있는 실마리를 찾았을 때, 그 길이 어려운것 같다고 포기를 하지 않았으면 대회 순위를 좀 더 올리고, 저 또한 한층 더 성장할 수 있었을 텐데 그러지 않은 점이 아쉽습니다.
한계/교훈을 바탕으로 다음 프로젝트에서 스스로 새롭게 시도해볼 것
이번 대회에서는 머신러닝 파이프라인을 전반적으로 경험해 보고 데이터셋이나 모델 학습,
추론 과정의 바탕이 되는 코드를 확보할 수 있는 과정이었습니다. 또한 평소 주로 사용하던 쥬피터노트북이 아닌 Python Idle로 pytorch template에 맞게 프로젝트를 구성하는 방법을 배울 수 있었습니다.
기반을 다져 둔 만큼 다음 프로젝트에서는 1단계에서 해 보지 못한 시도를 더 해 보려고
합니다. 어려울 것 같다고 포기했던 여러가지 방법론들을 적용해볼 것이고, 포기하지 않는 집념을 가지고 성능이 오르지 않더라도 하나라도 더 배워간다는 마음가짐으로 프로젝트에 임할 계획입니다.
이번 대회에서는 시간이 없어서 앙상블을 많이 적용해보지 못했기 때문에 다음 프로젝트에서는 여러 앙상블을 시도해보고자 합니다.
