(01강) Image Classification 1
사람은 오감, 특히 시각을 통해 세상과 소통을 합니다. 우리는 모든 정보의 약 75%를 눈을 통해서 받고, 뇌에서 50% 이상을 사용하여 시각정 정보를 처리한다고 합니다. 이러한 시각을 통해 정보를 해석하는 과정을 기계가 하는 방식으로 표현하면 아래 그림과 같이 나타낼 수 있습니다.
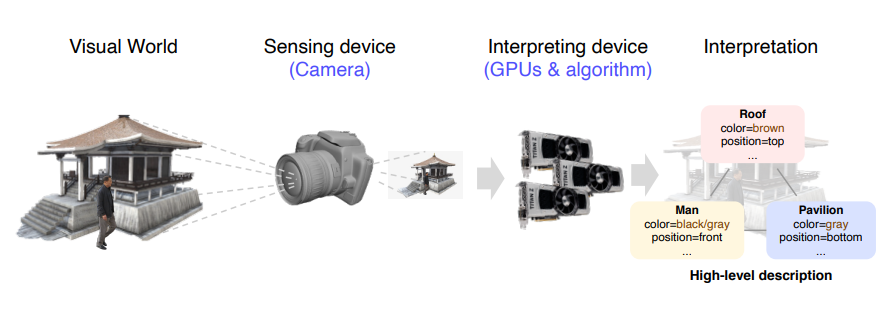
그림을 보시면 카메라가 사람의 눈 역할을 하며, GPU 및 알고리즘이 사람의 뇌 역할을 하게 됩니다. 추가적으로 이렇게 얻어진 정보를 다시 2D 이미지를 그려내는 것을 Rendering 이라고 부릅니다.
What is computer vision?
컴퓨터 비전이란 무엇일까요?
위키백과에 따르면 "컴퓨터 비전(Computer Vision)은 기계의 시각에 해당하는 부분을 연구하는 컴퓨터 과학의 최신 연구 분야 중 하나이다." 라고 나와있습니다. 즉, 컴퓨터 비전은 인간의 시각이 할 수 있는 몇 가지 일을 수행하는 자율적인 시스템을 만드는 것을 목표로 합니다. 그리고 컴퓨터 비전은 인간의 시각적 지각 능력을 이해하는 것을 포함합니다.
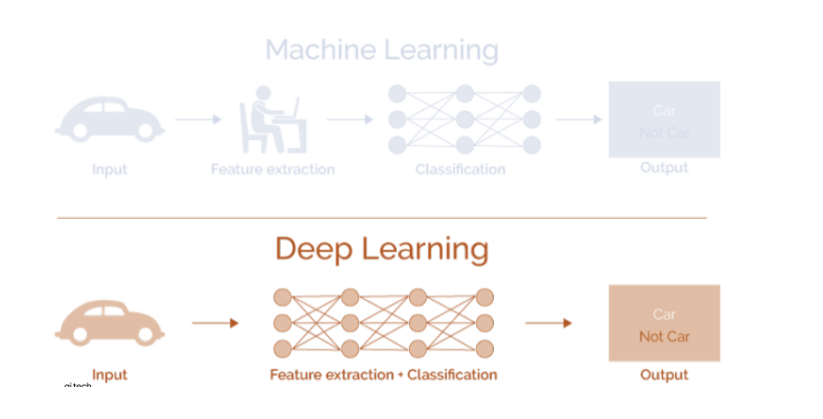
위 그림과 같이 과거에는 사람이 직접 feature을 추출하여 모델을 학습시켰다면, 현재는 Feature extraction과 Classification을 모델에서 동시에 하는 end-to-end 학습을 합니다.
Image classification
Image classification 즉, 이미지분류란 영상안에 어떤 물체가 있는지 분류하는 문제입니다.
우리가 만약 모든 데이터를 가지고 있다 가정하면, 분류문제는 k-NN(k Nearest Neighbors)로 풀 수 있습니다. 하지만 이 방법은 시간, 공간 복잡도와 각 데이터의 유사도 측정 방법 선정에 있어서 단점이 있습니다.
그렇다면 neural network는 어떨까요?
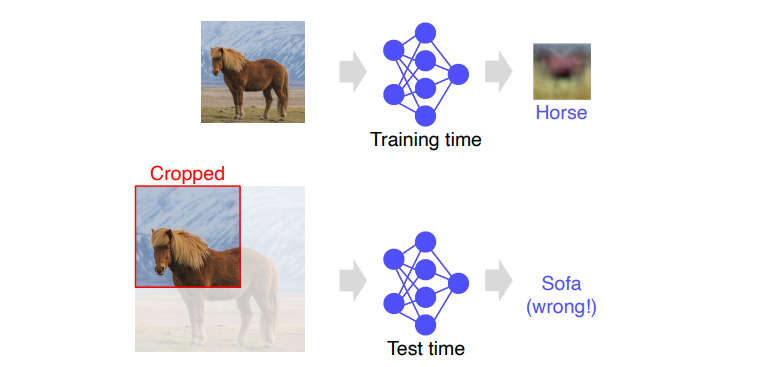
위와 같은 상황에서 single fc layer로 이미지 분류를 한다면 layer가 1개이기 때문에 표현력이 떨어지며 일반화 성능도 떨어질 것 입니다. 아래 사진과 같이 말이죠.
이러한 단점들을 해결한 것이 바로 CNN 입니다.
CNN은 FC layer와는 달리 locally하게 연결된 neural network입니다. 또한 가중치를 공유하여 FCN보다 모델의 파라미터 수도 현저히 적습니다.
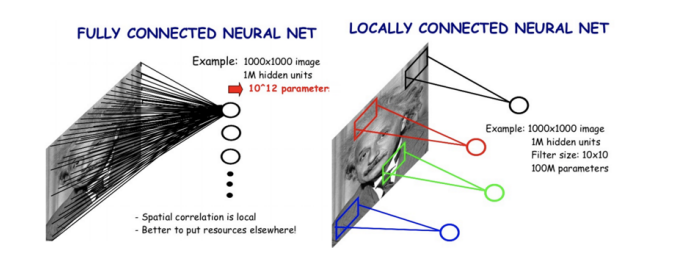
위 그림을 보면 FCN에 비해 CNN은 파라미터 수가 매우 적은 것을 볼 수 있습니다.
이렇게 CNN은 커널(필터)를 sliding window 기법으로 data를 순회하며 이미지의 국부적인 영역에서 feature을 추출합니다.
CNN architectures for image classification 1
cnn의 다양한 아키텍쳐는 이전 포스팅에 올려놨으니 여기서는 간단하게만 소개하겠습니다.
-
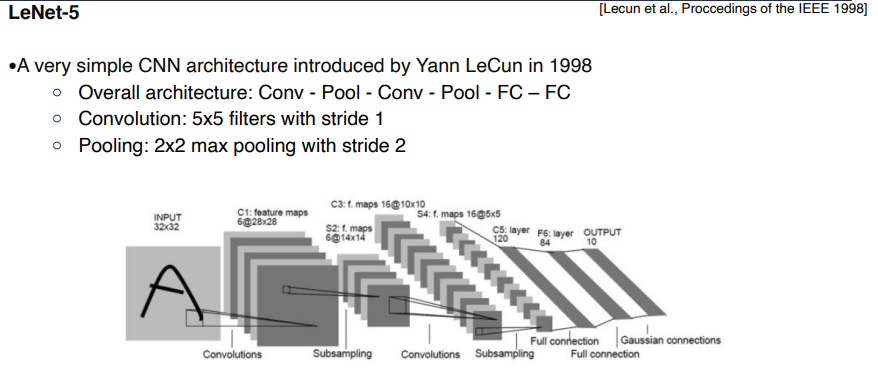
LeNet-5
-
AlexNet
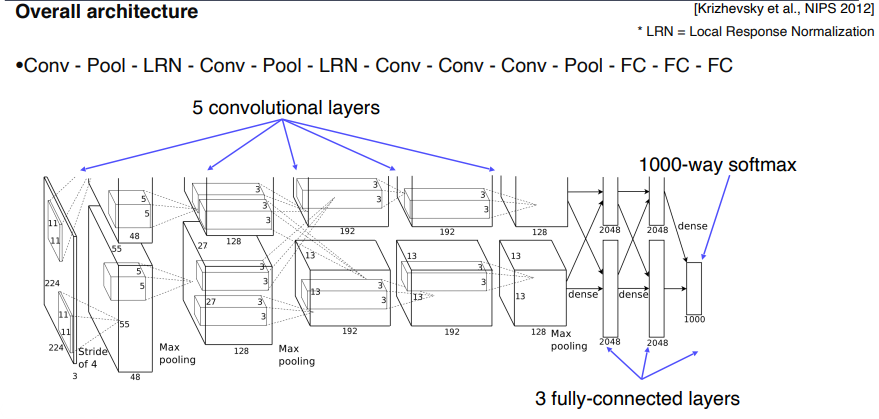
- AlexNet은 LeNet에 비해 모델이 더 커지고, ReLU를 사용했으며 Dropout 기법을 적용했습니다.
여기서 한 가지 알아가야 할 개념은 수용장(Receptive field) 입니다. convolution 연산은 입력과 그보다 작은 커널의 상호작용만으로 출력을 내기 때문에 결과적으로 특정 입력 노드 주변의 노드들만 기여를 하는데, 이때 기여하는 입력 노드들의 집합을 receptive field라고 합니다.
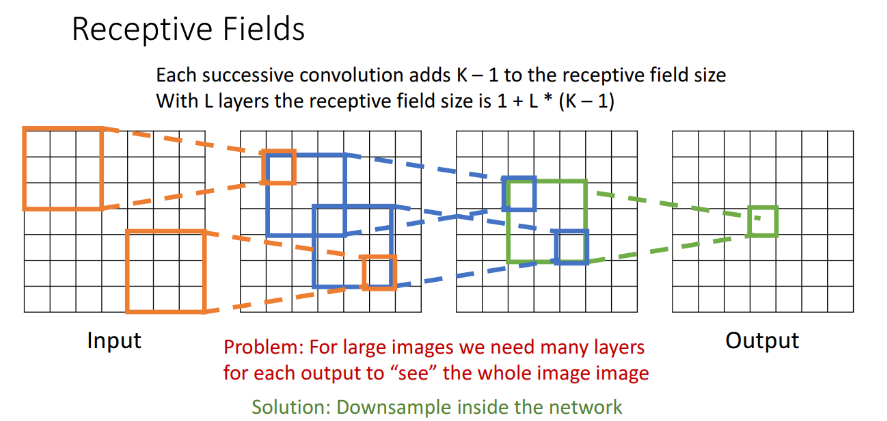
위 그림은 3-conv layer 일때의 receptive field의 예시입니다. output에서부터 확장해 나가면서 receptive field의 크기가 3x3, 5x5, 7x7까지 커지는 모습입니다.
-
VGGNet
-
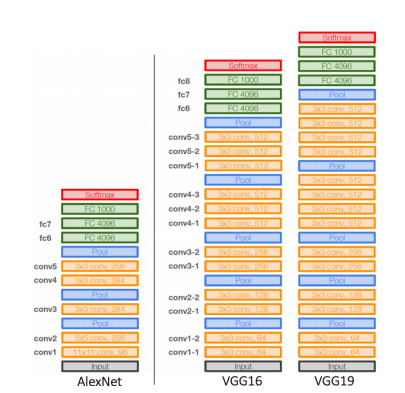
-
Deeper architecture (16 and 19 layers)
-
Simple architecture (No LRN, only 3x3 conv filter blocks, 2x2 max pooling) -> 작은 filter를 쌓으면 큰 Receptive field를 보는 것과 같은 효과
-
Better performance & Better generalization
-
다른 아키텍쳐들은 다다음 강의인 Image Classification2 에서 이어집니다.
Futher Reading
- VGGNet : https://arxiv.org/pdf/1409.1556.pdf
(02강) Annotation Data Efficient Learning
Neural Network는 데이터셋의 feature들을 학습합니다. 하지만 대부분의 dataset들은 biased 되어 있습니다. 즉, real data의 분포를 모두 표현할 수 없기 때문에 우리는 data augmentation을 사용하여 그 차이를 매꿀 수 있습니다.
data augmentation에는 많은 기법들이 있고, TORCHVISION.TRANSFORMS에서 확인할 수 있습니다.
Modern augmentation techniques
-
CutMix
-

-
‘Cut’ and ‘Mix’ training example to help model better localize objects
-
Mixing both images and labels
-
-
RandAugment
-
Many augmentation methods exist. Hard to find best augmentations to apply
-
Automatically finding the best sequence of augmentations to apply
-
Random sample, apply, and evaluate augmentations
-
Augmentation policy has two parameters
- Which augmentation to apply
- Magnitude of augementation to apply (how much to augment)
-
Parameters used in the above example
- Which augmentation to apply : ‘ShearX’ & ‘AutoContrast’
- Magnitude of augmentation to apply : 9
-
Transfer learning
Transfer learning : 기존에 미리 학습시켜놓은 모델을 사용하여 적은 학습으로 새로운 task에 적용
- Transfer knowledge from a pre-trained task to a new task ( Feature extraction )
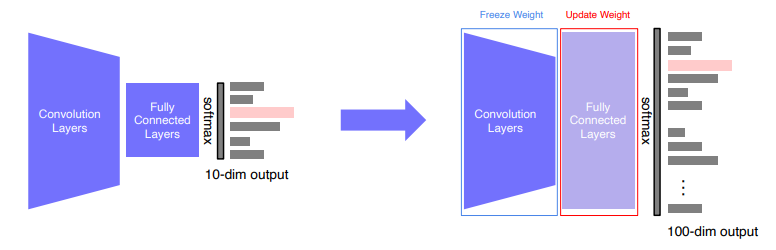
- Backbone은 freeze 시키고, FC layer만 새로 붙여 학습
-
Fine-tuning the whole model
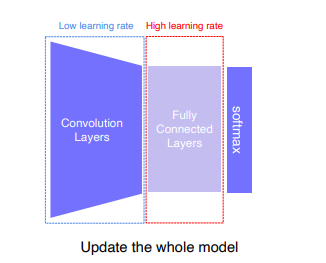
- 마찬가지로 classification을 위한 final layer은 바꾸고, Backbone은 low learning rate, FC layer 는 High learning rate를 주어 학습시킵니다. 데이터가 많이 필요합니다.
Knowledge distillation
- Teacher-student learning : 큰 모델이 학습한 지식을 작은 모델에 전달.
- 모델 압축에 사용(더 큰 모델이 알고 있는 것을 모방)
- pseudo-labeling에 사용됨(레이블이 없는 데이터세트에 대한 유사 라벨 생성)
-
Teacher-student network structure
-
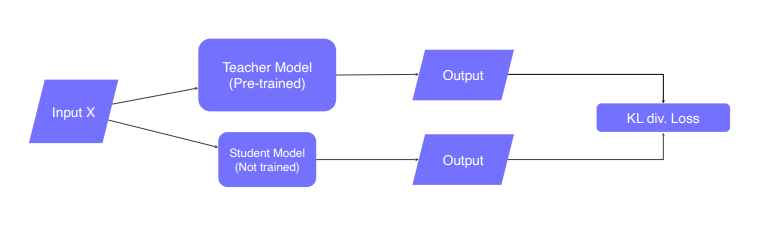
-
student network는 teacher network가 알고 있는 것을 학습합니다. 그리고 student network는 teacher network의 출력을 모방합니다. 이렇게 레이블이 지정되지 않은 데이터로만 학습을 수행하기 때문에 비지도 학습이라 할 수 있습니다.
-
-
Knowledge distillation
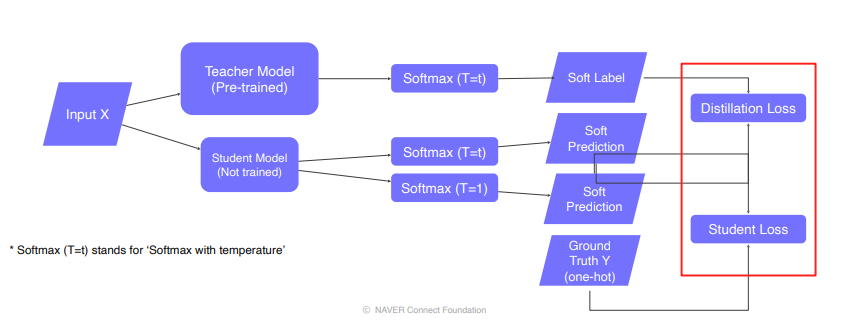
- labeled data가 있다면, 이를 Student Loss ( Ground Truth와의 Cross Entropy Loss (Hard Label) )로 활용할 수 있습니다.
- Distillation Loss는 teacher와 student모델 결과의 유사도 측정하는 KL-Divergence Loss (Soft Label)입니다.
- Semantic information은 distillation시 고려하지 않습니다.
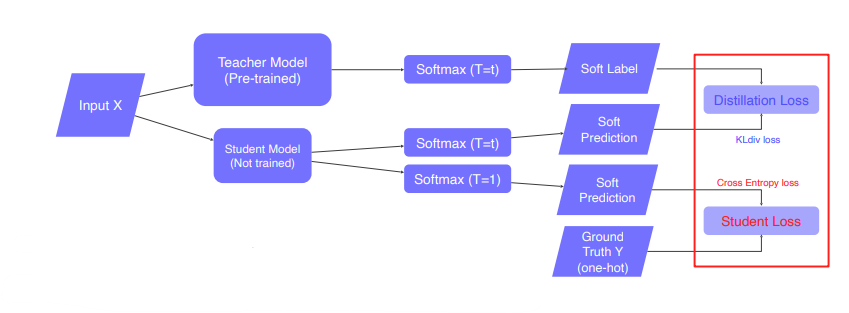
- Weighted sum of ”Distillation loss” and “Student loss”
- Softmax with temperature : hard prediction과 같은 극단적인 값보다는 중간 값들도 나오게 만들어 더 많은 정보를 가지게 함으로써 student가 teacher를 더 잘 모방하게 합니다.
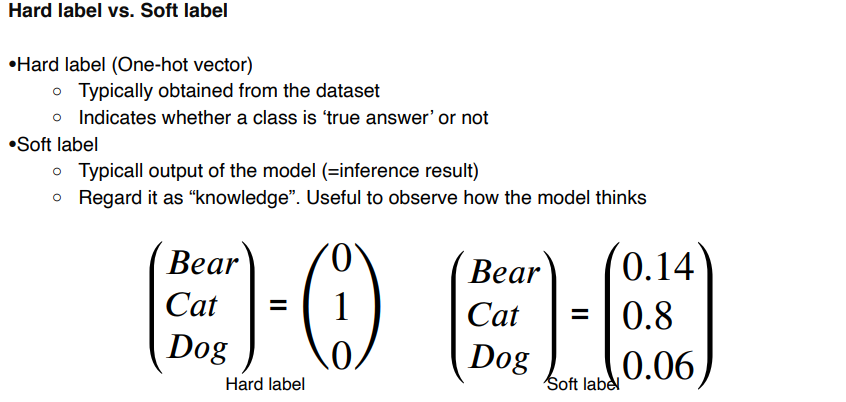

Semi-supervised learning
일반적으로 전체 데이터 중에서 일부 데이터만 라벨링이 되어있고, 대부분의 데이터는 unlabeled 데이터인 경우가 많습니다.
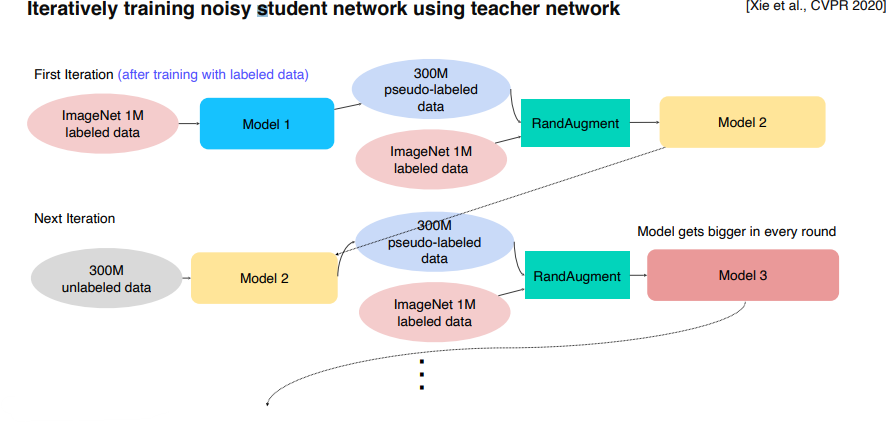
Semi-supervised learning(준-지도학습)은 말 그대로 Unsupervised (No label) + Fully Supervised (fully labeled) 입니다. 준지도학습은 아래 그림과 같이 학습을 이어나갑니다.
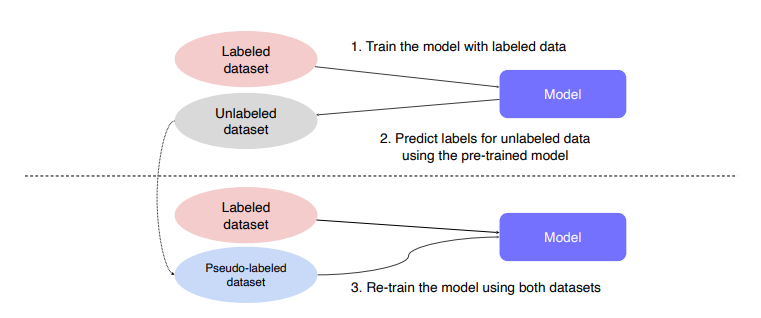
Self-training
Recap : Data efficient learning methods so far
Data Augmentation + Knowledge distillation + Semi-supervised learning (Pseudo label-based method)
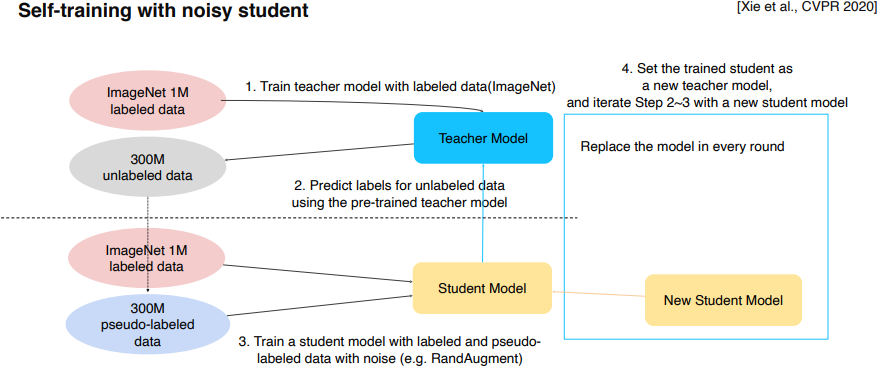
- 라벨이 있는 데이터로 teacher model 학습
- teacher model이 라벨 없는 데이터에 라벨 부여
- 라벨이 있는 데이터 + 라벨 부여 받은 데이터로 student model 학습 (Rand Augment 적용)
- student model을 teacher model로 만들고 student model은 조금 더 큰 모델로 다시 생성
- step 2~4 반복
이를 좀더 쉽게 시각화 하면 아래 그림과 같다.
Further Reading
- CutMix : https://arxiv.org/abs/1905.04899
(03강) Image Classification 2
Problems with deeper layers
신경망은 점점 깊어지고 넓어지고 있습니다. 깊은 신경망은 넓은 receptive fields 와 더 많은 용량 및 비선형성에 의해 더 많은 feature 들을 학습할 수 있습니다.
하지만 무조건 깊은 신경망이 항상 좋은 성능을 낼까요?
Hard to Optimize
신경망의 깊이가 깊어질수록 최적화 하기가 어려워 집니다. 왜냐하면 Gradient vanishing / exploding 때문입니다. 또한 깊은 신경망은 파라미터 수가 많아지기 때문에 계산 복잡도가 매우 올라갑니다.
CNN architectures for image classification 2
GoogLeNet
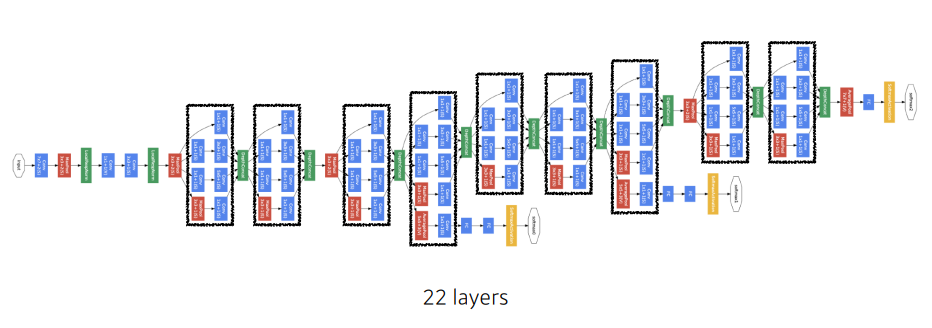
-
GoogLeNet의 핵심은 인셉션 모듈(inception module)
- 수용장의 다양한 특징을 추출하기 위해 NIN 의 구조를 확장하여 복수의 병렬적인 컨볼루션 층을 가집니다.
- [참고] NIN 구조
- 기존 컨볼루션 연산을 MLPConv 연산으로 대체
- 커널 대신 비선형 함수를 활성함수로 포함하는 MLP를 사용하여 특징 추출 유리함
- 신경망의 미소 신경망(micro neural network)가 주어진 수용장의 특징을 추상화 시도
- 전역 평균 풀링(global average pooling) 사용
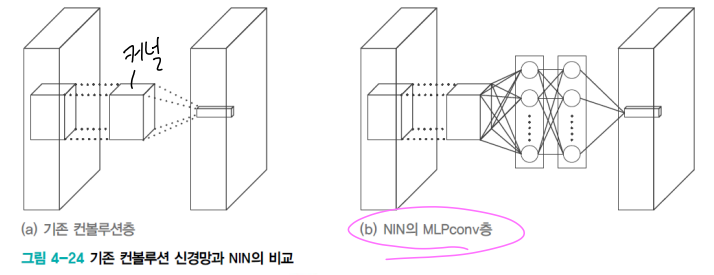
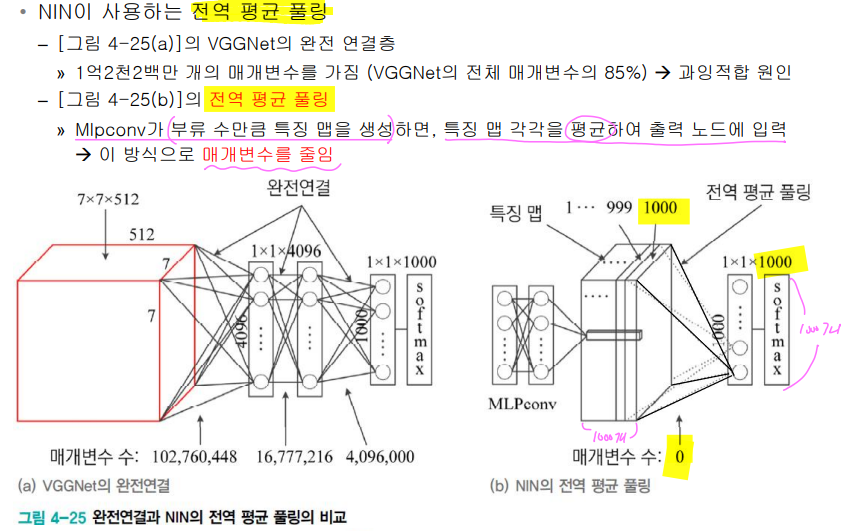
-
GoogLeNet은 NIN 개념을 확장한 신경망
- 인셉션 모듈
- 마이크로 네트워크로 Mlpconv 대신 네 종류의 컨볼루션 연산 사용 → 다양한 특징 추출
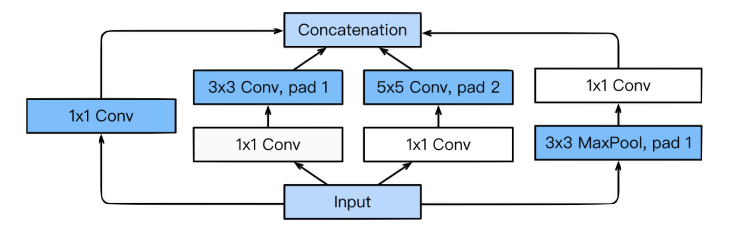
- 1x1 컨볼루션을 사용하여 차원 축소(dimension reduction)
- 매개변수의 수 (=특징 맵의 수)를 줄임 + 깊은 신경망
- 3x3, 5x5 같은 다양한 크기의 컨볼루션을 통해서 다양한 특징들을 추출
-
1x1 커널
- 차원 통합
- 차원 축소 효과
- c2>c3: 차원 축소 (연산량 감소)
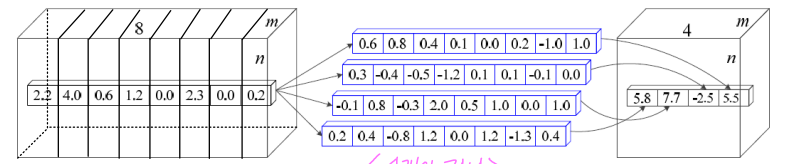
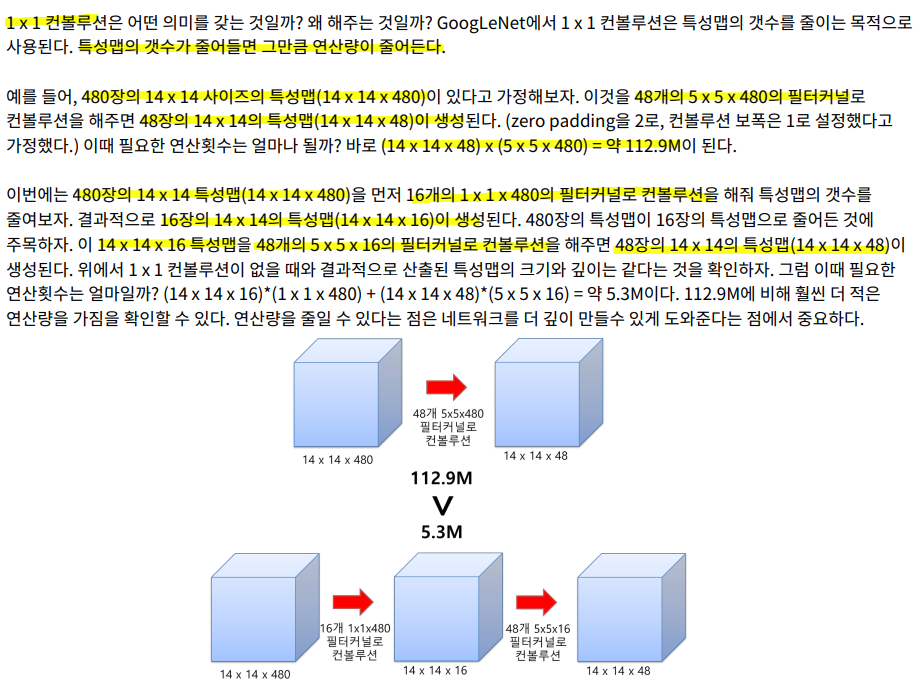
- 위 그림에서 mxn의 특징 맵 8개에 1x1 커널을 4개 적용 → mxn의 특징 맵 4개 출력
- 즉, 8xmxn 텐서에 8x1x1 커널을 4개 적용하여 4xmxn 텐서를 출력하는 셈
- [1x1 컨볼루션 참고]
-
Auxiliary classifiers
- 네트워크의 깊이가 깊어지면 깊어질수록 vanishing gradient 문제를 피하기 어려워진다. 가중치를 훈련하는 과정에 역전파(back propagation)를 주로 활용하는데, 역전파 과정에서 가중치를 업데이트하는데 사용되는 gradient가 점점 작아져서 0이 되어버리는 것입니다. 이 문제를 극복하기 위해서 GoogLeNet에서는 네트워크 중간에 두 개의 보조 분류기(auxiliary classifier)를 달아주었습다.
- auxiliary classifier는 inference 시에는 제거합니다.
ResNet
-
신경망의 깊이를 깊게 하면 무조건 성능이 좋아질까??
-
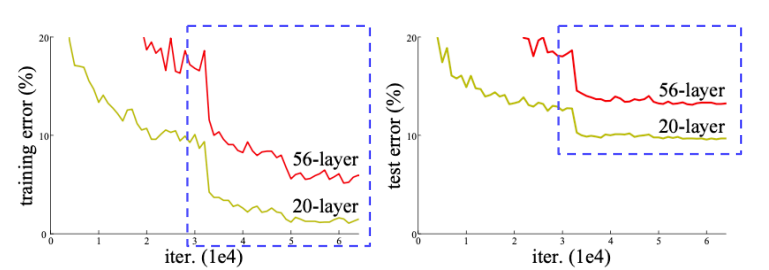
-
위 그래프를 보면 오히려 56층의 신경망 구조가 20층의 신경망보다 더 나쁜 성능을 보입니다. 즉, 기존의 방식으로는 무조건적으로 깊은 신경망이 성능이 좋게 나오지 않는다는 것을 확인한 것입니다.
-
-
Residual Block
- 아래 그림에서 오른쪽이 Residual Block입니다. 기존의 망과 차이가 있다면 입력값을 출력값에 더해줄 수 있는 지름길(shortcut)이 하나 있는 것 뿐입니다.
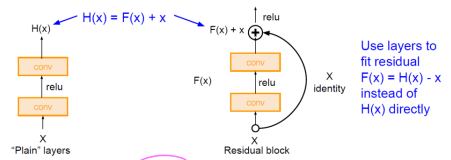
-
기존의 신경망은 입력값 x를 타겟값 y로 매핑하는 함수 H(x)를 얻는 것이 목적이었습니다. 그러나 ResNet은 F(x) + x 를 최소화하는 것을 목적으로 합니다. x는 현시점에서 변할 수 없는 값이므로, 이는 F(x)를 0에 가깝게 만드는 것이 목적 이 됩니다. F(x)가 0이 되면 출력과 입력이 모두 x로 같아지게 됩니다. F(x) = H(x) - x이므로 F(x)를 최소로 해준다는 것은 H(x) - x를 최소로 해주는 것과 같은데, 여기서 H(x) - x를 잔차(residual)라고 합니다.
-
지름길 연결(short cut)을 두는 이유는?
- 깊은 신경망도 최적화가 가능해짐
- 단순한 학습의 관점의 변화를 통한 신경망 구조 변화
- 단순 구조의 변경으로 매개변수 수에 영향이 없음
- 덧셈 연산만 증가하므로 전체 연산량 증가도 미비함
- 깊어진 신경망으로 인해 정확도 개선 가능함
- 경사 소멸 문제 해결
- dentity X를 전달하여 역전파시 gradient를 적어도 1은 보장하고(X의 미분값 = 1), 이렇게해서 vanishing gradient로 인한 degradation problem을 해결합니다.
- 깊은 신경망도 최적화가 가능해짐
-
3x3 커널 사용
-
잔류 학습 사용
-
전역 평균 풀링 사용 (FC 층 제거)
-
배치 정규화(batch normalization) 적용 (드롭아웃 적용 불필요)
-
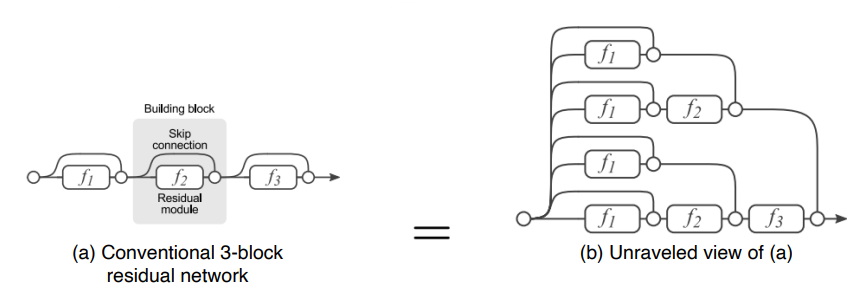
- 2^n 개의 gradient가 지나갈수 있는 input-output path가 생성. residual block이 하나 추가될때마다 경로는 2배가 됩니다. 이를 통해 굉장히 복잡한 mapping을 학습할 수 있다.
-
Overall architecture
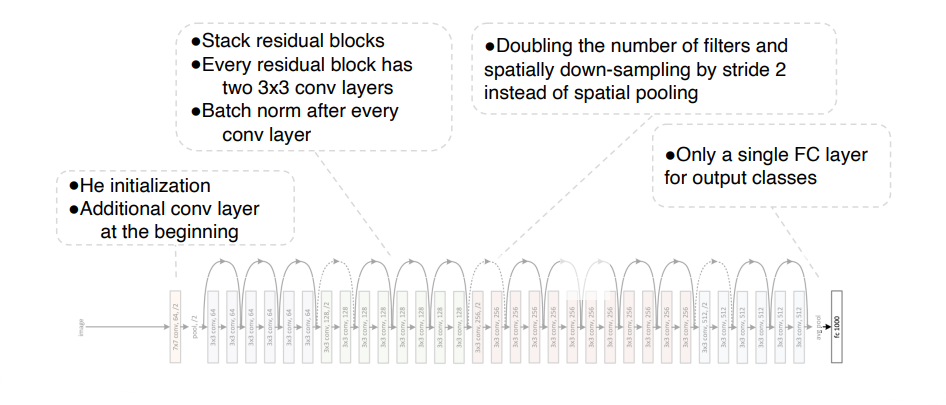
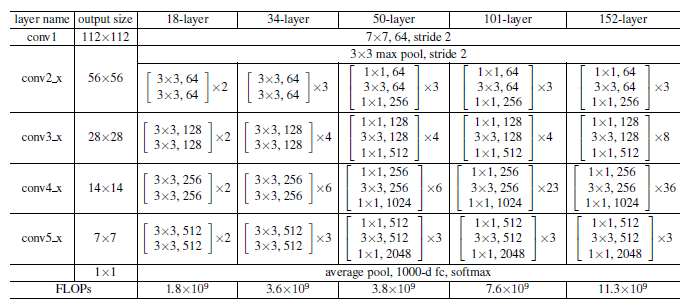
DenseNet
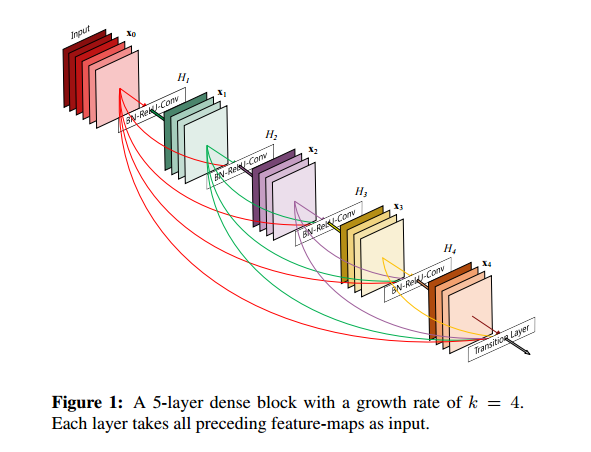
ResNet에서는 레이어의 입력과 출력을 요소별로 추가했습니다.
Dense 블록에서는 각 레이어의 모든 출력은 채널 축을 따라 concat 합니다.
- 기울기 소실 문제 해결
- 파라미터 수가 적음
SENet
Further Reading
