(04강) Semantic Segmentation
What is semantic segmentation?
Semantic Segmentation의 목적은 사진에 있는 모든 픽셀을 해당하는 (미리 지정된 개수의) class로 분류하는 것입니다. 여기서 주의해야하는 점은 semantic image segmentation 은 같은 class의 instance 를 구별하지 않는다는 것입니다.

위 그림을 보시면 Semantic Segmentation은 오른쪽처럼 픽셀 단위로 어떤 class인지만 구분하지만, Instance Segmentation은 왼쪽처럼 픽셀 단위로 어떤 class인지 구분한 이후, 동일한 class 내에서도 다른 Instance를 구분합니다.
Fully Convolutional Networks (FCN)
FCN은 Semantic Segmentation의 대표적인 모델 중 하나입니다. FCN은 Semantic Segmentation을 위한 최초의 end-to-end 아키텍처이며, 임의의 크기의 이미지를 입력으로 받아 해당 크기의 segmentation map을 출력합니다.
Fully connected vs Fully convolutional
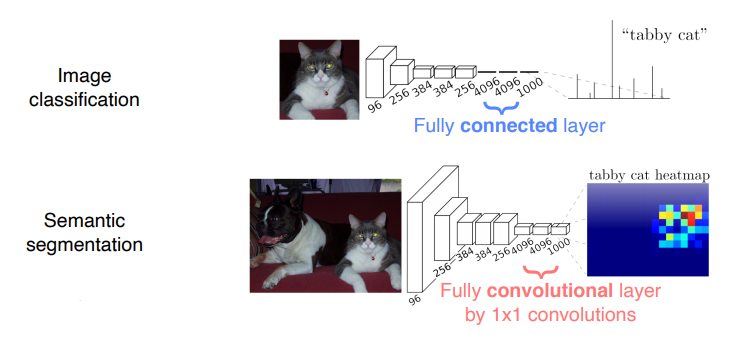
- Fully connected layer : 고정된 차원의 벡터를 출력하고, spatial coordinates를 버림
- Fully convoluytional layer : sparial coordinates를 가지고 있는 classification map을 출력
즉, Fully connected layer은 항상 입력이미지를 네트워크에 맞는 고정된 사이즈로 입혁해줘야 합니다. 또한, 공간정보를 잃게 되는 큰 단점이 있습니다.
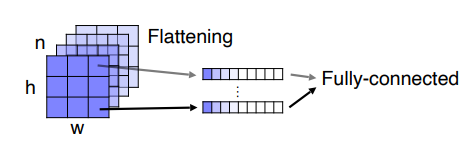
위의 그림처럼 Fully connected layer은 하나의 벡터로 flattening해서 영상의 공간정보를 활용하지 못합니다.
이러한 문제를 해결하기 위해, FCN 모델은 아래 그림처럼 fully connected 층을 1x1 convolution 층으로 바꿨습니다. 이를 통해 더 이상 입력 이미지 크기에 제한을 받지 않게 되었으며, 입력이미지의 공간정보를 대략적으로 유지할 수 있게 되었습니다. 여기서 중요한 것은, 이 convolution 층들을 거치고 나서 얻게 된 마지막 특성맵의 개수는 훈련된 클래스의 갯수와 동일하다는 것입니다. 5개의 클래스로 훈련된 네트워크라면, 5개의 특성맵(heatmap)을 산출해내며, 각 특성맵은 하나의 클래스를 대표합니다. 만약, 고양이 클래스에 대한 특성맵이라면 고양이가 있는 위치의 픽셀값들이 높고, 강아지 클래스에 대한 특성맵이라면 강아지 위치의 픽셀값들이 높게됩니다.
하지만 단점이 존재하는데, 바로 예측한 특성맵의 해상도가 저해상도라는 것입니다. 해상도가 작으면 입력의 공간정보를 "대략적으로만" 가지게 됩니다. 이렇게 저해상도가 되는 이유는 큰 RF를 얻기위해 여러개의 pooling layer가 적용되기 때문에 발생합니다. 그러면 stride와 pooling을 없애면 되지 않을까? 라는 생각을 할 수도 있지만, 이는 RF를 작게 하기 때문에 또 문제가 됩니다.(Trade-off 관계) 이러한 단점을 Upsampling 을 사용하여 해결할 수 있습니다.
What is Upsampling?
우선 FCN의 Architecture는 아래와 같이 크게 4단계로 나뉩니다.
.png)
- Convolution Layer를 통해 Feature 추출
- 1 x 1 Convolution Layer를 통해, 낮은 해상도의 Class Presence Heat Map 추출
- Transposed Convolution 을 통해서, 이 낮은 해상도의 Heat Map을 Upsampling 한 뒤, 인풋과 같은 크기의 Map 생성
- Map의 각 pixel class에 따라 색칠 한 뒤, Segmentation 결과 반환
1,2번 과정은 downsampling 단계로, convolution을 통해 차원을 줄이는 단계입니다.
3번 과정은 upsampling 단계로, 1,2번 과정을 통해 만들어진 특성맵(heatmap)의 크기를 원래 이미지의 크기로 다시 복원해주는 단계입니다. 이미지의 모든 픽셀에 대해서 클래스를 예측하는 것이, semantic segmentation의 목적이기 때문입니다.
Upsampling에는 크게 2가지 방법이 있습니다. Transposed convolution과 Upsampling + Convolution 입니다.
-
Interpolation
-
Nearest neighbor interpolation, bilinear interpolation, bicubic interpolation
-
위 interpolation 방법들은 기존 픽셀값들 만으로 해상도를 늘리는 방법들이므로 새로운 파라미터를 학습할 것이 없습니다. 즉, 학습과 무관한 연산입니다.
-
-
Transposed Convolution
-
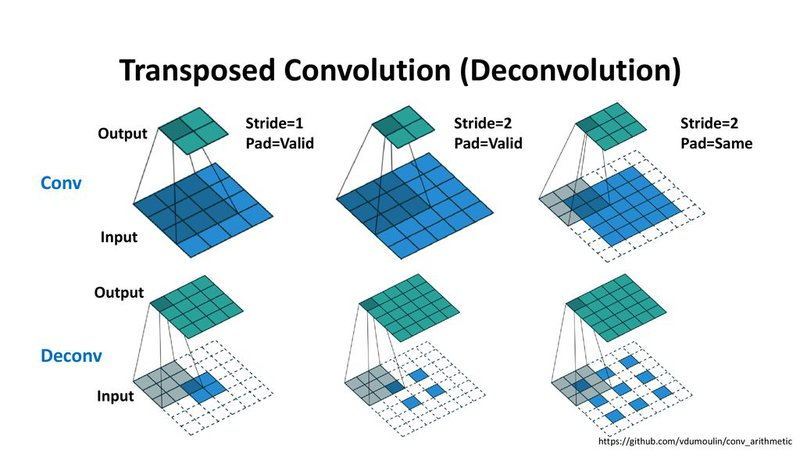
-
만약 딥러닝 네트워크가 네트워크 목적에 맞도록 최적화하여 Upsampling을 하도록 하려면 Transposed Convolution을 사용할 수 있습니다. 이 방법은 앞에서 설명한 interpolation과 다르게 학습할 수 있는 파라미터가 있는 방법입니다.
-
기존 Convolution 연산은 다대일(many-to-one) 관계를 가진다면, Transposed Convolution은 일대다(one-to-many) 관계를 가진다.
-
연산의 방식은 JINSOL KIM 님의 github 블로그를 참고하시면 되겠습니다.
-
문제점
-
checkboard artifact
-

-
위 그림을 보면 출력의 형태가 체크보드와 같은 인공물 처럼 나오는 것을 확인할 수 있습니다.
-
Transposed Convolution 또한 Convolution 연산이므로 커널이 슬라이딩 윈도우 방식으로 이동하면서 연산이 진행됩니다. 특히, kernel의 크기와 stride의 크기에 따라서 transposed convolution 연산의 overlap 영역이 발생할 수 있습니다. 이 때 Transposed Convolution을 어떻게 사용하느냐에 따라서 overlap이 없을 수도 있고 또는 많이 생길 수도 있습니다.
-
interpolation을 이용한 Upsampling + Convolution 조합으로 문제를 개선할 수 있습니다. Transposed Convolution은 interpolation과 convolution 연산을 한번에 하는 역할을 하지만 interpolation + convolution에서는 bilinear, bicubic, nearest-neight 등의 방법을 이용하여 먼저 interpolation을 하고 그 뒤에 convolution 연산을 추가하는 방식입니다. 즉, interpolation 역할과 convolution 역할을 분리하는 것입니다.
-
-
특성맵(heatmap)의 크기를 원래 이미지의 크기로 다시 복원해주는 Upsampling을 알아보았는데, 단순히 upsampling만 시행하면 특성맵의 크기는 한 번에 원래 이미지의 크기로 복원되고, 그것들로부터 원래 이미지 크기의 segmentation map을 얻을 수 있지만, 디테일하지 못한 segmentation map을 얻게 됩니다.
이런 점을 보완하기 위해 Deep & Coarse(추상적인) 레이어의 의미적(Semantic) 정보와 Shallow & fine 층의 외관적(appearance) 정보를 결합한 skip connection 기법이 개발되었습니다.
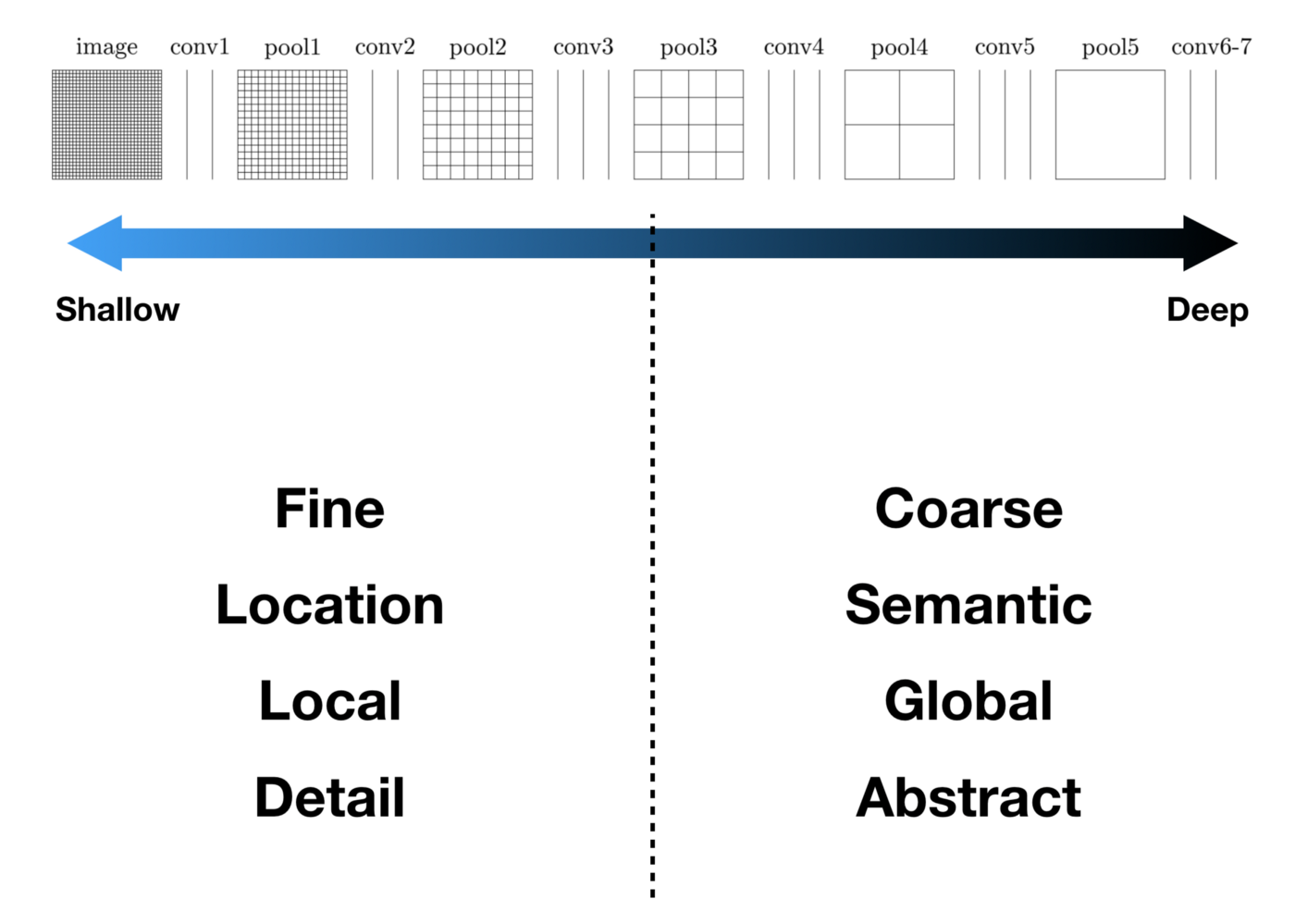
기본적인 생각은 다음과 같습니다. 컨볼루션과 풀링 단계로 이루어진 이전 단계의 컨볼루션층들의 특성맵을 참고하여 upsampling을 해주면, 좀 더 정확도를 높일 수 있지 않을까?
왜냐하면, 이전 컨볼루션층들의 특성맵들이 해상도 면에서는 더 낫기 때문입니다.
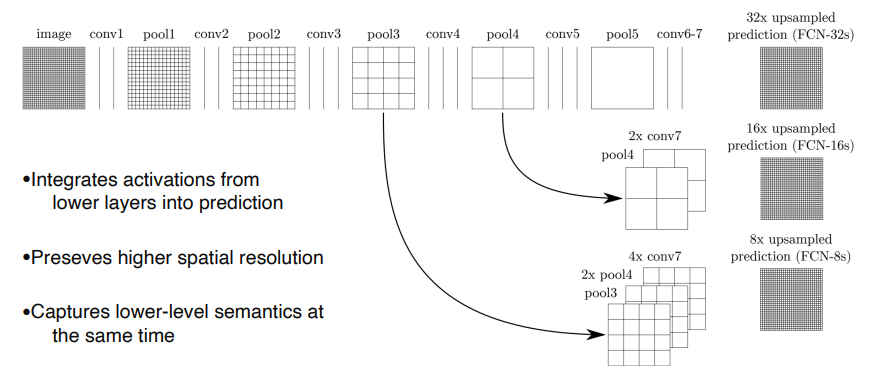
따라서, 위 그림과 같이 바로 전 컨볼루션층의 특성맵(pool4)과 현재 층의 특성맵(conv7)을 2배 upsampling한 것을 더한 (pool4 + 2x conv7)을 16배 upsampling 해 얻은 특성맵들로 segmentation map을 얻는 방법을 FCN-16s라고 부릅니다.
더 나아가서, 전전 단계의 특성맵(pool3)과, 전 단계의 특성맵(pool4)을 2배 upsampling한 것과, 현 단계의 특성맵(conv7)을 4배 upsampling 한 것을 모두 더한 다음에, (pool3 + 2xpool4 + 4xcon7)을 8배 upsampling을 해 얻은 특성맵들로 segmentation map을 얻는 방법을 FCN-8s라고 부릅니다.

위 그림을 보면 FCN-8s가 FCN-16s보다 좀 더 세밀하고, FCN-32s보다는 훨씬 더 정교해졌음을 알 수 있습니다.
U-Net
-
기존 Segmentation 모델의 단점이었던 느린 연산 속도를 개선
-
이미지를 인식하는 단위(Patch)에 대한 Overlap 비율이 적기 때문
-
U-Net의 경우, 이전 Patch에서 검증이 끝난 부분을 다음 Patch에서 중복하여 검증하지 않기 때문에, 연산의 낭비가 없고 이로 인해 향상된 속도를 얻을 수 있습니다.
-
-
Segmentation Network는 클래스 분류를 위한 인접 문맥 파악(Context)과 객체의 위치 판단(Localization)을 동시에 수행해야 합니다. 각 성능은 Patch의 크기에 영향을 받는데, 이때 Trade-Off 관계를 가지게 됩니다.(위에서 설명했듯이) Patch의 크기가 커지면 더 넓은 범위의 이미지를 한 번에 인식할 수 있어 Context 파악에는 탁월한 효과를 보이지만, 많은 Max-Pooling을 거치며 Localization 성능에는 부정적인 영향을 미치게 됩니다.
- U-Net은 다층의 Layer의 Output을 동시에 검증해서 이러한 Trade-Off를 극복
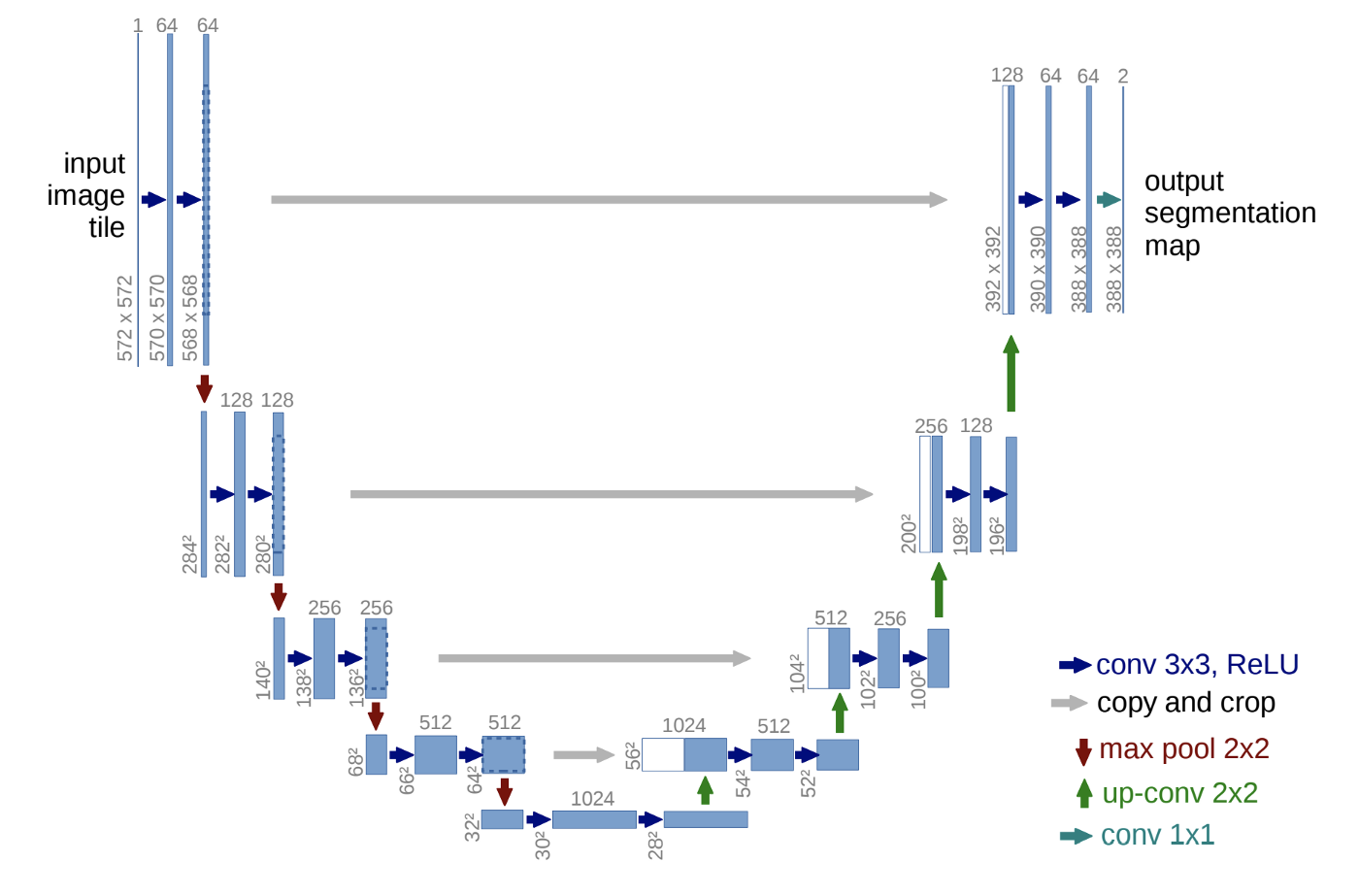
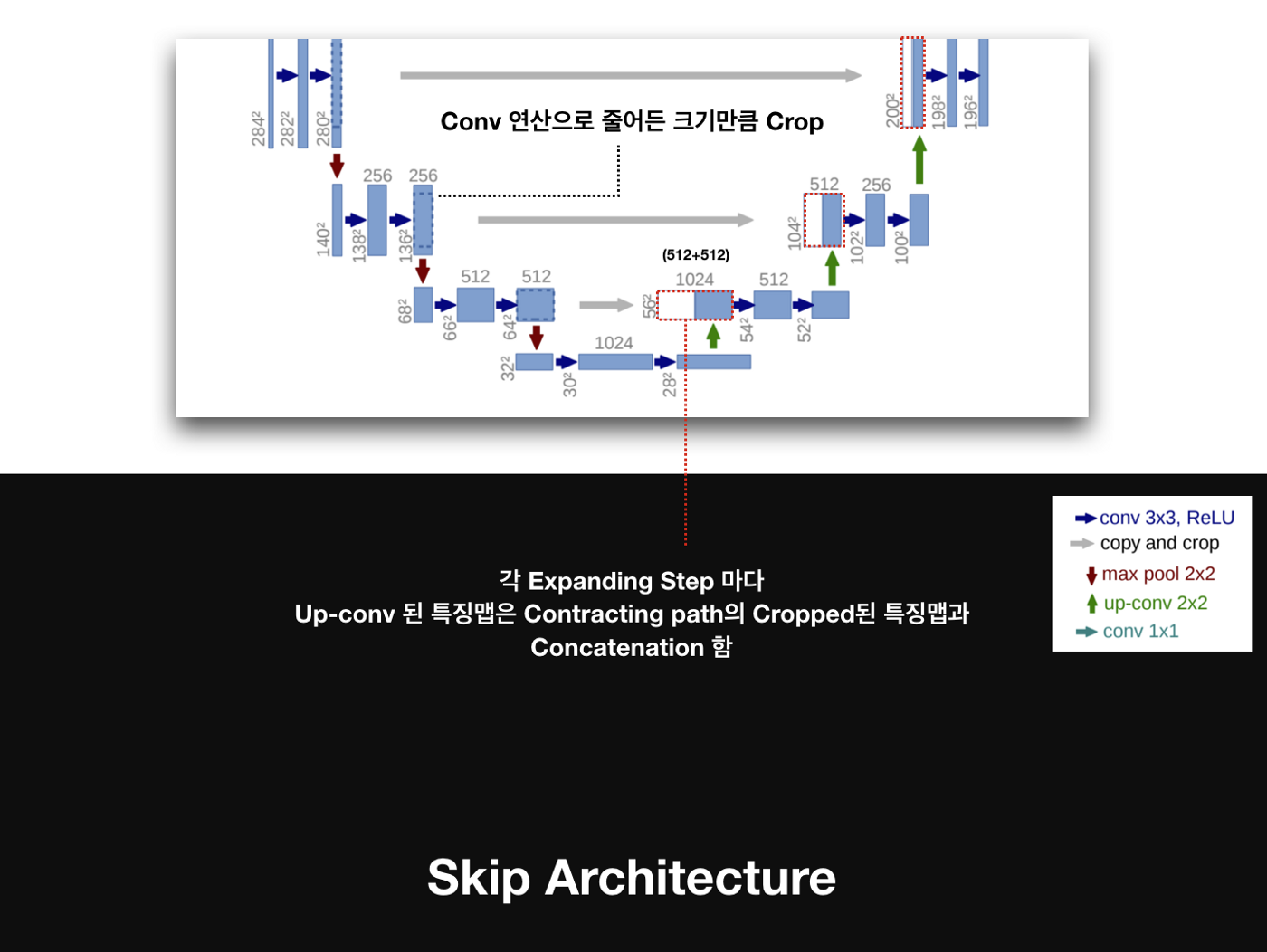
자세한 U-Net의 구조
-
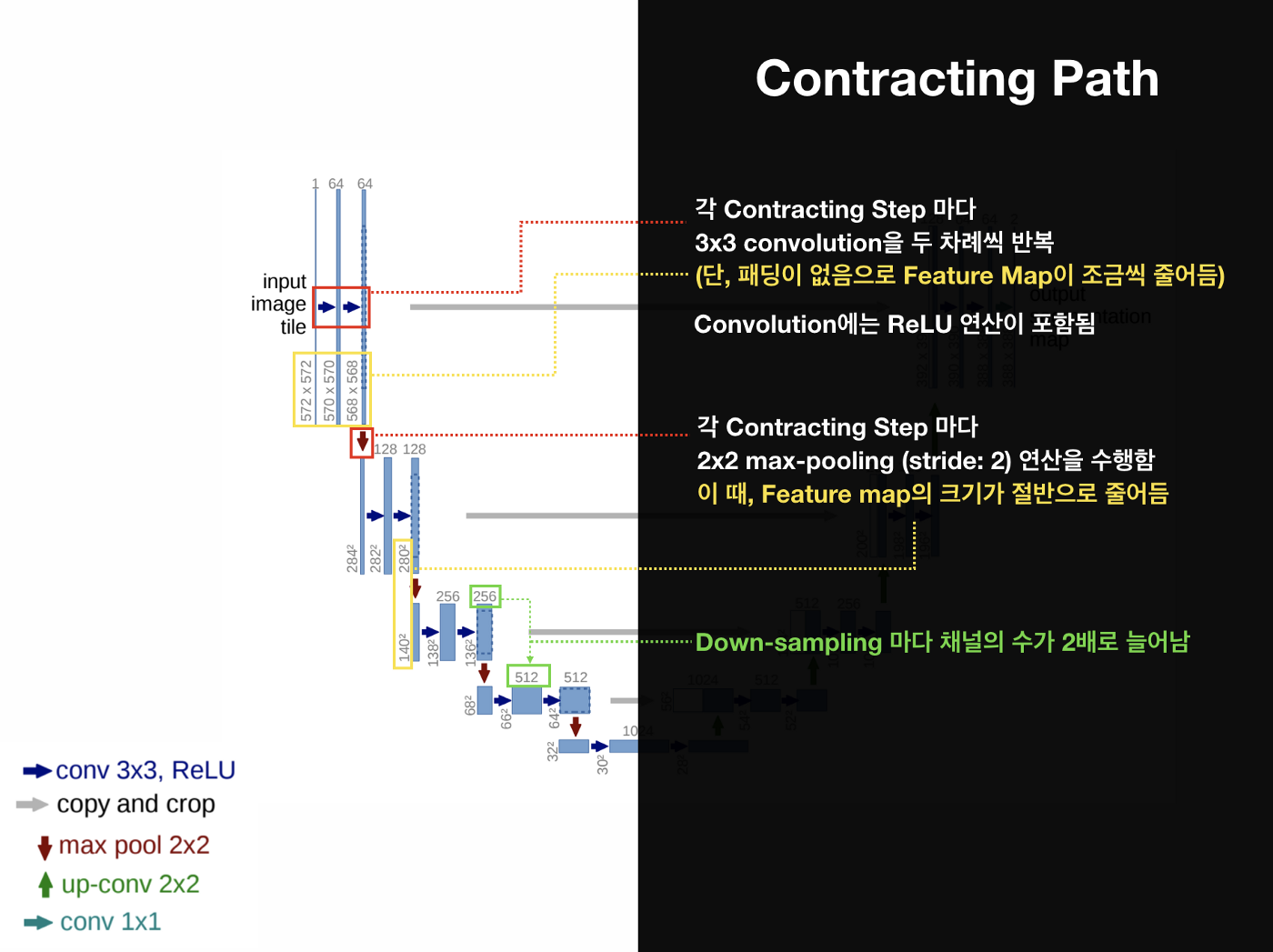
Contracting Path
-
Contracting Path는 Encoder의 역할을 수행하는 부분으로 전형적인 Convolution Network로 구성
-
Contracting Path는 입력을 Feature Map으로 변형해 이미지의 Context를 파악
-
3x3 convolutions을 두 차례씩 반복 (패딩 없음)
-
활성화 함수는 ReLU
-
2x2 max-pooling (stride: 2)
-
Down-sampling 마다 채널의 수를 2배로 늘림
-
-
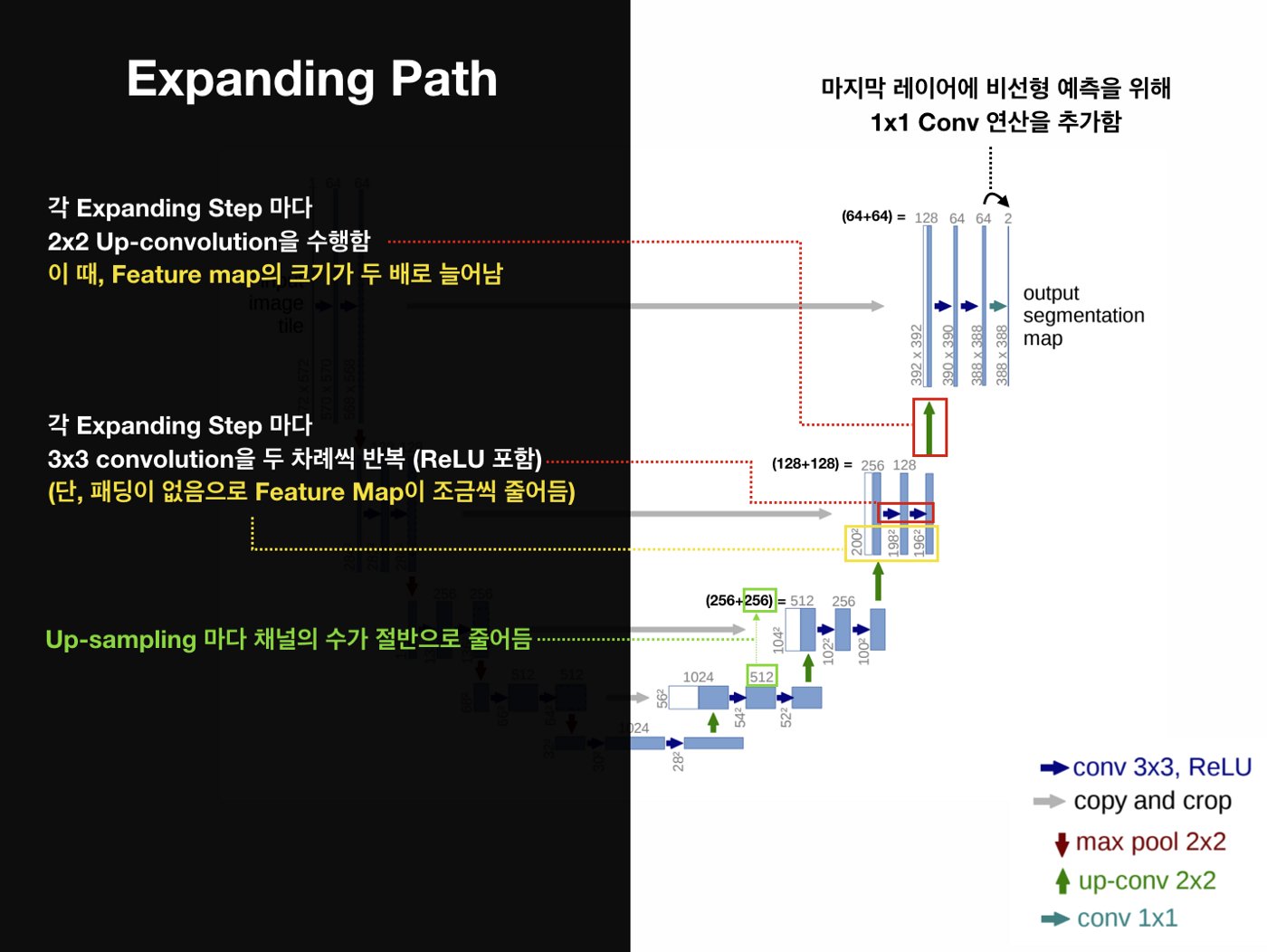
Expanding Path
-
Expanding Path는 Decoder의 역할을 수행하는 부분으로, 전형적인 Upsampling + Convolution Network로 구성
-
Expanding Path에서는 Contracting을 통해 얻은 Feature Map을 Upsampling하고,
각 Expanding 단계에 대응되는 Contracting 단계에서의 Feature Map과 결합해서(Skip-Connection Concatenate) 더 정확한 Localization을 수행 -
2x2 convolution (“up-convolution”)
-
3x3 convolutions을 두 차례씩 반복 (패딩 없음)
-
Up-Conv를 통한 Up-sampling 마다 채널의 수를 반으로 줄임
-
활성화 함수는 ReLU
-
Up-Conv 된 특징맵은 Contracting path의 테두리가 Cropped된 특징맵과 concatenation 함
-
마지막 레이어에 1x1 convolution 연산
-
DeepLab
DeepLab 이라 불리는 semantic segmentation 방법은, version 1부터 시작하여 지금까지 총 4번의 개정본(1, 2, 3, 3+)이 출판되었습니다.
전체적으로 DeepLab은 semantic segmentaion을 잘 해결하기 위한 방법으로 atrous convolution을 적극적으로 활용할 것을 제안하고 있습니다.
V1에서는 atrous convolution을 적용해 보았고,
V2에서는 multi-scale context를 적용하기 위한 Atrous Spatial Pyramid Pooling (ASPP) 기법을 제안하고,
V3에서는 기존 ResNet 구조에 atrous convolution을 활용해 좀 더 dense한 feature map을 얻는 방법을 제안하였습니다.
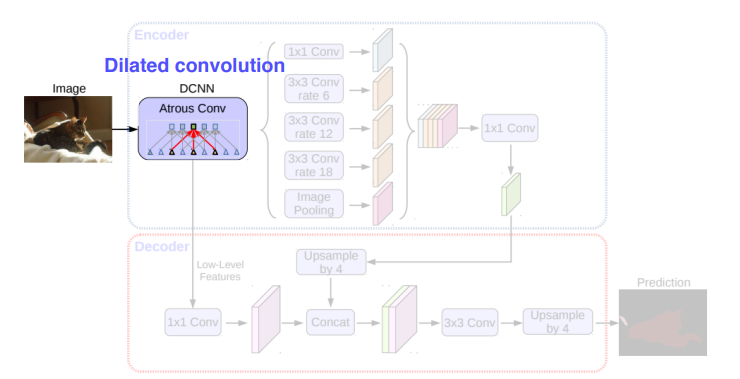
그리고 최근 발표된 V3+에서는 separable convolution과 atrous convolution을 결합한 atrous separable convolution의 활용을 제안하고 있습니다.
-
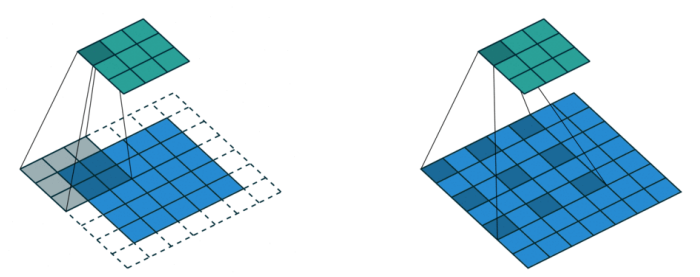
Dilated convolution
-
Atrous convolution이라고도 불림
-
-
Dilated convolution은 기존 convolution과는 다르게, 필터 내부에 빈 공간을 둔 채로 작동
-
기존 convolution과 동일한 양의 파라미터와 계산량을 유지하면서도, field of view (한 픽셀이 볼 수 있는 영역) 를 크게 가져갈 수 있게 됩니다.
-
보통 semantic segmentation에서 높은 성능을 내기 위해서는, convolutional neural network의 마지막에 존재하는 한 픽셀이 입력값에서 어느 크기의 영역을 커버할 수 있는지를 결정하는 receptive field 크기가 중요하게 작용합니다. Dilated convolution을 활용하면 파라미터 수를 늘리지 않으면서도 receptive field를 크게 키울 수 있습니다.
-
-
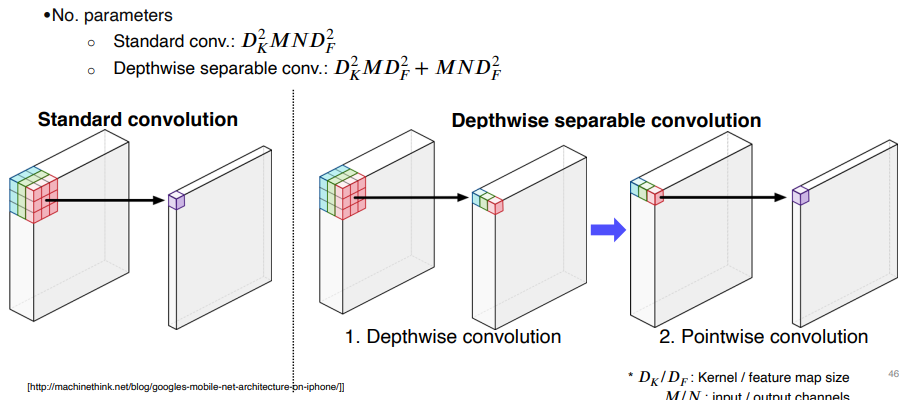
Depthwise Separable Convolution
-
-
Convolution 연산에서 channel 축을 filter가 한 번에 연산하는 대신에, 입력 영상의 channel 축을 모두 분리시킨 뒤, filter의 channel 축 길이를 항상 1로 가지는 여러 개의 convolution filter로 대체시킨 연산을 depthwise convolution이라고 합니다.
-
그리고 depthwise convolution으로 나온 결과에 대해, 1×1×C 크기의 convolution filter를 적용한 것을 depthwise separable convolution 이라 합니다.
-
이처럼 복잡한 연산을 수행하는 이유는 기존 convolution과 유사한 성능을 보이면서도 사용되는 파라미터 수와 연산량을 획기적으로 줄일 수 있기 때문입니다.
- 위 그림의 식을 보면, Standard convolution은 지수가 6이지만 Depthwise separable convolution은 최대 지수가 5입니다.
-
-
DeepLab V3+
-
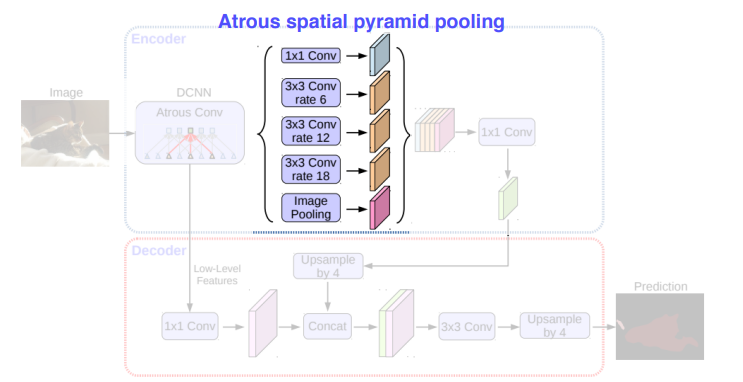
.png)
Further Reading
- Checkerboard artifacts: https://distill.pub/2016/deconv-checkerboard/
- FCN: https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
- UNet: https://arxiv.org/pdf/1505.04597.pdf
참고
- https://wooono.tistory.com/267
- https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sogangori&logNo=220952339643
(05강) Object Detection
Object detection
.png)
위 그림을 보시면 Instance segmentation, Panoptic segmentation은 똑같은 class라도 각각 개체마다 다르게 분류할 수 있기 때문에 훨씬 유용한 정보제공이 가능합니다.
이러한 각 객체를 구분하는 기술이 object detection 입니다.
object detection은 Semantic segmentation 보다 더 구체적이고 전반적인 이해를 위해 필요한 근본적 기술입니다.
.png)
Object detection은 Classification과 Box localization을 동시에 하는 Task입니다.
그렇다면 Object detection은 주로 어디에 활용될까요?
.png)
자율주행, OCR 등 다양한 분야에 쓰이고 있고, 그만큼 산업적 가치가 높습니다.
Two-stage detector
Traditional methods - hand-crafted techniques
과거에는 어떤 방식으로 Object detection을 수행했을까?
-
Gradient-based detector (e.g., HOG = Histogram of Oriented Gradients)
-
사람 경계선의 평균들을 내서 이미지를 만들었더니 1번 사진처럼 실루엣이 잘 묻어 나오는 것을 확인할 수 있습니다. 그래서 경계선의 특징을 잘 알기 위한 엔지니어링을 수행합니다. (SVM 사용)
-
.png)
-
영상의 경계선(Gradient)을 기준으로 물체를 찾기 위한 방법
-
HOG: 구역마다 edge의 분포를 모델링
-
Selective search
.png)
-
다양한 물체 후보군에 대해서 영역을 특정해서 제한해줌 → Bounding Box를 제한 (Box proposal)
-
시행 알고리즘
-
영상을 비슷한 색끼리 잘게 분할함 (Oversampling)
-
잘게 분할된 영역들을 비슷한 영역끼리 합쳐준다. → 비슷함의 기준을 색인지, 그레디언트의 분포인지를 정의해줘야 함
-
각자 큰 Segmentation을 포함하는 bounding-box를 tight 하게 추출해서 물체의 후보군으로 사용
-
R-CNN
AlexNet이 image classification에서 큰 성능을 거둔 후 바로 object detection에 응용된 기술입니다.
AlexNet과 마찬가지로 기존의 방법들에 비해 압도적으로 높은 성능을 보여줬습니다.
.png)
-
Selective search를 이용하여 2천 개 이하의 region proposal(anfcprk dlTdmfaksgks duddur)을 구해줌
-
각 Region을 image classification NN의 input size에 맞게 warpping을 해줌 (Ex. Alex - 224x224)
-
AlexNet의 중간 특징값에 SVM (Support vector machine)을 적용하여 각각의 region proposal의 클래스를 구분
-
단점
-
계산의 비효율성 : 각각 region마다 CNN에 넣어야하기 때문에 속도가 굉장히 느림
-
End-to-end로 트레이닝이 불가 : Region proposal을 뽑는 부분을 뉴럴넷이 아닌 고전적인 Selective search 알고리즘을 사용하기 때문에 AlexNet 부분만 뉴럴넷으로 구현
-
Fast R-CNN
R-CNN의 단점을 개선하고자 기존 저자들이 제시한 방법으로서, 영상 전체에 대한 feature를 한번에 추출하고 이를 재활용해 여러 object를 detect하게 해줍니다.
.png)
- CNN에서 convolution layer까지 feature map을 미리 뽑아둡니다. 이렇게 conv layer만 거친 feature map은 tensor 형태를 가지고 있습니다.
.png)
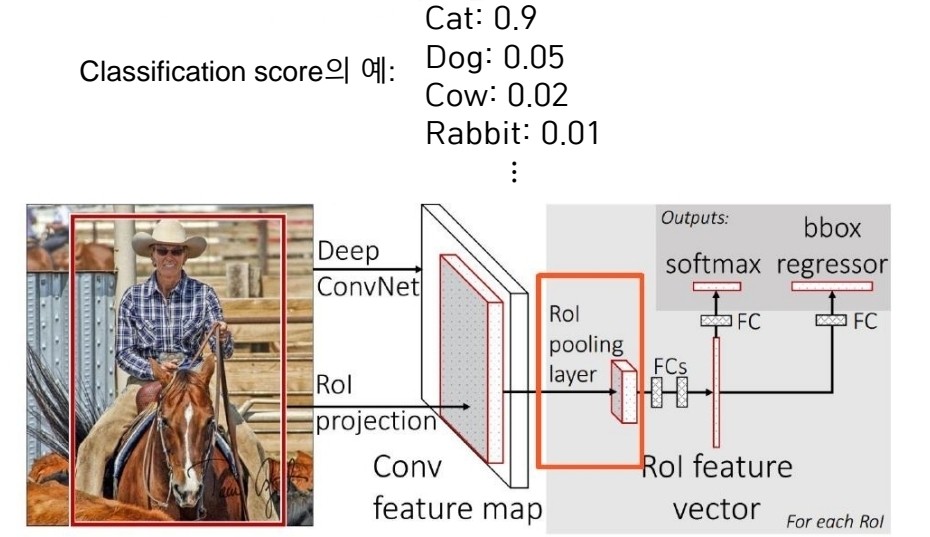
- RoI pooling을 사용해 region proposal의 영역에 해당하는 특징값을 가져옵니다. 추출된 feature은 일정한 size를 가지도록 resampling 됩니다.
RoI (Region of interest pooling)
- CNN 특징지도에서 region proposal의 영역에 해당하는 특징값을 가져옴
- Region proposal에 해당하는 바운딩박스를 특징지도에 투영 (RoI)
- 투영된 박스 안의 영역을 정해진 크리 HxW로 분할
- 분할된 영역의 특징값에 Max pooling을 적용하여 HxW의 정해진 사이즈의 특징값을 만들어냄
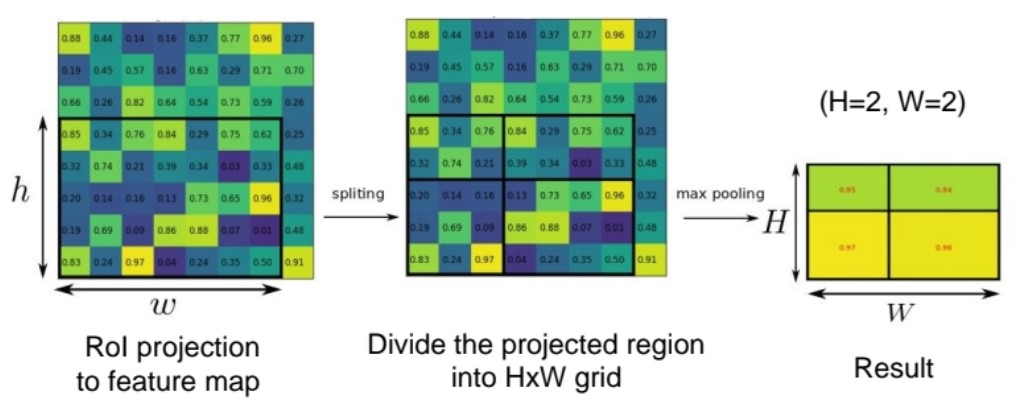
.png)
- 더 정확한 bbox를 위하여 bbox regressor을 취해주고 classifier를 취해줍니다.
이렇게 Fast R-CNN은 이렇게 Feature만 재활용했는데 기존에 비해 18배가 빨라졌습니다. 하지만 Region Proposal이 Selective search를 통해 이루어지기 때문에 학습을 통한 성능 향상이 어려운 것은 여전히 문제로 남았습니다.
Faster R-CNN
Object Detection에서 최초의 모든 네트워크가 NN 기반인 End-to-End 모델입니다.
모델을 알기에 앞서 기본 개념을 알아보겠습니다.
-
IOU
-
.png)
-
두 영역의 overlap을 측정하는 기준. 이 수치가 높을수록 두 영역이 잘 결합했다고 판단
-
-
NMS
-
Non-maximum suppression
-
.png)
-
기존방법 문제점 : 하나의 물체에 대해서 얻은 검출 결과가 많이 중복되는 현상
-
NMS 방법을 사용하여 RPN과 RefineNet의 결과에 대해 각각 중복되는 박스들을 가장 스코어가 큰 검출 결과로 병합
-
-
Faster R-CNN
-
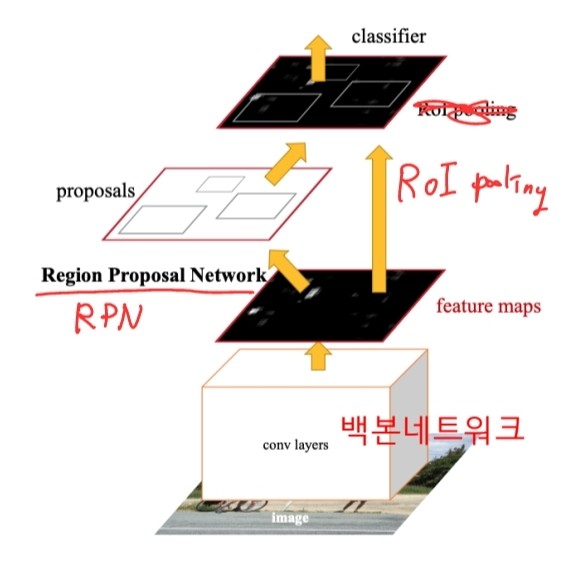
-
CNN 백본 네트워크는 전체 영상에 대해서 한 번만 적용 -> 이 후 물체 검출을 위해 백본 네트워크의 출력 특징지도를 재사용
-
Region proposals을 찾아내는 부분을 뉴럴넷으로 구현 -> 2단계의 검출 네트워크를 한번에 end to end로 학습
-
검출단계
-
Conv layers 백본 네트워크 : 전체 카메라 영상으로 부터 특징지도 추출
-
RPN : Region proposals (물체 위치)을 찾는 역할, 기존의 Selective search 방법을 대체
-
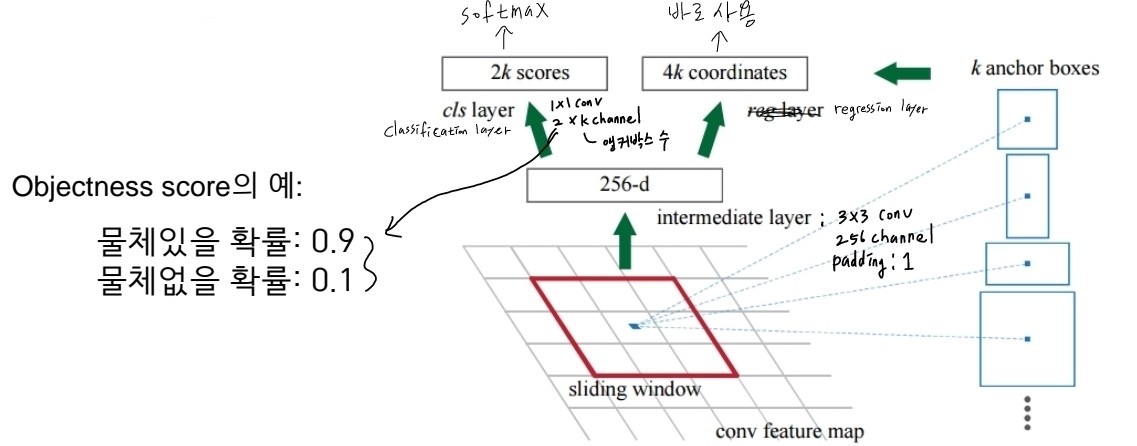
-
백본네트워크에서 출력된 CNN의 특징지도의 각 픽셀에 대해 3x3 커널을 적용
-
3x3 커널 적용 후 Objectness score 2개, 바운딩 박스의 좌표값 4개(x축 중심, y축 중심, 높이, 너비)를 출력
-
바운딩 박스의 좌표값은 어떻게 추정하나? 답) 앵커박스를 기준으로 변화량을 추정
-
앵커박스가 필요한 이유 : 절대적인 값을 추정하는 것 보다 앵커박스를 기준으로 상대적인 변화량을 추정하는 것이 더 쉬움
-
다양한 크기의 물체를 검출하기 위해 다른 크기와 aspect ratio를 갖는 하나 이상의 앵커박스를 사용
-
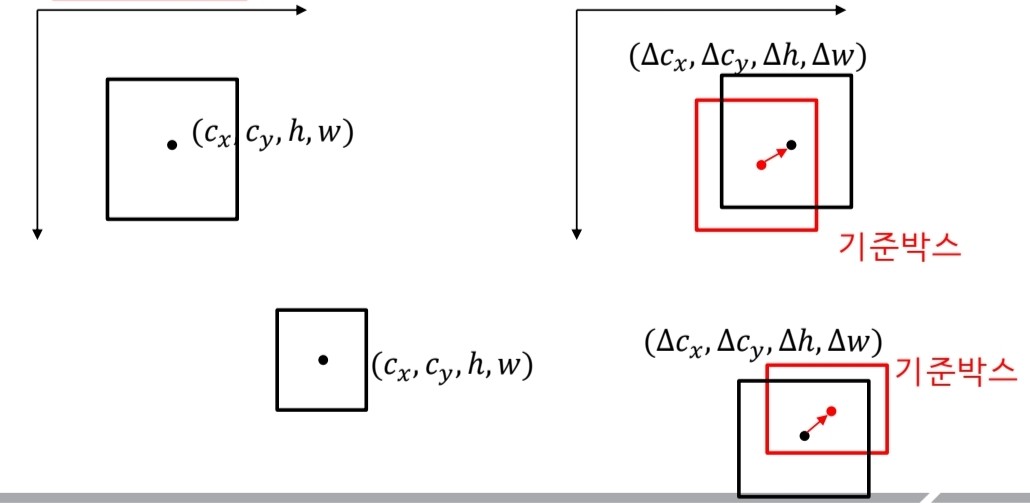
-
-
RoI pooling : Region proposal에 해당하는 영역을 CNN 특징지도로부터 Crop해 옴
-
RefineNet : RoI pooling으로부터 얻은 특징값을 다시 Refine하여 물체의 종류와 정밀한 박스위치를 알아냄
-
RoI pooling 계층으로 부터 얻은 특징값에 추가적인 Fuilly connected 계층을 적용하여 물체에 종류에 대한 classfication score와 Region proposal의 박스를 기준으로 바운딩박스의 변화량을 출력
-
-
-
트레이닝
-
-

Summary
.png)
Single-stage detector
.png)
One-stage detector는 정확도를 조금 포기하더라도 속도를 높여서 real-time detection이 가능하도록 설계하는 데에 목적을 둠, Region proposal을 기반으로 한 RoI를 사용하지 않고, 곧바로 Box Regression과 Classification을 하기 때문에 구조가 단순하고 빠른 수행 시간을 보여준다.
YOLO
.png)
B개의 box를 4개의 좌표와 confidence score를 예측하고 그것에 따른 class score를 또 따로 예측함
.png)
학습시킬땐 ground truth와 match된 b-box와 학습 label를 positive로 간주
.png)
총 30 channel의 결과가 나옴. bbox의 anchor는 2개, B는 2이다. 그리고 Object class는 20개. B 1개에 x, y, w, h, object score 5개씩 이므로 5B+C = 30
SSD
.png)
Multi-scale object를 더 잘 처리하기 위해 중간 feature map을 각 해상도에 적절한 b-box를 출력할 수 있는 multi-scale 구조를 만듬
.png)
각 scale마다 object detection을 출력하게 해서 다양한 scale의 object에 대해 더 잘 대응할 수 있게 설계함.
각 feature map마다 몇 개의 anchor box가 각 위치마다 존재하는지를 계산 후, 각 layer의 결과를 더해주면 anchor box들의 총 숫자가 나옴
Two-stage detector VS One-stage detector
.png)
Single-stage는 RoI pooling이 없기 때문에 모든 영역에서의 loss가 계산되고, 일정 gradient가 발생하게 됩니다. 위 그림처럼 실제 필요한 것은 object에 대한 b-box인데 배경도 다 b-box가 만들어져 고려되기 때문에 class imbalance가 발생하는 단점이 있습니다.
Focal loss
.png)
-
Focal loss는 cross-entropy loss의 확장입니다.
-
cross-entropy loss와 비교해 볼 때, 앞 부분에 확률텀을 추가.
-
γ가 클수록 잘 맞추면 gradient가 0에 가까워 무시되고, 못 맞추면 sharp한 gradient가 발생해 큰 영향을 주게 됩니다.
-
즉, 어렵고 잘못 판별된 예제들에 대해선 강한 weight를 주고, 쉬운 것들에 대해서는 작은 weight를 줍니다.
RetinaNet
.png)
-
low level의 특징 layer들과 high level의 특징을 둘 다 잘 활용하면서도 각 scale별로 물체를 잘 찾기 위한 설계
-
U-Net과 달리 concat이 아니라 add
-
class, box head가 각각 구성돼서 classification과 box regression을 dense하게 각 위치마다 수행
Detection with Transformer
-
NLP에서 높은 성과를 낸 Transformer를 이용해서 CV에서도 성과를 내고자 하는 흐름
-
ViT (Vision Transformer) by Google
-
DeiT (Data-efficient image Transformer) by Facebook
-
DETR (DEtection TRansformer) by Facebook
-
DETR
.png)
-
Transformer를 object detection에 적용한 사례
-
CNN의 feature map과 각 위치를 multi dimension으로 표현한 encoding을 섞어 입력토큰을 만듬
-
Encoding된 feature들을 decoder에 넣으면, query(각 위치)에 해당하는 물체가 무엇인지 b-box에 대한 정보와 함께 parsing돼서 나온다
Further Question
(1) Focal loss는 object detection에만 사용될 수 있을까요?
(2) CornerNet/CenterNet은 어떤 형식으로 네트워크가 구성되어 있을까요?
