(06-1강) CNN Visualization
What is CNN visualization?
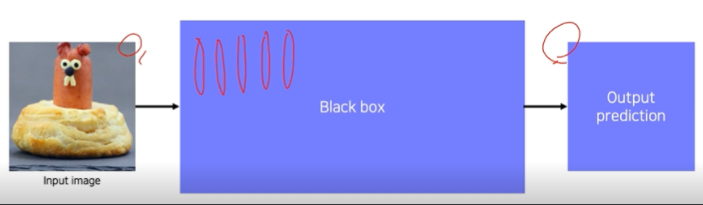
CNN 기반의 neural network들은 학습 가능한 convolution과 non-linear activation function들의 연산기입니다. 하지만, CNN은 워낙 복잡한 구조로 얽혀있어서 해석하기에 어려움이 있습니다. 이것을 Black box라 불리는 이유입니다. 그래서 개발자들은 시각화를 통해서 이를 분석하고자 했습니다.
CNN을 시각화 한다는 것은 디버깅 도구를 갖는다는 것과 같은 의미라고 볼 수 있습니다.
즉, 안에 뭐가 들어있고, 왜 좋은 성능이 나오고, 어떻게 개선할지를 알 수 있습니다.
ZFNet
.png)
-
낮은 계층에는 방향선이 있는 선이나 원을 찾는 영상처리 필터 역할
-
높은 계층으로 갈수록 high level, 의미가 있는 feature를 학습함
-
시각화를 통해 관찰하면서 tuning한 덕에 ImageNet Challenge에서 우승을 차지함
Filter visualization
.png)
-
Filter visualization으로 CNN의 첫 layer가 어떤 특징에 집중하는지 알 수 있음
-
Low level feature는 시각화 할 수 있지만 그 이상 올라가면 channel 수가 커져서 visualization이 불가
How to visualize?
.png)
위 그림은 다양한 visualize 방법론이 나와있습니다. 왼쪽으로 갈 수록 모델 자체의 특성을 분석하는 방법이며, 오른쪽으로 갈 수록 하나의 입력 데이터에서부터 모델이 왜 그런 결과를 냈는지 출력을 분석하는 방법입니다.
Analysis of model behaviors
.png)
- High level layer를 해석하는 방법
Embedding feature analysis

-
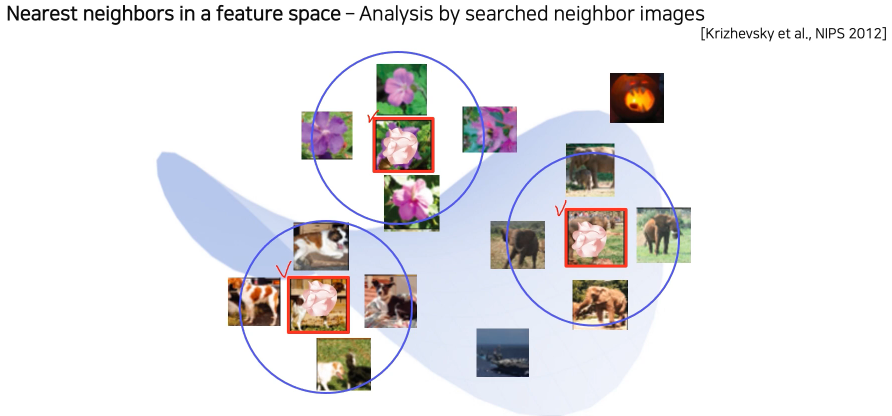
Nearest neighbors (NN) in a feature space - Example
-
예제 영상을 통해 visualize 하는 방법
-
Query image와 유사한 이웃 영상들을 DB에서 찾아 거리순으로 정렬
-
왼쪽 input(query data) - 오른쪽 output(DB에 저장된 데이터)
-
의미론적으로 유사한 영상들이 cluster 되어있음
-
하지만 검색된 예제를 통해서 분석하는 방법은 전체적인 그림을 파악하기 어려운 단점이 존재
-
이제 Nearest neighbors를 이용한 예제검색이 구체적으로 어떻게 동작하는지 알아보겠습니다.
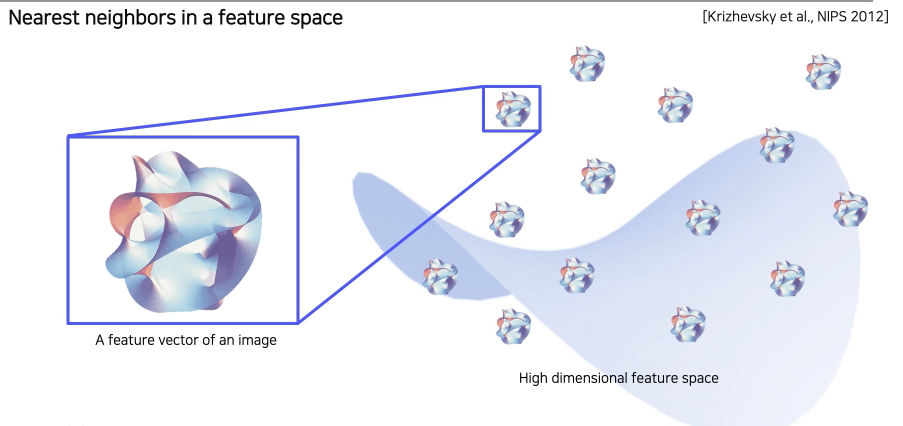
- 돌멩이같은 것이 고차원의 feature vector를 표현하는 것입니다.
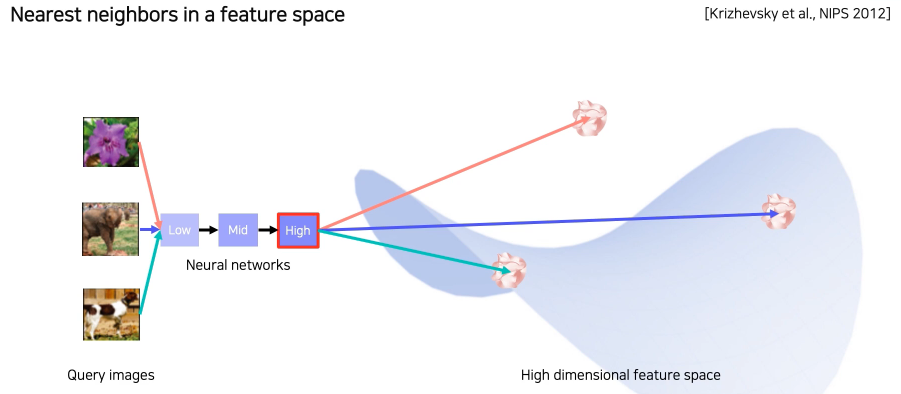
- 미리 학습된 NN에서 마지막 fc layer를 제거해 input image의 feature vector를 추출할 수 있게 만듬
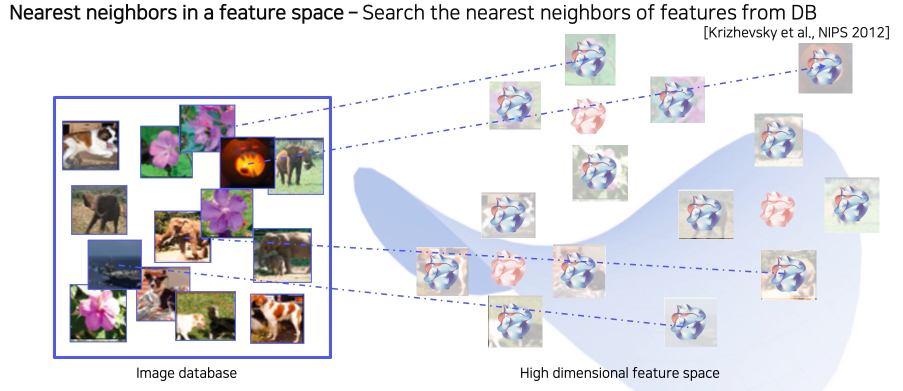
- DB의 모든 image들을 feature vector를 추출해 다시 DB에 저장
- Query image를 넣어 feature vector를 추출하고 그것과 근접한 거리에 있는 feature vector의 원본 image를 찾아 return
Dimensinality reduction
.png)
Backbone network을 활용해서 특징을 추출하게 되면 고차원 특징 벡터가 나오게 되는데 이것이 너무 고차원이라 해석하기 힘든 문제가 있습니다.
3차원까지는 해석하기 쉽지만, 이보다 더 고차원으로 가면 해석하기가 어려워지기 때문입니다.
이런 문제를 해결하기 위해서 고차원 벡터를 저차원으로 내려서 표현하는 방법 즉, 차원 축소 방법을 통해서 눈으로 쉽게 확인 가능한 분포를 얻어내는 방법을 소개합니다.
t-SNE
.png)
-
High dimensional feature를 2차원 상에 각 클래스마다 다른 색으로 표현
-
몇몇 튀는 example들을 제외하곤 전반적으로 비슷한 클래스들 끼리 잘 분포되어 있다
-
클래스간의 분포도, 유사성을 거리를 기반으로 판단 가능
-
3, 5, 8은 조금 맞닿아있다. 겹치는 부분은 헷갈릴 수 있음 → 비슷한 특징을 보인다는 뜻
실제로도 3과 5와 8은 비슷하게 생겼음
Activation investigation 1
Layer의 activation을 분석함으로써 모델의 특성을 파악하는 방법을 소개합니다.
Layer activation
Mid, high layer의 activation을 해석하는 방법입니다.
.png)
.png)
-
위 첫번째 행은 AlexNet에서 Conv5 layer의 138번째 채널의 activation을 적당한 값으로 threshoding 후 마스크로 만들어서 영상에 overlay 한 결과
-
각 activation의 채널이 어디를 중점적으로 바라보고 있는지 파악할 수 있음
-
CNN은 중간의 hidden node들이 손, 얼굴 등 부분을 detect하는 것을 다층적으로 쌓아서 물체를 인식한다는 것을 알 수 있음
Maximally activating patches
- Mid layer에 적용하는 방법
.png)
-
layer activation을 이용한 분석방법 중에 patch를 뜯어서 사용하는 방법
-
각 layer의 채널에서 하는 역할을 판단하기 위해서 그 hidden node에서 한 채널을 가져왔을 때 가장 높은 값을 갖는 위치의 patch를 출력
-
국부적 patch만을 보기 때문에 mid layer에 적합
-
Pick a channel in a certain layer
-
Feed a chunk of images and record each activation map(of the chosen channel)
2.1 이미지를 넣고 각각의 activation map을 저장함 -
Crop image patches around maximum activation values
3.1 activation map의 가장 큰 값을 고르고 그것의 receptiva field를 계산하여 patch를 뜯어옴
Class visualization - Gradient ascent
.png)
지금까지는 activation을 분석하기 위해 데이터를 사용했지만, 이제부터는 예제 데이터를 사용하지 않고, 네트워크가 내재하고 있는 이미지를 분석하는 방법입니다.
각 클래스를 판별할 때 이 네트워크는 어떤 모습을 상상하고 있는지 볼 수 있습니다.
.png)
-
bird class에서는 새 모습들이, 개 class에서는 개 모습이 추출되는 것을 확인 가능
-
dog class에서는 개 뿐만 아니라 인간의 모습도 출력되고 있음
- 이 모델은 개를 파악하기 위해 해당 물체만 찾는게 아니라 주변의 사람 같은 모습도 찾고 있다
- Dataset이 가족적인 사진으로 biased 돼있다
이 방법은 간단한 연산으로는 구현 불가능하고, 최적화를(Gradient Descent) 통해서 합성 영상을 찾아나갑니다. 이와 비슷하게 로스를 최적화시켜주는 과정을 거치는데 2개의 로스가 있습니다.
- I = 영상 입력
- f = CNN 모델
- argmaxf(I) : CNN model f를 지나서 출력된 하나의 score
- Reg(I): 입력 image의 Regularization term (해석 가능한 형태(image)가 아닌 I가 입력으로 들어왔을 때 f(I)의 값이 매우 커서 정답으로 분류하는 것을 방지)
.png)
score를 높이는 영상 애들만 사용하게 되면, 더이상 영상이 아닌 애들도 찾을 수 있습니다. 그래서 우리가 이해할 수 있는 간단한 loss인 regularization term을 추가하게 됩니다!
Gradient ascent - Image synthesis
이제 step-by-step 으로 알아보겠습니다.
-
Get a prediction score (of the target class) of a dummy image (blank or random initial)
임의의 영상으로 분석하고자하는 CNN에 입력해준다 → 관심 class score를 추출
.png)
-
Backpropagate the gradient maximizing the target class score w.r.t the input image
역전파를 통해 입력이 어떻게 변해야 target class score가 높아지는지를 찾는다. (gradient를 더해주는 것, loss를 측정할 때 score값에 -를 붙여서 내려가는 방향으로 만들고 gradient를 측정해주면 이전에 사용하던 gradient descent 방식이랑 동일함)
.png)
- 그리고 그 방향으로 input image를 update 해줌(빈 이미지에서 아래의 사진처럼 update)
.png)
- 23번을 반복한다
다만, 초기값을 어떻게 설정하든 문제가 없으나 설정값에 따라 update되는 것이기 때문에 결과가 조금씩 달라질 수 있습니다.
Model decision explaination
모델이 특정 입력을 어떤 각도로 해석하고 있는지 분석하는 방법
Sailency test
영상이 주어졌을 때 이것이 제대로 판정되기 위한 각 영역의 중요도를 추출하는 방법
Occlusion map
.png)
영상이 주어졌을 때 이것이 제대로 판정되기 위한 각 영역의 중요도를 추출하는 방법입니다.
.png)
-
A와 B라는 큰 Patch로 가려주었을 때 Elephant라고 대답을 할 확률
-
이 Patch를 모든 곳에다가 적용을 한 후 그 heatmap을 만들면 그 중요도가 확인 가능하다
via Backpropagation
.png)
-
Gradient ascent를 이용해 분석 이미지를 생성했던 방법과 유사
-
임의의 image가 아니라 목표로 하는 image를 입력으로 넣는다는 점이 차이점
.png)
위 그림처럼 특정 이미지를 classification을 해보고 최종 결론이 나온 class에 결정적으로 영향을 미친 부분이 어디인지 heatmap 형태로 나타내는 기법.
-
입력 image에 대한 class score를 구함
.png)
-
Backpropagate로 gradient의 절댓값를 구함
gradient의 부호보다는 magnitude 자체가 중요한 정보기 때문에 절댓값이나 제곱을 사용
(Magnitude가 큰 부분이 input에서 바뀌어야 score도 변함, 민감한 영역)
.png)
Backpropagation - based saliency
Rectified unit (backward pass)
.png)
-
일반적으로 CNN에서는 ReLU를 사용하는데, Forward pass에서 음수가 나온 부분을 0으로 바꿔준다. 이 위치들을 기억해뒀다가, backpropagation이 올 때 같은 위치면서 음수가 되는 부분을 0으로 바꿔줌
-
Zeiler는 deconvolution된 activation이 backward로 내려올 때 gradient 자체에 ReLU를 적용. 즉, 그냥 backward 연산 시에 음수인 파트들을 0으로 바꿔줌
이를 수식으로 표현해보면 아래와 같이 나타낼 수 있습니다.
.png)
아래 그림은 forward, backward 모듀 ReLU를 적용한 수식. 수학적으로 의미는? 잘 모르겠지만 결과가 좋다고 합니다.
.png)
.png)
Class activation mapping (CAM)
- 가장 유명하고 자주 사용되는 알고리즘
.png)
- 아래 그림처럼 어떤 부분을 참고해서 결과가 나왔는지 heatmap으로 보여줌
.png)
- Convolution의 결과로 나온 feature map을 FC layer가 아니라 GAP(global average pooling)을 통과하게 바꿈
- 그 다음에 최종 FC layer 1개만 통과해서 classify
- 그 후 그 개조된 network에 CAM을 훈련시킴
.png)
-
구현 수식
-
.png)
-
: Convolution layer의 output인, convolution map(혹은 feature map)의 channel 수
-
:FC layer에서 class c에 해당하는 weight. class dptj 의 중요도를 나타냄
-
: conv map의 k번째 channel에서 (x, y)좌표 pixel의 값
-
: conv map의 k번째 channel의 모든 pixel을 GAP한 값(node)
-
: weight 와 feature 의 linear combination. class C에 대한 score
-
: (x, y) 좌표의 pixel의 class c 에 대한 중요도 (input이 c로 분류되는데 해당 pixel이 얼마나 영향을 미치는지)
- GAP을 적용하기 전이기 때문에 공간에 대한 정보(width x, height y)가 남아있음 --> image처럼 visualization이 가능
-
하나의 class Score는 마지막 FC layer의 class에 대한 weight와 Feature로 linear combination
-
이것은 각각의 pixel에 각 채널마다 평균을 취한 것
-
그 수식이 linear 함으로 교환법 칠을 사용하면 마지막 수식이 도출됨
-
CAM은 Global average pooling을 취하기 전이므로 공간에 대한 정보가 남아있다.
- 그것을 영상처럼 visualization 해주면 위와 같이 결과가 나온다.
-
.png)
-
는 공간정보가 남아있기 때문에 heatmap 형태로 visaulization이 가능
-
위 사진에서 각 heatmap은 feature map의 각 channel을 의미
-
-
.png)
-
CAM 적용을 하려면 마지막 layer 구성이 GAP과 FC layer로 이뤄저야 해서, 일부 model에서 CAM을 사용하기 위해선 architecture를 바꾼 후 재학습을 해야된다는 점이 단점 --> 성능이 떨어지거나 parameter tuning이 다시 필요함
-
GoogLeNet 같은 경우는 마지막에 AveragePooling, FC layer가 있기 때문에 CAM을 적용하기 쉬움
-
참고: https://mole-starseeker.tistory.com/m/66?category=859657
https://kangbk0120.github.io/articles/2018-02/cam
--> 코드도 있음!
-
Global Average Pooling (GAP)
.png)
-
공간 정보가 FC layer보다는 덜 날아감 == channel이 남아있기 때문에???, 하지만 width, height가 날아가기 때문에 손실되는것 자체는 맞다
-
GAP는 어떤 크기의 feature 라도 같은 채널의 값들을 하나의 평균 값으로 대체하기 때문에 벡터가 된다.
-
따라서 어떤 사이즈의 입력이 들어와도 상관이 없고, 단순히 (H, W, C) → (1, 1, C) 크기로 줄어드는 연산이므로 파라미터가 추가되지 않으므로 학습 측면에서도 유리
-
또한 파라미터의 갯수가 FC Layer 만큼 폭발적으로 증가하지 않아서 over fitting 측면에서도 유리
-
따라서 GAP 연산 결과 1차원 벡터가 되기 때문에 최종 출력에 FC Layer 대신 사용할 수 있음
-
경우에 따라서 FC layer와 같이 사용 되기도 함
-
FC layer에 전달하기 전에 GAP를 이용하여 차원을 줄여서 벡터로 만든 다음에 FC layer로 전달 하면 FC Layer에서 쉽게 사이즈를 맞출 수 있기 때문
-
-
GAP이 공간정보가 유지된다고 하는 이유??
-
GAP를 쓰면 사상(embedding)된 특징 공간에서 이미지의 특정 영역이 response 되고, 이를 class activation map으로 시각화 함으로써 확인할 수 있기 때문입니다.
-
더 자세히 말하면, GAP 연산은 채널 별로 평균을 낼 뿐이고, 평균을 통해 얻은 클래스 개수만큼의 1차원 벡터와 클래스 라벨로 loss를 계산해 업데이트 했을 때, GAP 연산의 결과가 아닌 GAP 연산을 거치기 전의 컨볼루션 필터(커널)들을 학습시킵니다.
-
이때 역전파를 통해 loss를 업데이트하면서 해당 컨볼루션 필터들은 이미지의 특징을 더 잘 잡도록 훈련될 것이며, 그 부분이 response가 됩니다.
-
이 response 덕에 GAP 연산을 적용하면 FC Layer에 비해 location 정보를 상대적으로 덜 잃는 것으로 볼 수 있습니다.
-
-
참고: https://velog.io/@hanlyang0522/CV-6%EA%B0%95-CNN-Visualization#class-activation-mapping
Grad-CAM
.png)
-
Pre-trained network를 변경하지 않고 사용할 수 있음
-
Model을 변경할 필요가 없기 때문에 image task에만 국한되지 않고 backbone이 CNN이기만 하면 사용 가능

- CAM의 weighted sum을 해주는 weight를 어떻게 구해주느냐가 핵심
.png)
-
Input image까지가 아니라 activation map(conv layer)까지만 backpropagate함
-
: 현재 class의 score
-
: 현재 class의 weight
score를 미분 후 공간축으로 GAP해서 각 channel의 gradient 크기를 구함
Activation map을 결합하기 위한 weight로 사용
.png)
- 와 (activation map)을 선형결합한 후 ReLU를 적용해 양수값을 사용
.png)
-
CNN backbone 외엔 별다른 요구사항이 없기 때문에 classification, RNN 등 여러 task에 적용할 수 있는 일반화된 도구
-
Grad-CAM은 rough, smooth, class에 민감하고 Guided Backprop은 sharp, sensitive, high frequency하기 때문에 둘의 결과를 곱해서 특정 class에 대한 texture만 알아낼 수 있음
SCOUTER
.png)
요즘에는 Grad-CAM을 개선해서 class를 판별할 뿐만 아니라 어딜 보고 해석했는지, 왜 다른 class는 아닌지에 대한 정보도 얻을 수 있습니다.
Further Question
(1) 왜 filter visualization에서 주로 첫번째 convolutional layer를 목표로할까요?
(2) Occlusion map에서 heatmap이 의미하는 바가 무엇인가요?
(3) Grad-CAM에서 linear combination의 결과를 ReLU layer를 거치는 이유가 무엇인가요?
- 참고
(06-2강) AutoGrad
https://colab.research.google.com/drive/1bxXiqDc0pFGXuMCiJUuuP6vKUO10Iag8#scrollTo=pE5a3cHbMHsS
