(07강) Instance/Panoptic Segmentation and Landmark Localization
Instance segmentation
What is instance segmentation?

Instance segmenters
Mask R-CNN
.png)
Mask R-CNN은 기존의 Faster R-CNN과 거의 동일한 구조이지만, RoIAlign 이라는 새로운 Pooling layer을 제안했다.
RoIAlign 은 정수 좌표만 지원하는 기존의 RoI Pooling에 비해 interpolation을 통해서 소수점 픽셀까지 지원을 하여 좀 더 정교하다.
.png)
Mask R-CNN은 Faster R-CNN + Mask branch
-
Mask branch
-
위 그림을 보면, w 와 h는 upsampling하여 14x14가 되었고, channel은 줄였다.
-
모든 class에 대해 binary mask를 predict
-
하나의 bbox 마다 모든 클래스의 mask를 한 번에 생성한 후 classification 결과에 따라 하나씩 참조.
-
YOLACT
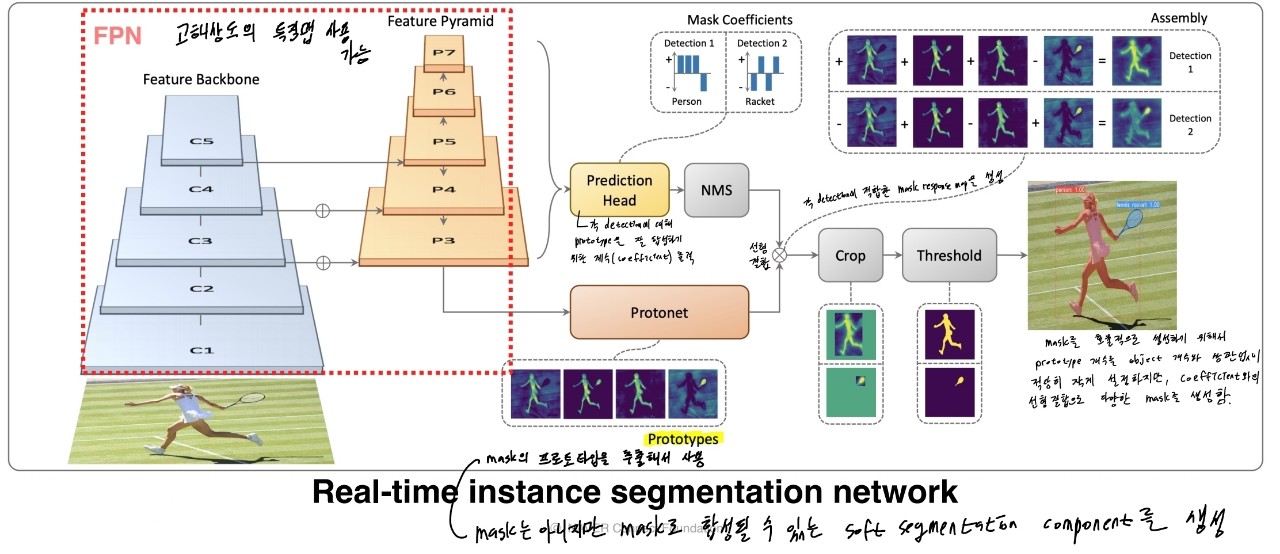
-
Single-stage network
-
Backbone으로 FPN(Feature pyramid network)를 사용하여 고해상도의 feature map 사용 가능
-
Prototypes : mask의 프로토타입을 추출해서 사용
- mask는 아니지만 mask로 합성될 수 있는 soft segmentation component를 생성
-
Projection head : 각 detection에 대해 prototype을 잘 합성하기 위한 계수(coefficient)를 출력
- 이후 coefficient와 prototype을 선형결합하여 각 detection에 적합한 mask response map을 생성
-
Mask를 효율적으로 생성하기 위해 prototype의 갯수를 object(class) 갯수와 상관없이 적당히 작게 설정하지만, coefficient와의 선형결합으로 다양한 mask를 생성하는 것이 핵심
YolactEdge
.png)
-
YOLACT를 소형화, 가볍게 만든 모델
-
이전 frame에서 key frame의 feature를 다음 frame에 전달해서 계산량을 획기적으로 줄임
-
속도 개선을 하였지만, mask가 불안정하다는 단점이 존재.
Panoptic segmentation
.png)
-
Panoptic segmentation : Instance segmentation의 단점이었던 background를 잘 구분하지 못한다는 문제를 해결
-
또한 Background 뿐만 아니라 관심을 가질만한 물체들의 instance도 구분
UPSNet
.png)
-
Backbone network : FPN
-
Head branches
-
Semantic head : Fully convolution 구조, semantic map을 예측
-
Instance head : Object detection과 box regression, mask의 logit을 예측
-
Panoptic head : 앞선 head의 결과를 조합해 최종적으로 하나의 segmentation map을 만듬
-
.png)
-
: instance mask
-
, : 각각 물체와 배경에 대한 mask
-
각 instance들을 bbox가 아니라 전체 영상에 해당하는 위치에 넣기 위해 을 masking해서 와 더함
-
와 을 뺄셈 처리 해서 Instance와 object 모두에 해당하지 않는 부분은 제외하고 unknown class로 만든 후 1 channel로 최종 결과에 추가
VPSNet
.png)
-
Panoptic segmentation을 video로 확장
-
시간차 를 가지는 영상 사이에 라는 motion map을 사용해 각 frame에서 나온 feature map을 motion에 따라 warpping
-
motion map 란?
-
모든 pixel에 대해서, 한 image에서의 포인트가 다음 image엔 어디로 가는지에 대한 대응점들을 가지고 있는 motion을 나타낸 것
-
에서 뽑힌 feature를 t에서는 어떤 위치인지 옮김(tracking)
-
-
-
이후 원래 각 frame 에서 찍혔던 feature와 warpping된 feature 두개를 합침.
-
이전 프레임에서 빌려온 특징들 덕분에 현재 프레임에서 추출된 feature 만으로 대응하지 못하거나 보이지 않게 가려졌던 부분들도 더 높은 detection 성공률이 나온다.
-
여러 프레임의 feature를 합쳐서 사용함으로써 시간 연속적으로 smooth 한 segmentation이 될 확률도 높아진다
.png)
-
VPN을 통해서 RoI 들의 feature를 추출한 후 Track head를 통해서 기존 RoI들과 현재 RoI가 어떤 연관이 있는지 확인
-
같은 물체는 같은 ID 를 가질 수 있도록, 시간에 따라서 tracking을 하게끔 함.
.png)
- 이후는 UPSNet과 동일하게 B-box, mask, semantic head에서 나온 결과를 하나의 panoptic segmentation map으로 붙여준다.
Landmark localization
.png)
landmark localization : 얼굴이나 사람의 몸통등 특정 물체에 대해서 중요하다고 생각하는 landmark를 정의하고 이를 추적하는 것
Coordinate regression vs heatmap classification
.png)
-
Coordinate regression
-
Box regression 처럼 FC layer의 각 node가 landmark의 x,y 위치를 예측하게 하는 방식
-
부정확하고 일반화가 어려움
-
-
heatmap classification
-
Semantic segmentation처럼 각 채널이 각각의 key point를 담당
-
각 key point 마다 하나의 클래스로 생각해서 그 key point가 발생할 확률 map을 각 pixel별로 classification
-
성능이 훨씬 좋음. 하지만 계산량이 많다
-
Landmark location to Gaussian heatmap
.png)
-
x,y 위치가 label로 주어졌을 때, 즉 landmark가 (x,y)에 있을 경우, 각 위치의 confidence(landmark가 있을 가능성)를 heatmap으로 변환
-
Label 로 주어진 x,y가 gaussian의 평균을 나타내고 그 위치 근처에 gaussian 분포를 만듦
size = 6 * sigma + 1 # 임의의 영상크기 사이즈(보통은 출력 해상도의 크기 사용) x = np.arange(0, size, 1, float) # 출력 영상의 모든 픽셀의 좌표 값들을 나열하기 위한 x,y y = x[:, np.newaxis] x0 = y0 = size // 2 if type == 'Gaussian': g = np.exp(- ((x - x0) ** 2 + ((y - y0)) ** 2) / (2 * sigma ** 2)) elif type == 'Cauchy': g = sigma / (((x - x0) ** 2 + (y - y0) ** 2 + sigma ** 2) ** 1.5)
Hourglass network
.png)
-
UNet과 비슷한 구조
-
영상을 작게 만들어서 RF의 크기를 키움
-
Receptive field를 크게 가져가서 큰 영역을 보면서도 skip connection 이 있어 low level feature 를 참고해서 정확한 위치를 특정하도록 유도
.png)
-
UNet처럼 concat하지 않고 더해줘서 dimension이 늘어나지 않는다
-
skip connection 할때 또 다른 convolution layer를 통과해서 전달이 되게 된다
Extensions
DensePose
.png)
-
UV map 이란?
- 표준 3D 모델에 각 V 를 2D 로 펼쳐서 이미지 형태로 만들어 놓은 좌표 표기법
-
UV map에서의 한 점은 3D mesh 모델상의 한점과 1:1 대응
-
3D mesh가 움직여도 이 id는 보존
-
map 은 고정된 형태의 지도라서 특정 점의 위치를 알고 있으면 3D 상에서 어디에 위치하는지 계속알 수 있다
.png)
-
Patch : 각 body의 segmentation map
-
마지막의 mask branch 부분이 UV map prediction으로 변환하여 DensePose를 예측.
RetinaFace
.png)
-
공통된 정보 이외에 task마다 조금씩 다른 정보를 backbone network가 학습하기 때문에 훨씬 강하게 학습
-
공통된 정보 이외에 task마다 다른 정보를 backbone이 학습하기 때문에 효과가 좋다
-
사용한 데이터양 대비해서 성능 향상 폭이 큰 경우가 많음
Detecting objects as keypoints
CornerNet
.png)
-
Top-left, Bottom-right 정보만 갖고 bbox를 찾아내는 방식
-
Heatmap에서는 corner point만 출력하고, embedding에서 같은 object끼리 match
-
성능보다는 속도를 강조한 구조
CenterNet
.png)
Center point를 추가해서 성능을 개선
.png)
Further Question
(1) Mask R-CNN과 Faster R-CNN은 어떤 차이점이 있을까요? (ex. 풀고자 하는 task, 네트워크 구성 등)
(2) Panoptic segmentation과 instance segmentation은 어떤 차이점이 있을까요?
(3) Landmark localization은 human pose estimation 이외의 어떤 도메인에 적용될 수 있을까요?
Reference
.png)
(08강) Conditional Generative Model
Conditional generative model

Conditional generative model 이란?
Condition이 주어졌을 때, 조건에 해당하는 결과가 나오는 형태
.png)
-
기존 generative model은 image나 sample을 생성할 수는 있지만, 조작은 할 수 없었음
-
Conditional generative model은 user의 의도를 반영해 응용 가능성을 높임
GAN vs Conditional GAN
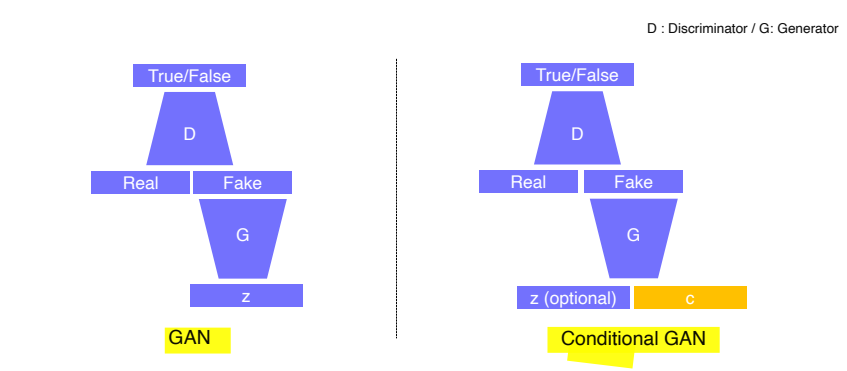
-
GAN : Generator의 입력으로 random vector z를 넣고, fake data가 생성되면 discriminator로 판별
-
Conditional GAN : Input으로 conditional input c를 넣음
Conditional GAN and image translation

Example : Super resolution

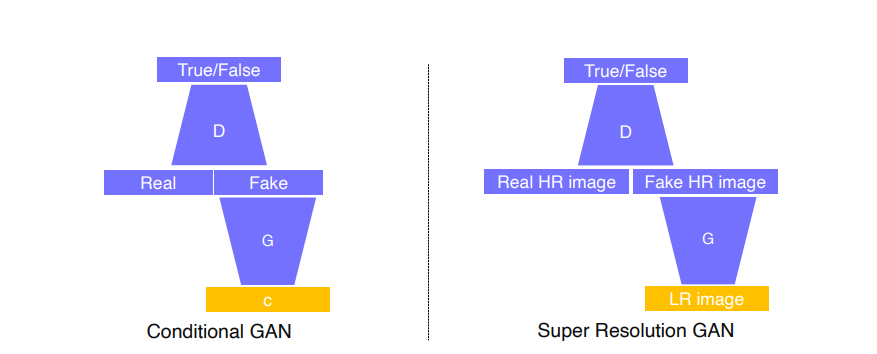
Low resolution을 입력해서 Fake high resolution image를 만들고, real data로 real high resolution image를 줘서 가짜 HR image가 실제 HR image와 비슷한 통계적 특성을 지니는지 판별
.png)
이전까지는 단순히 L1, L2 loss를 사용했다

-
MAE(L1), MLE(L2)를 사용하면 높은 해상도에서 blur image를 얻게된다.
왜냐하면 평균 error를 구하다보니 출력 결과가 비슷한 error를 가지는 많은 패치들이 존재하기 때문. -
GAN은 real data와 구분을 못하게 하는 것이 목적이므로 가장 가까운 real data와 더 닮게 함으로써 loss를 낮춤
.png)
- L1 loss : 두 real image에 대해 모두 loss를 낮추는 중간값을 선택
- GAN : Discriminator가 real data 중 비슷한게 있는지 판별하기 때문에 real data에 가까워짐
Image translation GANs
Pix2Pix
.png)
-
image의 domain을 다른 domain으로 translate하는 task
-
Image translation task를 CNN 구조를 이용해 학습기반으로 처음 정리한 연구

L1 loss 는 blur를 만들지만 적당한 guide로 쓰기에 좋다. 왜냐하면 GAN은 real/fake만 판별하기 때문에 y에 대한 학습을 못하기 때문이다.
GAN loss는 realistic output을 만든다.
.png)
-
L1만 쓰면 blurry하고, GAN만 쓰면 GT와 다른 스타일의 output이 나오는 것 확인 가능
-
L2는 어중간한 색상을 선택해 안전한(어느 input에도 loss가 적절히 작은) 선택을 한다
CycleGAN
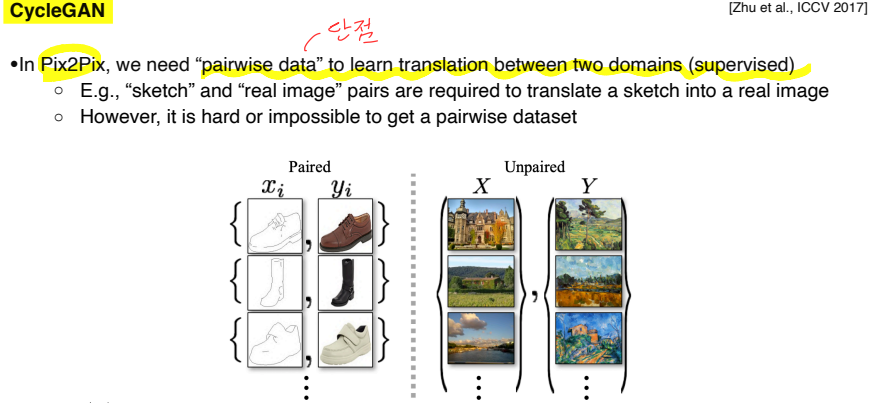
Pix2Pix는 의 pairwise data를 얻기 어렵다는 것이 단점이다.

CycleGAN은 1:1 대응하는 data가 아니라 non-pairwise dataset만 있어도 활용할 수 있다.

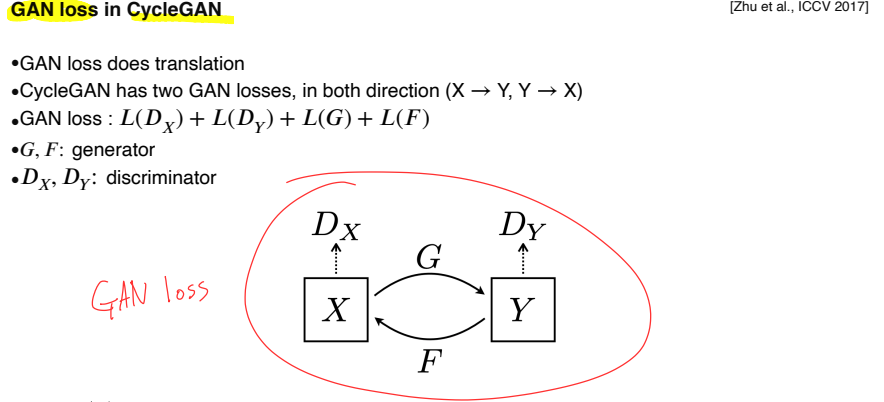
-
generator(G)가 X로 Y를 만들면 실제 데이터와 비슷한지 가 판별
-
generator(F)가 Y로 X를 만들면 원래 X와 비슷한지 가 판별

-
GAN loss만 계속 사용하면 input에 관계없이 하나의 realistic한 output만 출력하는 Mode Collapse 가 발생
-
Mode Collapse : input과 다르긴 한데 realistic 하니까 GAN에서는 잘하고 있다고 판단하고 더 이상 학습하지 않는 현상
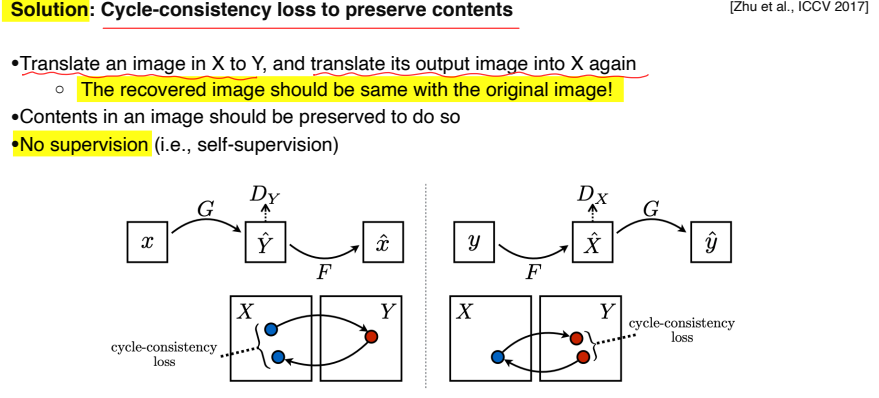
-
Cycle-consistency loss : style 뿐만 아니라 content도 유지해야 한다
-
X가 Y가 되고 다시 X를 생성했을 때 원본 data가 유지되야 한다
-
Loss를 계산할 때 어떤 supervision도 들어가지 않기 때문에 self-supervision 이다.
Perceptual loss

GAN loss는 학습시키기에 어렵다.
WHY?
위 그림에서 GAN loss 식에서 를 보면 알 수 있는데, Generator와 Discriminator를 서로 경쟁하면서 학습 시켜야하기 때문이다.
Perceltual loss를 사용하면 GAN과 같이 복잡한 연산을 하지 않더라도 쉽게 image translation, style transfer 할 수 있다.

-
GAN loss(Adversarial loss)
- 위에서 말했다시피 Generator, discriminator가 서로 경쟁하면서 학습해야하기 때문에 복잡하다는 단점이 존재
-
Pre-trained network가 필요하지 않다는 장점
-
Application에 상관없이 data만 주어지면 사용 가능하다는 장점
- Data-dependency가 단점이 될 수도 있음
-
Perceptual loss
-
일반적인 NN을 train하듯 forward & backward computation으로 사용 가능
-
Pre-trained network가 필요
-
.png)
-
Pre-trained의 early network filter들이 human perception의 방법과 닮아있다는 점에서 착안
-
Pre-trained filter가 image를 인간이 세상을 바라보는 방법과 비슷하게 perceptual space로 변환하는 transformer 역할을 할 수 있다는 점에서 착안
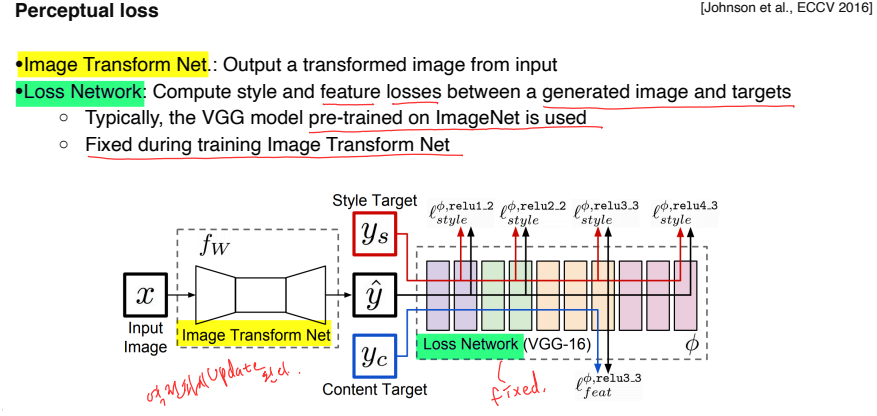
-
Image Transform Net : Input image를 원하는 1개의 style로 transform 시킨다.
- Backpropagation시 학습됨
-
Loss network : 학습될 loss를 측정하고, feature(activation)를 추출한다.
- Networks는 pre-trained model을 사용하고 fixed라 학습되지 않음
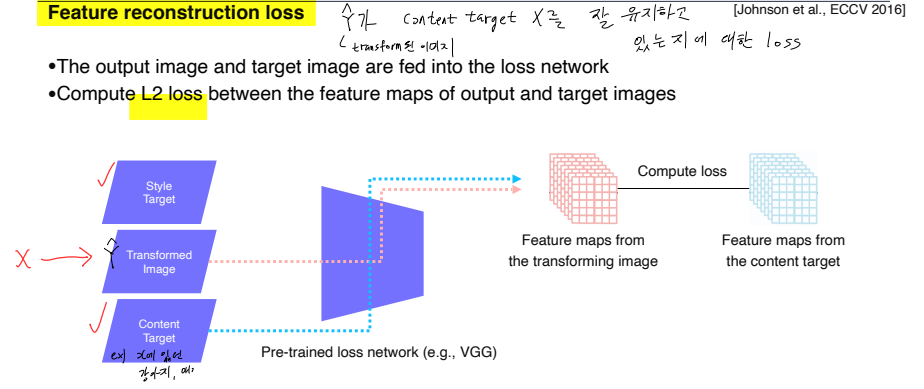
-
Feature reconstruction loss
- transform된 이미지 이 content target 를 잘 유지하고 있는지에 대한 loss
-
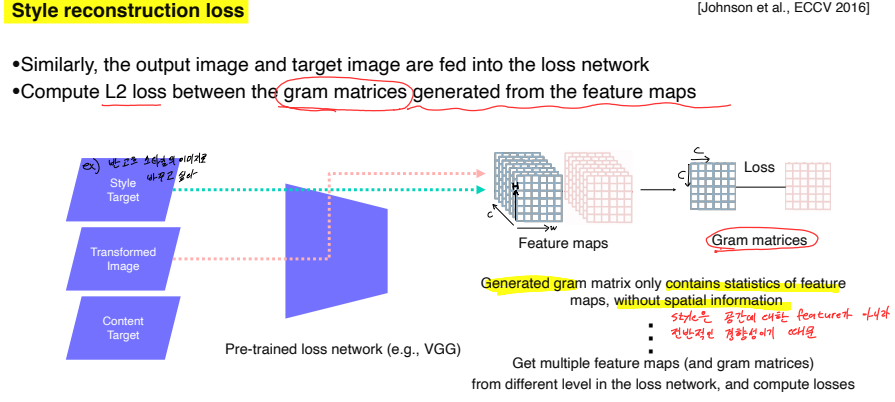
Style reconstruction loss
-
원본의 style을 잘 유지하고 있는지에 대한 loss
-
Style 비교를 위해 feature map을 바로 비교하지 않고 gram matrix를 만들어서 비교
-
Gram matrix : Feature map의 spatial information이 없는 통계적 특징을 담기 위해 생성. 왜냐하면 Style은 특정 공간에 대한 feature가 아니라 전반적인 경향성이기 때문이다
-
하나의 convolution layer에서만 gram matrix를 뽑는게 아니라 중간중간 channel에서 다 뽑은 후 서로 다른 level에서 style loss를 내적
-
.png)
-
[C, H, W]의 tensor를 [C, H*W]의 2차원 dim으로 reshape한 후, 내적을 통해 [C, C]의 tensor 생성
-
결국 transformed image의 gradient는 style target의 channel 간의 correlation(statistics)을 저장
-
즉, transformed image의 gram matrix가 style target의 gram matrix를 닮아가게 된다.
-
-
만약 Super resolution처럼 style이 변하지 않는 경우엔 style reconstruction loss는 쓰지 않고 Feature reconstruction loss만 사용해서 content는 유지하되, perceptual한 quality를 높임
-
Reference
.png)
Further Reading
- Generative Adversarial Networks : https://arxiv.org/pdf/1406.2661.pdf
- StyleGAN : https://arxiv.org/pdf/1812.04948.pdf
