📌 Optimization
- 최적화에서는 사용하는 용어를 제대로 알고 있지 않으면 나중에 가서 잘못된 이해를 할 수 있으므로 용어의 정의를 명확하게 알아야 한다.
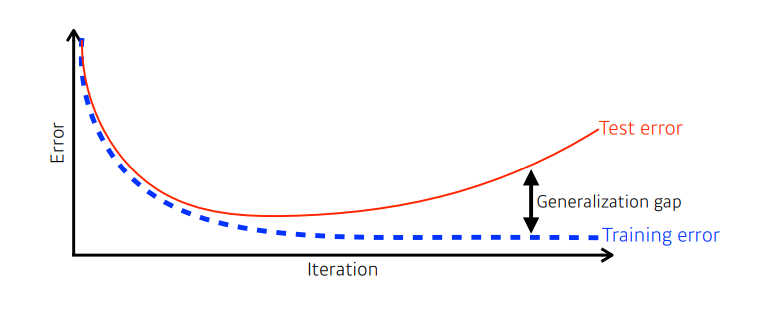
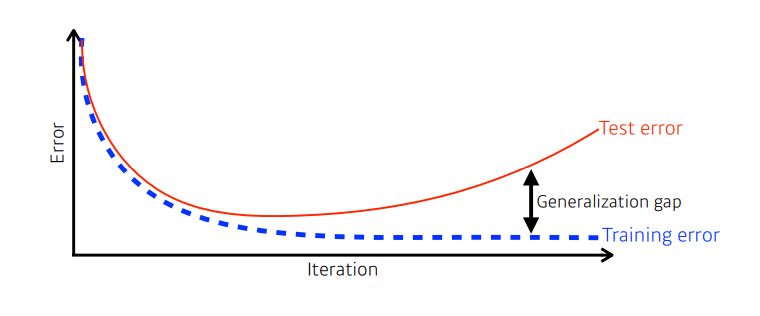
Generalization
- Generalization(일반화) : 학습된 모델이 test data에 대해 얼마나 잘 맞추는가
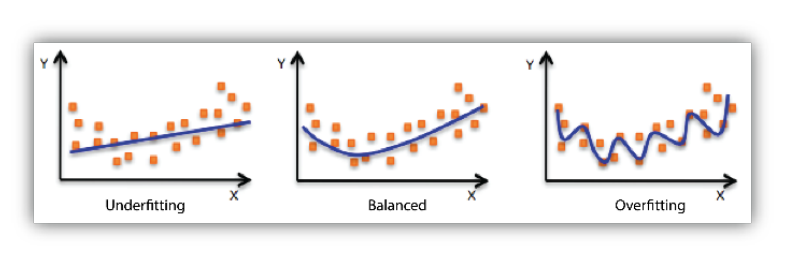
Under-fitting vs Over-fitting
-
underfitting(과소적합)
- 모델의 용량이 작아 오차가 클 수 밖에 없는 현상
- 훈련집합과 테스트집합 모두 낮은 성능
-
overfitting(과대적합)
- 모델의 용량이 크기 때문에 학습 과정에서 잡은까지 수용 => 훈련집합에 대해 너무 완벽하게 근사화함.
- 훈련집합에 높은 성능을 보이나 테스트집합에서는 낮은 성능.
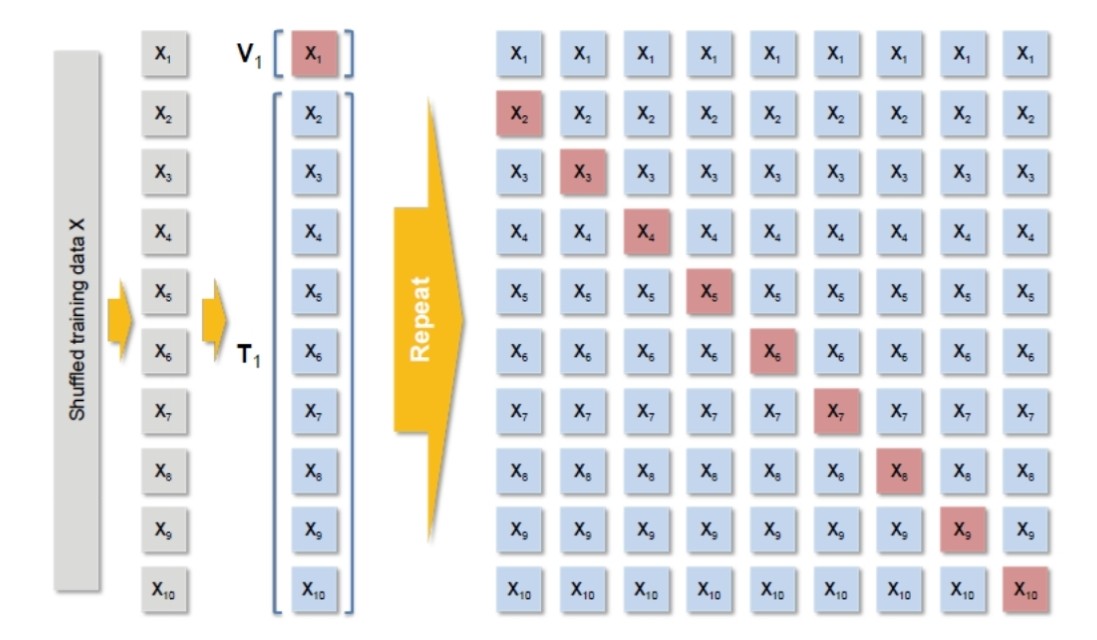
Cross-validation
- 교차검증이란?
- 데이터 편중을 막기 위해 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것.
- 예를 들면 수능(테스트 데이터)을 보기 전에 모의고사(교차 검증)을 보며 시험준비를 한다.
- 훈련집합을 등분하여, 학습과 평가 과정을 여러 번 반복한다. 아래 사진은 10겹 교차 검증의 예시이다.
Bias-variance tradeoff
-
편향(Bias)과 분산(Variance)
- 편향(Bias) : 예측값과 정답 간의 관계
- 분산(Variance) : 예측값끼리의 관계
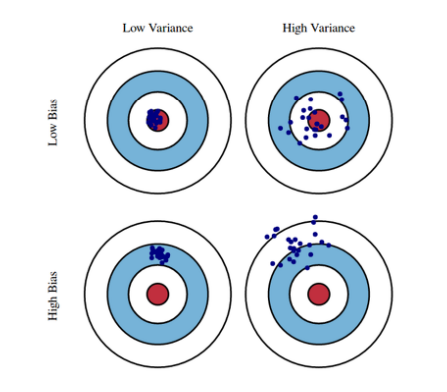
- 예시를 들자면, 편향이 낮다는 것은 화살이 과녁 정중앙에 꽂힌다는 의미이고, 분산이 낮다는 것은 여러개의 화살이 같은 지점에 꽂힌다는 의미.
-
이러한 편향과 분산은 상충관계(tradeoff) 이다. 즉, 분산이 높게되면 편향이 낮아지는 관계이다.
- 우리의 목표는 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표이다.
- 따라서 편향을 최소로 유지하며 분산도 최대로 낮추는 전략이 필요하다.
Bootstrapping
- 임의의 복원 추출 샘플링 (sampling with replacement) 반복.
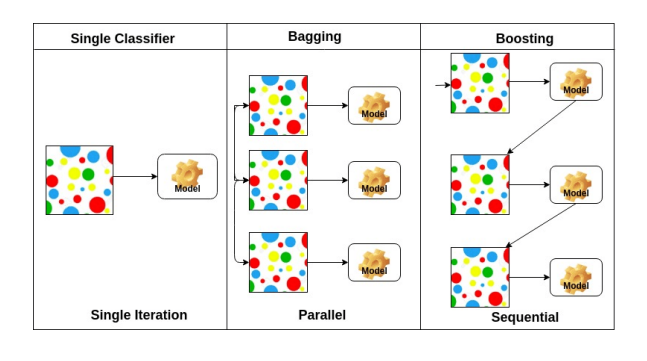
Bagging and Boosting
- Bagging(Bootstrapping aggregating)
- 훈련집합을 여러 번 샘플링 하여 서로 다른 훈련집합을 구성
- 동시다발적(Parallel)
- Boosting
- i 번째 예측기가 틀린 샘플을 i+1번째 예측기가 잘 인식하도록 연계성을 고려
- 순차적(Sequential)
서로 다른 여러 개의 모델을 결합하여 일반화 오류를 줄이는 기법인 앙상블 기법이라 볼 수도 있다.
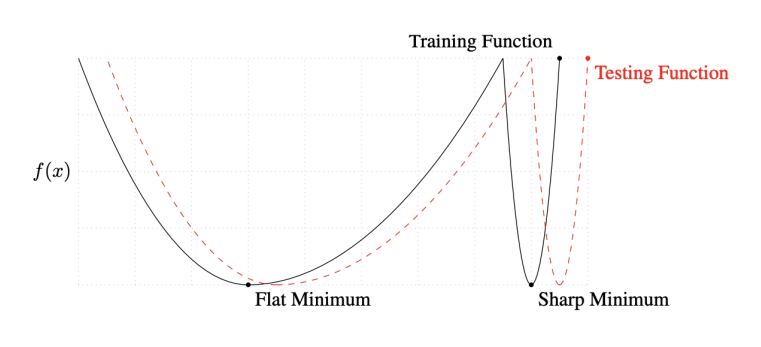
Batch-size Matters
- 큰 배치사이즈는 sharp minimizers로 수렴하는 경향이 있다.
- 작은 배치사이즈는 flat minimizers로 수렴하는 경향이 있다.
- 아래 그림을 보면 Training Function에서의 sharp minimum 지점은 Testing Function에서와 큰 차이 를 보이는 반면, flat minimum 지점은 큰 차이가 없다.
Gradient Descent Methods
Stochastic gradient descent
- Update with the gradient computed from a single sample.
Mini-batch gradient descent
- Update with the gradient computed from a subset of data.
Batch gradient descent
- Update with the gradient computed from the whole data.
Momentum
- 모멘텀(탄력, 가속도, 관성)
- 경사도의 잡음 현상
- 기계 학습은 훈련집합을 이용하여 매개변수의 경사도를 추정하므로 잡음 가능성 높음
- 모멘텀은 경사도에 부드러움(smoothing)을 가하여 잡음 효과 줄임
- 관성(가속도) : 과거에 이동했던 방식을 기억하면서 기존 방향으로 일정 이상 추가 이동함
- 수렴 속도 향상(지역 최저, 안장점에 빠지는 문제 해소)
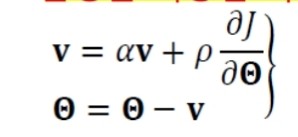
- 속도 벡터 v는 이전 경사도를 누적한 것에 해당
- a의 효과 (관성의 정도)
- a = 0 이면 관성이 적용 안된 이전 경사도 갱신 공식과 동일
- a가 1에 가까울수록 이전 경사도 정보에 큰 가중치를 주는 셈 -> theta가 그리는 궤적이 매끄러움
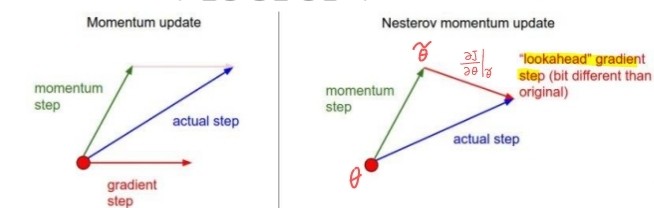
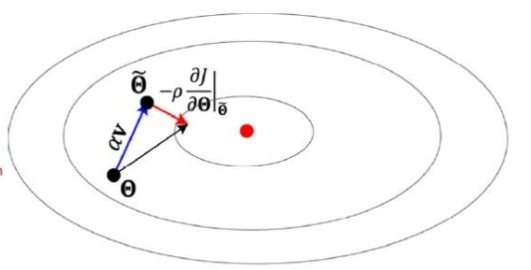
Nesterov accelerated gradient
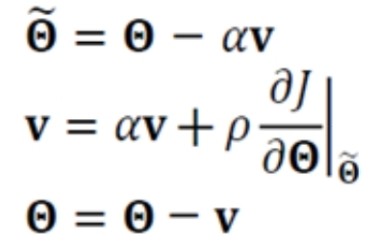
- 현재 v 값으로 다음 이동할 곳 theta' 을 예견한 후, 예견한 곳의 경사도를 사용.
Adagrad
- 기존 경사도 갱신은 모든 매개변수에 같은 크기의 학습률을 사용하는 셈이다.
- 적응적 학습률은 매개변수마다 자신의 상황에 따라 학습률을 조절해 사용한다.
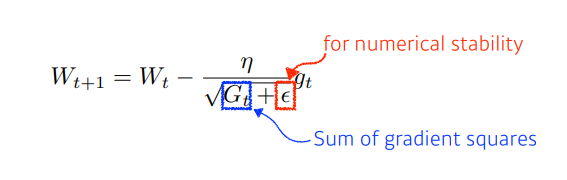
- 는 이전 경사도를 누적한 벡터
- 은 분모가 0이 됨을 방지하는 작은 값.
RMSprop
-
Adagrad의 단점
- 오래된 경사도와 최근 경사도는 같은 비중의 역할
- 가 점점 커져 수렴 방해할 가능성이 있다.
-
RMSprop은 가중 이동 평균(weight moving average) 기법 적용
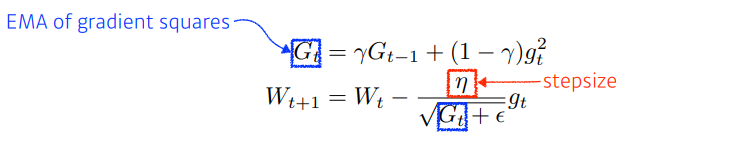
- 가 작을수록 최근 것에 비중을 둠.
Adam
- RMSProp에 관성(momentum)을 추가로 적용한 알고리즘.
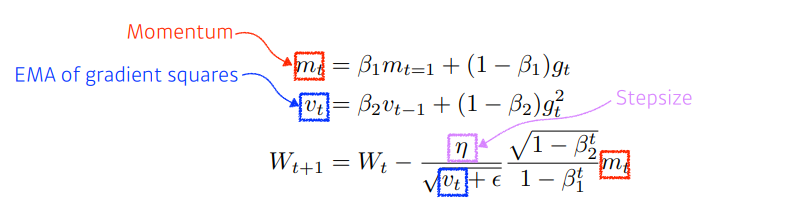
Regularization
- 학습 모델이 훈련집합의 예측을 너무 잘 수행하지 못하도록 방지
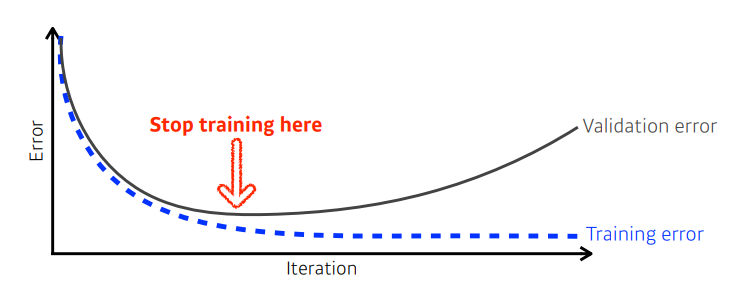
Early stopping
- 일정 시간이 지나면 과잉적합 현상이 나타나고(일반화 능력 저하), 훈련 데이터를 단순히 암기하기 시작.
- Early stopping 규제 기법은 검증집합의 오류가 최저인 접에서 학습을 멈춘다.
Parameter norm penalty
- 가중치 벌칙
- 학습 모델을 단순화 시킴으로서 일반화 성능을 향상 시킴
- 함수공간을 매끄럽게 하여 최적화 개선

- L2 놈을 규제항으로 사용하는 규제 기법을 weight decay라 부른다.
- 이는 최종해를 원점 가까이 당기는 효과(즉, 가중치를 작게 유지) 를 가진다.
Data augmentation
- 데이터 확대
- 과잉적합을 방지하는 가장 확실한 방법은 큰 훈련집합 사용
- 하지만 데이터 수집은 비용이 많이 드는 작업이다.
- Data augmentation은 인위적으로 변형하여 데이터를 확대한다.
- 이동,회전,반전 등을 적용하는데, 숫자 4와 같이 위아래 뒤집기를 하면 원래의 데이터와 아예 달리지기 때문에, 이러한 점은 주의를 할 필요가 있다.
Noise robustness
- 입력데이터 혹은 가중치에 임의의 노이즈를 추가하는 기법.
Dropout
- 완전연결층의 노드 중 일정 비율을 임의 서낵하여 제거하는 기법.
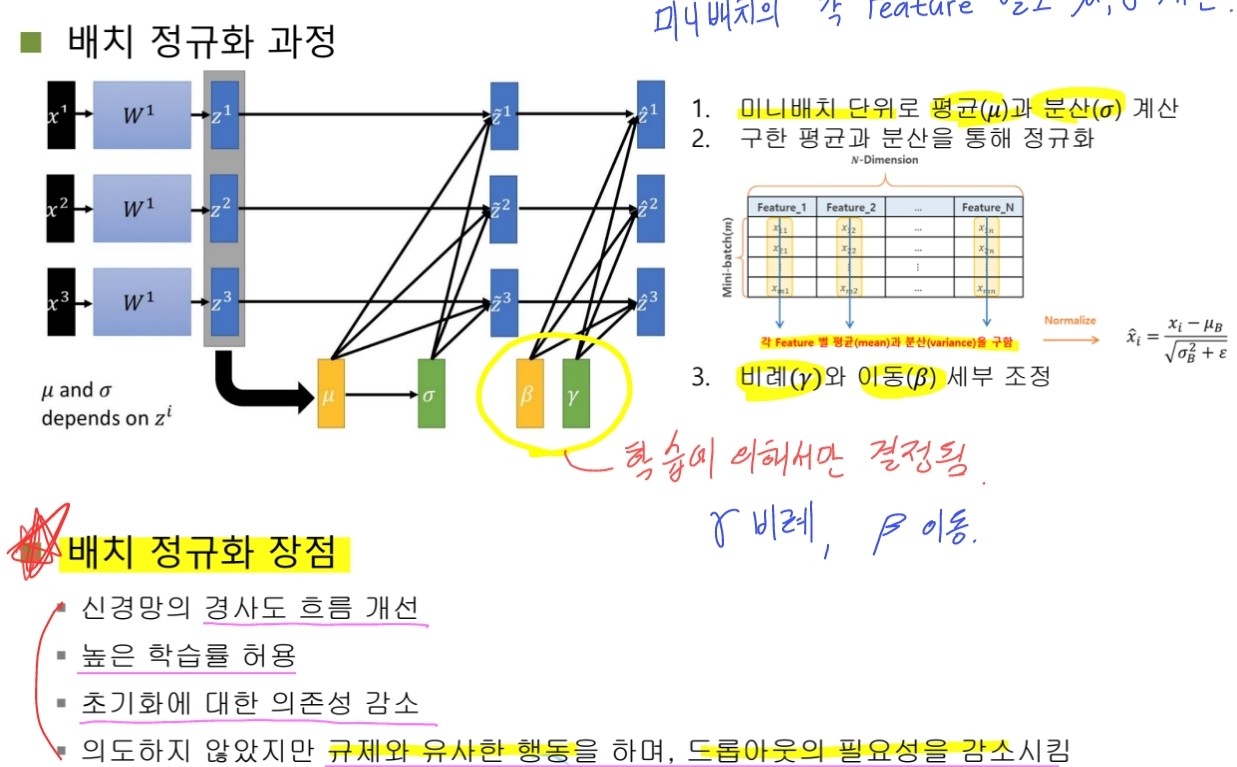
Batch normalization
- 공변량 시프트 현상을 누그러뜨리기 위해 아래 식의 정규화를 층 단위로 적용하는 기법.
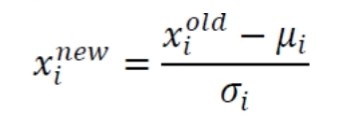
- 정규화를 적용하는 곳이 중요하다.
- 일반적으로 완전연결층 or conv층 이후 또는 활성함수 이전에 적용한다.
- 적용 단위는 미니배치에 적용하는 것이 유리하다.
📌 Convolution은 무엇인가?
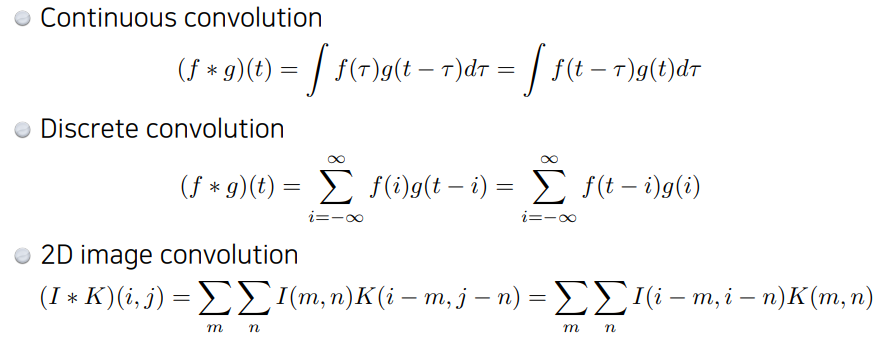
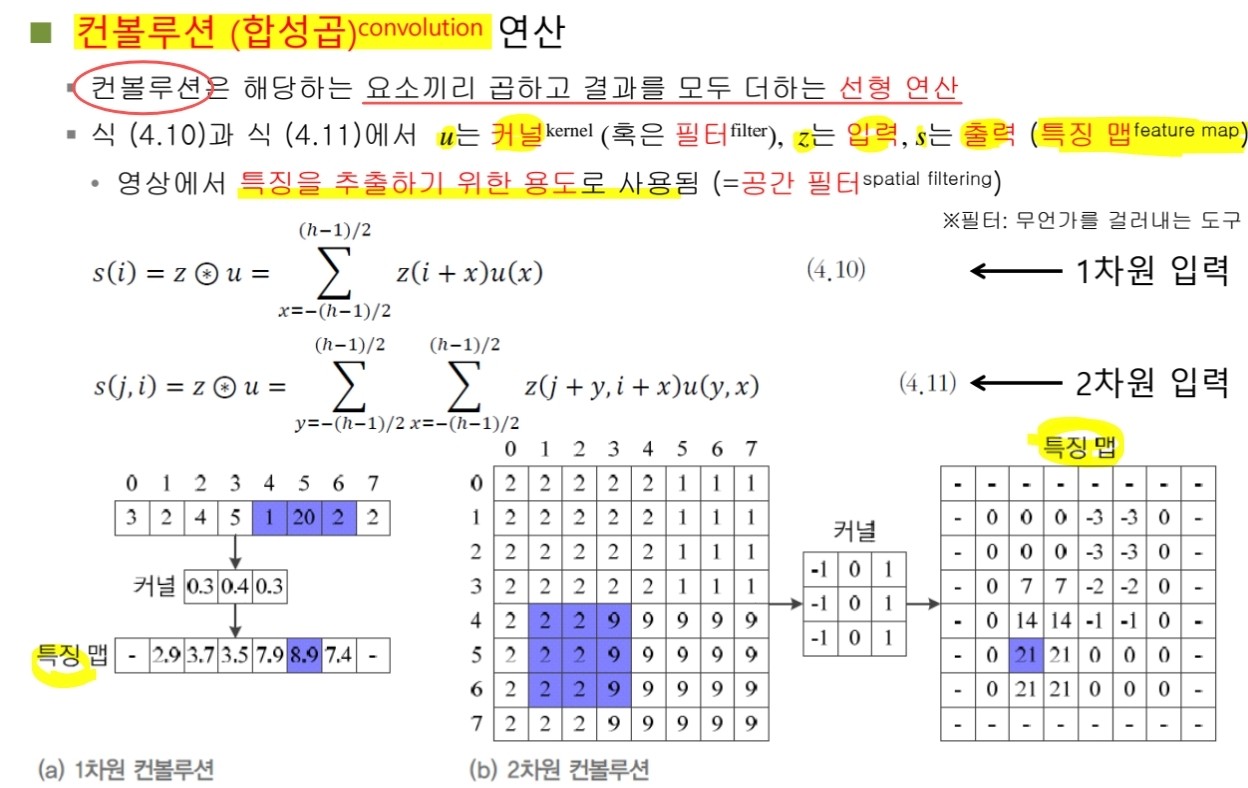
-
컨볼루션 연산은 위 그림과 같이 커널을 입력 이미지에 도장을 찍듯이 슬라이싱하며 적용하고, 각 요소끼리의 곱을 모두 더하는 연산이다.
-
CNN의 완전 연결 신경망과 차별
- [CONV] 학습에 의해 결정된 복수의 커널들에 대응되는 특징들을 추출하는 층
- 각 층의 입출력의 특징형상 유지 (특징맵)
- 영상의 공간 정보를 유지하면서 공간적으로 인접한 정보의 특징을 효과적으로 인식
- 각 커널은 매개변수를 공유함으로써 완전 연결 신경망 대비 학습 매개변수가 매우 적음
- [POOL] 추출된 영상의 특징을 요약하고 강화하는 층
- [CONV] 학습에 의해 결정된 복수의 커널들에 대응되는 특징들을 추출하는 층
RGB Image Convolution
- 현재의 일반적인 이미지는 rgb의 3채널 이미지이다. 그렇다면 이러한 3채널 이미지는 어떻게 convolution 연산을 수행할까? 다음 그림을 참고하자.
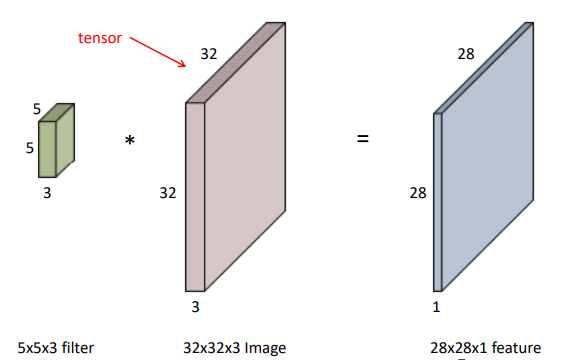
- 위 그림과 같이 커널의 채널수는 이미지의 채널수와 동일하다는 것을 외우자!! 그렇다면 커널의 각 채널별 각 요소들이 이미지에 대응되는 채널의 각 요소들과 곱해져서 모두 더하는 연산을 수행하게 된다.
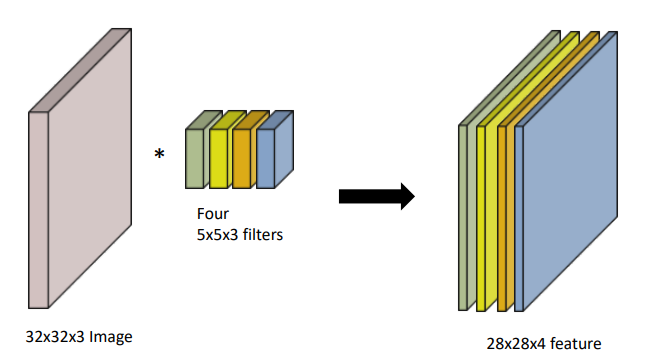
- 그렇다면 위 그림과 같이 여러개의 커널을 가지고 conv연산을 수행하면 어떻게 될까?
그림을 보면 알 수 있듯이 각 커널로 생성된 결과가 커널의 개수만큼 쌓이게 된다.
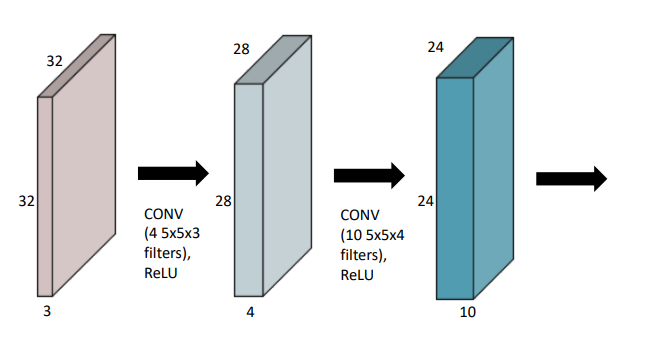
- 즉 cnn에서 conv 연산은 위 그림과 같이 커널을 적용하고, 활성화 함수를 적용한 모듈이 여러 layer로 쌓리게 된다.
Pooling
- 풀링연산은 요약 혹은 평균등의 통계적 대표성을 추출한다.
- 매개변수가 없다.
- 특징 맵의 수를 그대로 유지한다.(크기x)
- 최대 풀링, 평균 풀링 등이 있다.
Padding과 Stride
-
패딩 : 가장자리에 값을 덧대어 영상의 크기가 줄어드는 효과를 방지한다.
-
Stride : 보폭. 지금까지는 모든 화소에 보폭이 1인 커널 적용. 보폭이 k이면 특징 맵이 로 작아진다.
Conv층의 출력 크기와 매개변수 수
- 입력 : W1 x H1 x D1
- K개 F x F 커널, 보폭 S, 덧대기 P
- 출력의 크기 : W2 x H2 x D2
- W2 = ((W1-F+2P) / S ) + 1
- H2 = ((H1-F+2P) / S ) + 1
- D2 = K
- 매개변수의 수 : 커널마다 (F x F x D1)개의 가중치와 1개의 bias를 가진다. 따라서 전체 매개벼수 수는 (F x F x D1) x K + K
- 출력의 크기 : W2 x H2 x D2
📌Modern CNN
-
ImageNet
- 2만 2천여 부류에 대해 부류별로 수백~수만장의 사진을 인터넷에서 수집하여 1500만여 장의 사진을 구축하고 공개 (현재, 부류와 개수가 추가됨)
-
ILSVRC(ImageNet Large Scale Visual Recognition Competition 대회)
- 1000가지 부류에 대해 분류, 검출, 위치 지정 문제: 1순위와 5순위 오류 성능 대결
- 120만 장의 훈련집합, 5만 장의 검증집합, 15만 장의 테스트집합
- 우승: AlexNet (2012) → Clarifi팀 (2013) → GoogLeNet&VGGNet (2014) → ResNet (2015)
AlexNet
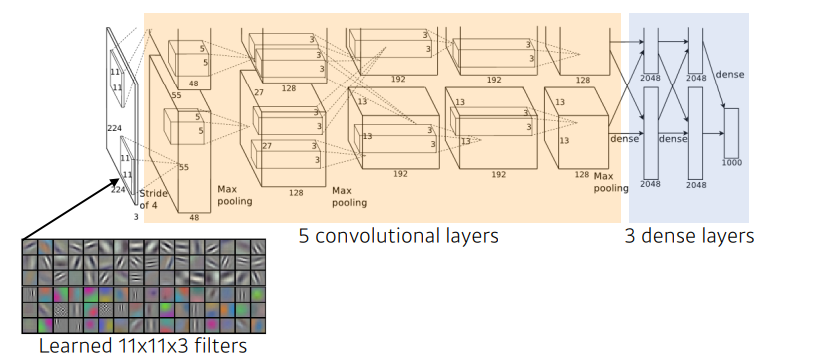
- 구조
- 컨볼루션층 5개와 완전연결fully connected (FC) 층 3개
- 8개 층에 290400-186624-64896-43264-4096-4096-1000개의 노드 배치
- 컨볼루션층은 200만개, FC층은 6500만개 가량의 매개변수
- FC층에 30배 많은 매개변수 → 향후 CNN은 FC층의 매개변수를 줄이는 방향으로 발전
- 당시 GPU의 메모리 크기 제한으로 인해 GPU#1, GPU#2으로 분할하여 학습 수행
- 3번째 컨볼루션 층은 GPU#1과 GPU#2의 결과를 함께 사용 (inter-GPU connections)
- 컨볼루션 층 큰 보폭으로 다운샘플링
- AlexNet이 학습에 성공한 요인
- 외적 요인
- ImageNet이라는 대규모 사진 데이터
- GPU를 사용한 병렬처리
- 내적 요인
- 활성함수로 ReLU 사용
- 지역 반응 정규화local response normalization 기법 적용
- ReLU 활성화 규제
- 1번째, 3번째 최대 풀링 전 적용
- 과잉적합 방지하는 여러 규제 기법 적용
- 데이터 확대 (잘라내기cropping와 반전mirroring으로 2048배로 확대)
- 드롭아웃dropout (완전연결층에서 사용)
- 테스트 단계에서 앙상블 적용
- 입력된 영상을 잘라내기와 반전을 통해 증가하고, 증가된 영상들의 예측 평균으로 최종 인식
- 2~3%만큼 오류율 감소 효과
- 외적 요인
VGGNet
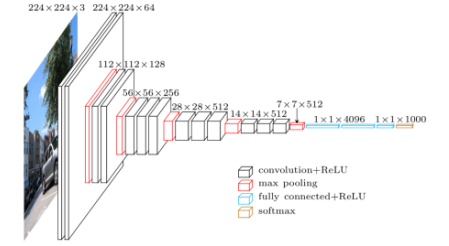
-
VGGNet의 핵심 아이디어
-
3x3의 작은 커널을 사용
-
신경망을 더욱 깊게 만듦 (신경망의 깊이가 어떤 영향을 주는지 확인)
-
컨볼루션층 8~16개를 두어 AlexNet의 5개에 비해 2~3배 깊어짐
-
작은 커널의 이점
- GoogLeNet의 인셉션 모듈처럼 이후 깊은 신경망 구조에 영향
- 큰 크기의 커널은 여러 개의 작은 크기 커널로 분해될 수 있음 → 매개변수의 수는 줄어들면서 신경망은 깊어지는 효과
- 예) 5x5 커널을 2층의 3x3 커널로 분해하여 구현
-

GoogLeNet
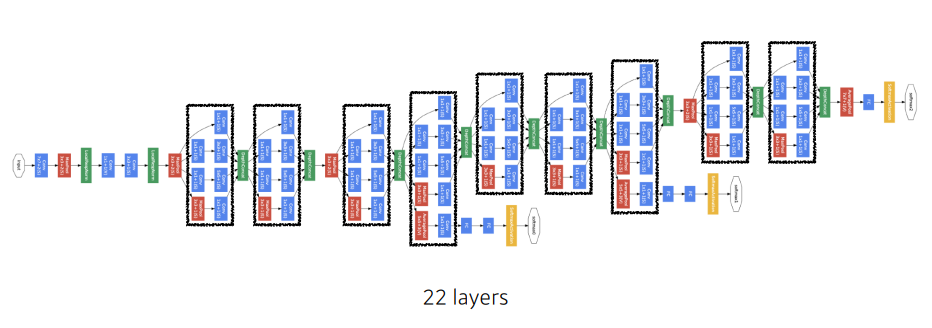
-
GoogLeNet의 핵심은 인셉션 모듈(inception module)
- 수용장의 다양한 특징을 추출하기 위해 NIN의 구조를 확장하여 복수의 병렬적인 컨볼루션 층을 가짐
- [참고] NIN 구조
- 기존 컨볼루션 연산을 MLPConv 연산으로 대체
- 커널 대신 비선형 함수를 활성함수로 포함하는 MLP를 사용하여 특징 추출 유리함
- 신경망의 미소 신경망(micro neural network)가 주어진 수용장의 특징을 추상화 시도
- 전역 평균 풀링(global average pooling) 사용
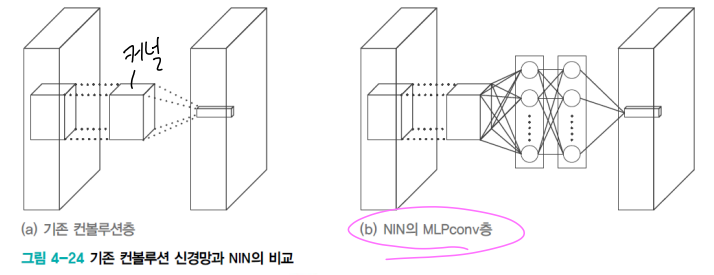
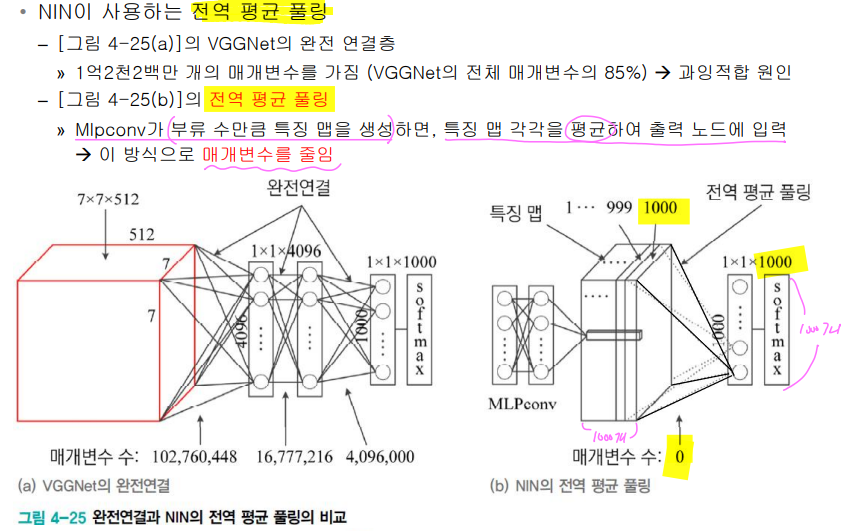
-
GoogLeNet은 NIN 개념을 확장한 신경망
- 인셉션 모듈
- 마이크로 네트워크로 Mlpconv 대신 네 종류의 컨볼루션 연산 사용 → 다양한 특징 추출
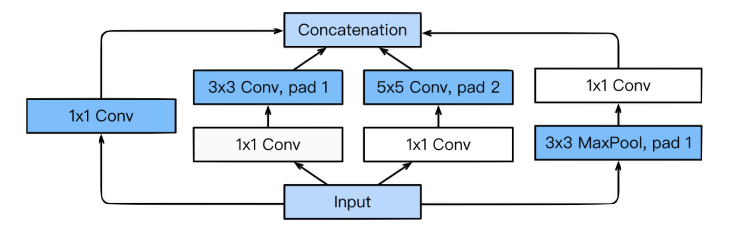
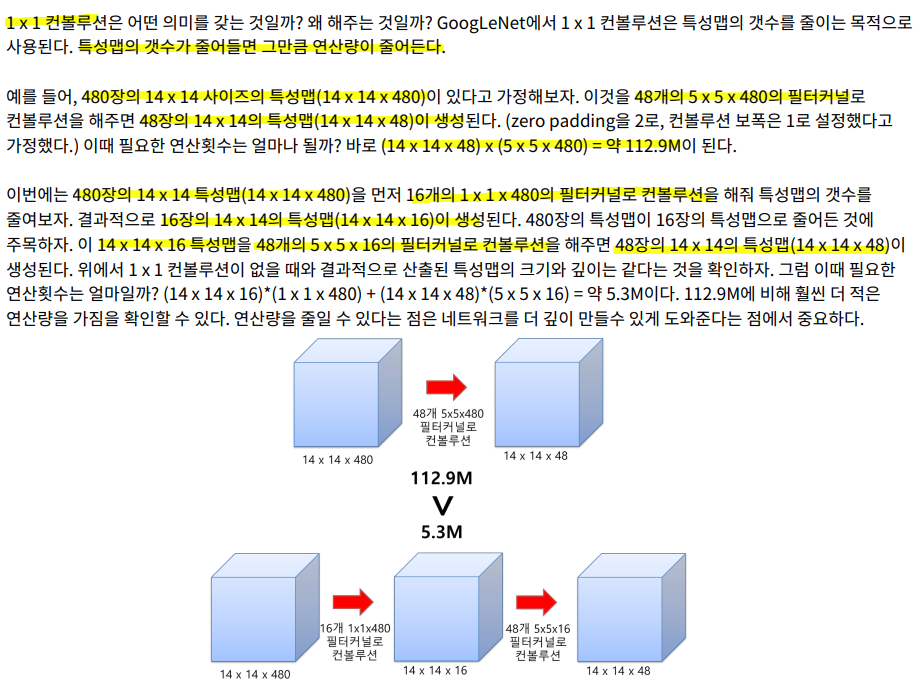
- 1x1 컨볼루션을 사용하여 차원 축소(dimension reduction)
- 매개변수의 수 (=특징 맵의 수)를 줄임 + 깊은 신경망
- 3x3, 5x5 같은 다양한 크기의 컨볼루션을 통해서 다양한 특징들을 추출
-
1x1 커널
- 차원 통합
- 차원 축소 효과
- c2>c3: 차원 축소 (연산량 감소)
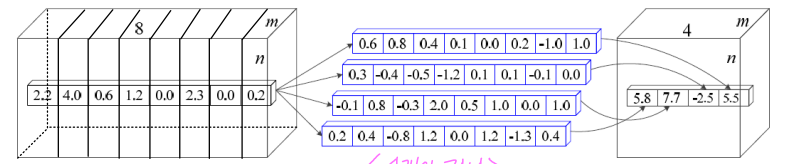
- 위 그림에서 mxn의 특징 맵 8개에 1x1 커널을 4개 적용 → mxn의 특징 맵 4개 출력
- 즉, 8xmxn 텐서에 8x1x1 커널을 4개 적용하여 4xmxn 텐서를 출력하는 셈
- [1x1 컨볼루션 참고]
ResNet
- 잔류(잔차) 학습(residual learning)이라는 개념을 이용하여 성능 저하를 피하면서 층 수를 대폭 늘림.
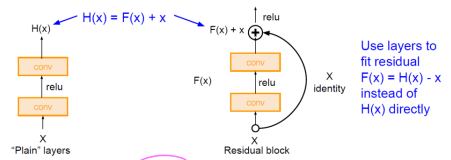
-
지름길 연결을 두는 이유는?
- 깊은 신경망도 최적화가 가능해짐
- 단순한 학습의 관점의 변화를 통한 신경망 구조 변화
- 단순 구조의 변경으로 매개변수 수에 영향이 없음
- 덧셈 연산만 증가하므로 전체 연산량 증가도 미비함
- 깊어진 신경망으로 인해 정확도 개선 가능함
- 경사 소멸 문제 해결
- 깊은 신경망도 최적화가 가능해짐
-
3x3 커널 사용
-
잔류 학습 사용
-
전역 평균 풀링 사용 (FC 층 제거)
-
배치 정규화(batch normalization) 적용 (드롭아웃 적용 불필요)
📌Computer Vision Applications
Semantic Segmentation
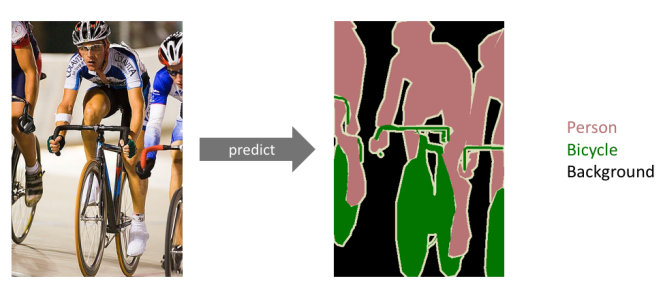
전체 이미지를 하나의 레이블로 분류하는 Classification,
한 단계 나아가 이미지 속 여러 물체의 위치를 찾아 Boxing 하는 Dectection,
그리고 한 단계 더 나아가 이미지를 의미 있는 부분끼리 묶어 분할하는 Segmentation.
즉, Segmentation은 이미지를 픽셀 단위로 구분해 각 픽셀이 어떤 물체의 class인지 분류한다.
Fully Convolutional Network
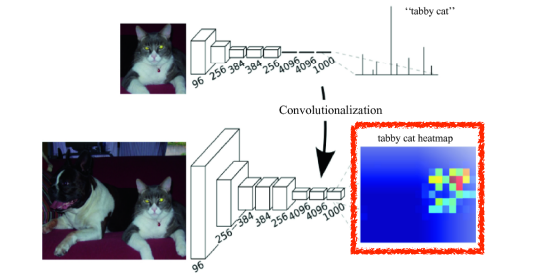
-
위 그림과 같이 classifiacation 작업에서는 물체의 위치 정보는 없고, 단지 확률 값만 가지게 된다.
-
이렇게 이미지 내에 존재하는 물체에 대한 공간 정보는 FC layer에서 사라진다.
- 왜냐하면 FC layer은 모든 노드들이 연결되어 버리기 때문이다.
-
이를 해결할 수 있는 방법은 FC Layer를 Convolutional Layer로 변환하는 Convolutionalization이다. 정확하게는 1×1 Convolutional Layer로 변환하는데 이를 통해 Input 이미지의 위치 정보를 끝까지 유지할 수 있다.
-
Convolutionalization의 문제점 : Convolutional Layer를 거치면서 Downsampling됨에 따라 feature map의 크기가 줄고 두께는 점점 두꺼워진다는 것.
- 원본 이미지에 대해 Segmentation을 수행해야 하는데 이처럼 Output 이미지의 크기가 줄어들어 정보가 소실되면 이는 불가능하다.
- 따라서 해상도를 원본 이미지에 가깝게 올려주고, 원본 이미지 크기에 가까운 Dense Map으로 바꿔주는 작업이 필요 ---> Upsampling
Deconvolution
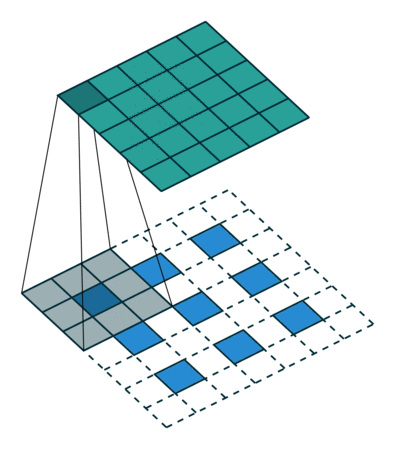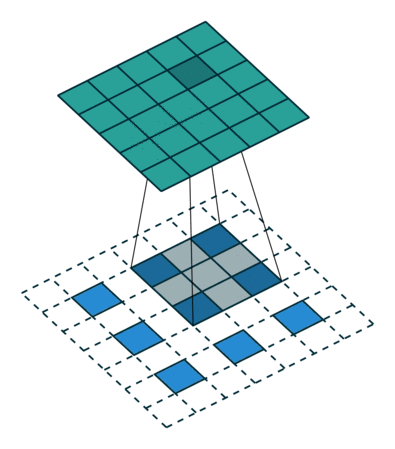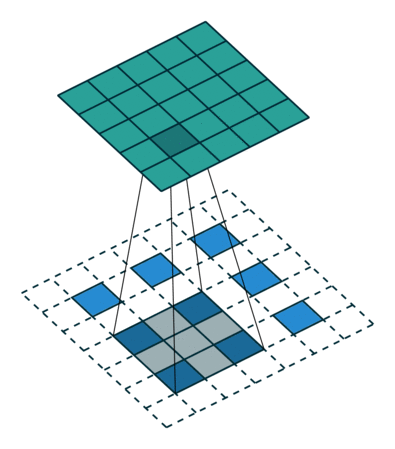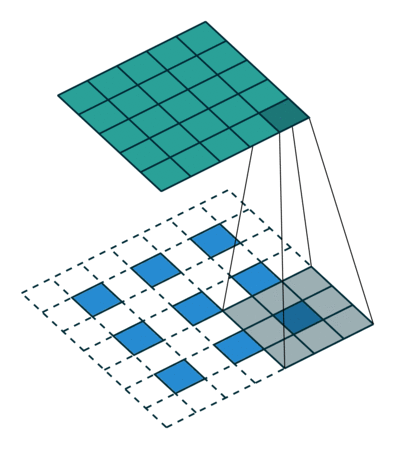
- Deconvolution은 아래와 같은 방식으로 동작한다.
- 각각의 픽셀 주위에 zero-padding을 추가한다.
- 이렇게 padding이된 것에 convolution 연산을 한다.
위 그림에서 아래쪽의 파란색 픽셀이 input 초록색이 output이다. 이 파란색 픽셀 주위로 흰색 zero-padding을 수행하고, 회색 filter를 통해 convolution 연산을 수행하여 초록색 output을 만들어낸다.
출처: https://3months.tistory.com/209 [Deep Play]
R-CNN
- Selective search라는 고전적인 비젼 방법을 사용하여 입력 영상으로 부터 Region proposals이라고 불리는 물체가 있을 만한 영역을 찾음 (약 2000개 정도의 Region proposals을 제시)
- 각 영역은 같은 사이즈로 변형하여 AlexNet에 입력
- AlexNet의 중간 특징값에 SVM (Support vector machine)을 적용하여 각각의 region
proposal의 클래스를 구분
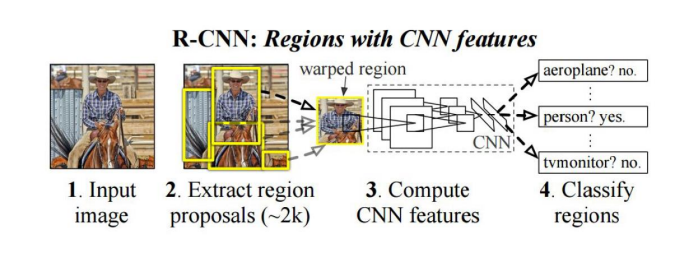
- RCNN의 한계점
- 계산의 비효율성: 2000개의 region proposals을 모두 CNN에 통과시켜야 함 -> 연산시간이 높음
- End to end로 트레이닝이 불가: Region proposals을 뽑는 부분을 뉴럴넷이 아닌 고전적인 Selective search 알고리즘을 사용하기 때문에 AlexNet 부분만 뉴럴넷으로 구현
Faster R-CNN
- RCNN의 단점을 극복
- CNN 백본 네트워크는 전체 영상에 대해서 한 번만 적용 -> 이 후 물체 검출을 위해 백본 네트워크의 출력 특징지도를 재사용
- Region proposals을 찾아내는 부분을 뉴럴넷으로 구현 -> 2단계의 검출 네트워크를 한번에 end to end로 학습
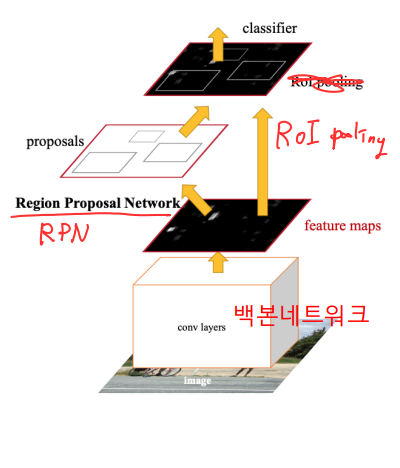
- 검출단계
- Conv layers 백본 네트워크 : 전체 카메라 영상으로 부터 특징지도 추출 (VGG16, VGG19, ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152)
- RPN (Region Proposal Network) : Region proposals (물체 위치)을 찾는 역할, 기존의 Selective search 방법을 대체
- RoI pooling : Region proposals에 해당하는 영역을 CNN특징지도로부터 Crop해 옴
- RefineNet : RoI pooling으로부터 얻은 특징값을 다시 Refine하여 물체의 종류와 정밀한 박스위치를 알아냄
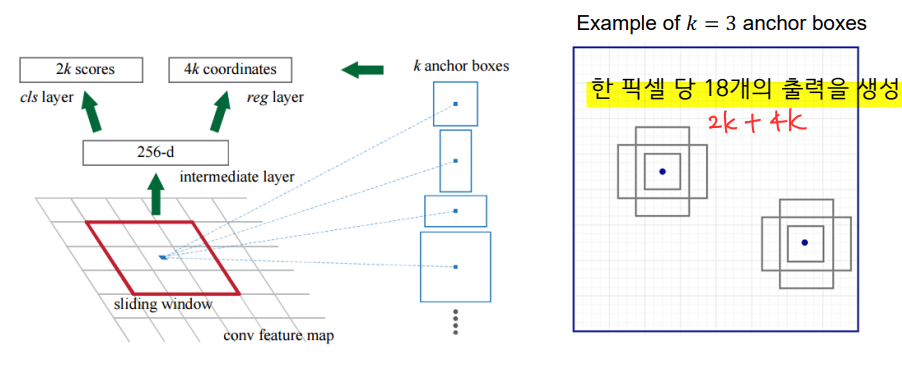
- RPN (Region Proposal Network)
- 백본네트워크에서 출력된 CNN의 특징지도의 각 픽셀에 대해 3x3 커널을 적용
- 3x3 커널 적용 후 Objectness score 2개, 바운딩 박스의 좌표값 4개 (x축 중심, y축 중심, 높이, 너비)를 출력함
- 바운딩 박스의 좌표값은 어떻게 추정하나? 답) 앵커박스를 기준으로 변화량을 추정
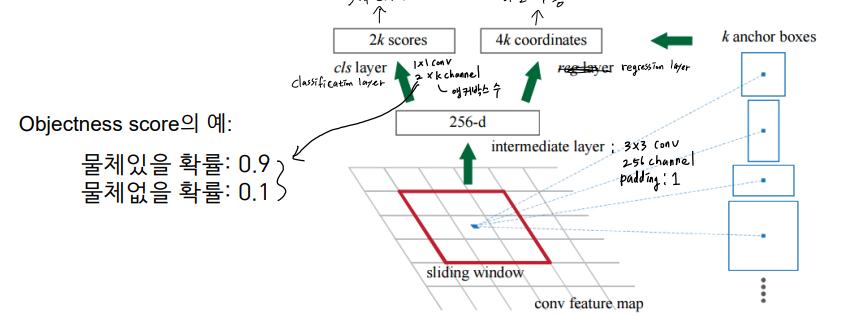
- 앵커박스가 필요한 이유: 절대적인 값을 추정하는 것 보다 앵커박스를 기준으로 상대적인 변화량을 추정하는 것이 더 쉬움
- 다양한 크기의 물체를 검출하기 위해 다른 크기와 aspect ratio를 갖는 하나 이상의 앵커박스를 사용
- 각 픽셀에서 모든 𝑘개의 앵커박스마다 objectness score와 bounding box의 상대좌표를 추정
- RoI (Region of interest) pooling
- CNN 특징지도에서 region proposal의 영역에 해당하는 특징값을 가져옴
- Region proposal에 해당하는 바운딩박스를 특징지도에 투영 (RoI)
- 투영된 박스 안의 영역을 정해진 크기 HxW로 분할
- 분할된 영역의 특징값에 Max pooling을 적용하여 HxW의 정해진 사이즈의 특징값을 만들어냄
📌피어세션
- 사이드프로젝트 논의
- React, Fast API, 협업 스케쥴러 결정.
