본 포스트는 변성윤 마스터님의 강의를 회고할 목적으로 작성하였습니다.
📌 머신러닝 프로젝트 라이프 사이클
📌 Linux & Shell Command
📕 Linux
Linux를 알아야 하는 이유
- 서버에서 자주 사용하는 OS
- Mac, Window도 서버로 활용은 가능하나 유로
- Free, 오픈소스
- 여러 버전이 존재 개인의 버전을 만들 수도 있음
- 안정성, 신뢰성. 유닉스라 Stability, Reliability
- 쉘 커맨드, 쉘 스크립트
CLI
CLI는 Command Line Interface의 약자로, 우리가 터미널 창에서 명령어를 입력하는 것이다. 서버에서 사용하는 운영체제는 대부분 CLI 환경으로 사용한다.
대표적인 Linux 배포판
- Debian : 온라인 커뮤니티에서 제작해 배포
- Ubuntu : 쉽고 편한 설치, 초보자들이 쉽게 접근할 수 있도록 만듬
- Redhat : 레드햇이라는 회사에서 배포한 리눅스
- CentOS : Red Hat이 공개한 버전을 가져와서 브랜드와 로고를 제거하고 배포한 버전
리눅스의 구조
리눅스는 크게 3가지의 구조로 나누어져 있다.
- 커널 Kernel
프로그램의 실행과정에서 가장 핵심적인 연산이 이루어지는 부분이다.
쉘과 관련되어 쉘에서 명령하는 작업을 수행하고 그 결과를 쉘로 보낸다.
- 쉘 Shell
운영체제에서 사용자가 입력하는 명령을 대신 해석해 커널에게 전달하고 실행해주는 프로그램이다.
쉘은 사용자가 입력한 문자열을 해석하고 해당하는 명령어를 찾아서 커널에 작업을 요청한다.
Mac OS의 bash, csh 등이 있다.
- 응용프로그램 Application
리눅스는 개발도구, 문서 편집도구, 네트워크 관련 도구 등 매우 다양한 응용프로그램을 제공한다.
📕Shell Command
쉘의 종류
- sh : 최초의 셀
- bash : Linux 표준 쉘
- zsh : Mac 카탈리나 OS 기본 쉘
쉘을 사용하는 경우
- 서버에서 접속해서 사용하는 경우
- crontab 등 Linux의 내장 기능을 활용하느 ㄴ경우
- 데이터 전처리를 하기 위해 쉘 커맨드를 사용
- *Docker를 사용하는 경우
- 수백대의 서버를 관리하는 경우
- Jupyter Notebook의 Cell에서 앞에 !를 붙이면 쉘 커맨드가 사용됨
- Test Code 실행
- 배포 파이프라인 실행
기본 쉘 커맨드
-
man: 쉘 커맨드의 매뉴얼 문서를 보고 싶은 경우. ex)man python종료 ::q -
mkdir: 폴더 생성하기 ex)mkdir linux-test -
ls: 현재 접근한 폴더의 폴더, 파일 확인.-
ls뒤에 아무것도 작성하지 않으면 현재 폴더 기준으로 실행 -
폴더를 작성하면 폴더 기준에서 실행
-
옵션
-
-a :
.으로 시작하는 파일, 폴더를 포함해 전체 파일 출력 -
-l : 퍼미션, 소유자, 만든 날짜, 용량까지 출력
-
-h : 용량을 사람이 읽기 쉽도록 GB, MB 등으로 표현.
-l과 같이 자주 사용. -
예 :
ls ~,ls -al,ls -lh
-
-
-
pwd: 현재 폴더 경로를 절대 경로로 보여줌 -
cd: 폴더 변경하기, 폴더로 이동하기.cd linux-test-
cd ~: 홈 디렉토리로 이동 -
cd /: 루트 디렉토리로 이동 -
cd ..: 상위 디렉토리로 이동
-
-
echo: Python의 print 처럼 터미널에 텍스트 출력.echo "hi"echo `쉘 커맨드` : 쉘 커맨드의 결과를 출력. `는 1 왼쪽에 있는 backtick
-
vi: vim 편집기로 파일 생성. INSERT 모드에서만 수정할 수 있음.vi test.sh입력.
(새로운 창이 뜨면) i를 눌러서 INSERT 모드로 변경
그 후echo "hi"작성
ESC를 누른 후:wq(저장하고 나가기, write and quit)
or
ESC를 누른 후:wq!(강제로 저장하고 나가기)
or
ESC를 누른 후:q(그냥 나가기)
-
vi편집기의 Mode-
Command Mode :
vi실행시 기본 Mode. 방향키를 통해 커서를 이동할 수 있음-
i : INSERT 모드로 변경
-
x : 커서가 위치한 곳의 글자 1개 삭제(5x : 문자 5개 삭제)
-
yy : 현재 줄을 복사
-
p : 현재 커서가 있는 줄 바로 아래에 붙여넣기
-
-
Insert Mode : 파일을 수정할 수 있는 Mode. 만약 Command Mode로 다시 이동하고 싶다면 ESC 입력
-
Last Line Mode : ESC를 누른 후 콜론(:)을 누루면 나오는 Mode
-
w : 현재 파일명으로 저장
-
q : vi 종료(저장 x)
-
q! : vi 강제종료
-
wq : 저장한 후 종료
-
/문자 : 문자 탐색. 탐색한 후 n을 누르면 계속 탐색 실행
-
set nu : vi 라인 번호 출력
-
-
-
bash: bash로 쉘 스크립트 실행.bash test.sh -
sudo: 관리자 권한으로 실행하고 싶은 경우 커맨으 앞에sudo를 붙임. 즉, 치고 권환을 가진 슈퍼 유저로 프로그램을 실행 -
cp: 파일 또는 폴더 복사하기.cp test.sh test2.sh-
-r: 디렉토리를 복사할 때 디렉토리 안에 파일이 있으면 recursive하게 모두 복사 -
-f: 복사할 때 강제로 실행
-
-
mv: 파일, 폴더 이동하기(또는 이름 바꿀 때도 활용).mv test.sh test3.sh -
cat: 특정 파일 내용 출력.cat test.sh-
여러 파일을 인자로 주면 합쳐저서 출력.
cat test2.sh test3.sh -
파일에 저장하고(overwrite) 싶은 경우.
cat test2.sh test3.sh > new_test.sh -
파일에 추가하고(append) 싶은 경우.
cat test2.sh test3.sh >> new_test.sh
-
-
clear: 터미널 창을 깨끗하게 해줌 -
history: 최근에 입력한 쉘 커맨드 History 출력. History 결과에서 느낌표를 붙이고 숫자 입력시 그 커맨드를 다시 활용할 수 있다. -
find: 파일 및 디렉토리를 검색할 때 사용.find -name "File" -
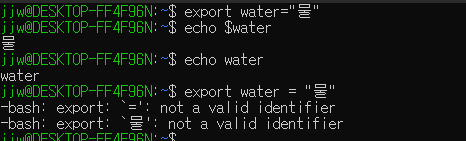
export: export로 환경 변수 설정.-
export로 환경 변수 설정한 경우, 터미널이 꺼지면 사라지게 됨. -
매번 쉘을 실행할 때마다 환경변수를 저장하고 싶으면
.barshrc,.zshrc에 저장하면 된다. ( Linux에서vi ~/.bashrc또는vi ~/.zshrc사용. 그런데 자신이 사용하는 쉘에 따라 다를 수도 있다) -
이후
source ~/.bashrc또는source ~/.zshrc를 하여 Linux 환경 설정을 재로그인하지 않고 즉시 적용.
-
-
alias: 터미널에서alias라고 치면 현재 별칭으로 설정된 것을 볼 수 있다.alias는 기본 명령어를 간단히 줄일 수 있다.alias ll2='ls -lll2를 입력하면ls -l이 동작됨. -
head,tail: 파일의 앞/뒤 n행 출력.head -n 3 test.sh숫자는 몇 번째 줄까지 볼것인지. -
sort: 행 단위 정렬-
-r: 정렬을 내림차순으로 정렬(Default 옵션 : 오름차순) -
-n: Numeric Sort -
다음과 같이 터미널에 입력하여 fruits.txt 파일을 만들어보자
- vi fruits.txt
banana
orange
apple
apple
orange
orange
apple
banana
ESC누르고 :wq로 저장.
- vi fruits.txt
-
이후
cat fruits.txt | sort와cat fruits.txt | sort -r을 입력하여 결과를 출력해보자.|는 Pipe 라고 뒤에서 설명할 개념이다.
-
-
uniq: 중복된 행이 연속으로 있는 경우 중복 제거.sort와 같이 자주 사용-
-c: 중복 행의 개수 출력 -
예 :
cat fruits.txt | uniq,cat fruits.txt | sort | uniq,
cat fruits.txt | uniq | wc -l,cat fruits.txt | sort | uniq | wc -l -
wc는 해당 파일의 단어 수를 세준다.-
-c: 문자수 -
-m: 캐릭터 수 -
-l: 라인 수 -
-w: 단어 수 -
-L: 가장 긴 문장의 길이
-
-
-
grep: 파일에 주어진 패턴 목록과 매칭되는 라인 검색.grep 옵션 패턴 파일명-
옵션
-
-i: Insensitively하게, 대소문자 구분 없이 찾기 -
-w: 정확히 그 단어만 찾기 -
-v: 특정 패턴 제외한 결과 출력 -
-E: 정규 표현식 사용
-
-
정규 표현식 패턴
-
^단어 : 단어로 시작하는 것 찾기
-
단어$ : 단어로 끝나느 것 찾기
-
.: 하나의 문자 매칭
-
-
-
cut: 파일에서 특정 필드 추출-
-f: 잘라낼 필드 지정 -
-d: 필드를 구분하는 구분자. (Default는\t) -
다음과 같이 cut_file을 만들어 보자.
- vi cut_file
root:x:0:0:root:/root:bin/bash
bin:x:1:1:bin:bin:/sbin:nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
ESC 누르고 :wq
- vi cut_file
-
cat cut_file | cut -d : -f 1,71 번째, 7 번째 값을 가져옴.
-
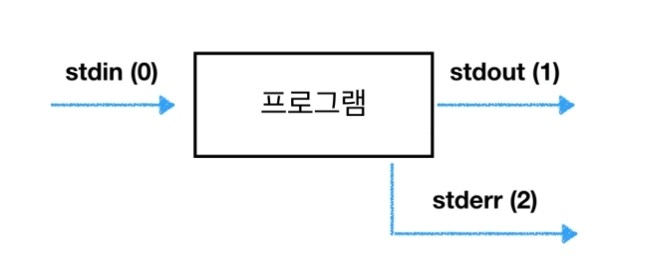
표준 스트림(Stream)
Unix에서 동작하는 프로그램은 커맨드 실행시 3개의 Stream이 생성.
-
stdin : 0으로 표현, 입력(비밀번호, 커맨드 등)
-
stdout : 1로 표현, 출력 값(터미널에 나오는 값)
-
stderr : 2로 표현, 디버깅 정보나 에러 출력
Redirection & Pipe
-
Redirection : 프로그램의 출력(stdout)을 다른 파일이나 스트림으로 전달
-
>: 덮어쓰기(overwrite) 파일이 없으면 생성하고 저장 -
>>: 맨 아래에 추가하기(append) -
echo "hi" > test3.sh
echo "hello" > test3.sh
cat test3.sh
-
-
Pipe : 프로그램의 출력(stdout)을 다른 프로그램의 입력으로 사용하고 싶은 경우.
|-
A의 Output을 B의 Input으로 사용(다양한 커맨드를 조합)
-
현재 폴더에 있는 파일명 중 vi가 들어간 단어를 찾고 싶은 경우
-
ls | grep "vi" -
위 결과를 다시 output.txt에 저장하고 싶다?
ls | grep "vi" > output.txt
-
-
서버에서 자주 사용하는 쉘 커맨드
-
ps: 현재 실행되고 있는 프로세스 출력하기-
-e: 모든 프로세스 -
-f: Full Format으로 자세히 보여줌
-
-
curl: Command Line 기반의 Data transfer 커맨드. Request를 테스트할 수 있는 명령어- 웹 서버를 작성한 후 요청이 제대로 실행되는지 확인할 수 있음
-
df: 현재 사용 중인 디스크 용량 확인-h: 사람이 읽기 쉬운 형태로 출력
-
scp: SSH를 이용해 네트워크로 연결된 호스트 간 파일을 주고 받는 명령어-
-r: 재귀적으로 복사 -
-P: ssh 포트 지정 -
-i: SSH 설정을 활용하여 실행 -
local remote
scp local_path user@ip:remote_directory
-
remote local
scp user@ip:remote_directory local_path
-
remote remote
scp user@ip:remote_directory user2@ip:remote_directory
-
-
nohup: 터미널 종료 후에도 계속 작업이 유지하도록 실행(백그라운드 실행)- nohup으로 실행될 파일은 Permission이 755여야함.
-
chmod: 파일의 권한을 변경하는 경우 사용. 유닉스에서 파일이나 디렉토리의 시스템 모드를 변경함
쉘 스크립트
.sh 파일을 생성하고, 그 안에 쉘 커맨드를 추가.
파이썬처럼 if, while, case 문이 존재하며 작성시 bash name.sh로 실행 가능
📌 Docker
📕 Docker 소개
가상화란?
개발할 때, 서비스 운영에 사용하는 서버에 직접 들어가서 개발하지 않습니다.
Local 환경에서 개발하고, 개발을 완료하면 Staging서버, Production 서버에 배포하는 형식입니다.
개발을 진행한 Local 환경과 Production 서버 환경이 다를 수도 있고(Local은 Windows, Production은 Linux), 서버 환경이 같지만 올바르게 작동하지 않을 수도 있기 때문(환경변수의 차이)입니다. 그래서 다양한 설정을 README 등에 기록하기도 하지만 매번 이런 작업을 해야 하는 과정이 귀찮습니다.
이러한 부분에서 "서버 환경까지도 모두 한번에 소프트웨어화 할 수 없을까?" 라는 고민이 생기게 되었고, 이런 고민을 해결하기 위해 나온 개념이 가상화 입니다.
즉, 가상화란 Research / Production 환경에서 공통적으로 사용하는 일종의 템플릿 입니다. 가상화를 이용하여 특정 소프트웨어 환경을 만들고 Local, Production 서버에서 그대로 활용할 수 있습니다. 이로인해 얻을 수 있는 이점은 다음과 같습니다.
- 개발(Local)과 운영(Production) 서버의 환경 불일치가 해소
- 어느 환경에서나 동일한 환경으로 프로그램을 실행
- 개발 외에 Research도 동일한 환경을 사용
Docker 등장하기 전
Docker가 등장하기 전에는 가상화 기술로 VM(Virtual Machine)을 사용했습니다.
VM은 호스트 머신이라고 하는 실제 물리적인 컴퓨터 위에 OS를 포함한 가상화 소프트웨어를 두는 방식입니다.
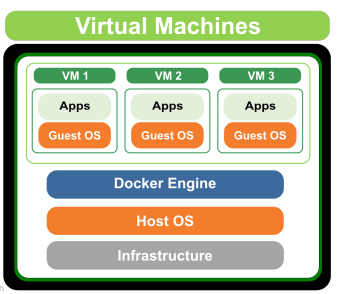
그러나 OS 위에 OS를 하나 더 싱행시키는 점에서 VM은 굉장히 많은 리소스를 사용하게 됩니다. 이런 경우를 "무겁다"라고 표현하죠.
이러한 단점을 해결하기 위해 "Container" 라는 개념이 나왔고, Container는 VM의 무거움을 크게 덜어주면서 가상화를 좀 더 경량화된 프로세스의 개념으로 만든 기술입니다.
Docker 소개
Container 기술을 쉽게 사용할 수 있도록 나온 도구가 바로 "Docker" 입니다.
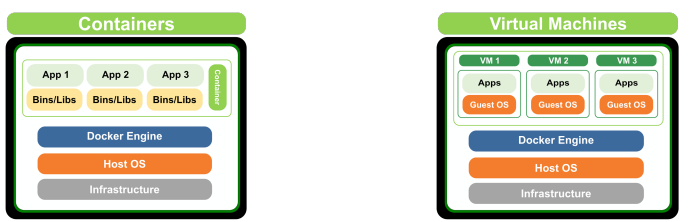
위 사진을 보면, Container는 리눅스/Windows와 Host OS 기반에 docker가 운영되고, Container 별로 각각 process 단위로 bin/libs가 구동됩니다. 반면 Virtual machine은 Hypervisor 위에 full host OS (리눅스/윈도우)가 올라가고 이를 기반으로 각각의 bin/libs가 구동됩니다
Docker를 쉽게 이해하기 위한 예시는 다음과 같습니다.
"PC방에서 특정 게임만 설치디고, 고객이 특정 프로그램을 깔아도 재부팅할 때 항상 PC방에서 저장해둔 형태로 다시 복구"되는 것은 Docker Image로 만들어두고, 재부팅하면 Docker Image의 상태로 실행되는 구조와 유사합니다.
Image는 Container을 실행할 때 사용할 수 있는 "템플릿"이고, Container는 Image를 활용해 실행되는 인스턴스라고 이해하시면 됩니다.
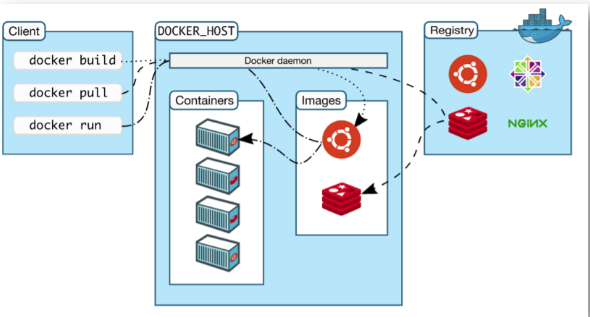
Docker로 할 수 있는일
Docker를 사용하면 다른사림이 만든 소프트웨어를 가져와서 바로 사용할 수 있습니다. MySQL을 Docker로 실행하는것 처럼 말이죠. 이때 다른 사람이 만든 소프트웨어를 Image라 할 수 있습니다.
자신만의 이미지를 만들면 다른 사람에게 공유를 할 수 있습니다. 즉, 원격 저장소에 저장하면 어디에서나 사용할 수 있습니다. 이때 원격 저장소를 Container Registry라고 합니다. 회사에서 서비스를 배포할 때는 원격 저장소에 이미지를 업로드하고, 서버에서 받아서 실행하는 식으로 진행합니다.
📕 Docker 실습하며 배워보기
설치하고 실행하기
도커 공식 홈페이지에서 자신의 운영체제에 맞는 Docker Desktop을 설치합니다. 설치후 터미널에서 docker 커맨드가 동작하는지 확인해봅니다. 정상적으로 실행이 된다면 다음과 같이 출력되는 것을 확인할 수 있습니다.
이제 설치가 완료되었으니 Image를 가져와 보겠습니다. docker pull "이미지 이름:태그"
저는 MySQL Image를 가져오겠습니다. docker pull mysql:8로 mysql 8 버전의 이미지를 다운받습니다.
이후 docker images를 치면 다운받은 이미지를 확인할 수 있습니다.

이제 Docker image에서 container를 실행해보겠습니다.docker run <옵션><이미지이름:태그><실행할 파일> 형식으로 실행합니다. 저는 아래와 같은 코드를 작성했습니다.
docker run --name mysql-tutorial -e MYSQL_ROOT_PASSWORD=1234 -d -p 3306:3306 mysql:8
여기서 --name mysql-tutorial은 컨테이너 이름 입니다. 지정하지 않을 시 랜덤하게 생성됩니다.
-e MYSQL_ROOT_PASSWORD=1234는 환경변수를 설정하는 것 입니다. 사용하는 이미지에 따라 설정이 다릅니다. MySQL은 환경변수를 통해 root 계정의 비밀번호를 설정합니다.
-d는 데몬(백그라운드) 모드 입니다. 컨테이너를 백그라운드 형태로 실행합니다. 이 설정을 하지 않으면 현재 실행하는 셀 위에서 컨테이너가 실행됩니다.
-p 2206:2206 은 포트를 지정합니다. <로컬 호스트 포트:컨테이너 포트> 형태로, 로컬 포트 3306으로 접근 시 컨테이너 포트 3306으로 연결되도록 설정합니다. MySQL은 기본적으로 3306 포트를 통해 통신합니다.
컨테이너를 성공적으로 실행했다면, docker ps 명령어로 확인할 수 있습니다.

docker exec -i "컨테이너 이름(혹은 ID)" /bin/bash 을 입력하면 MySQL이 실행되고 있는지 확인하기 위해 컨테이너에 진입합니다.

mysql -u root -p를 입력하시면 MySQL 프로세스로 들어가게 되고, MySQL 쉘 화면이 보이게 됩니다.

그러면 위와 같이 password를 입력하라고 하는데, 이때 password는 위에서 docker run을 할때 입력한 password 입니다. 그러면 다음과 같이 MySQL 쉘 화면이 나타납니다.
Bash shell에서 exit 또는 Ctrl+D 를 입력하면 컨테이너가 정지됩니다. 또한 Ctrl+P와 Ctrl+Q를 차례대로 입력하면 컨테이너를 정지하지 않고, 컨테이너에서 빠져나옵니다.
docker ps -a 명령어로 작동을 멈춘 컨테이너를 확인할 수 있습니다.( docekr ps는 실행중인 컨테이너 목록만 보여줍니다.)
docker rm "컨테이너 이름(ID)" 명령어는 멈춘 컨테이너를 삭제합니다.
기본 명령어 정리
docker pull “이미지 이름:태그": 필요한 이미지 다운docker images:다운받은 이미지 목록 확인docker run “이미지 이름:태그": 이미지를 기반으로 컨테이너 생성docker ps: 실행중인 컨테이너 목록 확인docker exec -it “컨테이너 이름(ID)" /bin/bash: 컨테이너에 진입docker stop “컨테이너 이름(ID)”: 실행중인 컨테이너를 중지docker rm “컨테이너 이름(ID)”: 중지된 컨테이너 삭제
추가적으로 Dockerhub에서 공개된 모든 이미지를 다운받을 수 있습니다!!
Docker Image 만들기
이제 이미지를 다운받아 사용하는 법을 알았으니 직접 Docker Image를 만들어 보겠습니다!
간단한 FastAPI 애플리케이션을 실행하는 서버를 Docker Image로 생성해보겠습니다.
프로젝트 셋팅 및 FastAPI 코드 작성
먼저 폴더를 하나 만들고 여기에 가상환경 세팅과 FastAPI 패키지를 설치합니다. pip install "fastapi[all]"
그리고 GET /hello 로 요청하면, 메시지를 전달하는 간단한 FastAPI 코드를 아래와 같이 작성합니다.
from fastapi import FastAPI
import uvicorn
app = FastAPI()
@app.get("/hello")
def hello():
return {"message": "world!"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)사용한 라이브러리 명시
pip freeze : 설치한 라이브러리를 모두 보여준다.
pip freeze > requirements.txt 명령어를 치시면 pip로 설치한 라이브러리를 모두 requirements.txt에 저장합니다.
반대로 requirements.txt 가 주어졌을 때, 이 안에 있는 패키지들을 모두 설치하려면 pip install -r requirements.txt 명령어를 입력하면 됩니다.
Dockerfile 작성
Docker Image는 이름을 지정할 수 있지만, 표준 규격으로 Dockerfile이라는 것을 만들어 Docker Image를 빌드하기 위한 정보를 담을 수 있습니다.
즉, Dockerfile은 Docker Image를 생성하기 위한 스크립트(설정파일) 입니다. Docker는 Dockerfile에 나열된 명령문을 차례대로 수행하면서 Docker Image를 생성합니다.
아래 사진은 Dockerfile의 간단한 예시입니다.
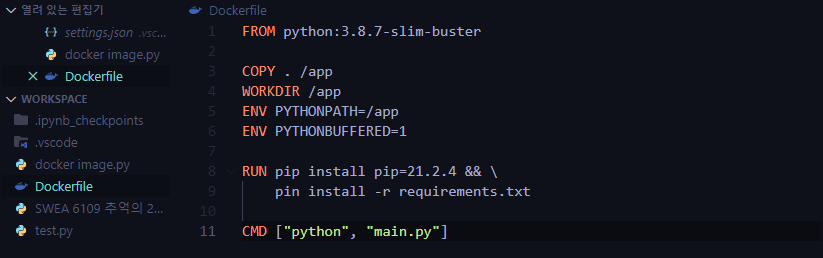
파일 이름을 Dockerfile 이라고 지정해주면 아이콘으로 익숙한 고래? 아이콘이 나옵니다. 그럼 위 코드를 하나씩 분석해보겠습니다!!
-
FROM python:3.8.7-slim-buster-
FROM "이미지 이름:태그"형식. (위에서 docker pull mysql:8 처럼 python 3.8.7-slim-buster 버전의 이미지를 베이스 이미지로 지정하겠다는 의미) -
이미지 빌드에 사용할 베이스 이미지를 지정
-
베이스 이미지는 이미 만들어진 이미지
-
보통 처음부터 만들지 않고, 이미 공개된 이미지를 기반으로 새로운 설정을 추가
-
위 이미지는 Dockerhub에 존재해있다.
-
-
COPY . /app-
COPY "로컬 디렉토리(파일)" "컨테이너 내 디렉토리(파일)"형식 -
컨테이너는 자체적인 파일 시스템과 디렉토리를 가집니다.
-
COPY 명령어는 Dockerfile이 존재하는 경로 기준 로컬 디렉토리를 컨테이너 내부의 디렉토리로 복사합니다.
-
해당 코드는 프로젝트 최상위에 존재하는 모든 파일을 컨테이너 내부 /app 디렉토리로 복사합니다.
-
파일을 컨테이너에서 사용하려면 COPY 명령어로 반드시 복사해야 합니다.
-
-
ENV PYTHONPATH=/app ...-
ENV "환경변수 이름=값"형식 -
컨테이너 내 환경변수를 지정
-
파이썬 애플리케이션의 경우 통상 위 두 값을 지정
-
-
RUN pip install ...-
RUN "실행할 리눅스 명령어 -
컨테이너 내에서 리눅스 명령어를 실행.
-
위의 경우
pip install pip와-r requirements.txt두 명령어를 실행. 한번에 실행할 명령어가 여러 개인 경우%% \로 이어줍니다. -
이전 라인에서 COPY와 WORKDIR이 실행되었기 때문에 컨테이너 내에 requiremetns.txt 가 존재하고, 이를
pip install -r명령어로 실행시킬 수 있습니다.
-
-
CMD ["python", "main.py"]-
`CMD ["실행할 명령어","인자",...]
-
docker run으로 이 이미지를 기반으로 컨테이너를 만들 때, 실행할 명령어입니다.
-
이 이미지는 실행되는 즉시 python main.py를 실행하며 CMD는 띄어쓰기를 사용하지 않습니다.
-
Docker Image Build
docker build "Dockerfile이 위치한 경로" 명령어를 사용하여 이미지를 생성(빌드라고 표현)합니다. 아래 이미지에서 .는 현재 폴더에 Dockerfile이 있음을 의미합니다.
-t "이미지이름:태그" 옵션으로 이미지 이름과 태그 지정을 할 수 있ㅅ븐디ㅏ. 태그는 미지정시 "latest"로 채워집니다.
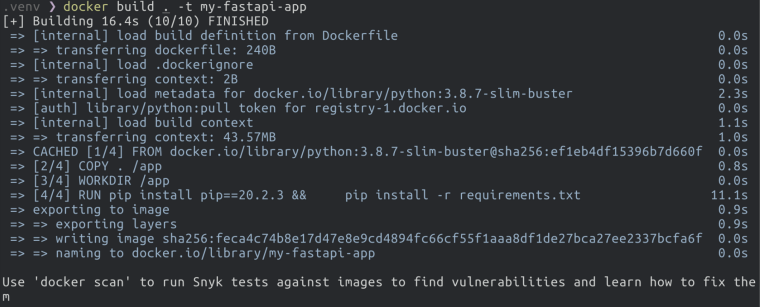
빌드된 이미지 확인
빌드를 마치면 docker images 명령어로 방금 빌드한 이미지를 확인할 수 있습니다.

컨테이너 실행
docker run "이미지이름:태그" 명령어를 사용하여 방금 만든 이미지를 실행합니다. 이때 태그가 "latest"인 경우에는 생략이 가능합니다. fastapi 코드에서 포트를 8000으로 설정해주었기 때문에 host끼리 연결하기 위해 포트는 8000을 입력합니다.
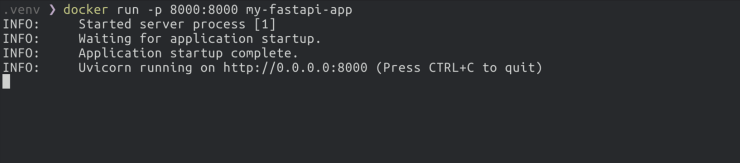
또한 다른 터미널을 열어 curl 명령어로 애플리케이션이 잘 작동하는지 확인할 수 있습니다.
정리
- 파이썬 환경 및 애플리케이션 코드를 작성
- Dockerfile 작성
FROM으로 베이스 이미지를 지정COPY로 로컬 내 디렉토리 및 파일을 컨테이너 내부로 복사WORKDIR로 RUN, CMD 등을 실행할 컨테이너 내 디렉토리 지정RUN으로 애플리케이션 실행에 필요한 여러 리눅스 명령어들을 실행CMD로 이미지 실행 시 바로 실행할 명령어를 지정
docker build “Dockerfile이 위치한 경로” -t “이미지 이름:태그”으로 이미지 빌드docker run “이미지 이름:태그”로 빌드한 이미지를 실행
참고 : 모바일 SW 개발자가 운영하는 블로그
📌 MLflow
📕 MLflow 개념 잡기
MLflow란
MLflow가 없던 시절에 사람들은 각자 자신의 코드를 Jupyter Notebook에 작성하고, 머신러닝 모델 학습시 사용한 Parameter, Metric등을 따로 기록했습니다. 그리고 이러한 기록물들을 github등에 올렸죠. 하지만 개인 컴퓨터, 연구실 서버 등을 사용하다보니 메모리 초과로 오류가 발생하는 등 단점이 있습니다.
이에 MLflow가 해결하려고 했던 Pain Point는 다음과 같습니다.
1. 실험을 추적하기 어렵다
2. 코드를 재현하기 어렵다
3. 모델을 패키징하고 배포하는 방법이 어렵다
4. 모델을 관리하기 위한 중앙 저장소가 없다.
MLflow의 핵심 기능
집에서 요리를 하는 과정을 예로 들어보겠습니다.
- 집에서 요리를 만들 때 레시피를 기록하면 어떤 조합이 좋은지 알 수 있다(파라미터, 모델 구조 등)
- 여러 시행착오를 겪으며 요리한다.(머신러닝 모델링도 많은 실험을 함)
- 수많은 레시피 중에서 제일 맛있었던(성능이 좋았던) 레시피를 사용한다.
- 요리 만드는 과정에서 생기는 부산물을 저장한다.(모델 Artifact, 이미지 등)
- 떡볶이(모델)는 다양한 종류가 있으므로 언제 만든 떡볶이인지(=모델 생성일), 얼마나 맛있었는지(모델 성능), 유동기한 등(모델 메타 정보)을 기록해둘 수 있다.
- 이제 기록한 정보에서 가장 잘 팔릴만한 떡볶이 종류를 판매한다.(여러 모델 운영)
대충 감이 오시죠? 즉 MLflow의 핵심 기능은 다음과 같습니다.
-
Experiment Management & Tracking
-
머신러닝 관련 "실험"들을 관리하고, 각 실험의 내용들을 기록할 수 있다.
- 예를 들어, 여러 사람이 하나의 MLflow 서버 위에서 각자 자기 실험을 만들고 공유할 수 있다.
-
실험을 정의하고, 실험을 실행할 수 있다. 이 실행은 머신러닝 훈련 코드를 실행한 기록
- 각 실행에 사용한 소스 코드, 하이퍼 파라미터, Metric, 부산물 등을 저장
-
-
Model Registry
-
MLflow로 실행한 머신러닝 모델을 Model Registry(모델 저장소)에 등록할 수 있다
-
모델 저장소에 모델이 저장될 때마다 해당 모델에 버전이 자동으로 올라간다.(Version 1 -> 2 -> 3..)
-
Model Registry에 등록된 모델은 다른 사람들에게 쉽게 공유 가능하고, 쉽게 활용할 수 있다.
-
-
Model Serving
-
Model Registry에 등록한 모델을 REST API 형태의 서버로 Serving 할 수 있다
-
Input = Model의 Input
-
Output = Model의 Output
-
직접 Docker Image 만들지 않아도 생성할 수 있다.
-
MLflow Comonent
-
MLflow Tracking
-
머신러닝 코드 실행, 로깅을 위한 API, UI
-
MLflow Tracking을 사용해 결과를 Local, Server에 기록해 여러 실행과 비교할 수 있다
-
팀에선 다른 사용자의 결과와 비교하며 협업할 수 있다
-
-
MLflow Project
-
머신러닝 프로젝트 코드를 패키징하기 위한 표준
-
Project
-
간단하겐 소스 코드가 저장된 폴더
-
Git Repo 와 비슷한 개념.
-
의존성과 어떻게 실행해야 하는지 저장
-
-
MLflow Tracking API를 사용하면 MLflow는 프로젝트 버전을 모든 파라미터와 자동으로 로깅한다.
-
-
MLflow Model
-
모델은 모델 파일과 코드로 저장
-
다양한 플랫폼에 배포할 수 있는 여러 도구 제공
-
MLflow Tracking API를 사용하면 MLflow는 자동으로 해당 프로젝트에 대한 내용을 사용한다
-
-
MLflow Registry
- MLflow Model의 전체 Lifecycle에서 사용할 수 있는 중앙 모델 저장소
MLflow 실습하며 알아보기
먼저 MLflow를 설치하자. pip install mlflow
처음 MLflow 에서 해야할 것은 Experiment를 생성하는 것입니다.
Experiment(실험) 이란?
-
MLflow에서 제일 먼저 Experiment를 생성
-
하나의 Experiment는 진행하고 있는 머신러닝 프로젝트 단위로 구성
- 예) “개/고양이 이미지 분류 실험” , “택시 수요량 예측 분류 실험”
-
정해진 Metric으로 모델을 평가
- 예) RMSE, MSE, MAE, Accuracy
-
하나의 Experiment는 여러 Run(실행)을 가짐
Experiment를 생성하기 위해선 터미널에 mlflow experiments create --experiment-name my-first-experiment을 입력합니다.
 이후
이후 ls -al을 사용해 폴더 확인을 하면 "mlruns"라는 폴더가 생깁니다. 이 폴더는 실험에 대한 run한 기록을 담고 있습니다.

Experiment 리스트를 확인 하려면? mlflow experiments list

mkdir logistic_regression 으로 폴더를 하나 생성한 후, 아래와 같은 머신러닝 코드를 작성해 두겠습니다.
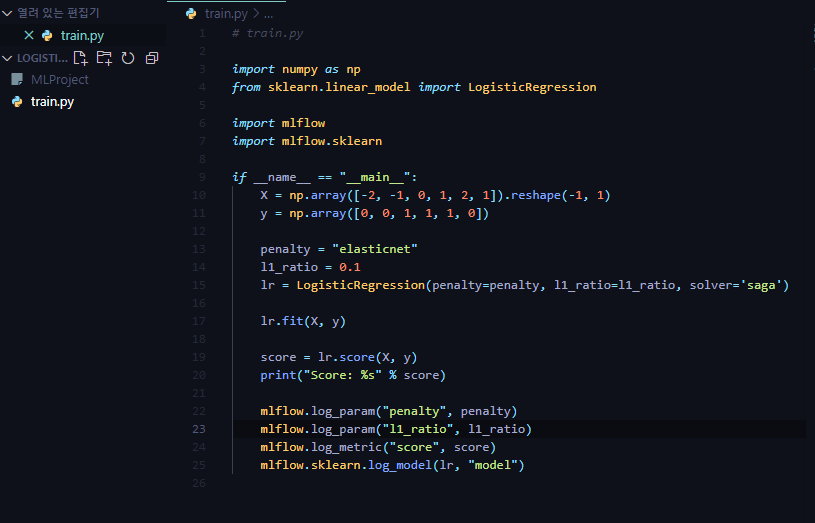
MLProject
- MLflow를 사용한 코드의 프로젝트 메타 정보 저장
- 프로젝트를 어떤 환경에서 어떻게 실행시킬지 정의
- 패키지 모듈의 상단에 위치
즉, MLProject는 MLflow에서 유용하게 관리, 사용하기 위해 정의하는 양식입니다.
vi logistic_regression/MLProject 를 터미널에 작성하여 MLProject를 생성할 수 있습니다. MLProject를 보시면 다음과 같습니다.

-
name- MLProject의 프로젝트 이름이라고 보면 된다.
-
entry_pointsmlflow run으로 실행할 때-e옵션으로 프로젝트 실행에 여러 진입점을 둘 수 있는데, 이 때 사용되는 값이다.- 예를 들면,
mlflow run -e main sklearn_elastic_wine으로main이라는 진입점으로 실행할 수 있다.
-
conda_env- MLProject 를 실행할 때 conda 환경을 만든 뒤 실행할 수 있는데, 이 때 참고할 conda 환경에 대한 파일이름을 값으로 가진다. 여기서는 이 프로젝트 내
conda.yaml에 이 설정 값들이 있다. - conda가 아닌 docker를 사용할 수 있는데, 이 때
docker_env라는 키를 사용하면 된다.
- MLProject 를 실행할 때 conda 환경을 만든 뒤 실행할 수 있는데, 이 때 참고할 conda 환경에 대한 파일이름을 값으로 가진다. 여기서는 이 프로젝트 내
Run
- 하나의 Run은 코드를 1번 실행한 것을 의미
- 보통 Run은 모델 학습 코드를 실행
- 즉, 한번의 코드 실행 = 하나의 Run 생성
- Run을 하면 여러가지 내용이 기록됨
Run에서 로깅하는 것들
- Source : 실행한 Project의 이름
- Version : 실행 Hash
- Start & end time
- Parameters : 모델 파라미터
- Metrics : 모델의 평가 지표, Metric을 시각화할 수 있음
- Tags : 관련된 Tag
- Artifacts : 실행 과정에서 생기는 다양한 파일들(이미지, 모델 Pickle 등)
이제 Run으로 실행해보자!
mlflow run logistic_regression --experiment-name my-first-experiment --no-conda 를 터미널에 입력하자. --no-conda 옵션은 conda 환경으로 돌리고 싶지 않을 시 작성합니다. 결과는 다음과 같습니다.

이제 기록을 확인하기 위해 UI를 실행해 봅시다. UI를 실행하는 방법은 mlflow ui를 입력하면 됩니다.

결과로 출력된 url로 들어가시면 다음과 같은 mlflow ui가 나옵니다!!
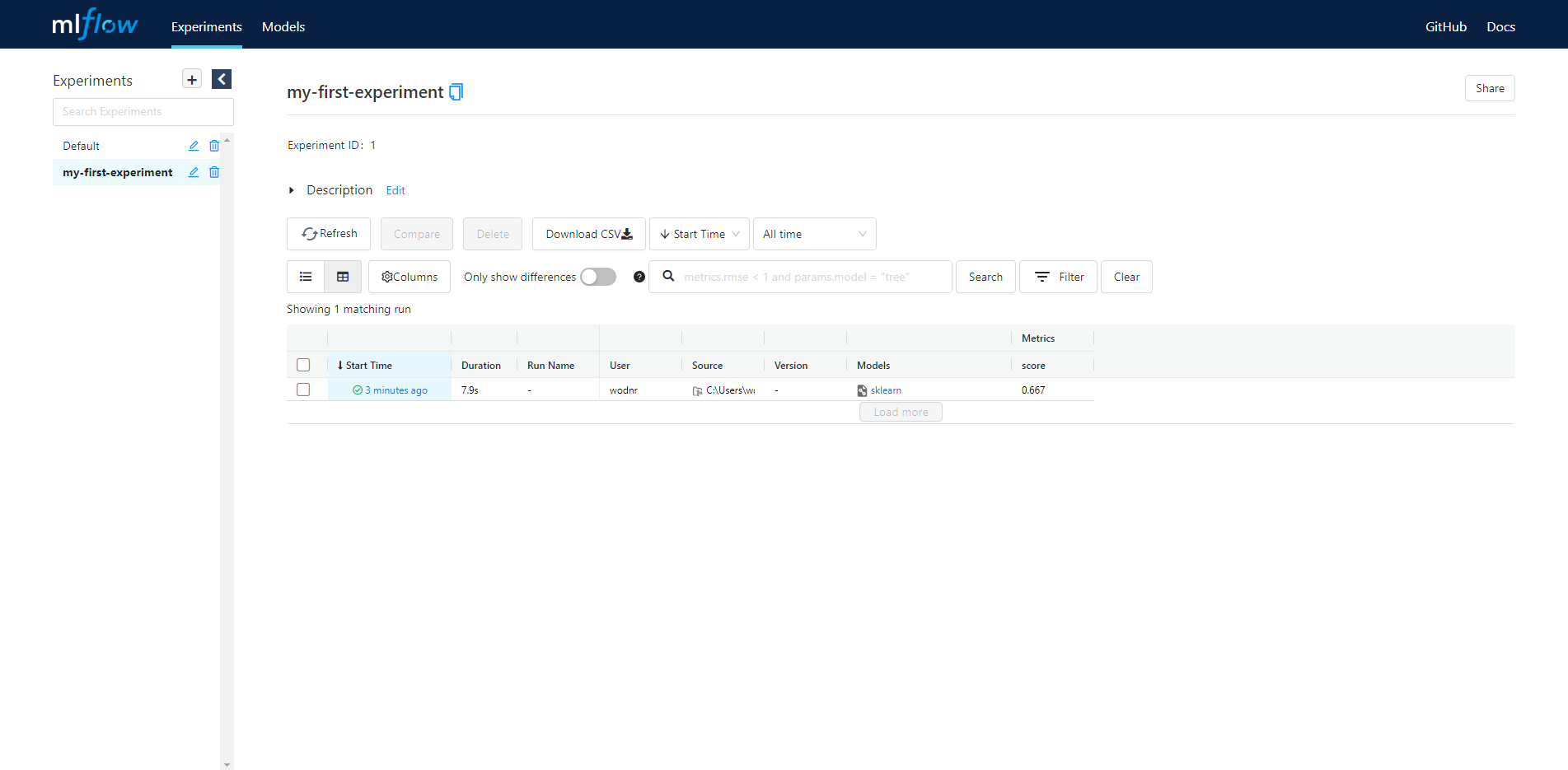
보시면 저희가 만든 Experiments 목록이 왼쪽에 나타나 있고, Experiment ID가 가운데 나타나 있습니다. 그 아래로는 Run 정보가 나타나 있습니다. Run 정보에서 Start Time에 있는 시간을 누르시면 실행한 Run 기록이 나타납니다.
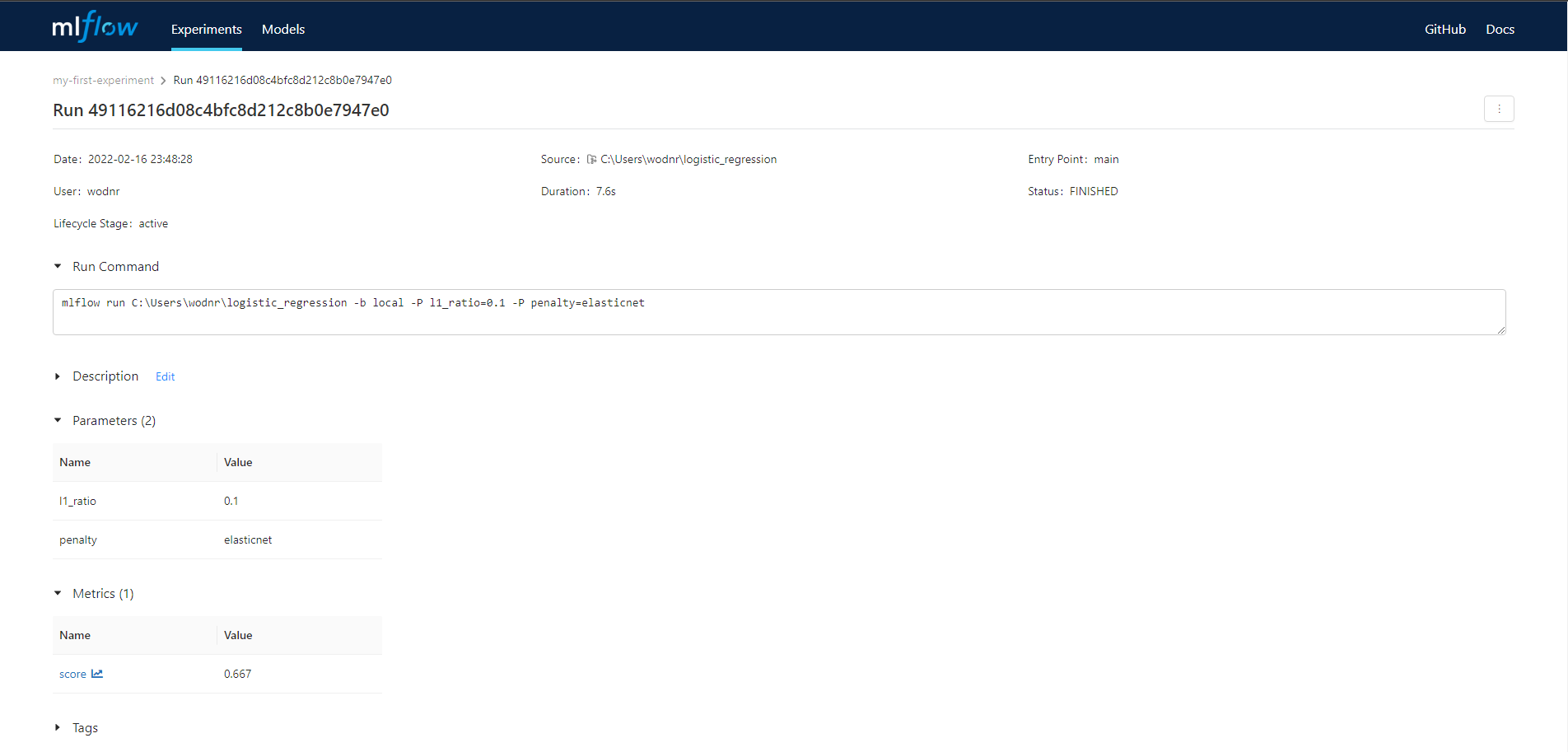
보시면 아시겠지만 Run Command, Duration, Parameter, Metric 등이 보입니다.
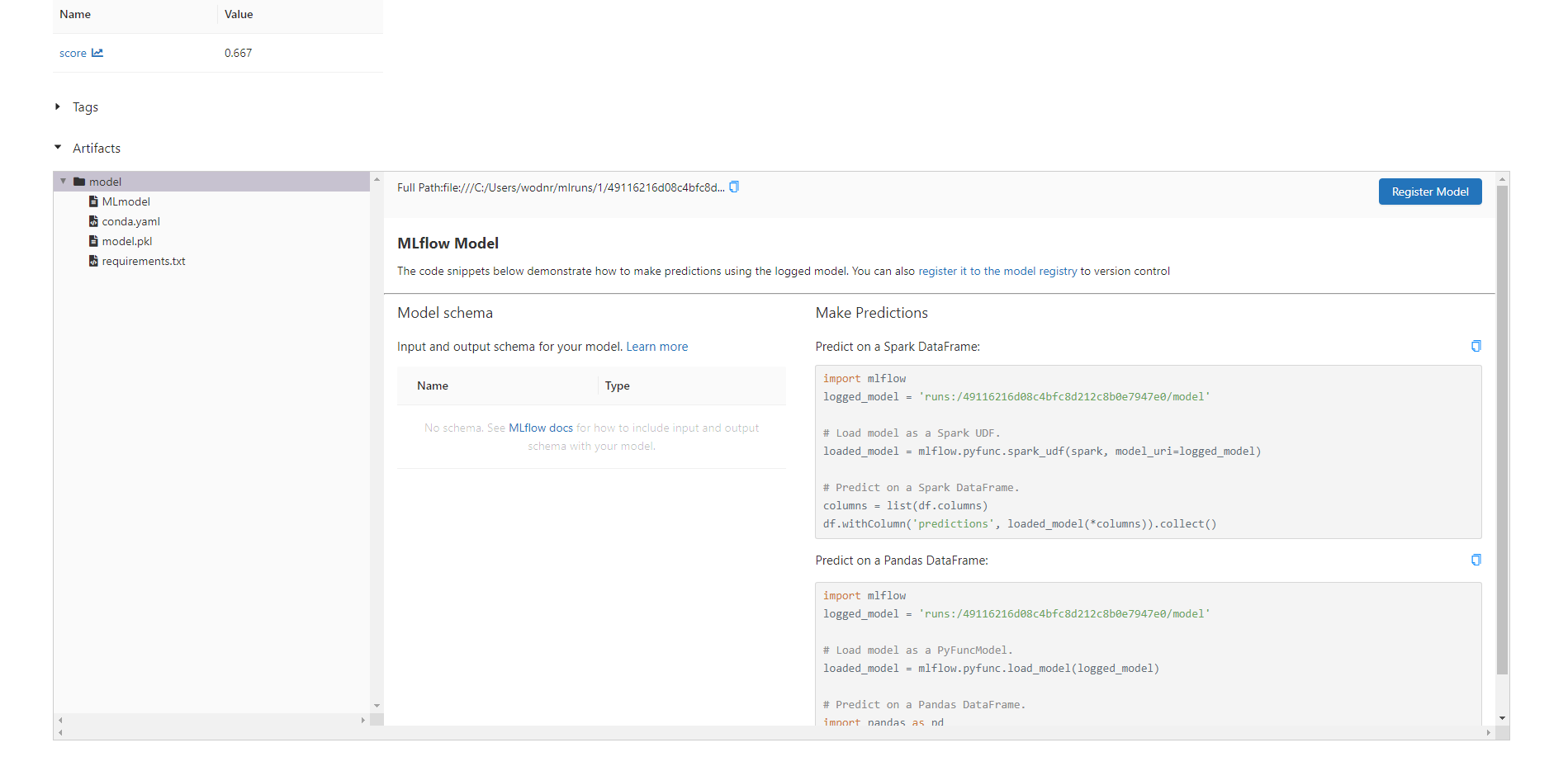
또한 저장된 Artifacts도 확인할 수 있습니다.
MLflow autolog
train.py를 생성할 때 파라미터등을 저장하기 위해 코드 마지막에 mlflow.log_param을 작성한 걸 기억하시죠? 이렇게 일일히 파라미터를 작성하는 방법도 있지만 autolog라는 아주 편리한 기능이 있습니다.
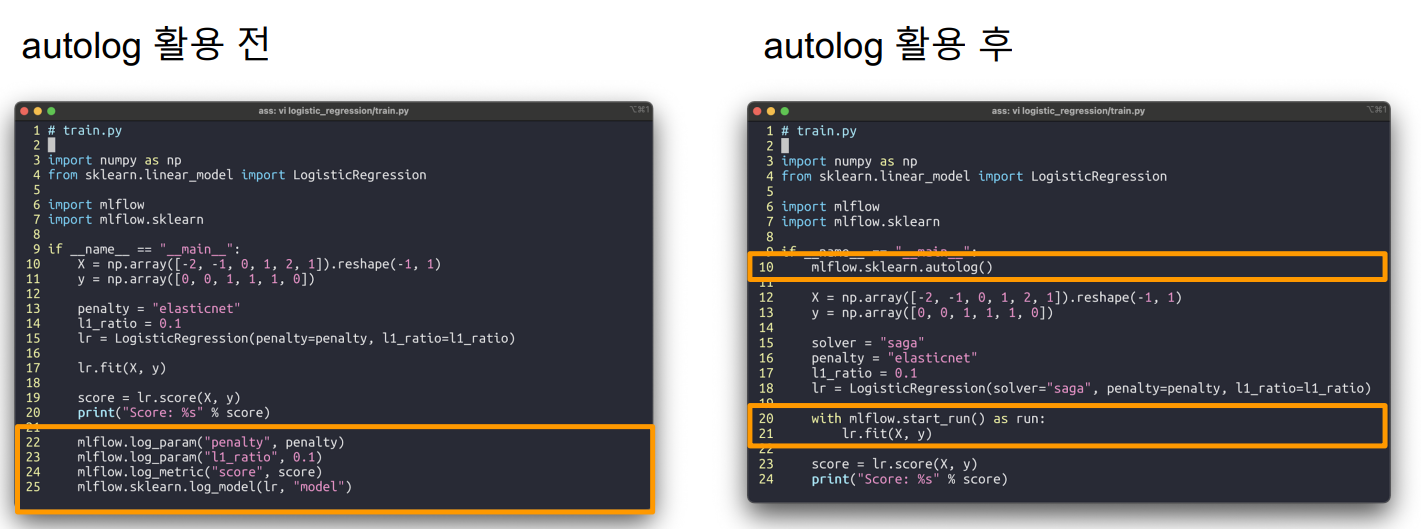
위 사진을 보시면 mlflow.sklearn.autolog()로 autolog를 실행한 후에 with mlflow.start_run() as run: 을 사용하여 피팅을 하면 모델이 돌아가면서 생기는 log는 자동으로 저장이 됩니다!
다시 Run하고 ui상에서 확인해 봅시다!
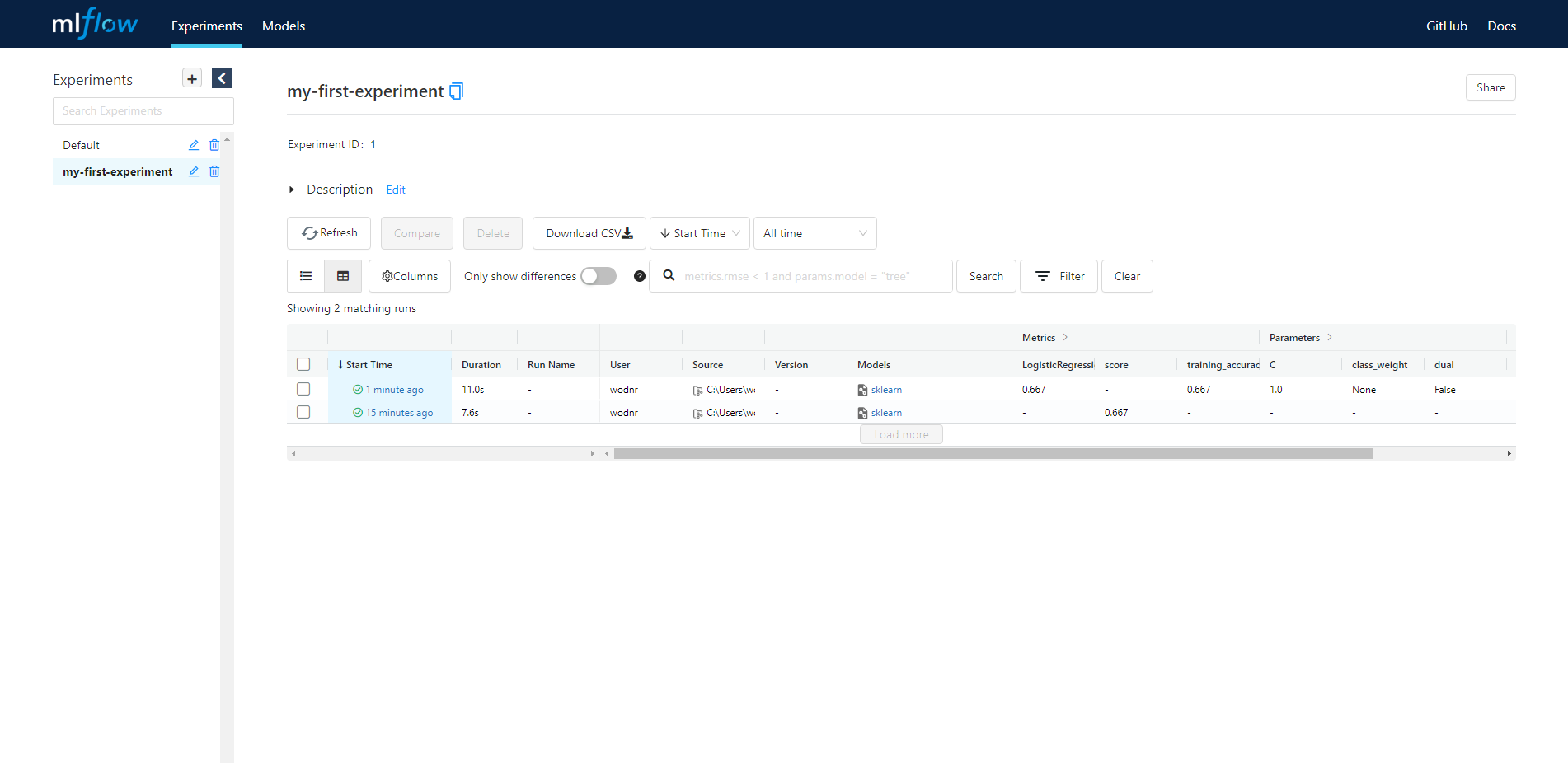
위와 같이 Run 정보에 행 하나가 더 추가가 되었습니다. Run 기록을 보면은 저희가 지정하지 않은 파라미터도 다 기록이 되는 것을 볼 수 있습니다.
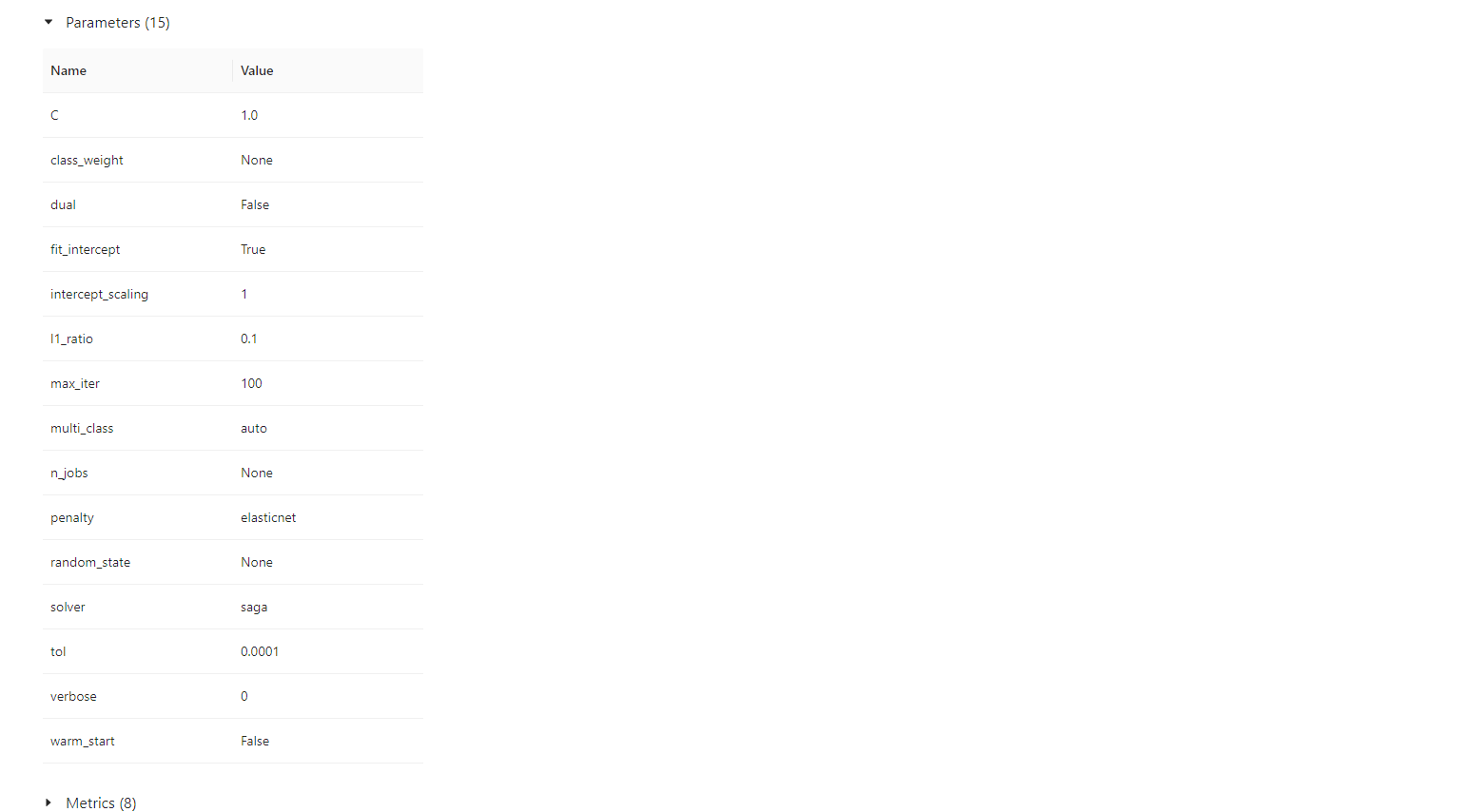
주의사항
- 모든 프레임워크에서 사용 가능한 것은 아님
- MLflow에서 지원해주는 프레임워크들이 존재
- 예) pytorch.nn.Module은 지원하지 않음(반면 Pytorch Lightning은 지원)
자세한 내용은 https://mlflow.org/docs/latest/tracking.html#id2 에서 확인
MLflow Parameter
MLflow는 autolog가 자동으로 기록을 한 것 처럼, 파라미터 또한 일일히 코드에 작성하지 않고 MLProject에 작성하여 적용할 수 있습니다.


이런 상황에서 Run은 다음과 같이 파라미터를 추가하면 됩니다.
mlflow run logistic_regression -P solver="saga" -P penalty="elasticnet" -P l1_ratio=0.01 --experiment-name my-first-experiment --no-conda
📕 MLflow 서버로 배포하기
MLflow Architecture
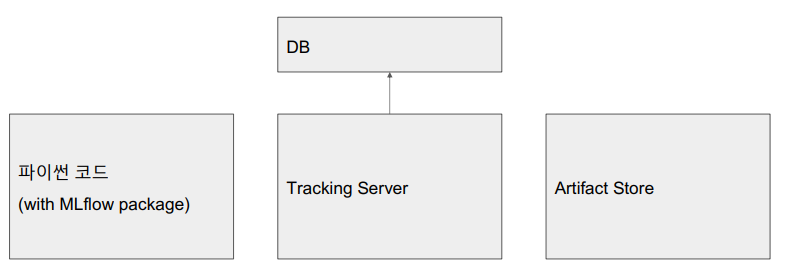
-
파이썬 코드(with MLflow package)
- 모델을 만들고 학습하는 코드
mlflow run으로 실행
-
Tracking Server
- 파이썬 코드가 실행되는 동안 Parameter, Metric, Model 등 메타정보 저장
- 파일 혹은 DB에 저장
-
Artifact Store
- 파이썬 코드가 실행되는 동안생기는 Model File, Image 등의 아티팩트를 저장
- 파일 혹은 스토리지에 저장
Tracking Server와 외부 스토리지 사용하기
Tracking Server는 DB에 연결되므로
-
mlflow server 명령어로 Backend Store URI 지정
mlflow server --backend-store-uri sqlite:///mlflow.db --default-artifact-root $(pwd)/artifacts
-
환경변수 지정
export MLFLOW_TRACKING_URI="http://127.0.0.1:5000"
-
Experiments를 생성한 후, Run
experiments create --experiments-name jodong2-second-experiment
mlflow run svm --experiment-name jodong2-second-experiment --no-conda
요약
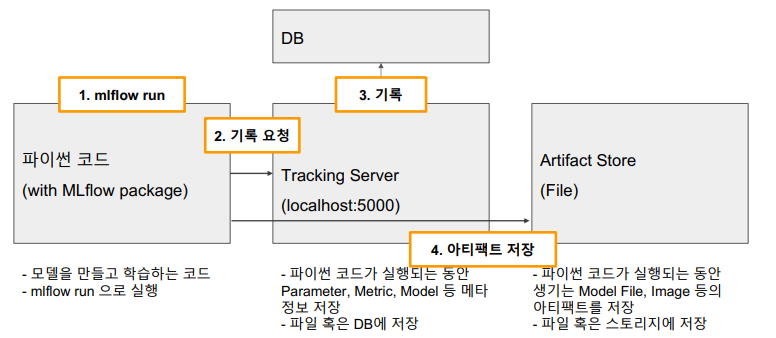
MLflow 실제 활용 사례
MLflow Tracking Server는 하나로 통합 운영
-
Tracking Server를 하나 배포하고, 팀 내 모든 Researcher가 이 Tracking Server에 실험 기록
- 배포할 때는 Docker Image, Kubernetes 등에 진행(회사의 인프라에 따라 다름)
-
로그나 모델이 한 곳에 저장되므로, 팀 내 모든 실험을 공유할 수 있음
-
Artifact Storage와 DB 역시 하나로 운영
-
Artifact Storage는 GCS나 S3 같은 스토리지 이용
-
DB는 CloudSQL이나 Aurora RDS 같은 DB 이용
-
-
이 두 저장소는 Tracking Server에 의해 관리

좋은 정보 감사합니다~