
1. Introduction
AlexNet 2012
2. Background
-Problem Statement
-Key Challenges
1) Intra class variation
2) Number of categories: 분류해야하는 object class가 너무 많고, 높은 퀄리티의 annotated data가 있어야 한다. 적은 양의 example을 사용하여 detector를 학습시키려는 연구가 진행중이다
3) Efficiency: high computation resource가 필요하다
3. Datasets, and Evaluation Metrics
-Dataset
1) PASCAL VOC 2007/2012
Visual Object Classes(VOC)
20 categories
2) ILSVRC(ImageNet)
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
2010~2017
3) MS-COCO
The Microsoft Common Objects in Context (MS-COCO)
0.5에서 0.95까지 0.5의 step으로 IOU를 계산한다(10 value) -> Average Precision (AP)
4) Open Image
Google’s Open Images dataset

5) Issues of Data Skew/Bias
skew in the dataset -> create bias
sked datasets -> 더 좋은 detection performance를 보인다.
-Metric
Object detector에서 사용하는 criteria
1) frames per second (FPS)
2) precision: percentage of correct predictions

3) recall: correct predictions with respect to the ground truth

여러 IOU -> 여러 precision -> 각 class 별로 average precision을 구한다 -> mean Average Precision (mAP) of all classes
이는 가장 많이 사용되는 evaluation metric이다
IoU (Intersection over Union): ground truth와 predicted bounding box 사이의 교집합/합집합
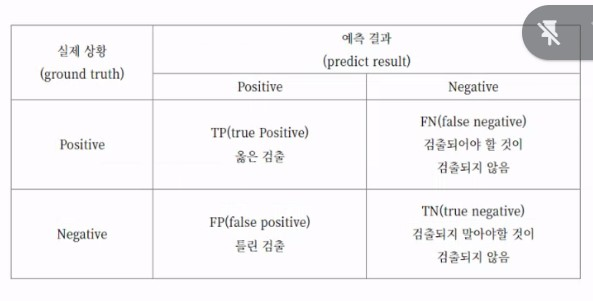
True Positive: detect o, IoU가 threshold를 넘을 때 -> true
False Positive: detect o, IoU가 threshold를 넘지 못할 때 -> false
False Negative: detect x
Ground Truth = True Positive+False Negative
(검출되야할 것이 검출되고, 검출되지 말아야할 것이 검출되지 않음)
4. Backbone Architectures
input image로 부터 feature를 추출한다
A. AlexNet(2012)
five convolutional + three fully connected layers
dropout and ReLU for regularization
accuracy 향상을 위해 smaller receptive window size에 집중했다
B. VGG(2014.09)
"Very deep convolutional networks for large-scale image recognition"
effect of network depth를 고려하였다. small convolution filters를 사용하여 다양한 깊이의 network를 만들 수 있다. 이때, network의 parameter의 개수가 줄어들고 더 빨리 converge한다.
a stack of convolutional layers(8~16) + three fully connected layer + softmax
VGG16
VGG19
C.GoogLeNet/Inception(2014.19)
1) scaled network는 computation cost가 크다.
2) bigger network는 많은 수의 parameter를 갖는데, 이는 data에 overfitting 되도록 하는 경향이 있다.
-> 위 문제를 해결하기 위해서
fully connected architecture -> locally sparse connected architecture
22 layer
Inception module(같은 level에 수많은 size의 filter를 갖는 network)을 쌓아서 만든다
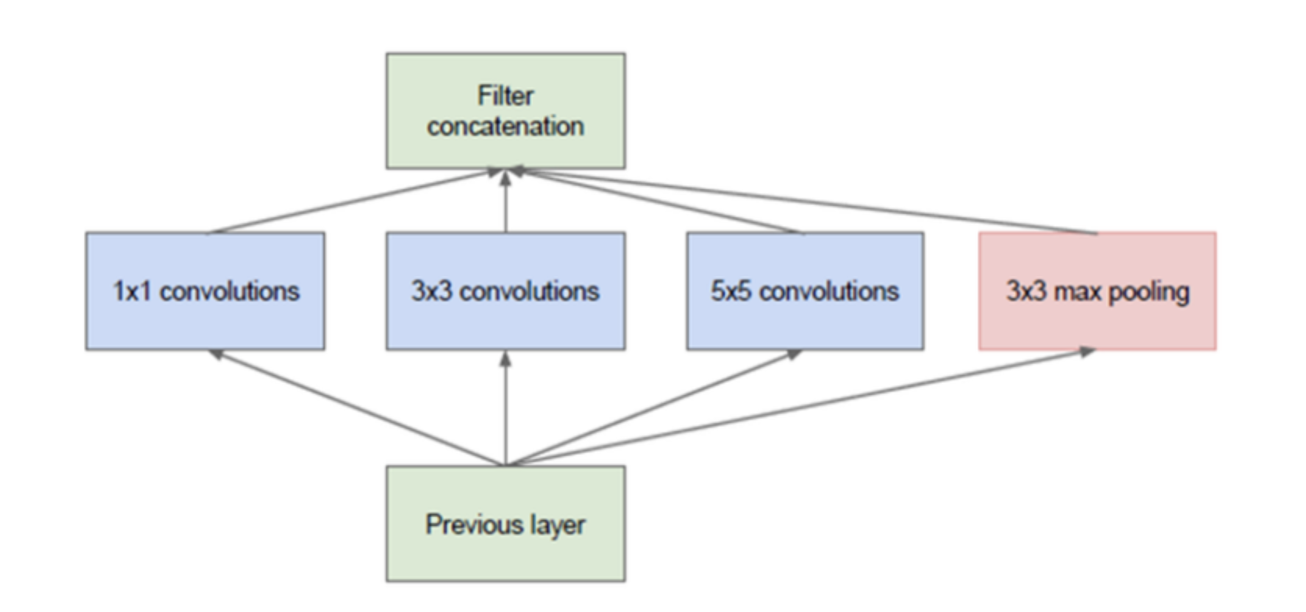
input feature map은 이러한 filter를 통과하고 concatenated되어 다음 layer로 forwarded 된다
correlation이 높은 노드끼리 연결할 수 있다.
D. ResNets(2015.12)
residual block, bottleneck block
layer 사이에 skip connection을 추가한다
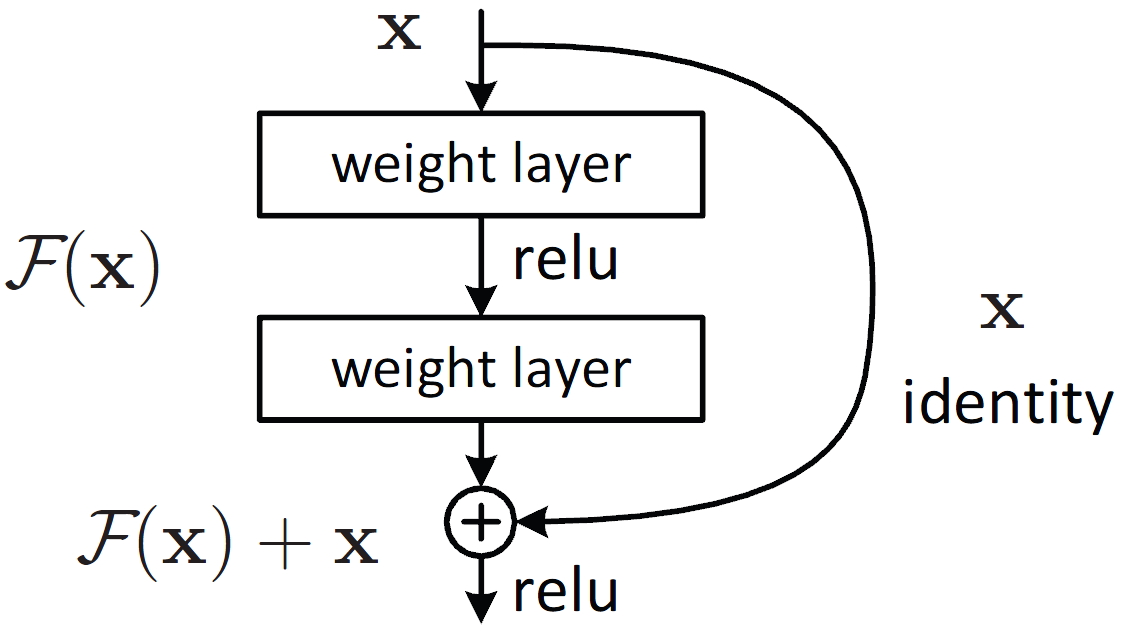
batch normalization, ReLU layer -> ResNetv2
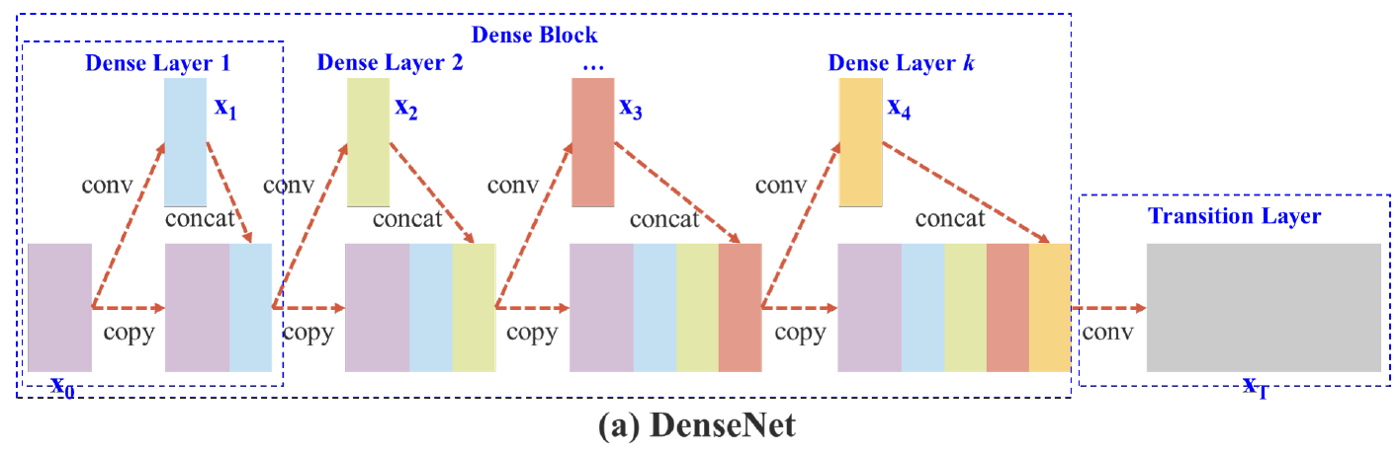
DenseNet(2016.08)
forward 방향의 다른 모든 layer와 연결되어 있는 Dense block 추가
ResNet을 더 deeper하게 만들 수 있다
E. ResNeXt(2016.11)
ResNet에서 ResNet block이 inception-like ResNext module로 대체 된 것이다
depth, width, resolution
multiple parallel pathway(cardinality)를 이용하여 residual block의 width를 확장한다
F. CSPNet(2019.11)
Cross Stage Partial Network
duplicate gradient information을 줄이기 위한 것이다.
partial convolution network block -> its output at a later stage
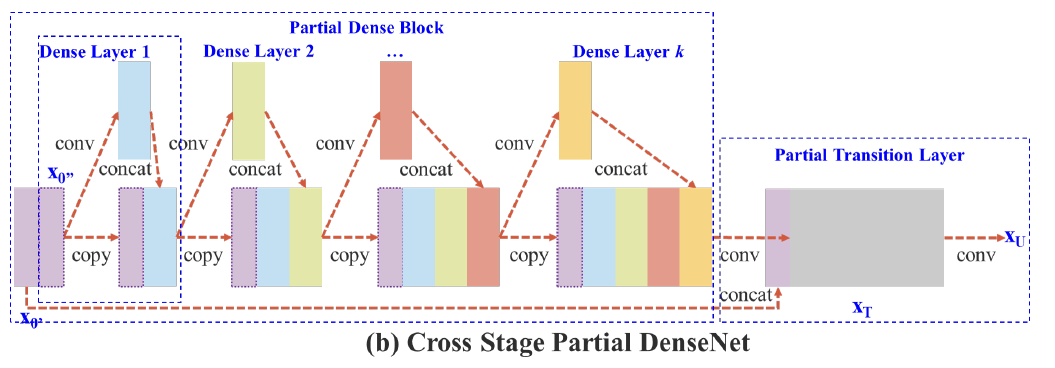
ResNext, YOLOv4, Scaled-YOLOv4에 활용되었다.
G. EfficientNet(2019.05)
scaling network depth -> richer and more complex feature를 capturing 할 수 있지만, vanishing gradient problem이 발생한다.
scaling network width -> fine-grained feature를 capture 할 수 있지만, high level feature를 얻을 수 없다.
compound coefficient that can uniformly scale all three dimensions(depth, width, resolution)
baseline architecture
5. Object Detectors
A. Pioneer work
two-stage detector: region proposal를 generate하기 위한 separate module을 가진 network
arbitary number of objects proposal을 찾는다 -> classify & localization
but, proposal을 generate 하는데 많은 시간이 걸려 global context를 파악할 수 없다.
one-stage detector: dense sampling을 사용하여 classify+localize semantic object를 한번에 수행한다.
predefined boxes/keypoint를 사용하여 localize
two-stage detector 보다 real-time perfomance가 우수하다
1) Viola-Jones(2001)
for face detection
1) input image에 sliding window를 이용하여 Haar-like features를 찾는다 -> integral image
2) trained Adaboost를 이용하여 각 haar feature의 classifier를 찾고 cascade 한다
2) HOG Detector(2005)
Histogram of Oriented Gradients
HOG -> gradient, edge의 orientation 얻어 feature table 생성 -> grid 안의 각 cell의 histogram 생성 -> region of interest를 발생시키고, linear SVM classifier을 통과하여 dectect한다
3) DPM(2009)
Deformable Parts Model
'divide and rule'
inference time 동안 object의 part를 각각 detect하고, 불가능한 configuration을 제외하여 combine 함으로서 detect한다.
B. Two-Stage Detectors
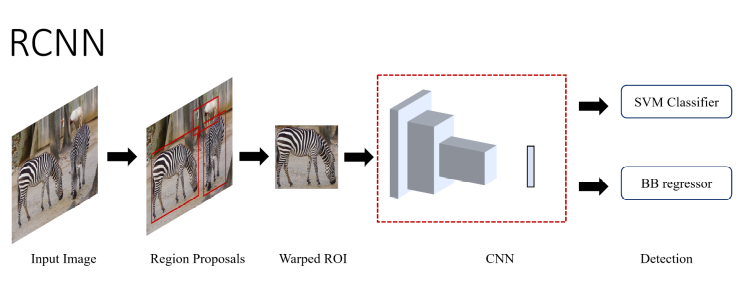
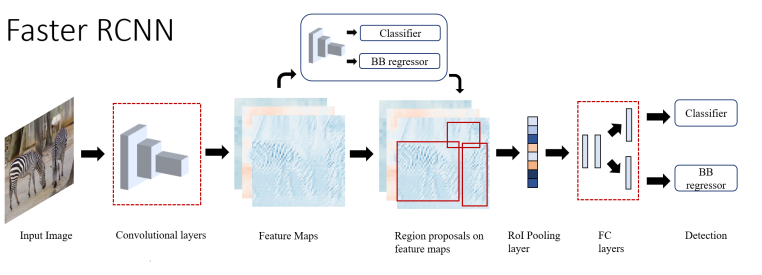
1) R-CNN(2013.11, CVPR 2014)
Region-based Convolutional Neural Network
region proposal을 도입하여 detection을 classification과 localization의 문제로 치환하였다.
mean-subtractede input image가 region proposal module을 통과 -> Selective Search로 object를 찾을 가능성이 높은 2000개의 object candidate을 만들어낸다 -> CNN network를 통과하면 각 proposal에서 4096-dimension feature vector를 추출한다 -> SVM를 거쳐서 confidence score를 얻는다 -> Non-maximum suppression (NMS)를 scored region에 적용 -> predict bounding box
1) 큰 classification dataset으로 CNN을 pre-training 시킨다
2) domain-specific images (mean-subtracted, warped proposals)을 이용하여 fine-tunning 시킨다.
3) stochastic gradient descent (SGD)를 이용하여 classification layer를 randomly initialized N+1-way classifier로 대체한다
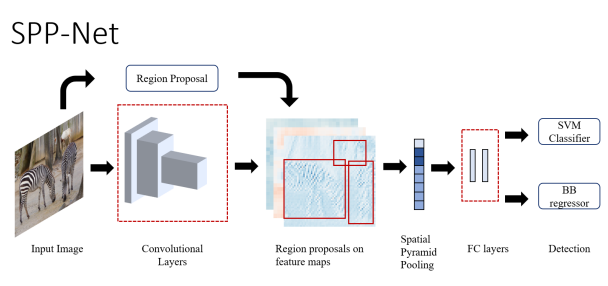
2) SPP-Net(2014.06)
Spatial Pyramid Pooling
SPP-net: CNN의 convolutioon layer + region proposal module 순으로 배치 -> pooling layer 추가 -> size/aspect ratio에 independent한 network를 만들어 낸다
selective search로 candidate window 생성 -> pyramidal pooling layer에 의해 fixed lengh representation으로 변환된다 -> fully-connected layer에 전달되어 SVM classifier로 class와 score를 예측한다.
어떤 shape나 aspect ratio의 image도 처리할 수 있어 input warping시 발생할 수 있는 image deformation도 막을 수 있다
but, R-CNN과 마찬가지로 multistage training이면서 연산이 복잡해 training time이 오래걸린다.
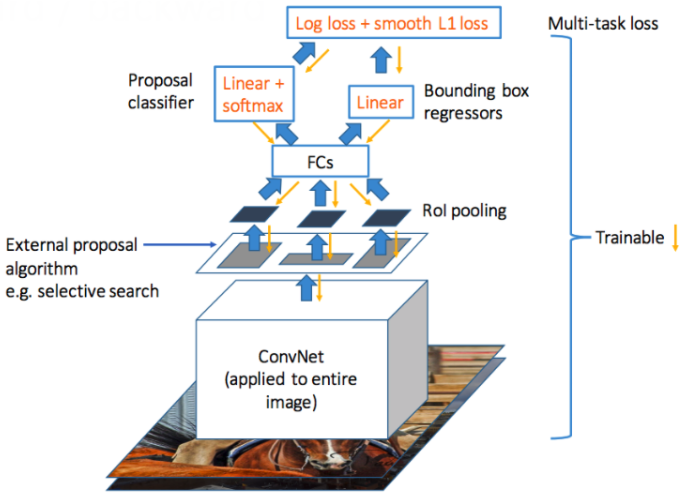
3) Fast R-CNN(2015.04)
image -> CNN layer -> object proposal이 mapped된 feature map 획득 -> RoI pooling layer
Log loss와 smooth L1 loss를 loss function으로 사용하여 multi-task loss로 network를 학습시킨다.
4) Faster R-CNN(2015.06)
region proposal network (RPN) 으로서 fully-convoluted network 도입
arbitary input image를 입력하면, set of candidate window를 출력한다. 각 window는 연관된 object의 likelihood를 결정하는 objectness score를 갖는다.
기존의 model들이 object들의 size variance들을 image pyramid를 이용하여 표현했다면, RPN는 Anchor boxes를 이용하여 이를 표현한다.
1) RPN는 ImageNet dataset으로 pre-trained 되어있고, PASCAL VOC dataset으로 fine-tuned 되어있다
detector의 convolution layer를 fix하고, RPN의 unique layer를 fine-tuning 한다 -> RPN을 update하면 Fast R-CNN을 fine-tuning 할 수 있다
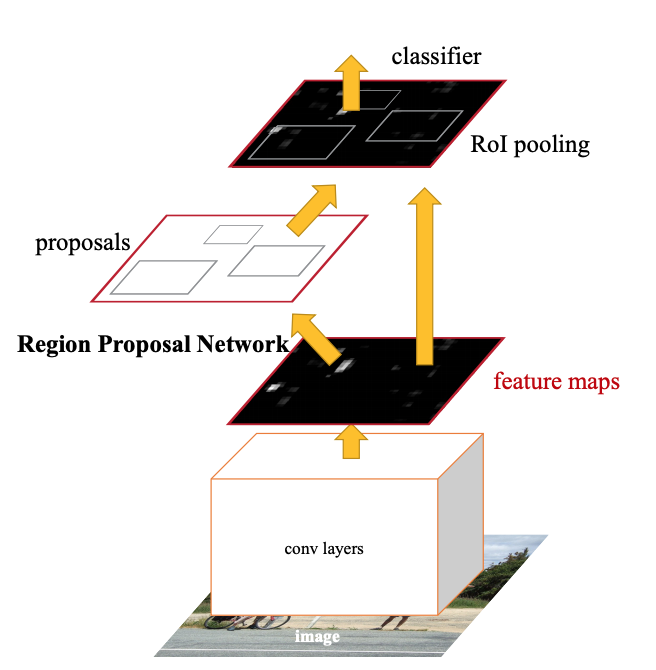
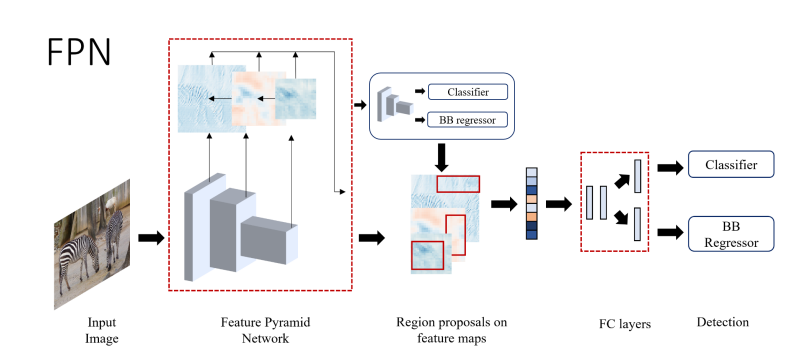
5) FPN(2016.12)
Feature Pyramid Network
small object에 대한 detection
high-level semantic feature를 high resolution feature(upsampled)에 mapping하는 architecture를 갖는다 -> feature의 semantic information이 증가한다
PANet, NAS-FPN, EfficientDet에 사용된다.
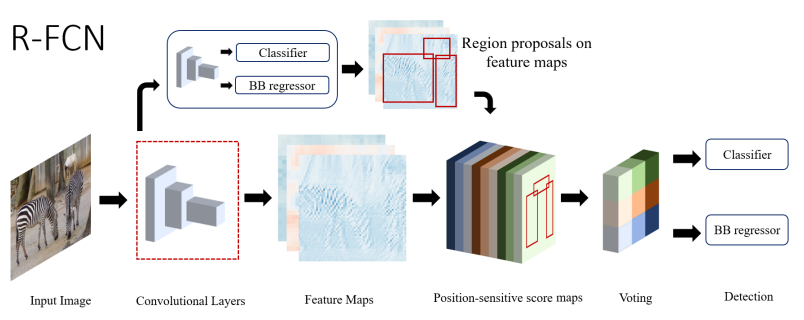
6) R-FCN(2016.5)
Region-based Fully Convolutional Network
Translation invariance 문제가 발생한다(물체의 위치가 바뀌더라도 물체를 인식한다)
-> position-sensitive score map(물체의 위치에 따라 다른 score를 부여한다) -> region of interest를 k x k grid로 나누고 각 cell의 likeliness를 scoring 한다 -> position-sensitive RoI pooling layer
7) Mask R-CNN(2017.03)
Faster Mask R-CNN에서 pixel-level object instance segmentation을 위하여 fully connected network(mask head)을 추가한 것이다
이는 각 pixel을 computation cost가 작은 segment로 분류하기 위하여 RoI에 적용한 것이다
spatial quantization에 의한 pixel level misalignment를 피하기 위해 RoIPool layer 대신, RoIAlign layer를 사용하였다.
ResNeXt-101(backbone)+FPN+RoIAlign layer
mask loss -> update R-CNN
5 anchor boxes with 3 aspect ratio -> update FPN
key point detection, human pose estimation
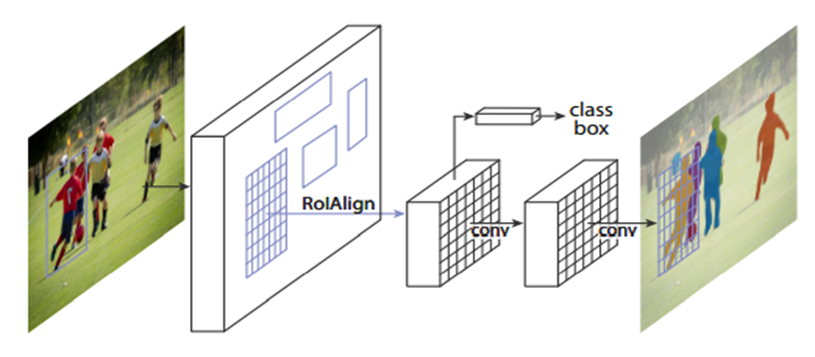
8) DetectoRS(2020.06)
기존의 two stage detector는 object proposal를 얻기 위하여 looking and thinking을 두번 한다.
network의 macro level과 micro level에 모두 이 mechanism을 적용한 것이다
macro level -> Recursive Feature Pyramid (RFP)
FPN - Atrous Spatial Pyramid Pooling layer(ASPP) - FPN
micro level -> convolution의 dilation rate를 regulate하는 Switchable Atrous Convolution (SAC)
average pooling layer(5x5 filter)
atrous convolution rate를 결정하는 switch function (1x1 convolution)
-> Recursive Feature Pyramid (RFP)과 Switchable Atrous Convolution (SAC)를 결합한 Hybrid Task Cascade (HTC)을 baseline model로 사용하였다
- ResNext-101 backbone
2021.04 기준 SOTA two stage detector
but, real time detection 에는 적합하지 않다.(4 fps)
C. Single-Stage Dectors
YOLO(2015.06, CVPR 2016)
image pixel을 objects와 bounding box attributes으로 직접 예측한다(regression)
x, y(center of bounding box) w, h, confidence score(dimensions of the box)
-> confidence score(object일 확률 * IOU값)
smaller convolution network를 cascade한 GoogLeNet model에 영감을 받았다
model이 high accuracy를 가질 때 까지 ImageNet data를 pre-trained 시킨다 -> randomly intialized convolution과 fully connected layer를 거친다.
training time 동안, gried cells은 오직 하나의 class를 예측하여 converge가 잘 되도록 한다. but, 대신 inference time이 증가한다.
small or clustered object에 대한 Localization accuracy가 작고, cell 당 object의 개수에 제한이 있다.
Non Maximum Suppression
Object Detector가 예측한 bouding box 중에서 가장 confidence가 높은 bounding box(ground truth)만 남기는 방법
SSD(Single Shot MultiBox Detector, 2015.12)
VGG-16+convolutinal layers
Multiscale feature maps → 다양한 크기의 객체 포착 가능
negative mining, heavy data augmentation
model을 학습 시키기 위해 DPM처럼 localization의 weighted sum과 confidence loss를 이용한다
non maximum suppresion
YOLO, Faster R-CNN 보다 빠르고 정확하지만, small object를 잘 detect 하지 못한다
-> 이 문제는 이후에 ResNet과 같은 다은 backbone network를 사용하여 해결하였다.
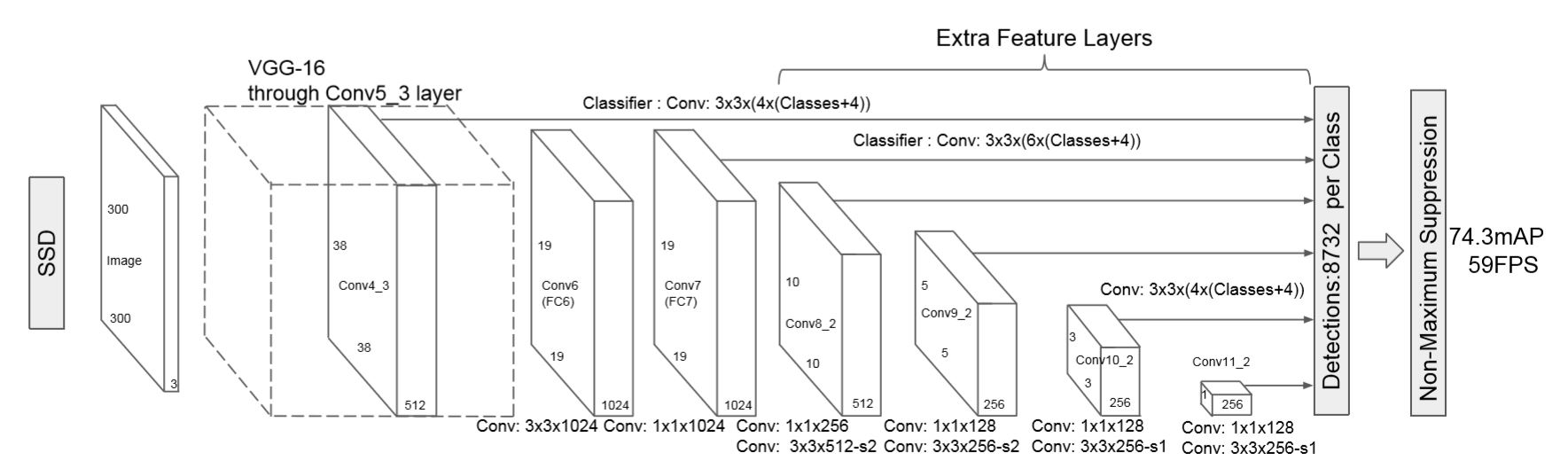
YOLOv2 and YOLO9000(2016.12, CVPR 2017)
YOLOv1을 개선한 버전, YOLO9000은 9000개의 객체를 real-time으로 detect할 수 있도록 학습된 모델
backbone architecture: GoogLeNet->DarkNet-19
Batch Normalization
remove fully connected layer -> speed 증가
learnt anchor boxes -> recall 향상
WordNet -> combine classification+detection dataset
RetinaNet(2017.08, ICCV 2017)
single stage detector의 단점이 'extreme foreground-background class imbalance'
-> Focal loss(reshaped cross entropy loss)
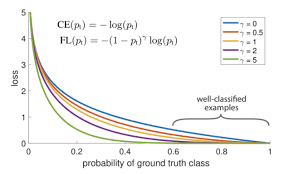
location, scale, aspect ratio를 가진 input image를 dense samping하여 object를 예측한다
Feature Pyramid Network (FPN)로 augmented 된 ResNet을 backbone, classification and bounding box regressor로 사용한다
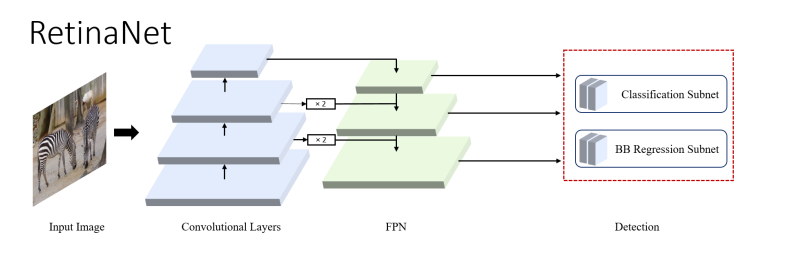
YOLOv3(2018.04)
feature extractor network를 Darknet-53으로 대체
data augmentation, multi-scaling traing, batch normalization
classifier layer의 softmax는 -> logistical classifier
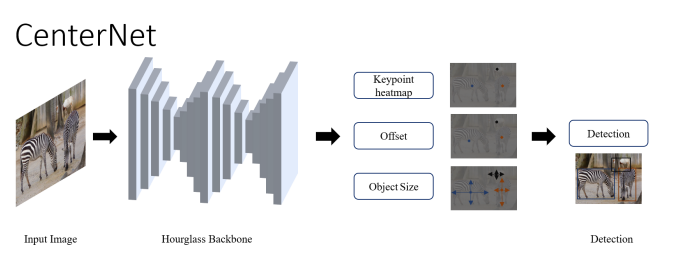
CenterNet(2019.04)
bounding box의 center에서의 single point로서 object를 예측하였다.
input image가 FCN를 거치면 detected object의 center를 peak로 하는 heatmap을 생성한다. ImageNet으로 pretrained 된 stacked Hourglass-101를 feature extractor network로 사용하였다.
heatmap head -> object center 결정
dimension head -> object size 결정
offset head -> object point의 offset을 바로 잡는다
3개의 head의 multitask loss는 feature extractor로 back-propagate 된다
inference 동안 offset head의 output은 object point를 결정하는데 사용되고, 최종적으로 box가 발생된다
기존의 model보다 정확하고 inference time이 적게 든다
3D object detection, keypoint estimation, pose, instance segmentation, orientation detection
EfficientDet(2019.05, ICML 2019)
scalable detector
efficient multi-scale features인 BiFPN(bi-directional feature pyramid network with learnable weights for cross connection of input features at
different scales)와 model scaling
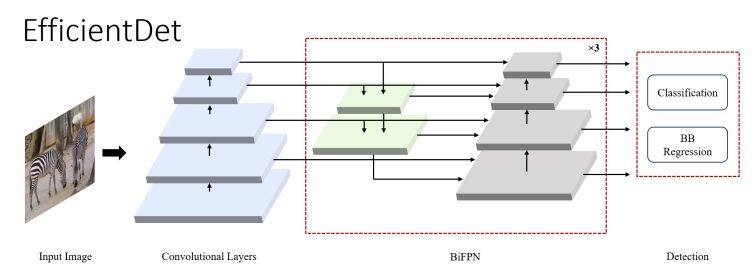
backbonce network인 EfficientNet의 모든 dimension(BiFPN network,
class/box network and resolution)을 scale up하는 compounding ciefficient
ReLU activation을 사용하지 않는다. synchronized batch normalization과 swish activation을 사용하는 SGD optimizer를 이용하여 학습한다
YOLOv4(2020.04)
"Bag of freebies"(training time만 증가되고 inference time에는 영향을 주지 않는 기법)
data augmentation technique, regularization method, class label smoothing, CIoU-loss, Cross mini-Batch Nomalization(CmBN), Self-adversarial training, Cosine annealing scheduler
(inference time만 영향을 주는 기법)
Mish activation, Cross-stage partial connection(CSP), SPP-Block, PAN path aggregated block, Multi input weighted residual connection(Mi-WRC), genetic algorithm for searching hyper-parameter
ImageNet pre-trained CSPNetDarknet-53(backbone)
SPP, PAN block neck, YOLOv3(detection head)
single GPU로 학습시킬 수 있다
YOLOv5(2020.05, 논문X)
Scaled-YOLOv4(2020.11, CVPR 2021)
YOLOR(2021.05)
YOLOX(2021.07)
Swin Transformer(2021.03 ICCV 2021)
Swin(shifted windows) transformer
Transformer는 attention model을 사용하여 sequence의 element사이의 dependencies를 만들어낸다. 또한, 다른 sequential architecture들 보다 더 긴 context를 반영한다.
CNN은 global context과 fixed post-training weight를 반영하지 못한다는 단점이 있다
Swin Transformer block은 local multi-headed self-attention(MSA) module로 구성되어 있다.
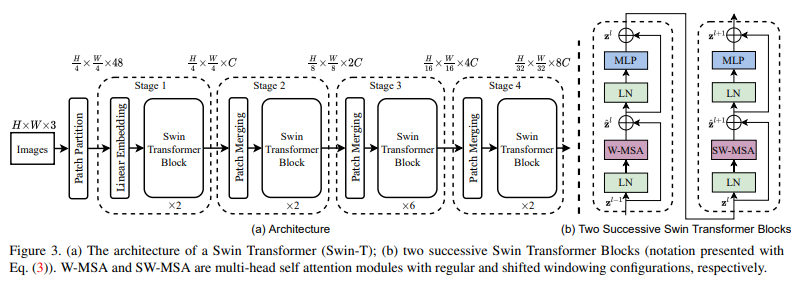
YOLOS(2021.06)
YOLOv6(2022)
Meituan
YOLOv7(2022.06)
6. Lightweight Dectors
A. SqueezeNet
B. MobileNets
C. ShuffleNet
D. MobileNetv2
E. PeleeNet
F. ShuffleNetv2
G. MnasNet
H. MobileNetv3
I. Once-For-All (OFA)

The only survey I know of is the customer satisfaction survey. Customer satisfaction surveys are conducted by well known stores, restaurants, gas stations, and many companies to gather their customer's genuine feedback to better their company services. Like every competition company JCPenney department store chain is also following the same customer satisfaction survey process and conducting the JCPenney survey at https://www.jcpenneycomsurvey.blog/ official website. The JCPenney survey winner will get a free 15% off coupon.