T-distribution (T-분포)
정규 분포의 평균 측정시 주로 사용, 모집단의 표준편차 모를때, 보통 N< 30 (T distribution), N이 30 이상이어도 T분포 사용한다.
t분포는 평균= 0, 분산 >1인 정규분포 따른다.
표본갯수가 불충분하거나, 모집단 표준편차 모르는 경우 사용한다.
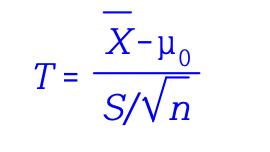
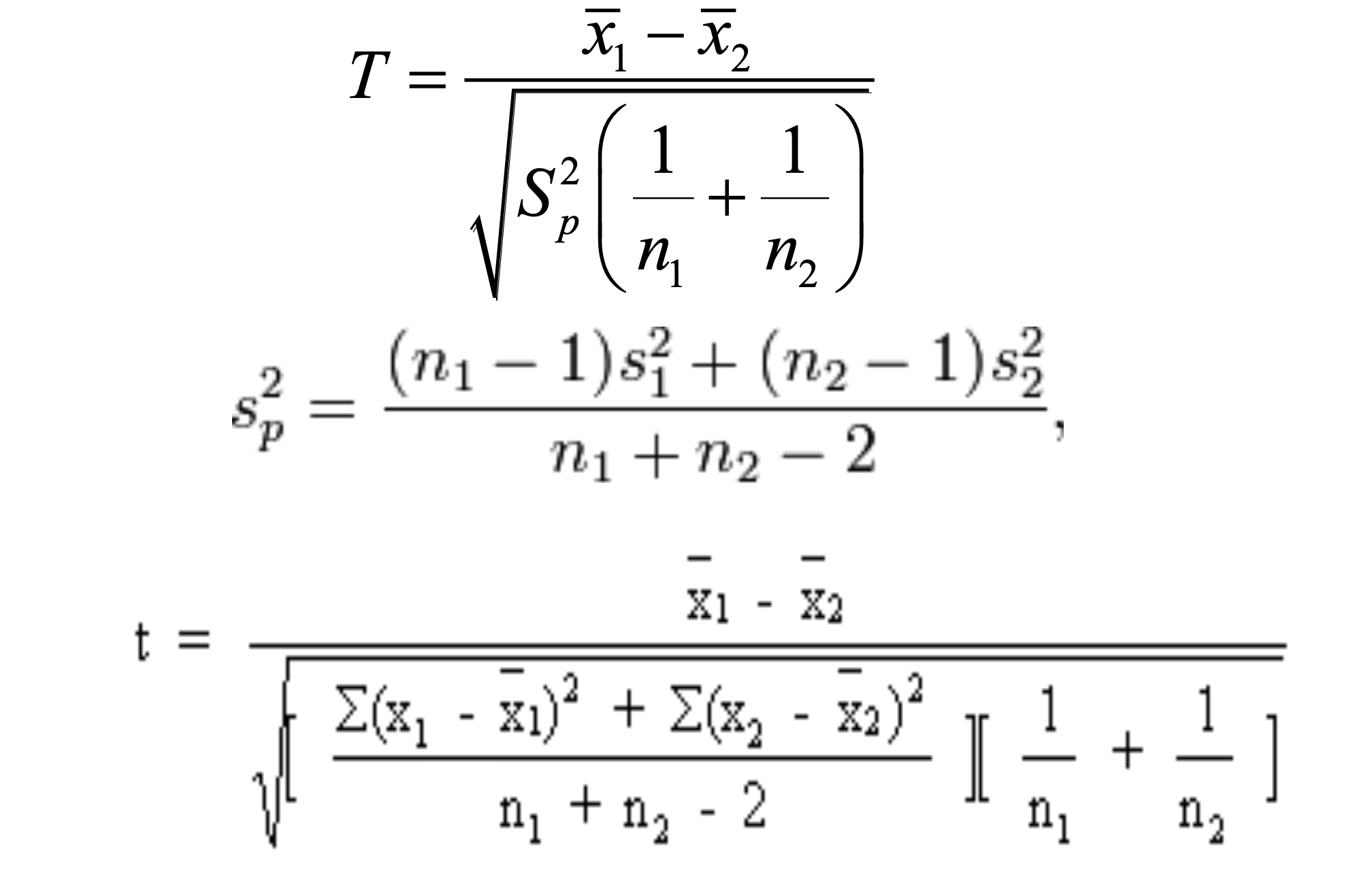
모평균의 100(1-a)% 신뢰구간(표준편차가 미지인 경우)은 다음과 같이 구한다.
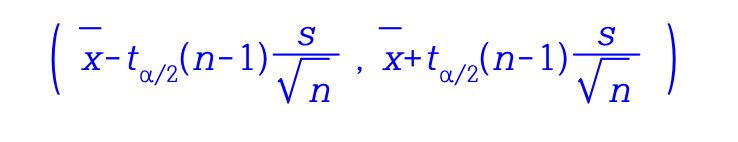
예 6.3
10 명의 창던지기 선수의 기록을 조사한 것이 표 6.4와 같다.
SAS를 이용하여 평균과 표준편차를 추정해 보고 평균의 95% 신뢰구간을 구해보자. 이는 MEANS 프로시져에서 CLM 옵션을 사용하여 구할 수 있다.
<표 6.4 창던지기 기록>
64.0 64.8 66.0 66.0 61.5 65.0 68.0 65.0 63.6 61.6 68.9SAS 프로그램
/* SPEAR.SAS : 표준편차를 모를 때, 평균의 95% 신뢰구간 구하기 */
DATA JAVELIN; /*데이타 세트 생성 */
INPUT SPEAR @@; /*변수 읽기*/
CARDS;
64.0 64.8 66.0 61.5 65.0 68.0 65.0 63.6 61.6 68.9
;
PROC MEANS DATA=JAVELIN MEAN STD ALPHA=0.05 CLM;
/*95% 신뢰구간*/
VAR
SPEAR;
RUN;출력결과
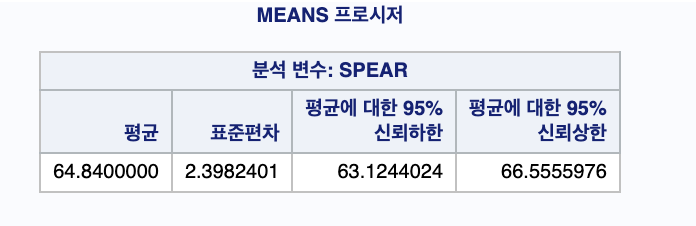
출력결과에서 보듯이 창던지기 기록 평균의 95% 신뢰구간은
( 63.12 ,66.56 )
예 6.4
표 6.5는 미국의 유명한 야구선수 베이브루스의 15년간 홈런기록을 크기 순서대로 나열한 자료이다. 홈런개수가 정규분포를 따른다는 가정했을때, 연평균홈런수가 40보다 크다고 말할 수 있는지 유의수준 에서 검정해 보자. 실제 연평균홈런수를 라고 할 때 적절한 가설은 다음과 같다.
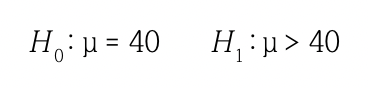
<표 6.5 홈런개수>
22 25 34 35 41 41 46 46 46 47 49 54 54 59 60SAS 프로그램
/*BASEBALL.SAS : 표준편차를 모를 때 모평균의 가설검정*/
OPTIONS NODATE;
DATA BASEBALL; /* 데이타 세트 생성 */
INPUT HOME @@; /* 변수 읽기 */
HOME2=HOME-40; /* 귀무가설하의 값을 뺀다 */
CARDS;
22 25 34 35 41 41 46 46 46 47 49 54 54 59 60
;
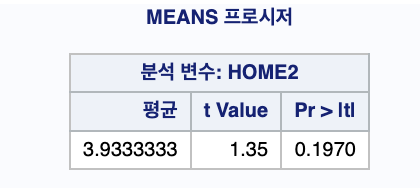
PROC MEANS DATA=BASEBALL MEAN T PRT; /*유의성 검정*/
VAR HOME2;
RUN;
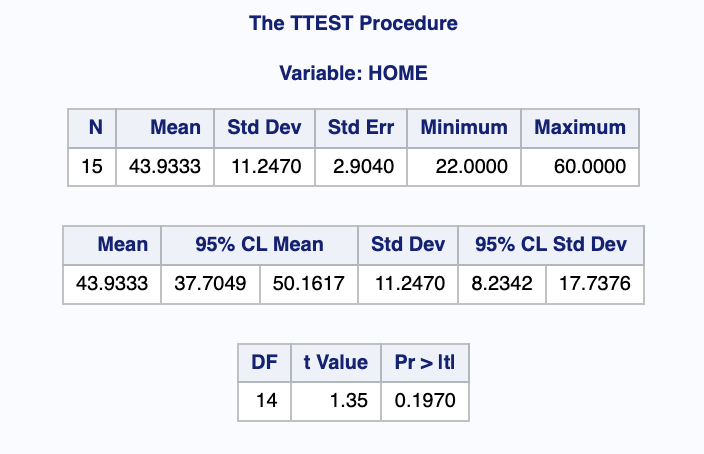
PROC UNIVARIATE DATA =BASEBALL PLOT; /*정규분포 분위수대조도*/
VAR HOME2;
RUN;출력결과
R 프로그램
# data set
x <- c(22,25,34,35,41,41,46,46,46,47,49,54,54,59,60)
#data frame으로 저장
df <- as.data.frame(x)
hist(df$x)
n <- nrow(df)
mu <- 40
df$sigma <- sd(df$x) # sd : 표준편차
df$xbar <- mean(df$x)
df$diff <- df$x - df$xbar
df$diffsq <- df$diff^2
sd_cal <- sqrt(sum(df$diffsq) / (n-1))
xbar <- mean(df$x)
# t값
t <- (xbar-mu) / (sd_cal/sqrt(n))
# p-value 양쪽 검정
p_value <- 2*(1-pt(t,n-1))
# p-value 한쪽 검정
p_1sided = p_value/2
# 실제 ttest 명령어
t.test(df$x, mu=40)
출력결과
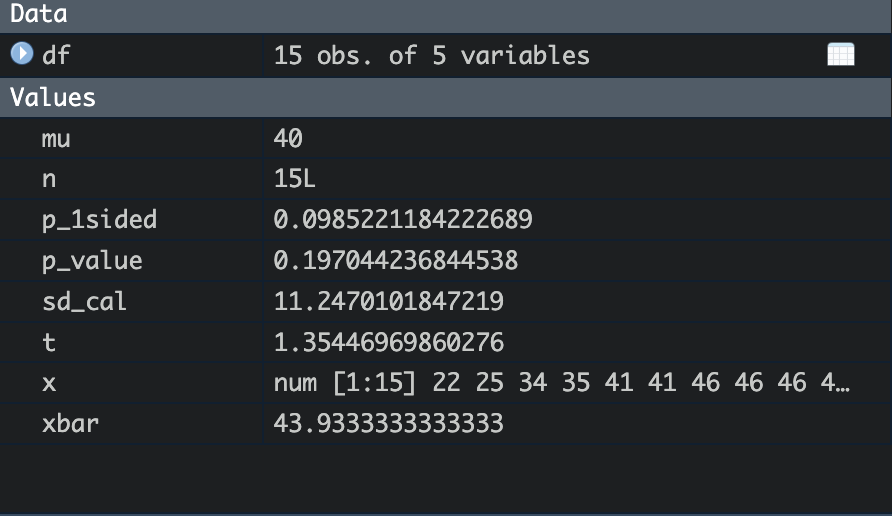
-
귀무가설, 대립가설 설정
귀무가설(H0) : μ=40 , 대립가설(H1) :μ>40
-
T값이 1.35446 이다.
-
p-value 단측 검정을 해야하므로 0.1970를 2로 나눔
: 0.0985 (유의 수준 5%) >0.05 -
H0 을 채택하고, H1 를 기각한다.
유의수준 5%에서 연평균홈런수가 40보다 크다는 증거는 없다.
Paired T-Test
Paired t-test(쌍체비교, 대응표본 T검정)는 쌍을 이룬 두 변수 간에 통계적으로 유의한 차이가 있는지를 검정하는 통계분석 방법.
가장 흔한 예는 한 집단을 대상으로 어떤 개입(intervention) 또는 처리(treatment)의 효과를 보기 위해 개입 전/후 값을 비교하여 개입의 효과를 측정하는 것이다.
예제
벨기에의 서부지역에서 공장지대에 방목되는 가축들의 소변에서 불소의 농도를 방목 초기와 일정기간 후에 11마리를 랜덤추출하여 측정하였다. 환경오염에 의해 소변 중 불소의 농도가 떨어진다는 증거가 있는지를 유의수준 1%에서 검정하고, 유의확률도 구해보자.(국제환경연구회 1978)
<가축의 소변에 있는 불소의 농도(ppm)>
방목초기 24.7 46.1 18.5 29.5 26.3 33.9 23.1 20.7 18.0 19.3 23.0
방목 후 12.4 14.1 7.6 9.5 19.7 10.6 9.1 11.5 13.3 8.3 15.0방목 초기에 가축의 소변 중 불소의 평균 농도를 , 일정기간 방목후 평균 농도를 라하면, 검정하려는 가설은 다음과 같다.
SAS 프로그램
/*PAIR.SAS : 대응(쌍체)비교를 통한 모평균의 비교*/
OPTIONS NODATE;
DATA PAIR; /*데이타 세트 생성 */
INPUT INITIAL AFTER @@; /*변수 읽기 */
DIFF = INITIAL-AFTER;
CARDS;
24.7 12.4 46.1 14.1 18.5 7.6 29.5 9.5 26.3 19.7 33.9 10.6
23.1 9.1 20.7 11.5 18.0 13.3 19.3 8.3 23.0 15.0
;
RUN;
PROC MEANS DATA=PAIR MEAN T PRT; /* 유의성 검정 */
VAR DIFF;
RUN;출력결과
R 프로그램
initial = c(24.7,46.1, 18.5, 29.5, 26.3, 33.9, 23.1, 20.7, 18.0, 19.3, 23.0)
after = c(12.4, 14.1, 7.6, 9.5, 19.7, 10.6, 9.1, 11.5, 13.3, 8.3, 15.0)
#col으로 두개의 데이터를 붙임
cow = cbind(initial,after)
cow = as.data.frame(cow)
ndata <- nrow(cow)
cow$diff <- cow$initial - cow$after
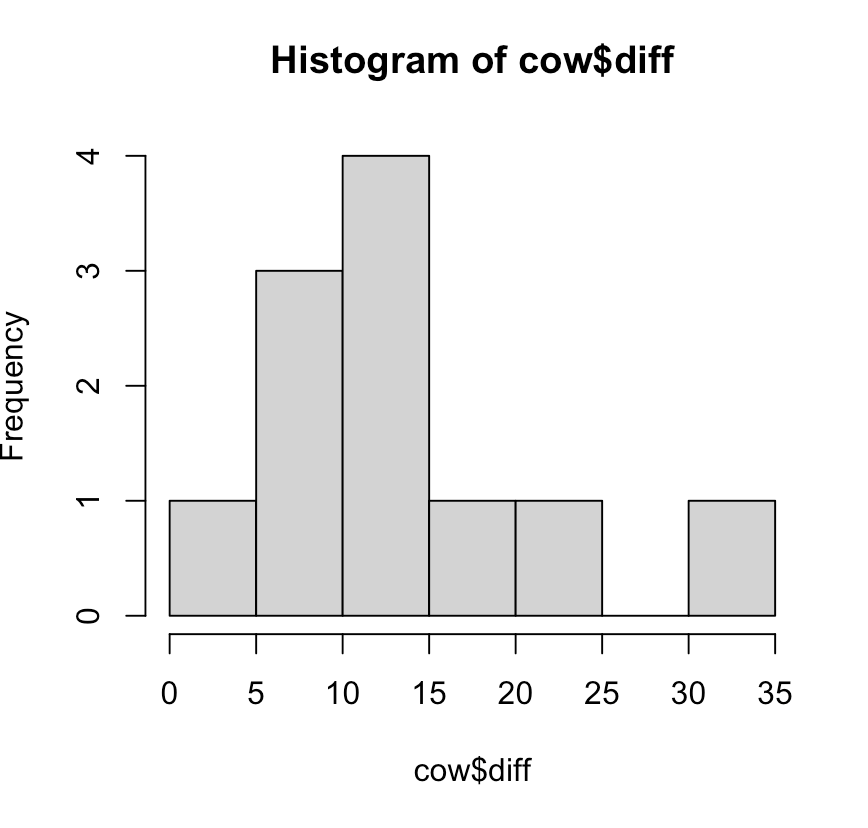
hist(cow$diff)
t.test(cow$diff, mu=0,alternative = "greater")
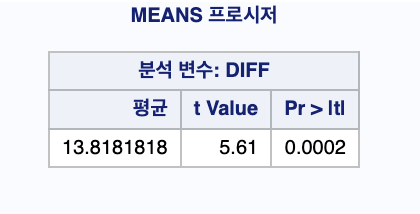
출력결과
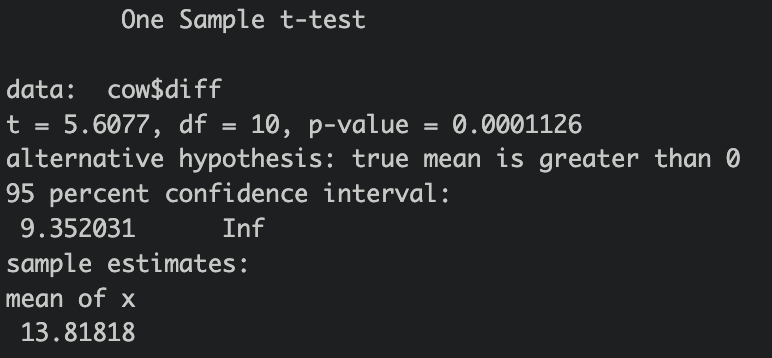
-
귀무가설, 대립가설 설정
D= -
귀무가설(H0) : D=0 , 대립가설(H1) :D<0
-
T값이 5.61 이다.
-
p-value 단측 검정을 해야하므로 0.0002를 2로 나눔
: 0.0001 (유의 수준 1%) <0.01 -
H1 을 채택하고, H0 를 기각한다.
관측결과로부터 환경오염에 의한 소변의 불소농도가 변화했다는 증거가 1%보다 강하게 나타남
실습1.
다음 자료는 어느 회사에서 생산되는 제품의 평균수명시간(단위 : 년)을 추정하기 위하여 20대의 제품을 랜덤추출하여 수명시간을 측정한 결과이다.
5.7 7.7 7.5 3.8 8.8 5.4 7.9 8.1 4.7 6.3
10.3 4.9 7.3 6.7 7.2 8.3 7.7 6.9 5.5 6.9 SAS를 이용하여 다음물음에 답하여라.
(a) 이 제품의 평균수명시간의 95%신뢰구간을 구하여라.
(b) 이 제품의 평균수명시간이 6시간보다 길다는 뚜렷한 증거가 있는가? 유의 수준 5%에서 검정하여라.
표준편차를 모르기때문에 T-Test 적용
SAS 프로그램
/*실습1.SAS : 표준편차를 모를 때 모평균의 가설검정*/
OPTIONS NODATE;
DATA PRODUCT; /* 데이타 세트 생성 */
INPUT TIME @@; /* 변수 읽기 */
TIME2=TIME-6; /* 귀무가설하의 값을 뺀다 */
CARDS;
5.7 7.7 7.5 3.8 8.8 5.4 7.9 8.1 4.7 6.3
10.3 4.9 7.3 6.7 7.2 8.3 7.7 6.9 5.5 6.9
;
Run;
PROC MEANS DATA=PRODUCT MEAN T PRT; /*유의성 검정*/
VAR TIME2;
RUN;
PROC UNIVARIATE DATA =PRODUCT PLOT; /*정규분포 분위수대조도*/
VAR TIME2;
RUN;
PROC TTEST DATA=PRODUCT h0=6;
VAR TIME;
RUN;
PROC MEANS DATA=PRODUCT MEAN STD ALPHA=0.05 CLM;
/*95% 신뢰구간*/
VAR
TIME;
RUN;출력결과
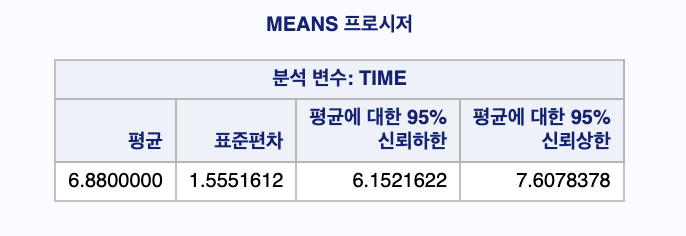
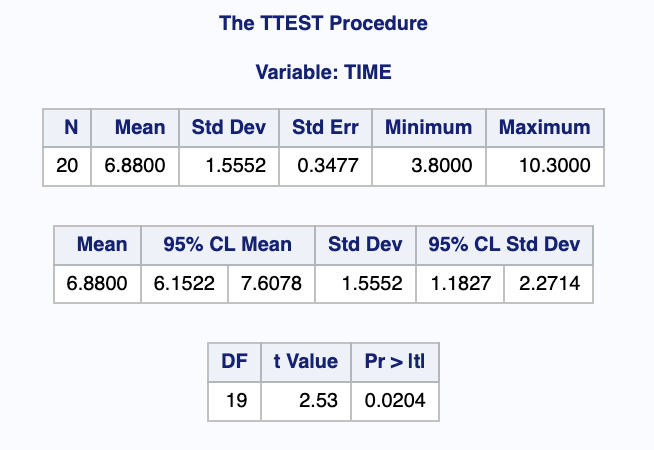
(a) 출력결과에 의해 제품의 평균수명시간의 95% 신뢰구간은 ( 6.1521 , 7.6078 ) 이다.
(b)
-
귀무가설, 대립가설 설정
귀무가설(H0) : =0 , 대립가설(H1) :>6
-
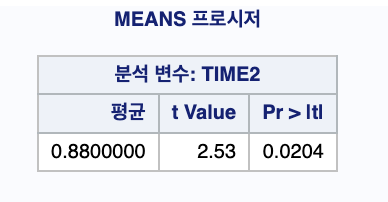
T값이 2.53 이다.
-
p-value 단측 검정을 해야하므로 0.0204를 2로 나눔
: 0.0102 (유의 수준 5%) <0.05 -
H1 을 채택하고, H0 를 기각한다.
제품의 평균수명시간이 6시간보다 길다는 강한 증거가 유의수준 5%에서 나타났다.
T-Test를 이용한 모평균비교
TTEST를 시행하면 등분산(Equal)인 경우와 이분산(Unequal)인 경우가 출력되므로 등분산성의 F-검정 결과에 따라 골라서 사용해야 한다.
즉, F-검정의 유의확률인 Prob>F'의 값이
5% (또는 1%) 이상이면 등분산(Pooled)
5% (또는 1%) 이하이면 이분산(Satterthwaite)
을 선택하여 t-검정 결과의 유의확률을 사용한다.

예 6.6
한 페인트 제조회사에서는 새 상품의 유성페인트를 개발하여 기존의 페인트와의 건조속도를 비교하고자 한다. 이를 확인하기 위해 시중에서 가장 인기있는 상품과 새상품을 각각 5종류의 벽에 칠한 후 건조시간을 측정하였다.
새 상품은 기존의 인기상품보다 건조시간이 더 빠르다고 할 수 있는가? 유의 수준 5%에서 검정해보자.
<건조시간(단위:분)>
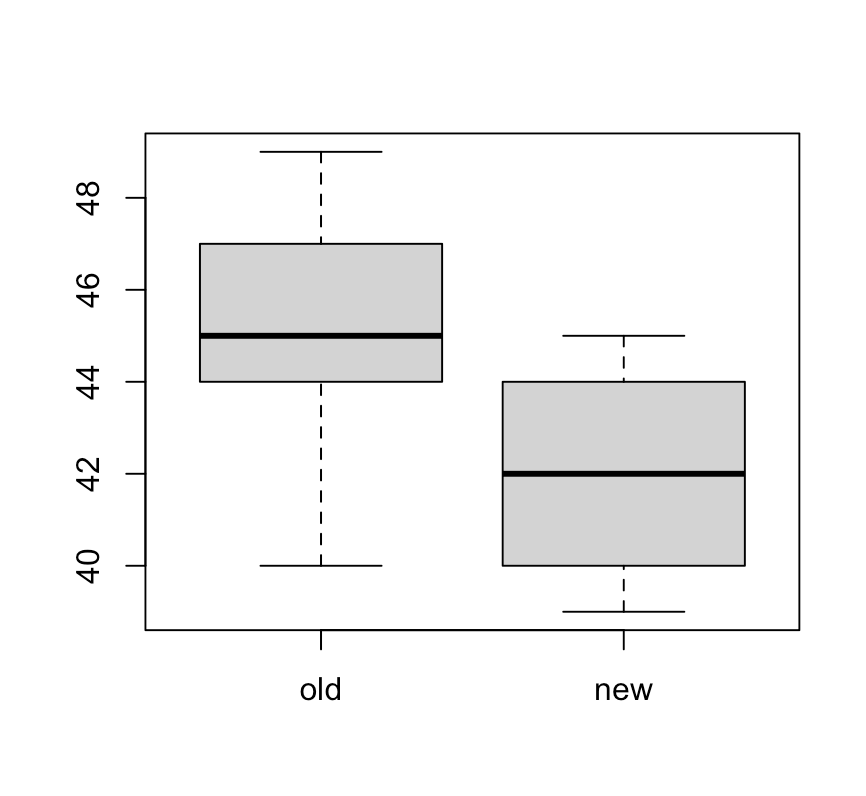
인기 상품 49 44 47 44 46 40 48 45 45 42
새 상품 44 41 45 44 43 39 42 40 40 42기존의 페인트의 평균 건조시간을 , 새 상품의 평균 건조시간을 라하면, 검정하려는 가설은 다음과 같다.
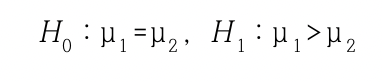
SAS 프로그램
/*PAINT.SAS : 두 표본의 모평균 비교 */
DATA PAINT; /* 데이터의 생성 */
INPUT GROUP $ TIME@@; /* 변수 읽기 , 문자형 변수 ($)*/
CARDS;
X1 49 X1 44 X1 47 X1 44 X1 46
X1 40 X1 48 X1 45 X1 45 X1 42
X2 44 X2 41 X2 45 X2 44 X2 43
X2 39 X2 42 X2 40 X2 40 X2 42
;
RUN;
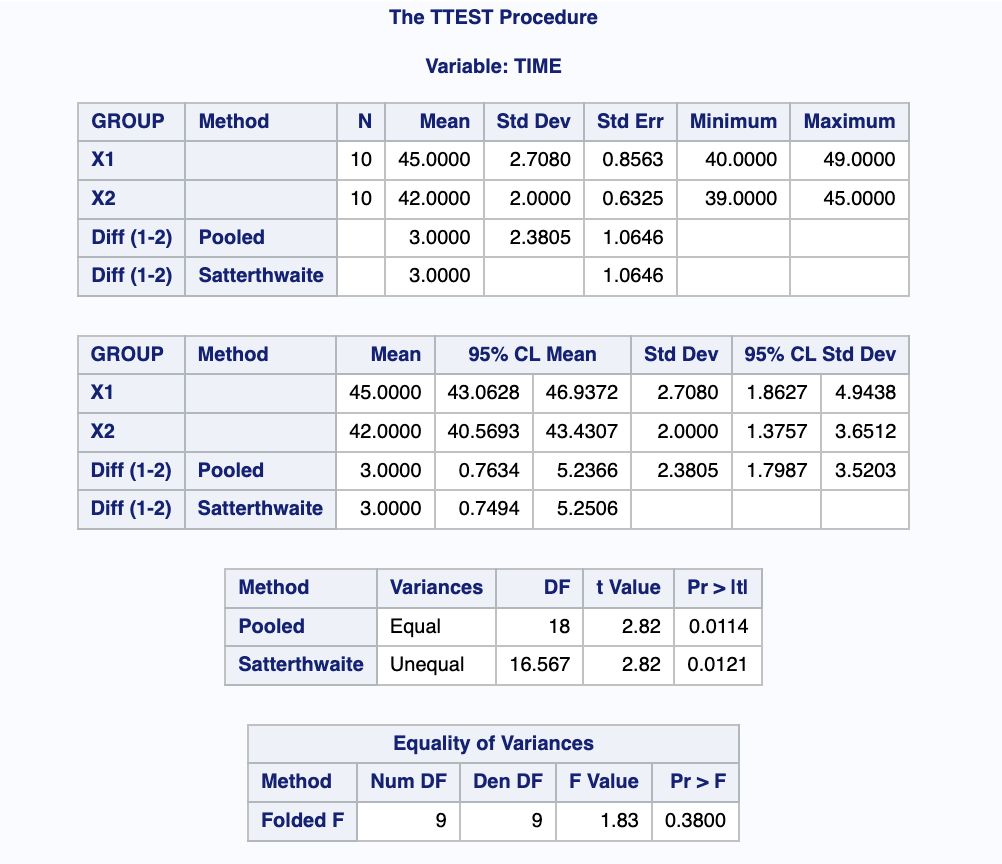
PROC TTEST DATA=PAINT; /* 평균과 분산에 대한 검정 */
VAR TIME;
CLASS GROUP;
RUN;
PROC GPLOT DATA=PAINT;
PLOT TIME*GROUP;
RUN;
출력결과
R 프로그램
x1 = c(49 ,44 ,47, 44, 46, 40, 48, 45, 45, 42)
x2 = c(44 ,41 ,45, 44, 43, 39, 42, 40, 40, 42)
# cbind : x1,x2를 col으로 붙임
paint = cbind(x1,x2)
paint = as.data.frame(paint)
boxplot(paint$x1,paint$x2, names = c("old","new"))
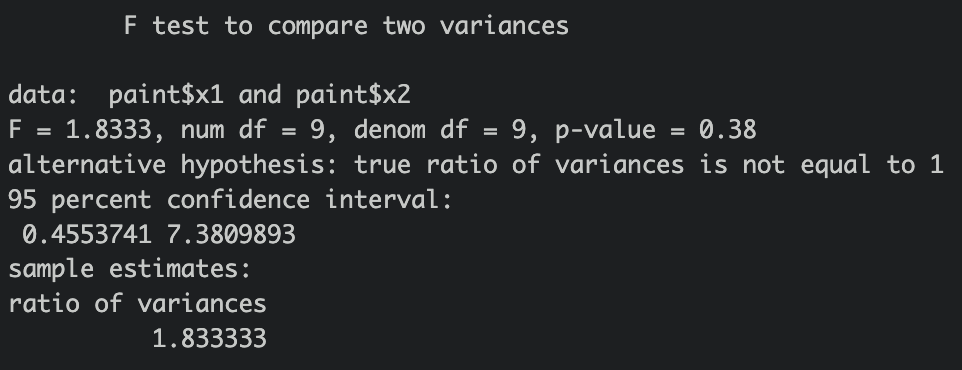
var.test(paint$x1,paint$x2)
t.test(paint$x1,paint$x2,paired=FALSE,var.equal=TRUE,alternative = "greater")
출력결과
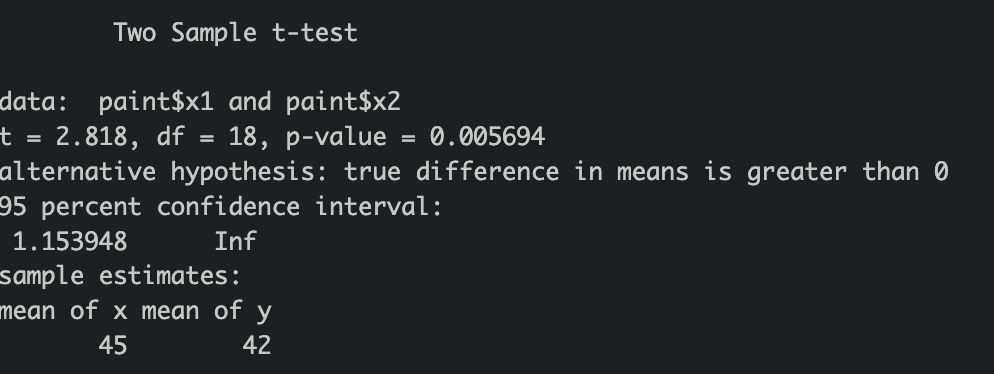
-
귀무가설, 대립가설 설정
귀무가설(H0) : = , 대립가설(H1) : >
-
T값이 2.818 이다.
Prob>F'의 값이 0.38 > 0.05이므로, 등분산을 선택함
-
p-value 단측 검정을 해야하므로 0.0114를 2로 나눔
: 0.0056 (유의 수준 5%) < 0.05 -
H1 을 채택하고, H0 를 기각한다.
새 상품이 기존의 상품보다 우수하다는 증거가 유의수준 5%에서 나타났다.
실습1.
질산칼륨의 과다 섭취가 성장을 저해하는 증거가 있는지를 알아보기 위하여 16마리의 쥐를 대상으로 실험을 하였다. 이들 중 9마리를 랜덤추출하여 2000ppm의 질산칼륨을 섭취하게 하고, 나머지 7마리는 일상적인 식사를 하게 하였다. 일정기간 후에 이들의 체중 증가율(%)을 조사하였다. 질산칼륨의 과다섭취가 성장을 저해하는 증거가 있는가를 유의수준 5%에서 검정하고 유의확률도 구하여라.
< 체중 증가율 (%) >
질산 칼륨 섭치군 12.7 19.3 20.5 10.5 14.0 10.8 16.6 14.0 17.2
규정식 섭취군 18.2 32.9 10.0 14.3 16.2 27.6 15.7SAS 프로그램
/*KNO3.SAS: 두 표본의 모평균 비교
X1:질산칼륨 섭취군 X2:규정식 섭취군 */
DATA KNO3; /* 데이터의 생성 */
INPUT GROUP $ WEIGHT@@; /* 변수 읽기 */
CARDS;
X1 12.7 X1 19.3 X1 20.5 X1 10.5
X1 14.0 X1 10.8 X1 16.6 X1 14.0
X1 17.2 X2 18.2 X2 32.9 X2 10.0
X2 14.3 X2 16.2 X2 27.6 X2 15.7
;
RUN;
PROC TTEST DATA=KNO3; /* 평균과 분산에 대한 검정 */
VAR WEIGHT;
CLASS GROUP;
RUN;출력결과
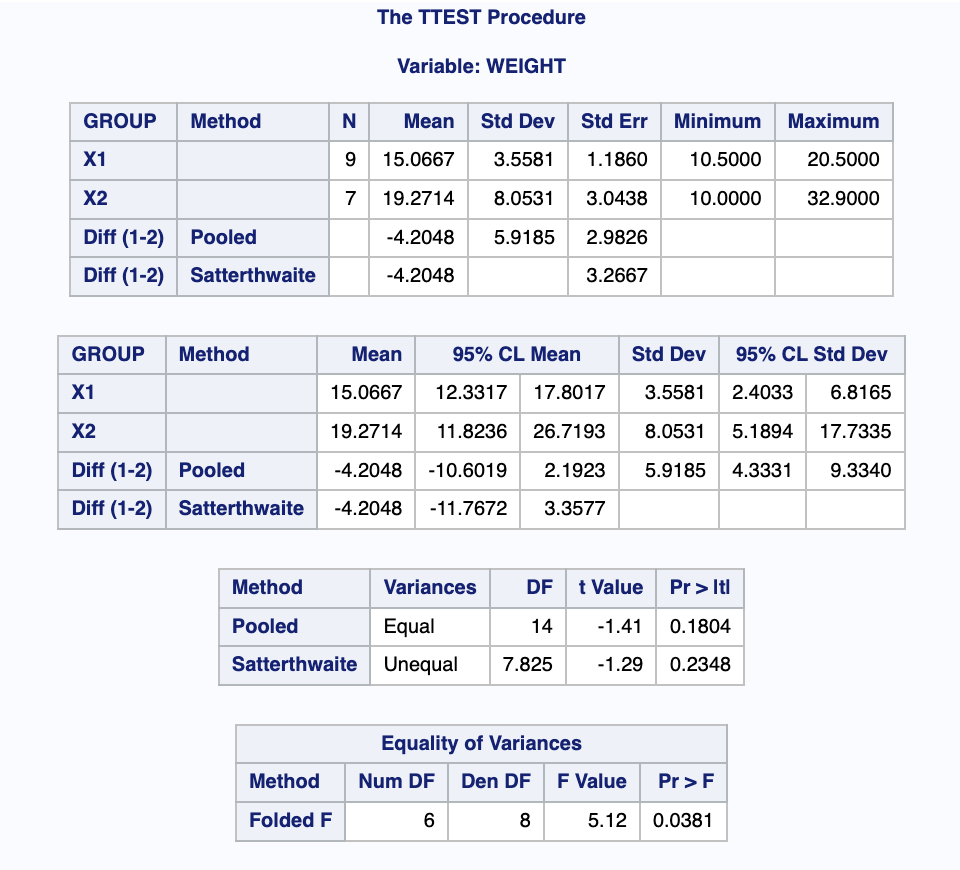
R 프로그램
# 6-6 실습1.
y1 = c(12.7, 19.3, 20.5, 10.5, 14.0, 10.8, 16.6, 14.0, 17.2)
y2 = c(18.2, 32.9, 10.0, 14.3,16.2, 27.6, 15.7)
boxplot(y1,y2,names = c("y1","y2"))
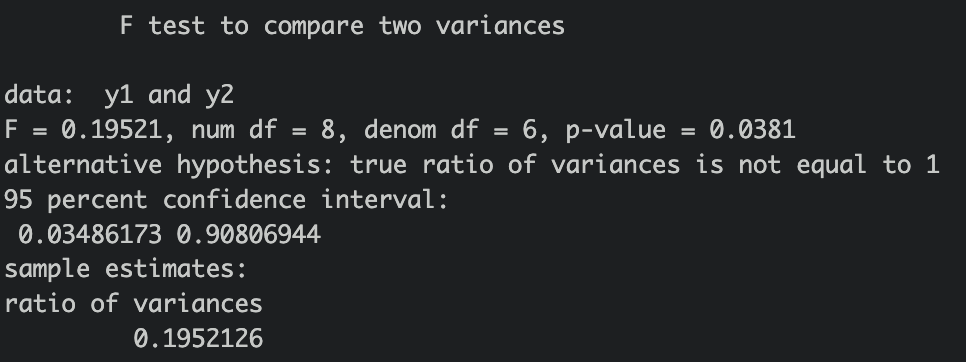
var.test(y1,y2)
# alternative "less" : m1<m2 , paired가 아니므로 false
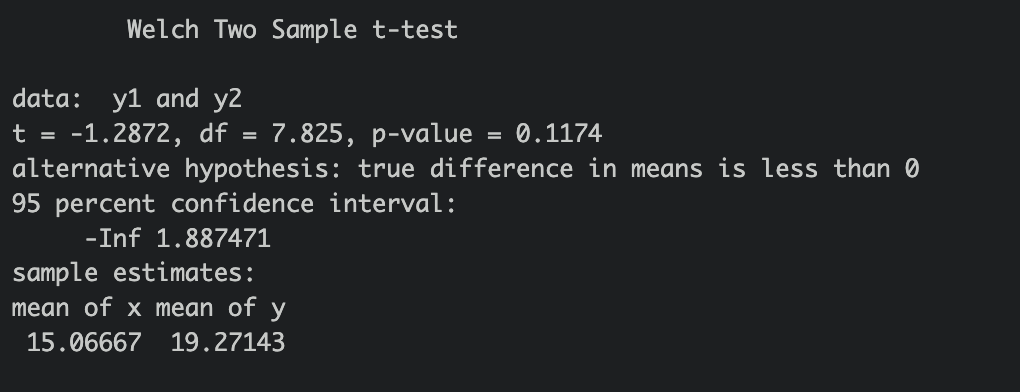
t.test(y1,y2,paired=FALSE,var.equal=FALSE,alternative = "less")
# ttest 검정통계량식(이분산)
mu1 <- mean(y1)
mu2 <- mean(y2)
n1 <- length(y1)
n2 <- length(y2)
sd1 <- sd(y1)
sd2 <- sd(y2)
numer <- mu1 - mu2
denom <- sqrt(sd1^2 / n1 + sd2^2 / n2)
t<-numer /denom
# 7.825 : 자유도
pval <- pt(t, 7.825, lower.tail = TRUE)
# 등분산 가정을 하지 않을 때 : (Welch's t-test) 자유도 계산이 조금 어려움.
출력결과
-
귀무가설, 대립가설 설정
귀무가설(H0) : = , 대립가설(H1) : <
alternative = "less" 로 설정
-
T값이 -1.2872 이다.
Prob>F'의 값이 0.038 < 0.05이므로, 이분산을 선택함
-
p-value 단측 검정을 해야하므로 0.2348를 2로 나눔
: 0.1174 (유의 수준 5%) > 0.05 -
H0 을 채택하고, H1 를 기각한다.
질산칼륨 섭취가 성장을 저해한다는 증거는 유의수준 5%에서 나타나지 않았다.
