Reference
안드로이드 멀티스레딩 - Efficient Android Threading
레퍼런스를 먼저 밝히고 시작하겠다. 이 포스팅은 위 책을 읽고 한 파트를 정리한 포스팅이다
읽으면서 인사이트를 가진 부분이나 새로 안 사실들 혹은 기존에 알고 있던 걸 명확하게 정리하기 위해 작성한다.
먼저 모든 안드로이드 응용프로그램(app)은 자바 언어가 가진 멀티스레드 프로그래밍 모델을 따라야한다.
멀티스레딩은 성능과 반응성 개선을 가져오지만, 복잡성 또한 증가한다. 우린 이에 관해 한 번 알아보자!
스레드의 기본
소프트웨어 프로그래밍이란 결국 작업을 수행하기 위해 하드웨어로 명령어를 지시하는 일이다.
이 명령어는 CPU가 순차적으로 처리하는 응용프로그램 코드로 정의하는데, 이 응용프로그램 코드를 스레드의 고수준 정의라고 한다.
App 관점에서 스레드는 자바 문장들로 이루어진 코드 경로의 실행이 된다.
또한, 질서 정연하게 하나의 스레드에서 실행하는 작업의 단위를 태스크라고 한다.
스레드는 순차적으로 하나 또는 다수의 태스크를 실행할 수 있다.
실행
안드로이드 앱 스레드는 java.lang.Thread에 의해 표현되는데, java.lang.Runnable 인터페이스 구현인 태스크의 실행을 지원한다.
다들 잘 알다시피 혹은 봤다시피 인터페이스의 run() 메서드 안에 태스크를 정의한다.
private class MyTask implements Runnable {
public void run() {
int i = 0; // 여기서 호출되는 직간접적 지역변수는 모두, 스레드의 지역 스택에 저장
}
}그리고 실행은 thread = Thread(new MyTask()), thread.start()로 실행한다
운영체제 레벨에서 스레드는 명령어 포인터와 스택 포인터 두 가지를 가지고 있다.
-
명령어 포인터 : 다음 실행할 명령어를 가리키고
-
스택 포인터 : 스레드의 지역 데이터를 저장하는 전용 메모리 영역을 가리킨다 (다른 스레드에서 접근할 수 없는 영역)
일반적으로 스레드의 지역 데이터는 해당 앱의 자바 메서드에서 정의된 변수 리터럴이다.
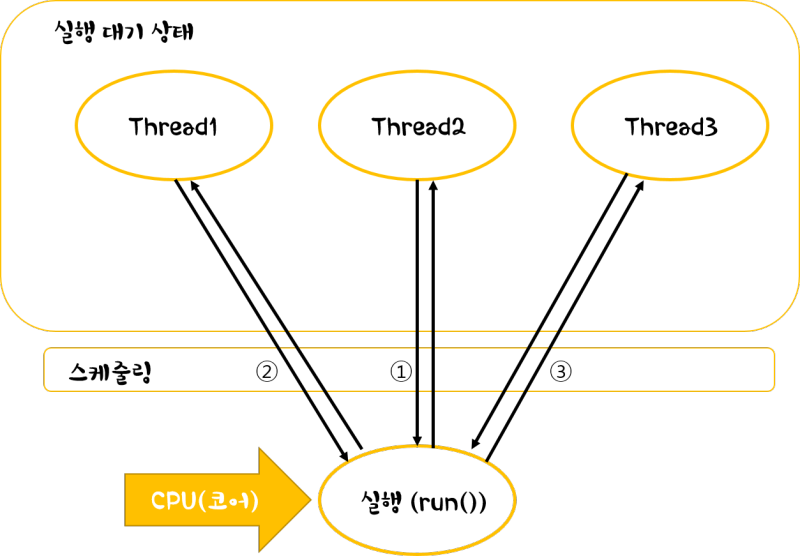
그리고 CPU는 한번에 하나의 스레드 명령어를 처리할 수 있어서 스레드의 우선순위를 두고 문맥교환으로 스케줄링을 한다.
싱글스레드 응용프로그램
각 앱은 실행 코드 경로를 정의하는 하나 이상의 스레드를 가진다. 만약 더 많은 스레드가 생성되지 않으면, 모든 코드는 같은 코드 경로를 따라 처리되며, 명령어는 처리되기 전에 모든 선행 명령어가 완료될 때까지 기다려야 한다.
그래서 싱글스레드 환경에서 UI 이벤트는 이전 명령어가 실행을 마칠 때가지 지연되므로 성능과 반응성이 저하될 수 있다.
즉, 앱을 여러 개의 코드 경로로 실행해야 한다.
멀티스레드 응용프로그램
멀티스레드를 통해 동작이 동시에 실행되는 것으로 인식하도록 앱 코드를 여러 코드 경로로 분할할 수 있다. 실행하는 스레드의 수가 프로세서의 수를 초과하면 완벽한 동시성이 될 수 없다.
그러나 스케줄러는 스레드를 빠르게 전환하며 순차적으로 처리되는 실행 간격 안에 모든 코드 경로를 분리하여 처리한다.
여기까지 보면 알겠지만, 앱에 멀티스레딩은 필수적이다. 그러나 이렇게 향상된 성능에는
- 복잡성 증가
- 메모리 소비 증가
- 불확정적(비결정적)인 실행 순서
가 동반되며 앱이 관리해야하는 몫으로 남겨졌다.
자원소비 증가
메모리와 프로세서 사용량 측면에서 스레드는 오버헤드를 동반한다. 더 많은 스레드가 실행될수록 더 많은 cs가 일어나고 성능이 저하될 수 있다.
복잡성 증가
싱글스레드 앱은 실행 순서를 알 수 있어서 실행을 분석하기 간단하다. 그러나 멀티스레드 응용프로그램은 어떻게 프로그램이 실행되고 코드가 어떤 순서로 진행되는지 분석하기 어렵다.
사전에 스케줄러가 스레드 실행 시간을 할당하는 방법을 알지 못하는 한, 스레드 간 실행 순서는 불확정적이다.
그럼 이 불확정으로 인해 코드의 오류를 디버깅하기 어려워지고, 새로운 오류를 낳을 위험도 생긴다
데이터 불일치
자원 접근 순서가 불확정적일 때 멀티스레드 프로그램에서는 2개 이상의 스레드가 공유 자원을 사용할 경우 문제가 생긴다.
example)
public class RaceCondition {
int sharedResource = 0;
public void startTwoThreads() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
sharedResource++;
}
});
t1.start();
Thread t2 = new Thread(new Runnable() {
@Ovveride
public void run() {
sharedResource--;
}
}).start();
}이 때 sharedResource는 race condition에 노출된다.
그래서 하나의 스레드가 인터럽트되지 않아야 하는 코드 부분을 실행하는 동안 문맥 교환(cs)이 발생할 수 있으므로, 항상 다른 스레드의 간섭없이 순차적으로 실행되는 코드 명령어의 원자 영역(atomic region)을 만드는 것이 필요하다.
하나의 스레드가 원자 영역에서 실행하고 있으면 다른 스레드는 원자 영역에서 실행하지 못하도로 차단된다.
자바에서 원자 영역은 하나의 스레드만 접근할 수 있기 때문에 상호 배탁적이라고 불린다.
이 원자 영역은 여러 가지 방법으로 만들 수 있지만, 가장 기본적인 동기화 메커니즘은 synchronized 키워드다.
synchronized (this) {
sharedResource++;
}공유 자원에 대한 모든 접근이 동기화되면 멀티스레드로 접근해도 접근해도 데이터의 일관성이 유지된다.
이 책에서 말할 이야기들은 대부분의 스레딩 메커니즘 이러한 오류의 위험을 줄일 수 있도록 설계되었다.
스레드 안전
thread safety하다는 이야기는 뭘까?
여러 스레드에서 객체에 접근할 때 객체가 항상 정확한 상태를 유지해야 스레드 안전이 보장된다.
스레드 안전은 상태에 대한 접근을 제어할 수 있도록 객체의 상태를 동기화함으로써 가능해진다.
컴공이라면 운영체제를 배울것이고 지금까지도 충분히 익숙한 이야기겠지만, 또 익숙한 이야기가 하나 더 나온다.
이 때 동기화는 하나의 스레드에 의해 변경되는 도중에 다른 스레드의 접근이 가능한 모든 변수를 읽거나 쓰는 코드에 적용되어야 한다. 이러한 코드 영역을 "임계 영역"이라고 한다.
그리고 이 임계 영역은 잠금 메커니즘(locking mechanism)으로 만들어지고 하나의 스레드가 임계 영역에서 실행을 완료할 때 까지 임계 영역에 진입하려는 다른 모든 스레드는 차단된다.
안드로이드는 다음과 같은 잠근 메커니즘을 포함한다
- 객체 암시적 잠금 (object intrinsic lock)
- synchronized 키워드
- 명시적 잠금 (explicit lock)
- java.util.concurrent.locks.ReentrantLock
- java.util.concurrent.locks.ReentrantReadWriteLock
암시적 잠금과 자바 모니터
synchronized 키워드는 모든 자바 객체에서 사용할 수 있는 암시적 잠금으로 동작한다.
암시적 잠금은 상호 배타적인데, 이는 임계 영역에서 스레드의 실행이 한 스레드에 독점적임을 의미한다.
암시적 잠금은 아래 그림 모니터처럼 작동한다.
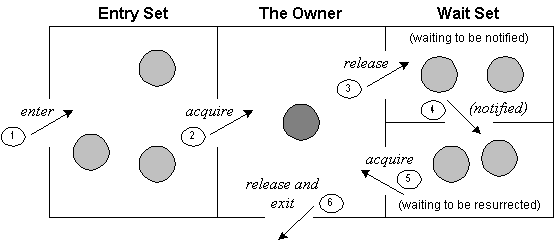
- Entry set (차단된 스레드)
- 다른 스레드에 의해 해제될 모니터를 기다리는 동안 일시 중단된 스레드 - The Owner (실행 중인 스레드)
- 모니터를 소유하고 현재 임계 영역에서 코드를 실행 중인 스레드 - Wait Set (대기 스레드)
- 임계 영역의 끝에 도달하기 전에 자발적으로 모니터의 소유권을 포기한 스레드. 이 스레드는 다시 소유권을 얻을 때까지 소유권의 신호를 기다린다.
1) 모니터 진입 -> 2) 잠금 획득 -> 3) 잠금 해제 및 대기 -> 4)~5) 신호 후 잠금 획득 -> 6) 잠금 해제 및 모니터 종료
위 순서가 아래 코드로 봐보자
synchronized (this) { (1)
//running code (2)
wait(); (3)
//running code (4)~(5)
}(5)공유 자원 접근의 동기화
동시 실행 중에 일관된 데이터를 유지하기 위해 동기화 전략이 필요하다. 이 전략은 상황에 따른 올바른 잠금 종류를 선택하고 임계 영역의 범위를 설정하는 것을 포함한다.
암시적 잠금 사용
- 객체 인스턴스를 둘러싸는 암시적 잠금으로 작동하는 메서드 레벨
synchronized void changeSatate() {
sharedResource++;
}- 객체 인스턴스를 둘러싸는 암시적 잠금으로 작동하는 블록 레벨
void changeSatate() {
synchronized(this) {
sharedResource++;
}
}-> 코드의 정확한 블록을 제어할 수 있고 보호될 상태와 관련된 코드만 줄여서 다룰 수 있다
필요 이상으로 원자 영역을 크게 만드는 것은 나쁜 습관.
필요하지 않은 곳까지 다른 스레드를 차단할 수 있고, 이는 응용프로그램의 느린 실행을 가져올 수 있다.
- 다른 객체의 암시적 잠금을 가지는 블록 레벨
private final Object mLock = new Object();
void changeSatate() {
synchronized(mLock) {
sharedResource++;
}
}- 클래스 인스턴스를 둘러싸는 암시적 잠금으로 작동하는 메서드 레벨
synchronized static void changeSatate() {
staticSharedResource++;
}- 클래스 인스턴스를 둘러싸는 암시적 잠금으로 작동하는 블록 레벨
static void changeSatate() {
synchronized(MyClass.class) {
staticSharedResource++;
}
}정적 메서드에 대한 동기화는 인스턴스 객체가 아닌 클래스 객체의 암시적 잠금으로 동작한다.
명시적 잠금 메커니즘 사용
좀 더 향상된 고급 잠금 전략은 synchronized 키워드 대신 ReentrantLock / ReentrantReadWriteLock 클래스를 사용한다.
임계 영역은 코드의 특정 부분에 대한 명시적 잠금 및 해제에 의해 보호받는다.
int sharedResource;
private ReentrantLock mLock = new ReentrantLock();
public void changeState() {
mLock.lock();
try {
shraedResource++;
} finally {
mLock.unlock();
}
}synchronized 키워드와 ReentrantLock은 같은 의미를 가진다.
한 스레드가 이미 임계 영역에 들어온 경우 임계 영역을 실행하려는 다른 모드 스레드를 차단하기 대문이다.
이는 '멀티스레드가 동시에 공유 변수를 읽는 것이 유해하지 않다'고 가정하는 방어적인 전략이다. 따라서 이들은 과잉보호로 이어질 수도 있다.
ReentrantReadWriteLock을 한 번 보자.
얘는 읽으려는 스레드는 동시에 실행되게 내버려두지만, 읽기 대 쓰기, 쓰기 대 쓰기의 경우는 차단한다.
int sharedResource;
private ReentrantReadWriteLock mLock = new ReentrantReadWriteLock();
// 공유 자원의 값을 변경하는 메서드(임계 영역에 하나의 스레드만 접근 가능)
public void changeState() {
mLock.writeLock().lock();
try {
shraedResource++;
} finally {
mLock.writeLock().unlock();
}
}
//공유 자원의 값을 읽는 메서드 (여러 스레드에서 동시 접근 가능)
public int readState() {
mLock.readLock().lock();
try {
return shraedResource;
} finally {
mLock.readLock().unlock();
}
}ReentrantReadWriteLock은 스레드가 허용 또는 차단할 수 있는 지 확인하므로 앞서 두 개의 방법들보다 상대적으로 복잡하고, 성능 저하를 가져올 수 있다.
따라서 동시에 공유 자원을 읽게 두는 것 <-> 평가의 복잡성에서 오는 성능 손실 의 상호 절충이 있는 셈.
여러 읽기 스레드와 약간의 쓰기 스레드가 있는 케이스에서는 좋은 사용 사례가 될 것이다.
마치며
안드로이드 앱은 싱글 혹은 멀티프로세서 플랫폼에서 성능을 향상하기 위해 멀티스레드로 만들어야 한다.
하나의 프로세서에서 실행을 공유하거나 or 멀티프로세서를 사용할 수 있을 때 진정한 동시성을 활용할 수 있다.
향상된 성능은 복잡성이 증가하기도 하지만, 스레드간의 공유 자원을 보호하고 데이터 일관성을 유지해야 하는 책임을 비용으로도 가져오기도 한다.
우리 앱이 왜 멀티스레드가 필수인지, 앱에서 어떤 전략으로 동시성을 유지하는지 조금이나마 알 수 있었던 파트였다.
synchronized 키워드는 익숙한데 나머지 클래스들은 이 책을 통해 처음 접해봤다.
오랜만에 운영체제 공부한 것도 상기시키면서 정리할 수 있었다!

감사합니다.