Android 앱 설계 방법: 규칙이 아닌 원칙에 대한 심층 분석
이 포스팅은 아래 글을 번역하며 이해하기 위해 작성된 글이다. 자세한 건 아래 링크를 확인하시길!
우리는 어떻게 하면 앱을 잘 설계할 수 있을까?
보통 무언가 제대로 방법을 알아내 개발하는 것보다 쉽게 수정하며 유지보수하는게 쉬운 앱에서 개발해 왔을 것이다. 그러나 수정에 대한 사이드 이펙으로 수백 개의 버그가 튀어나오기도 한다.
이것들은 모두 나쁜 아키텍트의 특징이다.
이 글은 저자의 또 다른 글인 Don't Fight The Architecture를 바탕으로 앱을 잘 설계하는 방법에 대한 것이다.
The right way to do it
앱을 잘 설계하면 앱이 안전하고 안정적이며 테스트 및 유지 관리가 가능하다. 어떤 백엔드를 사용할지 결정을 미루고 나중에 이러한 결정을 하도록 비교적 쉽게 되돌릴 수 있다. 그리고 우리 개발자들에게 가장 중요한 것은 분리가 필요한 부분을 올바르게 분리하는 명확한 "올바른 방법"을 아는 것이다. 즉, 연차가 가장 적은 주니어 개발자도 팀에서 유용하게 적용할 수 있다.
물론 소프트웨어를 설계하는 "올바른" 방법에 대한 많은 의견이 있다. 따라서 이 글에서 말하려는 것은 아키텍처의 기본 원칙을 제공하여 자신의 앱에 적합한 것이 무엇인지 스스로 결정할 수 있도록 하는 것이다. 즉 이 글은 규칙이 아니라 원칙에 관한 것이다.
훌륭한 건축가가 되려면 규칙이 아닌 원칙을 배우자. 그렇게 하면 소프트웨어와 팀에 적합한 아키텍처로 커스텀할 수 있다.
SOLID Rules
객체지향 중 SOLID는 사실 설명을 잘 해놓았기 때문에.. 여기선 원칙 측면에서 간략하게 말하겠다.
S = 책임 분리
클래스나 모듈이 변경해야 하는 이유가 하나만 있어야 한다는 원칙. 또는 동등하게 하나의 액터에게만 책임을 져야 한다.
O = 개폐
코드는 기존 코드를 수정하는 것이 아니라 코드를 추가하여 새로운 기능을 추가할 수 있도록 해야 한다.
L = 리스코프 치환
이 원칙은 기본 클래스 대신 파생 클래스를 사용할 수 있어야 한다. 가장 중요한 것은 기본 클래스 파생(자식 클래스)에서 기본 클래스의 의미를 변경하려고 시도해서는 안 된다.
I = 인터페이스 분리
클라이언트는 자신에게 적합하지 않은 인터페이스를 사용하도록 강요해서는 안 된다. 하나의 큰 메서드 인터페이스 대신 작은 한두 개의 메서드 인터페이스를 많이 갖는 것이 나쁠 것은 없다.
D = 종속성 역전
고수준의 클래스는 저수준의 클래스에 의존해서는 안 된다. 대신 둘 다 추상화에 의존해야 한다.
종속성 역전 원칙을 올바르게 적용하면 아키텍처 경계가 올바르게 형성된다. 어떻게 작동하는지 다음 파트에서부터 자세히 보자
Architectural boundaries and dependency inversion
사람들이 자신의 프로필을 만들고 저장할 수 있는 앱이 있다고 가정해보자. 이를 위해 Firebase를 사용한다.
처음의 구현은 다음과 같다.

여기서 클래스는 Firebase를 사용하여 프로필을 저장하는 User 메서드를 호출한다.
User 이 클래스는 비즈니스 로직을 포함하고 있기 때문에 고수준 클래스다.(즉, 시스템에서 데이터를 읽고 쓰는 방법에 대한 세부 사항이 아닌 순수한 로직이 있음)
반대로 FirebaseProfileSaver는 특정 기술을 위해 작성된 코드와 같은 구현 세부 사항을 포함하기 때문에 소위 저수준 클래스라 한다.
이 레이아웃은 상위 수준이 하위 수준에 종속되기 때문에 종속성 역전 원칙을 깨뜨린다.
User 클래스에는 import x.y.FirebaseProfileSaver로 참조되어 있을 것이다.
종속성이 제거된 두 개의 레이어(예: User imports X, Imports Y, Imports Y는 Firebase ProfileSaver)일 수 있다. 그러나 중요한 점은 User에서 FirebaseProfileSaver로 이어지는 종속성 방향으로 화살표를 그릴 수 있다는 것이다.
왜 문제일까?
문제는 바로 FirebaseProfileSaver 변경 사항에 대해 영향을 받는 것이다. 언젠가 Firebase SDK가 변경되면 분명히 FirebaseProfileSaver도 변경해야 한다. 그러나 User가 Fire..뭐시기를 의존하고 있으므로 영향을 받는 걸 막을 수 없다. 변경 사항을 테스트한다는 것은 모든 것을 테스트한다는 의미이다.
그리고 그다지 유연하지도 않다. Firebase에서 다른 원격 스토리지 provider로 migration해야할 경우 앱의 많은 부분을 다시 작성해야 할 수도 있다.
종속성 역전: the “plug socket” solution("플러그 소켓" 솔루션)
해결책은 FirebaseProfileSaver가 일종의 "플러그"가 되고 User 클래스가 일종의 "소켓"이 되는 것이다.
클래스 User는 아무것도 몰라야 한다.
대신 saveProfile()에 대해서는 추상적으로 알 수 있다. User의 "소켓"에 어떤 "플러그"를 넣었는지에 관계없이(FirebaseProfileSaver 또는 RoomDatabaseProfileSaver 또는 APIProfileSaver), "소켓"은 모두 동일한 방식으로 작동하기 때문에 어떻게 "소켓"과 연결해서 사용해야하는지는 알 수 있다.
따라서 FirebaseProfileSaver는 소켓에 맞는 플러그로 리팩터링된다.
그림으로 표현하면 아래와 같다.
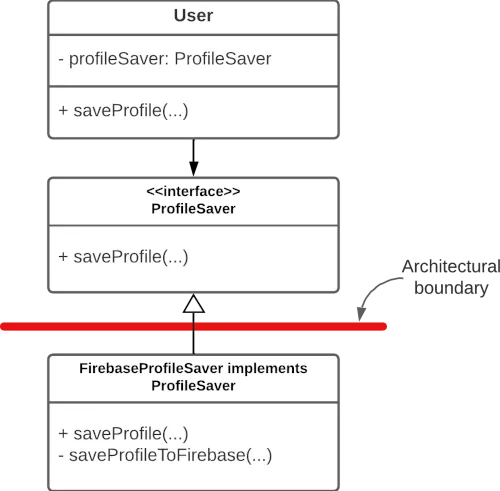
여기서 User 클래스는 추상적인 "ProfileSaver"와 대화하는 방법만 알고 있다. 중요한 것은, 여기에는 파이어베이스와 관련된 어떤 언급도 포함되어 있지 않다.
그런 다음 FirebaseProfileSaver는 ProfileSaver 인터페이스를 구현합니다. User 클래스는 이에 대한 지식이 없으므로 중요한 것은 Firebase 작동 방식에 대한 논리를 기반으로 하지 않는다.
이렇게 하면 Firebase 로직이 분리된다. 저수준 코드와 고수준 코드 사이에 위의 다이어그램과 같이 빨간색 선을 그릴 수 있다. 이 빨간색 선은 건축 경계이다.
종속성 화살표가 어떻게 낮은 수준에서 높은 수준으로 위쪽을 가리키는지 확인해보자. User 클래스에서 시작하여 Firebase에서 끝나는 종속성 화살표 시퀀스는 더 이상 없다.
Where should architectural boundaries go?
따라서 아키텍처 경계의 올바른 배치는 좋은 아키텍처에 필수적이다. 그러나 이 경계가 많을수록 더 좋아 보일 수 있지만 사실이 아니다.
Architectural boundaries에는 유지 관리 오버헤드가 있다. 그들은 더 많은 코드를 생성하고 일단 경계가 설정되면 미래의 모든 개발자는 이를 따라야한다.
(나 또한 이 문장에 동의한다. 많은 캡슐화는 필요도 없는데 interface를 매번 만들어줘야 한다.. 이건 매우 귀찮기도 하다)
그리고 경계가 있는 코드는 가독성이 훨씬 떨어진다. User 클래스에서의 profileSaver.saveProfile() 메서드 호출이 실제로 Firebase 로직을 트리거한다는 것이 고수준 클래스에서 코드로만 봤을 때, 명확하지 않다.
따라서 새로운 개발자를 온보딩하는 것이 조금 더 까다로워지고 코드 검토가 약간 더 어려워진다.
이 아키텍처 경계가 어디로 가는지 합리화하려는 한 가지 시도가 바로 클린 아키텍처다.
How about Clean Architecture for Android apps?
베테랑 건축가 Robert C Martin이 수집한 일련의 원칙인 Clean Architecture는 부분적으로 소프트웨어를 아키텍처 경계로 구분된 선택된 레이어 세트로 합리화하는 방법을 제공했다.
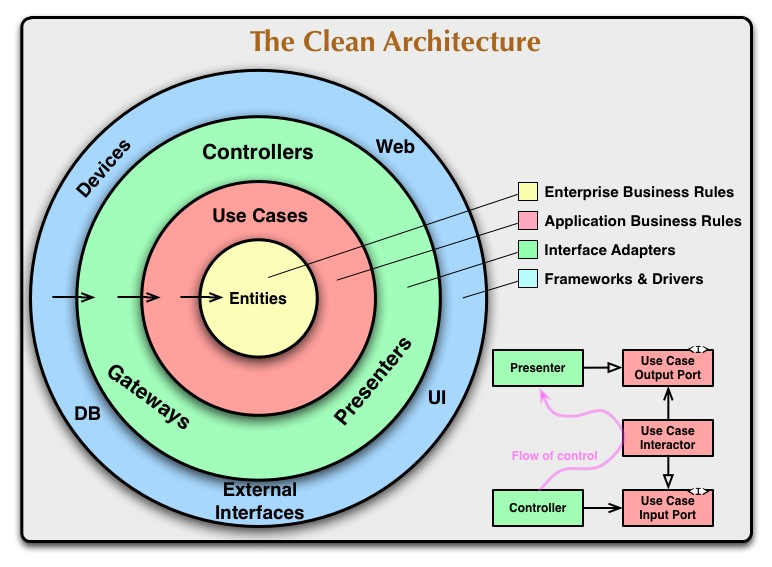
이 계층 다이어그램은 중앙에 고수준 코드(즉, 순수 논리)가 있고 외부에 저수준 코드가 있다. 이는 낮은 수준의 코드가 높은 수준의 코드에 의존할 수 있지만 그 반대는 절대 없다는 종속성 규칙(본질적으로 SOLID의 종속성 역전 원칙의 결과)에 의해 정의된다. 따라서 종속성을 나타내는 위의 화살표는 항상 안쪽을 가리키게 된다.
그렇다면 이러한 레이어는 무엇으로 구성되어 있을까?
Usecases 및 Entities (노란색 및 빨간색 원)
클린 아키텍처 다이어그램의 중앙에 사용 사례 및 엔터티 레이어가 있다. 여기에는 앱의 비즈니스 로직이 포함된다. 이는 구현 세부 사항과 아무 관련이 없는 앱의 동작을 제어하는 순수한 논리다.
만약 사용자 프로필을 저장하는 시나리오가 있다고 가정해보자.
-
보안/일관성 검사를 실행한다. 저장 중인 프로필에 유효한 데이터가 포함되어 있고 사용자가 이 작업을 수행할 수 있는지 확인한다.
-
데이터를 원격으로 저장한다.
-
새 프로필을 로컬로 캐싱한다.
-
업데이트가 필요함을 UI에 알린다.
이것은 우리가 어떻게 하고 있는지 가 아니라 무엇을 하고 있는지 에 관한 것이기 때문에 이것이 모두 비즈니스 논리다. 예를 들어 2단계에서는 데이터를 저장하기 위해 어떤 원격 API를 사용하는지 말하지 않고 4단계에서는 업데이트할 UI가 Android 휴대전화의 화면인지 웹 페이지인지 또는 PDF인지 말하지 않는다.
Usecase는 단일 행위자의 단일 요구 사항을 나타낸다(위의 SOLID의 단일 책임 원칙 참조).
또한 포괄적인 단계 목록입니다. 프로필을 저장하기 위해 더 이상 수행해야 할 작업이 없으며 이러한 단계의 하위 집합만 실행하려고 시도하는 것은 의미가 없다.
인터페이스 어댑터(녹색 원)
유스 케이스의 세부 사항이 있는 곳이다. 예를 들어 사용 사례에서 일부 데이터를 로컬로 캐시하도록 요청하는 경우 여기에서 SQL 데이터베이스에 대해 말할수 있다.(원문에서 진짜 동사가 talk임..)
아직 특정 브랜드의 SQL 데이터베이스에 대해서는 언급하지 않았다. 독점 기술인 것은 나중에 발표된다.(이 친구가 MySQL인지 오라클인지 위 종속성 역전 이야기 했을 때를 떠올려보자)
데이터 소스가 여러 개인 경우 인터페이스 어댑터 계층에서 데이터 소스를 수집하고 불일치를 관리해야 한다.
이는 또한 거의 전체 MVVM, MVC, MVP 등의 토폴로지가 (위상수학??) 이동해야 하는 부분이기도 하다. 여기서는 Jetpack Compose 또는 Android XML에 대해 설명하지 않지만, 해당 부품이 사용할 상태를 유지한다.
프레임워크 및 드라이버(파란색 원)
여긴 독점(특정한) 기술을 사용하는 모든 것이 가는 곳. 구현 세부 정보이다.
여기에서 Jetpack Compose의 @Composable이 진행된다. 또한 HTML의 내용이 여기에 있고 Firebase 코드, API 및 SQL 명령의 세부 사항, 회의실 주석(예: @Entity)으로 표시된 모든 항목 등이 포함된다.
이 계층의 코드는 일반적으로 독점 기술에 의존하기 때문에 테스트하기 어렵다. 예를 들어 Jetpack Compose 테스트는 Jetpack Compose용으로 특별히 작성된 도구(또는 일반적으로 Android용으로 작성된 도구이지만 요점은 그대로 유지됨)에 의존한다. 따라서 이 레이어를 가능한 한 얇게 유지하는게 좋다.
논리는 상위 계층으로 이동해야 한다. 이것은 인터페이스 어댑터의 요구 사항을 사용 중인 특정 기술로 "변환"하는 데 필요한 최소한의 것이다.
이 층은 또한 휘발성이다. 사용자의 입력 없이 변경 및 중단될 수 있다. 예를 들어, 사용 중인 API가 갑자기 다른 종류의 인증을 요구하는 경우 타이밍이 적합한지 또는 변경 사항에 만족하는지 여부에 관계없이 코드를 일치하도록 변경해야 한다. 이 계층을 가능한 한 얇게 유지하면 코드베이스의 나머지 부분에서 이러한 변경의 영향이 줄어든다.
Where does Android-specific code sit in Clean Architecture?
Clean Architecture에 따르면 공식적으로 Android는 독점 기술이므로 프레임워크 및 드라이버(파란색) 계층으로 제한되어야 한다. "import android.xy" 또는 "import androidx.xy"가 있는 항목은 이 레이어를 넘어서는 안 된다.
그러나 실제로는 이 규칙을 지키기엔 매우 어려울 수 있다.
한 가지 예로, 인터페이스 어댑터 영역과 같은 view model에서 참조하는 게 더 편리하고, 읽을 수 있는 권한을 요청할 수 있다.
그래서 이것은 내가 이 글이 규칙이 아닌 원칙에 관한 것이 되기를 원했던 이유에 대한 완벽한 예다. 규칙에 맞추기 위해 거꾸로 구부리고 있다면 그 뒤에 있는 원칙을 고려하자. 프로젝트마다 관련이 있을 수도 있고 그렇지 않을 수도 있기 때문이다.
이 예에서 필자는 개인적으로 Android가 인터페이스 어댑터에 언급되도록 허용하는 것도 괜찮다고 생각한다. 결국 Android 앱을 빌드하고 있으며 언젠가 iOS 또는 웹 앱과 정확히 동일한 코드베이스를 공유할 합리적인 가능성이 없다면 Android를 언급하지 않도록 코드를 관리하는 것은 가치가 없다. 분명히 iOS 및 웹 앱에는 일반적으로 별도의 자체 코드베이스가 있기 때문이다.
What makes a good app, and how can we architect that?
결국 앱은 한 가지 일을 잘 수행해야 한다. 이 목적은 시간이 지남에 따라 많이 변하지 않으며, 삶의 많은 새로운 기능을 발전시킬 수 있지만 대상 고객은 거의 변하지 않는다(단일 책임 원칙에 따라 동일한 행위자가 있음 ).
실제로 이해 관계자가 앱이 추가 사용자 유형을 충족하도록 요청하기 시작하면 그들의 요구에 적절하게 집중할 수 있도록 그들을 위해 새 앱을 만드는 것이 더 나은 경우가 많다. Microsoft에는 단일 Office 앱이 없다. 대신 별도의 Word, Excel 및 Powerpoint 앱이 있으며 각각 요구 사항이 다른 여러 사람이 사용한다.
따라서 클린 아키텍처(안드로이드 앱에서 발생하지 않을 가능성이 있는 이러한 종류의 변경으로부터 사용자를 격리하도록 설계된 많은 원칙)는 우리의 목적에 너무 무겁다고 말할 수 있다. 많은 경우에 이 의견에 나는 동의한다.
구글도 동의하는 것 같다. Modern App Architecture라고 하는 자체 아키텍처 권장 사항은 Clean Architecture의 다소 부드러운 버전이라고 볼수도 있기 때문이다.
Google’s Modern App Architecture
구글은 3가지 계층으로 단순화시켰다.
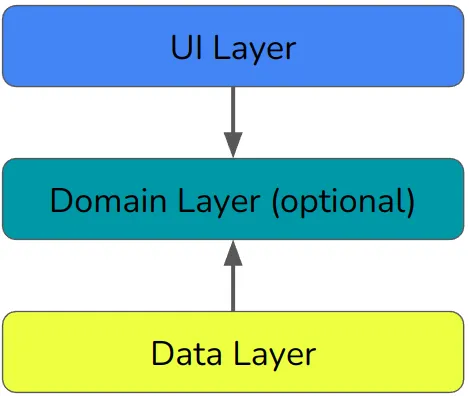
대체로 UI 레이어는 사용자의 입력과 출력을 처리하고 디스플레이를 업데이트하기 위한 것이다. 도메인 계층은 비즈니스 로직을 위한 것으로 Clean Architecture의 사용 사례와 거의 동일하다. 그리고 데이터 계층은 앱의 저장 메커니즘에서 데이터를 읽고 쓰기 위한 것이다.
이것은 단방향 아키텍처이다.(레이어드 아키텍처) 상태는 위로만 흐르고 이벤트는 아래로만 흐른다.
이 모든 것이 무엇을 의미하는지 자세히 살펴보자
UI 레이어: UI 요소 및 상태 홀더
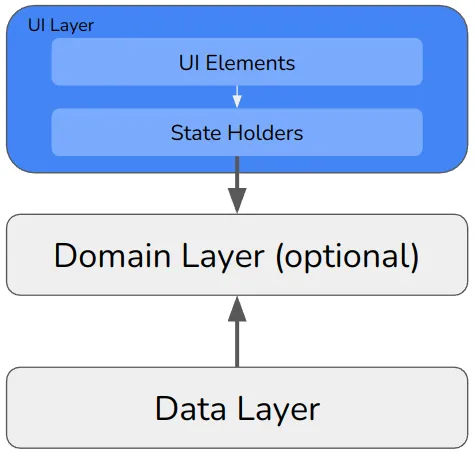
UI 레이어는 UI 요소와 상태 홀더로 나뉜다.
UI 요소 부분에는 독점 기술을 위해 작성된 코드가 독점적으로 포함되어 있다. Jetpack Composite를 사용하는 경우 여기에 @Composables를 배치한다. Fragments와 XML을 사용하는 경우도 여기에 해당된다. 하지만 다른 건 없다. 논리도 없고 데이터도 없다.
('논리 없음' 규칙은 XML 데이터 바인딩 사용자에게 어려운 경우가 있다. 예를 들어 데이터 바인딩을 사용하면 XML 코드 내에서 완전히 Celcuis/Fahrenheit 스위치를 구현할 수 있다. 이렇게 하지 말자.)
대조적으로 논리와 데이터는 상태 보유자(state holders)에게 들어간다. 그들은 UI의 상태를 유지하기 때문에 그렇게 불린다. 뷰 컨트롤러를 생각하자. 여기에는 UI 컨트롤을 지원하는 변수가 포함되어 있다. 예를 들어 UI에 텍스트 필드가 있는 경우 해당 텍스트 필드의 내용을 포함하는 변수가 여기에 존재한다.
Kotlin Flows와 같은 상태 변수를 노출하는 것이 좋다. 이는 동적 특성을 깔끔하게 캡슐화하고 UI에 업데이트해야 한다는 신호를 보내는 내장 메커니즘을 제공한다.
도메인 레이어: Usecase
도메인 계층에는 클린 아키텍처의 사용 사례와 정확히 동일한 사용 사례가 포함된다. 즉, 단일 행위자가 단일 작업을 수행하는 데 필요한 포괄적인 단계 목록들이다.
그러나 Google 아키텍처에서 이 레이어는 선택 사항이다. 즉, 순수한 비즈니스 로직을 상태 보유자(ex. viewModel)에 배치하는 데 아무런 문제가 없음을 의미한다.
비즈니스 로직이 여러 상태 보유자에서 재사용되는 경우 코드 복제를 방지하기 위해 해당 로직을 도메인 계층으로 가져오는 것이 유용할 수 있다.
예를 들어 앱의 여러 부분에서 사용자 프로필을 업데이트할 수 있다고 가정해보자. 이 경우 UpdateUserProfileUseCase를 만들고 필요할 때마다 참조할 수 있다.
데이터 레이어: Repository & Datasource
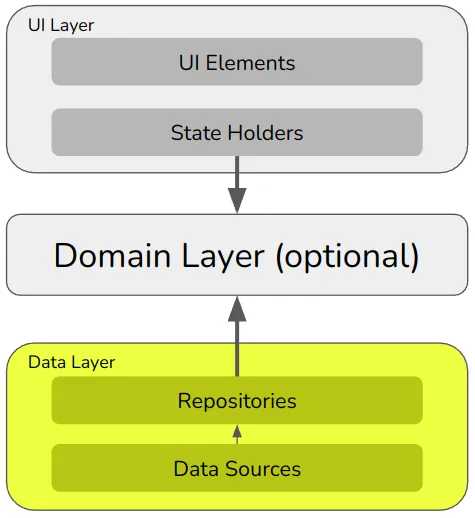
데이터 레이어는 Repository와 Datasource로 나뉜다.
저장소는 데이터 제공 및 저장을 담당한다. 이들은 getUserProfile()과 saveUserProfile(…) 메서드를 포함할 것이다.
Datasource는 API를 호출하거나 SQL 명령을 작성하는 등의 독점 작업을 수행한다.
종종 리포지토리는 여러 데이터 소스를 담당한다. 예를 들어 원격 리포지토리와 동일한 로컬 캐시에 데이터가 저장되어 있을 수 있다. 이들 각각은 별도의 데이터 소스로 구현된다. 그런 다음 사용자 프로필을 읽을 때 리포지토리는 로컬 캐시에서 읽기를 시도하고 캐시가 비어 있으면 원격 데이터베이스로 폴백할 수 있다. 이러한 방식으로 여러 데이터 소스를 담당하는 리포지토리는 사용할 소스와 동기화 방법을 조율해야 한다.
다시 말하지만 Kotlin Flows를 사용하여 호출자가 데이터를 사용할 수 있도록 하는 것이 좋다.
Comparing Google’s Modern App Architecture to Clean Architecture
모던 앱 아키텍처와 클린 아키텍처는 각각 미묘하게 다른 것을 의미하기 위해 "레이어"라는 단어를 사용한다. 아래는 함께 사용하는 방법이다.
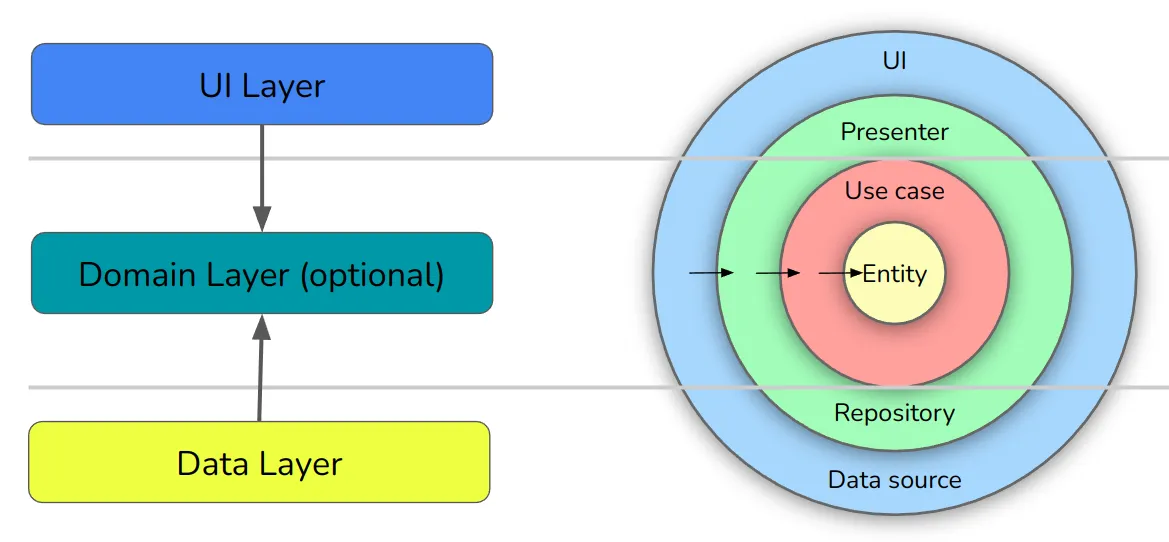
데이터 레이어와 마찬가지로 Google의 UI 레이어는 클린 아키텍처의 외부 두 링(인터페이스 어댑터, 프레임워크 및 드라이버)에 적합하다. 해당 도메인 계층은 Clean Architecture의 Usecases 및 Entities와 완전히 동일하다.
이러한 경계 중 일부는 위의 다이어그램에 표시된 것보다 약간 더 애매하다.
예를 들어 Google은 UI 레이어에 비즈니스 로직을 배치하는 데 반대하지 않는다. 이것이 자체 도메인 레이어가 선택 사항으로 표시되는 이유기도 하다.
UI 및 데이터 계층은 모두 Clean Architecture의 인터페이스 어댑터 및 프레임워크/드라이버 계층과 동일하다.
결론 및 정리
이 글은 명확하게 정리하고 영감을 얻기 위해 클린 아키텍처와 Google의 현대적인 앱 아키텍처라는 두 가지 일반적인 패러다임을 사용하여 좋은 아키텍처의 기본 원칙에 대해 깊이 파고들어봤다.
물론 이 글을 읽는 개발자의 각각 응용 프로그램에 가장 적합한 것이 무엇인지 파악하는 것은 개발자에게 달려 있다. 딱딱한 프레임워크가 아닌 생각을 제공함으로써 스스로 결정을 내릴 수 있는 툴킷이 제공됐으면 한다.
이 글을 쓴 저자는 아키텍처에 대한 구체적인 질문에 대답하는 것을 좋아하므로 원문 링크에 답변을 남기면 가능한 한 답변을 하겠다고 한다. 하나의 '정답'이 없고 토론을 할 때 가장 재미있다.
향후 글에서는 위의 내용을 사용하여 Kotlin 및 Compose에서 잘 설계된 샘플 앱을 만드는 과정을 단계별로 안내할 것이다.
저자는 20년 동안 소프트웨어 설계를 해왔고 현재 모바일 앱 전문가인 앱타우라의 공동 설립자이며 프리랜서로 뛰기도 한다고 한다!
