자료구조란?
효율적으로 데이터를 관리하고 수정, 삭제, 탐색, 저장 할 수 있는 데이터 집단.
복잡도란?
시간복잡도
문제를 해결하는 데 걸리는 시간과 입력의 함수 관계. 알고리즘이 시작되어 완료될 때까지 걸리는 시간.
시간복잡도-빅오표기법
Big-O = O(f(n))
시간복잡도를 표현하는 표기방식이며, 입력범위 n을 기준으로 로직이 몇 번 반복되는지 나타내는 것.
동전을 튕겨 뒷면이 나올 확률을 볼 때 운이 좋으면 1번 튕겨서 바로 뒷면이 나올 수 있지만 최악의 경우 n번 던져야 하는 경우가 발생할 수 있듯이 최악의 경우를 계싼하는 방식을 빅오 표기법이라 한다.
O(1) Constant
입력 데이터의 크기에 상관없이 언제나 일정한 시간이 걸리는 알고리즘.데이터의 증감은 영향을 거의 주지 않는다.
O(log-n) Logarithmic
입력 데이터의 크기가 커질수록 처리 시간이 로그(log: 지수 함수의 역함수) 만큼 짧아지는 알고리즘. 대표적으로 이진 탐색이 있다.
O(n) Linear
입력 데이터의 크기에 비례해 처리 시간이 증가하는 알고리즘. 1차원 for문.
O(n-log-n) Linear-Logarithmic
데이터가 많아질수록 처리시간이 로그(log) 배만큼 더 늘어나는 알고리즘.
O(n2) 제곱 quadratic
데이터가 많아질수록 처리시간이 급수적으로 늘어나는 알고리즘.
O(2n) 제곱 Exponential
데이터량이 많아질수록 처리시간이 기하급수적으로 늘어나는 알고리즘.
고효율 ||
O(1)<O(log-n)<O(n-log-n)<O(n2)<O(2n)|| 저효율
시간복잡도의 존재 이유
효율적인 코드로 개선하는 데 척도로 사용된다.
시간 복잡도를 줄이기 위해
시간 복잡도는 결국 알고리즘이 최단 시간에 종료되는 것이 좋기 때문에 가장 시간 복잡도에 영향을 미치는 반복문을 줄이는 것이 좋다. 또한 자료구조를 적합하게 사용하는 것 또한 시간 복잡도를 줄이는 방법 중 하나이다.
공간복잡도
프로그램을 실행시켰을 때 차지하는 공간(메모리). 정적 변수 뿐만아니라 동적으로 재귀적인 함수로 인해 공간을 계속해서 필요로 하는 경우도 포함된다.
O(1)
공간이 하나 생성되는 것.
공간 복잡도를 줄이기 위해
공간복잡도는 배열의 크기, 동적할당 여부, 몇번 호출하는 재귀함수인지 등이 영향을 준다.
프로그램에 필요한 공간은 고정공간과 가변공간이다. 공간복잡도만을 고려했을 때 가변공간을 사용하는 자료구조가 더 효율적이다.
선형 자료 구조 - 연결리스트, 배열, 벡터, 스택, 큐
선형 자료 구조란?
요소가 일렬로 나열되어 있는 자료 구조.
연결 리스트
데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화 시킨 자료구조.
prev 포인터와 next 포인터로 앞 뒤의 노드를 연결 시킨 것.
삽입,삭제 O(1) 탐색 O(0)
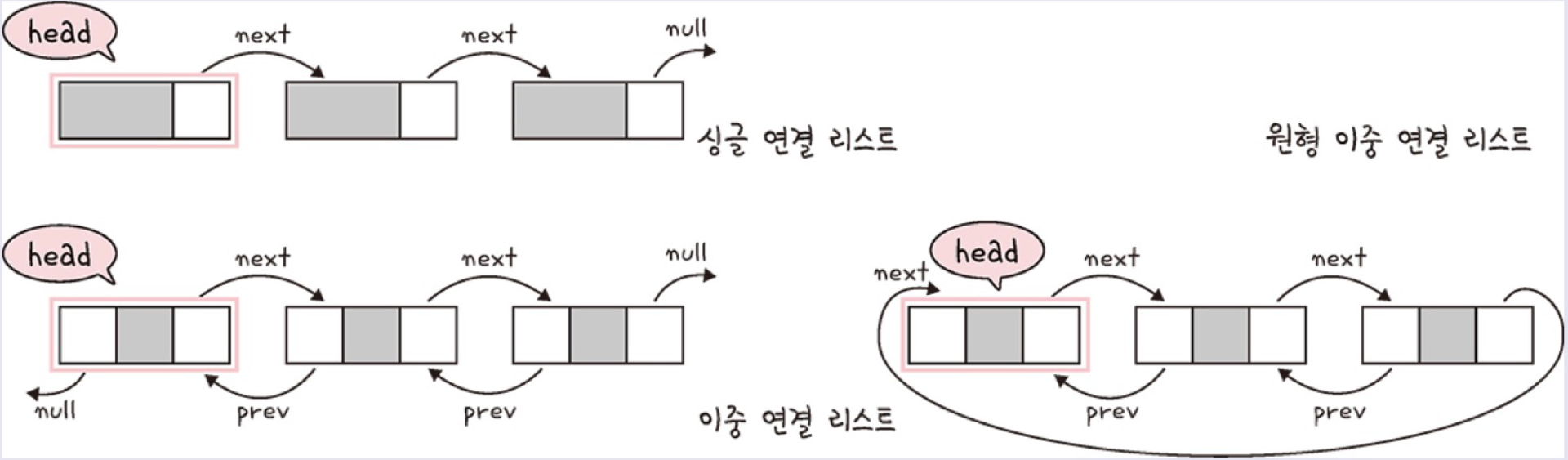
싱글 연결 리스트 : next 포인터만 가진다.
이중 연결 리스트 : next 포인터와 prev 포인터를 가진다.
원형 이중 연결 리스트 : 이중 연결 리스트와 동일하지만 마지만 노드의 next 포인터가 헤드 노드(맨 앞에 있는 노드)를 가리킨다.
배열(Array)
같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합.
중복을 허용하고 순서가 있다.
이 배열은 정적 배열 으로 탐색에 O(1)이 소요되어 랜덤접근이 가능하다. 삽입,삭제에 O(n)이 소요된다.
인덱스에 해당하는 원소를 빠르게 접근하거나 간단하게 데이터를 쌓고 싶을 때 사용한다.
삽입, 삭제가 많은 것은 연결 리스트를 사용하고 탐색이 많은 것은 배열을 사용하는 것이 좋다.
랜덤 접근과 순차적 접근
직접 접근이라고 하는 랜덤 접근은 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능. 이는 데이터에 저장된 순서대로 접근해야 하는 순차적 접근과는 반대이다.
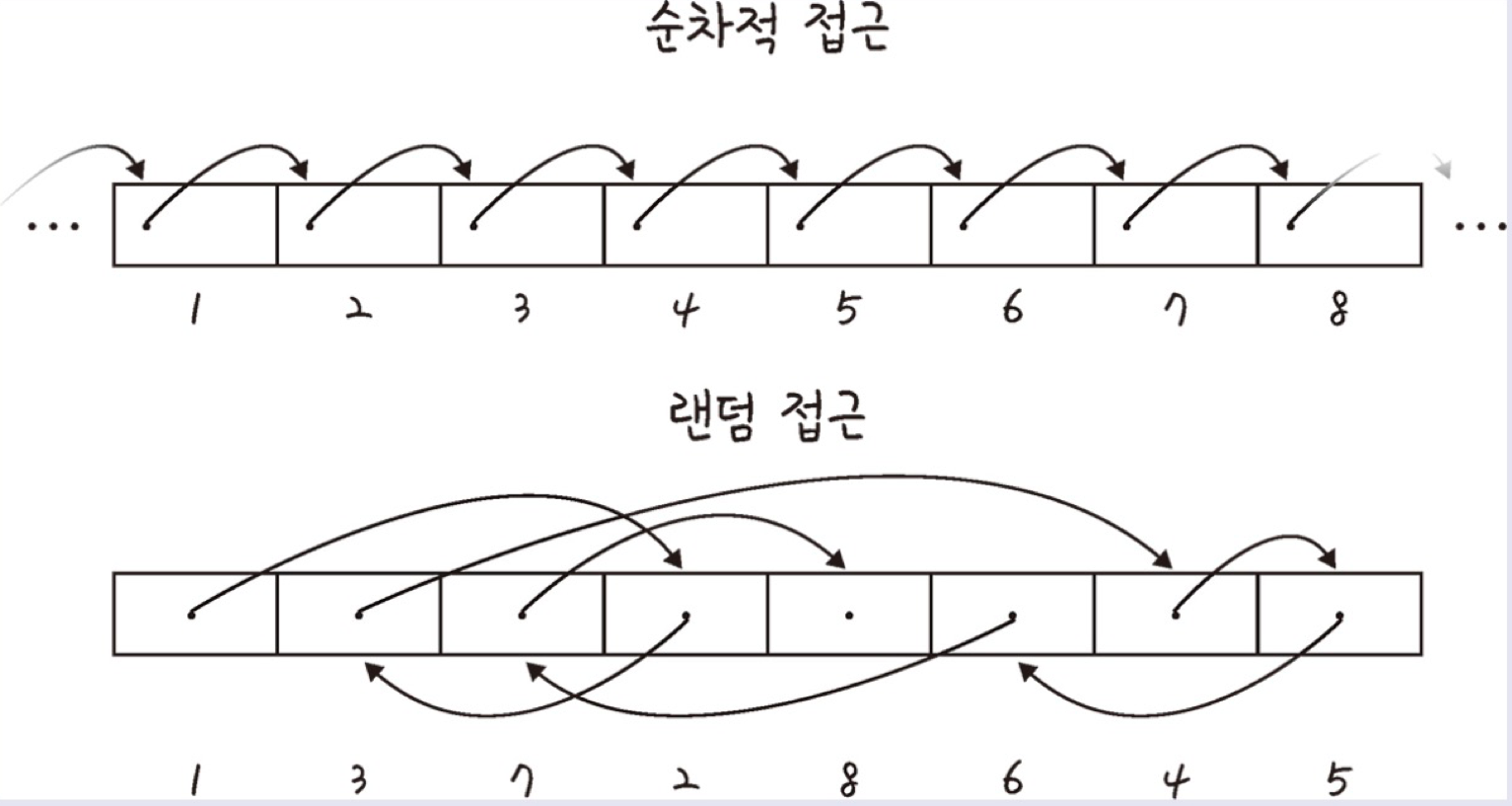
배열과 연결 리스트 비교
배열은 순서대로 상자를 나열한 데이터 구조.
몇 번째 상자인지만 알면 데이터를 꺼낼 수 있다. 랜덤접근이 가능한 O(1)
연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조.
상자 안에 요소를 알기 위해선 상자를 하나씩 꺼내어 확인해야 한다. 랜덤접근이 불가능한 O(n)
탐색은 배열이 빠르고 삽입,삭제는 연결리스트가 빠르다.
벡터(vector)
동적으로 요소를 할당할 수 있는 동적 배열.
컴파일 시점에서 개수를 모르다면 벡터를 써야한다.
데이터 중복을 허용하고 순서가 있으며 랜덤접근이 가능하다.
탐색, 맨 뒤의 요소를 삭제, 삽입 O(1) 소요
맨 뒤나 맨 앞의 요소가 아닌 요소를 삭제, 삽입하는 데 O(n) 소요
뒤에서 삽입하는 push_back()의 경우 O(1)의 시간이 소요되는데,
벡터의 크가가 증가되는 시간 복잡도가 amortized 복잡도(상수 시간 복잡도 O(1))와 유사한 시간 복잡도를 갖기 때문이다.
push_back()을 한다고 매번 크기가 증가하는 것은 아니고 2의 제곱 +1 일 때 마다 크기를 2배 늘린다.
스택(Stack)
후입선출, 가장 마지막에 들어간 데이터가 가장 먼저 나오는 성질을 가진 자료구조. 재귀적인 함수, 알고리즘에 사용되며 웹 브라우저 방문 기록 등에 쓰인다.
삽입, 삭제 O(1) 탐색 O(n) 소요.
큐(Queue)
선입선출, 먼저 들어간 데이터가 먼저 나오는 성질을 가진 자료구조.
CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행렬, 너비 우선 탐색, 캐시 등에 사용된다.
삽입, 삭제 O(1) 탐색 O(n) 소요.
비선형 자료 구조 - 그래프, 트리, 힙, 우선순위 큐, 맵, 셋, 해시테이블
비선형 자료 구조란?
일렬로 나열하지 않고 자료 순서나 관계가 복잡한 구조. 일반적으로 그래프나 트리를 말한다.
그래프
정점(vertex) 과 간선(edge) 으로 이루어진 자료구조.

간선이 한 방향으로만 진행된다면 단방향 간선 , 양방향으로 진행되면 양방향 간선 이 된다.
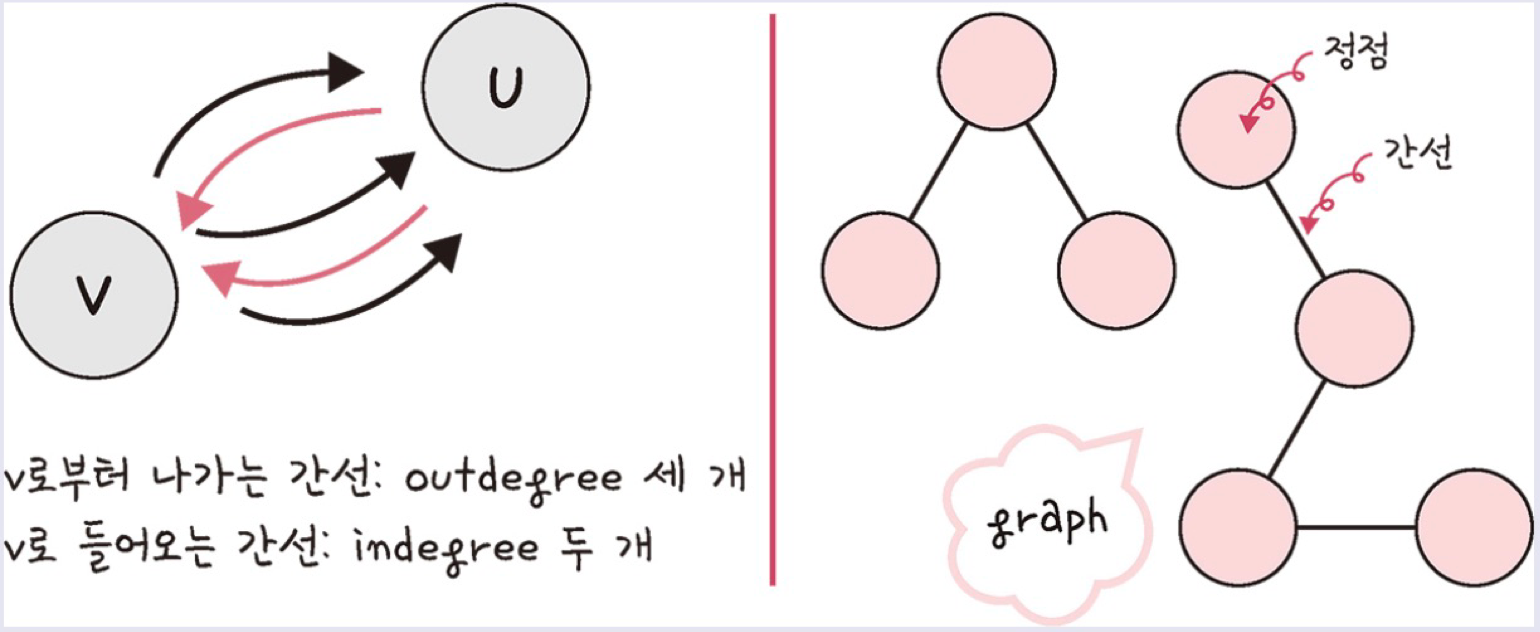
기준이 되는 정점에서 다른 정점으로 향하는 간선을 outdegree, 들어오는 간선을 indegree 라고 한다.
정점은 보통 약자로 V,U로 표기한다.
정점과 간선 사이에 드는 비용을 가중치라고 하는데, 1번 노드 ⇨ 2번 노드 까지 가는 비용이 한 칸이라면 1번 노드 ⇨ 2번 노드 까지 가는 가중치는 한 칸 이다.
트리
그래프 중 하나로 정점과 간선으로 이루어져 있고, 트리 구조로 배열된 부모-자식의 계층적 데이터의 집합.
노드 수 -1 = 간선수 라는 공식이 있다. (V -1 = E)
노드와 노드 사이에는 단 하나의 경로(간선)만 존재한다.
루트 노드, 내부 노드, 리프 노드 등으로 구성된다. 트리로 이루어진 집합을 숲 이라 한다.
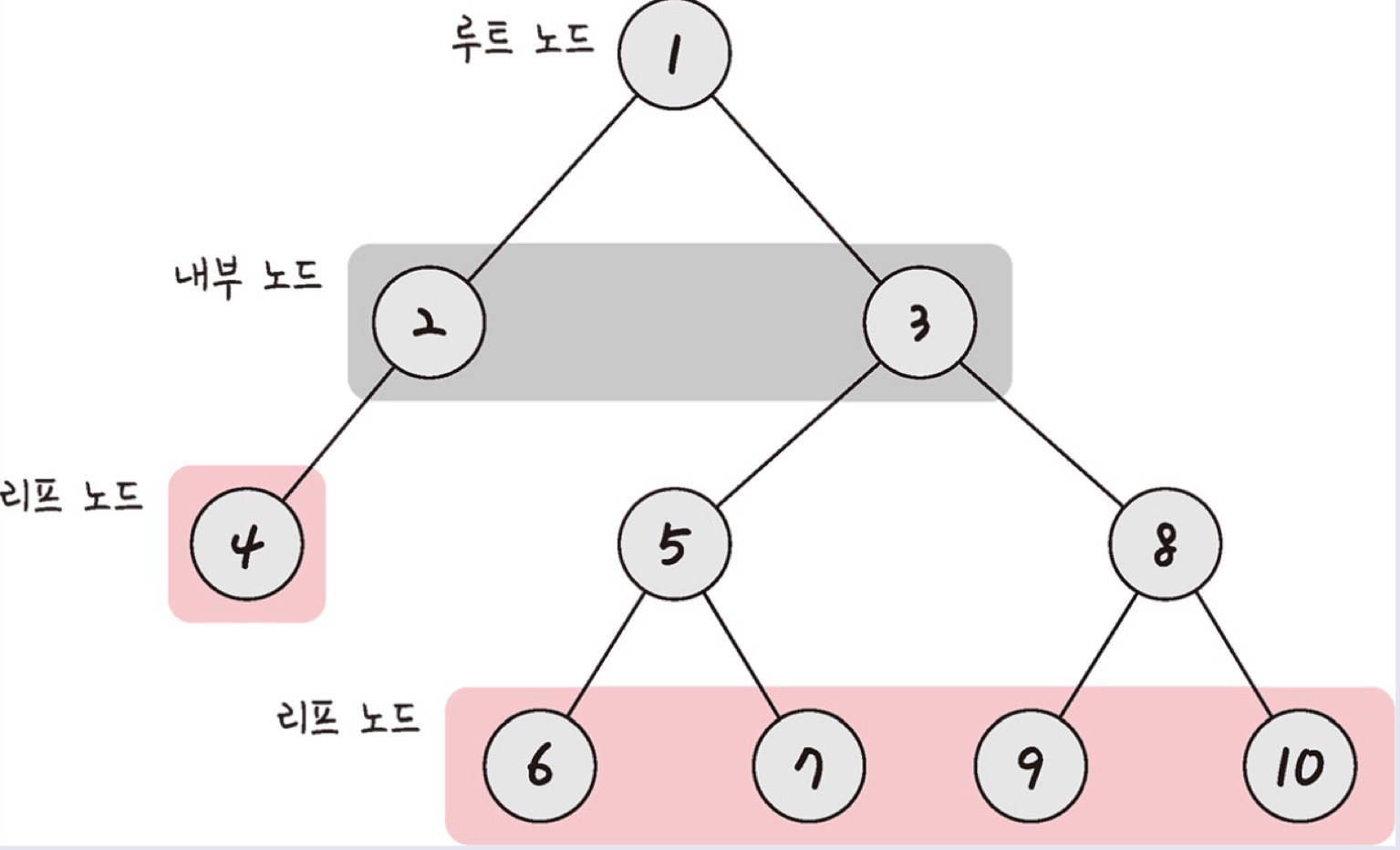
트리의 구성
루트 노드 : 가장 위에 있는 노드. 보통 트리를 검색할 때 루트 노드를 중심으로 탐색하면 쉽게 풀 수 있다.
내부 노드 : 루트 노드와 리프 노드 사이에 있는 노드
리프 노드 : 자식 노드가 없는 노드
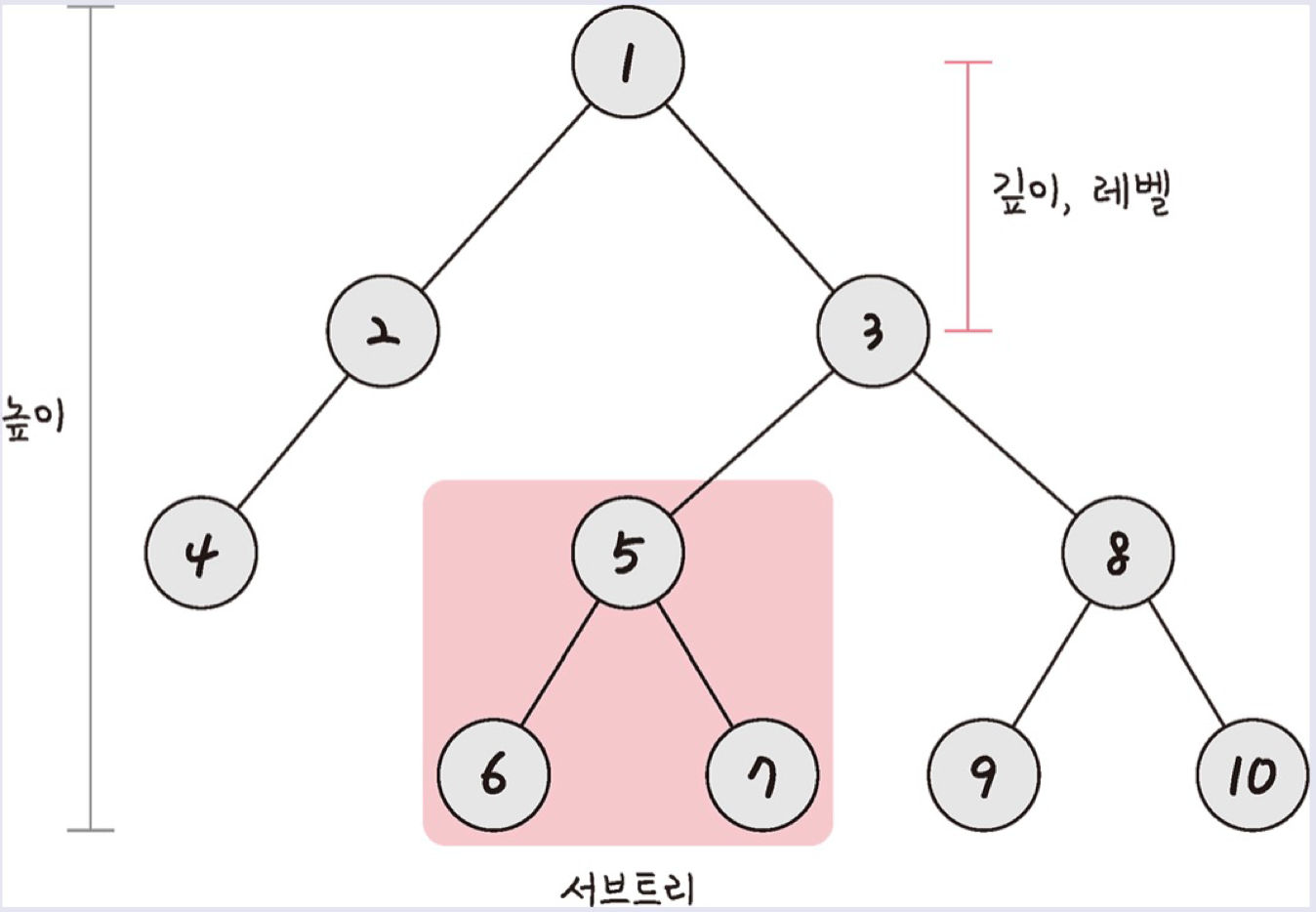
트리의 높이와 깊이
트리는 높이와 깊이를 설명할 수 있는데
높이는 루트 노드 ~ 리프 노드까지 거리 중 가장 긴 거리를 의미하며 이미지에 있는 트리의 높이는 3이다.
깊이는 루트 노드 ~ 특정 노드까지 최단 거리로 갔을 때의 거리를 말한다. 트리의 깊이는 노드마다 다르다. 8번 노드의 깊이는 2이다.
레벨은 보통은 깊이와 같은 의미를 가진다. 1번 노드를 0레벨이라 하면 5번 노드는 2레벨이 되고, 1번 노드가 1레벨이면 5번 노드는 3레벨이 된다.
서브트리는 트리 내 하위집합을 말하며 트리 내부의 부분집합니다.
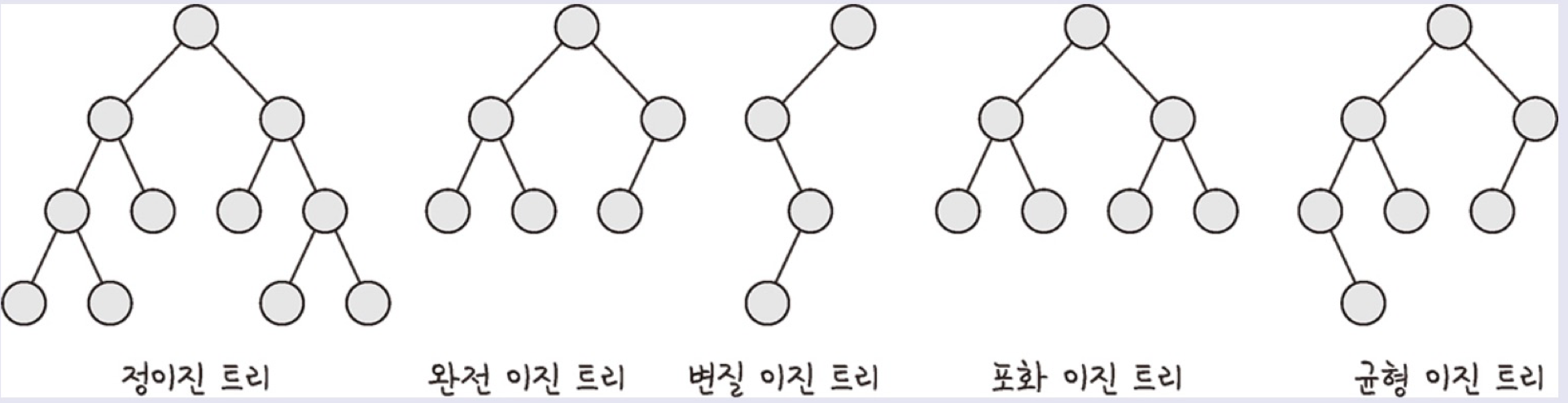
이진트리
이진트리는 자식 노드의 수가 두개 이하인 트리를 말한다.

이진 탐색 트리
이진 탐색 트리는 루트 노드 좌측 하위 노드는 모두 루트 노드의 값보다 작은 것을, 루트 노드 우측 하위 노드는 모두 루트 노드의 값보다 큰 것을 말한다. 이때 하위 트리도 동일한 특성을 갖는다.
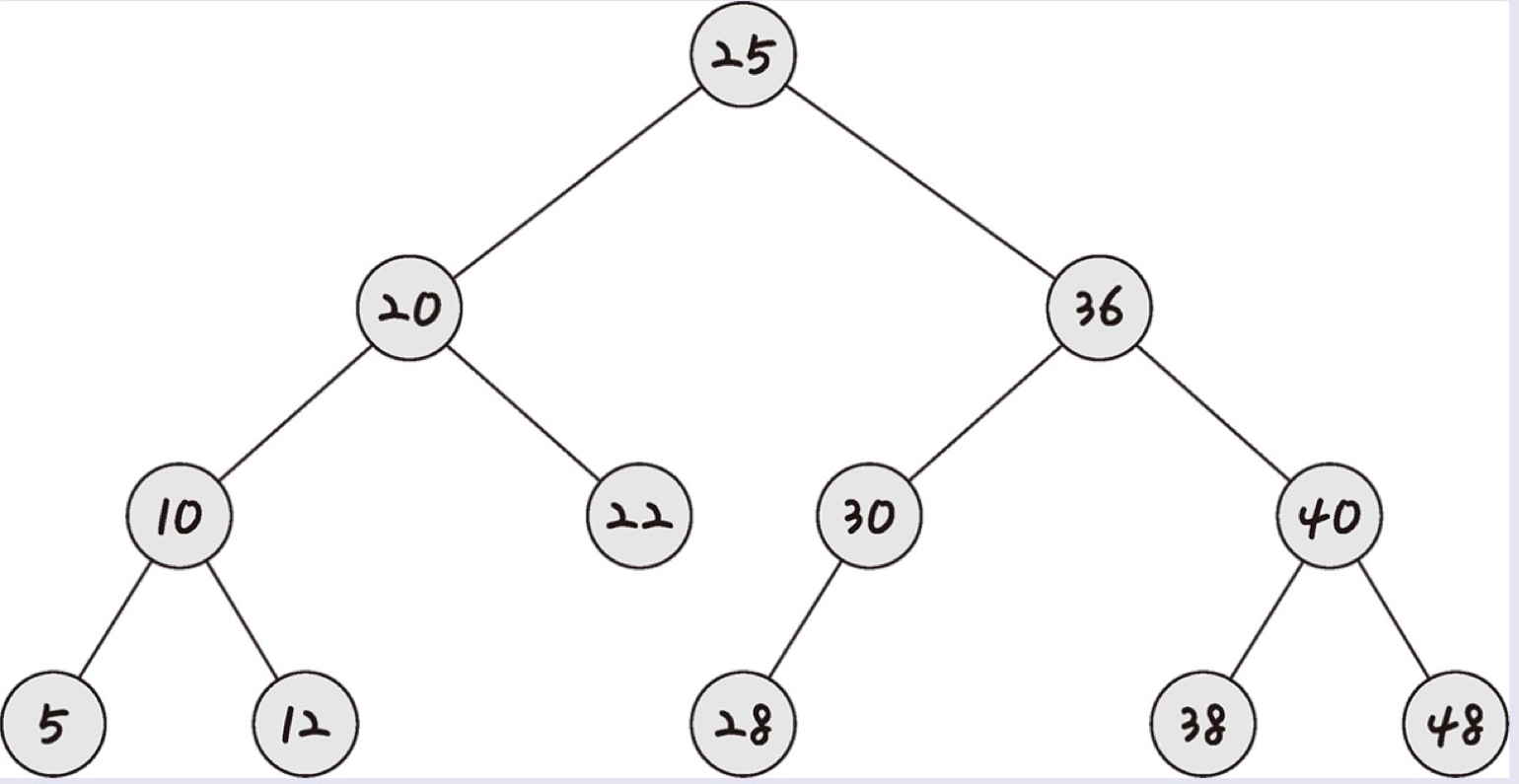
보통 요소를 찾을 때 이진 탐색 트리의 경우 O(log-n) 이 걸린다. 최악의 경우 O(n)이 걸린다.
이진 탐색 트리는 삽입 순서에 따라 선형적일 수도 있기 때문이다.
AVL트리
Adelson-Velsky and Landis Tree.
이진 탐색 트리 의 예시처럼 선형적 트리가 되는 것을 방지하고 스스로 균형을 잡는 이진 탐색 트리. 두 개의 서브트리의 높이는 항상 최대 1만큼 차이가 난다는 특징이 있다.
탐색, 삽입, 삭제 모두 O(log-n)이 소요되며 삽입, 삭제 때마다 균형을 맞추기 위해 트리 일부를 왼쪽 또는 오른쪽으로 회전시켜 균형을 잡는다.
레드 블랙 트리
균형 이진 탐색 트리로 탐색, 삽입, 삭제 모두 O(log-n))이다. 각 노드는 빨강 또는 검정색을 표현하는 비트를 추가로 저장하며 삽입, 삭제 중 트리가 균형을 유지하도록 하용된다.
"모든 리프 노드와 루트 노드는 블랙이고, 어떤 노드가 레드이면 그 노드의 자식은 반드시 블랙이다" 라는 규칙이 있다.
힙
완전 이진 트리 기반의 자료 구조이며, 최소힘과 최대힙 두 가지가 있고 해당 힙에 따라 특정한 특징을 지킨 트리.
- 최대힙 : 루트 노드에 있는 키는 모든 자식 노드에 있는 키 중 가장 커야 한다.
- 최소힙 : 루트 노드에 있는 키는 모든 자식 노드에 있는 키 중 최소값이어야 한다.
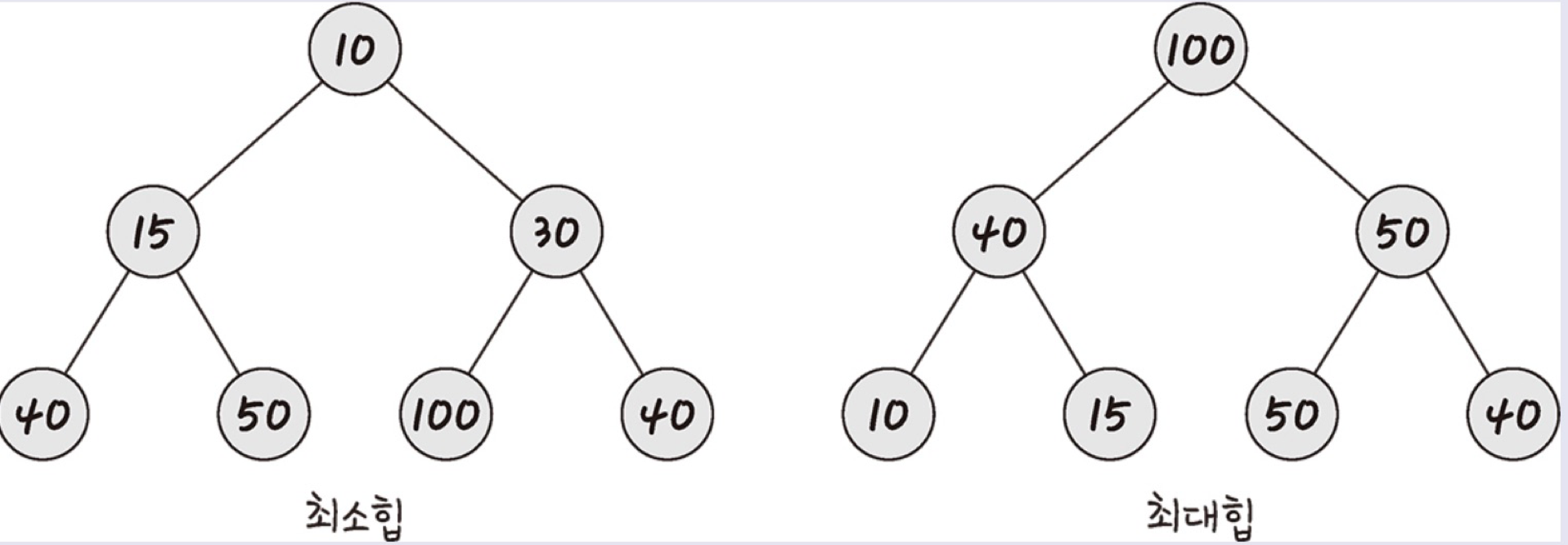
힙은 어떤 값이 들어와도 특정 힙의 규칙을 지키게 만들어져 있다.
우선순위 큐
우선순위 대기열이라고도 하며, 대기열에서 우선순위가 높은 요소가 우선순위가 낮은 요소보다 먼저 제공되는 자료 구조.
맵(map)
특정 순서에 따라 키와 매핑된 값의 조합으로 형성된 자료 구조.
레드 블랙 트리 자료 구조를 기반으로 형성되고, 삽입하면 자동으로 정렬된다.
map<string, int> 형태로 구현
배열과 비슷하게 clear() 함수로 모든 요소 삭제 가능
size()로 map의 크기를 구할 수 있음
erase() 해당 키와 매핑된 값을 지울 수 있다.
셋(set)
특정 순서에 따라 고유 요소를 저장하는 컨테이너.
중복 요소 없이 오로지 희소한(unique) 값만 저장하는 자료 구조.
해시테이블
무한에 가까운 데이터들을 유한한 개수의 해시 값으로 매핑한 테이블.
고유 인덱스 값으로 조회하여 빠른 데이터 검색에 유용하다.
해시함수가 충돌하는 경우 chainning 방식이나 open addressing 방식을 통해 충돌을 해결 할 수 있으나 최악의 경우 모든 저장공간을 다 방문해야 해서 기간복잡도가 O(n)까지 늘어날 수 있다.
삽입,삭제,탐색 시 평균 O(1) 소요.
chainning 방식 : 해시테이블의 각 인덱스의 저장공간을 연결리스트로 구현. 충돌이 발생하면 노드 하나 추가하면 됨
open addressing 방식 : 주소값이 충돌하면 비어있는 주소를 찾아 그 공간에 저장
면접 대비 질문
자료구조
복잡도 - 시간복잡도, 공간복잡도
Q. 빅오 Big-O 표기법이란?
A. 시간복잡도를 표현하는 표기방식이며, 입력범위 n을 기준으로 로직이 몇 번 반복되는지 나타내는 것.
동전을 튕겨 뒷면이 나올 확률을 볼 때 운이 좋으면 1번 튕겨서 바로 뒷면이 나올 수 있지만 최악의 경우 n번 던져야 하는 경우가 발생할 수 있듯이 최악의 경우를 계싼하는 방식을 빅오 표기법이라 한다.
선형 자료 구조 - 연결리스트, 배열, 벡터, 스택, 큐
Q. 배열의 가장 큰 특징과 그로인해 발생하는 장단점
A. 배열의 가장 큰 특징은 데이터를 순차적으로 저장한다는 점. 그래서 배열은 인덱스를 가지며 이를 이용해 특정 요소를 찾고 조작이 가능하다는 것이 장점. 또한 순차가 있기 떄문에 중간에 데이터가 삽입,삭제 되는 경우 뒤에 요소들이 밀리거나 당겨져서 인덱스가 변화한다는 점이 단점. 이를 이유로 배열은 자주 변경되는 정보를 담기에 적절하지 않다.
Q. 그럼 어떤 데이터를 배열에 담으면 좋을까 구체적인 예시 하나랑 그렇게 생각하는 이유까지 설명
A. 주식차트나 은행 입출금 내역을 담으면 좋겠다. 시간순으로 입력되며 중간에 내역이 삽입 또는 삭제될 정보가 아니기 때문이다.
Q. 연결리스트에서 한번에 중간값을 찾을 수 있는 방법은?
A. 이중포인터 Two-Pointer를 사용한다. 포인터 하나는 노드를 한 개씩 탐색하고 다른 포인터는 노드를 두 개씩 탐색하여 두 개씩 탐색하는 포인터가 리스트 끝에 도달할 때 한 개씩 탐색하는 노드의 위치가 중간값이다.
Q. 스택과 큐의 차이점
A. 스택과 큐 모두 선형 자료구조에 속합니다. 스택은 후입선출 형식 으로 웹 브라우저 방문 기록 등에 쓰이며, 큐는 선입선출 형식으로 그래프 탐색 방식인 BFS(너비우선탐색)에 사용됩니다.
Q. 1부터 100까지 정수가 있는 배열에서 한 개의 중복값이 있을 때 어떻게 찾을 수 있나?
A. n(n-2)/2는 1부터 n까지의 합을 나타낸다. 모든 배열의 요소를 더하고 1부터 100까지 더한 값을 빼면 중복값이 나온다.
비선형 자료 구조 - 그래프, 트리, 힙, 우선순위 큐, 맵, 셋, 해시테이블
Q. 그래프 탐색 방식인 DFS와 BFS에 대해 설명해주세요
A. DFS와 BFS는 각각 깊이우선탐색과 너비우선탐색으로 비선형구조인 그래프를 탐색하는 방법입니다.
그래프를 탐색한다는 것은 하나의 정점에서 시작해 모든 정점을 방문하는 것을 말하는데 '깊이우선탐색'의 경우 한 방향으로 최대한 깊이 내려간 뒤 리프 노드에 도착하면 분기를 이동하여 다시 깊이를 따라 내려가며 탐색하는 방식을 말합니다. 모든 노드를 탐색할 수 있고 너비우선탐색보다 간단하지만 탐색 속도는 상대적으로 느린것이 특징입니다.
'너비우선탐색'은 루트 노드를 시작으로 같은 레벨의 인접한 노드를 먼저 방문하는 방법으로 시작 정점인 루트 노드에서 가장 가까운 정점을 먼저 방문하고 가장 멀리 있는 정점을 나중에 방문하는 방법입니다. 주로 노드 사이의 최단 경로를 찾을 때 사용합니다.
두 방식 모두 조건 내 모든 노드를 검색한다는 점에서 시간복잡도는 동일합니다.
Q. 그래프와 트리의 차이점
A. 그래프는 정점과 간선으로 이루어진 자료구조이며, 부모-자식 개념이 없는 네트워크 모델로 도로와 같은 개념이라면 트리는 그래프의 한 종류로 계층 구조를 가지며 루트노드, 내부노드, 리프노드로 구성돼 있습니다. 한마디로 줄인다면 그래프 중 방향성인 있는 비순화 그래프를 트리라고 합니다.
Q. 이진탐색트리를 설명해주세요
A. 이진 트리를 이용한 자료구조로, 중위 순회를 통해 정렬된 값을 얻을 수 있다. 단점은 반정렬상태로, 부모-자식 관계에서만 대소 관계를 만족한다.
이진 탐색 트리의 4가지 조건으로 모든 노드의 값은 유일 - 왼쪽 서브트리의 모든 값은 루트의 값보다 작아야 함 - 오른쪽 서브트리의 모든 값은 루트의 값보다 커야 함 - 서브트리도 이진 탐색 트리여야 함
Q. 우선순위큐(Priority Queue)에 대해 설명
A. 들어간 순서에 상관없이 우선순위가 높은 데이터를 먼저 꺼내기 위해 고안된 자료구조. 배열, 연결리스트, 힙으로 구현할 수 있다.
Q. 해시 테이블을 사용했을 때의 시간복잡도에 대해 설명
A. 해시 테이블은 내부적 배열을 이용해 빠르게 데이터를 검색할 수 있는 자료구조로 각 key 값은 해시함수에 의해 고유 인덱스를 값게되어 데이터 조회에 평균 O(1)의 시간 복잡도가 소요되지만 인덱스 값의 충돌이 발생한 경우 연결된 리스트를 전부 검색해야 하므로 O(n) 까지 복잡도가 증가할 수 있다.
참고 링크
읽어보기
https://okky.kr/articles/673648
https://mintpsyco.tistory.com/7
그래프와 트리 https://devuna.tistory.com/32
복잡도 https://velog.io/@cha-suyeon/Algorithm-시간-복잡도-공간-복잡도
https://dev-coco.tistory.com/159
https://snoop-study.tistory.com/56
