출처: Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow (지음: 오렐리앙 제롱, 옮김: 박해선, 출판: 한빛미디어
1~4장, 10~16장만 학습
부가적으로 챗GPT 활용
01_머신러닝
1.1_머신러닝
머신러닝: 컴퓨터가 데이터로 학습하도록 프로그래밍 하는 과학(혹은 예술)
데이터 마이닝: 데이터를 머신러닝 기술을 적용해 분석하여 겉으로 보이지 않던 것(패턴)을 발견하는 것
1.2_머신러닝 시스템 종류
- 학습 알고리즘
- 지도 학습: 답을 알려주고 학습
- 비지도 학습: 답 없이 학습
- 준지도 학습: 전체가 아닌 일부에만 답이 있는 학습
강화학습: 행동에 따라 보상과 벌점을 부과하여 촤상의 전략을 스스로 학습하도록 함
- 데이터 학습 방법
- 배치 학습(오프라인 학습): 보유한 데이터 전체를 우선 학습하고 이후엔 학습 없이 적용
- 온라인 학습(점진적 학습): 데이터를 작은 묶음 단위로 주입하여 훈련하여 데이터가 도착하는대로 즉시 학습 가능
- 일반화 방법
- 사례 기반 학습: 훈련 데이터와 유사도를 비교하여 예측
- 모델 기반 학습: 데이터들의 모델을 만들어 예측
1.3_머신러닝 주요 과제
- 좋은 데이터와 좋은 알고리즘 사용(나쁜 데이터와 나쁜 알고리즘 회피):
- 충분한 데이터
- 대표성 있는 데이터
- 샘플링 잡음: 우연에 의한 대표성 없는 데이터
- 샘플링 편항: 치중된 데이터 추출로 편향 발생
- 고질의 데이터
- 관련된 특성
- 특성 선택: 갖고 있는 특성 중 유용한 특성 선택
- 특성 공학: 특성을 결합하여 더 유용한 특성 생성
- 새 특성 생성: 새로운 데이터 수집
- 과대·과소 적합
1.4_테스트와 검증
일반화 정도를 확인하기 위해 데이터를 학습용과 테스트용으로 나눠 학습 및 검증
데이터 불일치: (이해 못함) 학습 데이터와 테스트 데이터의 내용물이 다를 경우??(책에선 웹의 사진과, 앱으로 촬영한 사진을 예로 듦)
02_머신러닝 프로젝트
2.1 데이터 얻기 좋은 사이트
- 데이터 저장소
- 데이터 저장소 모음 리스트
2.2 설계
- 문제 정의: 모델을 어디에 사용해 어떤 결과를 얻으려 하는지
목적을 통해 문제 구성, 알고리즘 선택, 평가 지표 선택, 튜닝 비용 등 결정
2.3 데이터
데이터 불러오기
살피기: 데이터 갯수, 결측치, 형식, 데이터 분산
테스트 셋 생성
# 데이터 로드 및 기본 정보 확인
import pandas as pd
housing = pd.read_csv('housing.csv')
housing.info()
# 데이터 시각화
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20, 15))
plt.show()
# 데이터셋 나누기
from sklearn.model_selection import train_test_split, StratifiedShuffleSplit
housing.reset_index()
train_set, test_set = train_test_split(housing.reset_index(), test_size=0.2, random_state=42)
# 균형 있게 데이터셋 나누기
from sklearn.model_selection import train_test_split, StratifiedShuffleSplit
housing['income_cat'] = pd.cut(housing['median_income'],
bins=[0, 1.5, 3, 4.5, 6, np.inf],
labels=[1,2,3,4,5])
train_set, test_set = train_test_split(housing.reset_index(), test_size=0.2, random_state=42)
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing['income_cat']):
start_train_set = housing.loc[train_index]
start_test_set = housing.loc[test_index]2.4 데이터 탐색 및 시각화
2.4.1 지리적 데이터 시각화
housing = start_train_set.copy()
housing.plot(kind='scatter', x='longitude', y='latitude', alpha=0.4,
s=housing['population']/100, label='population', figsize=(10, 7),
c='median_house_value', cmap='jet', colorbar=True,
sharex=False)
plt.legend();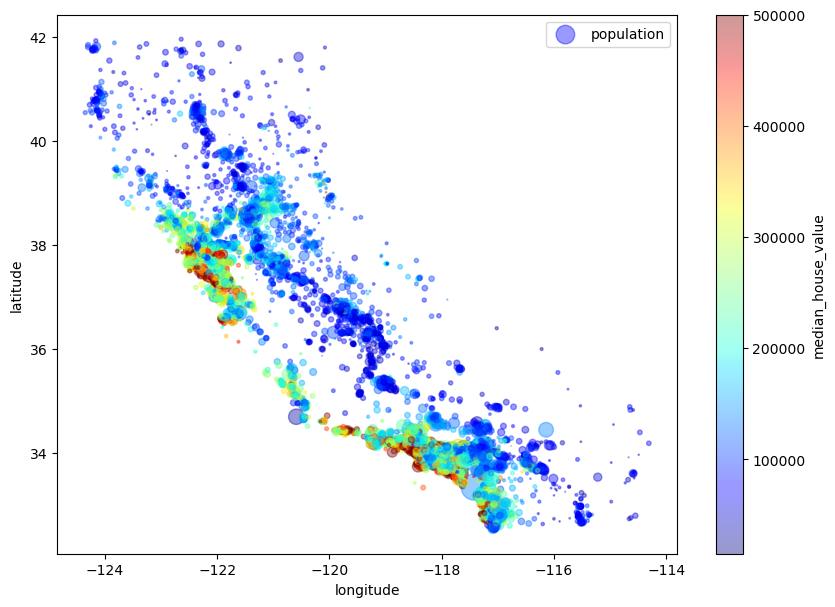
지역에 따라 어느 정도 가격 분포가 모여 있는 것을 알 수 있음
2.4.2 상관관계 조사
# 상관계수 확인
corr_matrix = housing.corr(numeric_only=True)
corr_matrix['median_house_value'].sort_values(ascending=False)
## 결과
median_house_value 1.000000
median_income 0.687151
total_rooms 0.135140
housing_median_age 0.114146
households 0.064590
total_bedrooms 0.047781
population -0.026882
longitude -0.047466
latitude -0.142673
Name: median_house_value, dtype: float64
##
# 상관관계 시각화
from pandas.plotting import scatter_matrix
attributes = ['median_house_value', 'median_income', 'total_rooms', 'housing_median_age']
scatter_matrix(housing[attributes], figsize=(12,8));
# 가장 상관계수 높은 하나 확인
housing.plot(kind='scatter', x='median_income', y='median_house_value', alpha=0.1);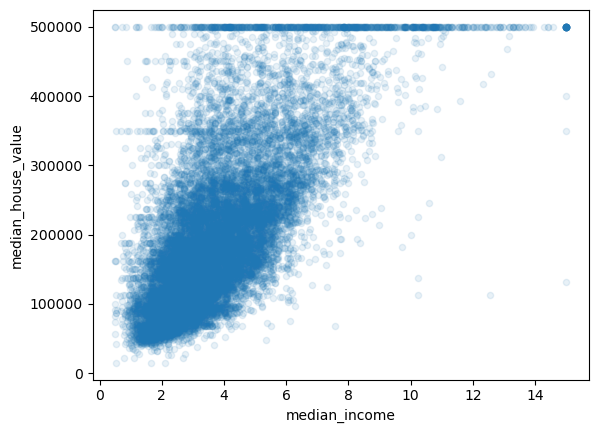
상관계수 확인 및 시각화 통한 이상치 확인
2.4.3 특성 공학
housing['rooms_per_household'] = housing['total_rooms']/housing['households']
housing['bedrooms_per_room'] = housing['total_bedrooms']/housing['total_rooms']
housing['population_per_household'] = housing['population']/housing['households']
corr_matrix = housing.corr(numeric_only=True)
corr_matrix['median_house_value'].sort_values(ascending=False)
## 결과
median_house_value 1.000000
median_income 0.687151
rooms_per_household 0.146255
total_rooms 0.135140
housing_median_age 0.114146
households 0.064590
total_bedrooms 0.047781
population_per_household -0.021991
population -0.026882
longitude -0.047466
latitude -0.142673
bedrooms_per_room -0.259952
Name: median_house_value, dtype: float64
##bedrooms_per_room와 rooms_per_household가 기존 변수보다 상관계수가 높음
2.5 데이터 준비
2.5.1 대치(보간)
# 데이터 초기화
housing = start_train_set.drop('median_house_value', axis=1)
housing_labels = start_train_set['median_house_value'].copy()
# 대치(보간)
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='median')
housing_num = housing.drop('ocean_proximity', axis=1)
imputer.fit(housing_num)
imputer.statistics_ # 각 열별 중앙값
X = imputer.transform(housing_num)
housing_tr = pd.DataFrame(X, columns=housing_num.columns, index=housing_num.index)2.5.2 범주형 데이터
# 원 핫 인코딩(값의 유무)
from sklearn.preprocessing import OneHotEncoder
housing_cat = housing[['ocean_proximity']]
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
# 라벨링(서열 척도)
from sklearn.preprocessing import OrdinalEncoder
housing_cat = housing[['ocean_proximity']]
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded2.5.3 사용자 변환기
from sklearn.base import BaseEstimator, TransformerMixin
rooms_ix, bedrooms_ix, population_ix, housholds_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room=True) -> None:
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, housholds_ix]
population_per_househod = X[:, population_ix] / X[:, housholds_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, housholds_ix]
return np.c_[X, rooms_per_household, population_per_househod, bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_househod]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)2.5.4 스케일링
특성의 범위를 같도록 만들어주는 것
from sklearn.preprocessing import MinMaxScaler, StandardScaler
sclaer = MinMaxScaler()
sclaer.fit_transform(housing.iloc[:,:8])
sclaer.transform(start_test_set.iloc[:,:8])2.5.5 변환 파이프라인
전처리 등의 연속된 변환을 순서대로 처리할 수 있는 기능
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler())
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
# 컬럼별로 변환해주는 클래스
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ['ocean_proximity']
full_pipeline = ColumnTransformer([
('num', num_pipeline, num_attribs),
('cat', OneHotEncoder(), cat_attribs)
])
housing_prepared = full_pipeline.fit_transform(housing)2.6 모델 선택과 훈련
2.6.1 훈련 및 평가
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("예측:", lin_reg.predict(some_data_prepared))
print('레이블:', list(some_labels))
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
print(lin_rmse)
## 결과
예측: [ 86966.76314664 311402.23074473 148976.79951747 181706.73859317
242735.90928981]
레이블: [72100.0, 279600.0, 82700.0, 112500.0, 238300.0]
68738.53010201632
##rmse가 너무 커 다른 모델 학습
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)
print("예측:", tree_reg.predict(some_data_prepared))
print('레이블:', list(some_labels))
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
print(tree_rmse)
## 결과
예측: [ 72100. 279600. 82700. 112500. 238300.]
레이블: [72100.0, 279600.0, 82700.0, 112500.0, 238300.0]
0.0
##성능 개선됐지만 잔차 0으로 과적합으로 보임
2.6.2 교차 검증
k-fold cross-validation: 주로 k-fold로 칭하며 훌련 세트를 k개의 fold로 분할하여 매번 1개의 다른 fold를 검증용으로 사용
from sklearn.model_selection import cross_val_score
def display_scores(scores):
print("점수:", scores)
print("평균:", scores.mean())
print("표준편차:", scores.std())
scores = cross_val_score(tree_reg, housing_prepared, housing_labels, scoring='neg_mean_squared_error', cv=10)
tree_rmse_scores = np.sqrt(-scores)
display_scores(tree_rmse_scores)
print('='*20)
scores = cross_val_score(lin_reg, housing_prepared, housing_labels, scoring='neg_mean_squared_error', cv=10)
lin_rmse_scores = np.sqrt(-scores)
display_scores(lin_rmse_scores)
## 결과
점수: [71284.13501105 69757.44860496 68110.6994918 72139.78166401
69531.94683951 74370.46345791 73318.61706802 72336.26460596
70774.88732504 72251.6226878 ]
평균: 71387.58667560713
표준편차: 1790.6317127912441
====================
점수: [72190.03655178 64547.37000901 67926.86409171 69078.39269088
66740.22093242 72797.90784075 71846.35947234 69233.46542656
66683.98023845 70353.04007355]
평균: 69139.76373274506
표준편차: 2566.053640298285
##선형 모델의 성능이 더 좋음
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
forest_reg.fit(housing_prepared, housing_labels)
print("예측:", forest_reg.predict(some_data_prepared))
print('레이블:', list(some_labels))
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
print(forest_rmse)
scores = cross_val_score(forest_reg, housing_prepared, housing_labels, scoring='neg_mean_squared_error', cv=10)
forest_rmse_scores = np.sqrt(-scores)
display_scores(forest_rmse_scores)
## 결과
예측: [ 76863. 299415.01 82686. 121424. 230676. ]
레이블: [72100.0, 279600.0, 82700.0, 112500.0, 238300.0]
18723.769912175063
점수: [51502.90420853 49810.66754099 47070.1518589 51896.12603164
48023.65989016 51337.66762255 52981.41768203 49996.05195324
48491.36464553 54823.62173737]
평균: 50593.363317094954
표준편차: 2260.100015818377
##더 좋음
2.7 튜닝
2.7.1 파라미터 튜닝
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]}
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True, error_score='raise')
grid_search.fit(housing_prepared, housing_labels)
grid_search.best_params_2.7.2 앙상블 방법
여러 모델을 합쳐서 만드는 것
2.7.3 중요도에 따른 특성 선택
feature_importance = grid_search.best_estimator_.feature_importances_
extra_attribs = ['rooms_per_hhold', 'pop_per_hhold', 'bedrooms_per_room']
cat_encoder = full_pipeline.named_transformers_['cat']
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importance, attributes), reverse=True)
## 결과
[(0.25799432888537294, 'median_income'),
(0.170484405918087, 'income_cat'),
(0.11434218303578292, 'INLAND'),
(0.10870798745792358, 'pop_per_hhold'),
(0.06877392025431936, 'latitude'),
(0.06681178713235325, 'longitude'),
(0.054913320139819644, 'rooms_per_hhold'),
(0.04246145268576092, 'housing_median_age'),
(0.02337296886450235, 'bedrooms_per_room'),
(0.01927574079253312, 'total_rooms'),
(0.01818331840588853, 'population'),
(0.017886250996033252, 'total_bedrooms'),
(0.017175430992374605, 'households'),
(0.011209810958091974, '<1H OCEAN'),
(0.0048196052862487775, 'NEAR OCEAN'),
(0.003549400578525269, 'NEAR BAY'),
(3.808761638263969e-05, 'ISLAND')]
##위 정보를 바탕으로 불요 특성 제거
2.7.4 테스트 셋으로 평가
from scipy import stats
# 전처리 및 예측
final_model = grid_search.best_estimator_
X_test = start_test_set.drop('median_house_value', axis=1)
y_test = start_test_set['median_house_value'].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
# 신뢰구간 범위 확인
confidence = 0.95
squared_erros = (final_predictions - y_test)**2
np.sqrt(stats.t.interval(confidence, len(squared_erros)-1,
loc=squared_erros.mean(),
scale=stats.sem(squared_erros)))
## 결과
array([46908.75170357, 50814.84569256])
##2.8 몰랐던 함수
from scipy.stats import expon, reciprocal
# expon(Exponential Distribution): 지수 분포: 한쪽으로 치우친 배열 생성(값의 기준을 좀 알 때)
# reciprocal(Reciprocal Distribution): 값의 역수를 따르는 균등 분포: 균등한 배열 생성(값의 기준을 전혀 모를 때)
def indices_of_top_k(arr, k):
return np.sort(np.argpartition(np.array(arr), -k)[-k:])
# np.argpartition(array, k: 오름차순 순번): 오름차순 기준 k번째 값 이하는 k 앞에, 초과 값은 뒤로 정렬 없이 인덱스 배치
03_분류
3.1 이진분류
from sklearn.datasets import fetch_openml
import numpy as np
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
X, y = mnist['data'], mnist['target'].astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train==5)
y_test_5 = (y_test==5)
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)3.2 성능 측정
3.2.1 교차 검증을 사용한 정확도 측정
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone # 모델의 학습 결과는 복제하지 않음
skfolds = StratifiedKFold(n_splits=3, random_state=42, shuffle=True)
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_folds = X_train[test_index]
y_test_folds = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_folds)
n_correct = sum(y_pred==y_test_folds)
print(n_correct/len(y_pred))
from sklearn.model_selection import cross_val_score
print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring='accuracy'))3.2.2 오차 행렬 (Confusion Matrix)
오차 행렬: 분류 모델의 예측과 실제 값을 비교하여 각 클래스의 예측 성능을 시각적으로 나타내는 행렬
- True Positive (TP): 실제 양성이고 모델이 양성으로 예측한 경우
- True Negative (TN): 실제 음성이고 모델이 음성으로 예측한 경우
- False Positive (FP): 실제 음성인데 모델이 양성으로 예측한 경우
- False Negative (FN): 실제 양성인데 모델이 음성으로 예측한 경우
Precision (정밀도)
Precision은 모델이 양성으로 예측한 것들 중 실제로 양성인 비율. 정밀도는 모델이 양성으로 예측할 때의 신뢰도를 측정.
Recall (재현율) / Sensitivity (민감도)
Recall 또는 Sensitivity는 실제 양성인 것들 중에서 모델이 양성으로 정확히 예측한 비율.
Specificity (특이도)
Specificity는 실제 음성인 것들 중에서 모델이 음성으로 정확히 예측한 비율.
F1 Score
F1 Score는 Precision과 Recall의 조화 평균을 나타내며, 두 성능 지표를 균형 있게 고려함.
Accuracy (정확도)
Accuracy는 모델이 전체 데이터 중 얼마나 많은 데이터 포인트를 올바르게 예측했는지를 측정.
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
print(confusion_matrix(y_train_5, y_train_pred))
from sklearn.metrics import f1_score
print(f1_score(y_train_5, y_train_pred))3.2.3 정밀도 재현율 트레이드 오프
precision을 올리면 recall이 줄고 recall을 올리면 precision가 주는 것.
결정 함수(decision function): 클래스를 구분하는 임계값을 결정하는 함수
y_scores = sgd_clf.decision_function([some_digit])
print(y_scores)
from sklearn.metrics import precision_recall_curve
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method='decision_function')
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], 'b--', label='precision')
plt.plot(thresholds, recalls[:-1], 'g--', label='recall')
plt.legend(loc="center right", fontsize=16) # Not shown in the book
plt.xlabel("Threshold", fontsize=16) # Not shown
plt.grid(True) # Not shown
plt.axis([-50000, 50000, 0, 1]) # Not shown
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show(block=False)
plt.pause(2)
plt.close()
from sklearn.metrics import precision_score, recall_score
threshold_90_precision = thresholds[np.argmax(precisions >= 0.9)]
y_train_pred_90 = (y_scores >= threshold_90_precision)
print(precision_score(y_train_5, y_train_pred_90))
print(recall_score(y_train_5, y_train_pred_90))3.2.4 ROC와 AUC
ROC(Receiver Operating Characteristic) 곡선(Curve): 이진 분류 문제에서 True Positive Rate (TPR)과 False Positive Rate (FPR)을 다양한 임계값에서 계산하여 그린 그래프.
-
True Positive Rate (TPR): 실제 양성 샘플 중에서 모델이 양성으로 올바르게 예측한 비율 == Recall
-
False Positive Rate (FPR): 실제 음성 샘플 중에서 모델이 양성으로 잘못 예측한 비율.
-
ROC 곡선의 구성
- X축: False Positive Rate (FPR)
- Y축: True Positive Rate (TPR)
ROC 곡선은 다양한 분류 임계값에 대해 FPR과 TPR을 계산하여 그린 곡선입.
========================
AUC (Area Under the Curve): ROC 곡선 아래의 면적을 의미.
- AUC의 계산|: AUC는 ROC 곡선 아래의 면적을 수치적으로 계산. 면적은 0과 1 사이의 값으로 표현.
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0,1], [0,1], 'k--')
plot_roc_curve(fpr, tpr)
plt.show(block=False)
plt.pause(2)
plt.close()
print(roc_auc_score(y_train_5, y_scores))3.3 다중 분류
- One-versus-the-Rest (OvR): 클래스마다 하나의 이진 분류기를 학습하여 나머지 모든 클래스와 구분. 클래스 수가 증가하면 이진 분류기의 수가 증가().
※ One-versus-All(OvA) 라고도 함 - One-versus-One (OvO): 모든 클래스 쌍에 대해 이진 분류기를 학습하여, 다수결로 최종 클래스를 결정. 클래스 수가 증가하면 이진 분류기의 수가 기하급수적으로 증가().
대부분 OvR을 선호하지만 SVM 같은 작은 훈련셋에서 많은 분류기를 훈련시키는 쪽이 빠르면 OvO 선호.
from sklearn.svm import SVC
svm_clf = SVC()
svm_clf.fit(X_train, y_train)
print(svm_clf.predict([some_digit]))
some_digit_scores = svm_clf.decision_function([some_digit])
print(some_digit_scores)
some_digit_scores = svm_clf.decision_function([some_digit])
print(some_digit_scores)
svm_clf.classes_[np.argmax(some_digit_scores)]
# OvR 강제
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC())
ovr_clf.fit(X_train, y_train)
print(ovr_clf.predict([some_digit]))
print(len(ovr_clf.estimators_)) # 분류기의 갯수3.4 오류 분석
잘못 분류된 값을 직접 확인 및 분석
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
print(cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring='accuracy'))
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
print(conf_mx)
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show(block=False)
plt.pause(2)
plt.close()
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
print(row_sums)
print(norm_conf_mx)
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show(block=False)
plt.pause(2)
plt.close()3.5 다중 레이블 분류
다중 레이블 분류 (Multi-label Classification): 각 샘플이 여러 개의 레이블(클래스)을 가짐. ex) 뉴스 기사에 대해 여러 주제를 동시에 예측.
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
print(knn_clf.predict(some_digit))
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3)
print(f1_score(y_multilabel, y_train_knn_pred, average='macro'))3.6 다중 출력 분류
다중 출력 분류 (Multi-output Classification): 각 샘플에 대해 여러 개의 서로 다른 출력 값을 예측. ex) 뉴스 기사에 대해 주제와 길이 같은 여러 속성을 동시에 예측.
noise = np.random.randint(0, 100, (len(X_train),784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
some_index = 0
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[some_index]])
plot_digit(clean_digit)04_회귀
4.1 선형 회귀(해석적 방법)
- 유사역행렬(무어-펜로즈 역행렬)
- 특잇값 분해(SVD: Singular Vlaue Decomposition)
import numpy as np
import matplotlib.pyplot as plt
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.rand(100, 1)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show(block=False)
plt.pause(2)
plt.close()
X_b = np.c_[np.ones((100, 1)), X]
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
print(theta_best)
X_new = np.array([[0], [2]])
X_new_b = np.c_[np.ones((2, 1)), X_new]
y_predict = X_new_b.dot(theta_best)
print(y_predict)
plt.plot(X_new, y_predict, 'r-')
plt.plot(X, y, 'b.')
plt.axis([0, 2, 0, 15])
plt.show(block=False)
plt.pause(2)
plt.close()
# 선형회귀 모델
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
print(lin_reg.intercept_, lin_reg.coef_)
print(lin_reg.predict(X_new))
# 유사역행렬 계산
theta_best_svd, residuals, rank, s = np.linalg.lstsq(X_b, y, rcond=1e-6)
print(theta_best_svd)4.2 경사하강법(gradient descent)
비용 함수를 최소화하기 위해 반복해서 그래디언트가 감소하는 방향으로 파라미터를 조정하는 기법.
- 배치 경사 하강법
eta = 0.1
n_iterations = 1000
m = 100
theta = np.random.randn(2, 1)
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
print(theta)- 확률적 경사 하강법
# 학습 스케줄 이용
n_epochs = 50
t0, t1 = 5, 50
def learning_schedule(t):
return t0 / (t + t1)
theta = np.random.randn(2, 1)
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(epoch * m + i)
theta = theta - eta * gradients
print(theta)
# sklearn
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1)
sgd_reg.fit(X, y.ravel())
print(sgd_reg.intercept_, sgd_reg.coef_)- 미니배치 경사 하강법
theta_path_mgd = []
n_iterations = 50
minibatch_size = 20
theta = np.random.randn(2, 1)
t = 0
for epoch in range(n_iterations):
shuffled_indices = np.random.permutation(m)
X_b_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]
for i in range(0, m, minibatch_size):
t += 1
xi = X_b_shuffled[i:i+minibatch_size]
yi = y_shuffled[i:i+minibatch_size]
gradients = 2/minibatch_size * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(t)
theta = theta - eta * gradients
theta_path_mgd.append(theta)
print(theta)4.3 다항 회귀
거듭제곱으로 새로운 특성을 추가하여 이 특성을 포함한 데이터셋에 선형 모델을 훈련시키는 것.
from sklearn.preprocessing import PolynomialFeatures
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5 * X**2 + X + 2 + np.random.randn(m, 1)
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
print(X[0], X_poly[0])
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
print(lin_reg.intercept_, lin_reg.coef_)4.4 학습 곡선
학습 과정의 성능 변화를 나타내는 그래프.
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.5)
train_errors, val_errors = [], []
for m in range(1, len(X_train)):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train[:m], y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
plt.plot(np.sqrt(train_errors), 'r-+', linewidth=2, label='train set')
plt.plot(np.sqrt(val_errors), 'b-', linewidth=3, label='validation set')
plt.legend(loc="upper right", fontsize=14)
plt.xlabel("Training set size", fontsize=14)
plt.ylabel("RMSE", fontsize=14)
# Set y-axis ticks
plt.yticks(np.arange(0, 5.5, 0.5))
# Set y-axis limits
plt.ylim(0, 5)
plt.show(block=False)
plt.pause(2)
plt.close()
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline([
('poly_features', PolynomialFeatures(degree=1, include_bias=False)),
('lin_reg', LinearRegression())
])
# 과소적합
plot_learning_curves(polynomial_regression, X, y)
# 과대적합
polynomial_regression.set_params(poly_features__degree=10)
plot_learning_curves(polynomial_regression, X, y)4.5 규제가 있는 선형 모델
4.5.1 릿지(ridge) 회귀
릿지(L2정규화): 회귀 계수의 제곱합을 정규화 항으로 추가하는 기법.
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver='cholesky', random_state=42)
ridge_reg.fit(X, y)
print(ridge_reg.predict([[1.5]]))
sgd_reg = SGDRegressor(penalty='l2', random_state=42)
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict([[1.5]]))4.5.2 라쏘(Lasso: least absolute shrinkage and selection operator) 회귀
라쏘(L1정규화): 회귀 계수의 절댓값의 합을 정규화 항으로 추가하는 기법. 덜 중요한 특성의 가중치 제거.
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1, random_state=42)
lasso_reg.fit(X, y)
print(lasso_reg.predict([[1.5]]))
sgd_reg = SGDRegressor(penalty='l1', random_state=42)
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict([[1.5]]))4.5.3 엘라스틱넷(elastic net)
릿지 회귀와 라쏘 회귀를 함께 사용.
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
# l1_ratio: 혼합 비율(r). 0=릿지, 1=라쏘.
elastic_net.fit(X, y)
print(elastic_net.predict([[1.5]]))4.5.4 조기 종료
과대 적합 전에 훈련 종료.
from sklearn.preprocessing import StandardScaler
from copy import deepcopy
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 2 + X + 0.5 * X**2 + np.random.randn(m, 1)
X_train, X_val, y_train, y_val = train_test_split(X[:50], y[:50].ravel(), test_size=0.5, random_state=10)
poly_scaler = Pipeline([
('poly_features', PolynomialFeatures(degree=90, include_bias=False)),
('std_scaler', StandardScaler())
])
X_train_poly_scaled = poly_scaler.fit_transform(X_train)
X_val_poly_scaled = poly_scaler.fit_transform(X_val)
sgd_reg = SGDRegressor(max_iter=1, tol=None, warm_start=True,
penalty=None, learning_rate='constant', eta0=0.0005)
minimum_val_error = float('inf')
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train)
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val, y_val_predict)
if val_error < minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = deepcopy(sgd_reg)
print(best_epoch, epoch)
print(minimum_val_error, val_error)4.6 로지스틱 회귀
임계값에 따라 1이나 0으로 구분하는 분류 모델
4.6.1 확률 추정
- 로지스틱 모델의 확률 정
# 로지스틱(시그모이드) 함수
t = np.linspace(-10, 10, 100)
sig = 1 / (1 + np.exp(-t))
plt.figure(figsize=(9, 3))
plt.plot([-10, 10], [0, 0], "k-")
plt.plot([-10, 10], [0.5, 0.5], "k:")
plt.plot([-10, 10], [1, 1], "k:")
plt.plot([0, 0], [-1.1, 1.1], "k-")
plt.plot(t, sig, "b-", linewidth=2, label=r"$\sigma(t) = \frac{1}{1 + e^{-t}}$")
plt.xlabel("t")
plt.legend(loc="upper left", fontsize=20)
plt.axis([-10, 10, -0.1, 1.1])
plt.show(block=False)
plt.pause(2)
plt.close()
4.6.2 소프트맥스 회귀
-
소프트맥스 점수:
-
소프트맥스 함수:
-
크로스 엔트로피 비용 함수:
10_인공신경망
인공신경망(Artificial Neural Network): 생물학적 뉴런과 자연신경망에 착안해서 인공 뉴런으로 만든 신경망.
10.1 퍼셉트론
10.1.1 개념
퍼셉트론(perceptron): 인공 신경망의 가장 기본적인 형태로, 선형 분류 문제를 해결하기 위한 단순한 모델. 임계값 기준으로 1 또는 0 출력.
- 입력 층 (Input Layer): 입력 데이터를 받아들이는 층. 입력층의 각 뉴런은 모델의 입력 특성(feature)을 나타냄. 입력 층은 데이터의 원본 정보를 신경망에 제공 및 다음 층으로 데이터를 전달.
- 은닉 층 (Hidden Layer): 입력층과 출력층 사이에 위치하는 층. 하나 이상의 은닉 층이 있는 경우, 각 층은 입력 데이터를 가공하여 보다 추상적인 특성을 추출. 은닉 층에서의 뉴런은 비선형 활성화 함수를 통해 입력 신호를 변형하여 더 복잡한 패턴을 학습할 수 있음.
- 출력 층 (Output Layer): 모델의 최종 예측 결과를 생성하는 층. 출력층의 뉴런은 문제에 따라 다양한 형태의 출력을 생성.
- 완전 연결 층 (Fully Connected Layer): 모든 뉴런이 이전 층의 모든 뉴런과 연결되어 있는 층. 밀집 층(dense layer)이라고도 함.
- 편향(Bias): 각 뉴런에 추가되는 상수 값으로, y절편 역할을 함. 편향은 입력의 총합에 더해져서 활성화 함수의 결과를 조정. 이를 통해 모델은 더 유연하게 결정 경계를 설정할 수 있음.
- 피드포워드 신경망(Feedforward Neural Network): 입력에서 출력으로 데이터가 한 방향으로만 흐르는 신경망. 피드포워드 신경망은 순방향 전파(forward propagation)를 통해 입력 데이터를 처리하며, 출력층에서 예측 결과를 생성.
- 역전파 (Backpropagation): 출력층에서 계산된 오류를 입력층으로 역전파하여 가중치와 편향을 업데이트. 역전파는 경량화와 오류의 최소화를 통해 모델의 성능을 개선. 이 과정은 오류를 계산하고 이를 통해 가중치를 조정하는 과정을 포함.
- 활성화 함수(Activation Function): 인공 신경망의 뉴런에서 입력 신호를 변형하여 다음 층으로 전달하기 전에 비선형성을 추가하는 함수. 신경망이 복잡한 패턴과 비선형 관계를 학습할 수 있도록 만듦.
- 다층 퍼셉트론 (Multi-Layer Perceptron, MLP): 여러 개의 퍼셉트론을 층층이 쌓아 올린 모델. 다층 퍼셉트론은 하나 이상의 은닉 층을 포함하며, 이를 통해 비선형 문제를 해결.
10.1.2 다층 퍼셉트론 구현
다중 분류
- 데이터 불러오기
import tensorflow as tf
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
print(X_train_full.shape, X_train_full.dtype)
X_valid, X_train = X_train_full[:5000]/255, X_train_full[5000:]/255
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X_test = X_test / 255
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']- 모델 생성
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
# input 형태를 지정하고 1차원 변환
model.add(keras.layers.Dense(300, activation='relu'))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
# 클래스 갯수만큼 노드 생성
model.summary()
# 위와 동일한 결과
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation='relu'),
keras.layers.Dense(100, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# loss는 이진 분류, 원핫 분류, 라벨 분류, 회귀 등 모델에 맞는 loss 사용
# optimizer는 역전파 알고리즘
# metrics는 성능 평가 지표- 모델 구성 확인
print(model.layers)
hidden1 = model.layers[1]
print(hidden1.name)
print(model.get_layer(hidden1.name) is hidden1) # 'dense_3'
weights, biases = hidden1.get_weights()
print(weights)
print(weights.shape)
print(biases)
print(biases.shape)- 모델 훈련 및 평가
import pandas as pd
import matplotlib.pyplot as plt
# 훈련
history = model.fit(X_train, y_train, batch_size=1028, epochs=30, validation_data=(X_valid, y_valid))
# history는 모델의 훈련 정보를 반환 받음, model.history로도 확인 가능
# history 시각화
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show(block=False)
plt.pause(2)
plt.close()
# 평가
print(model.evaluate(X_test, y_test))
X_new = X_test[:3]
y_proba = model.predict(X_new)
y_proba.round(2)- fit의 일부 parameter 설명:
class_weight: 클래스 비율이 다를 때 지정
sample_weight: 샘플의 신뢰도?가치?가 다를 때 지정(ex: 한 샘플은 전문가가 레이블 지정, 다른 샘플은 비전문가가 레이블 지정)
회귀
- 데이터 불러오기
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(housing.data, housing.target)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full)
# 스케일링
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)- 모델 생성 및 훈련·예측
model = keras.models.Sequential([
keras.layers.Dense(30, activation='relu', input_shape=X_train.shape[1:]),
keras.layers.Dense(1) # 회귀임으로 노드 1개
])
model.compile(loss='mean_squared_error', optimizer='sgd')
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
X_new = X_test[:3]
y_pred = model.predict(X_new)10.1.3 다양한 모델 만드는 방법
Residual Connection
입력값을 네트워크의 중간 레이어의 출력에 더하여 다음 레이어로 전달하는 구조.
- 수식:
- 는 레이어의 입력, 는 네트워크의 중간 레이어에서 계산된 출력.
- 장점:
- 기울기 소실 문제 해결: 입력값을 직접 전달함으로써, 기울기가 네트워크의 더 깊은 층까지 전달되기 쉬워짐.
- 학습의 용이성: 네트워크가 더 쉽게 학습할 수 있도록 하여, 매우 깊은 네트워크에서도 효과적으로 학습할 수 있음.
- 성능 향상: 더 깊은 네트워크에서의 성능 향상을 도움.
Skip Connection
네트워크의 한 레이어에서 다른 레이어로 직접 연결하는 방식. 이 방식은 입력값이나 중간 레이어의 출력을 네트워크의 더 깊은 층으로 직접 전달.
-
수식:
- 는 입력값 를 직접 전달하는 함수 또는 변형 함수. 는 네트워크의 중간 레이어에서 계산된 출력.
-
장점:
- 정보 유지: 입력값이나 중간 레이어의 출력을 직접 전달함으로써, 네트워크 정보 손실 감소.
- 다양한 적용: Skip Connection은 Residual Connection뿐만 아니라 다양한 네트워크 구조에서 사용.
-
함수형 API
# Residual Connection
input_ = keras.layers.Input(shape=X_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation='relu')(input_)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
concat = keras.layers.Concatenate()([input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.Model(inputs=[input_], outputs=[output])
model.compile('SGD', 'mse')
model.fit(X_train, y_train, 1028, 20, validation_data=(X_valid, y_valid))
model.evaluate(X_test, y_test)
# 다중 입력
input_A = keras.layers.Input(shape=[5], name='wide_input') # short_path
input_B = keras.layers.Input(shape=[6], name='deep_input')
hidden1 = keras.layers.Dense(30, activation='relu')(input_B)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
concat = keras.layers.concatenate([input_A, input_B])
output = keras.layers.Dense(1, name='output')(concat)
model = keras.Model(inputs=[input_A, input_B], outputs=output)
model.compile(loss='mse', optimizer=keras.optimizers.SGD(learning_rate=1e-3))
X_train_A, X_train_B = X_train[:, :5], X_train[:, 2:]
X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:, 2:]
X_test_A, X_test_B = X_test[:, :5], X_test[:, 2:]
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3]
history = model.fit((X_train_A, X_train_B), y_train, epochs=20,
validation_data=((X_valid_A, X_valid_B), y_valid))
mse_test = model.evaluate((X_test_A, X_test_B), y_test)
y_pred = model.predict((X_new_A, X_new_B))
# 다중 출력 및 보조출력
input_A = keras.layers.Input(shape=[5], name='wide_input') # short_path
input_B = keras.layers.Input(shape=[6], name='deep_input')
hidden1 = keras.layers.Dense(30, activation='relu')(input_B)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
concat = keras.layers.concatenate([input_A, input_B])
output = keras.layers.Dense(1, name='main_output')(concat)
aux_output = keras.layers.Dense(1, name='aux_output')(hidden2)
model = keras.Model(inputs=[input_A, input_B], outputs=[output, aux_output])
model.compile(loss=['mse', 'mse'], loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(learning_rate=1e-3))
history = model.fit((X_train_A, X_train_B), [y_train, y_train], epochs=20,
validation_data=((X_valid_A, X_valid_B), [y_valid, y_valid]))
total_loss, main_loss, aux_loss = model.evaluate((X_test_A, X_test_B), [y_test, y_test])
print(total_loss, main_loss, aux_loss)
y_pred_main, y_pred_aux = model.predict((X_new_A, X_new_B))
print(y_pred_main, y_pred_aux, sep='\n\n')- 서브클래싱
class WideAndDeepModel(keras.Model):
def __init__(self, units=30, activation='relu', **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel()
model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(learning_rate=1e-3))
history = model.fit((X_train_A, X_train_B), (y_train, y_train), epochs=10,
validation_data=((X_valid_A, X_valid_B), (y_valid, y_valid)))
total_loss, main_loss, aux_loss = model.evaluate((X_test_A, X_test_B), [y_test, y_test])
print(total_loss, main_loss, aux_loss)
y_pred_main, y_pred_aux = model.predict((X_new_A, X_new_B))
print(y_pred_main, y_pred_aux, sep='\n\n')10.1.4 모델 저장과 복원
#### API 모델
model.save(path + model_name.h5)
model = keras.models.load_model(path + model_name.h5)
#### 서브클래싱 모델
### 모델 전체 저장
model.save(path + dir_name, save_format='tf')
model = keras.models.load_model(path + dir_name, custom_objects={'SubClassing': SubClassing})
### 모델 가중치 저장 ※ 확장자는 ckpt
model.save_weights(path + model_name.ckpt)
# 동일한 구조로 모델 정의
model = SubClassing()
model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer='SGD')
model.load_weights(path + model_name.ckpt)
### 확장자를 h5를 썼을 경우에는 fit을 해야지만 load 가능 내부 변수 어쩌구하는데 이유는 모름. gpt도 모름
model.save_weights(path + model_name.h5)
# 동일한 구조로 모델 정의
model = SubClassing()
model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer='SGD')
# 최소 조건으로 fit
history = model.fit((X_train_A[:1], X_train_B[:1]), (y_train[:1], y_train[:1]), epochs=1)
# 가중치 로드
model.load_weights(path + model_name.h5)
y_pred_main, y_pred_aux = model.predict((X_new_A, X_new_B))
print(y_pred_main, y_pred_aux, sep='\n\n')10.1.5 콜백 사용
- 사용자 콜백 생성
class PrintValTrainRatioCallback(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nval/train: {:.2f}'.format(logs['val_loss']/logs['loss']))
# 아래의 함수를 이용해서 callback 생성 가능
# on_batch_begin, on_batch_end,
# on_epoch_begin, on_epoch_end,
# on_predict_batch_begin, on_predict_batch_end, on_predict_begin, on_predict_end,
# on_test_batch_begin, on_test_batch_end, on_test_begin, on_test_end,
# on_train_batch_begin, on_train_batch_end, on_train_begin, on_train_end,- 체크포인트, 얼리스탑
# 모델 생성
class WideAndDeepModel(keras.Model):
def __init__(self, units=30, activation='relu', **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel()
model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(learning_rate=1e-3))
# 콜백 생성 및 사용
checkpoint_cb = keras.callbacks.ModelCheckpoint('my_keras_model.ckpt')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=1, restore_best_weights=True)
custom_callback = PrintValTrainRatioCallback()
history = model.fit((X_train_A, X_train_B), (y_train, y_train), epochs=100,
validation_data=((X_valid_A, X_valid_B), (y_valid, y_valid)),
callbacks=[checkpoint_cb, early_stopping_cb, custom_callback])
total_loss, main_loss, aux_loss = model.evaluate((X_test_A, X_test_B), [y_test, y_test])
print(total_loss, main_loss, aux_loss)
y_pred_main, y_pred_aux = model.predict((X_new_A, X_new_B))
print(y_pred_main, y_pred_aux, sep='\n\n')10.1.6 텐서보드
tensorflow의 시각화 도구
class WideAndDeepModel(keras.Model):
def __init__(self, units=30, activation='relu', **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel()
model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(learning_rate=1e-3))
# 텐서보드 콜백
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
history = model.fit((X_train_A, X_train_B), (y_train, y_train), batch_size=1028, epochs=30,
validation_data=((X_valid_A, X_valid_B), (y_valid, y_valid)),
callbacks=[tensorboard_cb])터미널에서 입력
$ tensorboard --logdir=./my_logs --port=6006
폴더가 여러 개일 경우
$ tensorboard --logdir=./my_logs --reload_multifile=true --port=6006
실행 후 http://localhost:6006/ 로 이동하여 사용
- tf.summary
test_logdir = get_run_logdir()
writer = tf.summary.create_file_writer(test_logdir)
with writer.as_default():
for step in range(1, 1000+1):
tf.summary.scalar('my_scalar', np.sin(step/10), step=step)
data = (np.random.randn(100) + 2) * step /100
tf.summary.histogram('my_hist', data, buckets=50, step=step)
images = np.random.rand(2, 32, 32, 3) # 32*32 RGB 이미지
tf.summary.image('my_images', images * step / 1000, step=step)
texts = ['The step is ' + str(step), 'Its square is ' + str(step**2)]
tf.summary.text('my_text', texts, step=step)
sine_wave = tf.math.sin(tf.range(12000) / 48000 * 2 * np.pi * step)
audio = tf.reshape(tf.cast(sine_wave, tf.float32), [1, -1, 1])
tf.summary.audio('my_audio', audio, sample_rate=48000, step=step)뭔가 기능은 많은데 잘 모르겠음
10.2 하이퍼파라미터 튜닝
# 모델 생성
def build_model(n_hidden=1, n_neurons=30, learning_rate=3e-3, input_shape=[8]):
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=input_shape))
for layer in range(n_hidden):
model.add(keras.layers.Dense(n_neurons, activation='relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate=learning_rate)
model.compile(loss='mse', optimizer=optimizer)
return model
keras_reg = keras.wrappers.scikit_learn.KerasRegressor(build_model)
# keras.wrappers.scikit_learn: Keras 모델을 Scikit-Learn의 API와 호환되도록 만드는 유틸리티
from scipy.stats import reciprocal
from sklearn.model_selection import RandomizedSearchCV
param_distribs = {
'n_hidden': [0, 1, 2, 3],
# 'n_neurons': np.arange(1,100),
'n_neurons': [2**n for n in range(8)],
'learning_rate': reciprocal(3e-4, 3e-2)
}
rnd_search_cv = RandomizedSearchCV(keras_reg, param_distribs, n_iter=10, cv=3)
rnd_search_cv.fit(X_train, y_train, batch_size=1028, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=[keras.callbacks.EarlyStopping(patience=10)])
print(rnd_search_cv.best_params_)
print(rnd_search_cv.best_score_)
print(rnd_search_cv.best_estimator_)
model = rnd_search_cv.best_estimator_.model11_심층 신경망
11.1 기울기 소실 및 폭주
-
기울기 소실 (Vanishing Gradient): 네트워크의 역전파 과정에서 기울기(gradient)가 점점 작아지는 현상. 네트워크의 깊이가 깊어질수록 잘 발생하며, 결과적으로 네트워크의 초기 층에서는 기울기가 거의 0에 가까워져 학습이 잘 되지 않음.
- 해결법
- 수렴하지 않는 함수 사용: ReLU (Rectified Linear Unit)와 그 변형 함수(Leaky ReLU, Parametric ReLU 등) 등 사용(양숫값이 제한 되지 않아 기울기 소실 방지).
- 배치 정규화(Batch Normalization): 각 층의 입력을 정규화하여 기울기 소실을 완화.
- 가중치 초기화 방법: 적절한 가중치 초기화 방법 (예: He Initialization, Xavier Initialization)을 사용하여 기울기 소실 방지.
-
기울기 폭주 (Exploding Gradient): 네트워크의 역전파 과정에서 기울기가 발산하는 현상. 네트워크의 가중치가 급격하게 커져서 학습이 불안정해짐.
- 해결법
- 기울기 클리핑 (Gradient Clipping): 기울기의 크기를 미리 정해진 임계값으로 제한.
- 배치 정규화 (Batch Normalization): 네트워크의 각 층의 입력을 정규화하여 기울기 폭주를 줄임.
- 가중치 초기화: 적절한 가중치 초기화 방법 (예: He Initialization, Xavier Initialization)을 사용하여 기울기 소실 방지.
11.1.1 수렴하지 않는 함수
- 활성화 함수에 따라 초기화 방법이 다름.
| 초기화 전력 | 활성화 함수 | (정규분포) |
|---|---|---|
| Glorot (Xavier) Initialization | 활성화 함수 없음, Sigmoid, Tanh, logistic, softmax | |
| He Initialization | ReLU와 그 변종 | |
| LeCun Initialization | SELU |
: 입력 층 노드의 개수
: 출력 층 노드의 개수
# 케라스는 기본적으로 균등분포의 그로럿 초기화 사용
from tensorflow import keras
# kernel_initializer 설정
keras.layers.Dense(10, activation='relu', kernel_initializer='he_normal')
he_avg_init = keras.initializers.VarianceScaling(scale=2, mode='fan_avg', distribution='uniform')
keras.layers.Dense(10, activation='sigmoid', kernel_initializer=he_avg_init);| 활성화 함수 | 설명 | 수식 | 특징 |
|---|---|---|---|
| ReLU | 입력이 0보다 크면 입력 값을 그대로 출력하고, 0 이하일 경우 0을 출력합니다. | 계산이 간단하고 빠르며 기울기 소실 문제를 줄임. | |
| Leaky ReLU | 입력이 0 이하일 경우 작은 기울기 를 사용하여 출력합니다. | 0 이하의 입력에 대해 작은 기울기를 사용하여 죽은 뉴런 문제를 완화. | |
| RReLU | Leaky ReLU의 변형으로, 입력이 0 이하일 경우 무작위로 선택된 기울기 값을 사용합니다. | 학습 중에 무작위 기울기를 사용하여 더 강력한 일반화 성능을 제공. | |
| PReLU | 입력이 0 이하일 경우 학습 가능한 기울기 를 사용하여 출력합니다. | 는 학습 가능한 파라미터로, 네트워크가 최적의 기울기 값을 학습할 수 있음. | |
| ELU | 입력이 0 이하일 경우 지수 함수를 사용하여 부드러운 출력을 제공합니다. | 0 이하의 입력에 대해 매끄럽고 0에 가까운 출력을 제공하여 기울기 소실 문제를 완화. | |
| SELU | ELU의 변형으로, 자기 정규화(self-normalizing) 기능을 갖추고 있어 네트워크 깊이가 깊어도 안정적인 학습이 가능. | 학습 과정에서 평균이 0, 분산이 1로 유지되도록 설계되어 네트워크의 자기 정규화를 촉진. |
- : 활성화 함수의 하이퍼파라미터 (Leaky ReLU, RReLU, PReLU에서 사용)
- : SELU 함수의 스케일링 파라미터 (통상적으로 1.0507로 설정됨)
- SELU 주의점:
- 입력 특성 표준화(평균 0, 표준편차1)
- 모든 은닉층 가중치는 르쿤 정규분포 초기화 사용(keras 기준 kernel_initializer='lecun_normal')
- 일렬로 쌓은 층으로 구성(순환 신경망이나 스킵 연결 지양, 자기 정규화가 보장되지 않음)
- 일반적인 사용 순서
SELU > ELU > LeakyReLU(포함 ReLU 변종) > ReLU> tanH > logistic
자기 정규화 불가 시: ELU
실행 속도: LeakyReLU
과대 적합 시: RReLU
훈련 세트 거대: PReLU
# LeakyReLU
keras.layers.Dense(10, kernel_initializer='he_normal')
keras.layers.LeakyReLU(alpha=0.2)
# SELU
keras.layers.Dense(10, activation='selu', kernel_initializer='lecun_normal');11.1.2 배치 정규화
신경망의 각 층에 대해 입력 데이터의 분포를 정규화하는 과정. 학습을 안정화하고 가속화하여 더 빠르고 효율적인 네트워크 학습 가능.
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.BatchNormalization(momentum=0.99), # momentum: 기본 0.99 미니배치가 작을수록 소수점 뒤에 9를 넣어 1에 가깝게 만듦
keras.layers.Dense(300, activation='elu', kernel_initializer='he_normal'),
keras.layers.BatchNormalization(),
keras.layers.Dense(100, kernel_initializer='he_normal', use_bias=False),
keras.layers.BatchNormalization(),
keras.layers.Activation('elu'),
keras.layers.Dense(10, activation='softmax'),
])
model.summary()배치 정규화는 너무 작은 배치 크기에서는 잘 동작하지 않을 수 있고 RNN에 적용하기 어려움.
책에서 Fixup(fixed-update) 가중치 초기화 기법을 언급하였으나 관련 최신 내용 찾기 어려움.
11.1.3 그래디언트 클리핑(Gradient Clipping)
역전파 시 일정 임곗값을 넘지 못하게 기울이글 잘라내어 기울기 폭주 문제를 완화.
optimizer = keras.optimizers.SGD(clipvalue=1.0, clipnorm=1.0)
# clipvalue=1.0: loss의 모든 편미분 값을 -1.0 ~ 1.0으로 잘라냄.
# clipnorm=1.0: 해당 값 기준으로 정규화
# 두 인자 모두 기입 시 norm을 먼저 적용
model.compile(loss='mse', optimizer=optimizer)11.2 전이학습
전이 학습(transfer learning): 이미 학습된 모델을 다른 문제에 재사용하는 방법.
11.2.1 전이 학습의 유형
- 특징 추출(Feature Extraction): 사전 학습된 모델의 중간 층에서 추출된 특징을 활용하여 새로운 데이터셋에서 학습. 사전 학습 모델의 가중치는 동결하고 마지막 레이어만 학습.
- 미세 조정(Fine-Tuning): 사전 학습된 모델의 전체 또는 일부 층을 새로운 데이터셋에 맞게 추가 학습.
- 모델 재학습: 사전 학습된 모델의 가중치를 초기값으로 사용하여 새 데이터셋에 맞게 처음부터 끝까지 학습.
11.2.2 사전 학습 모델 획득
- 기존 학습한 모델 사용.
- 비지도 사전훈련: 오토인코더나 GAN을 훈련하여 하위층을 재사용.
- 보조작업에서 사전 훈련: 레이블된 학습 데이터가 적을 경우, 레이블된 훈련 데이터를 쉽게 얻거나 생성할 수 있는 보조 작업에서 첫 번째 신경망을 훈련.
11.3 옵티마이저
11.3.1 모멘텀(momentum)
매 반복에서 현재 기울기를 학습률에 곱하고 모멘텀 벡터에 더한 후 이값을 빼는 방식으로 가중치를 갱신. 기울기를 가속도로 이용.
optimizer = keras.optimizers.SGD(learning_rate=0.001, momentum=0.9)11.3.2 네스테로프 가속 경사(Nesterov Accelerated Gradient, NAG)
현재의 모멘텀이 아닌 예측한 모멘텀으로 계산하여 진동을 감소시키고 수렴을 빠르게 만듬.
optimizer = keras.optimizers.SGD(learning_rate=0.001, momentum=0.9, nesterov=True)11.3.3 AdaGrad(Adaptive Gradient Algorithm)
가장 가파른 차원을 따라 그레디언트 벡터의 스케일을 감소시키는 적응적 학습률(adaptive learning rate) 사용.
optimizer = keras.optimizers.Adagrad(learning_rate=0.001)11.3.4 RMSprop(Root Mean Square Propagation)
가장 최근 반복에서 비롯된 그레디언트만 누적하여 계산.
optimizer = keras.optimizers.RMSprop(learning_rate=0.001, rho=0.9)11.3.5 Adam (Adaptive Moment Estimation)
모멘텀 최적화와 RMSProp를 합친 것.
optimizer = keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999)- AdaMax: 기울기 제곱의 무한 노름을 사용하여 학습률을 조정.
optimizer = keras.optimizers.Adamax(learning_rate=0.001, beta_1=0.9, beta_2=0.999)- Nadam 네스테로프 기법을 더한 것.
optimizer = keras.optimizers.Nadam(learning_rate=0.001, beta_1=0.9, beta_2=0.999)11.3.6 학습 스케쥴
큰 학습률로 시작하여 학습 속도가 느려질 때 학습률을 낮추는 방법.
- 거듭제곱 스케줄링: t=time, s= step
- 지수 스케줄링:
- 구간별 고정 스케줄링: 직접 구간별 학습률 지정
- 성능 스케줄링: 스템마다 검증오차를 측정하고 오차 미감소시 배 만큼 학습률 감소
- 1사이클 스케줄링:
- 훈련 절반 동안 를 선형적으로 까지 증가. 은 최적의 학습률 방법 적용. 는 대략 의 0.1배
- 나머지 절반 동안 선형적으로 로 감소 및 최종 몇 번의 에폭은 선형적으로 소수점 n자리까지 줄임.
- 모멘텀 존재 경우 선형적으로 감소 후 증가, 최종 몇 번은 최대값으로 진행.
- 구현
# 거듭제곱법
optimizer = keras.optimizers.SGD(learning_rate=0.01, decay=1e-4)
# 지수
def exponential_decay_fn(epoch):
return 0.01 * 0.1**(epoch/20)
def exponential_decay(lr0, s):
def exponential_decay_fn(epoch):
return 0.01 * 0.1**(epoch/20)
return exponential_decay_fn
exponential_decay_fn = exponential_decay(lr0=0.01, s=20)
# callback 기능을 이용하기 때문에 위의 형태로 작성
lr_scheduler = keras.callbacks.LearningRateScheduler(exponential_decay_fn)
history = model.fit(X_train, y_train, batch_size=1028, epochs=200, callbacks=[lr_scheduler])
def exponential_decay_fn(epoch, lr):
return lr * 0.1**(1/20)
# 구간별 고정
def piecewuse_constant_fn(epoch):
if epoch < 5:
return 0.01
elif epoch <15:
return 0.005
else:
return 0.001
# 성능 기반
lr_scheduler = keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=5)
# 연속 patience에폭 동안 vla_loss가 개션되지 않을 때 factor를 학습률에 곱함
import math
### 1사이클
# 최적 학습률 확인
class ExponentialLearningRate(keras.callbacks.Callback):
def __init__(self, factor):
self.factor = factor
self.rates = []
self.losses = []
def on_epoch_begin(self, epoch):
self.prev_loss = 0
def on_batch_end(self, batch, logs=None):
batch_loss = logs["loss"] * (batch + 1) - self.prev_loss * batch
self.prev_loss = logs["loss"]
self.rates.append(model.optimizer.lr.numpy())
self.losses.append(batch_loss)
self.model.optimizer.lr = self.model.optimizer.lr * self.factor
def find_learning_rate(model, X, y, epochs=1, batch_size=32, min_rate=10**-5, max_rate=10):
init_weights = model.get_weights()
iterations = math.ceil(len(X) / batch_size) * epochs
factor = np.exp(np.log(max_rate / min_rate) / iterations)
init_lr = model.optimizer.lr.numpy()
model.optimizer.lr = min_rate
exp_lr = ExponentialLearningRate(factor)
history = model.fit(X, y, epochs=epochs, batch_size=batch_size,
callbacks=[exp_lr])
model.optimizer.lr = init_lr
model.set_weights(init_weights)
return exp_lr.rates, exp_lr.losses
# 1사이클 클래스
class OneCycleScheduler(keras.callbacks.Callback):
def __init__(self, iterations, max_rate, start_rate=None, last_iterations=None, last_rate=None):
self.total_iteration = iterations # 총 학습률 조정 반복 횟수
self.max_rate = max_rate # 최대 학습률
self.start_rate = start_rate or max_rate / 10 # 시작 학습률 (디폴트는 최대 학습률의 10%)
self.last_iterations = last_iterations or iterations // 10 + 1 # 마지막 단계의 반복 횟수 (디폴트는 총 반복 횟수의 10%)
self.half_iteration = (iterations - self.last_iterations) // 2 # 중간 단계 반복 횟수
self.last_rate = last_rate or self.start_rate / 1000 # 마지막 학습률 (디폴트는 시작 학습률의 1/1000)
self.current_iteration = 0 # 현재 반복 횟수 초기화
def _interpolate(self, from_iter, to_iter2, from_rate, to_rate):
# 두 지점 사이에서 선형 보간을 통해 학습률 계산하여 to_iter까지 선형적으로 rate 변화
return ((to_rate - from_rate) * (self.current_iteration - from_iter) / (to_iter2 - from_iter) + from_rate)
def on_batch_begin(self, batch, logs):
if self.current_iteration < self.half_iteration:
# 초기 상승 단계
rate = self._interpolate(0, self.half_iteration, self.start_rate, self.max_rate)
elif self.current_iteration < 2 * self.half_iteration:
# 최대 학습률로 상승한 후 하락 단계
rate = self._interpolate(self.half_iteration, 2 * self.half_iteration, self.max_rate, self.start_rate)
else:
# 마지막 하락 단계
rate = self._interpolate(2 * self.half_iteration, self.total_iteration, self.start_rate, self.last_rate)
self.current_iteration += 1 # 반복 횟수 증가
self.model.optimizer.lr = rate # 모델의 학습률 업데이트11.4 과적합 방지
11.4.1 과 규제
- 규제: 모델의 가중치 벡터에 대한 노름을 규제 항으로 추가하는 방식. 노름은 벡터의 각 요소의 절대값을 합한 것.
- 규제: 모델의 가중치 벡터에 대한 노름을 규제 항으로 추가하는 방식. 노름은 벡터의 각 요소의 제곱을 합한 후 제곱근을 취한 것.
# 규제 적용 방식
layer = keras.layers.Dense(100, activation='elu',
kernel_initializer='he_normal',
kernel_regularizer=keras.regularizers.l1(0.01))
layer = keras.layers.Dense(100, activation='elu',
kernel_initializer='he_normal',
kernel_regularizer=keras.regularizers.l2(0.01))
layer = keras.layers.Dense(100, activation='elu',
kernel_initializer='he_normal',
kernel_regularizer=keras.regularizers.l1_l2(0.01, 0.01))
# 적용
from functools import partial
# partial: 함수의 인자 기본값을 새로 지정하여 사용할 수 있게 함.
RegularizedDense = partial(keras.layers.Dense,
activation='elu',
kernel_initializer='he_normal',
kernel_regularizer=keras.regularizers.l1_l2(0.01, 0.01))
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
RegularizedDense(300),
RegularizedDense(100, activation='relu'),
RegularizedDense(10, activation='softmax', kernel_initializer='glorot_uniform')
])
[print(layer.activation) for layer in model.layers[1:]];11.4.2 Dropout
학습하는 동안 신경망의 일부 뉴런을 dropout rate에 따라 생략하여, 모델이 특정 뉴런에 과도하게 의존하지 않도록 하는 것.
※ 일반적으로 출력층 제외한 맨 위의 측부터 3번째층까지만 드롭아웃 적용
※ SELU 사용 시 AlphaDropout 사용: 자기 정규화 네트워크 규제
- 보존 확률(keep probability): 뉴련이 훈련한 것보다 많은 입력 신호 받아 오류 나는 것을 방지하기 위해 훈련이 끝난 뒤 각 입력의 연결 가중치에 곱하는 값(1-dropout rate). 케라스에선 자동 적용
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[29, 29]),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(300, activation='elu', kernel_initializer='he_normal'),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(100, activation='elu', kernel_initializer='he_normal'),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(10, activation='softmax')
])11.4.3 몬테 카를로 드롭아웃(Monte Carlo dropout)
MC dropout: dropout을 test에도 사용, 예측값을 상이하게 하여 여러 번 예측한 값들의 편균으로 예측하는 것. summation과 동일
※ 확실하진 않지만 이미 모델의 성능이 높을 때는 오히려 성능이 떨어지는 듯
import numpy as np
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from sklearn.metrics import accuracy_score
# 데이터 준비 (예제 데이터 사용)
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.reshape(-1, 3072).astype('float32') / 255
x_test = x_test.reshape(-1, 3072).astype('float32') / 255
# 모델 정의
model = Sequential([
Dense(300, activation='relu', input_shape=(3072,)),
Dropout(0.5), # Dropout 층 추가
Dense(100, activation='relu'),
Dropout(0.5), # Dropout 층 추가
Dense(10, activation='softmax')
])
# 모델 컴파일
model.compile(loss="sparse_categorical_crossentropy", optimizer='adam', metrics=["accuracy"])
# 모델 훈련
model.fit(x_train, y_train, batch_size=1024, epochs=100, validation_split=0.2)
# 검증
y_probas = np.stack([model(x_test, training=True)
for sample in range(100)])
y_proba = y_probas.mean(axis=0)
y_pred = np.argmax(y_proba, axis=1)
print(accuracy_score(y_test, np.argmax(model.predict(x_test), axis=1)))
print(accuracy_score(y_test, y_pred))- 모델이 훈련하는 동안 다르게 작동하는 층(BatchNormalization 등)이 있을 경우
class MCDropout(keras.layers.Dropout):
def call(self, inputs):
return super().call(inputs, training=True)
# training을 True로 반환하여 개별적으로 설정.
mc_model = keras.models.Sequential([
MCDropout(layer.rate) if isinstance(layer, keras.layers.Dropout) else layer
for layer in model.layers
])
optimizer = keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, nesterov=True)
mc_model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
mc_model.set_weights(model.get_weights())
y_probas = np.stack([mc_model.predict(x_test)
for sample in range(100)])
# predict로 예측11.4.4 맥스-노름 규제(max-norm regularization)
각 뉴런의 가중치 벡터의 노름(norm)을 제한하여 과적합을 방지하는 방법.
keras.layers.Dense(100, activation='elu', kernel_initializer='he_normal',
kernel_constraint=keras.constraints.max_norm(1.))12_사용자 정의 모델과 훈련 알고리즘
12.1 tensorflow
구글에서 개발한 수치 계산용 라이브러리리
12.1.1 텐서플로 기본(연산, 타입 변환 등)
- 연산 및 타입구조
import tensorflow as tf
# 텐서플로 상수(변경 불가 객체)
t = tf.constant([[1., 2., 3.], [4., 5., 6.,]])
# 텐서 생성
print(t,
t[:, :, tf.newaxis],
t+10,
tf.square(t),
t@tf.transpose(t),
tf.cast(t, tf.float16),
sep='\n\n')
# 텐서플로 변수(변경 가능 객체: 가중치, 기울기 등에 사용)
v = tf.Variable([[1., 2., 3.], [4., 5., 6.]])
print(v)
v.assign(2*v)
print(v)
v[0, 1].assign(42)
print(v)
v[:, 1].assign([0., 1.])
print(v)
v.scatter_nd_update(indices=[[0, 0], [1, 2]], updates=[100., 200.])
print(v)- 다양한 데이터 구조: 희소 텐서(tf.SparseTensor), 텐서 배열(tf. TensorArray), 래그드 텐서(tf.RaggedTensor), 문자열 텐서(tf.string), 집합(tf.sets), 큐(tf.queue) 등
12.2 사용자 정의 알고리즘
12.2.1 손실 함수
데이터 블러오기
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(
housing.data, housing.target.reshape(-1, 1), random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_full, y_train_full, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_valid_scaled = scaler.transform(X_valid)
X_test_scaled = scaler.transform(X_test)
# 사용자 정의 손실 함수
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < 1
squared_loss = tf.square(error) / 2
linear_loss = tf.abs(error) -0.5
return tf.where(is_small_error, squared_loss, linear_loss)
# 사용자 정의 손실 함수 인자 설정
def create_huber(threshold=1.0):
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < threshold
squared_loss = tf.square(error) / 2
linear_loss = threshold * tf.abs(error) - threshold**2 / 2
return tf.where(is_small_error, squared_loss, linear_loss)
return huber_fn
# 사용자 정의 손실함수 인자 저장
class HuberLoss(keras.losses.Loss):
def __init__(self, threshold=1.0, **kwargs):
self.threshold = threshold
super().__init__(**kwargs)
def call(self, y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < self.threshold
squared_loss = tf.square(error) / 2
linear_loss = self.threshold * tf.abs(error) - self.threshold**2 / 2
return tf.where(is_small_error, squared_loss, linear_loss)
def get_config(self):
base_config = super().get_config()
return {**base_config, 'threshold': self.threshold}
# get_config를 통해 threshold 인자까지 저장
# 훈련, 저장, 불러오기
model.compile(loss=HuberLoss(2.0), optimizer='nadam', metrics=['mae'])
model.fit(X_train_scaled, y_train, epochs=2,
validation_data=(X_valid_scaled, y_valid))
model.save("my_model_with_a_custom_loss.h5")
model = keras.models.load_model("my_model_with_a_custom_loss.h5",
custom_objects={"HuberLoss": HuberLoss})12.2.2 활성화 함수, 초기화, 규제, 제한
# 함수
def my_softplus(z):
return tf.math.log(tf.exp(z) + 1.0)
def my_glorot_initializer(shape, dtype=tf.float32):
stddev = tf.sqrt(2. / (shape[0] + shape[1]))
return tf.random.normal(shape, stddev=stddev, dtype=dtype)
def my_l1_regularizer(weights):
return tf.reduce_sum(tf.abs(0.01 * weights))
def my_positive_weights(weights):
return tf.where(weights < 0., tf.zeros_like(weights), weights)
# 클래스
class MyL1Regularizer(keras.regularizers.Regularizer):
# 부모 클래스에 생성자와 get_config가 정의돼 있지 않아 호출(super) 불요.
def __init__(self, factor):
self.factor = factor
def __call__(self, weights):
# loss, layer, model의 경우 call / regularizer, initializer, constraint의 경우 __call__
return tf.reduce_sum(tf.abs(self.factor * weights))
def get_config(self):
return {'factor': self.factor}
# 적용
layer = keras.layers.Dense(30, activation=my_softplus,
kernel_initializer=my_glorot_initializer,
kernel_regularizer=my_l1_regularizer,
kernel_constraint=my_positive_weights,
input_shape=input_shape)
model = keras.models.Sequential([
layer,
keras.layers.Dense(1, activation=my_softplus,
kernel_regularizer=MyL1Regularizer(0.01),
kernel_constraint=my_positive_weights,
kernel_initializer=my_glorot_initializer),
])
model.compile(loss="mse", optimizer="nadam", metrics=["mae"])
model.save("my_model_with_many_custom_parts.h5")
model = keras.models.load_model(
"my_model_with_many_custom_parts.h5",
custom_objects={
"my_l1_regularizer": my_l1_regularizer,
"my_positive_weights": my_positive_weights,
"my_glorot_initializer": my_glorot_initializer,
"my_softplus": my_softplus,
'MyL1Regularizer': MyL1Regularizer
})12.2.3 지표(metric)
- metric 구성 및 작동 방식
precision = keras.metrics.Precision()
print(precision([0, 1, 1, 1, 0, 1, 0, 1], [1, 1, 0, 1, 0, 1, 0, 1]))
print(precision([0, 1, 0, 0, 1, 0, 1, 1], [1, 0, 1, 1, 0, 0, 0, 0]))
print(precision.result())
[print(_) for _ in precision.variables]
precision.reset_states()
print(precision.result())- 사용자 정의 지표
# 사용자 정의 지표 컴파일 및 훈련
model.compile(loss='mse', optimizer='nadam', metrics=[create_huber(2.0)])
model.fit(X_train_scaled, y_train, epochs=2,
validation_data=(X_valid_scaled, y_valid))
# 클래스 구현
class HuberMetric(keras.metrics.Metric):
def __init__(self, threshold=1.0, **kwargs):
super().__init__(**kwargs)
self.threshold = threshold
self.huber_fn = create_huber(threshold)
self.total = self.add_weight('total', initializer='zeros')
self.count = self.add_weight('count', initializer='zeros')
def update_state(self, y_true, y_pred, sample_weight=None):
metric = self.huber_fn(y_true, y_pred)
# tf.Variable 객체이므로 assign_add 사용
self.total.assign_add(tf.reduce_sum(metric))
self.count.assign_add(tf.cast(tf.size(y_true), tf.float32))
def result(self):
return self.total / self.count
def get_config(self):
base_config = super().get_config()
return {**base_config, 'threshold': self.threshold}
model.compile(loss=create_huber(2.0), optimizer="nadam", metrics=[HuberMetric(2.0)])
model.fit(X_train_scaled.astype(np.float32), y_train.astype(np.float32), epochs=2)12.2.4 layer
exponential_layer = keras.layers.Lambda(lambda x: tf.exp(x)) # 지수 함수
# 사용자 정의 layer
class MyDense(keras.layers.Layer):
def __init__(self, units, activation=None, **kwargs):
super().__init__(**kwargs) # 부모 클래스의 초기화 메서드를 호출합니다.
self.units = units # 출력 유닛 수를 저장합니다.
self.activation = keras.activations.get(activation) # 활성화 함수를 가져옵니다.
def build(self, batch_input_shape):
# 커널 가중치: 입력 차원과 유닛 차원을 가지며, 'glorot_normal' 초기화 방법을 사용합니다.
self.kernel = self.add_weight(
name='kernel', shape=[batch_input_shape[-1], self.units],
initializer='glorot_normal'
)
# 바이어스: 유닛 수에 해당하는 크기를 가지며, 0으로 초기화됩니다.
self.bias = self.add_weight(
name='bias', shape=[self.units], initializer='zeros'
)
super().build(batch_input_shape) # 부모 클래스의 build 메서드를 호출하여 추가적인 작업을 수행합니다.
def call(self, X):
# X와 kernel의 행렬 곱에 bias를 더하고 활성화 함수를 적용합니다.
return self.activation(X @ self.kernel + self.bias)
def compute_output_shape(self, batch_input_shape):
# 입력 모양에서 마지막 차원을 유닛 수로 대체하여 출력 모양을 계산합니다.
return tf.TensorShape(batch_input_shape.as_list()[:-1] + [self.units])
def get_config(self):
base_config = super().get_config() # 부모 클래스의 구성 정보를 가져옵니다.
return {**base_config, 'units': self.units,
'activation': keras.activations.serialize(self.activation)} # 추가된 구성 정보를 포함합니다.# 다중 입력 및 출력 층 생성
class MyMultilayer(keras.layers.Layer):
def call(self, X):
X1, X2 = X
return [X1+X2, X1*X2, X1/X2]
def compute_output_shape(self, batch_input_shape):
b1, b2 = batch_input_shape
return [b1, b1, b1] # 맞게 브로드캐스팅 돼야 함.# 훈련에서만 동작하는 층(ex: Dropout, BatchNormalization)
class MyGaussianNoise(keras.layers.Layer):
def __init__(self, stddev, **kwargs):
super().__init__(**kwargs)
self.stddev = stddev
def call(self, X, training=None):
if training:
noise = tf.random.normal(tf.shape(X), stddev=self.stddev)
return X + noise
else:
return X
def compute_output_shape(self, batch_input_shape):
return batch_input_shape
# 모델 생성 및 훈련
model = keras.models.Sequential([
MyGaussianNoise(stddev=1.0),
keras.layers.Dense(30, activation="selu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer="nadam")
model.fit(X_train_scaled, y_train, epochs=2,
validation_data=(X_valid_scaled, y_valid))
model.evaluate(X_test_scaled, y_test)12.2.5 사용자 정의 모델
# 잔차 블록(resudual block) 층(layer) 정의
class ResidualBlock(keras.layers.Layer):
def __init__(self, n_layers, n_neurons, **kwargs):
super().__init__(**kwargs)
self.hidden = [keras.layers.Dense(n_neurons, activation='elu', kernel_initializer='he_normal')
for _ in range(n_layers)]
def call(self, inputs):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
return inputs + Z
# 모델 정의
class ResidualRegressor(keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(30, activation='elu', kernel_initializer='he_normal')
self.block1 = ResidualBlock(2, 30)
self.block2 = ResidualBlock(2, 30)
self.out = keras.layers.Dense(output_dim)
def call(self, inputs):
Z = self.hidden1(inputs)
for _ in range(1+3):
Z = self.block1(Z)
Z = self.block2(Z)
return self.out(Z)
model = ResidualRegressor(1)
model.compile(loss="mse", optimizer="nadam")
history = model.fit(X_train_scaled, y_train, epochs=5)
score = model.evaluate(X_test_scaled, y_test)
# y_pred = model.predict(X_test_scaled)
print(score)
model.save("my_custom_model.ckpt")
model = keras.models.load_model("my_custom_model.ckpt")
history = model.fit(X_train_scaled, y_train, epochs=5)12.2.6 모델 구성 요소 기반 loss와 metric
import tensorflow as tf
from tensorflow import keras
class ReconstructingRegressor(keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
# 5개의 Dense 레이어를 정의합니다. 각 레이어는 30개의 유닛을 가지고, 'selu' 활성화 함수와 'lecun_normal' 초기화 방법을 사용합니다.
self.hidden = [
keras.layers.Dense(30, activation="selu", kernel_initializer="lecun_normal")
for _ in range(5)
]
# 최종 출력 레이어입니다. 출력 차원은 모델의 출력 차원(output_dim)입니다.
self.out = keras.layers.Dense(output_dim)
# 재구성 손실을 저장하는 메트릭입니다.
self.reconstruction_mean = keras.metrics.Mean(name="reconstruction_error")
def build(self, batch_input_shape):
n_inputs = batch_input_shape[-1] # 입력 차원 수를 추출합니다.
# 입력 차원 수와 동일한 출력 차원을 가진 Dense 레이어를 정의합니다.
self.reconstruct = keras.layers.Dense(n_inputs)
# 부모 클래스의 build 메서드를 호출하여 추가적인 초기화 작업을 수행합니다.
super().build(batch_input_shape)
def call(self, inputs, training=None):
Z = inputs
# 모든 Dense 레이어를 입력에 순차적으로 적용합니다.
for layer in self.hidden:
Z = layer(Z)
# 마지막 Dense 레이어를 통해 입력의 재구성을 수행합니다.
reconstruction = self.reconstruct(Z)
# 재구성 손실을 계산합니다. 재구성 결과와 입력 간의 평균 제곱 오차를 계산합니다.
self.recon_loss = 0.05 * tf.reduce_mean(tf.square(reconstruction - inputs))
# 모델이 학습 중인 경우, 재구성 손실을 메트릭에 추가합니다.
if training:
result = self.reconstruction_mean(self.recon_loss)
self.add_metric(result)
# 최종 출력 레이어를 적용하여 예측 결과를 반환합니다.
return self.out(Z)
def train_step(self, data):
x, y = data # 훈련 데이터에서 입력 x와 타겟 y를 추출합니다.
with tf.GradientTape() as tape:
y_pred = self(x) # 모델을 사용하여 예측값을 계산합니다.
# 손실을 계산합니다. 재구성 손실을 정규화 손실로 추가합니다.
loss = self.compiled_loss(y, y_pred, regularization_losses=[self.recon_loss])
# 그래디언트를 계산합니다.
gradients = tape.gradient(loss, self.trainable_variables)
# 그래디언트를 적용하여 모델의 가중치를 업데이트합니다.
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
# 현재 배치에 대한 메트릭 결과를 딕셔너리 형태로 반환합니다.
return {m.name: m.result() for m in self.metrics}
model = ReconstructingRegressor(1)
model.compile(loss="mse", optimizer="nadam")
history = model.fit(X_train_scaled, y_train, epochs=2)
y_pred = model.predict(X_test_scaled)12.2.7 자동 미분으로 기울기 계산
def f(w1, w2):
return 3 * w1**2 + 2 * w1 * w2
w1, w2 = 5, 3
eps = 1e-6
print((f(w1+eps, w2) - f(w1, w2)) / eps)
print((f(w1, w2+eps) - f(w1, w2)) / eps)
# 자동 미분
w1, w2 = tf.Variable(5.), tf.Variable(3.)
with tf.GradientTape() as tape:
# 자동 미분
z = f(w1, w2)
gradients = tape.gradient(z, [w1, w2])
# tape.gradient(): 호출 즉시 tape 자동 제거(ex: list.pop)
print(gradients)
# 무한 호출
with tf.GradientTape(persistent=True) as tape:
# 자동 제거 해제
z = f(w1, w2)
dz_dw1 = tape.gradient(z, w1)
dz_dw2 = tape.gradient(z, w2)
print(dz_dw1, dz_dw2)
print(tape.gradient(z, w1), tape.gradient(z, w2))
del tape
# 상수로 구현
c1, c2 = tf.constant(5.), tf.constant(3.)
with tf.GradientTape() as tape:
z = f(c1, c2)
gradients = tape.gradient(z, [c1, c2])
print(gradients) # Variable이 아닌 constant는 None 반환
with tf.GradientTape() as tape:
tape.watch(c1)
# 연산 강제
tape.watch(c2)
z = f(c1, c2)
gradients = tape.gradient(z, [c1, c2])
print(gradients)
# 역전파 미이행
def f(w1, w2):
return 3 * w1**2 + tf.stop_gradient(2*w1*w2)
with tf.GradientTape() as tape:
z = f(w1, w2)
gradients = tape.gradient(z, [w1, w2])
print(gradients)
# 부동소수점 정밀도 오류로 인한 무한 나누기 무한으로 nan 반환
x = tf.Variable([100.])
with tf.GradientTape() as tape:
z = my_softplus(x)
gradients = tape.gradient(z, [x])
print(gradients)
@tf.custom_gradient
def my_better_softplus(z):
exp = tf.exp(z)
def my_softplus_gradients(grad):
return grad / (1 + 1/exp)
return tf.math.log(exp + 1), my_softplus_gradients
x = tf.Variable([10.])
with tf.GradientTape() as tape:
z = my_better_softplus(x)
z, tape.gradient(z, [x])12.2.8 사용자 정의 훈련 반복
# L2 정규화(가중치 감소) 설정
l2_reg = keras.regularizers.l2(0.05)
# Sequential 모델 정의
model = keras.models.Sequential([
keras.layers.Dense(30, activation='elu', kernel_initializer='he_normal',
kernel_regularizer=l2_reg),
keras.layers.Dense(1, kernel_regularizer=l2_reg)
])
# 데이터 배치 추출 함수 정의
def random_batch(X, y, batch_size=32):
idx = np.random.randint(len(X), size=batch_size) # 데이터에서 랜덤 인덱스 생성
return X[idx], y[idx] # 선택된 데이터와 레이블 반환
# 학습 상태를 출력하는 함수 정의
def print_status_bar(iteration, total, loss, metrics=None):
# 손실과 메트릭을 포맷하여 문자열로 변환
metrics = ' - '.join(['{}: {:.4f}'.format(m.name, m.result())
for m in [loss] + (metrics or [])])
# 출력 문자열 구성, 진행 중일 때는 줄바꿈 없이 출력
end = '' if iteration < total else '\n'
print('\r{}/{} - '.format(iteration, total) + metrics, end=end)
# 하이퍼파라미터 및 설정 정의
n_epochs = 5
batch_size = 32
n_steps = len(X_train) // batch_size # 한 에포크에서의 배치 수 계산
optimizer = keras.optimizers.Nadam(learning_rate=0.01) # 옵티마이저 설정
loss_fn = keras.losses.mean_squared_error # 손실 함수 설정
mean_loss = keras.metrics.Mean() # 평균 손실 메트릭 초기화
metrics = [keras.metrics.MeanAbsoluteError()] # 추가 메트릭 설정
# 학습 루프 시작
for epoch in range(1, n_epochs + 1):
print('epoch {}/{}'.format(epoch, n_epochs)) # 현재 에포크 출력
for step in range(1, n_steps + 1):
# 배치 데이터 추출
X_batch, y_batch = random_batch(X_train_scaled, y_train)
# GradientTape를 사용한 기울기 계산 및 업데이트
with tf.GradientTape() as tape:
y_pred = model(X_batch, training=True) # 모델을 통한 예측
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred)) # 주요 손실 계산
loss = tf.add_n([main_loss] + model.losses) # 총 손실 (정규화 손실 포함)
gradients = tape.gradient(loss, model.trainable_variables) # 기울기 계산
optimizer.apply_gradients(zip(gradients, model.trainable_variables)) # 가중치 업데이트
mean_loss(loss) # 평균 손실 업데이트
for metric in metrics:
metric(y_batch, y_pred) # 추가 메트릭 업데이트
# 학습 상태 출력
print_status_bar(step * batch_size, len(y_train), mean_loss, metrics)
# 에포크 끝난 후 상태 출력
print_status_bar(len(y_train), len(y_train), mean_loss, metrics)
# 메트릭 상태 리셋
for metric in [mean_loss] + metrics:
metric.reset_states()12.3 텐서플로 함수와 그래프
def cube(x):
return x**3
print(cube(2))
print(cube(tf.constant(2.0)))
tf_cube = tf.function(cube) # 텐서플로 함수로 변환(텐서 객체로 반환)
print(cube)
print(tf_cube)
print(tf_cube(2))
print(tf_cube(tf.constant(2.0)))
@tf.function # 텐서플로 함수로 선언하는 데코레이터
def tf_cube2(x):
return x**3
print(tf_cube2(2))
print(tf_cube2.python_function(2)) # 파이썬 함수로 사용하는 메서드
# keras는 자동으로 텐서플로 함수로 변환하지만 dynamic=True를 주거나 compile 시 run_eagerly=True 지정하면 불변환
# 텐서플로 함수의 소스코드 출력
print(tf.autograph.to_code(cube))
print(tf.autograph.to_code(tf_cube.python_function))12.3.1 오토그래프(Autograph)
오토그래프: TensorFlow의 기능으로, Python 코드(특히 Python의 제어 흐름 구조)를 TensorFlow의 그래프 코드로 변환.
import tensorflow as tf
@tf.function
def my_function(x):
if tf.reduce_sum(x) > 0:
return x * 2
else:
return x / 2
x = tf.constant([-1, 2, 3])
result = my_function(x)
print(result)위 코드에서 @tf.function 데코레이터는 my_function을 TensorFlow의 그래프 모드로 변환. if 문과 같은 Python의 제어 흐름 문장도 TensorFlow의 그래프 코드로 변환되어 실행.
12.3.2 트레이싱(Tracing)
트레이싱: TensorFlow의 tf.function이 입력에 대해 모델의 실행 그래프를 생성하는 과정.
import tensorflow as tf
@tf.function
def add(x, y):
return x + y
a = tf.constant(1)
b = tf.constant(2)
result = add(a, b)
print(result)위 코드에서 add 함수는 @tf.function 데코레이터에 의해 트레이싱됨. TensorFlow는 add 함수에 대해 정적 실행 그래프를 생성 후 같은 형태의 입력에 대해 이 그래프를 재사용.
- 오토그래프와 트레이싱의 차이점
- 트레이싱은
tf.function이 호출될 때 TensorFlow 그래프를 생성하는 과정을 설명. 함수가 입력값에 따라 그래프 생성 및 최적화. - 오토그래프는 Python의 제어 흐름(조건문, 반복문 등)을 TensorFlow 그래프 코드로 변환하여, TensorFlow 그래프 모드에서 실행되도록 도움.
- 트레이싱은
12.3.3 텐서플로 함수 사용(변환) 시 유의점
- 타 라이브러리 호출 시 그래프에 포함되지 않음. 함수는 텐서플로의 함수 사용
- 텐서플로 함수 안에서 호출하는 파이썬 함수도 자동으로 그래프 모드 적용.
- 함수에서 텐서플로 변수를 선언 시 최초 1회만 호출. 새 값 할당 시 tf.Variable.assign() 사용.
- 파이썬 함수의 소스 코드를 텐서플로에서 사용 가능해야 함.
- 텐서플로 함수는 텐서나 데이터셋을 순회하는 for문만 감지.
- 반복문보다 벡터화된 구현을 사용하는 것이 성능 면에서 좋음.
13_데이터 적재 및 전처리
13.1 데이터 API
13.1.1 텐서플로 dataset
import tensorflow as tf
X = tf.range(10)
dataset = tf.data.Dataset.from_tensor_slices(X) # 각 원소를 아이템으로 변환
print(dataset)
for item in dataset:
print(item)
print('='*10)
dataset2 = dataset.repeat(3).batch(7) # 3번 반복, 배치 크기 7
for item in dataset2:
print(item)
print('='*10)
dataset2 = dataset.map(lambda x: x*2) # 데이터에 함수 적용
dataset2 = dataset2.repeat(3).batch(7, drop_remainder=True) # 배치 크기보다 작은 데이터 버림
for item in dataset2:
print(item)
print('='*10)
dataset2 = dataset2.apply(tf.data.experimental.unbatch()) # 배치 해제(배치 크기 1)
for item in dataset2:
print(item)
print('='*10)
dataset2 = dataset2.filter(lambda x: x < 10) # 필터
for item in dataset2:
print(item)
print('='*10)
for item in dataset2.take(3): # 인자 값의 길이만큼만 반환.(One-based indexing)
print(item)13.1.2 셔플링
- 버퍼
dataset = tf.data.Dataset.range(10).repeat(3)
dataset = dataset.shuffle(buffer_size=5, seed=42).batch(7)
# buffer_size만큼 순서대로 추출 후 임의값 1개 추출, 다음 값으로 buffer 채움. 반복.
for item in dataset:
print(item)- dataset 경로
# 데이터 불러오기
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
import csv, os
from glob import glob
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(
housing.data, housing.target.reshape(-1, 1), random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_full, y_train_full, random_state=42)
# 데이터 분할 및 경로 반환
import csv, os
from glob import glob
os.makedirs('dataset_hosing', exist_ok=True)
header_cols = housing.feature_names + ["MedianHouseValue"]
def make_data_files(data_using_type: str, X: np.array, y: np.array, split_nums: int=10) -> list:
for idx, data in enumerate(np.array_split(np.column_stack((X, y)), split_nums)):
with open(f'dataset_hosing/{data_using_type}_{idx:0>2}.csv', 'w') as f:
writer = csv.writer(f)
writer.writerows(np.row_stack((header_cols, data)))
return glob(f'dataset_hosing/{data_using_type}*.csv')
train_filepaths = make_data_files("train", X_train, y_train, 20)
valid_filepaths = make_data_files("valid", X_valid, y_valid)
test_filepaths = make_data_files("test", X_test, y_test)
# 데이터 불러오기
filepath_dataset = tf.data.Dataset.list_files(train_filepaths, seed=42)
# tf.data.Dataset.list_files: 파일들의 경로 리스트로 dataset 생성
n_readers = 5
dataset = filepath_dataset.interleave( # tf.data.Dataset.interleave: dataset에 함수를 적용하여 병렬로 데이터 읽음.
lambda filepath: tf.data.TextLineDataset(filepath).skip(1), # 첫 행 스킵(컬럼명)
cycle_length=n_readers # 병렬로 읽을 dataset 수
)
# tf.data.TextLineDataset: 텍스트 파일 데이터를 한 줄씩 읽음.
for line in dataset.take(5):
print(line.numpy())13.1.3 전처리
- csv 텐서 변환
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_mean = scaler.mean_
X_std = scaler.scale_
n_inputs = 8
@tf.function
def preprocess(line):
defs = [0.] * n_inputs + [tf.constant([], dtype=tf.float32)]
# defs=기본값 지정: 각 input에 0. 기본값 + y는 tf.float32 타입의 빈 배열(실수지만 기본값 없음: 값 누락 시 오류 발생)
fields = tf.io.decode_csv(line, record_defaults=defs)
# csv 형식의 문자열을 단일 값인 0차원 스칼라 텐서로 변환
x = tf.stack(fields[:-1])
y = tf.stack(fields[-1:])
return (x - X_mean) / X_std, y
print(preprocess(line.numpy()))13.1.4 프리페치(prefetch)
훈련 알고리즘이 한 미니 배치로 작업하는 동안 다음 미니 배치를 준비.
def csv_reader_dataset(filepaths, repeat=1, n_readers=5,
n_read_threads=None, shuffle_buffer_size=10000,
n_parse_threads=5, batch_size=32):
dataset = tf.data.Dataset.list_files(filepaths).repeat(repeat)
dataset = dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1),
cycle_length=n_readers, num_parallel_calls=n_read_threads)
dataset = dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(preprocess, num_parallel_calls=n_parse_threads)
return dataset.batch(batch_size).prefetch(1)
# 항상 1개 배치 미리 준비13.1.5 데이터셋 사용과 알아두면 좋은 함수
from tensorflow import keras
train_set = csv_reader_dataset(train_filepaths, repeat=None)
valid_set = csv_reader_dataset(valid_filepaths)
test_set = csv_reader_dataset(test_filepaths)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1),
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=1e-3))
batch_size = 128
model.fit(train_set, steps_per_epoch=len(X_train) // batch_size, epochs=10,
validation_data=valid_set)
model.evaluate(test_set, steps=len(X_test) // batch_size)- 알아두면 좋은 함수
- concatenate(), zip(), window(), reduce(), shard(), flat_map(), padded_batch(), from_generator, from_tensors()
# `Dataset` 클래스에 있는 메서드의 간략한 설명입니다:
for m in dir(tf.data.Dataset):
if not (m.startswith("_") or m.endswith("_")):
func = getattr(tf.data.Dataset, m)
if hasattr(func, "__doc__"):
print("● {:21s}{}".format(m + "()", func.__doc__.split("\n")[0]))
# 출력
● apply() Applies a transformation function to this dataset.
● as_numpy_iterator() Returns an iterator which converts all elements of the dataset to numpy.
● batch() Combines consecutive elements of this dataset into batches.
● bucket_by_sequence_length()A transformation that buckets elements in a `Dataset` by length.
● cache() Caches the elements in this dataset.
● cardinality() Returns the cardinality of the dataset, if known.
● choose_from_datasets()Creates a dataset that deterministically chooses elements from `datasets`.
● concatenate() Creates a `Dataset` by concatenating the given dataset with this dataset.
● element_spec() The type specification of an element of this dataset.
● enumerate() Enumerates the elements of this dataset.
● filter() Filters this dataset according to `predicate`.
● flat_map() Maps `map_func` across this dataset and flattens the result.
● from_generator() Creates a `Dataset` whose elements are generated by `generator`. (deprecated arguments)
● from_tensor_slices() Creates a `Dataset` whose elements are slices of the given tensors.
● from_tensors() Creates a `Dataset` with a single element, comprising the given tensors.
● get_single_element() Returns the single element of the `dataset`.
● group_by_window() Groups windows of elements by key and reduces them.
● interleave() Maps `map_func` across this dataset, and interleaves the results.
● list_files() A dataset of all files matching one or more glob patterns.
● load() Loads a previously saved dataset.
● map() Maps `map_func` across the elements of this dataset.
● options() Returns the options for this dataset and its inputs.
● padded_batch() Combines consecutive elements of this dataset into padded batches.
● prefetch() Creates a `Dataset` that prefetches elements from this dataset.
● random() Creates a `Dataset` of pseudorandom values.
● range() Creates a `Dataset` of a step-separated range of values.
● reduce() Reduces the input dataset to a single element.
● rejection_resample() A transformation that resamples a dataset to a target distribution.
● repeat() Repeats this dataset so each original value is seen `count` times.
● sample_from_datasets()Samples elements at random from the datasets in `datasets`.
● save() Saves the content of the given dataset.
● scan() A transformation that scans a function across an input dataset.
● shard() Creates a `Dataset` that includes only 1/`num_shards` of this dataset.
● shuffle() Randomly shuffles the elements of this dataset.
● skip() Creates a `Dataset` that skips `count` elements from this dataset.
● snapshot() API to persist the output of the input dataset.
● take() Creates a `Dataset` with at most `count` elements from this dataset.
● take_while() A transformation that stops dataset iteration based on a `predicate`.
● unbatch() Splits elements of a dataset into multiple elements.
● unique() A transformation that discards duplicate elements of a `Dataset`.
● window() Returns a dataset of "windows".
● with_options() Returns a new `tf.data.Dataset` with the given options set.
● zip() Creates a `Dataset` by zipping together the given datasets.13.2 TFRecord
13.2.1 TFRecord 포맷
크기가 다른 연속된 이진 레코드를 저장하는 단순한 이진 포맷
with tf.io.TFRecordWriter('my_data.tfrecord') as f:
f.write(b'This is the first record')
f.write(b'and this is the second record')
# 현재는 바이트 문자열이 아닌 그냥 문자열로 입력해도 알아서 변환됨.
filepaths = ['my_data.tfrecord']
dataset = tf.data.TFRecordDataset(filepaths)
for item in dataset:
print(item)- 압축
options = tf.io.TFRecordOptions(compression_type="GZIP")
with tf.io.TFRecordWriter("my_compressed.tfrecord", options) as f:
f.write(b"This is the first record")
f.write(b"And this is the second record")
dataset = tf.data.TFRecordDataset(["my_compressed.tfrecord"],
compression_type="GZIP")
for item in dataset:
print(item)13.2.2 프로토콜 버퍼
프로토콜 버퍼(protocol buffer/protobuf): 2001년 구글이 개발한 이식성과 확장성이 좋고 효율적인 이진 포맷
syntax = "proto3"; // proto3 버전 사용
message Person { // Person이란 message 정의
string name = 1;// 자료형 필드명 = 필드식별자
int32 id = 2;
repeated string email = 3
};from person_pb2 import Person # 생성된 클래스 임포트
person = Person(name="Al", id=123, email=["a@b.com"]) # Person 객체 생성
print(person)
person.name = "Alice"
person.email.append("c@d.com")
print(person.name, person.email[1])
s = person.SerializeToString() # 바이트 문자열로 객체 직렬화
print(s)
person2 = Person()
print(person2.ParseFromString(s))
print(person == person2)13.2.3 텐서플로 프로토콜 버퍼
- 프로토콜 버퍼 정의
syntax = "proto3";
message BytesList { repeated bytes value = 1; }
message FloatList { repeated float value = 1 [packed = true]; } // [packed = true]: 값을 압축된 형식으로 저장.
message Int64List { repeated int64 value = 1 [packed = true]; }
message Feature {
oneof kind { // "oneof":하나의 메시지에서 여러 필드 중 하나만 사용할 수 있음.
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
message Features { map<string, Feature> feature = 1; }; // Features는 특성 이름과 값을 매핑한 딕셔너리를 가짐.
message Example { Features features = 1; }; // 하나의 Features 객체를 가짐.- tf.train,Example 객체 생성 및 파일 저장
from tensorflow.train import BytesList, FloatList, Int64List
from tensorflow.train import Feature, Features, Example
person_example = Example(
features = Features(
feature = {
"name": Feature(bytes_list = BytesList(value=[b"Alice"])),
"id": Feature(int64_list = Int64List(value=[123])),
"emails": Feature(bytes_list = BytesList(value=[b"a@b.com",
b"c@d.com"]))
}
)
)
with tf.io.TFRecordWriter("my_contacts.tfrecord") as f:
f.write(person_example.SerializeToString())- 프로토콜 버퍼 읽기 및 파싱
feature_description = {
"name": tf.io.FixedLenFeature([], tf.string, default_value=""),
"id": tf.io.FixedLenFeature([], tf.int64, default_value=0),
"emails": tf.io.VarLenFeature(tf.string)
}
for serialized_example in tf.data.TFRecordDataset(["my_contacts.tfrecord"]):
parsed_example = tf.io.parse_single_example(serialized_example, feature_description)
# tf.io.parse_single_example: 하나씩 파싱, 딕셔너리로 반환
print(tf.sparse.to_dense(parsed_example["emails"], default_value=b""))
# tf.sparse.to_dense: 희소 텐서를 밀집 텐서로 변환
print(parsed_example["emails"].values)
display(parsed_example)
for serialized_example in tf.data.TFRecordDataset(["my_contacts.tfrecord"]).repeat(13).batch(10):
parsed_example = tf.io.parse_example(serialized_example, feature_description)
# tf.io.parse_example: 배치 단위 파싱, 딕셔너리로 반환
print(parsed_example["name"].numpy()) # SparseTensor가 아니라 .numpy() 사용
display(parsed_example) # 반복문에서 할당이기에 마지막 배치를 할당하여 호출- 이미지
from sklearn.datasets import load_sample_images
import matplotlib.pyplot as plt
img = load_sample_images()["images"][0]
plt.imshow(img)
plt.axis("off")
plt.title("Original Image")
plt.show()
data = tf.io.encode_jpeg(img)
example_with_image = Example(features=Features(feature={
"image": Feature(bytes_list=BytesList(value=[data.numpy()]))}))
serialized_example = example_with_image.SerializeToString()
# then save to TFRecord
feature_description = { "image": tf.io.VarLenFeature(tf.string) }
example_with_image = tf.io.parse_single_example(serialized_example, feature_description)
decoded_img = tf.io.decode_jpeg(example_with_image["image"].values[0])
# tf.io.decode_image(): BMP, GIF, JPEG, PNG 포맷을 지원.
decoded_img = tf.io.decode_image(example_with_image["image"].values[0])
plt.imshow(decoded_img)
plt.title("Decoded Image")
plt.axis("off")
plt.show()- SequenceExample: 문맥 데이터를 위한 하나의 Features 객체와 이름 있는 한 개 이상의 FeatureList를 가진 FeatureLists 객체를 포함.
message FeatureList { repeated Feature feature = 1; };
message FeatureList { map<string, FeatureList> feature_list = 1; };
message SequenceExample {
Features context = 1;
FeatureLists feature_lists = 2;
};from tensorflow.train import FeatureList, FeatureLists, SequenceExample
# 예제용 시퀀스 샘플 생성
context = Features(feature={
"author_id": Feature(int64_list=Int64List(value=[123])),
"title": Feature(bytes_list=BytesList(value=[b"A", b"desert", b"place", b"."])),
"pub_date": Feature(int64_list=Int64List(value=[1623, 12, 25]))
})
content = [["When", "shall", "we", "three", "meet", "again", "?"],
["In", "thunder", ",", "lightning", ",", "or", "in", "rain", "?"]]
comments = [["When", "the", "hurlyburly", "'s", "done", "."],
["When", "the", "battle", "'s", "lost", "and", "won", "."]]
def words_to_feature(words):
return Feature(bytes_list=BytesList(value=[word.encode("utf-8")
for word in words]))
# 문자열을 Feature로 환
content_features = [words_to_feature(sentence) for sentence in content]
comments_features = [words_to_feature(comment) for comment in comments]
# 리스트 포함하여 저장
sequence_example = SequenceExample(
context=context,
feature_lists=FeatureLists(feature_list={
"content": FeatureList(feature=content_features),
"comments": FeatureList(feature=comments_features)
}))
print(type(sequence_example))
# 프로토콜 버퍼 파싱
serialized_sequence_example = sequence_example.SerializeToString()
context_feature_descriptions = {
"author_id": tf.io.FixedLenFeature([], tf.int64, default_value=0),
"title": tf.io.VarLenFeature(tf.string),
"pub_date": tf.io.FixedLenFeature([3], tf.int64, default_value=[0, 0, 0]),
}
sequence_feature_descriptions = {
"content": tf.io.VarLenFeature(tf.string),
"comments": tf.io.VarLenFeature(tf.string),
}
parsed_context, parsed_feature_lists = tf.io.parse_single_sequence_example(
serialized_sequence_example, context_feature_descriptions, sequence_feature_descriptions)
parsed_content = tf.RaggedTensor.from_sparse(parsed_feature_lists["content"])
print(parsed_content)
print(parsed_feature_lists["content"].values)13.3 입력 특성 전처리
13.3.1 원-핫
vocab = ["<1H OCEAN", "INLAND", "NEAR_OCCEAN", 'NEAR BAY', 'ICELAND']
indices = tf.range(len(vocab), dtype=tf.int64)
table_init = tf.lookup.KeyValueTensorInitializer(vocab, indices)
# 초기화 객체 생성
num_oov_buckets = 2 # oov(out-of-vocabulary) 갯수 지정
# 어휘 사전에 없는 값이 들어올 경우 oov에 할당
table = tf.lookup.StaticVocabularyTable(table_init, num_oov_buckets)
categories = tf.constant(["NEAR BAY", "DESERT", "INLAND", "INLAND"])
cat_indeices = table.lookup(categories)
print(cat_indeices)
cat_one_hot = tf.one_hot(cat_indeices, depth=len(vocab) + num_oov_buckets)
print(cat_one_hot)13.3.2 임베딩
embedding_dim = 2
embed_init = tf.random.uniform([len(vocab) + num_oov_buckets, embedding_dim])
embedding_matrix = tf.Variable(embed_init)
print(embedding_matrix)
categories = tf.constant(["NEAR BAY", "DESERT", "INLAND", "INLAND"])
cat_indeices = table.lookup(categories)
print(cat_indeices)
cat_embed = tf.nn.embedding_lookup(embedding_matrix, cat_indeices)
print(cat_embed)13.3.3 케라스 전처리 층
# 전처리층을 포함한 모델
norm_layer = tf.keras.layers.Normalization()
model = tf.keras.models.Sequential([
norm_layer,
tf.keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(learning_rate=2e-3))
norm_layer.adapt(X_train) # 모든 특성의 평균과 분산을 계산합니다.
# 모델에서 정규화
model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=5)
# 전처리를 별도로 하는 모델
norm_layer = tf.keras.layers.Normalization()
norm_layer.adapt(X_train)
# input 전처리
X_train_scaled = norm_layer(X_train)
X_valid_scaled = norm_layer(X_valid)
# 전처리층 없이 모델 구성
model = tf.keras.models.Sequential([tf.keras.layers.Dense(1)])
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(learning_rate=2e-3))
model.fit(X_train_scaled, y_train, epochs=5,
validation_data=(X_valid_scaled, y_valid));13.3.4 다양한 전처리 방법
- Discretization
age = tf.constant([[10.], [93.], [57.], [18.], [37.], [5.]])
discretize_layer = tf.keras.layers.Discretization(bin_boundaries=[18., 50.])
age_categories = discretize_layer(age)
print(age_categories)
discretize_layer = tf.keras.layers.Discretization(num_bins=3)
discretize_layer.adapt(age)
age_categories = discretize_layer(age)
print(age_categories)- Hashing
hashing_layer = tf.keras.layers.Hashing(num_bins=2)
print(hashing_layer([["Paris"], ["Tokyo"], ["Auckland"], ["Montreal"]]))- CategoryEncoding
onehot_layer = tf.keras.layers.CategoryEncoding(num_tokens=3) # output_mode="multi_hot"(default)
print(onehot_layer(age_categories))
two_age_categories = np.array([[1, 0], [2, 2], [2, 0], [1,0]])
print(onehot_layer(two_age_categories))
onehot_layer = tf.keras.layers.CategoryEncoding(num_tokens=3, output_mode="count")
print(onehot_layer(two_age_categories))
onehot_layer = tf.keras.layers.CategoryEncoding(num_tokens=3, output_mode="one_hot")
print([onehot_layer(cat) for cat in tf.transpose(two_age_categories)])- StringLookup
cities = ["Auckland", "Paris", "Paris", "San Francisco"]
str_lookup_layer = tf.keras.layers.StringLookup()
str_lookup_layer.adapt(cities)
print(str_lookup_layer([["Paris"], ["Auckland"], ["Auckland"], ["Montreal"]]))
str_lookup_layer = tf.keras.layers.StringLookup(num_oov_indices=5)
str_lookup_layer.adapt(cities)
print(str_lookup_layer([["Paris"], ["Auckland"], ["Foo"], ["Bar"], ["Baz"]]))
str_lookup_layer = tf.keras.layers.StringLookup(output_mode="one_hot")
str_lookup_layer.adapt(cities)
print(str_lookup_layer([["Paris"], ["Auckland"], ["Auckland"], ["Montreal"]]))- IntegerLookup
ids = [123, 456, 789]
int_lookup_layer = tf.keras.layers.IntegerLookup()
int_lookup_layer.adapt(ids)
print(int_lookup_layer([[123], [456], [123], [111]]))13.4 TFT(TensorFlow Transform)
TFX(TensorFLow Extended)의 빌부분으로 배포 모델의 전처리 효울화와 통일성을 위한 기능
※ 라이브러리 설치 순서 및 버전 확인 중요
tensorflow_transform github 참조
pip install tfx-bsl
pip install -U tensorflow-transform13.5 몰랐던 함수
ExitStack: 여러 컨텍스트 관리자(예: with 문에서 사용하는 객체)를 동적으로 관리하거나, 필요에 따라 컨텍스트 관리자를 나중에 추가하고 제거할 수 있게 해주는 클래스
- 동적으로 컨텍스트 관리자 추가: 컨텍스트 블록이 실행되는 동안 필요에 따라 컨텍스트 관리자 추가 가능.
- 정렬된 종료: 추가된 컨텍스트 관리자들을 올바른 순서로 종료.
- 조건부 종료: 특정 조건에 따라 컨텍스트 관리자를 조건적으로 종료 가능.
사용 예제
기본 사용법
from contextlib import ExitStack
# 파일을 열고 닫는 예제
with ExitStack() as stack:
# 파일 열기
file1 = stack.enter_context(open('file1.txt', 'w'))
file2 = stack.enter_context(open('file2.txt', 'w'))
# 파일에 데이터 쓰기
file1.write('Hello, world!\n')
file2.write('Goodbye, world!\n')이 코드에서 ExitStack은 file1과 file2를 열고, with 블록이 종료되면 두 파일을 올바르게 닫음.
동적 컨텍스트 관리자 추가
컨텍스트 관리자를 동적으로 추가하는 예제.
from contextlib import ExitStack
# 조건에 따라 파일을 열거나 닫는 예제
files = ['file1.txt', 'file2.txt']
with ExitStack() as stack:
file_handles = [stack.enter_context(open(file, 'w')) for file in files]
for file_handle in file_handles:
file_handle.write('This is a test.\n')이 코드에서는 files 리스트에 있는 모든 파일을 열고, with 블록이 종료되면 자동으로 모든 파일을 닫음.
주요 메서드
enter_context(enterable):enterable(컨텍스트 관리자 또는 객체)이ExitStack에 추가되며, 컨텍스트 블록이 종료될 때 자동 종료.pop_all():ExitStack에 추가된 모든 컨텍스트 관리자를 종료.
14_CNN
14.1 합성곱층
합성곱: 한 함수가 다른 함수 위를 이동하면서 원소별 곱셈의 적분을 계산하는 수학 연산
스트라이드(stride): 한 수용장과 다음 수용장 사이의 간격
필터(filter)/합성곱 커널(convolution kernel): 두 개로 이루어진 가중치 세트
import numpy as np
import tensorflow as tf
from tensorflow import keras
from sklearn.datasets import load_sample_image
import matplotlib.pyplot as plt
china = load_sample_image('china.jpg') / 255
flower = load_sample_image('flower.jpg') / 255
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # 수직선
filters[3, :, :, 1] = 1 # 수평선
outputs = tf.nn.conv2d(images, filters, strides=1, padding='SAME')
for image_index in (0, 1):
plt.figure(figsize=(10, 10))
for channel in range(channels):
plt.subplot(3, 2, channel+1, title=f'channel: {channel}')
plt.imshow(images[image_index, :, :, channel], cmap='gray')
plt.axis("off")
plt.subplot(3, 2, 4, title='channel: mean')
plt.imshow(images[image_index].mean(axis=2).reshape(-1, 640, 1), cmap='gray')
plt.axis("off")
plt.subplot(3, 2, 5, title='output: 0')
plt.imshow(outputs[image_index, :, :, 0], cmap='gray')
plt.axis("off")
plt.subplot(3, 2, 6, title='output: 1')
plt.imshow(outputs[image_index, :, :, 1], cmap='gray')
plt.axis("off")
plt.show(block=False)
plt.pause(2)
plt.close()
conv = keras.layers.Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')14.2 풀링 층
파라미터 수를 줄여 계산량과 메모리 사용량을 줄이는 축소본을 만드는 층. 풀링 층은 파라미터가 없어 가중치를 계산하지 않음.
14.3 다양한 CNN 모델(변천사)
14.3.1 기본
# 데이터 불러오기
(X_train_full, y_train_full), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()
X_train, X_valid = X_train_full[:-5000], X_train_full[-5000:]
y_train, y_valid = y_train_full[:-5000], y_train_full[-5000:]
X_mean = X_train.mean(axis=0, keepdims=True)
X_std = X_train.std(axis=0, keepdims=True) + 1e-7
X_train = (X_train - X_mean) / X_std
X_valid = (X_valid - X_mean) / X_std
X_test = (X_test - X_mean) / X_std
X_train = X_train[..., np.newaxis]
X_valid = X_valid[..., np.newaxis]
X_test = X_test[..., np.newaxis]
# 기본 모델
model = keras.models.Sequential([
keras.layers.Conv2D(64, 7, activation='relu', padding='same', input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 3, activation='relu', padding='same'),
keras.layers.Conv2D(256, 3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation='softmax')
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"])
history = model.fit(X_train, y_train, batch_size=1024, epochs=10, validation_data=(X_valid, y_valid))
score = model.evaluate14.3.2 LeNet-5
- 1998년에 개발된 가장 널리 알려진 CNN 모델(기초)
lenet = keras.Sequential([
keras.layers.Conv2D(filters=6, kernel_size=5, strides=1, padding='same', activation='tanh', input_shape=(28,28,1)),
keras.layers.AvgPool2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, 5, 1, 'same', activation='tanh'),
keras.layers.AvgPool2D(2, 2),
keras.layers.Conv2D(120, 5, 1, 'same', activation='tanh'),
keras.layers.Flatten(),
keras.layers.Dense(84, activation='tanh'),
keras.layers.Dense(10, activation='softmax')
])
lenet.summary()
del lenet14.3.3 AlexNet
- 처음으로 풀링 없이 합성곱 층끼리 쌓은 층이 존재. lrn 사용.
- lrn(local response normalization): 가장 강하게 활성화된 뉴런이 다른 특성맵 동일 위치의 뉴런 억제(경쟁적 정규화)
alexnet = keras.Sequential([
keras.layers.experimental.preprocessing.Resizing(227, 227, input_shape=(28, 28, 3)),
keras.layers.Conv2D(filters=96, kernel_size=11, strides=4, padding='valid', activation='relu'),
keras.layers.MaxPool2D(pool_size=3, strides=2),
keras.layers.Conv2D(256, 5, 1, 'same', activation='relu'),
keras.layers.MaxPool2D(pool_size=3, strides=2),
keras.layers.Conv2D(384, 3, 1, 'same', activation='relu'),
keras.layers.Conv2D(384, 3, 1, 'same', activation='relu'),
keras.layers.Conv2D(256, 3, 1, 'same', activation='relu'),
keras.layers.MaxPool2D(pool_size=3, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(4096, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(4096, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation='softmax')
])
alexnet.summary()
del alexnet14.3.4 GoogLeNet
- 깊고 서브 네트워크(인셉션 모듈)를 사용하여 AlexNet보다 10배 적은 파라미터 사용
- 인셉션 모듈(inception module): 처음 입력 신호가 복사 되어 4개의 다른 층에 주입. 하위 층은 합성곱과 맥스풀링. 상위 층은 커널 크기만 다른 합성곱층. 스트라이드는 전부 1, 패딩은 'same'
- 참조: Going Deeper with Convolutions(InceptionV1) - 논문 구현: Hwangbo Gyeom님 velog
14.3.5 VGGNet
- 2 or 3개의 합성곱 층 뒤에 풀링층이 나오는 구조
14.3.6 ResNet(Residual Network)
- 스킵 연결을 이용한 잔차 학습이 핵심. 층 수에 따라 뒤에 숫자가 붙음(ex: ResNet-34, ResNet-152 등)
# res 유닛(혹은 층) 구현
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation='relu', **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Conv2D(filters, 3, strides=strides, padding='same', use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters, 3, strides=1, padding='same', use_bias=False),
keras.layers.BatchNormalization()
]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
keras.layers.Conv2D(filters, 1, strides=strides, padding='same', use_bias=False),
keras.layers.BatchNormalization()
]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self. activation(Z + skip_Z)
# 모델 구현
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(64, 7, strides=2, input_shape=[224, 224, 3], padding='same', use_bias=False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation('relu'))
model.add(keras.layers.MaxPooling2D(pool_size=3, strides=2, padding='same'))
prev_filters = 64
for filters in [64]*3 + [128]*4 + [256]*6 + [512]*3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary();14.3.7 Xception(eXtreme inception)
- GoogLeNet의 변종으로 GoogLeNet과 ResNet의 아이디어를 합침. 인셉션 모듈을 깊이별 분리 합성곱 층(detpwise separable convolution layer)으로 대체(입력 채널마다 하나의 공간 필터만 가짐).
14.3.8 SENet(Squeeze-and-Excitation Network)
- SE 브록이라는 작은 신경망을 추가하여 성능 향상(SE-Inception, SE-ResNet).
- SE 블록(Squeeze-and-Excitation Block): 채널 간의 상호 관계를 학습하여 각 채널의 중요도를 조정하는 방법.
- Squeeze 단계: 채널의 공간적 정보를 압축하여 요약.
- Excitation 단계: 요약된 정보를 사용하여 각 채널의 중요도를 학습.
- Scaling 단계: 학습된 중요도 값을 이용하여 채널별로 특성 맵의 값을 조정.
- 코드 및 개념 참조: (SENet) Squeeze-and-Excitation Networks 번역 및 추가 설명과 Keras 구현: Aroddary's Personal Lab 깃허브 블로그
- SE 블록(Squeeze-and-Excitation Block): 채널 간의 상호 관계를 학습하여 각 채널의 중요도를 조정하는 방법.
14.4 사전훈련 모델 사용 및 전이학습
# 사전 훈련 모델 사용
model = keras.applications.resnet50.ResNet50(weights='imagenet')
images_resized = tf.image.resize(images, [224, 224])
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
Y_proba = model.predict(inputs)
top_K = keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print('이미지 #{}'.format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(' {} - {:12s} {:.2f}%'.format(class_id, name, y_proba*100))
print()
### 전이 학습
# 데이터 불러기
import tensorflow_datasets as tfds
dataset, info = tfds.load('tf_flowers', as_supervised=True, with_info=True)
dataset_size = info.splits['train'].num_examples
class_names = info.features['label'].names
n_classes = info.features['label'].num_classes
test_set, valid_set, train_set = tfds.load("tf_flowers",
split=["train[:10%]", "train[10%:25%]", "train[25%:]"],
as_supervised=True)
# 전처리
def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
batch_size = 32
train_set = train_set.shuffle(1000)
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)
# 모델 로드 및 프리즈
base_model = keras.applications.xception.Xception(weights='imagenet', include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation='softmax')(avg)
model = keras.Model(inputs=base_model.input, outputs=output)
print(len(base_model.trainable_variables), len(model.trainable_variables))
for layer in base_model.layers:
layer.trainable = False
print(len(base_model.trainable_variables), len(model.trainable_variables))
base_model.trainable = True
print(len(base_model.trainable_variables), len(model.trainable_variables))
base_model.trainable = False
print(len(base_model.trainable_variables), len(model.trainable_variables))
# 새로운 층 훈련
optimizer = keras.optimizers.SGD(learning_rate=0.2, momentum=0.9)
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history = model.fit(train_set, epochs=5, validation_data=valid_set)
# 미세 조정(모든 층 훈련)
print(len(base_model.trainable_variables), len(model.trainable_variables))
base_model.trainable = True
print(len(base_model.trainable_variables), len(model.trainable_variables))
optimizer = keras.optimizers.SGD(learning_rate=0.01, momentum=0.9)
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history = model.fit(train_set, epochs=3, validation_data=valid_set)14.5 분류와 위치 추정, 객체 탐지
- 바운딩 박스(bounding box) 예측
base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = keras.layers.Dense(n_classes, activation="softmax")(avg)
loc_output = keras.layers.Dense(4)(avg)
model = keras.models.Model(inputs=base_model.input,
outputs=[class_output, loc_output])
model.compile(loss=["sparse_categorical_crossentropy", "mse"],
loss_weights=[0.8, 0.2], # 어떤 것을 중요하게 생각하느냐에 따라
optimizer=optimizer, metrics=["accuracy"])
# IoU(Intersection over Union): 바운딩 박스에 널리 사용되는 지표. tf.keras.metrics.MeanIoU 사용- 객체 탐지(object detection): 하나의 이미지에서 여러 물체를 분류하고 위치를 추정하는 작업. 지표로 mAP(mean Average Precision) 주로 사용.
- 완전 합성곱 신경망(FCN: Fully Convolution Network): Dense층 없이 모두 Conv층으로 이뤄짐.
- YOLO(You Only Look Once): 매우 유명한 객체 탐지 모델(구조, 알고리즘)
14.6 시맨틱 분할
-
시맨틱 분할(Semantic Segmentation): 이미지에서 각 픽셀을 특정 클래스(또는 레이블)에 할당하는 작업. 이 기술은 이미지의 각 픽셀을 특정 의미 있는 범주로 분류하는 데 중점을 두며, 일반적으로 이미지의 모든 객체와 배경을 구분.
-
시맨틱 분할의 주요 개념
- 픽셀 단위의 분류: 시맨틱 분할은 이미지의 각 픽셀을 특정 클래스 레이블로 분류.
- 클래스 레이블: 각 픽셀은 사전 정의된 클래스(예: 도로, 건물, 사람, 배경 등)에 할당.
- 구조적 정보: 시맨틱 분할은 이미지의 구조적 정보와 공간적 관계를 보존하는 것이 중요.
- 전치 합성곱 층(transposed convolutional layer): input에 stride 값에 따라 0를 배치하고 맵(가중치)을 곱하여 upsampling.
15_RNN과 CNN을 사용한 sequence 처리
15.1 RNN(Recurrent Neural Network)
- 메모리 셀(memory cell): 타임 스텝에 걸쳐 상태를 보존하는 신경망의 구성 요소.
15.1.1 입력과 출력 시퀀스
- 시퀀스 데이터(sequence data): 순차적인 데이터. 순서대로 정렬된 데이터의 연속.
- 시퀀스 투 시퀀스(seq2seq), 시퀀스 투 벡터(seq2vec), 벡터 투 시퀀스(vec2seq)
- 인코더(seq2vec) 모델과 디코더(vec2seq) 모델을 연결하여 기계 번역 등에 사용
15.1.2 시계열
- 차분(Differencing): 시계열 데이터를 안정화시키기 위한 기법. 일반적으로 시계열 데이터는 추세나 계절성 같은 구조적 요소를 포함하고 있어, 이를 제거하고 보다 안정적인 시계열을 만들기 위해 사용.
- 대변(Transformation): 데이터를 변형하여 분석을 용이하게 만드는 방법. 일반적으로 데이터의 분포를 변형하거나 데이터를 정규화하는 데 사용.
- 데이터 생성
import numpy as np
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
def generate_time_series(batch_size, n_steps):
freq1, freq2, offset1, offset2 = np.random.rand(4, batch_size, 1)
time = np.linspace(0, 1, n_steps)
series = 0.5 * np.sin((time - offset1) * (freq1 * 10 + 10)) # 사인 곡선 1
series += 0.2 * np.sin((time - offset2) * (freq2 * 20 + 20)) # 사인 곡선 2
series += 0.1 * (np.random.rand(batch_size, n_steps) - 0.5) # 잡음
return series[..., np.newaxis].astype(np.float32)
n_steps = 50
sereis = generate_time_series(10000, n_steps+1)
X_train, y_train = sereis[:7000, :n_steps], sereis[:7000, -1]
X_valid, y_valid = sereis[7000:9000, :n_steps], sereis[7000:9000, -1]
X_test, y_test = sereis[9000:, :n_steps], sereis[9000:, -1]
def plot_series(series, y=None, y_pred=None, x_label="$t$", y_label="$x(t)$", legend=True):
plt.plot(series, ".-")
if y is not None:
plt.plot(n_steps, y, "bo", label="Target")
if y_pred is not None:
plt.plot(n_steps, y_pred, "rx", markersize=10, label="Prediction")
plt.grid(True)
if x_label:
plt.xlabel(x_label, fontsize=16)
if y_label:
plt.ylabel(y_label, fontsize=16, rotation=0)
plt.hlines(0, 0, 100, linewidth=1)
plt.axis([0, n_steps + 1, -1, 1])
if legend and (y or y_pred):
plt.legend(fontsize=14, loc="upper left")
fig, axes = plt.subplots(nrows=1, ncols=3, sharey=True, figsize=(12, 4))
for col in range(3):
plt.sca(axes[col])
plot_series(X_valid[col, :, 0], y_valid[col, 0],
y_label=("$x(t)$" if col==0 else None),
legend=(col == 0))
plt.show(block=False)
plt.pause(2)
plt.close()
# 순진한 예측(naive forecasting): 마지막 값을 예측값으로 그대로 사용. 지금은 기준 성능으로써 사용.
y_pred = X_valid[:, -1]
print(np.mean(keras.losses.mean_squared_error(y_valid, y_pred)))
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show(block=False)
plt.pause(2)
plt.close()- Simple RNN
model = keras.models.Sequential([
keras.layers.SimpleRNN(1, input_shape=[None, 1])
])
optimizer = keras.optimizers.Adam(learning_rate=0.005)
model.compile(loss="mse", optimizer=optimizer)
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], model.predict(X_valid)[0, 0])
plt.show(block=False)
plt.pause(2)
plt.close()
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show(block=False)
plt.pause(2)
plt.close()- Deep RNN(Simple RNN을 쌓은 것)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20), # return_sequences=False
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], model.predict(X_valid)[0, 0])
plt.show(block=False)
plt.pause(2)
plt.close()
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show(block=False)
plt.pause(2)
plt.close()- 여러 타임 스텝 예측
series = generate_time_series(10000, n_steps+10)
X_train, y_train = series[:7000, : n_steps], series[:7000, -10:, 0]
X_valid, y_valid = series[7000: 9000, : n_steps], series[7000: 9000, -10:, 0]
X_test, y_test = series[9000:, : n_steps], series[9000:, -10:, 0]
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(10)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid)
plot_multiple_forecasts(X_valid, y_valid[..., np.newaxis], model.predict(X_valid)[..., np.newaxis])
plt.show(block=False)
plt.pause(2)
plt.close()
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show(block=False)
plt.pause(2)
plt.close()
# TimeDistributed
# 입력 시퀀스의 각 타임 스텝에 대해 동일한 레이어를 독립적으로 적용하여 동일한 연산을 수행하고,
# 각 시간 단계의 출력을 별도의 시퀀스로 반환함.
def last_time_step_mse(y_true, y_pred):
return keras.metrics.mean_squared_error(y_true[:, -1], y_pred[:, -1])
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
optimizer = keras.optimizers.Adam(learning_rate=0.01)
model.compile(loss='mse', optimizer=optimizer, metrics=[last_time_step_mse])
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_test, y_test)
plot_multiple_forecasts(X_valid, y_valid[..., np.newaxis], model.predict(X_valid)[..., np.newaxis])
plt.show(block=False)
plt.pause(2)
plt.close()
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show(block=False)
plt.pause(2)
plt.close()15.2 긴 시퀀스 다루기
15.2.1 불안정한 기울기 문제
- RNN의 경우 타임 스텝마다 가중치를 갱신하기에 ReLU 같은 발산형 함수는 기울기 폭주 위험이 큼.
- 배치 정규화는 층 사이에만 사용 가능하여 비효과적.
- Layer Normalization: 배치 차원이 아닌 특성 차원에 대해 정규화.
class LNSimpleRNNCell(keras.layers.Layer):
def __init__(self, units, activation='tanh', **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = keras.layers.SimpleRNNCell(units, activation=None)
self.layer_norm = keras.layers.LayerNormalization()
self.activation = keras.activations.get(activation)
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]
model = keras.models.Sequential([
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True, input_shape=[None, 1]),
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))15.2.2 LSTM(Long Short-Term Memory)
장기 기억을 보관하여 장기 패턴을 잡아냄.
model = keras.models.Sequential([
keras.layers.LSTM(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.LSTM(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))15.2.3 GRU(Gated Recurrent Unit)
lstm의 간소화 버전
model = keras.models.Sequential([
keras.layers.GRU(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))15.2.4 1D CNN - GRU(LSTM)
100 타임 스텝 이상의 시퀀스에서 장기 패턴을 학습하기 어려워 1D 합성곱층으로 입력 시퀀스를 짧게 줄임
model = keras.models.Sequential([
keras.layers.Conv1D(20, kernel_size=4, strides=2, padding='valid', input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, y_train[:, 3::2], epochs=20,
validation_data=(X_valid, y_valid[:, 3::2]))15.2.5 WaveNet
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=[None, 1]))
for rate in (1, 2, 4, 8)*2:
model.add(keras.layers.Conv1D(20, kernel_size=2, padding='causal', activation='relu', dilation_rate=rate))
# padding='causal': 현재와 과거 위치만 참조하여 패딩. 미래 정보 미사용. 순서 유지.
# dilation rate(팽창 비율): 필터의 적용 간격을 조정하는 매개변수
model.add(keras.layers.Conv1D(10, kernel_size=1))
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))16_자연어 처리(생성형 모델)
16.1 Char-RNN
16.1.1 모델 생성 및 훈련
import numpy as np
import tensorflow as tf
from tensorflow import keras
# 데이터셋 생성
shakespeare_url = 'https://homl.info/shakespeare'
filepath = keras.utils.get_file('shakespeare.txt', shakespeare_url)
with open(filepath) as f:
shakespeare_text = f.read()
tokenizer = keras.preprocessing.text.Tokenizer(char_level=True)
tokenizer.fit_on_texts(shakespeare_text)
print(tokenizer.texts_to_sequences(['First']))
print(tokenizer.sequences_to_texts(tokenizer.texts_to_sequences(['First'])))
max_id = len(tokenizer.word_index) # 고유한 문자 갯수
dataset_size = tokenizer.document_count # 전체 문자 갯수
print(max_id, dataset_size)
[encoded] = np.array(tokenizer.texts_to_sequences([shakespeare_text])) -1 # 1~39를 0~38로 변환하기 위해 -1
print(encoded.shape)
# 순차 데이터셋 나누기(TBPTT)
train_size = dataset_size * 90 // 100
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
print(train_size, dataset_size)
n_steps = 100
window_length = n_steps + 1 # target: 다음 1글자 앞의 input
dataset = dataset.window(window_length, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
batch_size = 32
dataset = dataset.shuffle(10000).batch(batch_size)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(lambda X_batch, y_batch: (tf.one_hot(X_batch, depth=max_id), y_batch))
dataset = dataset.prefetch(1)
# 모델링
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, input_shape=[None, max_id],
dropout=0.2, recurrent_dropout=0.2),
# dropout=0.2),
keras.layers.GRU(128, return_sequences=True,
dropout=0.2, recurrent_dropout=0.2),
# dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id,
activation="softmax"))
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam")
history = model.fit(dataset, epochs=10)
# 모델 사용하기
def preprocess(texts):
X = np.array(tokenizer.texts_to_sequences(texts)) - 1
return tf.one_hot(X, max_id)
X_new = preprocess(["How are yo"])
y_pred = np.argmax(model(X_new), axis=-1)
print(X_new)
print()
print(y_pred)
print(tokenizer.sequences_to_texts(y_pred + 1)[0][-1])
# 텍스트 생성
def next_char(text, temperature=1):
X_new = preprocess([text])
y_proba = model(X_new)[0, -1:, :]
rescaled_logits = tf.math.log(y_proba) / temperature
char_id = tf.random.categorical(rescaled_logits, num_samples=1) + 1
return tokenizer.sequences_to_texts(char_id.numpy())[0]
def complete_text(text, n_chars=50, temperature=1):
for _ in range(n_chars):
text += next_char(text, temperature)
return text
print(complete_text('t', temperature=0.2))
print('='*30)
print(complete_text('w', temperature=1))
print('='*30)
print(complete_text('w', temperature=2))-
BPTT(Backpropagation Through Time: RNN의 역전파): RNN의 파라미터를 학습하기 위해 시간 축을 따라 역전파를 수행하는 방법.
- 시퀀스의 전체 길이를 고려하여 오차를 시간 축을 따라 전파.
- 이 과정에서 긴 시퀀스는 기울기 소실이나 폭주 발생 가능하며 메모리와 계산 자원을 많이 소모할 수 있음.
-
TBPTT (Truncated Backpropagation Through Time): TBPTT는 BPTT의 계산적 부담을 줄이고, 긴 시퀀스 학습을 더 효율적으로 하기 위해 고안된 기법으로 시퀀스를 구간으로 나눠 구간 단위로 역전파를 수행.
- TBPTT의 주요 개념:
- 구간 나누기: 시퀀스를 여러 개의 일정한 길이의 짧은 구간으로 나누어 구간 단위로 역전파 수행.
- 단계별 역전파: 각 구간에서의 순전파(forward pass) 후, 구간의 끝에서 역전파(backward pass)를 수행. 역전파는 구간의 끝까지 수행되며, 이전 구간의 상태가 다음 구간으로 전달됨.
- 기울기 전파: 각 구간의 역전파 과정에서 계산된 기울기는 구간의 끝에서 다음 구간의 시작 상태로 전파. 이렇게 함으로써 긴 시퀀스 전체에 대해 기울기가 전파됨.
- TBPTT의 주요 개념:
16.1.2 상태가 있는 RNN
- 상태가 없는 RNN(stateless RNN): 각 epoch에서 무작위 텍스트의 일부 학습.
- 상태가 있는 RNN(stateful RNN): 훈련과 반복 사이에서 은닉 상태 유지하고 중지된 곳에서 이어서 상태 반영(마지막 상태를 다음 훈련 배치의 초기 상태로 사용). 긴 패턴 학습.
# 데이터 생성
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
dataset = dataset.window(window_length, shift=n_steps, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
dataset = dataset.batch(1)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(lambda X_batch, y_batch: (tf.one_hot(X_batch, depth=max_id), y_batch))
dataset = dataset.prefetch(1)
# 콜백 함수 정의
class ResetStatesCallback(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs):
self.model.reset_states()
# 모델링
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, stateful=True, dropout=0.2, recurrent_dropout=0.2,
batch_input_shape=[1, None, max_id]),
keras.layers.GRU(128, return_sequences=True, stateful=True, dropout=0.2, recurrent_dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id, activation='softmax'))
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
history = model.fit(dataset, epochs=50, callbacks=[ResetStatesCallback()])print(complete_text('t', temperature=0.2))
print('='*30)
print(complete_text('w', temperature=1))
print('='*30)
print(complete_text('w', temperature=2))16.2 감성분석
16.2.1 IMDb 리뷰 데이터
# 데이터 불러오기
import tensorflow_datasets as tfds
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data()
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
word_index = keras.datasets.imdb.get_word_index()
id_to_word = {id_ + 3: word for word, id_ in word_index.items()}
for id_, token in enumerate(('<pad>', '<sos>', '<unk>')):
id_to_word[id_] = token
print(" ".join(id_to_word[id_] for id_ in X_train[0][:10]))
datasets, info = tfds.load('imdb_reviews', as_supervised=True, with_info=True)
train_size = info.splits['train'].num_examples
# 전처리
from collections import Counter
def preprocess(X_batch, y_batch):
X_batch = tf.strings.substr(X_batch, 0, 300)
X_batch = tf.strings.regex_replace(X_batch, b'<br\\s*/?>', b' ')
X_batch = tf.strings.regex_replace(X_batch, b"[^a-zA-Z']", b' ')
X_batch = tf.strings.split(X_batch)
return X_batch.to_tensor(default_value=b'<pad>'), y_batch
vocabulary = Counter()
for X_batch, y_batch in datasets['train'].batch(32).map(preprocess):
for review in X_batch:
vocabulary.update(list(review.numpy()))
print(vocabulary.most_common()[:3])
# 어휘 사전 축소
vocab_size = 10000
truncated_vocabulary = [word for word, count in vocabulary.most_common()[:vocab_size]]
words = tf.constant(truncated_vocabulary)
word_ids = tf.range(len(truncated_vocabulary), dtype=tf.int64)
vocab_init = tf.lookup.KeyValueTensorInitializer(words, word_ids)
num_oov_buckets = 1000
table = tf.lookup.StaticVocabularyTable(vocab_init, num_oov_buckets)
# train_set 완료
def encode_words(X_batch, y_batch):
return table.lookup(X_batch), y_batch
train_set = datasets["train"].batch(32).map(preprocess)
train_set = train_set.map(encode_words).prefetch(1)
for X_batch, y_batch in train_set.take(1):
print(X_batch)
print(y_batch)
# 모델링
embed_size = 128
model = keras.models.Sequential([
keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size,
mask_zero=True, # 0 값을 패딩으로 간주하여 무시
input_shape=[None]),
keras.layers.GRU(128, return_sequences=True),
keras.layers.GRU(128),
keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
history = model.fit(train_set, epochs=5)16.2.2 마스킹
K = keras.backend
inputs = keras.layers.Input(shape=[None])
mask = keras.layers.Lambda(lambda inputs: K.not_equal(inputs, 0))(inputs)
z = keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size)(inputs)
# 0=False 나머지는 True로 하여 패딩값 무시하도록 함.
z = keras.layers.GRU(128, return_sequences=True)(z, mask=mask)
z = keras.layers.GRU(128)(z, mask=mask)
outputs = keras.layers.Dense(1, activation='sigmoid')(z)
model = keras.Model(inputs=[inputs], outputs=[outputs])
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
history = model.fit(train_set, epochs=5)16.2.3 사전 훈련된 임베딩 재사용
import tensorflow_hub as hub
model = keras.models.Sequential([
hub.KerasLayer('https://tfhub.dev/google/nnlm-en-dim50/1',
dtype=tf.string, input_shape=[], output_shape=50),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
datasets, info = tfds.load('imdb_reviews', as_supervised=True, with_info=True)
train_size = info.splits['train'].num_examples
batch_size = 32
train_set = datasets['train'].batch(batch_size).prefetch(1)
history = model.fit(train_set, epochs=5)
model = keras.Sequential([
# trainable=True로 할 경우 코랩에서 메모리 부족 에러가 발생합니다.
hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder/4",
trainable=False, dtype=tf.string, input_shape=[]),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="nadam",
metrics=["accuracy"])
model.fit(train_set, epochs=10);16.3 기계 번역을 위한 인코더-디코더 네트워크
import tensorflow_addons as tfa
import numpy as np
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
sequence_lengths = keras.layers.Input(shape=[], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
encoder = keras.layers.LSTM(512, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_embeddings)
encoder_state = [state_h, state_c]
sampler = tfa.seq2seq.sampler.TrainingSampler()
decoder_cell = keras.layers.LSTMCell(512)
output_layer = keras.layers.Dense(vocab_size)
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell, sampler, output_layer=output_layer)
final_outputs, final_state, final_sequence_lengths = decoder(decoder_embeddings, initial_state=encoder_state,
sequence_length=sequence_lengths)
y_proba = tf.nn.softmax(final_outputs.rnn_output)
model = keras.Model(inputs=[encoder_inputs, decoder_inputs, sequence_lengths], outputs=[y_proba])
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam")
X = np.random.randint(100, size=10*1000).reshape(1000, 10)
y = np.random.randint(100, size=15*1000).reshape(1000, 15)
X_decoder = np.c_[np.zeros((1000, 1)), y[:, :-1]]
seq_lengths = np.full([1000], 15)
history = model.fit([X, X_decoder, seq_lengths], y, epochs=2)16.3.1 양방향 RNN과 빔 검색
- 양방향 순환층(bidirectional recurrent layer): 좌에서 우로 하나, 우에서 좌로 하나씩 읽어 두 출력을 연결함.
- 빔 검색(beam search): k(빔 너비: beam width)개의 가능성 있는 문장 리스트를 유지하고 디코더 단계마다 이 문장의 단어를 하나씩 생성하여 가능성 있는 k개의 문장 생성.
# 데이터 준비
from pathlib import Path
url = "https://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip"
path = keras.utils.get_file("spa-eng.zip", origin=url, cache_dir="datasets",
extract=True)
text = (Path(path).with_name("spa-eng") / "spa.txt").read_text()
text = text.replace("¡", "").replace("¿", "")
pairs = [line.split("\t") for line in text.splitlines()]
np.random.shuffle(pairs)
sentences_en, sentences_es = zip(*pairs) # 쌍을 2개의 리스트로 분리합니다.
for i in range(3):
print(sentences_en[i], "=>", sentences_es[i])
vocab_size = 1000
max_length = 50
text_vec_layer_en = keras.layers.TextVectorization(
vocab_size, output_sequence_length=max_length)
text_vec_layer_es = keras.layers.TextVectorization(
vocab_size, output_sequence_length=max_length)
text_vec_layer_en.adapt(sentences_en)
text_vec_layer_es.adapt([f"startofseq {s} endofseq" for s in sentences_es])
print(text_vec_layer_en.get_vocabulary()[:10])
print(text_vec_layer_es.get_vocabulary()[:10])
X_train = tf.constant(sentences_en[:100_000])
X_valid = tf.constant(sentences_en[100_000:])
X_train_dec = tf.constant([f"startofseq {s}" for s in sentences_es[:100_000]])
X_valid_dec = tf.constant([f"startofseq {s}" for s in sentences_es[100_000:]])
Y_train = text_vec_layer_es([f"{s} endofseq" for s in sentences_es[:100_000]])
Y_valid = text_vec_layer_es([f"{s} endofseq" for s in sentences_es[100_000:]])
# 모델링
encoder_inputs = keras.layers.Input(shape=[], dtype=tf.string)
decoder_inputs = keras.layers.Input(shape=[], dtype=tf.string)
embed_size = 128
encoder_input_ids = text_vec_layer_en(encoder_inputs)
decoder_input_ids = text_vec_layer_es(decoder_inputs)
encoder_embedding_layer = keras.layers.Embedding(vocab_size, embed_size, mask_zero=True)
decoder_embedding_layer = keras.layers.Embedding(vocab_size, embed_size, mask_zero=True)
encoder_embeddings = encoder_embedding_layer(encoder_input_ids)
decoder_embeddings = decoder_embedding_layer(decoder_input_ids)
encoder = keras.layers.Bidirectional(
keras.layers.LSTM(256, return_state=True))
encoder_outputs, *encoder_state = encoder(encoder_embeddings)
encoder_state = [tf.concat(encoder_state[::2], axis=-1), # 단기 상태 (0 & 2)
tf.concat(encoder_state[1::2], axis=-1)] # 장기 상태 (1 & 3)
# 추가 코드 - 모델을 완성하고 학습시킵니다.
decoder = keras.layers.LSTM(512, return_sequences=True)
decoder_outputs = decoder(decoder_embeddings, initial_state=encoder_state)
output_layer = keras.layers.Dense(vocab_size, activation="softmax")
Y_proba = output_layer(decoder_outputs)
model = keras.Model(inputs=[encoder_inputs, decoder_inputs],
outputs=[Y_proba])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",
metrics=["accuracy"])
model.fit((X_train, X_train_dec), Y_train, epochs=10,
validation_data=((X_valid, X_valid_dec), Y_valid))
# 예측 및 번역
def translate(sentence_en):
translation = ""
for word_idx in range(max_length):
X = np.array([sentence_en]) # encoder input
X_dec = np.array(["startofseq " + translation]) # decoder input
y_proba = model.predict((X, X_dec))[0, word_idx] # last token's probas
predicted_word_id = np.argmax(y_proba)
predicted_word = text_vec_layer_es.get_vocabulary()[predicted_word_id]
if predicted_word == "endofseq":
break
translation += " " + predicted_word
return translation.strip()
print(translate("I like soccer"))
print('='*30)
print(translate("I like soccer and also going to the beach"))# 추가 코드 - 빔 검색의 기본 구현
def beam_search(sentence_en, beam_width, verbose=False):
X = np.array([sentence_en]) # 인코더 입력
X_dec = np.array(["startofseq"]) # 디코더 입력
y_proba = model.predict((X, X_dec))[0, 0] # 첫 번째 토큰의 확률
top_k = tf.math.top_k(y_proba, k=beam_width)
top_translations = [ # 촤상의 (log_proba, translation) 리스트
(np.log(word_proba), text_vec_layer_es.get_vocabulary()[word_id])
for word_proba, word_id in zip(top_k.values, top_k.indices)
]
# 추가 코드 - verbose 모드에서 상위 첫 단어를 표시합니다.
if verbose:
print("상위 첫 단어:", top_translations)
for idx in range(1, max_length):
candidates = []
for log_proba, translation in top_translations:
if translation.endswith("endofseq"):
candidates.append((log_proba, translation))
continue # 번역이 완료되었으므로 번역을 이어가지 않습니다.
X = np.array([sentence_en]) # 인코더 입력
X_dec = np.array(["startofseq " + translation]) # 디코더 입력
y_proba = model.predict((X, X_dec))[0, idx] # 마지막 토큰의 확률
for word_id, word_proba in enumerate(y_proba):
word = text_vec_layer_es.get_vocabulary()[word_id]
candidates.append((log_proba + np.log(word_proba),
f"{translation} {word}"))
top_translations = sorted(candidates, reverse=True)[:beam_width]
# 추가 코드 - verbose 모드의 경우 지금까지의 최상의 번역을 출력합니다.
if verbose:
print("지금까지 최상의 번역:", top_translations)
if all([tr.endswith("endofseq") for _, tr in top_translations]):
return top_translations[0][1].replace("endofseq", "").strip()
# 추가 코드 - 모델이 어떻게 오류를 발생시키는지 보여줍니다.
sentence_en = "I love cats and dogs"
print(translate(sentence_en))
print('='*30)
print(beam_search(sentence_en, beam_width=3, verbose=True))16.4 어텐션
16.4.1 트랜스포머
- 위치 인코딩(positional encoding): 문장 안의 단어 위치를 인코딩한 밀집 벡터. 절대 위치와 상대 위치를 알 수 있어 모델이 입력 시퀀스 내 단어의 순서를 인식할 수 있음.
- 어텐션(Self-Attention): 인코더의 모든 출력을 디코더로 전송하여 디코더 메모리 셀에서 인코더 출력의 가중치 합에 따라 집중함. 시퀀스 내 단어들 간의 상호작용을 학습하여 각 단어가 다른 단어들에 얼마나 주의를 기울여야 하는지를 결정.
- 멀티-헤드 어텐션(multi-head attention): 셀프 어텐션 메커니즘을 확장하여 여러 개의 독립적인 어텐션 헤드를 사용하는 방법. 각 헤드의 출력을 연결(concatenate)하고, 이를 선형 변환하여 최종 출력을 생성. 관련이 많은 단어에 더 많은 주의를 기울이며 각 단어와 동일한 문장에 있는 다른 단어의 관계를 인코딩함.
- 마스크드 멀티헤드 어텐션(Masked Multi-Head Attention): 현재 시점 이후의 정보가 예측에 영향을 미치지 않도록 함함. 주로 시퀀스 생성 모델(디코더)에서 사용.
# 위치 인코딩
class PositionalEncoding(keras.layers.Layer):
def __init__(self, max_steps, max_dims, dtype=tf.float32, **kwargs):
super().__init__(dtype=dtype, **kwargs)
if max_dims%2 == 1:
max_dims += 1 # max_dims는 짝수여야 함
p, i = np.meshgrid(np.arange(max_steps), np.arange(max_dims//2))
pos_emb = np.empty((1, max_steps, max_dims))
pos_emb[0, :, ::2] = np.sin(p / 10000**(2 * i / max_dims)).T
pos_emb[0, :, 1::2] = np.cos(p / 10000**(2 * i / max_dims)).T
self.positional_embedding = tf.constant(pos_emb.astype(self.dtype))
def call(self, inputs):
shape = tf.shape(inputs)
return inputs + self.positional_embedding[:, :shape[-2], :shape[-1]]
# 모델링
vocab_size = 10000
max_length = 50 # 전체 훈련 세트에 있는 최대 길이
embed_size = 128
# input 설정
encoder_inputs = keras.layers.Input(shape=[], dtype=tf.string)
decoder_inputs = keras.layers.Input(shape=[], dtype=tf.string)
encoder_input_ids = text_vec_layer_en(encoder_inputs)
decoder_input_ids = text_vec_layer_es(decoder_inputs)
encoder_embedding_layer = keras.layers.Embedding(vocab_size, embed_size, mask_zero=True)
decoder_embedding_layer = keras.layers.Embedding(vocab_size, embed_size, mask_zero=True)
encoder_embeddings = encoder_embedding_layer(encoder_input_ids)
decoder_embeddings = decoder_embedding_layer(decoder_input_ids)
pos_embed_layer = keras.layers.Embedding(max_length, embed_size)
batch_max_len_enc = tf.shape(encoder_embeddings)[1]
encoder_in = encoder_embeddings + pos_embed_layer(tf.range(batch_max_len_enc))
batch_max_len_dec = tf.shape(decoder_embeddings)[1]
decoder_in = decoder_embeddings + pos_embed_layer(tf.range(batch_max_len_dec))
pos_embed_layer = PositionalEncoding(max_length, embed_size)
encoder_in = pos_embed_layer(encoder_embeddings)
decoder_in = pos_embed_layer(decoder_embeddings)
# 인코더
N = 2
num_heads = 8
dropout_rate = 0.1
n_units = 128
encoder_pad_mask = tf.math.not_equal(encoder_input_ids, 0)[:, tf.newaxis]
Z = encoder_in
for _ in range(N):
skip = Z
attn_layer = keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate)
Z = attn_layer(Z, value=Z, attention_mask=encoder_pad_mask)
Z = keras.layers.LayerNormalization()(keras.layers.Add()([Z, skip]))
skip = Z
Z = keras.layers.Dense(n_units, activation='relu')(Z)
Z = keras.layers.Dense(embed_size)(Z)
Z = keras.layers.Dropout(dropout_rate)(Z)
Z = keras.layers.LayerNormalization()(keras.layers.Add()([Z, skip]))
# 디코더
batch_max_len_dec = 50 # tf.shape(decoder_embeddings)[1]
batch_max_len_dec = tf.shape(decoder_embeddings)[1]
decoder_pad_mask = tf.math.not_equal(decoder_input_ids, 0)[:, None]
causal_mask = tf.linalg.band_part( # 행렬의 대각선 부분을 추출하거나 수정하는 함수
tf.ones((batch_max_len_dec, batch_max_len_dec), tf.bool), -1, 0)
encoder_outputs = Z
Z = decoder_in
for _ in range(N):
skip = Z
attn_layer = keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate)
Z = attn_layer(Z, value=Z, attention_mask=causal_mask&decoder_pad_mask)
Z = keras.layers.LayerNormalization()(keras.layers.Add()([Z, skip]))
skip = Z
attn_layer = keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate)
Z = attn_layer(Z, value=encoder_outputs, attention_mask=encoder_pad_mask)
Z = keras.layers.LayerNormalization()(keras.layers.Add()([Z, skip]))
skip = Z
Z = keras.layers.Dense(n_units, activation='relu')(Z)
Z = keras.layers.Dense(embed_size)(Z)
Z = keras.layers.LayerNormalization()(keras.layers.Add()([Z, skip]))
y_proba = keras.layers.Dense(vocab_size, activation='softmax')(Z)
# 모델 생성 및 훈련
model = keras.Model(inputs=[encoder_inputs, decoder_inputs], outputs=[y_proba])
model.compile(loss='sparse_categorical_crossentropy', optimizer='nadam', metrics=['accuracy'])
model.fit((X_train, X_train_dec), Y_train, epochs=10, validation_data=((X_valid, X_valid_dec), Y_valid))