
- 구조체(Struct)
- 구조체 안의 구조체
- 구조체 포인터
- 구조체를 인자로 가지는 함수
- 구조체를 반환하는 함수
- 열거형(Enum)
- 공용체(Union)
- Q&A
- 마치며
1. 구조체(Struct)
1) 구조체란?
- 구조체(Struct)
: 사용자가 C언어의 기본 타입을 가지고 새롭게 정의할 수 있는 사용자 정의 타입struct 구조체 이름{ ... 멤버 ... };
- 멤버(Member)
: 구조체를 구성하는 변수
다음 예시를 봅시다.
# include<stdio.h>
struct Human { // Struct
int age;
int height;
int weight;
};
int main() {
struct Human Man;
Man.age = 20;
Man.height = 185;
Man.weight = 70;
printf("Man에 대한 정보\n");
printf("나이 : %d\n", Man.age);
printf("키 : %d\n", Man.height);
printf("몸무게 : %d\n", Man.weight);
return 0;
}[Result]
Man에 대한 정보
나이 : 20
키 : 185
몸무게 : 70
구조체는 쉽게 말해,
"각 원소의 타입이 제각각인 배열"입니다.
따라서 구조체는 배열과 달리,
각 멤버의 타입을 명확히 알 수 없으므로, 모든 멤버의 타입을 명시해야 합니다.
예시에서의 Man의 타입을 struct Human으로 정의했습니다.
즉, int와 float와 같이 struct Human은 새로운 타입으로 정의된 것입니다.
2) 구조체 멤버에 접근
배열과 마찬가지로, 구조체에서도 멤버에 대한 접근을 할 수 있습니다.
배열에서는 [ ]을 사용했습니다.
구조체에서는 .을 사용합니다.
- 구조체 멤버에 접근
(구조체 이름).(멤버 변수)
위의 예시의
Man.age = 20;
Man.height = 185;
Man.weight = 70;
와 같이 접근할 수 있습니다.
3) 구조체 변수의 정의 방법
(1) 구조체와 구조체 변수를 동시에 선언
struct 구조체 이름{ ... 멤버 ... }구조체 변수 이름;
아래의 예시는 struct Human타입의 변수 person을 생성하는데,
구조체를 정의하면서, 동시에 변수를 생성하는 방법입니다.
struct Human{
int age;
int gender;
} person;(2) typedef 키워드
- typedef 키워드
: 이미 존재하는 타입에 새로운 이름을 부여typedef struct (구조체 이름) (구조체의 새로운 이름);typedef struct (구조체 이름:생략 가능){ ... 멤버 ... }구조체의 새로운 이름;구조체를 정의할 때 typedef를 사용하면, 구조체의 기존 이름은 생략할 수 있습니다.
typedef struct Human Persontypedef struct (Human: 생략 가능){
int age;
int gender;
} Person;다음 예시를 봅시다.
# include<stdio.h>
typedef struct{
int age;
int gender;
}Human;
int main() {
Human person;
person.age = 20;
person.gender = 1;
printf("Age : %d || Gender : %d ", person.age, person.gender);
return 0;
}typedef연산자를 이용하면,
매번 struct 이름과 같이 사용하지 않고,
int나 float와 같이, 하나의 타입처럼 새로운 이름같이 사용할 수 있습니다.
4) 구조체 변수의 초기화
구조체를 정의할 때는 주의해아할 점이 있습니다.
구조체의 정의할 때, 멤버는 초기화 할 수 없습니다.
struct Human{
char name[10];
int age = 20; // Compile Error!!!
int height;
};위의 예시에서,
struct Human의 멤버 변수 name을 20으로 초기화했습니다.
하지만 실행하면, 컴파일 오류가 출력됩니다.
그렇다면 어떻게 초기화를 해야할까요 🤔
바로 { }와 .을 이용합니다.
- 구조체 변수의 초기화
구조체 변수 = {.멤버변수1 = 값1, ...}; 구조체 변수 = {값1, 값2, ...}; //배열과 비슷하죠?
다음 예시를 보면 이해하실 겁니다.
Man = {.name = "Tom", .age = 20, .height = 185};
Man = {"Tom", 20, 185};
5) 구조체의 대입
구조체는 =(대입 연산자)를 이용해서 대입할 수 있습니다.
# include<stdio.h>
char copy_str(char* dest, char* src);
struct Human {
char name[10];
int age;
};
int main() {
struct Human m1;
struct Human m2;
copy_str(m1.name, "Tom");
m1.age = 20;
m2 = m1; // 구조체의 대입
printf("m1의 이름 : %s\n", m1.name);
printf("m2의 이름 : %s\n\n", m2.name);
printf("m1의 나이 : %d\n", m1.age);
printf("m2의 나이 : %d\n", m2.age);
return 0;
}
char copy_str(char* dest, char* src) {
while (*src) {
*dest = *src;
dest++;
src++;
}
*dest = '\0';
return 1;
}[Result]
m1의 이름 : Tom
m2의 이름 : Tom
m1의 나이 : 20
m2의 나이 : 20
구조체끼리 =을 사용하면,
각 멤버 변수끼리 대입할 수 있습니다.
2. 구조체 안의 구조체
구조체는, 사용자가 정의한 하나의 타입이라고 했습니다.
그렇다면,
구조체는 구조체를 하나의 멤버로 가질 수 있습니다.
# include<stdio.h>
struct Human {
int age;
int gender;
};
struct Animal {
struct Human human; // Struct in Struct
char name[10];
};
int main() {
struct Animal person;
person.human.age = 20;
person.human.gender = 1;
printf("Age : %d || Gender : %d ", person.human.age, person.human.gender);
return 0;
}위의 예시에서,
struct Animal은 구조체 struct Human을 가집니다.
3. 구조체 포인터
앞서 말했듯이, 우리가 정의한 struct Human도 하나의 타입입니다.
int나 float에서도 포인터를 사용했듯이,
구조체에서도 포인터를 사용할 수 있습니다.
# include<stdio.h>
struct Human {
int age;
};
int main() {
struct Human Man;
struct Human* pMan; // 구조체 포인터
pMan = &Man;
(*pMan).age = 1;
printf("Man에 대한 정보\n");
printf("나이 : %d\n", Man.age);
return 0;
}[Result]
Man에 대한 정보
나이 : 20
pMan = &Man;를 보면 &연산자를 사용하네요.
구조체는 절대로 배열이 아닙니다! (그냥 비슷하게 생긴거죠)
그래서 배열처럼
"구조체의 이름도 시작 주소값을 나타내는거 아냐? &을 왜 쓰지?"라고 생각하면 안됩니다.
구조체는 구조체일뿐입니다.
구조체 타입으로 정의된 변수도 그냥 변수일뿐입니다.
그래서 꼭 &을 사용해주세요!
(*pMan).age = 1;을 보면,
pMan은 Man을 가리키는 포인터이므로,
*pMan은 Man과 동일하다고 생각할 수 있습니다.
그런데 굳이 ()를 사용해야하나요?
그냥 pMan.age = 1;을 하면 안될까요?
그렇게 하면 컴파일 오류가 출력됩니다.
왜 그럴까요?
바로 연산자 우선순위 때문입니다.
.연산자는 *연산자보다 우선 순위이기 때문에,
()를 사용하지 않으면,
pMan.age를 실행한 후, 그 값에 *를 한 것에 20이 들어갑니다.
pMan은 그저 포인터입니다.
절대로 구조체가 아닌, 그저 구조체를 가리키는 단순 포인터일뿐입니다.
그러니 포인터에는 있지도 않은 멤버 age를 어떻게 접근하겠어요...
즉, 구조체 포인터를 사용해서 멤버에 접근하고자 할 때는
반드시 ()를 사용해야 합니다.
그래서 프로그래머들은 ()를 사용하는 대신,
사용할 수 있는 기호 ->를 만들었습니다.
# include<stdio.h>
struct Human {
int age;
};
int main() {
struct Human Man;
struct Human* pMan;
pMan = &Man;
/*(*pMan).age = 1;*/
pMan->age = 1;
printf("Man에 대한 정보\n");
printf("나이 : %d\n", Man.age);
return 0;
}[Result]
Man에 대한 정보
나이 : 20
4. 구조체를 인자로 가지는 함수
아래의 예시를 봅시다.
# include<stdio.h>
int setting(struct Human a, int age, int gender);
struct Human {
int age;
int gender;
};
int main() {
struct Human m;
setting(m, 20, 1);
printf("Age : %d || Gender : %d ", m.age, m.gender);
return 0;
}
int setting(struct Human a, int age, int gender){
a.age = age;
a.gender = gender;
return 1;
}setting이라는 함수에 인자로 struct Human이라는 구조체를 인자로 전달했습니다.
실행을 하면 컴파일 오류가 출력됩니다.
오류는 "m이 초기화되지 않은 상태로 사용되었다"고 합니다.
우리는 함수 setting을 통해서 초기화를 하려고 했는데,
제대로 작동하지 않은 모양이네요..😢
전에도 배웠지만,
특정한 변수의 값을 다른 함수를 통해 바꾸려면, 변수의 주소값을 전달해야 한다"
는 것을 명심해야 합니다.
그렇다면 위의 예시를 수정해봅시다.
# include<stdio.h>
int setting(struct Human* a, int age, int gender);
struct Human {
int age;
int gender;
};
int main() {
struct Human m;
setting(&m, 20, 1); // 주소값 전달
printf("Age : %d || Gender : %d ", m.age, m.gender);
return 0;
}
int setting(struct Human *a, int age, int gender){
a->age = age;
a->gender = gender;
return 1;
}[Result]
Age : 20 || Gender : 1
5. 구조체를 반환하는 함수
구조체는 하나의 타입이므로,
함수의 반환형으로도 사용할 수 있습니다.
# include<stdio.h>
struct Human generate(int age, int gender);
struct Human {
int age;
int gender;
};
int main() {
struct Human person;
person = generate(20, 1);
printf("Age : %d || Gender : %d ", person.age, person.gender);
return 0;
}
struct Human generate(int age, int gender) {
struct Human t;
t.age = age;
t.gender = gender;
return t; //구조체를 return
}[Result]
Age : 20 || Gender : 1
6. 열거형(Enum)
프로그래밍을 하다보면, 각 데이터에 수를 대응시키는 경우가 많습니다.
예를 들어, 남자는 0, 여자는 1.
빨강에는 0, 파랑에는 1.
뭐 이런식으로요.
이 때, 각 데이터에 대응하는 수가 뭔지 헷갈리는 경우가 많습니다.
(외우기도 귀찮죠..)
상수를 정의해서 사용해도 되지만, 메모리가 낭비됩니다.
이 때, 사용하는 것이 '열거형(Enum)'입니다.
- 열거형(Enum)
: 새로운 타입을 선언하면서, 동시에 해당 타입이 가질 수 있는 정수형 상수값을 명시할 수 있는 타입
다음 예시를 봅시다.
# include<stdio.h>
enum{ RED, BLUE, WHITE};
int main() {
int color = RED;
switch (color) {
case RED:
printf("Color is RED\n");
break;
case BLUE:
printf("Color is BLUE\n");
break;
case WHITE:
printf("Color is WHITE\n");
break;
}
return 0;
}[Result]
Color is RED
enum{ RED, BLUE, WHITE};을 통해 열거형을 정의했습니다.
열거형의 각 원소에는 0부터 차례대로 정수값을 매겨줍니다.
RED는 0, BLUE는 1, WHITE는 2처럼 말이죠.
처음 시작 정수값을 따로 설정할 수 있습니다.
enum{ RED = 3, BLUE, WHITE};위처럼 하면, RED = 3, BLUE = 4, WHITE = 5가 됩니다.
활용하면 다음도 가능합니다.
enum{ RED = 3, BLUE, WHITE = 3, BLACK};이렇게 하면, RED, WHITE = 3, BLUE, BLACK = 4가 됩니다.
7. 공용체(Union)
공용체는 Union 키워드를 사용해 선언하며,
한 가지를 제외하면 구조체와 같습니다.
바로 모든 멤버 변수가 하나의 메모리 공간을 공유합니다.
오잉?? 무슨 말일까요?
구조체는 각 멤버 변수가 다른 공간의 메모리에 저장됩니다.
하지만 구조체는 동일한 영역을 사용하는데요,
그래서 공용체는 한 번에 하나의 멤버 변수만 사용할 수 있습니다.
이 때, 할당되는 메모리 공간의 크기는,
멤버 변수 중 크기가 가장 큰 멤버 변수의 크기로 할당 받습니다.)
# include<stdio.h>
union A {
int i;
char j;
};
int main() {
union A a;
a.i = 0x12345678;
printf("%x", a.j);
return 0;
}[Result]
78
오잉?? 이상한 점이 있습니다.
일단 초기화하지 않은 j값을 출력하자 78이라는 결과가 나왔습니다.
변수 i와 j는 공용체 A의 멤버 변수이고,
이 둘은 메모리 공간을 공유하게 됩니다.
그것까지는 알겠는데 왜 0x12도 아닌 78이 나올까요?
컴퓨터에서 메모리에 수를 저장할 때,
2가지 방법이 있습니다. 살펴보죠
1) 빅 엔디안(Big Endian) Vs 리틀 엔디안(Little Endian)
- 빅 엔디안(Big Endian)
: 낮은 주소값에 상위 비트를 적는 방식
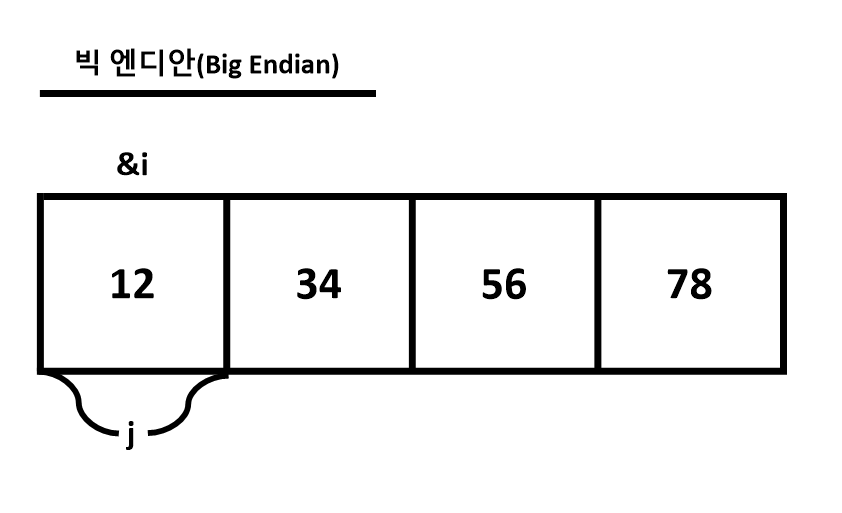
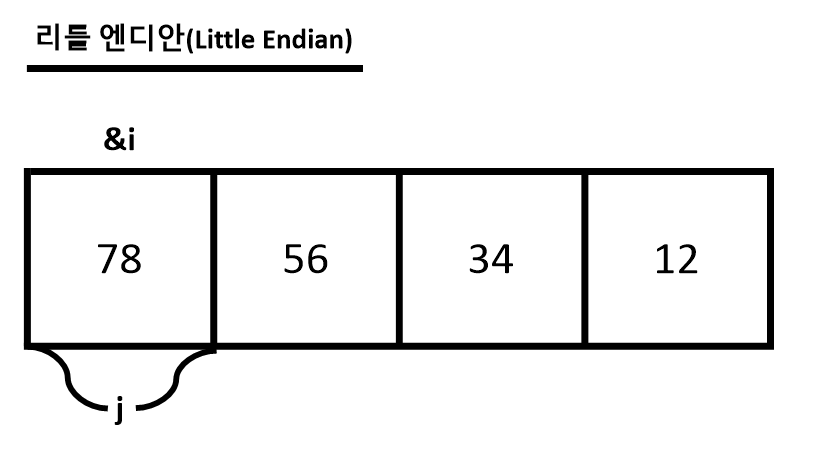
- 리틀 엔디안(Little Endian)
: 높은 주소값에 상위 비트를 적는 방식
: 대부분의 컴퓨터는 리틀 엔디안 방식을 사용
그러면 위의 예시에서 char j를 short j로 바꿔볼까요?
그러면 결과가 5678이 나옵니다.
???
short는 2바이트니까 j에 해당하는 부분은 분명
0x7856이지 않을까요?
그런데, i의 주소값을 출력해도 0x78563412이 안나오고, 0x12345678이 나오지 않나요?
즉, 컴퓨터는 자신이 리틀 엔디안 방식을 사용하고 있다는 것을 알고,
출력할 때는 0x12345678로 적절하게 변환하여 출력합니다.
그러면 j도 마찬가지겠죠?
0x7856이 아니라, 변환을 통해 0x5678이 출력됩니다.
8. Q&A
-
9. 마치며
으아...정말 많은 내용이네요..
그래도 어려운 내용은 없는 것 같습니다.
한 번씩 읽어보면서 정리하는 느낌으로 복습한 것 같네요...
[Reference] : 위 글은 다음 내용을 참고, 인용하여 만들어졌습니다.
