강화 학습(reinforcement learning, RL)은 최근 머신러닝에서 가장 흥미진진한 분야이자 가장 오래된 분야
강화 학습 분야에 강력한 딥러닝을 적용하면 상상 이상의 성능을 기대할 수 있음
18.1 보상을 최적화하기 위한 학습
강화 학습에서 소프트웨어 에이전트는 관측(observation)을 하고 주어진 환경에서 행동을 함. 결과에 따라 환경으로부터 보상을 획득
에이전트는 환경 안에서 행동하고 시행착오를 겪으며 양의 보상을 최대 / 음의 보상을 최소가 되도록 학습
미로 속을 움직이는 것과 같이 양의 보상이 전혀 없을 수도 있음. 미로에서는 매 타임 스텝마다 음의 보상을 받기 때문에 가능한 한 빨리 탈출구를 찾아야 함.
18.2 정책 탐색
정책(policy) : 소프트웨어 에이전트가 행동을 결정하기 위해 사용하는 알고리즘
확률적 정책(stochastic policy) : 무작위 성이 포함되어 있는 정책
정책 탐색(policy search) : 변경이 가능한 정책 파라미터에 많은 다른 값을 시도해보고 가장 성능이 좋은 조합을 고르는 학습 알고리즘
→ 정책 공간(policy space)이 매우 크면 이 방법으로 좋은 파라미터 조합을 찾는 것은 매우 어려움
유전 알고리즘(genetic algorithm)
예시)
- 1세대 정책 100개를 랜덤 생성
- 성능이 낮은 정책 80개는 버리고 20개를 살림
- 남은 정책 20개에게 각각 자식 정책 4개를 생산하게 함
- 자식 정책은 부모를 복사한 것에 약간의 무작위성을 더함
- 살아남은 정책과 그 자식은 2세대를 구성
- 좋은 정책을 찾을 때까지 여러 세대를 반복
정책 그레이디언트(policy gradient, PG)
- 정책 파라미터에 대한 보상의 그레이디언트를 평가
- 높은 보상의 방향을 따르는 그레이디언트로 파라미터를 수정하는 최적화 기법
18.3 OpenAI Gym
강화 학습에서 어려운 점은 에이전트를 훈련하기 위해 시뮬레이션 환경이 필요하다는 것
OpenAI Gym(https://gym.openai.com)은 다양한 종류의 시뮬레이션 환경을 제공하는 툴킷. 코랩에 설치되어 있음.
환경을 만든 후 reset() 메서드로 꼭 초기화 해야함.
18.4 신경망 정책
신경망 정책에서 신경망은 관측을 입력으로 받고 실행할 행동을 출력함. (각 행동에 대한 확률 추정)
→ 추정된 확률에 따라 랜덤하게 행동 선택
왜 가장 높은 점수의 행동을 선택하지 않고, 신경망이 만든 확률을 기반으로 행동을 선택하는가?
→ 에이전트가 새로운 행동을 탐험하는 것과 잘할 수 있는 행동을 활용(exploiting)하는 것 사이에서 균형을 맞추게 함
탐험과 활용의 딜레마는 강화 학습의 핵심
각 관측이 환경에 대한 완전한 상태를 담고 있기 때문에 과거의 행동과 관측은 무시해도 괜찮음.
만약 어떤 상태가 숨겨져 있다면 과거의 행동과 관측도 고려해야 함.
18.5 행동 평가 : 신용 할당 문제
각 스텝에서 가장 좋은 행동이 무엇인지 알고 있다면 추정된 확률과 타깃 확률 사이의 크로스 엔트로피를 최소화하도록 신경망을 훈련할 수 있음.
하지만 강화 학습에서 에이전트가 얻을 수 있는 가이드는 보상뿐. 보상은 일반적으로 드물고, 지연되어 나타남.
→ 에이전트가 보상을 받았을 때 어떤 행독 덕분(탓)인지 알기 어려운 신용 할당 문제(credit assignment problem) 발생
행동이 일어난 후 각 단계마다 할인 계수(discount factor) 를 적용한 보상을 모두 합하여 행동을 평가하는 방법으로 해당 문제를 해결. 할인된 보상의 합을 행동의 대가(return)이라 함.
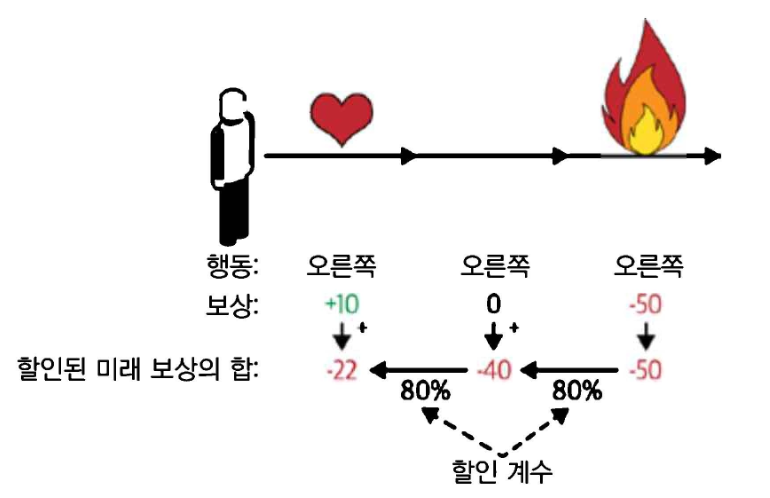
- 에이전트가 오른쪽으로 3번 이동하기로 결정하고 첫 번째 스텝에서 +10, 두 번째 스텝에서 0, 세 번째 스텝에서 -50의 보상을 받았을 때 할인 계수 =0.8을 사용한다고 가정
- 행동의 이득은 -22
- 할인 계수가 0에 가까우면 미래의 보상은 현재의 보상만큼 중요하게 취급되지 않음
- 할인 계수가 1에 가까우면 미래의 보상은 현재의 보상만큼 중요하게 고려
- 전형적인 할인 계수의 값은 0.9~0.99
좋은 행동 뒤에 나쁜 행동이 몇 번 뒤따르면 좋은 행동이 낮은 대가를 받음. 충분히 많은 횟수만큼 반복하면 평균적으로 좋은 행동이 나쁜 행동보다 더 높은 대가를 받음.
추정해야하는 것은 '평균적으로' 다른 행동과 비교해서 각 행동이 얼마나 좋은지/나쁜지를 추정해야 함.
→ 이것을 행동 이익(action advantage)라고 함.
많은 에피소드를 실행하고, 모든 행동의 대가를 정규화하면, 행동 이익이 음수인 행동은 나쁘고, 양수인 행동은 좋다고 가정할 수 있음.
18.6 정책 그레이디언트
REINFORCE 알고리즘
- 1992년 로날드 윌리엄스가 소개
- 일반적으로 많이 사용하는 REINFORCE 알고리즘 방식
- 신경망 정책이 여러 번에 걸쳐 게임을 플레이. 매 스텝마다 선택된 행동이 더 높은 가능성을 가지도록 만드는 그레이디언트 계산
- 에피소드를 몇 번 실행하고, 각 행동의 이익 계산
- 한 행동의 이익이 양수 → 좋은 행동 → 미래에 선택될 가능성이 높도록 앞서 계산한 그레이디언트 적용
- 행동 이익이 음수 → 나쁜 행동 → 미래에 행동이 덜 선택되도록 반대의 그레이디언트 적용
- 모든 결과 그레이디언트 벡터를 평균 내어 경사 하강법 스텝 수행
샘플 효율성(sample efficiency)이 매우 좋지 못하기 때문에, 아주 긴 시간 동안 게임을 플레이해야 정책을 많이 개선할 수 있음
→ 크고 복잡한 문제에는 적용하기 어려움
18.7 마르코프 결정 과정
PG 알고리즘은 보상을 증가시키기 위해 정책을 직접적으로 최적화하지만 이번에 살펴볼 알고리즘은 덜 직접적임. 알고리즘을 이해하려면 먼저 마르코프 결정 과정(Markov Decision Process, MDP)에 대한 이해가 우선.
마르코프 연쇄(Markov chain)
- 20세기 초 수학자 안드레이 마르코프가 연구
- 메모리가 없는 확률 과정(stochastic process)에 대한 연구
정해진 개수의 상태를 가지고 있으며, 각 스텝마다 한 상태에서 다른 상태로 랜덤하게 전이
상태 s에서 상태 s'으로 전이하기 위한 확률은 고정되어 있으며, 시스템에 메모리가 없으므로 과거 상태에 상관없이 (s, s') 쌍에 의존
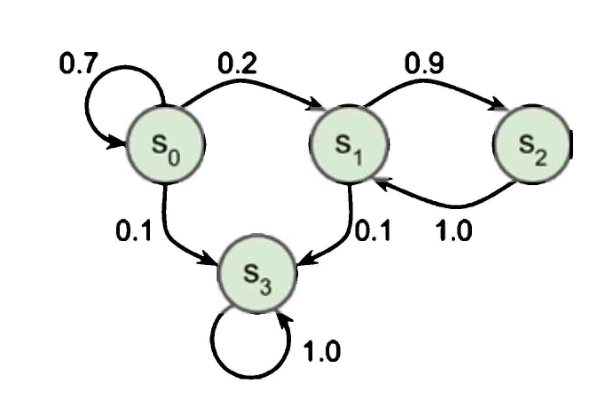
4개의 상태가 있는 마르코프 연쇄의 예시
- 과정이 상태 s0에서 시작한다고 가정하면,
다음 스텝에서 이 상태에 남을 확률은 70%이고, s0 방향을 가리키는 상태가 없기 때문에 이 상태를 떠나면 다시 돌아올 수 없음 - 만약 상태 s1로 갔다면, 상태 s2로 갈 가능성이 90%. 그다음 바로 s1으로 100% 돌아옴
- 두 상태를 여러 번 오갈 수 있지만 결국 상태 s3에 도달하고, 나오는 길이 없기 때문에 영원히 그 상태에 남음
→ 종료 상태(terminal state)
마르코프 연쇄는 다양한 역학 관계를 모델링 할 수 있어서 많은 분야에서 사용
마르코프 결정 과정
마르코프 연쇄와 비슷하지만 약간 다른 점이 있음
- 각 스텝에서 에이전트는 여러 가능한 행동 중 하나를 선택
- 전이 확률은 선택된 행동에 따라 달라짐
- 상태 전이는 보상을 반환
- 에이전트의 목적 : 시간이 지남에 따라 보상을 최대화하기 위한 정책을 찾는 것
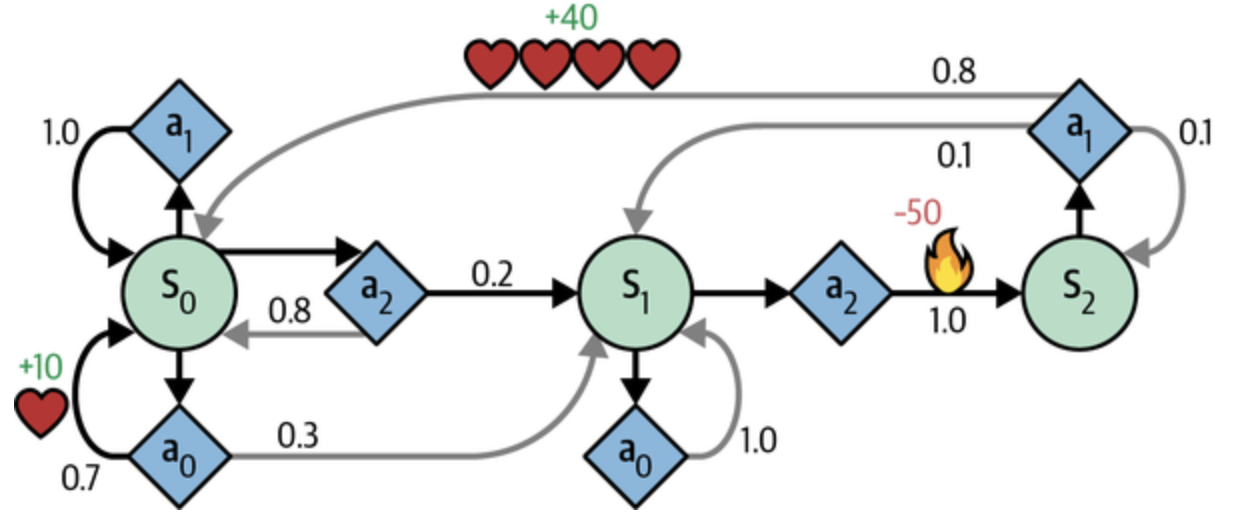
- 상태 s0 → 행동 a0, a1, a2 선택 가능
- a0 선택
70% 확률로 +10 보상 / s0으로 이동
가능한 한 보상을 많이 받도록 계속해서 반복 시도 가능 → 언젠간 s1로 이동 - a1 선택
그대로 a0에 남고, 아무런 보상 X
- a0 선택
- 상태 s1 → 행동 a0, a2 선택 가능
- a0 선택
계속 같은 상태에 머무름 - a2 선택
s2로 이동하고, -50의 보상
- a0 선택
- 상태 s2 → 행동 a1 선택 가능
- a1 선택
상태 s0으로 돌아갈 가능성이 높고 +40 보상
- a1 선택
상태 s0 : 행동 a0 이 최선
상태 s2 : a1 외에는 선택 불가능
상태 s1 : a0 / a2 중에서 확실하지 않음
벨만 최적 방정식(Bellman optimality equation)
에이전트가 최적으로 행동하면 적용되는 방정식
어떤 상태 s의 최적의 상태 가치(optimal state value) 를 추정하는 방법
에이전트가 상태 s에 도달한 후 최적으로 행동한다고 가정하고 평균적으로 기대할 수 있는 할인된 미래 보상의 합
- T(s, a, s')는 에이전트가 행동 a를 선택했을 때 상태 s에서 상태 s'로 전이될 확률
- R(s, a, s')는 에이전트가 행동 a를 선택해서 상태 s에서 상태 s'로 이동했을 때 에이전트가 받을 수 있는 보상
- 는 할인 계수
알고리즘이 가능한 모든 상태에 대한 최적의 상태 가치를 정확히 추정할 수 있도록 돕는 방정식
- 모든 상태 가치를 0으로 초기화
- 가치 반복(value iteration) 알고리즘을 사용하여 반복적으로 업데이트
- 가치 반복 알고리즘. 이 식에서 는 알고리즘의 k번째 반복에서 상태 s의 추정 가치
- 충분한 시간이 주어지면 이 추정값이 최적의 정책에 대응되는 최적의 상태 가치에 수렴하는 것이 보장
최적의 상태 가치를 아는 것은 정책을 평가할 때 매우 유용
Q-가치(Q-value)
최적의 상태-행동 가치(state-action value)를 추정할 수 있는 알고리즘
상태-행동(s, a) 쌍에 대한 최적의 Q-가치인 는 에이전트가 상태 s에 도달해서 행동 a를 선택한 후 이 행동의 결과를 얻기 전에 평균적으로 기대할 수 있는 할인된 미래 보상의 합
알고리즘 작동 방식
- Q-가치의 추정을 모두 0으로 초기화
- Q-가치 반복(Q-value iteration) 알고리즘을 사용해 업데이트
- Q-가치 반복 알고리즘
- 최적의 Q-가치를 구하고 나면 최적의 정책인 를 정의하는 것은 간단함. 에이전트가 상태 s에 도달했을 때 가장 높은 Q-가치를 가진 행동을 선택.
18.8 시간차 학습
독립적인 행동으로 이루어진 강화 학습 문제는 보통 마르코프 결정 과정으로 모델링될 수 있지만, 초기에 에이전트는 전이 확률에 대해 알지 못하며 보상이 얼마나 되는지도 알지 못함.
보상에 대해 알기 위해서는 적어도 한 번은 각 상태와 전이를 경험해야 하고, 전이 확률에 대해 신뢰할 만한 추정을 얻으려면 여러 번 경험해야 함.
시간차 학습(temporal difference learning, TD학습)
- Q-가치 반복 알고리즘과 매우 비슷하지만 에이전트가 MDP에 대해 일부 정보만 알고 있을 때를 다룰 수 있도록 변형한 것
- 에이전트가 초기에 가능한 상태와 행동만 알고 다른 것은 모른다고 가정
- 에이전트는 탐험 정책(exploration policy)을 사용해 MDP를 탐험
- 탐험이 진행될 수록 TD 학습 알고리즘이 실제 관측된 전이와 보상에 근거해 상태 가치의 추정값을 업데이트
TD 학습 알고리즘
또는 다음과도 같이 표현할 수 있음
- 는 학습률
- 는 TD 타깃
- 는 TD 오차
- 표기법을 사용하면 더 간단히 나타낼 수 있음
이 표기법은 을 뜻함
식의 첫째 줄을 해당 표기법을 사용하면와 같이 나타낼 수 있음
18.9 Q-러닝
전이 확률과 보상을 초기에 알지 못한 상황에서 Q-가치 반복 알고리즘을 적용한 것
Q-러닝은 점진적으로 Q-가치 추정을 향상하는 방식으로 작동. 정확한 Q-가치 추정을 얻게 되면 최적의 정책은 가장 높은 Q-가치를 가지는 행동을 선택.
- Q 러닝 알고리즘
각 상태-행동 (s, a) 쌍마다 알고리즘이 행동 a를 선택해 상태 s를 떠났을 때 에이전트가 받을 수 있는 보상 r과 기대할 수 있는 할인된 미래 보상의 합을 더한 이동 평균을 저장
미래 보상의 합을 추정하기 위해서는 타깃 정책이 이후로 최적으로 행동한다고 가정하고 다음 상태 s'에 대한 Q-가치 추정의 최댓값을 선택
18.9.1 탐험 정책
완전한 랜덤 정책은 모든 상태와 전이를 여러 번 경험하도록 보장하지만, 극단적으로 오랜 시간이 걸릴 수 있음
𝜺-그리디 정책(𝜺-greedy policy)는 각 스텝에서 𝜺 확률로 랜덤하게 행동하거나 1-𝜺 확률로 그 순간 가장 최선인 것으로 행동
Q-가치 추정이 점점 더 향상되기 때문에 환경에서 관심 있는 부분을 살피는 데 점점 더 많은 시간을 사용한다는 장점이 있고, 𝜺 값은 높게 시작해서 점점 감소되는 것이 일반적
18.9.2 근사 Q-러닝과 심층 Q-러닝
Q-러닝의 주요 문제는 많은 상태와 행동을 가진 대규모 MDP에 적용하기 어렵다는 것
근사 Q-러닝(approximate Q-learning)
해결책은 어떤 상태-행동 (s,a) 쌍의 Q-가치를 근사하는 함수 를 적절한 개수의 파라미터를 사용하여 찾는 것(는 파라미터 벡터)
2013년 딥마인드는 심층 신경망을 사용해 복잡한 문제에서 더 좋은 결과를 보임
- 어떤 특성 공학도 사용하지 않음
- 심층 Q-네트워크(deep Q-network, DQN) : Q-가치를 추정하기 위해 사용하는 DNN
- 심층 Q-러닝(deep Q-learning) : 근사 Q-러닝을 위해 DQN을 사용하는 것
DQN 훈련 방법
주어진 상태-행동 쌍(s,a)에 대해 DQN이 계산한 근사 Q-가치
- 벨만 식을 근거로, 근사 Q-가치는 상태 s에서 행동 a를 실행했을 때 관측된 보상 r과 최적으로 행동해서 얻은 할인된 가치를 더한 값에 가능한 가까워야 함
- 미래의 할인된 가치를 추정하기 위해서는 다음 상태 s'와 모든 가능한 행동 a'에 대해 DQN 실행
➔ 모든 가능한 행동에 대한 미래의 근사 Q-가치를 얻음 - 근사 Q-가치가 가장 높은 것을 고르고 할인을 적용하면 할인된 미래 보상의 추정을 얻을 수 있음
- 타깃 Q-가치
- 보상 r과 미래의 할인된 가치 추정을 더해 얻은 상태-행동 쌍 (s,a)에 대한 타깃 Q-가치 y(s,a)
18.10 심층 Q-러닝 구현
input_shape = [4]
n_outputs = 2
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, activation="elu", input_shape=input_shape),
tf.keras.layers.Dense(32, activation="elu"),
tf.keras.layers.Dense(n_outputs)
])첫 번째로 필요한 것은 심층 Q-네트워크
이론적으로는 상태-행동 쌍을 입력으로 받고 근사 Q-가치를 출력하는 신경망이 필요하지만, 실전에서는 상태만 입력으로 받고 가능한 모든 행동에 대한 근사 Q-가치를 각각 출력하는 것이 훨씬 효율적
def epsilon_greedy_policy(state, epsilon=0):
if np.random.rand() < epsilon:
return np.random.randint(n_outputs) # 랜덤 행동
else:
Q_values = model.predict(state[np.newaxis], verbose=0)[0]
return Q_values.argmax() # DQN으로 계산한 최적의 행동- DQN으로 행동을 선택하기 위해 예측 Q-가치가 가장 큰 행동 선택
- 에이전트가 환경을 탐험하도록 만들기 위해 𝜺-그리디 정책 사용
from collections import deque
replay_buffer = deque(maxlen=2000)- 재생 버퍼(replay buffer)에 모든 경험을 저장하고 훈련 반복마다 여기에서 랜덤한 훈련 배치를 샘플링
- 경험과 훈련 배치 사이의 상관관계가 줄어들어 훈련에 큰 도움
def sample_experiences(batch_size):
indices = np.random.randint(len(replay_buffer), size=batch_size)
batch = [replay_buffer[index] for index in indices]
return [
np.array([experience[field_index] for experience in batch])
for field_index in range(6)
] # [states, actions, rewards, next_states, dones, truncateds]- 각 경험은 원소 6개로 구성
- 상태 s
- 에이전트가 선택한 행동 a
- 결과 보상 r
- 도달한 다음 상태 s'
- 에피소드 종류 여부(boolean done)
- 에피소드 중단 여부(boolean truncated)
def play_one_step(env, state, epsilon):
action = epsilon_greedy_policy(state, epsilon)
next_state, reward, done, truncated, info = env.step(action)
replay_buffer.append((state, action, reward, next_state, done, truncated))
return next_state, reward, done, truncated, info𝜺-그리디 정책으로 하나의 스텝을 실행하고 반환된 경험을 재생 버퍼에 저장하는 함수
batch_size = 32
discount_factor = 0.95
optimizer = tf.keras.optimizers.Nadam(learning_rate = 1e-2)
loss_fn = tf.keras.losses.mean_squared_error
def training_step(batch_size):
experiences = sample_experiences(batch_size)
states, actions, rewards, next_states, dones, truncateds = experiences
next_Q_values = model.predict(next_states, verbose=0)
max_next_Q_values = next_Q_values.max(axis=1)
runs = 1.0 - (dones | truncateds)
target_Q_values = rewards + runs * discount_factor * max_next_Q_values
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, n_outputs)
with tf.GradientTape() as tape:
all_Q_values = model(states)
Q_values = tf.reduce_sum(all_Q_values * mask, axis=1, keepdims=True)
loss = tf.reduce_mean(loss_fn(target_Q_values, Q_values))
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))재생 버퍼에서 경험 배치를 샘플링하고 경사 하강법 한 스텝을 수행하여 DQN을 훈련하는 함수
- 하이퍼파라미터 정의 및 옵티마이저, 손실 함수 생성
- training_step()
- 경험 배치 샘플링
- DQN으로 각 경험의 다음 상태에서 가능한 모든 행동에 대한 Q-가치 예측
- 다음 상태에 대한 최대 Q-가치만 저장
- 각 경험의 상태-행동쌍에 대한 Q-가치 계산
- DQN이 에이전트가 실제로 선택한 행동뿐 아니라 다른 가능한 행동에 대한 Q-가치도 출력하기 때문에 필요하지 않은 모든 Q-가치를 마스크 처리
- 손실 계산
- 경사 하강법 수행
for episode in range(600):
obs, info = env.reset()
for step in range(200):
epsilon = max(1-episode /500, 0.01)
obs, reward, done, truncated, info = play_one_step(env, obs, epsilon)
if done or truncated:
break
if episode > 50:
training_step(batch_size)- 최대 스텝 200번으로 이루어진 에피소드 600개 실행
- 𝜺-그리디 정책에 대한 epsilon 값 계산
- 행동을 선택하여 실행하고 그 경험을 재생 버퍼에 기록
- 에피소드가 종료되거나 중단되면 반복 종료
- 50 에피소드 이후에는 샘플링한 배치로 모델 훈련
최악의 망각
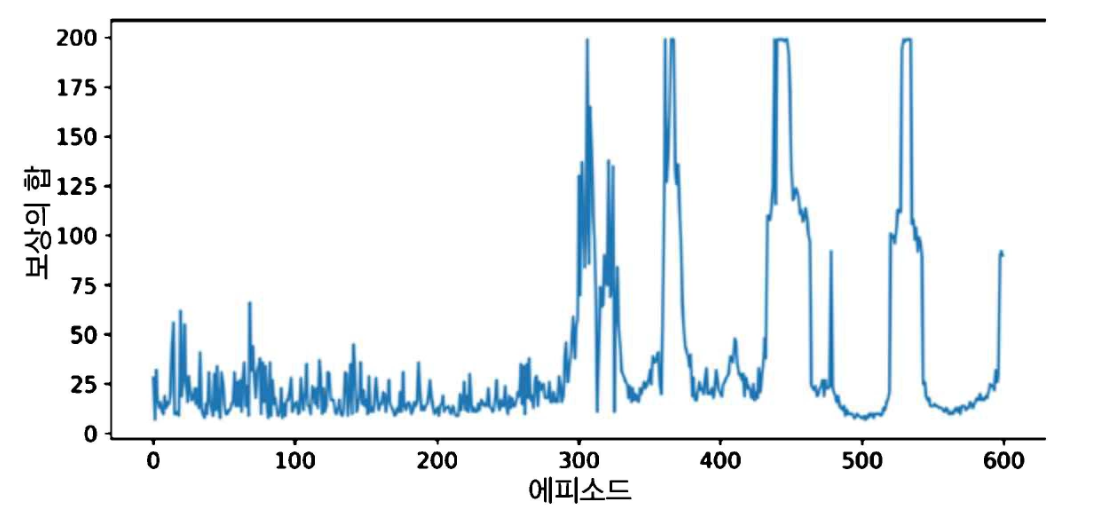
최대 보상에 도달하지만 곧바로 떨어지고, 몇 번 오르내리다가 안정되는 것처럼 보였으나 다시 점수가 급격히 떨어지는 경향
→ 최악의 망각(catastrophic forgetting)
- 모든 RL알고리즘이 직면하는 문제
- 환경의 한 부분에서 학습한 것이 앞서 다른 부분에서 학습한 것을 망가뜨릴 수 있음
- 재생 버퍼 크기를 늘리거나, 학습률을 튜닝하거나, 많은 하이퍼파라미터 값과 랜덤 시드를 시도해야 잘 작동하는 조합을 찾을 수 있음
18.11 심층 Q-러닝의 변형
훈련을 안정적이고 빠르게 만드는 심층 Q-러닝 알고리즘의 몇 가지 변형
18.11.1 고정 Q-가치 타깃
기본 심층 Q-러닝 알고리즘에서 모델은 예측을 만들고 타깃을 설정하는 데 모두 사용
→ 자신의 꼬리를 쫓는 강아지에 비유할 만한 상황을 만들 수 있음(피드백 순환)
→ 네트워크를 불안정하게 만들어 발산, 진동, 동결 등의 문제 발생
문제를 해결하기 위해 2013년 논문에서 딥마인드의 연구자들은 한 개가 아닌 두 개의 DQN 사용
첫 번째 DQN : 각 스텝에서 학습하고 에이전트를 움직이는 데 사용하는 온라인 모델
두 번째 DQN : 타깃을 정의하기 위해서만 사용하는 타깃 모델. 타깃 모델은 온라인 모델의 단순한 복사본
타깃 모델은 온라인 모델보다 자주 업데이트 X → Q-가치 타깃이 더 안정적, 피드백 반복 완화
연구자들은 0.00025라는 작은 학습률과 10,000 스텝마다 타깃 모델을 업데이트, 매우 큰 재생 버퍼 사용하는 방법 사용
epsilon을 100만 스텝 동안 1에서 0.1까지 매우 천천히 감소시키고 5천만 스텝 동안 알고리즘 실행
18.11.2 더블 DQN
더블 DQN(double DQN)
- 2015년 딥마인드 연구자들 발표
- DQN 알고리즘을 개선하여 성능과 훈련 안전성 향상
- 타깃 네트워크가 Q-가치를 과대평가하기 쉽다는 관측을 기반으로 하여 이를 개선하기 위해 다음 상태에서 최선의 행동을 선택할 때 타깃 모델 대신 온라인 모델을 사용하도록 제안
- 타깃 모델은 최선의 행동에 대한 Q-가치를 추정할 때만 사용
18.11.3 우선 순위 기반 경험 재생
중요도 샘플링(importance sampling, IS) 또는 우선 순위 기반 경험 재생(prioritized experience replay, PER)
- 재생 버퍼에서 경험을 균일하게 샘플링하지 않고 중요한 경험을 더 자주 샘플링하는 아이디어
- 2015년 딥마인드 연구자들이 소개
어떤 경험이 학습 진행을 빠르게 만들면 '중요한' 것으로 간주
- TD 오차()의 크기를 측정하여 평가
- 큰 TD 오차는 전이 (s,a,s')에서 배울 가치가 있음을 의미
경험은 재생 버퍼에 기록될 때 적어도 한 번 샘플링 되기 위해 매우 높은 우선 순위 값으로 설정
샘플링된 후 TD 오차를 계산하여 경험 우선 순위를 로 설정
우선 순위 p의 경험을 샘플링할 확률 P는 에 비례
- 는 우선 순위 샘플링을 얼마나 탐욕적으로 할 것인지 제어하는 하이퍼파라미터
- =0이면 균등하게 샘플링, =1이면 완전한 중요도 샘플링.
- 저자들은 =0.6 사용
- 최적의 값은 작업에 따라 다름
샘플이 중요한 경험에 편향되어 있으므로 훈련하는 동안 중요도에 따라 경험의 가중치를 낮춰서 이 편향을 보상해줘야 함. 중요한 경험이 더 자주 샘플링되기를 원하지만, 훈련 과정에서 이 샘플에 낮은 가중치를 주어야 한다는 의미
→ 각 경험의 훈련 가중치 를 정의
- n은 재생 버퍼에 있는 경험의 개수
- 는 중요도 샘플링 편향을 얼마나 보상할지 조정하는 하이퍼파라미터
- 저자들은 훈련 초기에 =0.4를 사용하고 훈련 마지막에는 1까지 선형적으로 증가시킴
- 최적의 값은 작업에 따라 다름. 둘 중 하나를 증가시키면 일반적으로 다른 값도 증가.
18.11.4 듀얼링 DQN
듀얼링 DQN(dueling DQN)
- 2015년 딥마인드 연구자들의 또 다른 논문에서 소개
알고리즘의 작동 방식을 이해하려면 상태-행동 (s,a) 쌍의 Q-가치가
처럼 표현될 수 있다는 것을 이해해야 함
- V(s) : 상태의 가치
- A(s,a) : 상태 s에서 다른 모든 가능한 행동과 비교하여 행동 a를 선택했을 때 이득(advantage)
- 상태의 가치는 이 상태에서 최선의 행동 의 Q-가치와 같음. 따라서 이고 이는 을 의미
듀얼링 DQN에서는 모델이 상태의 가치와 가능한 각 행동의 이익을 모두 추정함
최선의 행동은 이익이 0이기 때문에 모델이 예측한 모든 이익에서 모든 최대 이익을 뺌
더블 듀얼링 DQN을 만들고 우선 순위 기반 경험 재생과 연결할 수 있음.
일반적으로 많은 강화 학습 기법은 합칠 수 있고, 2017년 딥마인드가 소개한 논문의 저자들은 6개의 기법을 Rainbow라는 하나의 에이전트에 적용하여 최고 수준의 성능을 보임.
18.12 다른 강화 학습 알고리즘
알파고
심층 신경망에 기반한 몬테 카를로 트리 검색의 변형을 사용
몬테 카를로 트리 검색(Monte Carlo tree search, MCTS)
- 현재 위치에서 시작하여 탐색 트리를 반복적으로 탐색하고 가장 유망한 가지에 더 많은 시간을 할애하여 많은 시뮬레이션을 실행한 후 최상의 수를 선택
- 방문하지 않은 노드에 도달하면 게임이 끝날 때까지 랜덤하게 플레이
- 방문한 각 노드에 대한 추정치를 업데이트하여 최종 결과에 따라 각 추정치를 늘리거나 줄임
알파고는 동일한 원리를 기반으로하지만, 랜덤하게 수를 두는 대신 정책 네트워크를 사용하여 수를 선택하고, 정책 네트워크는 정책 그레이디언트를 사용하여 훈련
액터-크리틱
- 정책 그레이디언트와 심층 Q-네트워크를 결합한 강화 학습 알고리즘
- 정책 네트워크와 DQN 네트워크 두 개를 포함
DQN은 보통과 같이 훈련, 정책 네트워크는 일반적인 정책 그레이디언트와 다르게 훈련
여러 에피소드를 진행해서 각 행동의 가치를 추정하고 각 행동의 할인된 미래 보상을 합하여 정규화하는 대신 에이전트는 DQN이 추정한 행동 가치에 의존
A3C
A3C(asynchronous advantage actor-critic)
- 일정한 간격으로 하지만 비동기적으로 각 에이전트가 마스터 네트워크로 가중치 업데이트를 전송
- 네트워크에서 최신의 가중치를 받아옴
- 각 에이전트는 마스터 네트워크의 향상에 기여하면서 다른 에이전트가 학습한 것에서 혜택을 받음
- Q-가치를 추정하는 대신 안정적인 훈련을 위해 DQN이 각 행동의 이익을 추정
A2C
A2C(advantage actor-critic)
- 비동기성을 제거한 A3C 알고리즘의 변형
- 모든 모델이 동기적으로 업데이트
- GPU의 성능을 활용해 큰 배치에 대해 그레이디언트 업데이트를 수행
SAC
SAC(soft actor-critic)
- 액터-크리틱 변형
- 보상뿐만 아니라 행동의 엔트로피를 최대화하도록 훈련
- 환경을 탐색하여 훈련 속도를 높이고 DQN이 불완전한 추정을 만들 때 같은 행동을 반복실행하지 않도록 함
- 놀라운 샘플링 효율성
PPO
PPO(proximal policy optimization)
- 큰 가중치 업데이트를 피하기 위해 손실 함수를 클리핑하는 A2C기반 알고리즘
- OpenAI에서 제안한 TRPO(trust region policy optimization) 알고리즘의 간소화 버전
호기심 기반 탐색
호기심 기반 탐색(curiosity-based exploration)
- 강화 학습에서 계속 일어나는 문제는 보상의 희소성.
→ 학습을 느리고 비효율적이게 함. - 보상을 무시하고, 에이전트가 순수한 호기심만으로 환경을 탐색한다면, 보상은 환경에서 오는 것이 아니라 에이전트 자체의 성질이 됨.
- 에이전트는 끊임없이 자신의 행동의 결과를 예측하려고 시도하고, 결과가 예측과 맞지 않는 상황을 탐색
- 결과가 예측 가능하면 다른 곳으로 이동하고, 결과가 예측하지 못한 것이라면 에이전트는 이를 제어할 방법이 없다는 것을 인식함. 시간이 지나면 이 또한 예측이 가능해짐.
개방형 학습
개방형 학습(Open-ended learning, OEL)
- 차례대로 생성되는 새롭고 흥미로운 작업을 끊임없이 학습할 수 있는 에이전트를 훈련하는 것이 목표
POET 알고리즘
- 우버 AI 연구팀이 2019년 발표
- 여러 개의 시뮬레이션된 2D 환경을 생성하고 각 환경마다 하나의 에이전트를 훈련시키는 알고리즘
- 처음에는 간단한 환경으로 시작하지만 시간이 지남에 따라 점점 어려워짐. 이를 커리큘럼 학습(curriculum learning)이라고 함.
- 각 에이전트는 한 환경 내에서만 학습되지만, 다른 환경에 있는 모든 에이전트와 정기적으로 경쟁
- 승자는 복사되어 각 환경에서 이전에 있던 에이전트를 대체. 다른 환경에 지식이 정기적으로 이전되고 가장 적응력이 뛰어난 에이전트가 선택됨.
