1.1 머신러닝이란?
머신러닝 : 데이터에서 학습하도록 컴퓨터를 프로그래밍하는 과학
어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다.
training set : 학습하는데 사용하는 샘플
training instance / sample : 각각의 훈련 데이터
model : 학습하고 예측을 만드는 부분
1.2 왜 머신러닝을 사용하는가?
전통적인 프로그래밍 기법 : 어려운 문제에 대해 규칙이 점점 길고 복잡해지므로 유지보수하기가 매우 힘들다는 단점.
머신러닝 기법 : 자주 나타나는 패턴을 감지하여 자동으로 학습 → 프로그램이 훨씬 짧아지고, 유지 보수가 용이하고, 정확도가 높아짐.
data mining : 대용량의 데이터를 분석하여 숨겨진 패턴을 발견하는 것
머신러닝이 뛰어난 분야
- 기존 솔루션으로는 많은 수동 조정과 규칙이 필요한 문제
- 전통적인 방식으로는 해결 방법이 없는 복잡한 문제
- 유동적인 환경
- 복잡한 문제와 대량의 데이터에서 인사이트 얻기
1.3 애플리케이션 사례
- 이미지 분류
- 시맨틱 분할
- 자연어 처리 (natural language processing, NLP)
- 자연어 이해 (natural language understanding, NLU)
- 회귀 (regression)
- 음성 인식
- 이상치 탐지 (outlier detection)
- 군집 (clustering)
- 데이터 시각화
- 추천 시스템
- 강화 학습 (reinforcement learning, RL)
1.4 머신러닝 시스템의 종류
훈련 지도 방식에 따른 분류
지도 학습 (supervised learning)
알고리즘에 주입하는 훈련 데이터에 원하는 답(레이블)을 포함.
- 분류 (classification)
- 회귀 (regression) : 특성(feature)을 사용해 타깃(target) 수치를 예측
- 로지스틱 회귀 (logistic regression) : 클래스에 속할 확률 예측
비지도 학습 (unsupervised learning)
훈련 데이터에 레이블이 없음.
- 계층 군집 (hierarchical clustering) : top-down 방식인 분할 군집(divisive clustering)
- 시각화 (visualization)
- 차원 축소 (dimensionality reduction) / 특성 추출 (feature extraction) : 데이터를 주입하기 전에 차원의 수를 줄이는 것이 유용할 때가 많음. 속도의 향상 / 메모리 공간 확보 / 성능 향상 등..
- 이상치 탐지 (outlier detection) : 비정상적인 샘플 탐지
- 특이치 탐지 (novelty detection) : 훈련 세트에 있는 모든 샘플과 달라 보이는 새로운 샘플 탐지
- 연관 규칙 학습 (association rule learning) : 대량의 데이터에서 특성 간의 관계 탐지
준지도 학습 (semi-supervised learning)
레이블이 일부만 있는 상태.
대부분은 지도 학습과 비지도 학습의 조합으로 구성
ex)
1. 군집 알고리즘을 사용해 비슷한 샘플을 모으고,
2. 각 샘플에 레이블을 할당
3. 전체 데이터셋에 레이블이 부여되면 지도 학습 알고리즘 사용 가능
자기 지도 학습 (self-supervised learning)
레이블이 전혀 없는 데이터셋에서 레이블이 완전히 부여된 데이터셋을 생성하는 것.
자기 지도 학습은 훈련하는 동안 생성된 레이블을 사용하기 때문에 지도 학습에 더 가까움.
자기 지도 학습을 별개의 범주로 다루는 것이 가장 좋음.
강화 학습 (reinforcement learning)
agent : 학습하는 시스템
환경을 관찰해서 행동을 실행하고 그 결과로 보상 / 벌점을 받음.
정책(policy) : 가장 큰 보상을 얻기 위해 학습하는 최상의 전략. 주어진 상황에서 에이전트가 어떤 행동을 해야하는지 정의함.
배치 학습과 온라인 학습
배치 학습 (batch-learning)
한 번에 모든 훈련 데이터를 학습하는 방법
한 번에 모든 훈련 데이터를 학습 → 시간과 자원을 많이 소모 → 오프라인에서 수행
모델 부패 (model rot) / 데이터 드리프트 (data drift) : 오프라인 학습 모델의 성능이 시간이 지남에 따라 천천히 감소하는 현상.
새로운 데이터에 대해 학습하려면 전체 데이터를 사용하여 시스템의 새로운 버전을 처음부터 다시 훈련해야 함. 데이터를 필요한 만큼 자주 훈련시키는 방식으로 해결 가능.
→ 훈련하는 데 오랜 시간이 걸릴 수 있음. 많은 자원이 필요하고, 데이터의 양이 아주 많으면 알고리즘 사용이 불가능할 수도 있음. 자원이 제한된 시스템이나 빠르게 변화하는 시스템에 대한 예측에는 적합하지 않음.
온라인 학습
데이터를 순차적으로 한 개씩 또는 미니배치(mini-batch)라 부르는 작은 묶음 단위로 시스템을 훈련시키는 학습하는 방법
매 학습 단계가 빠르고 비용이 적게 들어서 데이터가 도착하는 대로 학습 할 수 있음.
컴퓨터 자원이 제한된 경우나 극도로 빠른 변화에 적응해야 하는 시스템(주식 시장 등)에 적합함.
학습률(learning rate) : 변화하는 데이터에 얼마나 빠르게 적응하는지에 대한 파라미터. 온라인 학습 시스템에서 중요
학습률 ↑ : 시스템이 데이터에 빠르게 적응하지만, 이전 데이터를 금방 잊어버림.
학습률 ↓ : 새로운 데이터에 있는 노이즈나 대표성 없는 데이터 포인트에 덜 민감해지지만, 더 느리게 학습됨.
데이터 품질(시스템에 나쁜 데이터가 주입)이나 학습률에 따라 시스템 성능이 빠르게 감소할 수 있다는 문제점을 가짐 → 성능 감소가 감지되면 즉각 학습을 중지시켜야함 (이상치 탐지 알고리즘 등)
사례 기반 학습과 모델 기반 학습
어떻게 일반화(generalization) 되는가에 따라 머신러닝 시스템을 분류할 수 있음.
일반화 : 새로운 샘플에 대해서도 좋은 예측을 만들어 내는 것
사례 기반 학습
훈련 샘플을 기억함으로써 학습하는 방법
새로운 데이터와 학습한 샘플을 비교하는 식으로 일반화
모델 기반 학습
샘플들의 모델을 만들어 예측에 사용하는 방법
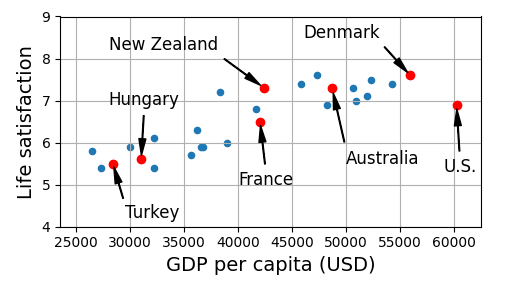
데이터가 선형으로 변화하는 경향을 보이니까, 1인당 GDP의 선형 함수로 삶의 만족도를 모델링하겠다!
→ 모델 선택(model selection) 단계에서 1인당 GDP라는 특성을 하나 가진 삶의 만족도에 대한 선형 모델(linear model)을 선택. 선형 모델은 다음과 같음.
모델 파라미터 (model parameter) : ,
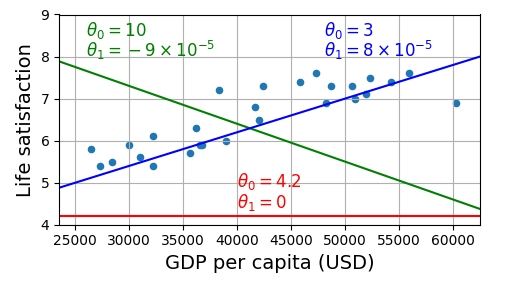
모델을 사용하기 전에 , 의 값을 정의해야 함 → 모델이 최상의 성능을 내도락하는 값은 어떻게 구할 수 있을까?
효용 함수 (utility function), 적합도 함수(fitness function) : 모델이 얼마나 좋은지 측정하는 함수
비용 함수 (cost function) : 모델이 얼마나 나쁜지 측정하는 함수
선형 회귀에서는 보통 선형 모델의 예측과 훈련 데이터 사이의 거리를 재는 비용 함수를 사용하고, 그 거리를 최소화하는 것을 목표로 함.
훈련 (training) : 알고리즘에 훈련 데이터를 공급하면서 데이터에 가장 잘 맞는 선형 모델의 파라미터를 찾는 과정
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 데이터 다운로드
data_root = "https://github.com/ageron/data/raw/main/"
lifesat = pd.read_csv(data_root + "lifesat/lifesat.csv")
X = lifesat[["GDP per capita (USD)"]].values
y = lifesat[["Life satisfaction"]].values
# 데이터를 그래프로 표현
lifesat.plot(kind='scatter', grid=True,
x="GDP per capita (USD)", y="Life satisfaction")
plt.axis([23_500, 62_500, 4, 9])
plt.show()
# 선형 모델 선택
model = LinearRegression()
# 모델 훈련
model.fit(X, y)
# 키프로스에 대한 예측
X_new = [[37_655.2]] # 2020년 키프로스 1인당 GDP
print(model.predict(X_new)) # 출력 [[6.30165767]]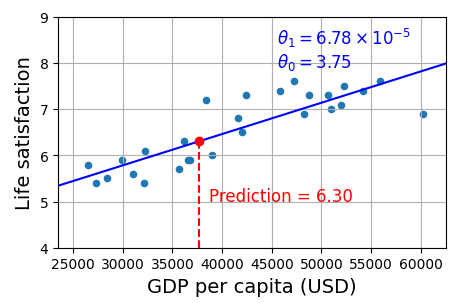
# 이전 코드의 선형 회귀 모델을 knn 회귀로 바꾸려면 참고
from sklearn.neighbors import KNeighborsRegressor
model = kNeighborsRegressor(n_neighbors=3)지금까지의 작업을 요약하면,
1. 데이터 분석
2. 모델 선택
3. 훈련 데이터로 모델 훈련
4. 추론
1.5 머신러닝의 주요 도전 과제
충분하지 않은 양의 훈련 데이터
머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 한다.
대표성 없는 훈련 데이터
일반화가 잘되려면 훈련 데이터가 일반화하고 싶은 새로운 사례를 잘 대표하는 것이 중요하다.
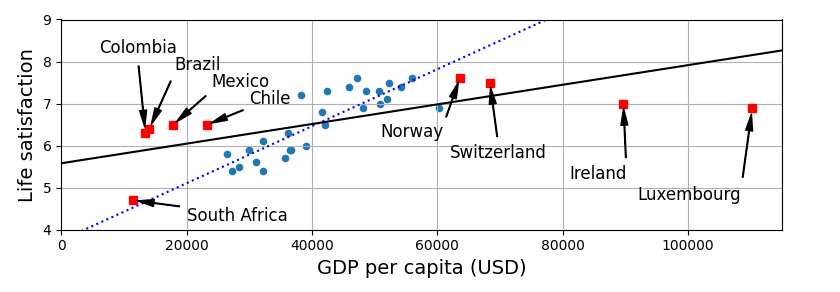
샘플링 잡음 (sampling noise) : 샘플이 작을 경우에 생기는, 우연에 의한 대표성 없는 데이터
샘플링 편향 (sampling bias) : 매우 큰 샘플에서 표본 추출 방법이 잘못되었을 때 발생하는, 대표성을 나타내지 못하는 현상
낮은 품질의 데이터
훈련 데이터 정제에 시간을 투자할 만한 가치는 충분하다.
훈련 데이터가 오류, 이상치, 잡음으로 가득하다면 제대로 작동하지 않음.
다음의 경우 훈련 데이터 정제가 필요함.
- 일부 샘플이 이상치라는게 명확하면, 해당 샘플들을 무시하거나 수동으로 잘못된 것을 고치는 것이 좋다.
- 일부 샘플에 특성 몇 개가 빠져있다면 이 특성을 모두 무시할지, 이 샘플을 무시할지, 빠진 값을 채울지, 또는 이 특성을 넣은 모델과 제외한 모델을 따로 훈련시킬 것인지 결정해야 한다.
관련없는 특성
garbage in, garbage out
특성 공학 (feature engineering) : 훈련에 사용할 좋은 특성들을 찾는 것. 성공적인 머신러닝 프로젝트의 핵심 요소
- 특성 선택 (feature selection) : 훈련에 가장 유용한 특성을 선택
- 특성 추출 (feature extraction) : 특성을 결합하여 더 유용한 특성을 생성
- 데이터 수집 : 새로운 데이터를 수집하여 새 특성을 생성
훈련 데이터 과대적합
과도한 일반화는 기계도 함정에 빠지게 한다.
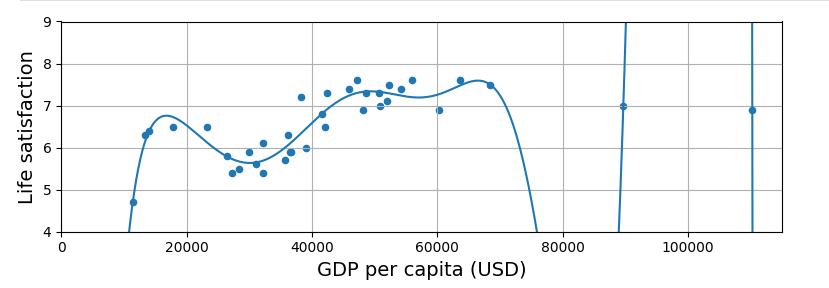
과대적합 (overfitting) : 훈련 데이터에는 너무 잘 맞지만 일반성이 떨어지는 상태
과대적합의 해결 방법
- 파라미터 수가 적은 모델 선택, 훈련 데이터에 있는 특성 수 줄이기, 모델에 제약을 가하여 단순화하기
- 훈련 데이터를 더 많이 모으기
- 훈련 데이터의 잡음 줄이기 (오류 데이터 수정, 이상치 제거)
규제 (regularization) : 모델을 단순하게 하고 과대적합의 위험을 줄이기 위해 모델에 제약을 가하는 것
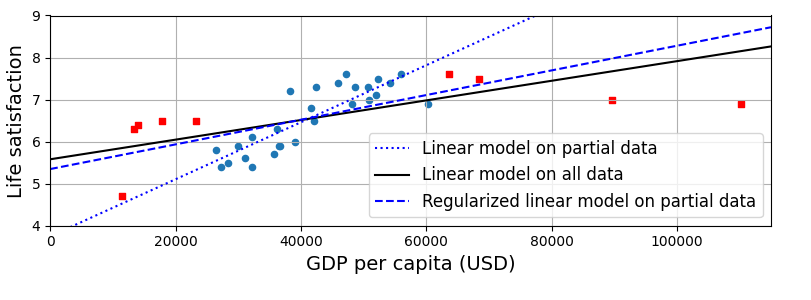
하이퍼파라미터 (hyperparameter) : 학습하는 동안 적용할 규제의 양.
모델이 아닌 학습 알고리즘의 파라미터이기 때문에 학습 알고리즘으로부터 영향을 받지 않으며, 훈련 전에 미리 지정되고, 훈련하는 동안에는 상수로 남아있음.
하이퍼파라미터 튜닝은 머신러닝 시스템 구축에서 매우 중요한 과정이다.
훈련 데이터 과소적합
과소적합 (underfitting) : 과대적합의 반대
모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생.
과소적합의 해결 방법
- 모델 파라미터가 더 많은 강력한 모델 선택
- 학습 알고리즘에 더 좋은 특성 제공 (feature engineering)
- 모델의 제약 감소 (하이퍼파라미터 감소)
핵심 요약
- 머신러닝 : 기계가 데이터로부터 학습하여 어떤 작업을 더 잘하도록 만드는 것
- 지도 학습, 비지도 학습, 배치 학습, 온라인 학습, 사례 기반 학습, 모델 기반 학습
- 모델 기반 학습 : 훈련 세트에 모델을 맞춤
- 사례 기반 학습 : 샘플을 기억하는 것이 학습, 유사도 측정을 사용하여 학습한 샘플과 새로운 샘플을 비교하여 일반화
- garbage in, garbage out / underfitting / overfitting
1.6 테스트와 검증
훈련 데이터를 훈련 세트와 테스트 세트로 분리
훈련 세트를 사용해 모델을 훈련하고 테스트 세트를 사용해 모델을 테스트
일반화 오차 (generalization error) : 외부 샘플 오차(out-of-sample error). 새로운 샘플에 대한 오차 비율
테스트 세트에서 모델을 평가함으로써 오차에 대한 추정값을 얻을 수 있음. 이 추정값은 이전에 본 적이 없는 새로운 샘플에 모델이 얼마나 잘 작동할지 알려줌.
훈련 오차가 작지만, 일반화 오차가 크다면 이는 모델이 훈련 데이터에 overfitting 되었다는 의미
하이퍼파라미터 튜닝과 모델 선택
일반화 오차를 테스트 세트에서 여러 번 측정하면, 모델과 하이퍼파라미터가 테스트 세트에 최적화된 모델을 만드는 문제가 발생함. 이 경우 새로운 데이터에 잘 작동하지 않을 수 있음.
홀드아웃 검증 (holdout validation)
훈련 세트의 일부를 떼어내어 여러 후보 모델을 평가하고 가장 좋은 하나를 선택하여 검증 세트 (validation set)로 결정.
줄어든 훈련 세트 (전체 훈련 세트 - 검증 세트)에서 다양한 하이퍼파라미터 값을 가진 여러 모델을 훈련하고, 검증 세트에서 가장 높은 성능을 내는 모델을 선택.
홀드아웃 검증 과정이 끝나면 최선의 모델을 전체 훈련 세트 (검증 세트 포함)에서 다시 훈련하여 최종 모델을 생성.
마지막으로 최종 모델을 테스트 세트에서 평가하여 일반화 오차를 추정.
일반적으로는 홀드아웃 검증이 잘 작동하지만, 검증 세트가 너무 작으면 모델이 정확하게 평가되지 않을 수 있다는 문제점이 있음.
교차 검증 (cross-validation)
작은 검증 세트를 여러 개를 사용해 반복적인 교차 검증을 수행함으로써 홀드아웃 검증의 문제점을 해결할 수 있음.
모든 모델의 평가를 평균하면 훨씬 정확한 성능을 측정할 수 있지만, 훈련 시간이 검증 세트의 개수에 비례해 늘어난다는 단점도 있음.
데이터 불일치
검증 세트와 테스트 세트가 실전에서 기대하는 데이터를 가능한 한 잘 대표해야 한다.
훈련-개발 세트 (train-dev set) : 훈련 세트의 일부를 떼어내 만든 또 다른 세트
모델을 훈련 세트에서 훈련하고, 훈련-개발 세트에서 평가했을 때 잘 작동하지 않으면 훈련 세트에 과대적합 → 모델을 규제하거나, 더 많은 데이터를 모으거나 훈련 데이터 정제를 시도
잘 작동했다면 검증 세트에서 평가 → 검증 세트에서도 잘 작동한다면 테스트 세트에서 평가하여 제품에 사용될 때 얼마나 잘 작동할지 알 수 있음.
훈련 세트 → 훈련-개발 세트 → 검증 세트 → 테스트 세트
