케라스의 전처리 층
케라스는 강력하면서도 사용하기 쉬운 전처리 층을 제공함
케라스의 전처리 층 사용 시,
- 전처리 코드를 추가할 필요 없이 원시 데이터를 직접 주입할 수 있음
- 훈련 중에 사용된 전처리 코드와 제품 환경에서 사용된 전처리 코드가 달라서 생기는 위험을 제거
- 다른 프로그래밍 언어로 코딩된 앱에 모델을 배포할 경우 동일한 전처리 코드를 구현할 필요가 사라짐
13.1 데이터 API
tf.data
대용량 데이터셋에서 텐서플로 모델을 훈련할 때는 자체 데이터 로드 및 전처리 API인 tf.data를 사용하는 것이 좋음
- 효율적으로 데이터를 로드/전처리
- 멀티스레드와 큐를 사용하여 여러 파일에서 동시에 읽고, 샘플을 셔플링하거나 배치로 만드는 등의 작업 가능
- GPU/TPU가 데이터 배치를 처리하는 동시에 여러 CPU 코어에서 다음 데이터 배치를 로드하고 전처리
- 메모리보다 큰 데이터셋 처리 가능 + 하드웨어 리소스 최대 활용 → 훈련 속도 향상
tf.data API가 읽을 수 있는 데이터
- 텍스트 파일 (CSV 파일)
- 고정 길이 레코드를 가진 이진 파일
- TFRecord 포맷의 이진 파일
13.1.1 연쇄 변환
데이터셋이 준비되면 변환 메서드를 호출하여 여러 종류의 변환을 수행할 수 있음
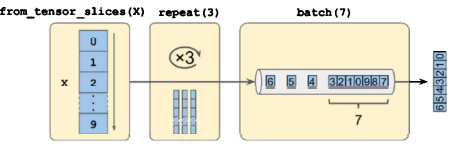
- repeat() : 원본 데이터셋의 아이템을 반복하는 새로운 데이터셋 반환
- batch() : 다시 새로운 데이터셋이 만들어짐
- 마지막 데이터셋의 아이템을 순회(나머지).
drop_remainder=True로 호출하면 마지막 나머지 배치를 버리고 모든 배치를 동일한 크기로 맞춤 - map() : 아이템을 변환할 때 사용. 데이터에 전처리 작업 적용할 수 있음.
- filter() : 조건을 설정하여 데이터셋을 필터링
- take(n) : 데이터셋에 있는 n개의 아이템만 보고 싶을 때 사용
13.1.2 데이터 셔플링
경사 하강법은 훈련 세트에 있는 샘플이 독립적이고 동일한 분포일 때 최고의 성능을 보임
→ shuffle() 을 사용하여 샘플을 섞어서 구현
랜덤 시드를 부여하여 셔플링되는 순서를 프로그램 실행때마다 동일하게 만들 수 있음
메모리 용량보다 큰 대규모 데이터셋은 간단한 셔플링 버퍼 방식으로는 충분하지 않음
→ 원본 데이터 자체를 섞음으로써 해결할 수 있음. 셔플링 효과가 크게 향상.
원본 데이터가 섞여 있더라도 epoch마다 한 번 더 섞어주면, epoch마다 동일한 순서가 반복되어 모델에 편향이 추가되는 것을 방지할 수 있음.
13.1.3 여러 파일에서 한 줄씩 번갈아 읽기
파일 여러 개를 랜덤으로 선택하고 파일에서 동시에 읽은 레코드를 돌아가면서 반환한 뒤, shuffle()을 사용해 셔플링 버퍼를 추가하면 효과를 극대화 할 수 있음.
이를 위해서는 여러 파일에서 한 줄씩 번갈아 읽는 기능을 구현해야 함.
train_filepaths # 훈련 파일 경로를 담은 리스트
filepath_dataset = tf.data.Dataset.list_files(train_filepaths, seed=42)
n_readers=5
dataset = filepath_dataset.interleaver(
# 각 파일의 첫 번째 줄은 열 이름이므로 skip(1)
lambda filepath: tf.data.TextLineDataset(filepath).skip(1),
cycle_length=n_readers)interleave()
- 한 번에 여러 개의 파일을 한 줄씩 번갈아 읽을 수 있음
- 위의 예제 코드에서는 filepath_dataset에 있는 5개의 파일 경로에서 데이터를 읽는 데이터셋을 생성함
- 인터리빙(interleaving)이 잘 작동하려면 파일의 길이가 동일한 것이 좋음
13.1.4 데이터 전처리
※ 데이터셋으로는 '캘리포니아 주택 데이터셋'을 활용함
주택 데이터셋에는 바이트 문자열이 담긴 텐서가 있으므로, 문자열을 파싱하고 데이터 스케일을 조정하는 등의 전처리 작업이 필요함
X_mean, X_std = [...] # 훈련세트의 각 특성의 평균과 표준편차
n_inputs = 8
def parse_csv_line(line):
defs = [0.] * n_inputs + [tf.constant([], dtype=tf.float32)]
fields = tf.io.decode_csv(line, record_defaults=defs)
return tf.stack(fields[:-1]), tf.stack(fields[-1:])
def preprocess(line):
x, y = parse_csv_line(line)
return (x - X_mean) / X_std, y- X_mean과 X_std는 특성마다 1개씩 8개의 실수를 가진 1D 텐서
- parse_csv_line () : CSV 한 라인을 받아 파싱
- tf.io.decode_scv() : 열마다 한 개씩 스칼라 텐서의 리스트를 반환
- preprocess() : parse_csv_line() 함수 호출, 입력 특성에서 평균을 빼고 표준 편차로 나누어 스케일 조정
13.1.5 데이터 적재와 전처리 합치기
지금까지 작성한 함수들을 캘리포니아 주택 데이터셋을 효율적으로 적재하고 전처리, 셔플링, 배치를 적용한 데이터셋을 만들어 반환하는 함수 하나로 작성
def csv_reader_dataset(filepaths, n_readers=5, n_read_threads=None,
n_parse_threads=5, shuffle_buffer_size=10_000, seed=42,
batch_size=32):
dataset = tf.data.Dataset.list_files(filepaths, seed=seed)
dataset = dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1)
cycle_length=n_readers, num_parallel_calls=n_read_threads)
dataset = dataset.map(preprocess, num_parellel_calls=n_parse_threads)
dataset = dataset.shuffle(shuffle_buffer_size, seed=seed)
return dataset.batch(batch_size).prefetch(1)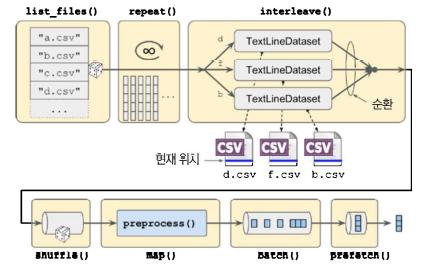
13.1.6 프리페치
csv_reader_dataset() 함수의 마지막에 prefetch(1)을 호출하면 데이터셋은 항상 하나의 배치가 미리 준비되도록함
- 훈련 알고리즘이 한 배치로 작업을 하는 동안 데이터셋이 동시에 다음 배치를 준비함
- 멀티스레드로 데이터를 적재하고 전처리하면 짧은 시간 안에 하나의 배치 데이터를 준비할 수 있음
→ GPU를 100% 활용할 수 있어서 훈련 속도가 더 빨라짐(성능 향상)
13.1.7 케라스와 데이터셋 사용하기
csv_reader_dataset() 함수로 훈련 세트, 검증 세트, 테스트 세트를 위한 데이터셋을 생성하고, 케라스 모델을 만들어 이 데이터셋으로 훈련할 수 있음
13.2 TFRecord 포맷
- 대용량 데이터를 저장하고 효율적으로 읽기 위해 텐서플로가 선호하는 포맷.
- 크기가 다른 연속된 이진 레코드를 저장하는 단순한 이진 포맷
13.2.1 압축된 TFRecord 파일
- 네트워크를 통해 읽어야 하는 경우 TFRecord 파일을 압축할 필요가 있음
- options 매개변수를 사용하여 압축된 TFRecord 파일 생성 가능
13.2.2 프로토콜 버퍼 개요
- 일반적으로 TFRecord는 직렬화된 프로토콜 버퍼를 담고 있음
- 프로토콜 버퍼 정의만 제공하면 tf.io.decode_proto() 함수를 사용하여 어떤 프로토콜 버퍼도 파싱 가능함
13.2.3 텐서플로 프로토콜 버퍼
- TFRecord 파일에서 사용하는 전형적인 주요 프로토콜 버퍼는 Example 프로토콜 버퍼
- Example 프로토콜 버퍼는 이름을 가진 특성의 리스트를 가지고 있고, 각 특성은 바이트 문자열 리스트 / 실수 리스트 / 정수 리스트 중 하나
13.2.4 Example 프로토콜 버퍼 읽고 파싱하기
- 직렬화된 Example 프로토콜 버퍼를 읽기 위해서는 tf.data.TFRecordDataset 사용
- tf.io.parse_single_example() 으로 각 Example 파싱. 이 함수에는 2개의 매개변수(직렬화된 데이터를 담은 문자열 스칼라 텐서 / 각 특성에 대한 설명)가 필요함.
- Example 프로토콜 버퍼는 매우 유연하지만, 리스트의 리스트를 다룰 때는 사용하기 어려움
13.2.5 SequenceExample 프로토콜 버퍼로 리스트의 리스트 다루기
- SequenceExample은 문맥 데이터를 위한 하나의 Features 객체와 이름이 있는 한 개 이상의 FeatureList를 가진 FeatureLists 객체를 포함
- SequenceExample을 만들고, 직렬화하고, 파싱하는 것은 Example을 다루는 것과 비슷함
- 하지만 하나의 SequenceExample을 파싱하려면 tf.io.parse_single_sequence_example()을 사용하고, 배치를 파싱하려면 tf.io.parse_sequence_example()을 사용해야 함
13.3 케라스의 전처리 층
신경망에 사용할 데이터를 준비하기 위해 전처리 하는 방법에는 여러가지가 있음
- 훈련 데이터 파일을 준비할 때, numpy, pandas, scikit-learn과 같은 도구를 사용하여 미리 전처리 수행
- 데이터셋의 map() 메서드를 사용하여 데이터셋의 모든 원소에 전처리 함수를 적용한 후, tf.data로 데이터를 로드하는 동안 바로 전처리 수행
- 모델 내부에 전처리 층을 직접 포함시켜 훈련 중에 즉시 모든 입력 데이터에 대한 전처리 수행
13.3.1 Normalization 층
Normalization 층에서는 입력 특성을 표준화할 수 있음
층을 생성할 때 각 특성의 평균과 분산을 지정하거나 / adapt() 메서드에 훈련 세트를 전달하여 특성의 평균과 분산을 계산함
모델에 Normalization 층 을 추가하면,
+) 모델이 정규화를 알아서 처리하고, 전처리 불일치 위험(훈련과 제품에 사용하는 전처리 코드를 별도로 유지하다가 제대로 업데이트가 되지 않는 문제)을 완전히 제거함
-) 전처리가 훈련하는 동안 즉시 적용되기 때문에 epoch마다 매번 수행하게 되어 훈련 속도가 느려짐
모델과 Normalization 층을 독립적으로 사용하면,
+) 전처리를 한 번만 수행하여 훈련 속도가 빨라짐
-) 모델을 제품에 배포했을 때 입력을 전처리하지 못함
→ Normalization 층과 훈련된 모델을 포함하는 새로운 모델을 만들고, 최종 모델을 제품에 배포
- 훈련 전에 데이터를 한 번만 전처리하기 때문에 훈련 속도 빠름
- 최종 모델이 입력 데이터를 바로 전처리 할 수 있어 전처리 불일치 위험 없음
13.3.2 Discretization 층
Discretization 층에서는 값 범위를 범주로 매핑하여 수치 특성을 범주형 특성으로 변환
다중모드(multimodal) 분포를 가진 특성이나 타깃과의 관계가 매우 비선형적인 특성에 유용함
- 원하는 구간 경계를 명시하거나
- 원하는 구간 개수를 전달하고 adapt() 메서드를 통해 적절한 구간 경계를 찾게 만드는 방법 사용할 수 있음
범주 식별자는 원-핫 인코딩을 사용해 인코딩하고, 신경망으로 주입해야 함
13.3.3 CategoryEncoding 층
범주의 개수가 적다면 원-핫 인코딩은 좋은 옵션. CategoryEncoding은 이를 제공함
동시에 한 개 이상의 범주형 특성을 인코딩하면 CategoryEncoding 클래스는 기본적으로 멀티-핫 인코딩 수행. 입력 특성에 있는 범주에 해당하는 위치마다 출력 텐서의 값이 1이 됨.
멀티-핫 인코딩과 카운트 인코딩은 범주를 활성화한 특성이 어떤 것인지 알 수 없기 때문에 정보에 손실이 있음
→ 특성마다 별도로 원-핫 인코딩을 한 다음 출력을 합치면, 범주 식별자가 겹치지 않도록 조정할 수 있음
멀티-핫 인코딩 / 특성별 원-핫 인코딩이 더 나을지는 미리 알기 어려움. 두 방식을 모두 테스트하여 비교해보아야 함.
13.3.4 StringLookup 층
StringLookup 층에서는 텍스트로 된 범주형 특성을 다룸
StringLookup 층을 만들 때 output_mode="one_hot"으로 지정하면 정수대신 원-핫 벡터 출력
훈련 세트가 매우 크면 랜덤하게 일부를 추출하여 adapt() 에 전달하는 것이 편리
이 경우, adapt() 는 등장 빈도가 낮은 범주를 모두 0으로 매핑하기 때문에 모델이 구별할 수 X
→ num_oov_indices를 1보다 큰 정수로 지정하여 이런 위험을 줄일 수 있음
= OOV(out-of-vocabulary) 버킷 개수를 지정하는 것. 알 수 없는 범주는 해시 함수를 사용해 OOV 버킷 중 하나로 랜덤하게 매핑
해싱 충돌
cities = ["Auckland", "Paris", "Paris", "San Francisco"]
str_lookup_layer = tf.keras.layers.StringLookup(num_oov_indices=5)
str_lookup_layer.adapt(cities)
str_lookup_layer([["Paris"], ["Auckland"], ["Foo"], ["Bar"], ["Baz"]])
# <tf.Tensor: shape(4, 1), dtype=int64, numpy=array([[5], [7], [4], [3], [4]])>- OOV 버킷의 개수를 5개로 지정하여, 이미 알려진 범주인 Paris의 ID는 5
- Foo, Bar, Baz는 알 수 없는 범주이므로 OOV 버킷 중 하나에 매핑
- Bar는 ID=3에 매핑되었으나, Foo와 Baz는 같은 버킷인 ID=4에 매핑되어 구분할 수 없어짐 → 해싱 충돌(hasing collision)
해싱 충돌의 위험을 줄이는 유일한 방법은 OOV 버킷 수를 늘리는 것
- 범주의 전체 개수가 늘어가서 필요한 메모리가 늘어남
- 범주마다 원-핫 인코딩되기 때문에 모델 파라미터도 증가
- 너무 많이 늘려서는 안됨
13.3.5 Hashing 층
해싱 트릭 : 범주를 랜덤하게 버킷에 매핑하는 아이디어
케라스에는 해싱 트릭을 위한 전용 Hasing 층이 존재함
여기에서도 해싱 충돌이 발생하기 때문에 일반적으로는 StringLookup 층을 사용
13.3.6 임베딩을 사용해 범주형 특성 인코딩
임베딩(Embedding)
- 범주나 어휘 사전의 단어와 같은 고차원 데이터의 밀집 표현. 원-핫 인코딩과 비교했을 때 상대적으로 작은 밀집 벡터.
- 일반적으로 랜덤하게 초기화
- 다른 모델 파라미터와 함께 경사 하강법으로 훈련
표현 학습(representation learning)
- 임베딩을 훈련할 수 있기 때문에 훈련 도중에 점차 향상됨
- 비슷한 범주들은 경사 하강법이 더 가깝게 만들고, 표현이 좋을수록 신경망이 정확한 예측을 만들기 쉬움
- 범주가 유용하게 표현되도록 임베딩이 훈련되는 경향이 존재함. 이를 표현 학습 이라고 함.
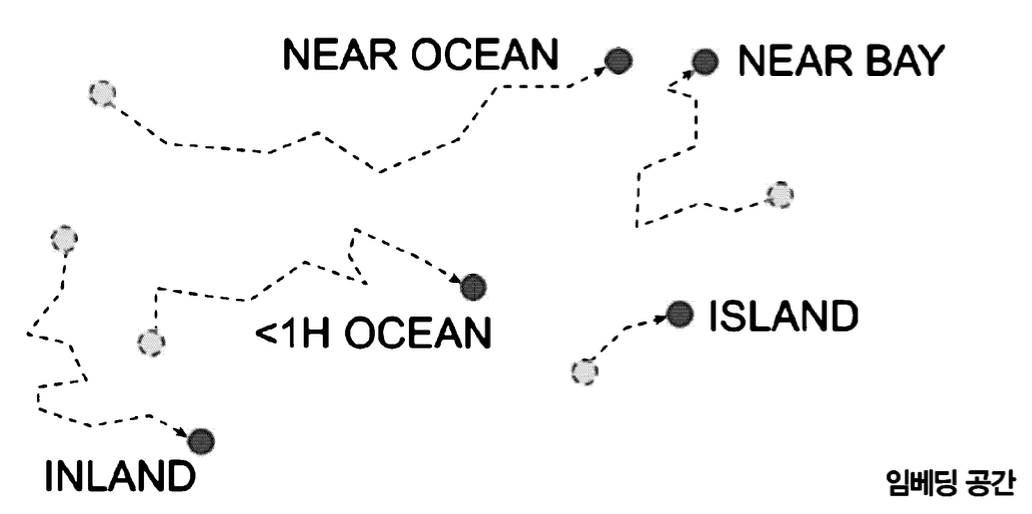
임베딩 행렬은
- 범주마다 하나의 행을, 임베딩 차원마다 하나의 열을 가짐
- 기본적으로 랜덤 초기화
케라스는 임베딩 행렬을 감싼 Embedding 층을 제공
범주 ID를 임베딩으로 변환하기 위해 Embedding 층이 범주에 해당하는 행을 찾아 반환함
지금까지 설명한 층들을 사용하여 일반적인 수치 특성과 함께 범주형 텍스트 특성을 처리하고, 각 범주를 위한 임베딩을 학습하는 케라스 모델 예제
X_train_num, X_train_cat, y_train = [...] # 훈련세트 로드
X_valid_num, X_valid_cat, y_valid = [...] # 검증세트 로드
num_input = tf.keras.layers.Input(shape=[8], name="num")
cat_input = tf.keras.layers.Input(shape=[], dtype=tf.string, name="cat")
cat_embeddings = lookup_and_embed(cat_input)
encoded_inputs = tf.keras.layers.concatenate([num_input, cat_embeddings])
outputs = tf.keras.layers.Dense(1)(encoded_inputs)
model = tf.keras.models.Model(inputs=[num_input, cat_input], outputs=[outputs])
model.compile(loss="mse", optimizer="sgd")
history = model.fit((X_train_num, X_train_cat), y_train, epochs=5,
validation_data=((X_valid_num, X_valid_cat), y_valid))- 두 개의 입력
- num_input : 샘플마다 8개의 수치 특성
- cat_input : 샘플마다 1개의 범주형 텍스트 특성
- lookup_and_embed : 해안 근접성 범주를 훈련 가능한 임베딩으로 인코딩하는 모델
- concatenate() : 수치 입력과 임베딩을 연결하여 완전히 인코딩된 입력 생성
- 하나의 밀집 출력 층을 추가하여 간단히 함
- 정의한 입력과 출력으로 케라스 모델 생성
- 모델을 컴파일하고 수치 입력과 범주형 입력을 모두 전달해 훈련
단어 임베딩 (word embedding)
자연어 처리 작업을 수행할 때 직접 단어 임베딩을 훈련하는 것보다 사전 훈련된 임베딩을 재사용하는 것이 좋은 경우가 많음
비슷한 말은 임베딩이 매우 비슷하고, France / Spain / Italy 같이 관련(국가명)된 단어들은 함께 군집을 형성
단어 임베딩은 어떤 의미를 가진 축을 따라 임베딩 공간 안에서 조직됨
단어의 인베딩 벡터를 더하고 뺄 수 있음
-
예시 1 ) King - Man + Woman 계산
- 결괏값은 Queen 단어의 임베딩과 매우 가까움.
- 단어 임베딩이 성별의 개념을 인코딩 한 것
-
예시 2 ) Madrid - Spain + France 계산
- 결괏값은 Paris 단어의 임베딩과 매우 가까움.
- 단어 임베딩이 국가 수도의 개념을 인코딩 한 것
하지만, 단어 임베딩은 크게 편향되는 경우가 있음
13.3.7 텍스트 전처리
TextVectorization층에서는 기본적인 텍스트 전처리를 할 수 있음
층을 생성할 때 vocabulary 매개변수로 어휘 사전을 전달하거나, adapt() 메서드를 사용해 훈련 데이터로부터 어휘 사전을 학습할 수 있음
train_data = ["To be", "!(to be)", "That's the question", "Be, be, be."]
text_vec_layer = tf.keras.layers.TextVectorization()
text_vec_layer.adapt(train_data)
text_vec_layer(["Be good!", "Question: be or be?"])
<tf.Tensor: shape=(2, 4), dtype=int64, numpy=
# array([[2, 1, 0, 0],
# [6, 2, 1, 2]])>- 어휘 사전을 구성하기 위해 adapt()는 먼저 텍스트를 소문자로 바꾸고, 구두점을 삭제
→ Be, be, be? 가 모두 2로 인코딩 - 문장을 공백으로 나누고 만들어진 단어를 빈도에 따라 정렬하여 최종 어휘 사전 생성
- 알 수 없는 단어는 1로 인코딩
- 첫 번째 문장이 두 번째 문장보다 짧아서 9으로 패딩
대소문자와 구두점을 유지하거나, 문장 분할을 막으려면 옵션을 설정할 수 있음
to, the와 같은 단어는 너무 자주 등장해서 중요성이 떨어지는 반면, basketball과 같이 드물게 나타나는 단어는 많은 정보를 가짐 → output_mode="tf_idf"로 설정
TF-IDF
- term-frequency inverse-document-frequency
- 훈련 데이터에 자주 등장하는 단어의 가중치를 줄이고, 드물게 등장하는 단어의 가중치를 높임
- 알 수 없는 단어에는 평균 가중치를 사용
- 공백으로 단어가 구분되는 언어에만 사용할 수 있고, 동음이의어를 구별하지 못함
- "evolution"과 "evolutionary" 같은 단어의 관계에 대한 힌트를 모델에게 주지 못함
텐서플로 텍스트 라이브러리를 사용하면 텍스트를 단어보다 작은 토큰(token)으로 분할할 수 있는 부분 단어 토크나이저(subword tokenizer)를 제공
→ TextVectorization 보다 높은 기능 수행
13.3.8 사전 훈련된 언어 모델 구성 요소 사용하기
텐서플로 허브 라이브러리를 사용하면 텍스트, 이미지, 오디오 등을 위해 사전 훈련된 모델의 구성요소를 쉽게 재사용할 수 있음. 이러한 모델의 구성 요소를 모듈이라고 함.
문장 인코더
- 문자열을 입력으로 받아 하나의 벡터로 인코딩
- 내부적으로 문자열을 파싱하고 대규모 말뭉치(corpus)에서 사전 훈련된 임베딩 행렬을 사용해 각 단어를 임베딩
- 모든 단어 임베딩의 평균을 계산하면 그 결과가 문장 임베딩
13.3.9 이미지 전처리 층
케라스 전처리 API에는 3개의 이미지 전처리 층이 포함
- tf.keras.layers.Resizing : 입력 이미지를 원하는 크기로 변환
- tf.keras.layers.Rescaling : 픽셀값의 스케일을 0~255에서 -1~1으로 변환
- tf.keras.layers.CenterCrop : 원하는 높이와 너비의 중간 부분만 유지하면서 이미지를 자름
데이터 증식 : 인공적으로 훈련 세트의 크기를 증가시켜 변형된 이미지가 증식되지 않은 실제 이미지처럼 보이는 한 성능을 향상시킴
13.4 텐서플로 데이터셋 프로젝트
import tensorflow_datasets as tfds
dataset = tfds.load(name="mnist")
mnist_train, mnist_test = dataset["train"], dataset["test"] - MNIST 데이터셋 다운로드
for batch in mnist_train.shuffle(10_000, seed=42).batch(32).prefetch(1):
images = batch["image"]
labels = batch["label"]
# [...] images와 labels로 필요한 작업 수행- 원하는 변환(셔플링, 배치 분할, 프리페칭)을 적용해 모델을 훈련하기 위한 준비하는 예시코드
train_set, valid_set, test_set = tfds.load(
name="mnist",
split=["train[:90%]", "train[90%:]", "test"],
as_supervised=True
)
train_set = train_set.shuffle(buffer_size=10_000, seed=42).batch(32).prefetch(1)
valid_set = valid_set.batch(32).cache()
test_set = test_set.batch(32)cache()
tf.random.set_seed(42)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",
metrics=["accuracy"])
history = model.fit(train_set, validation_data=valid_set, epochs=5)
test_loss, test_accuracy = model.evaluate(test_set)- TFDS는 split 매개변수를 통해 데이터를 간편하게 분할할 수 있음
- 훈련 세트의 첫 90%는 훈련에, 나머지 10%는 검증에, 테스트 세트는 모두 테스트에 사용
- TFDS를 사용하여 MNIST 데이터를 로드하고 분할하여 이를 사용한 케라스 모델을 훈련하고 평가하는 완전예제
