차원의 저주 : 훈련 샘플이 너무 커서 훈련을 느리게하고, 좋은 솔루션을 찾기 어렵게 만드는 것
실전에서는 특성 수를 크게 줄여서 문제를 해결 가능한 범위로 변경하는 방법으로 해결함
차원 축소의 효과
-
잡음이나 불필요한 사항을 걸러내기 때문에 성능이 높아질 수도 있다. 일반적으로는 '훈련 속도'만 빨라지는 경우가 많다.
-
데이터 시각화에도 유용하다. 보이지 않던 패턴을 감지해 중요한 인사이트를 얻을 수 있다.
차원을 축소시키면 일부 데이터가 유실된다. 따라서 훈련 속도가 빨라질 수는 있지만 성능이 조금 나빠질 수 있다. 또한, 작업 파이프라인이 조금 복잡해지고 유지 관리가 어려워진다. 그렇기 때문에 먼저 원본 데이터로 시스템을 훈련하는 것을 권장한다.
8.1 차원의 저주
고차원 데이터셋은 저차원일 때보다 예측이 더 불안정.
훈련 세트의 차원이 클수록 과대적합 위험이 커짐.
8.2 차원 축소를 위한 접근법
8.2.1 투영
대부분의 훈련 샘플은 모든 차원에 걸쳐 균일하게 퍼져있지 않음.
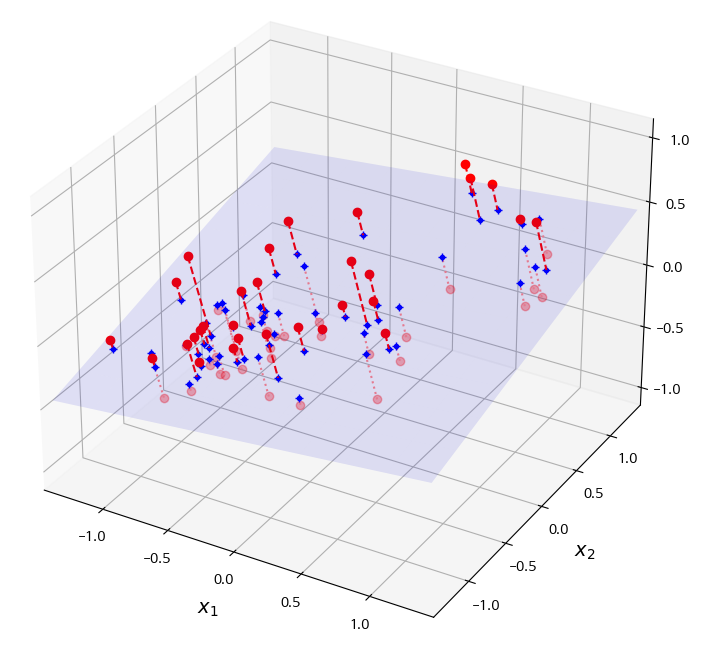
- 다음과 같이 고차원 공간 안의 저차원 부분 공간(subspace)에 놓여있는 경우가 있음
- 모든 훈련 샘플이 거의 평면 형태
- 고차원(3D) 공간에 있는 저차원(2D) 부분 공간
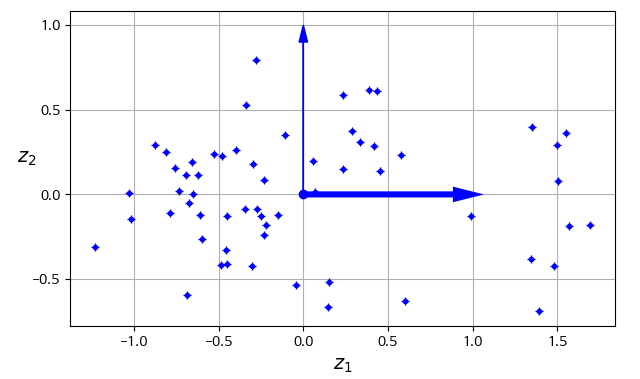
- 위의 데이터셋에서 훈련 샘플을 부분 공간에 수직으로 투영하여 얻은 2D 데이터셋
- 차원을 3D에서 2D로 감소
- 각 축은 새로운 특성 z1, z2에 대응
 |  |
|---|
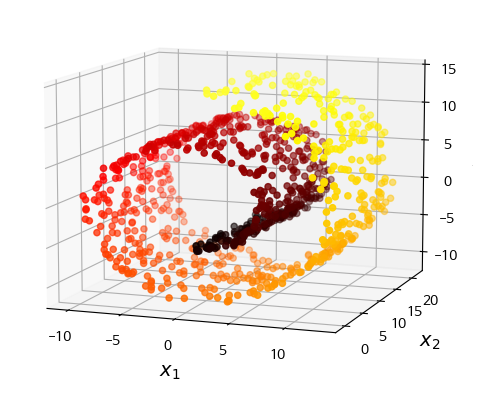
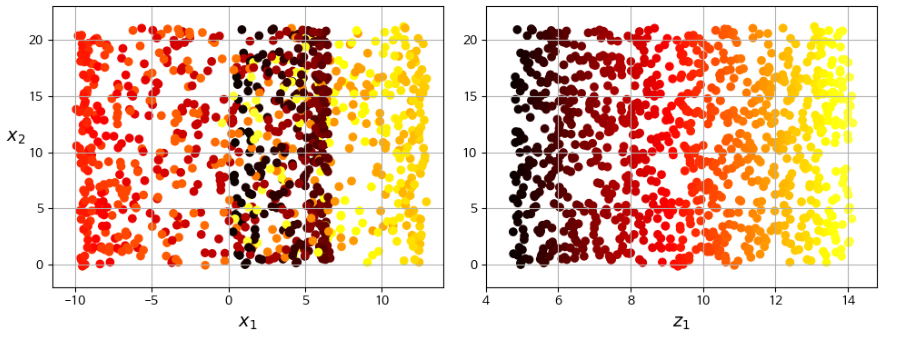
- 스위스롤 데이터셋처럼 부분 공간이 뒤틀리거나 휘어있기도 함
- 이 경우 그냥 평면에 투영시키면 층이 서로 뭉개져버림
- 가장 오른쪽처럼 스위스롤을 펼쳐서 오른쪽처럼 2D 데이터셋을 얻고 싶을땐 투영 사용이 어려움
8.2.2 매니폴드 학습
d차원 매니폴드는 d차원 초평면(hyperplane)으로 보일 수 있는 n차원 공간의 일부
스위스 롤의 경우에는 d=2, n=3
매니폴드 학습 : 훈련 샘플이 놓여 있는 매니폴드(manifold)를 모델링하는 식으로 작동. 대부분 실제 고차원 데이터셋이 더 낮은 저차원 매니폴드에 가깝게 놓여 있다는 매니폴드 가정에 근거함.
매니폴드 가정은 '처리해야 할 작업이 저차원의 매니폴드 공간에 표현되면 더 간단해질 것'이라는 가정과 병행되기도 함.
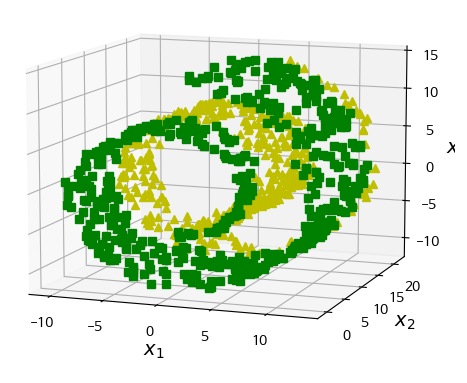 | 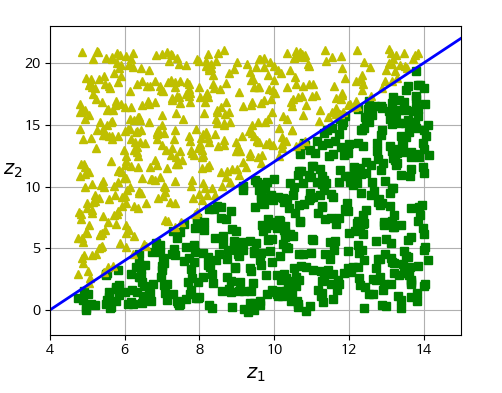 |
|---|
- 3D에서는 복잡한 결정 경계가 매니폴드 공간인 2D에서는 단순한 직선으로 결정 경계가 나타나는 경향
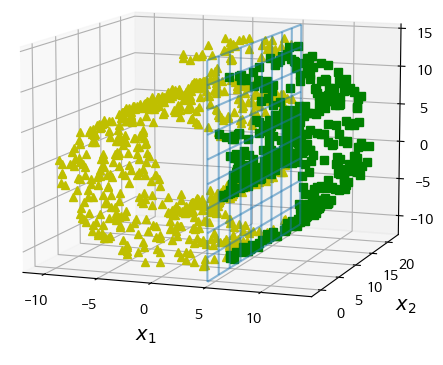 | 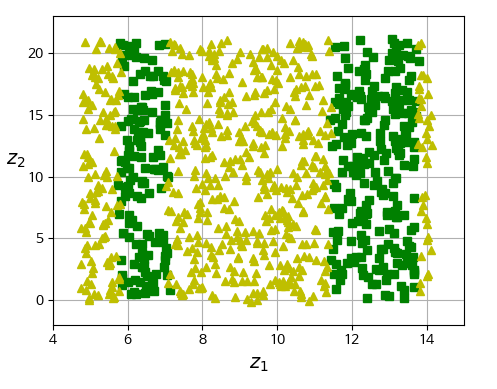 |
|---|
- 하지만 매니폴드 가정이 항상 성립하는 것은 아님.
- 오히려 결정 경계가 더 복잡해져버린 예시
정리하자면, 훈련시키기 전에 훈련 세트의 차원을 감소시키면 훈련 속도는 빨라지지만 항상 더 나은 해결책이 되는 것은 아님. 전적으로 데이터셋에 달린 문제.
8.3 주성분 분석
주성분 분석(principal component analysis, PCA) : 가장 인기 있는 차원 축소 알고리즘. 데이터에 가장 가까운 초평면을 정의한 다음, 데이터를 이 평면에 투영시키는 방법
8.3.1 분산 보존
올바른 초평면을 선택하는 것이 중요.
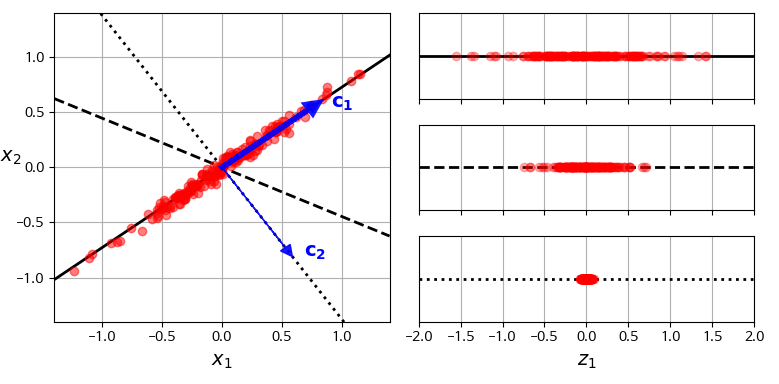
- 왼쪽 그래프는 간단한 2D 데이터셋이 세 개의 축과 표현
- 오른쪽 그래프는 데이터셋이 각 축에 투영된 결과. 실선에 투영된 것이 분산을 최대로 보존하는 것으로 파악됨.
- 분산이 최대로 보존되는 축을 선택하는 것이 정보가 가장 적게 손실 → 합리적
8.3.2 주성분
PCA는 훈련 세트에서 분산이 최대인 축을 탐색함. 그 축에 직교하고 남은 분산을 최대한 보존하는 두 번째 축을 찾음.
고차원 데이터셋이라면, PCA는 데이터셋에 있는 차원의 수만큼 세 번째, 네 번째, ... , n번째 축을 찾음.
i 번째 축을 이 데이터의 i번째 주성분(principal component, PC)라고 함.
훈련 세트의 주성분은 특잇값 분해(singular value decomposition, SVD)로 훈련 세트 행렬 를 세 개 행렬의 행렬 곱셈인 로 분해하여 구할 수 있음. 찾고자 하는 모든 주성분의 단위벡터가 에 담겨 있음.
import numpy as np
X = [...] # 임의의 3D 데이터셋
X_centered = X - X.mean(axis=0)
U, s, Vt = np.linalg.svd(X_centered)
c1 = Vt[0]
c2 = Vt[1]- svd() 함수를 이용해 3D 훈련 세트의 모든 주성분을 구하고, 처음 두 개의 PC를 정의하는 두 개의 단위 벡터를 추출하는 코드
- PCA는 데이터셋의 평균이 0이라고 가정함. 사이킷런의 PCA 클래스는 이 작업을 대신 처리해주지만, PCA를 직접 구현하거나 다른 라이브러리를 사용한다면 데이터를 원점에 맞춰야함.
8.3.2 d차원으로 투영하기
주성분을 모두 추출했다면 처음 d개의 주성분으로 정의한 초평면에 투영하여 데이터셋의 차원을 d차원으로 축소시킬 수 있음. 이 초평면은 분산을 최대한 보존하는 투영.
초평면에 훈련 세트를 투영하고 d차원으로 축소된 데이터셋 를 얻기 위해서는 행렬 와 의 첫 d열로 구성된 행렬 를 행렬 곱해야 함.
W2 = Vt[:2].T
X2D = X_centered @ W2- 첫 두 개의 주성분으로 정의된 평면에 훈련 세트를 투영하는 코드
8.3.4 사이킷런 사용하기
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X2D = pca.fit_transform(X)- components_ 속성에 의 전치가 담김
8.3.5 설명된 분산의 비율
pca.explained_variance_ratio_
# array([0.7578477 , 0.15186921])- 데이터셋 분산의 76%가 첫 번째 PC를 따라 놓여 있고 15%가 두 번째 PC를 따라 놓여 있음
8.3.6 적절한 차원 수 선택
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', as_frame=False)
X_train, y_train = mnist.data[:60_000], mnist.target[:60_000]
X_test, y_test = mnist.data[60_000:], mnist.target[60_000:]
pca = PCA()
pca.fit(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum >= 0.95) + 1 # d == 154- mnist 데이터셋을 로드하여 차원을 줄이지 않고 PCA 수행
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X_train)- n_components=d로 설정하여 PCA 수행
- 유지하려는 주성분의 수를 지정하기보다 보존하려는 분산의 비율을 n_components에 0.0~1.0 사이로 설정하는 편을 권장함
pca.n_components_
# 154- 실제 주성분 개수는 훈련 중에 결정되며, ncomponents 속상에 저장
분산을 차원 수에 대한 함수로 그리는 방법도 있음 (cumsum을 그래프로 그림)
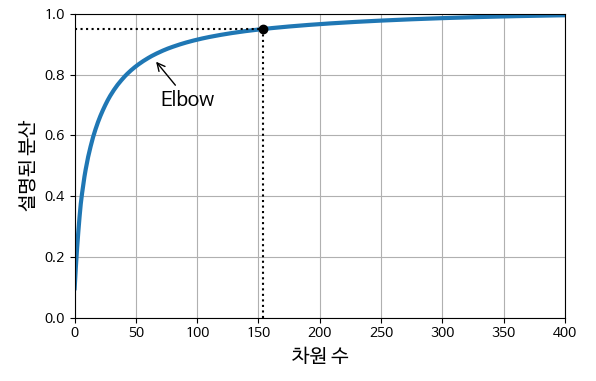
- 분산의 빠른 성장이 멈추는 변곡점이 있음
- 이 그래프는 차원을 약 100 으로 축소해도 분산을 크게 손해보지 않을 것으로 추정
지도 학습 작업의 전처리 단계로 차원 축소를 사용하는 경우, 다른 하이퍼파라미터와 마찬가지로 차원 수를 튜닝할 수 있음
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from sklearn.pipeline import make_pipeline
clf = make_pipeline(PCA(random_state=42),
RandomForestClassifier(random_state=42))
param_distrib = {
"pca__n_components" : np.arange(10, 80),
"randomforestclassifier__n_estimators" : np.arange(50, 500)
}
rnd_search = RandomizedSearchCV(clf, param_distrib, n_iter=10, cv=3,
random_state=42)
rnd_search.fit(X_train[:1000], y_train[:1000])rnd_search.best_params_
# {'randomforestclassifier__n_estimators': 475, 'pca__n_components': 57}- 784개 차원의 데이터셋을 23개 차원으로 축소함
- RandomForest를 사용한 사실도 결과에 영향을 줌.
SGDClassifier를 사용했을 때는 약 70개의 수치를 보임.
8.3.7 압축을 위한 PCA
차원 축소 후 훈련 세트는 훨씬 적은 공간을 차지함. 95%의 분산을 유지하도록 MNIST 데이터 세트에 PCA를 적용하면 784개의 특성 중에서 154개의 특성만 남음
→ 데이터셋의 크기는 원본의 20% 이하로 줄지만, 분산은 5%만 손실
압축된 데이터셋에 변환을 반대로 적용하여 784개의 차원으로 되돌릴 수도 있음. 투영에서 5%의 분산이 유실되었기 때문에 이렇게 해도 원본 데이터셋을 얻을 수는 없지만, 거의 원본이라고 할 수 있음.
재구성 오차(reconstruction error) : 원본 데이터와 재구성된 데이터 사이의 평균 제곱 거리
- 원본의 차원 수로 되돌리는 PCA 역변환 공식
8.3.8 랜덤 PCA
처음 d개의 주성분에 대한 근삿값을 빠르게 찾는 확률적 알고리즘
랜덤 PCA 계산 복잡도 :
완전한 SVD 계산 복잡도 :
→ d가 n보다 많이 작으면 완전 SVD보다 훨씬 빨라짐
svd_solver 매개변수
- "auto" : 기본값
- "randomized" : 랜덤 PCA
- "full" : 완전한 SVD
rnd_pca = PCA(n_components=154, svd_solver="randomized", random_state=42)
X_reduced = rnd_pca.fit_transform(X_train)8.3.9 점진적 PCA
PCA 구현의 문제 : SVD 알고리즘을 실행하기 위해 전체 훈련 세트를 메모리에 올려야 함
점진적 PCA(incremental PCA, IPCA) : 훈련 세트를 미니배치로 나눈 뒤 IPCA 알고리즘에 한 번에 하나씩 주입. 훈련 세트가 클 때 유용하고, 온라인으로 PCA 적용할 수 있음.
from sklearn.decomposition import IncrementalPCA
n_batches = 100
inc_pca = IncrementalPCA(n_components=154)
for X_batch in np.array_split(X_train, n_batches):
inc_pca.partial_fit(X_batch)
X_reduced = inc_pca.transform(X_train)- mnist 훈련 세트를 100개의 미니배치로 나누고 IncrementalPCA에 주입하여 154개의 차원으로 줄임
- 전체 훈련 세트를 사용하는 fit() 메서드가 아니라 partial_fit() 메서드를 미니배치마다 호출
mmap
numpy의 mmap 클래스 : 디스크의 이진 파일에 저장된 대규모 배열을 메모리에 있는 것처럼 조작할 수 있게 함. 원하는 데이터만 메모리에 로드할 수 있음
filename = "my_mnist.mmap"
X_mmap = np.memmap(filename, dtype='float32', mode='write', shape=X_train.shape)
X_mmap[:] = X_train
X_mmap.flush()- 메모리 매핑된 파일(memmap)을 생성하고 msint 훈련 세트를 복사한 다음, flush()를 호출하여 캐시에 남아 있는 모든 데이터가 디스크에 저장되도록 함
- 실제 환경에서는 X_train 보다 한 청크씩 로드하여 각 청크를 memmap 배열의 적절한 위치에 저장
X_mmap = np.memmap(filename, dtype='float32', mode='readonly').reshape(-1, 784)
batch_size = X_mmap.shape[0] // n_batches
inc_pca = IncrementalPCA(n_components=154, batch_size=batch_size)
inc_pca.fit(X_mmap)- memmap 파일을 로드하고 일반적인 넘파이 배열처럼 사용하는 예시
- IncrementalPCA로 차원 축소
- 특정 순간에 배열의 작은 부분만 사용하기 때문에 메모리 부족 문제가 발생하지 않음
- partial_fit() 대신 일반적인 fit() 을 호출해도 문제가 발생하지 않아 매우 편리함
원시 이진 데이터만 디스크에 저장되므로 배열을 로드할 때 데이터 타입과 배열의 크기를 지정해야함. 크기 안적으면 ID 배열을 반환.
매우 고차원인 데이터셋은 PCA가 매우 느려질 수 있음.
수만 개 이상의 특성이 있는 데이터셋을 다루는 경우에는 랜덤 투영을 사용하는 것을 고려해야 함.
8.4 랜덤 투영
랜덤 투영 알고리즘 : 랜덤한 선형 투영을 사용하여 데이터를 저차원 공간에 투영
johnson_lindenstrauss_min_dim()
더 많은 차원을 삭제할수록 더 많은 정보가 손실되고, 더 많은 거리가 왜곡됨. 주어진 허용 오차 이상으로 변하지 않도록 보장하기 위해 보존할 최소 차원 수를 결정하는 방정식이 구현된 함수.
GaussianRandomProjection
from sklearn.random_projection import GaussianRandomProjection
ε = 0.1
n = 20_000
np.random.seed(42)
P = np.random.randn(d, n) / np.sqrt(d)
X = np.random.randn(m, n)
X_reduced = X @ P.T
gaussian_rnd_proj = GaussianRandomProjection(eps=ε, random_state=42)
X_reduced = gaussian_rnd_proj.fit_transform(X)- fit() 메서드를 호출하면 johnson_lindenstrauss_min_dim()을 사용해 출력차원을 결정
- 랜덤한 행렬을 생성하여 components_속성에 저장
- transform() 호출하면 랜덤 행렬을 사용하여 투영을 수행
- eps : ε을 조정
- n_components : 특정 차원 d를 강제로 적용
SparseRandomProjection
GaussianRandomProjection과 동일한 방식으로 타깃 차원을 결정하고 동일한 크기의 랜덤 행렬을 생성한 후 투영 동일하게 수행. 랜덤 행렬이 희소하다는 점은 다름.
랜덤 행렬을 생성하고 차원을 줄이는 데 있어서도 빠르고, 입력이 희소할 경우 이 변환은 희소성을 유지함.
이전 접근 방식과 동일한 거리 보존 속성을 가지며 차원 축소 품질도 비슷하기 때문에, 일반적으로 규모가 크거나 희박한 데이터셋의 경우 이 변환기를 사용하는 것이 바람직함.
components_pinv = np.linalg.pinv(gaussian_rnd_proj.components_)
X_recovered = X_reduced @ components_pinv.T- 역변환 수행
- scipy의 pinv() 함수를 사용하여 성분 행렬의 유사역행렬을 계산하고, 축소된 데이터에 유사역행렬의 전치를 곱함.
랜덤 투영은 간단하고 빠르며 효율이 높고 강력한 차원 축소 알고리즘으로, 특히 고차원 데이터셋을 다룰 때 염두에 두어야 함.
8.5 지역 선형 임베딩
지역 선형 임베딩(locally linear embedding, LLE)은 비선형 차원 축소(nonlinear dimensionality reduction, NLDR)기술
투영에 의존하지 않는 매니폴드 학습으로,
1. 각 훈련 샘플이 최근접 이웃에 얼마나 선형적으로 연관되어 있는지 측정하고
2. 국부적인 관계가 가장 잘 보존되는 훈련 세트의 저차원 표현을 찾음
잡음이 너무 많지 않은 경우 꼬인 매니폴드를 펼치는 데 효과적
from sklearn.datasets import make_swiss_roll
from sklearn.manifold import LocallyLinearEmbedding
X_swiss, t = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
lle = LocallyLinearEmbedding(n_components=2, n_neighbors=10, random_state=42)
X_unrolled = lle.fit_transform(X_swiss)- LocallyLinearEmbedding 으로 스위스 롤을 펼치는 코드
- t : 스위스 롤의 회전 축을 따라 각 샘플의 위치를 포함하는 1D numpy 배열
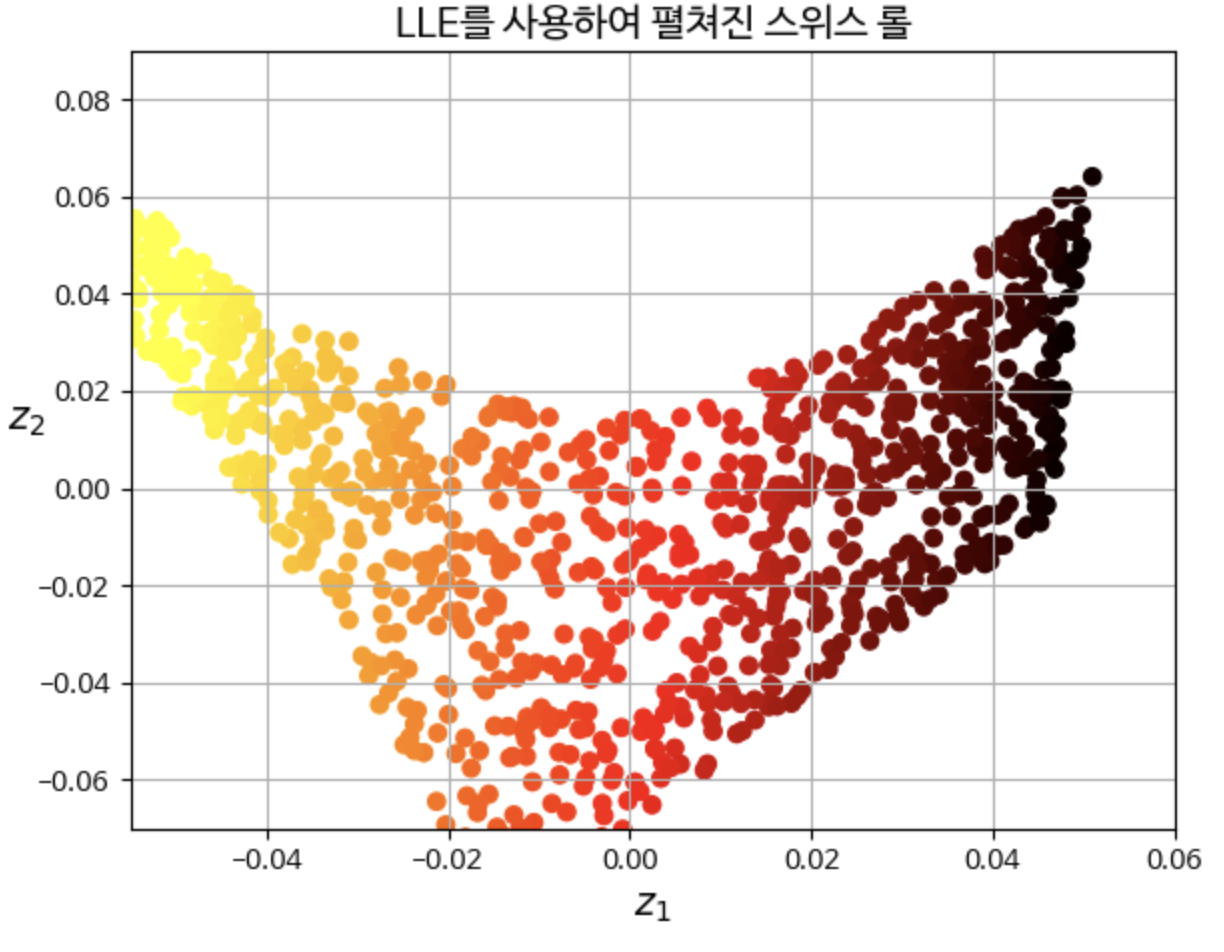
- 스위스 롤이 펼쳐졌고, 지역적으로는 샘플 간 거리가 잘 보존됨.
- 크게 보면 샘플 간 거리가 유지되지 않음. 스위스 롤은 직사각형.
- 그래도 LLE는 매니폴드를 모델링하는 데 잘 작동함.
8.6 다른 차원 축소 기법
- 다차원 스케일링
- Isomap
- t-SNE (t-distributed stochastic neighbor embedding)
- 선형 판별 분석 (linear discriminant analysis, LDA)
