검색 증강 생성(RAG)
- https://aws.amazon.com/ko/what-is/retrieval-augmented-generation/
- https://www.databricks.com/kr/glossary/retrieval-augmented-generation-rag
RAG란?
- RAG는 대규모 언어 모델(LLM)의 출력을 최적화하기 위해, 응답을 생성하기 전에 모델이 학습한 데이터 외부의 신뢰할 수 있는 지식 베이스에서 정보를 검색하는 방식
- 모델을 다시 훈련하지 않고도 특정 도메인이나 조직의 내부 지식 기반을 활용할 수 있으며 이는 LLM의 성능을 도메인 특화 지식으로 확장하면서도, 다양한 상황에서 관련성과 정확성을 높이기 위한 비용 효율적인 접근법
RAG가 중요한 이유
- LLM 기술의 특성상 LLM 응답에 대한 예측이 불가능하다. 또한 LLM 훈련 데이터는 정적이며 보유한 지식에 대한 마감일을 도입한다.
- 기존의 LLM은 아래와 같은 문제점이 있다.
- 답변이 없을 때 허위 정보를 제공
- 오래되거나 일반적인 정보를 제공
- 신뢰할 수 없는 출처로 응답 생성
- 용어 혼동으로 응답이 정확하지 않음
- RAG는 이러한 문제를 해결한다. LLM을 리디렉션하여 신뢰할 수 있는 사전 결정된 지식 출처에서 관련 정보를 검색한다.
RAG의 이점
- 비용 효율
- 기본적으로 챗봇은 파운데이션 모델(FM)을 사용하여 제작되고 FM은 재교육하는데 드는 시간이랑 비용이 많다.
- RAG는 새 데이터를 도입할 때 비용 효율적이다.
- 최신 정보
- LLM의 원본 훈련 데이터 소스가 요구사항에 적합해도 관련성을 유지하기 어렵다.
- RAG를 사용하면 최신 정보 소스에 직접 연결을 할 수 있고 LLM은 사용자에게 최신 정보를 제공하게 된다.
- 사용자 신뢰 강화
- RAG는 LLM은 소스의 저작자 표시를 통해 정확한 정보를 제공 가능
- 개발자 제어 강화
- LLM의 정보 소스를 제어하고 변경하여 변화하는 요구 사항, 부서 간 사용에 적응하고 민감한 정보 검색을 다양한 인증 수준으로 제한하고 적절한 응답을 생성하도록 한다.
- 특정 질문에 잘못된 정보를 참조할 경우 문제를 해결하게 수정할 수 있다.
RAG의 사용 사례
- 질의 응답 챗봇 - 회사 문서 및 지식 베이스에서 보다 정확한 답변을 자동으로 도출한다.
- 검색 증강 - LLM에서 생성된 답변으로 검색 결과를 보강하는 검색엔진과 LLM을 통합하면 정보 쿼리에 대한 응답을 개선한다
- 지식 엔진 - 데이터에 대한 질문 - 회사 데이터를 LLM의 컨텍스트로 사용할 수있어 이를 통해 답변을 받아올 수 있다
RAG 작동 원리
- LLM 단독으로는 제공하기 어려운 최신 정보, 신뢰 기반의 문서 기반 응답을 가능하게 해주는 프레임워크이므로 이를 기반으로 작동한다고 생각하면 편하다.
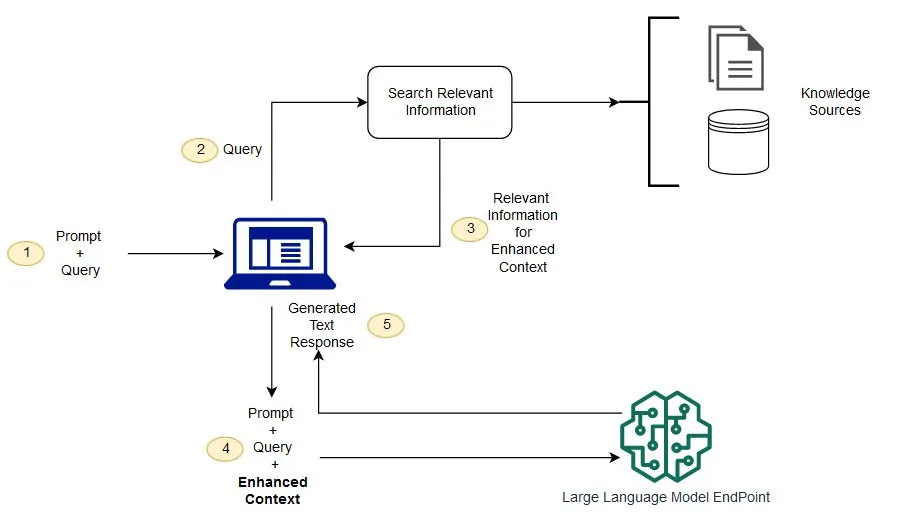
- 사용자 입력: Prompt + Query
- 사용자가 질문(Prompt + Query)을 입력하면, 이 입력은 시스템에 의해 처리되어 정보 검색 절차가 시작된다.
- 관련 정보 검색 요청
- 입력된 쿼리는 정보 검색 구성 요소로 전달되며, 이 구성 요소는 외부 지식 소스(문서, 데이터베이스, API 등)를 탐색해 관련 정보를 찾는다.
- 외부 데이터에서 정보 획득
- LLM이 원래 학습한 데이터가 아닌, 새로운 외부 데이터에서 정보를 수집한다. 예를 들어 회사의 연차 정책, 사내 규정, 기술 문서 등이 포함될 수 있다.
- 단순한 텍스트 검색이 아닌, 임베딩 언어 모델을 통해 텍스트를 수치화하여 벡터로 변환한 후, 벡터 검색이 가능한 데이터베이스에 저장한다.
- 프롬프트 보강: Enhanced Context 구성
- 검색된 관련 정보는 사용자의 질문과 결합되어, LLM이 이해할 수 있는 보강된 프롬프트(Enhanced Context)로 확장된다.
- 단순한 질문이 아닌 문맥이 풍부한 입력이 되어 모델에게 전달된다.
- 응답 생성
- 보강된 프롬프트를 바탕으로 LLM은 보다 정확하고 신뢰할 수 있는 응답을 생성한다.
- 외부 데이터 업데이트
- 지식의 최신성을 유지하기 위해 외부 문서는 비동기적으로 갱신되며, 이에 따라 임베딩된 벡터들도 주기적으로 업데이트된다.
실세 시스템에서 RAG가 사용되는 흐름
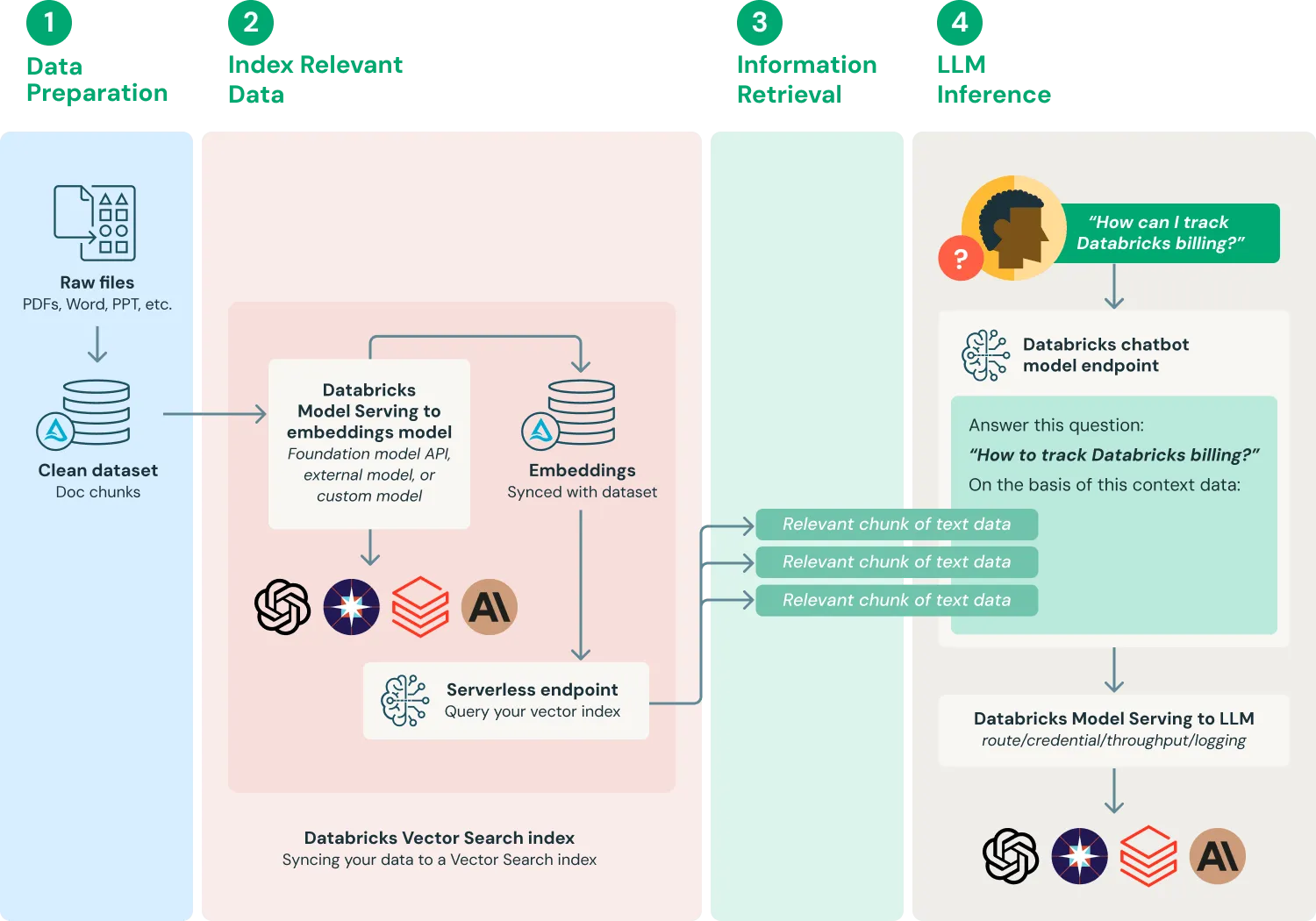
- 데이터 준비
- RAG 시스템에 사용되는 문서는 먼저 다양한 형식의 파일(PDF, 워드, 파워포인트 등)로 수집되며, 이때 제목, 작성자, 날짜 같은 메타데이터도 함께 저장된다. 수집된 문서에는 이름, 전화번호, 이메일처럼 개인을 식별할 수 있는 정보(PII)가 포함되어 있을 수 있는데, 이는 자동으로 감지되고, 익명 처리나 제거 과정을 거쳐 안전하게 정리된다.
- 정리된 문서는 그대로 사용할 수는 없고, AI가 이해할 수 있는 단위로 잘게 나누는 과정이 필요하다. 그래서 문서를 문단 단위나 일정한 글자 수, 토큰 수를 기준으로 잘라서 작은 조각으로 만든다. 이때, 문맥이 잘려서 이해가 어려워지지 않도록 문장을 일부 겹치게 나누는 방식도 함께 사용된다.
- RAG 애플리케이션에서 사용하려면 임베딩 모델 옵션과 문서를 컨텍스트로 사용하는 다운스트림 LLM 애플리케이션에 따라 문서를 적절한 길이로 분할한다.
- 관련 데이터 인덱싱
- 문서 임베딩을 생성하고 이 데이터로 Vector Search 인덱스를 수화(hydrate )한다.
- 수화란?
- 저장된 원시 데이터를 시스템이 활용할 수 있는 구조로 로딩하거나 변환하는 과정
- 관련 데이터 검색:
- 데이터에서 사용자의 쿼리와 관련된 부분을 검색한다. 그러면 텍스트 데이터가 LLM에 사용되는 프롬프트의 일부로 제공된다.
- LLM 애플리케이션 빌드
- LLM이 답변을 잘 생성할 수 있도록, 앞에서 검색된 문서 조각들과 사용자 질문을 하나의 프롬프트로 묶는 과정을 거친다. 이 과정을 프롬프트 증강이라고 부른다.
- 증강된 프롬프트는 LLM에게 전달되며, 모델은 이 정보를 바탕으로 보다 정확하고 풍부한 응답을 생성하게 된다.
- 이렇게 구성된 LLM 응답 시스템은 REST API 형태로 외부에 공개될 수 있다. 예를 들어, 고객 상담 챗봇이나 내부 지식 검색 서비스처럼 사용자는 단순히 질문을 입력하고, 시스템은 API를 통해 모델에 질문을 전달하고, 응답을 받아 화면에 출력하게 된다.
- 결과적으로 RAG는 복잡한 정보 검색과 생성 과정을 사용자 입장에서는 아주 간단한 형태로 제공할 수 있게 만들어준다.
MCP(Model Context Protocol)
MCP란?
- 대규모 언어 모델이 외부 데이터와 시스템을 더 효과적으로 활용할 수 있도록 설계된 연결 프로토콜
- USB-C 포트에 비유되며, USB-C가 다양한 기기와 주변 장치를 표준화된 방식으로 연결하는 MCP는 AI 모델이 다양한 데이터 소스와 도구에 표준화된 방식으로 연결될 수 있게 한다.
MCP의 주요 특징
- 개방형 표준 - MCP는 오픈소스로 공개되어 누구나 자유롭게 사용하고 개선할 수 있다. 또한 이는 Claude 모델뿐만 아니라 어떤 AI 시스템에도 사용할 수 있다.
- 양방향 연결 - AI 모델과 데이터 소스 간의 양방향 통신을 지원한다. 기존 API 호출 방식은 AI가 데이터를 요청하면 서버가 한 번 응답하고 끝났지만 MCP는 AI 모델과 데이터 소스가 지속적으로 연결된 상태에서 서로 정보를 주고 받는다
- 범용성과 표준화 - 다양한 데이터 소스와 도구를 하나의 표준 프로토콜로 연결. 각 데이터 소스들을 모두 단일 프로토콜을 통해 연결할 수 있다.
- 보안 및 신뢰성 - AI 모델과 데이터 소스 간의 안전하고 신뢰할 수 있는 연결 제공, 개인 정보 보호와 데이터 무결성을 유지
MCP의 핵심 구성 요소
- 클라이언트-서버 아키텍처를 기반으로 하며, AI 모델과 외부 데이터 소스 간의 원활한 통신을 가능하게 하는 구조로 설계된다.
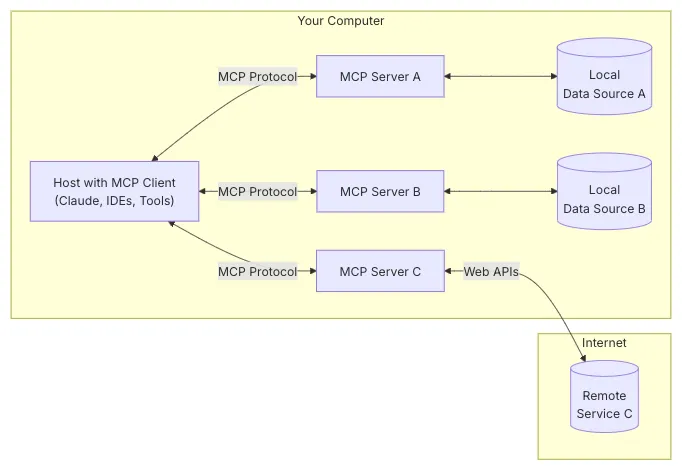
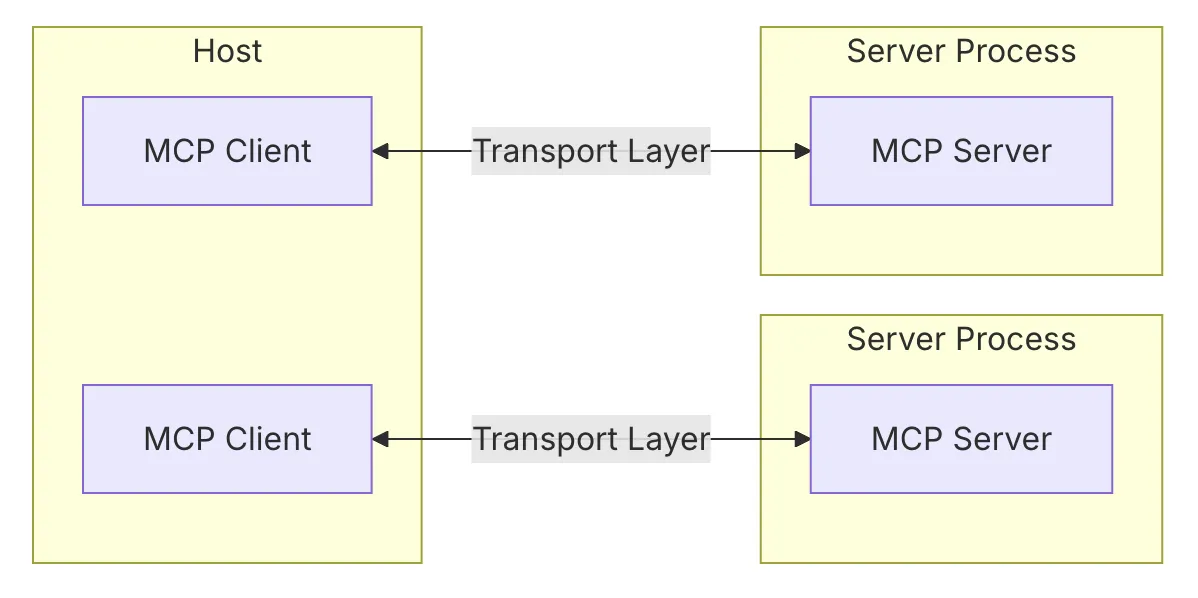
- 호스트(Host)
- AI 애플리케이션의 컨테이너이자 조정자 역할
- 여러 클라이언트 인스턴스를 관리
- 클라이언트 연결 권한과 생명주기를 제어
- 보안 정책과 동의 요구사항을 시행
- AI/LLM 통합 및 샘플링을 조정
- 클라이언트 간 컨텍스트 집계를 관리
- ex) Claude App, IDEs, AI 도구들
- MCP 클라이언트(MCP Clients)
- 호스트에 의해 생성되며 서버와의 독립적인 연결을 유지
- 서버당 하나의 상태 유지 세션을 설정
- 프로토콜 협상 및 기능 교환을 처리
- 양방향으로 프로토콜 메시지를 라우팅
- 구독 및 알림을 관리
- 서버 간 보안 경계를 유지
- MCP 서버(MCP Servers)
- 특화된 컨텍스트와 기능을 제공
- MCP 기본 요소를 통해 리소스, 도구 및 프롬프트를 노출
- 독립적으로 작동하며 집중된 책임을 가짐
- 클라이언트 인터페이스를 통해 샘플링을 요청
- 보안 제약을 준수
- 로컬 프로세스 또는 원격 서비스
MCP의 작동 방식
- 연결 설정(Connection Establishment)
- 호스트 애플리케이션(예: Claude Desktop)이 MCP 클라이언트를 생성
- 클라이언트는 MCP 서버와 연결을 설정
- 연결 설정 과정에서 프로토콜 버전, 기능, 권한 등이 협상
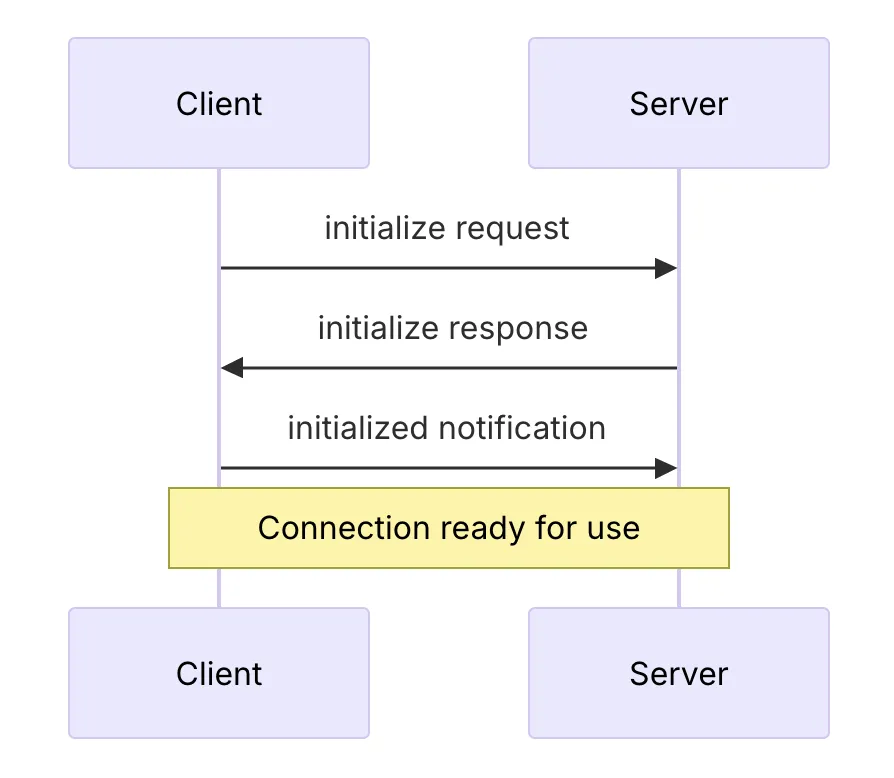
- 컨텍스트 교환(Context Exchange)
- 서버는 클라이언트에게 데이터 소스의 컨텍스트 정보를 제공
- 클라이언트는 이 정보를 호스트 프로세스에 전달
- 호스트 프로세스는 여러 클라이언트로부터 받은 컨텍스트를 집계하여 AI 모델에 제공
- 도구 호출(Tool Invocation)
- AI 모델은 특정 작업을 수행하기 위해 도구 호출을 요청
- 호스트 프로세스는 이 요청을 적절한 클라이언트에 전달
- 클라이언트는 서버에 도구 호출 요청을 전송
- 서버는 요청된 작업을 수행하고 결과를 클라이언트에 반환
- 결과 처리(Result Processing)
- 클라이언트는 서버로부터 받은 결과를 호스트 프로세스에 전달
- 호스트 프로세스는 이 결과를 AI 모델에 제공
- AI 모델은 이 정보를 바탕으로 응답을 생성
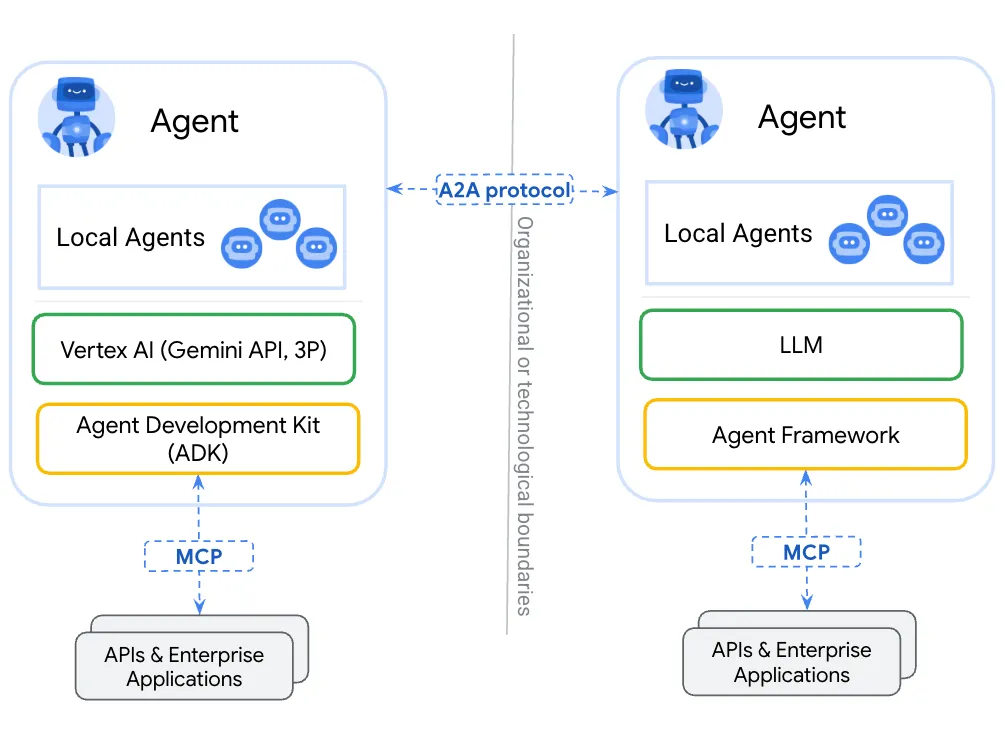
A2A(Agent-to-Agent)
A2A란?
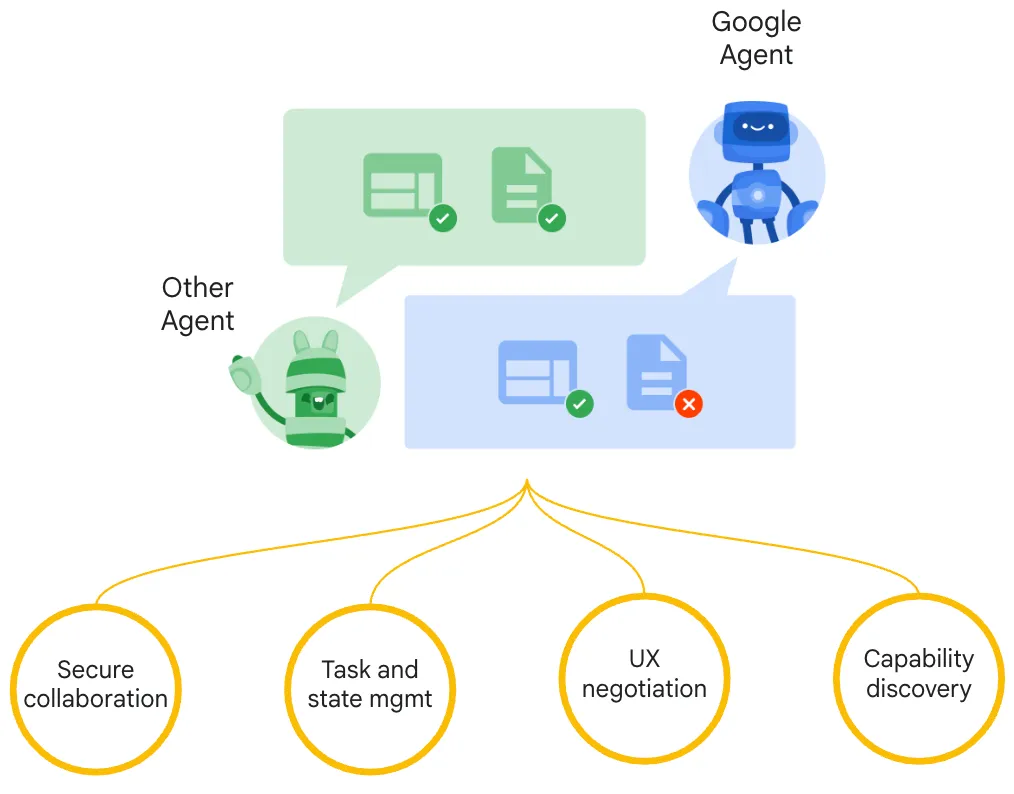
- 서로 다른 인공지능 에이전트들이 통신하고 협업할 수 있도록 만든 오픈 통신 프로토콜
A2A의 기능
- 기능 탐색 (Capability Discovery): 에이전트는 JSON 형식의 “에이전트 카드(Agent Card)“를 사용하여 자신의 기능을 알린다.
- 작업 관리 (Task and state Management): 클라이언트와 원격 에이전트 간의 통신은 작업 완료를 지향하며, 작업의 결과물은 “산출물(artifact)“로 표현된다.
- 보안 협업 (Secure Collaboration): 에이전트는 엔터프라이즈 인증과 OpenAPI 기반의 권한 부여를 지원하여 보다 안전하게 컨텍스트, 응답, 산출물 또는 사용자 지침을 전달하여 협업한다.
- 사용자 경험 협상 (User Experience Negotiation): 각 메시지에는 생성된 이미지와 같이 완전히 구성된 콘텐츠 조각인 “부분(parts)“이 포함되며, 사용자 인터페이스 기능에 대한 협상을 명시적으로 포함한다.

크레페는 귀엽다